Dieser Artikel konzentriert sich auf das Schreiben und Unterstützen einer nützlichen und relevanten Spezifikation für ein REST-API-Projekt, wodurch viel zusätzlicher Code eingespart und die Integrität, Zuverlässigkeit und Transparenz des gesamten Projekts erheblich verbessert wird.
Was ist eine RESTful-API?
Das ist ein Mythos.
Im Ernst, wenn Sie glauben, dass Ihr Projekt eine RESTful-API hat, irren Sie sich mit ziemlicher Sicherheit. Die Idee von RESTful ist es, eine API zu erstellen, die in jeder Hinsicht den vom REST-Stil beschriebenen Architekturregeln und -beschränkungen entspricht. Unter realen Bedingungen ist dies jedoch fast unmöglich .
Einerseits enthält REST zu viele vage und mehrdeutige Definitionen. Beispielsweise werden einige Begriffe aus Wörterbüchern von HTTP-Methoden und Statuscodes in der Praxis nicht für den vorgesehenen Zweck verwendet, während viele von ihnen überhaupt nicht verwendet werden.
Andererseits schafft REST zu viele Einschränkungen. Beispielsweise ist die atomare Nutzung von Ressourcen in der realen Welt für die von mobilen Anwendungen verwendeten APIs nicht rational. Eine vollständige Weigerung, den Status zwischen Anforderungen zu speichern, ist im Wesentlichen ein Verbot des Mechanismus von Benutzersitzungen, die in vielen APIs verwendet werden.
Aber warte, nicht alles ist so schlimm!
Warum benötigen wir die REST-API-Spezifikation?
Trotz dieser Mängel bleibt REST mit einem vernünftigen Ansatz eine hervorragende Grundlage für das Entwerfen wirklich cooler APIs. Eine solche API sollte interne Einheitlichkeit, eine klare Struktur, eine bequeme Dokumentation und eine gute Abdeckung durch Unit-Tests aufweisen. All dies kann erreicht werden, indem eine Qualitätsspezifikation für Ihre API entwickelt wird.
Am häufigsten wird die REST-API- Spezifikation mit ihrer Dokumentation verknüpft. Im Gegensatz zur ersten (eine formale Beschreibung Ihrer API) soll die Dokumentation von Personen gelesen werden, z. B. von Entwicklern einer Mobil- oder Webanwendung, die Ihre API verwenden.
Zusätzlich zur eigentlichen Erstellung der Dokumentation kann eine ordnungsgemäße API-Beschreibung jedoch noch viele Vorteile bringen. In dem Artikel möchte ich Beispiele dafür nennen, wie Sie unter Verwendung der kompetenten Verwendung der Spezifikation:
- Vereinfachung und Zuverlässigkeit von Unit-Tests;
- Vorverarbeitung und Validierung von Eingabedaten konfigurieren;
- Automatisierung der Serialisierung und Gewährleistung der Integrität der Antworten;
- und nutzen Sie sogar die statische Typisierung.
Openapi
Das heute allgemein akzeptierte Format zur Beschreibung der REST-API ist OpenAPI , das auch als Swagger bezeichnet wird . Diese Spezifikation ist eine einzelne Datei im JSON- oder YAML-Format, die aus drei Abschnitten besteht:
- einen Header, der den Namen, die Beschreibung und die Version der API sowie zusätzliche Informationen enthält;
- eine Beschreibung aller Ressourcen, einschließlich ihrer Kennungen, HTTP-Methoden, aller Eingabeparameter sowie Codes und Formate des Antwortkörpers mit Links zu Definitionen;
- Alle Definitionen von Objekten im JSON-Schema- Format, die sowohl in Eingabeparametern als auch in Antworten verwendet werden können.
OpenAPI hat einen schwerwiegenden Nachteil - die Komplexität der Struktur und häufig die Redundanz . Bei einem kleinen Projekt kann der Inhalt der JSON-Spezifikationsdatei schnell auf mehrere tausend Zeilen anwachsen. Es ist nicht möglich, diese Datei manuell in diesem Formular zu verwalten. Dies ist eine ernsthafte Bedrohung für die Idee, eine aktuelle Spezifikation beizubehalten, wenn sich die API weiterentwickelt.
Es gibt viele visuelle Editoren, mit denen Sie die API beschreiben und die resultierende OpenAPI-Spezifikation erstellen können. Auf diesen basieren wiederum zusätzliche Dienste und Cloud-Lösungen, z. B. Swagger , Apiary , Stoplight , Restlet und andere.
Für mich waren solche Dienste jedoch nicht sehr praktisch, da es schwierig war, die Spezifikation schnell zu bearbeiten und mit dem Code-Schreibprozess zu kombinieren. Ein weiteres Minus ist die Abhängigkeit von der Menge der Funktionen jedes einzelnen Dienstes. Beispielsweise ist es praktisch unmöglich, vollwertige Unit-Tests nur über einen Cloud-Service durchzuführen. Die Codegenerierung und sogar die Erstellung von "Steckern" für Endpunkte sind in der Praxis praktisch nutzlos, obwohl dies sehr gut möglich erscheint.
Tinyspec
In diesem Artikel werde ich Beispiele verwenden, die auf dem nativen REST-API-Beschreibungsformat - tinyspec - basieren . Das Format besteht aus kleinen Dateien, die die im Projekt verwendeten Endpunkte und Datenmodelle mit einer intuitiven Syntax beschreiben. Dateien werden neben dem Code gespeichert, sodass Sie sie direkt beim Schreiben überprüfen und bearbeiten können. In diesem Fall wird tinyspec automatisch zu einer vollwertigen OpenAPI kompiliert, die sofort im Projekt verwendet werden kann. Es ist Zeit, Ihnen genau zu sagen, wie.
In diesem Artikel werde ich Beispiele aus Node.js (koa, express) und Ruby on Rails geben, obwohl diese Praktiken für die meisten Technologien gelten, einschließlich Python, PHP und Java.
Wenn die Spezifikation unglaublich nützlich ist
1. Unit-Tests von Endpunkten
Die verhaltensgesteuerte Entwicklung (BDD) ist ideal für die Entwicklung einer REST-API. Der bequemste Weg, Unit-Tests zu schreiben, ist nicht für einzelne Klassen, Modelle und Controller, sondern für bestimmte Endpunkte. In jedem Test emulieren Sie eine echte HTTP-Anforderung und überprüfen die Serverantwort. In Node.js gibt es zum Emulieren von Testanforderungen Supertest und Chai-http in Ruby on Rails - Airborne .
Angenommen, wir haben ein User und einen GET /users Endpunkt, der alle Benutzer zurückgibt. Hier ist die Tinyspec-Syntax, die dies beschreibt:
- User.models.tinyspec- Datei:
User {name, isAdmin: b, age?: i}
- Datei users.endpoints.tinyspec :
GET /users => {users: User[]}
So wird unser Test aussehen:
Node.js
describe('/users', () => { it('List all users', async () => { const { status, body: { users } } = request.get('/users'); expect(status).to.equal(200); expect(users[0].name).to.be('string'); expect(users[0].isAdmin).to.be('boolean'); expect(users[0].age).to.be.oneOf(['boolean', null]); }); });
Ruby on Rails
describe 'GET /users' do it 'List all users' do get '/users' expect_status(200) expect_json_types('users.*', { name: :string, isAdmin: :boolean, age: :integer_or_null, }) end end
Wenn wir eine Spezifikation haben, die Serverantwortformate beschreibt, können wir den Test vereinfachen und die Antwort einfach anhand dieser Spezifikation überprüfen . Dazu nutzen wir die Tatsache, dass unsere Tinyspec-Modelle in OpenAPI-Definitionen umgewandelt werden, die wiederum dem JSON-Schema-Format entsprechen.
Jedes Literalobjekt in JS (oder Hash in Ruby, ein dict in Python, ein assoziatives Array in PHP und sogar eine Map in Java) kann auf Konformität mit einem JSON-Schema getestet werden. Und es gibt sogar geeignete Plugins zum Testen von Frameworks, zum Beispiel jest-ajv (npm), chai-ajv-json-schema (npm) und json_matchers (rubygem) für RSpec.
Bevor Sie die Schemata verwenden, müssen Sie sie mit dem Projekt verbinden. Zuerst generieren wir die openapi.json-Spezifikationsdatei basierend auf tinyspec (diese Aktion kann vor jedem Testlauf automatisch ausgeführt werden):
tinyspec -j -o openapi.json
Node.js
Jetzt können wir den empfangenen JSON im Projekt verwenden und den definitions entnehmen, der alle JSON-Schemata enthält. Schemata können Querverweise ( $ref ) enthalten. Wenn wir also verschachtelte Schemata haben (z. B. Blog {posts: Post[]} ), müssen wir sie "erweitern", um sie für Validierungen zu verwenden. Dazu verwenden wir json-schema-deref-sync (npm).
import deref from 'json-schema-deref-sync'; const spec = require('./openapi.json'); const schemas = deref(spec).definitions; describe('/users', () => { it('List all users', async () => { const { status, body: { users } } = request.get('/users'); expect(status).to.equal(200);
Ruby on Rails
json_matchers kann mit $ref Links umgehen, erfordert jedoch auf bestimmte Weise separate Dateien mit Schemata im Dateisystem. swagger.json müssen Sie swagger.json in viele kleine Dateien swagger.json (mehr dazu hier ):
Danach können wir unseren Test folgendermaßen schreiben:
describe 'GET /users' do it 'List all users' do get '/users' expect_status(200) expect(result[:users][0]).to match_json_schema('User') end end
Hinweis: Das Schreiben von Tests auf diese Weise ist unglaublich praktisch. Insbesondere, wenn Ihre IDE das Ausführen von Tests und das Debuggen unterstützt (z. B. WebStorm, RubyMine und Visual Studio). Sie können also überhaupt keine andere Software verwenden, und der gesamte Entwicklungszyklus der API wird auf drei aufeinanderfolgende Schritte reduziert:
- Spezifikationsdesign (z. B. in Tinyspec);
- Schreiben eines vollständigen Satzes von Tests für hinzugefügte / geänderte Endpunkte;
- Entwicklung von Code, der alle Tests erfüllt.
2. Validierung der Eingabe
OpenAPI beschreibt das Format nicht nur von Antworten, sondern auch von Eingabedaten. Dies ermöglicht es uns, die vom Benutzer direkt während der Anfrage erhaltenen Daten zu validieren .
Angenommen, wir haben die folgende Spezifikation, die das Aktualisieren von Benutzerdaten sowie alle Felder beschreibt, die geändert werden können:
Früher haben wir uns Plugins zur Validierung in Tests angesehen. In allgemeineren Fällen gibt es jedoch Validierungsmodule für Ajv (npm) und JSON-Schema (Rubygem). Verwenden Sie diese und schreiben Sie einen Controller mit Validierung.
Node.js (Koa)
Dies ist ein Beispiel für Koa , den Nachfolger von Express, aber für Express sieht der Code ähnlich aus.
import Router from 'koa-router'; import Ajv from 'ajv'; import { schemas } from './schemas'; const router = new Router();
Wenn in diesem Beispiel die Eingabedaten nicht der Spezifikation entsprechen, gibt der Server eine 500 Internal Server Error Antwort an den Client zurück. Um dies zu verhindern, können wir den Validierungsfehler abfangen und eine eigene Antwort erstellen, die detailliertere Informationen zu bestimmten Feldern enthält, die den Test nicht bestanden haben, und auch der Spezifikation entspricht .
Fügen FieldsValidationError Datei FieldsValidationError eine Beschreibung des FieldsValidationError Modells FieldsValidationError :
Error {error: b, message} InvalidField {name, message} FieldsValidationError < Error {fields: InvalidField[]}
Und jetzt geben wir es als eine der möglichen Antworten unseres Endpunkts an:
PATCH /users/:id {user: UserUpdate} => 200 {success: b} => 422 FieldsValidationError
Mit diesem Ansatz können Sie Komponententests schreiben, die die Richtigkeit der Fehlerbildung mit falschen Daten überprüfen, die vom Client empfangen wurden.
3. Serialisierung von Modellen
Fast alle modernen Server-Frameworks verwenden ORM auf die eine oder andere Weise. Dies bedeutet, dass die meisten in der API im System verwendeten Ressourcen in Form von Modellen, deren Instanzen und Sammlungen dargestellt werden.
Das Generieren einer JSON-Darstellung dieser Entitäten zur Übertragung in der API-Antwort wird als Serialisierung bezeichnet . Es gibt eine Reihe von Plugins für verschiedene Frameworks, die Serialisierungsfunktionen ausführen, z. B. Sequelize-to-Json (npm), Acts_as_api (Rubygem), Jsonapi-Rails (Rubygem). Tatsächlich ermöglichen diese Plugins einem bestimmten Modell, eine Liste von Feldern anzugeben, die im JSON-Objekt enthalten sein müssen, sowie zusätzliche Regeln, um sie beispielsweise umzubenennen oder Werte dynamisch zu berechnen.
Schwierigkeiten beginnen, wenn wir mehrere verschiedene JSON-Darstellungen desselben Modells benötigen oder wenn ein Objekt verschachtelte Entitäten enthält - Assoziationen. Vererbung, Wiederverwendung und Verknüpfung von Serialisierern sind erforderlich.
Verschiedene Module lösen diese Probleme auf unterschiedliche Weise, aber denken wir mal, kann uns die Spezifikation wieder helfen? Tatsächlich sind bereits alle Informationen zu den Anforderungen für JSON-Darstellungen, alle möglichen Kombinationen von Feldern, einschließlich verschachtelter Entitäten, enthalten. So können wir einen automatischen Serializer schreiben.
Ich mache Sie auf ein kleines Modul Sequelize-Serialize (npm) aufmerksam, mit dem Sie dies für Sequelize-Modelle tun können. Es verwendet eine Instanz des Modells oder eines Arrays sowie die erforderliche Schaltung und erstellt iterativ ein serialisiertes Objekt, wobei alle erforderlichen Felder berücksichtigt werden und verschachtelte Schaltungen für die zugeordneten Entitäten verwendet werden.
Angenommen, wir müssen alle Benutzer, die Blog-Beiträge haben, einschließlich der Kommentare zu diesen Beiträgen, von der API zurückgeben. Wir beschreiben dies anhand der folgenden Spezifikation:
Jetzt können wir die Abfrage mit Sequelize erstellen und ein serialisiertes Objekt zurückgeben, das genau der oben beschriebenen Spezifikation entspricht:
import Router from 'koa-router'; import serialize from 'sequelize-serialize'; import { schemas } from './schemas'; const router = new Router(); router.get('/blog/users', async (ctx) => { const users = await User.findAll({ include: [{ association: User.posts, required: true, include: [Post.comments] }] }); ctx.body = serialize(users, schemas.UserWithPosts); });
Es ist fast magisch, oder?
4. Statische Eingabe
Wenn Sie so cool sind, dass Sie TypeScript oder Flow verwenden, haben Sie sich vielleicht schon gefragt: "Was ist mit meinen lieben statischen Typen ?!" . Mit den Modulen sw2dts oder swagger-to-flowtype können Sie alle erforderlichen Definitionen basierend auf JSON-Schemata generieren und für die statische Typisierung von Tests, Eingabedaten und Serialisierern verwenden.
tinyspec -j sw2dts ./swagger.json -o Api.d.ts --namespace Api
Jetzt können wir Typen in Controllern verwenden:
router.patch('/users/:id', async (ctx) => { // Specify type for request data object const userData: Api.UserUpdate = ctx.request.body.user; // Run spec validation await validate(schemas.UserUpdate, userData); // Query the database const user = await User.findById(ctx.params.id); await user.update(userData); // Return serialized result const serialized: Api.User = serialize(user, schemas.User); ctx.body = { user: serialized }; });
Und in den Tests:
it('Update user', async () => { // Static check for test input data. const updateData: Api.UserUpdate = { name: MODIFIED }; const res = await request.patch('/users/1', { user: updateData }); // Type helper for request response: const user: Api.User = res.body.user; expect(user).to.be.validWithSchema(schemas.User); expect(user).to.containSubset(updateData); });
Beachten Sie, dass die generierten Typdefinitionen nicht nur im API-Projekt selbst, sondern auch in Clientanwendungsprojekten verwendet werden können, um die Arten von Funktionen zu beschreiben, in denen die API funktioniert. Angular Kundenentwickler werden mit diesem Geschenk besonders zufrieden sein.
5. Geben Sie die Konvertierung der Abfragezeichenfolge ein
Wenn Ihre API aus irgendeinem Grund Anforderungen mit dem MIME-Typ application/x-www-form-urlencoded und nicht application/json akzeptiert, application/x-www-form-urlencoded der Anforderungshauptteil folgendermaßen aus:
param1=value¶m2=777¶m3=false
Gleiches gilt für Abfrageparameter (z. B. in GET-Anfragen). In diesem Fall kann der Webserver die Typen nicht automatisch erkennen. Alle Daten liegen in Form von Zeichenfolgen vor ( hier finden Sie eine Erläuterung im Repository des Moduls qpm npm). Nach dem Parsen erhalten Sie das folgende Objekt:
{ param1: 'value', param2: '777', param3: 'false' }
In diesem Fall wird die Anforderung nicht gemäß dem Schema validiert. Dies bedeutet, dass manuell überprüft werden muss, ob jeder Parameter das richtige Format hat, und auf den erforderlichen Typ gebracht werden muss.
Wie Sie vielleicht erraten haben, kann dies mit denselben Schemata aus unserer Spezifikation erfolgen. Stellen Sie sich vor, wir haben einen solchen Endpunkt und ein solches Schema:
Hier ist ein Beispiel für eine Anforderung an einen solchen Endpunkt
GET /posts?search=needle&offset=10&limit=1&filter[isRead]=true
Schreiben wir eine castQuery Funktion, die alle Parameter in die für uns erforderlichen Typen castQuery . Es wird ungefähr so aussehen:
function castQuery(query, schema) { _.mapValues(query, (value, key) => { const { type } = schema.properties[key] || {}; if (!value || !type) { return value; } switch (type) { case 'integer': return parseInt(value, 10); case 'number': return parseFloat(value); case 'boolean': return value !== 'false'; default: return value; } }); }
Die vollständigere Implementierung mit Unterstützung für verschachtelte Schemata, Arrays und null ist in Cast-with-Schema (npm) verfügbar. Jetzt können wir es in unserem Code verwenden:
router.get('/posts', async (ctx) => {
Beachten Sie, wie von den vier Zeilen des Endpunktcodes die drei Verwendungsschemata aus der Spezifikation stammen.
Best Practices
Separate Schemata zum Erstellen und Ändern
In der Regel unterscheiden sich die Schemata, die die Serverantwort beschreiben, von denen, die die Eingabe zum Erstellen und Ändern von Modellen beschreiben. Beispielsweise sollte die Liste der verfügbaren Felder für PATCH und PATCH Anforderungen streng begrenzt sein, während bei PATCH Anforderungen normalerweise alle Felder des Schemas optional sind. Die Schemata, die die Antwort bestimmen, sind möglicherweise freier.
Die automatische Generierung von tinyspec CRUDL- Endpunkten verwendet die Postfixes New und Update . User* können wie folgt definiert werden:
User {id, email, name, isAdmin: b} UserNew !{email, name} UserUpdate !{email?, name?}
Versuchen Sie, nicht dieselben Schemata für verschiedene Arten von Aktionen zu verwenden, um versehentliche Sicherheitsprobleme aufgrund der Wiederverwendung oder Vererbung alter Schemata zu vermeiden.
Semantik in Schemanamen
Der Inhalt derselben Modelle kann an verschiedenen Endpunkten variieren. Verwenden Sie die Postfixes With* und For* in Schemanamen, um zu zeigen, wie sie sich unterscheiden und wofür sie bestimmt sind. In tinyspec können Modelle auch voneinander vererbt werden. Zum Beispiel:
User {name, surname} UserWithPhotos < User {photos: Photo[]} UserForAdmin < User {id, email, lastLoginAt: d}
Postfixes können variiert und kombiniert werden. Die Hauptsache ist, dass ihr Name das Wesentliche widerspiegelt und die Vertrautheit mit der Dokumentation vereinfacht.
Trennung der Endpunkte nach Clienttyp
Häufig geben dieselben Endpunkte je nach Clienttyp oder Rolle des Benutzers, der auf den Endpunkt zugreift, unterschiedliche Daten zurück. Beispielsweise können die Endpunkte von GET /users und GET /messages für Benutzer Ihrer mobilen Anwendung und für Backoffice-Manager sehr unterschiedlich sein. Gleichzeitig kann das Ändern des Namens des Endpunkts selbst zu kompliziert sein.
Um denselben Endpunkt mehrmals zu beschreiben, können Sie seinen Typ in Klammern nach dem Pfad einfügen. Darüber hinaus ist es nützlich, Tags zu verwenden: Dies hilft dabei, die Dokumentation Ihrer Endpunkte in Gruppen zu unterteilen, von denen jede für eine bestimmte Gruppe von Clients Ihrer API konzipiert ist. Zum Beispiel:
Mobile app: GET /users (mobile) => UserForMobile[] CRM admin panel: GET /users (admin) => UserForAdmin[]
REST-API-Dokumentation
Sobald Sie eine Spezifikation im Tinyspec- oder OpenAPI-Format haben, können Sie eine schöne Dokumentation in HTML erstellen und zur Freude der Entwickler veröffentlichen, die Ihre API verwenden.
Zusätzlich zu den zuvor erwähnten Cloud-Diensten gibt es CLI-Tools, die OpenAPI 2.0 in HTML und PDF konvertieren. Anschließend können Sie es auf jedes statische Hosting herunterladen. Beispiele:
Kennen Sie weitere Beispiele? Teile sie in den Kommentaren.
Leider wird OpenAPI 3.0, das vor einem Jahr veröffentlicht wurde, immer noch schlecht unterstützt, und ich konnte keine würdigen Beispiele für eine darauf basierende Dokumentation finden: weder unter Cloud-Lösungen noch unter CLI-Tools. Aus dem gleichen Grund wird OpenAPI 3.0 in tinyspec noch nicht unterstützt.
Auf GitHub veröffentlichen
Eine der einfachsten Möglichkeiten, Dokumentation zu veröffentlichen, sind GitHub-Seiten . Aktivieren Sie einfach die statische Seitenunterstützung für das Verzeichnis /docs in Ihren Repository-Einstellungen und speichern Sie die HTML-Dokumentation in diesem Ordner.
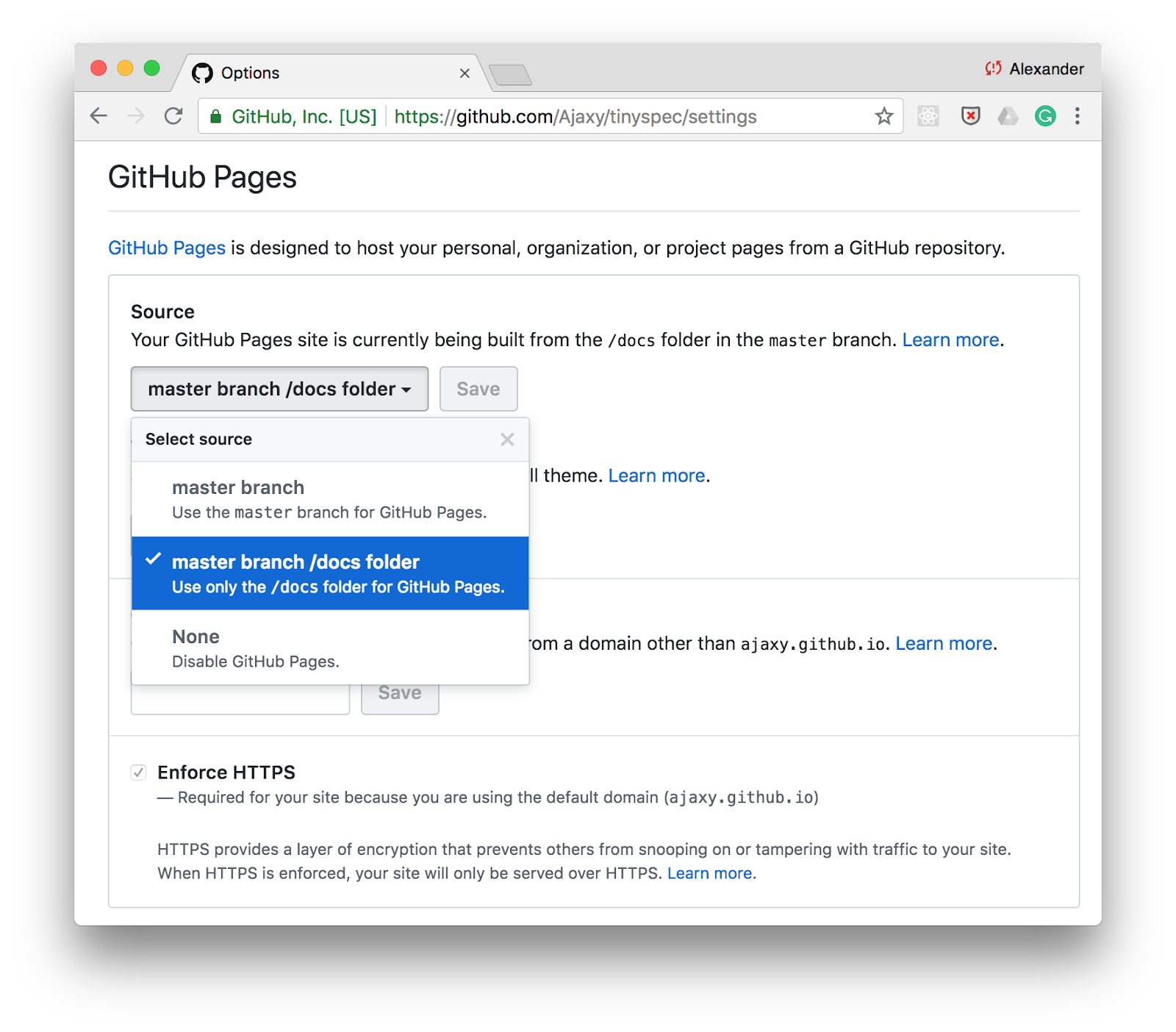
Sie können einen Befehl zum Generieren von Dokumentation über tinyspec oder ein anderes CLI-Tool in den scripts in package.json und die Dokumentation bei jedem Commit aktualisieren:
"scripts": { "docs": "tinyspec -h -o docs/", "precommit": "npm run docs" }
Kontinuierliche Integration
Sie können die Dokumentationsgenerierung in den CI-Zyklus aufnehmen und sie beispielsweise in Amazon S3 unter verschiedenen Adressen veröffentlichen, abhängig von der Umgebung oder Version Ihrer API, z. B. /docs/2.0 , /docs/stable , /docs/staging .
Tinyspec Wolke
Wenn Ihnen die Tinyspec-Syntax gefallen hat, können Sie sich unter tinyspec.cloud als Early Adopter registrieren . Wir werden auf dieser Basis einen Cloud-Service und eine CLI für die automatische Veröffentlichung von Dokumentationen mit einer großen Auswahl an Vorlagen und der Möglichkeit zur Entwicklung eigener Vorlagen erstellen.
Fazit
Die Entwicklung einer REST-API ist vielleicht die unterhaltsamste Aktivität von allen, die bei der Arbeit an modernen Web- und Mobilfunkdiensten vorhanden sind. Es gibt keinen Zoo mit Browsern, Betriebssystemen und Bildschirmgrößen, alles unterliegt unserer Kontrolle - „an Ihren Fingerspitzen“.
Die Beibehaltung der aktuellen Spezifikation und der Boni in Form verschiedener Automatisierungen, die gleichzeitig bereitgestellt werden, machen diesen Prozess noch angenehmer. Eine solche API wird strukturiert, transparent und zuverlässig.
In der Tat, selbst wenn wir uns mit der Erschaffung eines Mythos beschäftigen, warum machen wir ihn dann nicht schön?