Hallo, mein Name ist Maxim, ich bin ein Systemadministrator. Vor drei Jahren begannen meine Kollegen und ich, Produkte auf Microservices zu übertragen, und entschieden uns, Openstack als Plattform zu verwenden. Bei der Automatisierung von Testschaltungen waren wir mit einer Reihe nicht offensichtlicher Rechen konfrontiert. In diesem Beitrag geht es um die Nuancen der Einrichtung von OpenStack, die auf der fünften Seite der Suchmaschinenergebnisse kaum zu finden sind (oder besser gesagt auf der ersten Seite).
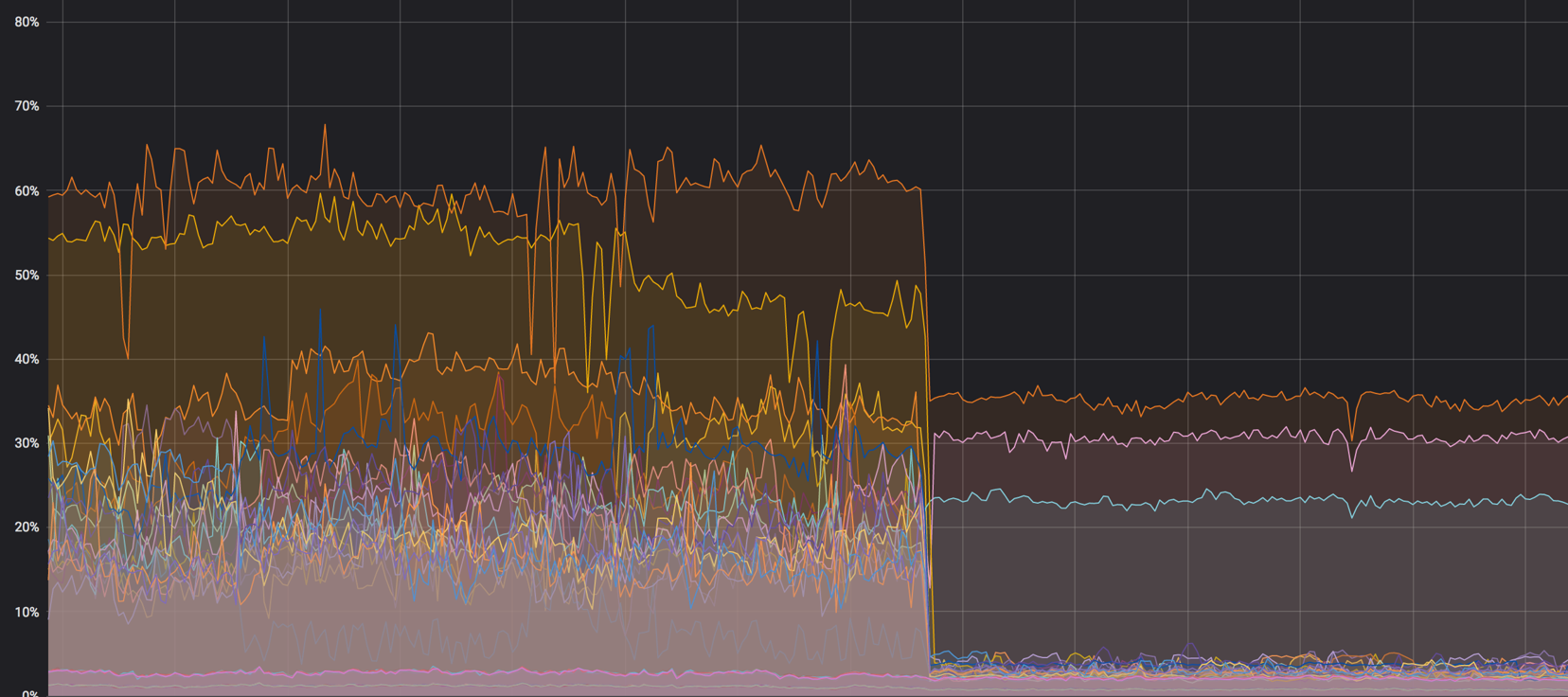
Die Last auf den Kernen: es war
NAT
In einigen Fällen verwenden wir Dualstack. In diesem Fall empfängt die virtuelle Maschine zwei Adressen gleichzeitig - IPv4 und IPv6. Zuerst haben wir sichergestellt, dass die "schwebende" v4-Adresse im internen Netzwerk über NAT zugewiesen wurde und der Computer v6 über BGP empfangen hat, aber es gibt einige Probleme damit.
NAT - ein zusätzlicher Knoten im Netzwerk, bei dem Sie auch ohne ihn die normale Lastverteilung überwachen müssen. Das Auftreten von NAT im Netzwerk führt fast immer zu Schwierigkeiten beim Debuggen - auf dem Host eine IP, in der Datenbank eine andere, und es wird schwierig, die Anforderung zu verfolgen. Die Massensuche beginnt und die Lösung befindet sich weiterhin in OpenStack.
Trotzdem erlaubt NAT keine normale Segmentierung des Zugriffs zwischen Projekten. Alle Projekte haben ihre eigenen Subnetze, Floating IPs werden ständig migriert, und mit NAT wird es absolut unmöglich, dies zu verwalten. Einige Installationen sprechen von der Verwendung von NAT 1 in 1 (die interne Adresse unterscheidet sich nicht von der externen), aber dies lässt immer noch unnötige Glieder in der Kette der Interaktion mit externen Diensten. Wir sind zu dem Schluss gekommen, dass für uns die beste Option ein BGP-Netzwerk ist.
Je einfacher desto besser
Wir haben verschiedene Automatisierungstools ausprobiert, uns aber für Ansible entschieden. Dies ist ein gutes Tool, aber seine Standardfunktionalität (auch unter Berücksichtigung zusätzlicher Module) reicht in einigen schwierigen Situationen möglicherweise nicht aus.
Über das Ansible-Modul können Sie beispielsweise nicht angeben, von welchen Subnetzadressen Sie zugewiesen werden sollen. Das heißt, Sie können ein Netzwerk angeben, aber keinen bestimmten Adresspool festlegen. Der Shell-Befehl, der die Floating-IP erstellt, hilft hier:
openstack floating ip create -c floating_ip_address -f value -project \ {{ project name }} —subnet private-v4 CLOUD_NET
Ein weiteres Beispiel für fehlende Funktionen: Aufgrund von Dualstack können wir keinen Router mit zwei Ports für Version 4 und Version 6 ordnungsgemäß erstellen. Hier bietet sich ein Bash-Skript an:
Das Skript erstellt einen Router, fügt ihm Subnetze der Versionen 4 und 6 hinzu und weist ein externes Gateway zu.
Wiederholen Sie den Vorgang
In jeder unverständlichen Situation - neu starten. Versuchen Sie es erneut, erstellen Sie eine Instanz, einen Router oder einen DNS-Eintrag, da Sie Ihr Problem nicht immer schnell verstehen. Ein erneuter Versuch kann die Verschlechterung des Dienstes verzögern, und zu diesem Zeitpunkt können Sie das Problem ruhig und ohne Nerven lösen.
Alle oben genannten Tipps funktionieren hervorragend mit Terraform, Puppet und allem anderen.
Alles hat seinen Platz
Jeder große Dienst (OpenStack ist keine Ausnahme) kombiniert viele kleinere Dienste, die sich gegenseitig in der Arbeit stören können. Hier ist ein Beispiel.
Netzwerkagent Neutron-L2-Agent ist für die Netzwerkkonnektivität in OpenStack verantwortlich. Wenn sich alle anderen Agenten teilweise auf den Controllern befinden, ist L2 aufgrund der Besonderheiten überall vorhanden.
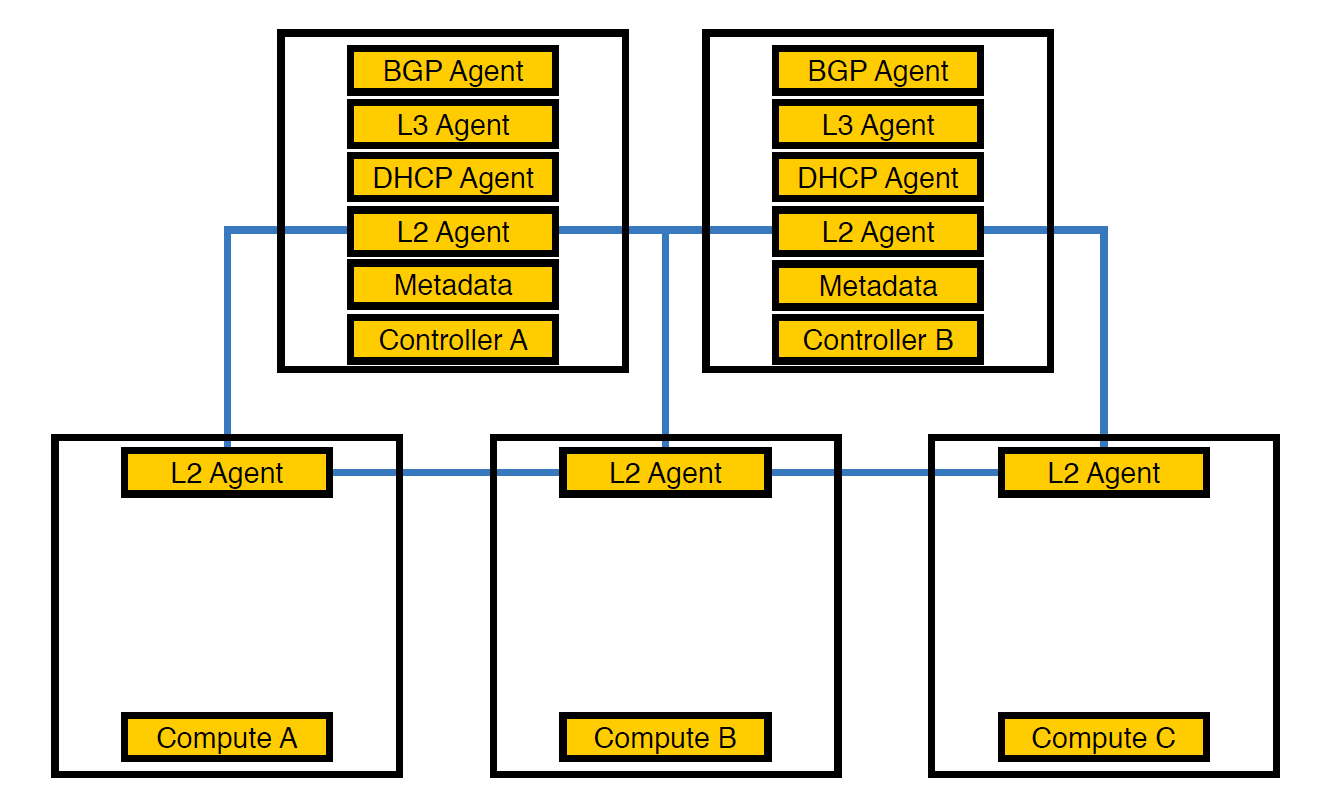
So sah unsere Infrastruktur von Anfang an aus, bis die Anzahl der Programme 50 überstieg
Zu diesem Zeitpunkt stellten wir fest, dass die Controller aufgrund dieser Anordnung von Agenten die Last nicht bewältigen konnten, und übertrugen die Agenten auf Rechenknoten. Sie sind leistungsfähiger als Controller, und außerdem muss sich der Controller nicht um die Verarbeitung von allem kümmern - er muss die Aufgabe dem ausführenden Knoten übergeben, und der Knoten wird sie ausführen.

Übertragene Agenten zum Berechnen von Knoten
Dies reichte jedoch nicht aus, da sich eine solche Anordnung negativ auf die Leistung virtueller Maschinen auswirkte. Bei einer Dichte von 14 virtuellen Kernen pro physischem System kann dies mehrere virtuelle Maschinen gleichzeitig betreffen, wenn ein Netzwerkagent mit dem Laden des Streams beginnt.
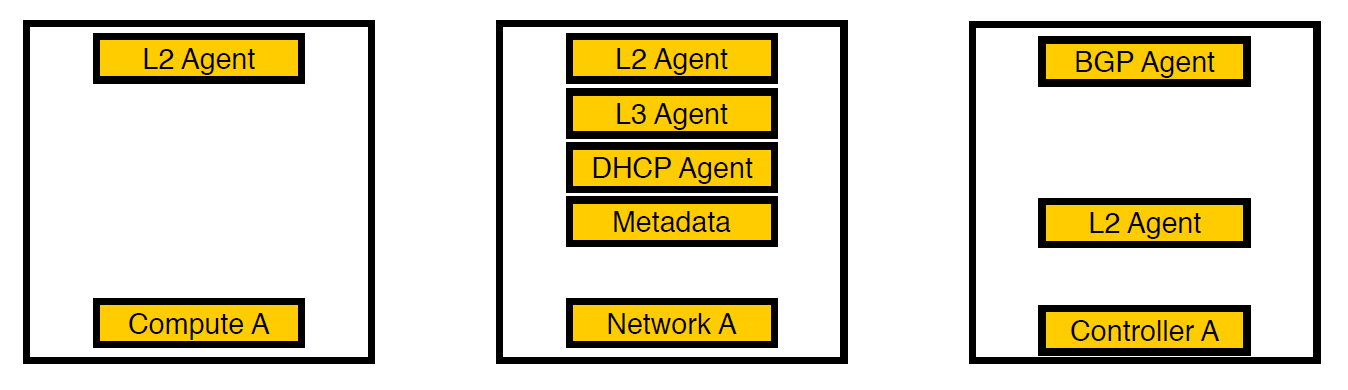
Dritte Iteration. Ausgewählte Knoten wurden angezeigt.
Wir haben nachgedacht und die Agenten auf separate Netzwerkknoten verschoben. Jetzt verbleiben nur noch Dienste für virtuelle Maschinen auf Rechenknoten, alle Agenten arbeiten auf Netzwerkknoten und nur BGP-Agenten, die sich mit dem v6-Netzwerk befassen, verbleiben auf den Controllern (da ein BGP-Agent nur einen Netzwerktyp bedienen kann). L2 blieb überall, denn ohne es würde, wie wir oben geschrieben haben, keine Konnektivität im Netzwerk bestehen.
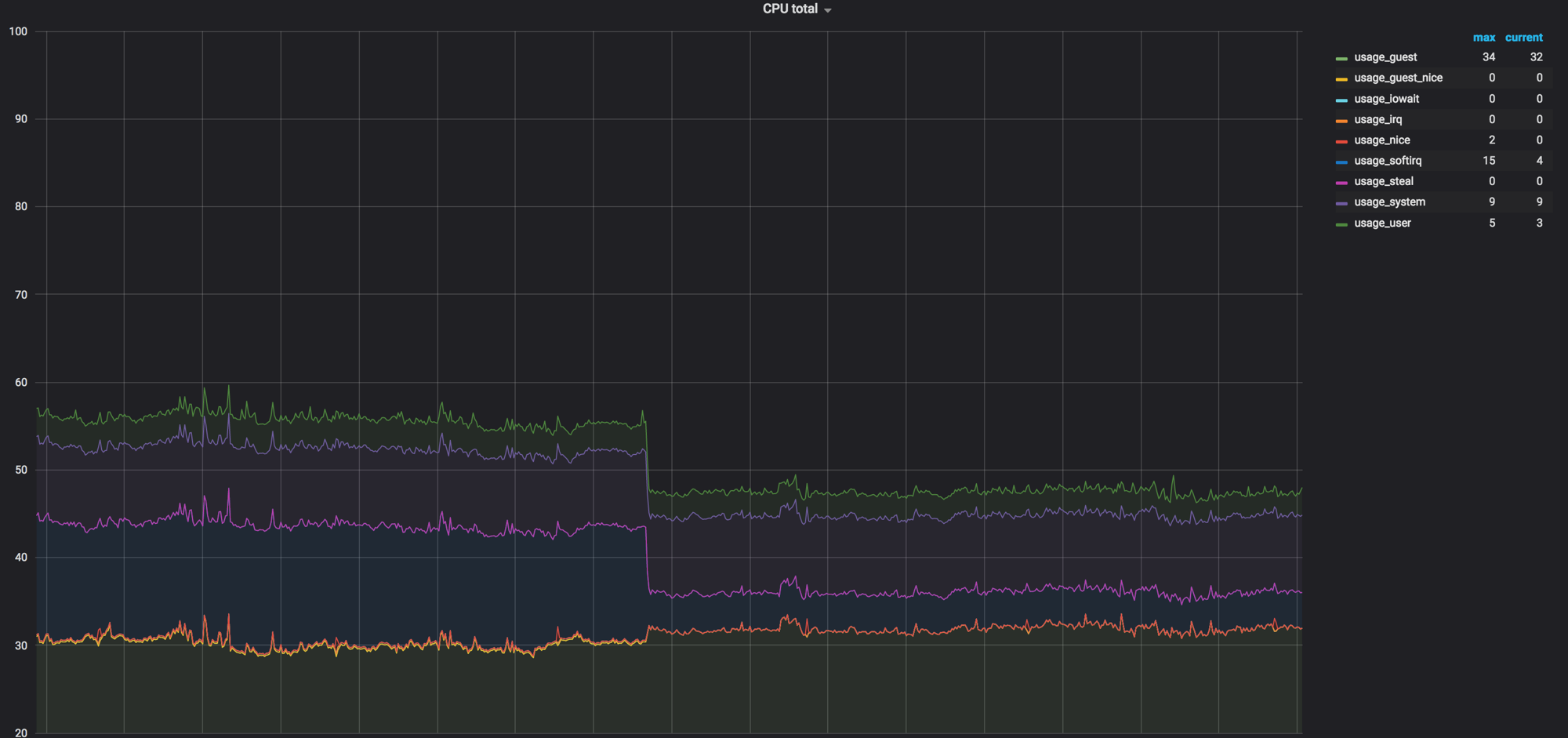
Laden Sie das Diagramm der Rechenknoten, bevor alles gemischt ist. Es war ungefähr 60%, aber die Last fiel unbedeutend

Durch das Laden von softirq vor den Netzwerkagenten wurden die Rechenknoten entfernt. 3 Kerne blieben geladen. Zu dieser Zeit dachten wir, es sei normal
Code als Dokumentation
Manchmal kommt es vor, dass der Code die Dokumentation ist, insbesondere bei so großen Diensten wie OpenStack. Bei einem sechsmonatigen Veröffentlichungszyklus vergessen Entwickler oder haben einfach keine Zeit, einige Dinge zu dokumentieren. Dies stellt sich wie im folgenden Beispiel heraus.
Über Timeouts
Sobald wir gesehen haben, dass Neutron-Aufrufe von Open vSwitch nicht in fünf Sekunden passen und das Timeout abfällt.
127.0.0.1:29696: no response to inactivity probe after 10 seconds, disconnecting neutron.agent.ovsdb.native.commands TimeoutException: Commands [DbSetCommand(table=Port, col_values=(('tag', 11),), record=qtoq69a81c6-e2)] exceeded timeout 5 seconds
Natürlich haben wir angenommen, dass dies irgendwo in den Einstellungen behoben ist. Wir haben uns das Konfigurations-, Dokumentations- und Deb-Paket angesehen, aber zuerst haben sie nichts gefunden. Als Ergebnis wurde die Beschreibung der gewünschten Einstellung auf der fünften Seite der Suchergebnisse gefunden - wir haben uns den Code erneut angesehen und die richtige Stelle gefunden. Die Einstellung ist folgende:
ovs_vsctl_timeout = 30
Wir stellten es für 30 Sekunden ein (es war 5) und alles begann etwas besser zu funktionieren.
Folgendes ist nicht offensichtlich: Wenn Sie Netzwerkkomponenten neu starten, werden möglicherweise einige Open vSwitch-Einstellungen zurückgesetzt. Dies geschieht beispielsweise mit ovs-vsctl inactivity_probe. Dies ist ebenfalls eine Zeitüberschreitung, wirkt sich jedoch auf die Aufrufe von ovs-vsctl selbst an die Datenbank aus. Wir haben es zu systemd init hinzugefügt, wodurch wir alle Switches mit den Parametern starten konnten, die wir beim Start benötigen.
ovs-vsctl set Controller "br-int" inactivity_probe=30000
Informationen zu den Netzwerkstapeleinstellungen
Wir mussten uns auch ein wenig von den allgemein akzeptierten Einstellungen im Netzwerkstapel entfernen, die wir auf unseren anderen Servern verwenden.
Hier ist die Einstellung, wie lange es dauert, ARP-Datensätze in einer Tabelle zu speichern:
net.ipv4.neigh.default.base_reachable_time = 60 net.ipv4.neigh.default.gc_stale_time=60
Der Standardwert ist 1 Tag. Im Allgemeinen kann ein Schema einige Wochen leben, aber pro Tag können Schemata 4-6 Mal neu erstellt werden, während sich die Entsprechung von MAC-Adresse und IP-Adresse ständig ändert. Damit sich kein Müll ansammelt, stellen wir die Zeit auf eine Minute ein.
net.ipv4.conf.default.arp_notify = 1 net.nf_conntrack_max = 1000000 (default 262144) net.netfilter.nf_conntrack_max = 1000000 (default 262144)
Darüber hinaus haben wir das Senden von ARP-Benachrichtigungen beim Erhöhen der Netzwerkschnittstelle erzwungen. Wir haben auch die Conntrack-Tabelle vergrößert, da wir bei Verwendung von NAT und Floating IP nicht den Standardwert hatten. Auf eine Million erhöht (Standardeinstellung 262 144), wurde alles noch besser.
Wir korrigieren die Größe der MAC-Tabelle von Open vSwitch selbst:
ovs-vsctl set bridge bt-int other-config:mac-table-size=50000 (default 2048)

Nach allen Einstellungen wurden 40% der Last fast Null
RX-Flow-Hash
Um die Verarbeitung des udp-Verkehrs auf alle Warteschlangen und Prozessorthreads zu verteilen, haben wir rx-flow-hash eingefügt. Auf Intel-Netzwerkkarten, nämlich im i40e-Treiber, ist diese Option standardmäßig deaktiviert. Wir haben Hypervisoren mit 72 Kernen in unserer Infrastruktur, und wenn nur einer beschäftigt ist, ist dies nicht sehr optimal.
Es wird so gemacht:
ethtool -N eno50 rx-flow-hash udp4 sdfn

Eine wichtige Schlussfolgerung: Sie können alles überhaupt konfigurieren. Die Standardkonfiguration passt irgendwann (wie wir), aber das Problem mit Zeitüberschreitungen machte eine Suche erforderlich. Und das ist normal.
Sicherheitsregeln
Entsprechend den Anforderungen des Sicherheitsdienstes haben alle Projekte innerhalb des Unternehmens persönliche und globale Regeln - es gibt ziemlich viele davon. Als wir 300 virtuelle Maschinen auf einen Hypervisor ins Ausland verlegten, floss dies alles in 80.000 Regeln für iptables ein. Für iptables selbst ist dies kein Problem, aber Neutron lädt diese Regeln von RabbitMQ in einen Stream (weil es in Python geschrieben ist und dort mit Multithreading alles traurig ist). Der Neutronenagent friert ein, verliert die Verbindung zu RabbitMQ und eine Kettenreaktion aufgrund von Zeitüberschreitungen. Nach der Wiederherstellung fordert Neutron alle Regeln erneut an, startet die Synchronisation und alles beginnt von vorne.
Gleichzeitig erhöhte sich die Zeit für die Erstellung von Ständen von 20 bis 40 Minuten auf bestenfalls eine Stunde.
Zuerst haben wir einfach alles mit Abrufen verpackt (bereits zu diesem Zeitpunkt haben wir festgestellt, dass das Problem nicht so schnell gelöst werden kann), und dann haben wir begonnen, FWaaS zu verwenden . Damit haben wir Sicherheitsregeln mit Rechenknoten herausgenommen, um Netzwerkknoten zu trennen, auf denen sich der Router selbst befindet.

Quelle - docs.openstack.org
Somit gibt es innerhalb des Projekts vollen Zugriff auf alles, was benötigt wird, und Sicherheitsregeln werden für externe Verbindungen angewendet. Also haben wir die Belastung von Neutron reduziert und sind auf 20 bis 30 Minuten zurückgekehrt, um eine Testumgebung zu erstellen.
Zusammenfassung
OpenStack ist eine coole Sache, bei der Sie Eisen recyceln, eine interne Cloud erstellen und darauf basierend etwas anderes erstellen können. Darüber hinaus gibt es in Telegram eine große Community und eine aktive Gruppe , in der sie uns zu Timeouts aufforderten.
Das ist alles Stellen Sie Fragen, meine Kollegen und ich sind bereit, unsere Erfahrungen zu beantworten und zu teilen.