Teil I. R extrahiert und zeichnet
Natürlich wurde PostgreSQL von Anfang an als universelles DBMS und nicht als spezialisiertes OLAP-System erstellt. Einer der großen Vorteile von Postgres ist jedoch die Unterstützung von Programmiersprachen, mit denen Sie alles daraus machen können. Angesichts der Fülle integrierter prozeduraler Sprachen ist es einfach nicht gleich. PL / R - Server-Implementierung von
R - der Lieblingssprache von Analysten - eine davon. Aber dazu später mehr.
R ist eine erstaunliche Sprache mit besonderen Datentypen - die
list kann beispielsweise nicht nur Daten verschiedener Typen, sondern auch Funktionen enthalten (im Allgemeinen ist die Sprache vielseitig, und wir werden nicht über ihre Zugehörigkeit zu einer bestimmten Familie sprechen, um keine störenden Diskussionen zu verursachen). Es hat einen hübschen
data.frame Datentyp, der eine RDBMS-Tabelle nachahmt - es ist eine Matrix, in der Spalten verschiedene Datentypen enthalten, die auf Spaltenebene gemeinsam sind. Daher (und aus anderen Gründen) ist die Arbeit mit Datenbanken in R sehr praktisch.
Wir werden in der
RStudio- Umgebung an der Befehlszeile arbeiten und über den
ODBC- RpostgreSQL- Treiber eine Verbindung zu PostgreSQL
herstellen . Sie sind einfach zu installieren.
Da R als eine Art Variante der
S- Sprache für diejenigen erstellt wurde, die sich mit Statistik beschäftigen, werden wir auch Beispiele aus einfachen Statistiken mit einfachen Grafiken geben. Wir haben kein Ziel, die Sprache einzuführen, aber es gibt ein Ziel, die Interaktion von
R und PostgreSQL zu zeigen .
Es gibt drei Möglichkeiten, in PostgreSQL gespeicherte Daten zu verarbeiten.
Erstens können Sie Daten mit allen geeigneten Mitteln aus der Datenbank pumpen, sie beispielsweise in JSON verpacken - R versteht sie - und sie in R weiterverarbeiten. Dies ist normalerweise nicht der effizienteste und sicherlich nicht der interessanteste Weg. Wir werden ihn hier nicht berücksichtigen.
Zweitens können Sie mit der Datenbank aus der R-Umgebung als Client kommunizieren - daraus lesen und Daten in sie speichern -, indem Sie den ODBC / DBI-Treiber verwenden und die Daten in R verarbeiten. Wir werden zeigen, wie dies gemacht wird.
Und schließlich können Sie die Verarbeitung mit den R-Tools durchführen, die sich bereits auf dem Datenbankserver befinden, wobei PL / R als integrierte prozedurale Sprache verwendet wird. Dies ist in einer Reihe von Fällen sinnvoll, da es in R beispielsweise bequeme Mittel zum Aggregieren von Daten gibt, die nicht in
pl/pgsql . Wir werden das auch zeigen.
Ein gängiger Ansatz besteht darin, die 2. und 3. Option in verschiedenen Phasen des Projekts zu verwenden: Debuggen Sie den Code zuerst als externes Programm und übertragen Sie ihn dann auf die Basis.
Fangen wir an. R interpretierte Sprache. Daher können Sie die Schritte ausführen oder den Code in ein Skript kopieren. Geschmackssache: Die Beispiele in diesem Artikel sind kurz.
Zunächst müssen Sie natürlich den entsprechenden Treiber anschließen:
# install.packages("RPostgreSQL") require("RPostgreSQL") drv <- dbDriver("PostgreSQL")
Die Zuweisungsoperation sieht in R, wie Sie sehen können, eigenartig aus. Im Allgemeinen bedeutet es in R a <- b dasselbe wie b -> a, aber die erste Schreibweise ist üblicher.
Wir nehmen die fertige Datenbank: die
Lufttransport-Demobase , die von den
Postgres Professional- Schulungsmaterialien verwendet wird. Auf
dieser Seite können Sie die Datenbankoption nach Geschmack (
dh Größe) auswählen und deren Beschreibung lesen. Wir reproduzieren das Datenschema der Einfachheit halber:
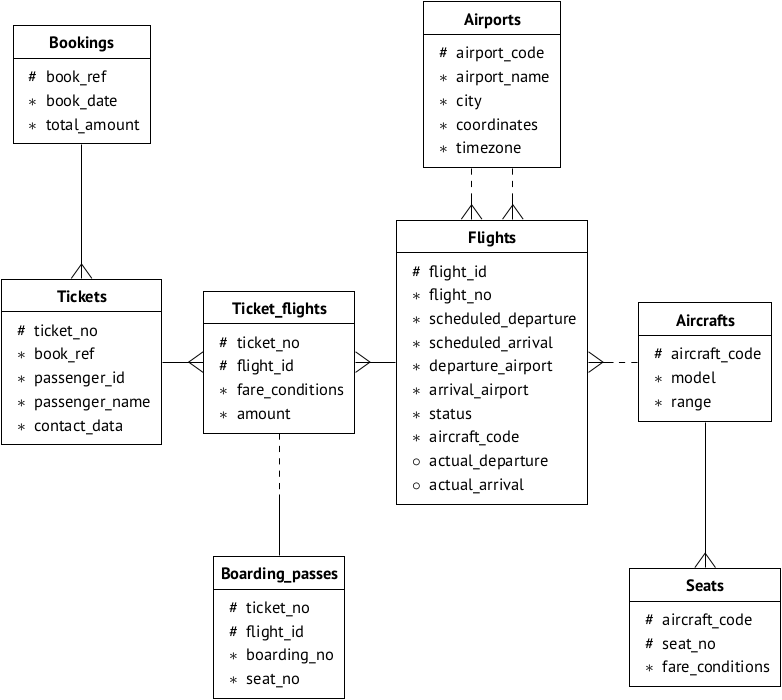
Angenommen, die Basis ist auf dem Server 192.168.1.100 installiert und heißt
demo . Verbinden:
con <- dbConnect(drv, dbname = "demo", host = "192.168.1.100", port = 5434, user = "u_r")
Wir fahren fort. Lassen Sie uns mit einer solchen Anfrage sehen, in welche Städte Flüge am häufigsten verspätet sind:
SELECT ap.city, avg(extract(EPOCH FROM f.actual_arrival) - extract(EPOCH FROM f.scheduled_arrival))/60.0 t FROM airports ap, flights f WHERE ap.airport_code = f.departure_airport AND f.scheduled_arrival < f.actual_arrival AND f.departure_airport = ap.airport_code GROUP BY ap.city ORDER BY t DESC LIMIT 10;
Um Minuten zu spät zu kommen, haben wir das Konstrukt postgres
extract(EPOCH FROM ...) verwendet, um die „absoluten“ Sekunden aus einem
timestamp zu extrahieren und durch 60,0 anstatt durch 60 zu teilen, um zu vermeiden, dass der Rest beim Teilen verworfen wird, was als Ganzzahl verstanden wird.
EXTRACT MINUTE kann nicht verwendet werden, da es zu Verzögerungen von mehr als einer Stunde kommt. Wir mitteln die Verspätung durch den
avg Operator.
Wir übergeben den Text an die Variable und senden die Anfrage an den Server:
sql1 <- "SELECT ... ;" res1 <- dbGetQuery(con, sql1)
Jetzt werden wir herausfinden, in welcher Form die Anfrage eingegangen ist. Zu diesem Zweck verfügt die R-Sprache über eine
class() -Funktion
class (res1)
Es wird gezeigt, dass das Ergebnis in den Typ
data.frame gepackt wurde,
data.frame , wie wir uns erinnern, ein Analogon der
data.frame : Tatsächlich handelt es sich um eine Matrix mit Spalten beliebiger Typen. Übrigens kennt sie die Namen der Spalten, und auf die Spalten kann beispielsweise wie folgt zugegriffen werden:
print (res1$city)
Es ist Zeit darüber nachzudenken, wie die Ergebnisse visualisiert werden können. Dazu können Sie sehen, was wir haben. Wählen Sie beispielsweise den entsprechenden Zeitplan aus
dieser Liste aus :
- R-Balkendiagramme (Balken)
- R-Boxplots (Lager)
- R-Histogramme
- R-Line-Diagramme (Diagramme)
- R-Streudiagramme (Punkt)
Es ist zu beachten, dass für jede Art von Eingabe ein für das Bild geeigneter Datentyp angegeben wird. Wählen Sie ein Balkendiagramm (liegende Balken). Für axiale Werte sind zwei Vektoren erforderlich. Der Typ "Vektor" in R ist einfach eine Menge von Werten des gleichen Typs.
c() ist ein Vektorkonstruktor.
Sie können die erforderlichen zwei Vektoren aus einem Ergebnis des Typs
data.frame wie folgt
data.frame :
Time <- res1[,c('t')] City <- res1[,c('city')] class (Time) class (City)
Die Ausdrücke auf der rechten Seite sehen seltsam aus, aber es ist eine bequeme Technik. Darüber hinaus können verschiedene Ausdrücke in R sehr kompakt geschrieben werden. In eckigen Klammern vor dem Komma der Index der Reihe, nach dem Komma - der Index der Spalte. Die Tatsache, dass das Komma nichts wert ist, bedeutet nur, dass alle Werte aus der entsprechenden Spalte ausgewählt werden.
Die Zeitklasse ist
numeric und die Stadtklasse ist ein
character . Dies sind verschiedene Vektoren.
Jetzt können Sie die Visualisierung selbst durchführen. Sie müssen eine Bilddatei angeben.
png(file = "/home/igor_le/R/pics/bars_horiz.png")
Danach folgt ein langwieriger Vorgang: Stellen Sie die Parameter (
par ) der Diagramme ein. Und um nicht zu sagen, dass alles in den R-Grafikpaketen intuitiv war. Beispielsweise bestimmt der Parameter
las die Position von Beschriftungen mit Werten entlang der Achsen relativ zu den Achsen selbst:
- 0 und standardmäßig parallel zu den Achsen;
- 1 - immer horizontal;
- 2 - senkrecht zu den Achsen;
- 3 - immer aufrecht
Wir werden nicht alle Parameter malen. Im Allgemeinen gibt es viele davon: Felder, Skalen, Farben - suchen Sie, experimentieren Sie nach Belieben.
par(las=1) par(mai=c(1,2,1,1))
Schließlich erstellen wir ein Diagramm aus den liegenden Spalten:
barplot(Time, names.arg=City, horiz=TRUE, xlab=" ()", col="green", main=" ", border="red", cex.names=0.9)
Das ist noch nicht alles. Ich muss noch eine letzte Sache sagen:
dev.off()

Zur Abwechslung zeichnen wir noch das Punktdiagramm der Verspätung. Entfernen Sie LIMIT aus der Anforderung, der Rest ist der gleiche. Ein Streudiagramm benötigt jedoch einen Vektor, nicht zwei.
Dots <- res2[,c('t')] png(file = "/home/igor_le/R/scripts/scatter.png") plot(input5, xlab="",ylab="",main=" ") dev.off()
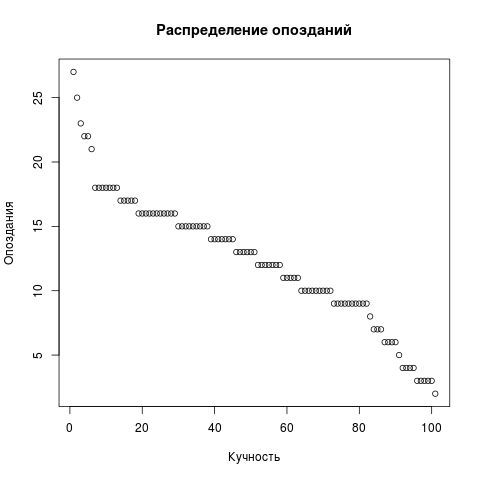
Zur Visualisierung haben wir Standardpakete verwendet. Es ist klar, dass R eine beliebte Sprache ist und Pakete um die Unendlichkeit existieren. Sie können nach bereits installierten fragen:
library()
Teil II R erzeugt Rentner
R ist nicht nur für die Datenanalyse, sondern auch für deren Generierung geeignet. Wo es umfangreiche statistische Funktionen gibt, kann es keine Vielzahl von Algorithmen zum Erstellen von Zufallssequenzen geben. Insbesondere können Sie typische (Gaußsche) und nicht ganz typische (Zipf) Verteilungen verwenden, um Datenbankabfragen zu simulieren.
Aber mehr dazu im nächsten Teil.