Durch maschinelles Lernen können Sie den Dienst für Benutzer wesentlich komfortabler gestalten. Es ist nicht so schwierig, mit der Umsetzung von Empfehlungen zu beginnen. Die ersten Ergebnisse können auch ohne eine etablierte Infrastruktur erzielt werden. Hauptsache, Sie beginnen. Und nur dann, um ein Großsystem aufzubauen. So fing alles bei Booking.com an. Und was daraus resultierte, welche Ansätze derzeit verwendet werden, wie Modelle in die Produktion eingeführt werden, welche überwacht werden müssen, sagte Viktor Bilyk gegenüber HighLoad ++ Siberia. Mögliche Fehler und Probleme gingen nicht über Bord, es wird jemandem helfen, die Untiefen zu umgehen, und jemand wird neue Ideen entwickeln.
 Über den Sprecher:
Über den Sprecher: Victor Bilyk führt auf Booking.com Produkte für maschinelles Lernen in den kommerziellen Betrieb ein.
Lassen Sie uns zunächst sehen, wo Booking.com in welchen Produkten maschinelles Lernen einsetzt.
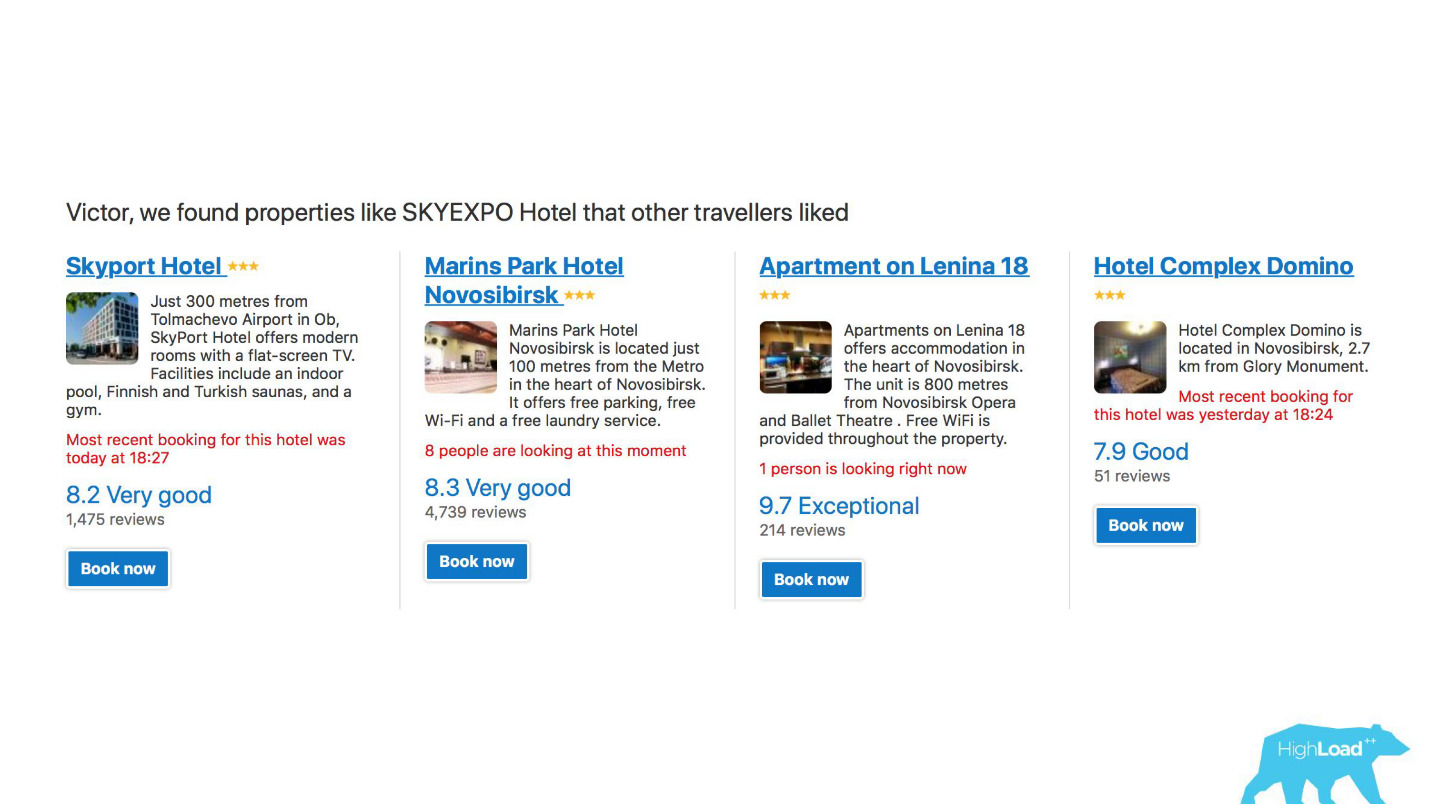
Erstens ist dies eine große Anzahl von Empfehlungssystemen für Hotels, Reiseziele, Daten und an verschiedenen Stellen im Verkaufstrichter und in verschiedenen Kontexten. Wir versuchen beispielsweise zu erraten, wohin Sie gehen, wenn Sie überhaupt nichts in die Suchzeile eingegeben haben.

Dies ist ein Screenshot in meinem Konto, und ich werde dieses Jahr definitiv zwei dieser Bereiche besuchen.
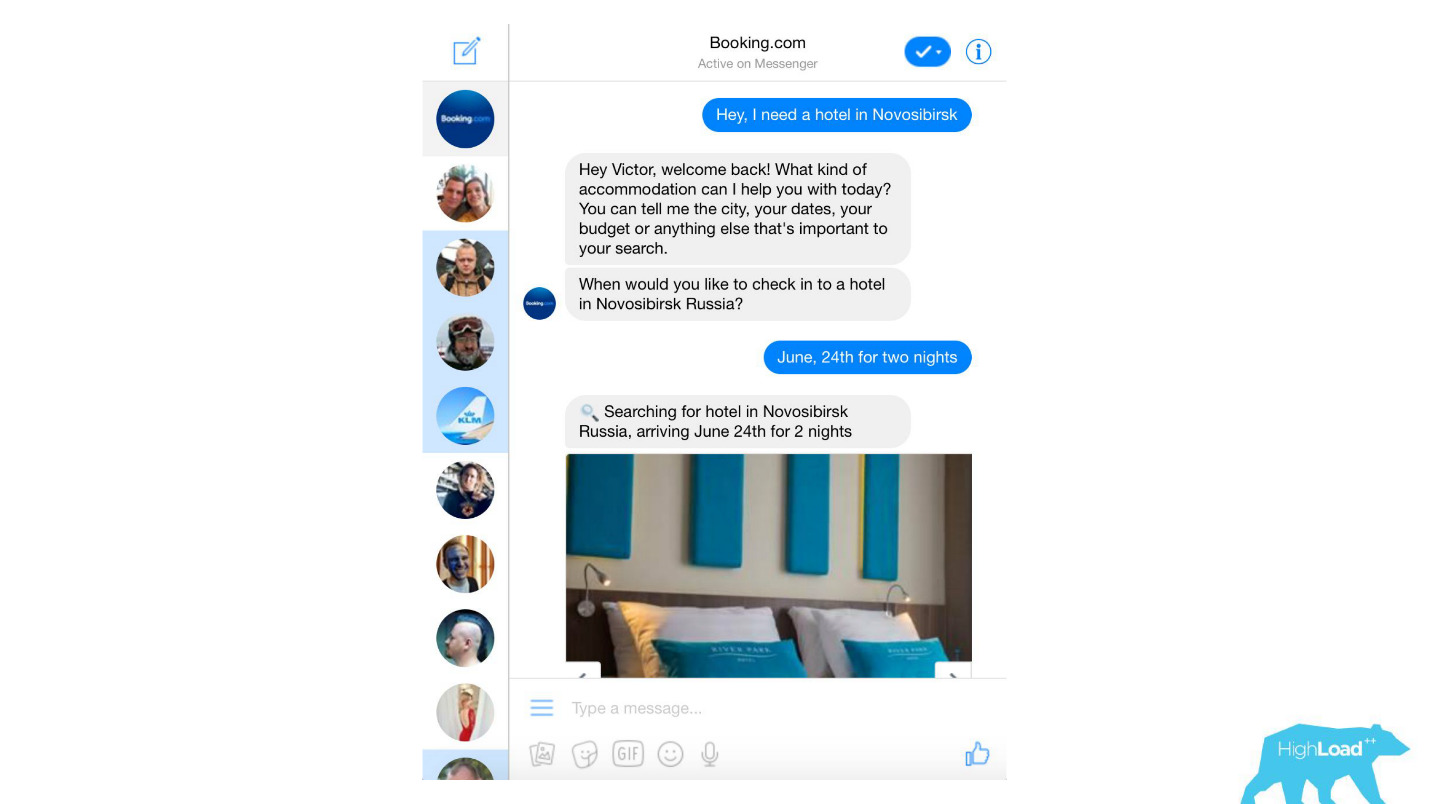
Wir verarbeiten fast alle Textnachrichten von Kunden, von banalen Spamfiltern bis hin zu hoch entwickelten Produkten wie Assistant und ChatToBook, die Modelle verwenden, um Absichten zu bestimmen und Entitäten zu erkennen. Darüber hinaus gibt es Modelle, die nicht so auffällig sind, beispielsweise die Betrugserkennung.
Wir analysieren Bewertungen. Models erzählen uns, warum Leute zum Beispiel nach Berlin gehen.
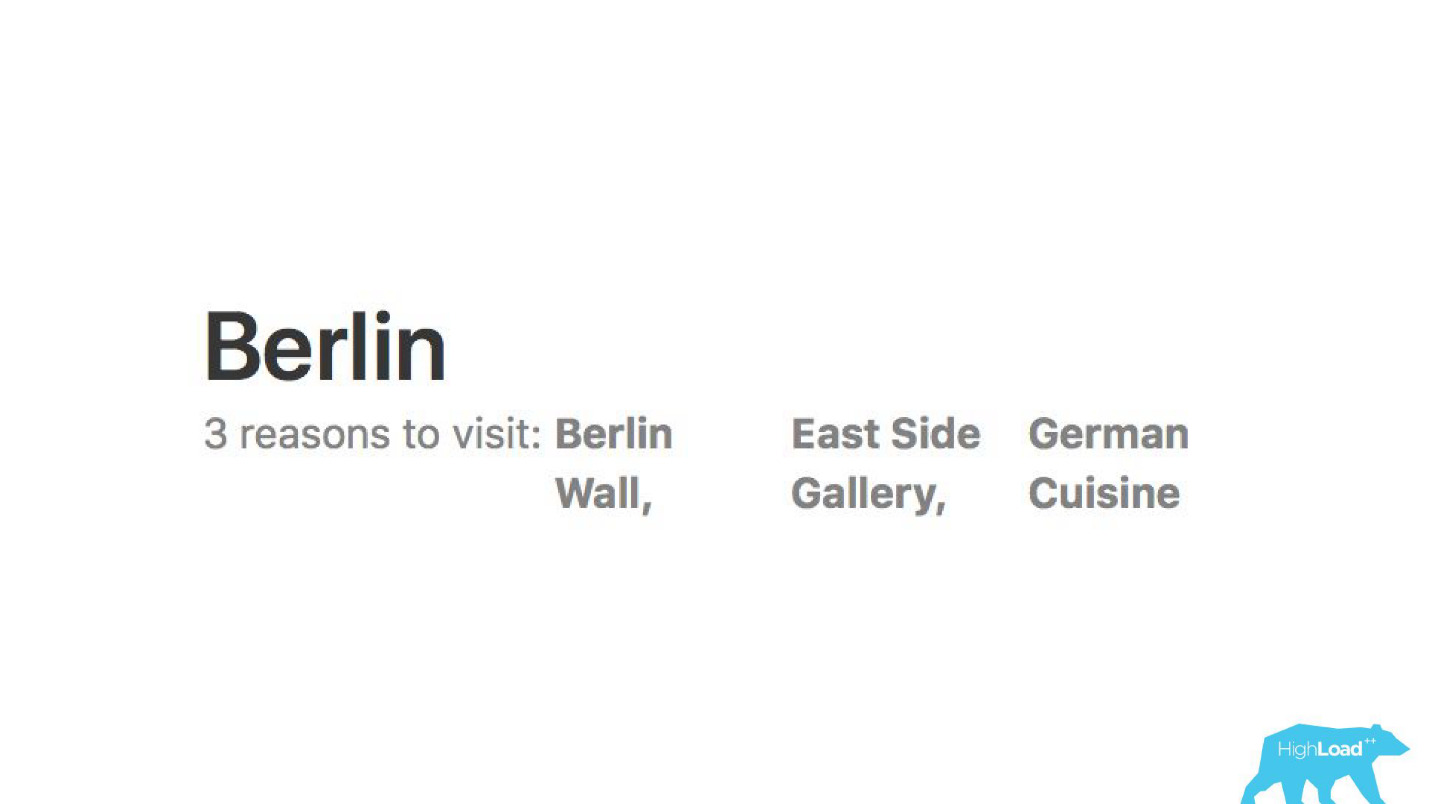
Mit Hilfe von Modellen für maschinelles Lernen wird analysiert, warum das Hotel gelobt wird, damit Sie nicht selbst Tausende von Bewertungen lesen müssen.
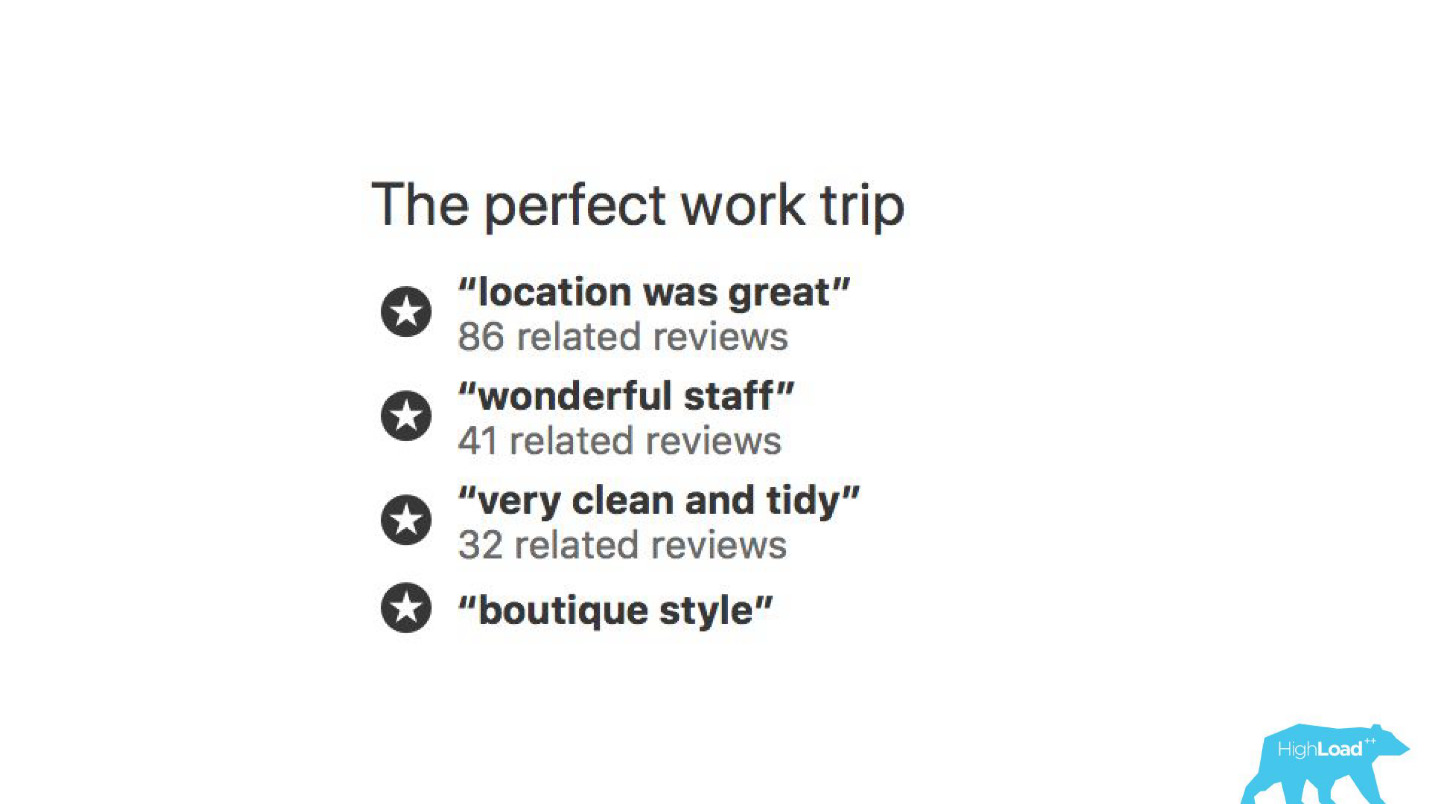
An einigen Stellen unserer Benutzeroberfläche ist fast jedes Teil an die Vorhersagen einiger Modelle gebunden. Zum Beispiel versuchen wir hier vorherzusagen, wann das Hotel ausverkauft sein wird.
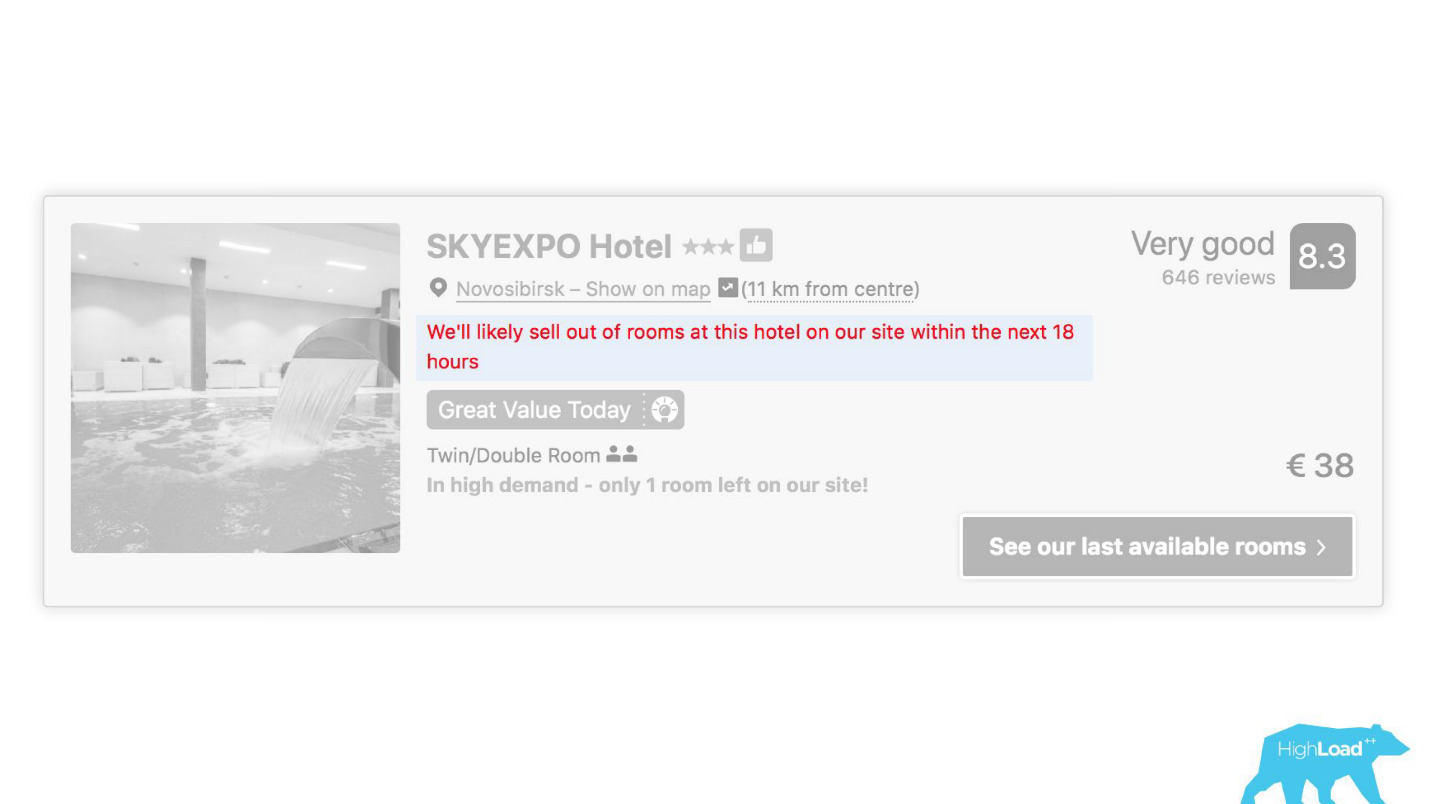
Wir haben oft Recht - nach 19 Stunden ist das letzte Zimmer bereits gebucht.
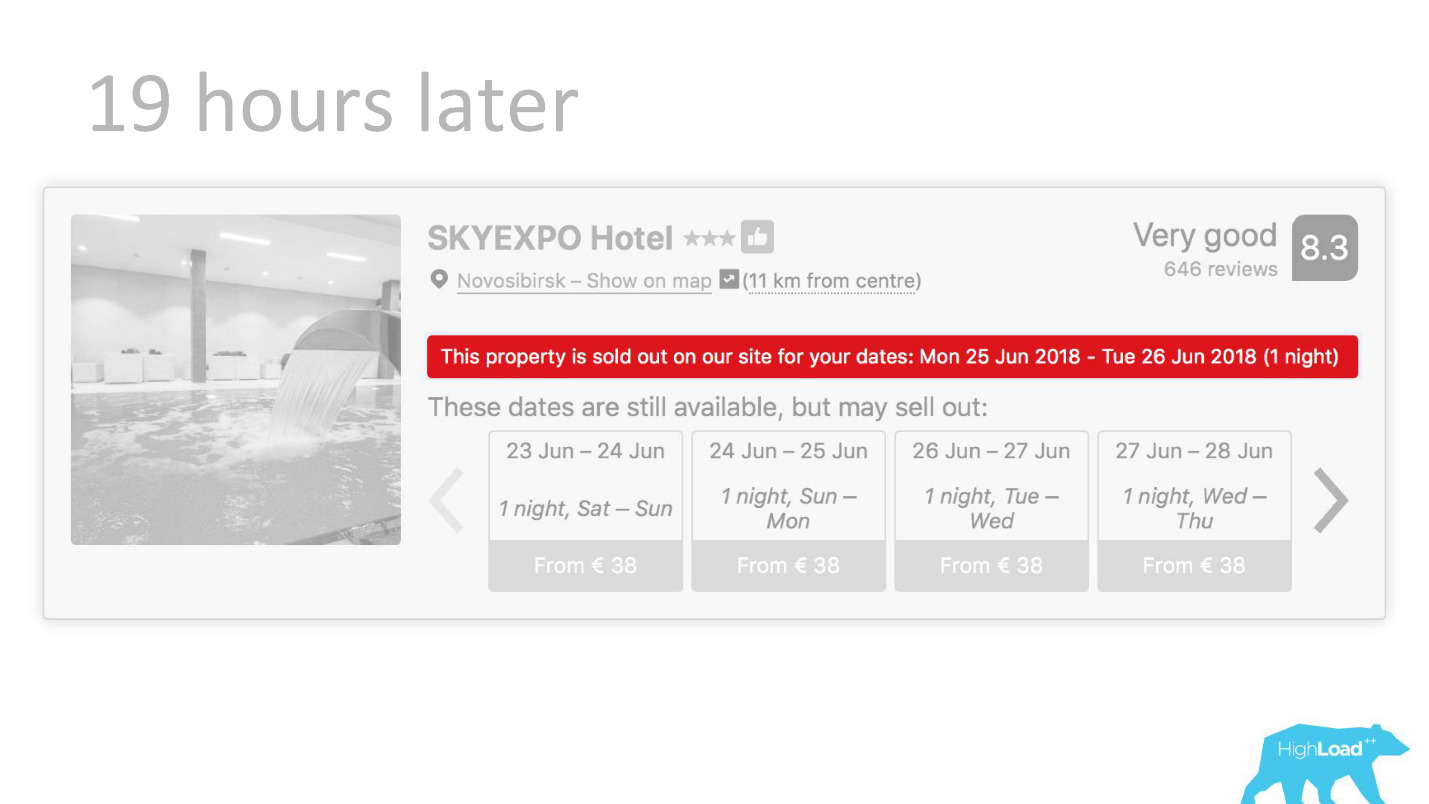
Oder zum Beispiel - das Abzeichen "Günstiges Angebot". Hier versuchen wir das Subjektive zu formalisieren: Was ist ein so vorteilhaftes Angebot? Wie kann man verstehen, dass die vom Hotel für diese Daten festgelegten Preise gut sind? Schließlich hängt dies neben dem Preis von vielen Faktoren ab, wie z. B. zusätzlichen Dienstleistungen, und oft sogar von externen Gründen, wenn beispielsweise in dieser Stadt gerade die Weltmeisterschaft oder eine große technische Konferenz stattfindet.
Beginn der Implementierung
Lassen Sie uns vor ein paar Jahren, im Jahr 2015, zurückspulen. Einige der Produkte, über die ich gesprochen habe, existieren bereits. Darüber hinaus ist das System, über das ich heute sprechen werde, noch nicht. Wie fand die Implementierung zu diesem Zeitpunkt statt? Die Dinge waren ehrlich gesagt nicht sehr. Tatsache ist, dass wir ein großes Problem hatten, von dem ein Teil technisch und ein Teil organisatorisch ist.
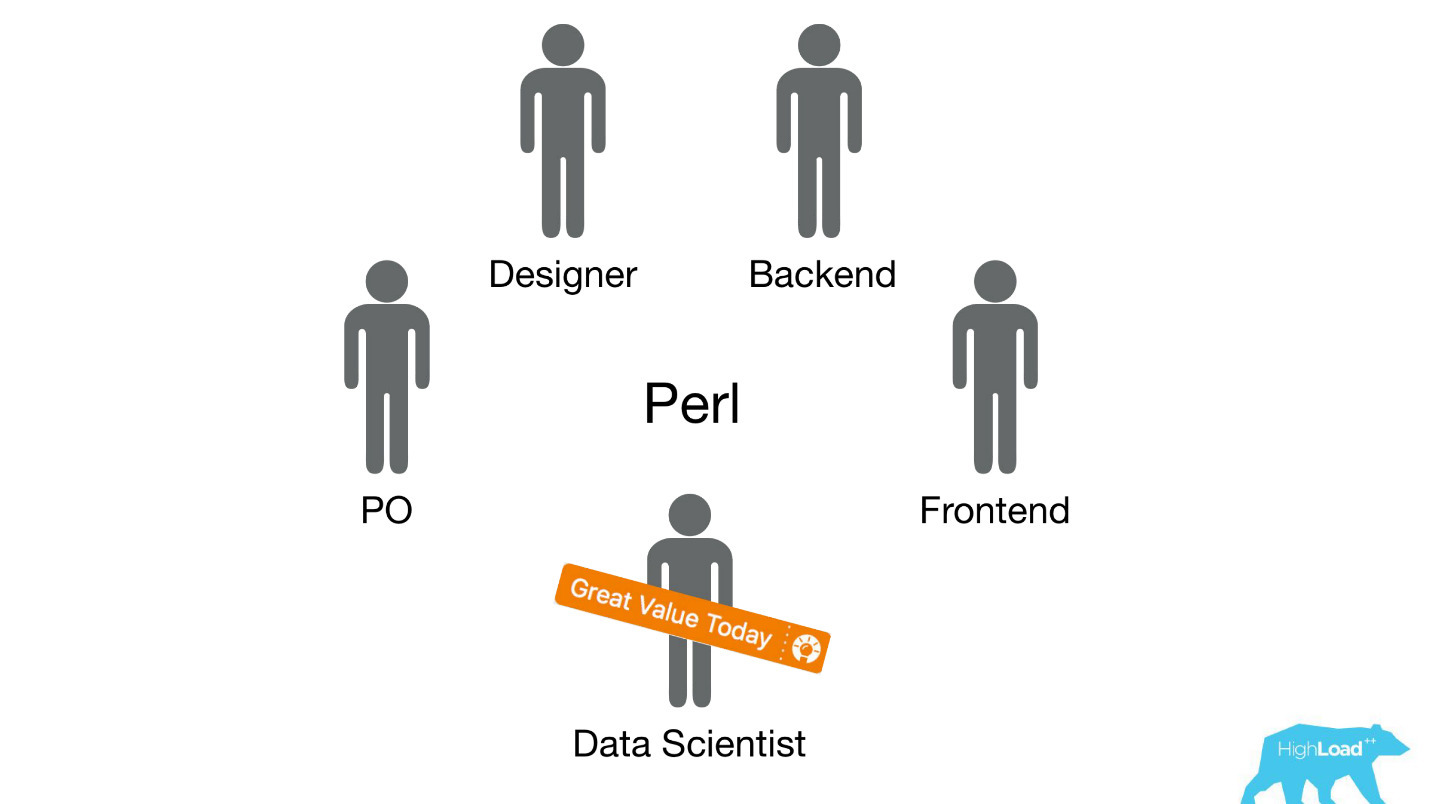
Wir haben Datenwissenschaftler an bestehende funktionsübergreifende Teams geschickt, die an einem bestimmten Benutzerproblem arbeiten, und erwartet, dass sie das Produkt irgendwie verbessern.
Meistens wurden diese Teile des Produkts auf dem Perl-Stapel erstellt. Es gibt ein offensichtliches Problem mit Perl - es ist nicht für intensives Computing ausgelegt, und unser Backend ist bereits mit anderen Dingen geladen. Darüber hinaus konnte die Entwicklung seriöser Systeme, die dieses Problem lösen würden, innerhalb des Teams nicht priorisiert werden, da der Fokus des Teams auf der Lösung eines Benutzerproblems und nicht auf der Lösung eines Benutzerproblems durch maschinelles Lernen liegt. Daher wäre Product Owner (PO) sehr dagegen.
Mal sehen, wie es dann passiert ist.
Es gab nur zwei Möglichkeiten - das weiß ich ganz genau, denn zu dieser Zeit arbeitete ich nur in einem solchen Team und half den Data Scientists, ihre ersten Modelle in den Kampf zu ziehen.
Die erste Option war die
Materialisierung von Vorhersagen . Angenommen, es gibt ein sehr einfaches Modell mit nur zwei Merkmalen:
- Land, in dem sich der Besucher befindet;
- die Stadt, in der er ein Hotel sucht.
Wir müssen die Wahrscheinlichkeit eines Ereignisses vorhersagen. Wir sprengen einfach alle Eingabevektoren: sagen wir 100.000 Städte, 200 Länder - insgesamt 20 Millionen Zeilen in MySQL. Es klingt nach einer voll funktionsfähigen Option für die Ausgabe einiger kleiner Rangfolgesysteme oder anderer einfacher Modelle in die Produktion.

Eine andere Möglichkeit besteht darin,
die Vorhersagen direkt in den Backend-Code einzubetten . Es gibt große Einschränkungen - Hunderte, vielleicht Tausende von Koeffizienten - das ist alles, was wir uns leisten können.

Offensichtlich können Sie weder auf die eine noch auf die andere Weise zumindest ein komplexes Modell in der Produktion herausbringen. Dies begrenzte das Rechenzentrum und die Erfolge, die sie durch die Verbesserung von Produkten erzielen konnten. Offensichtlich musste dieses Problem irgendwie gelöst werden.
Vorhersage-Service
Das erste, was wir machten, war ein Vorhersagedienst. Wahrscheinlich ist die einfachste Architektur, die jemals in Habré und HighLoad ++ gezeigt wurde, niedriger.
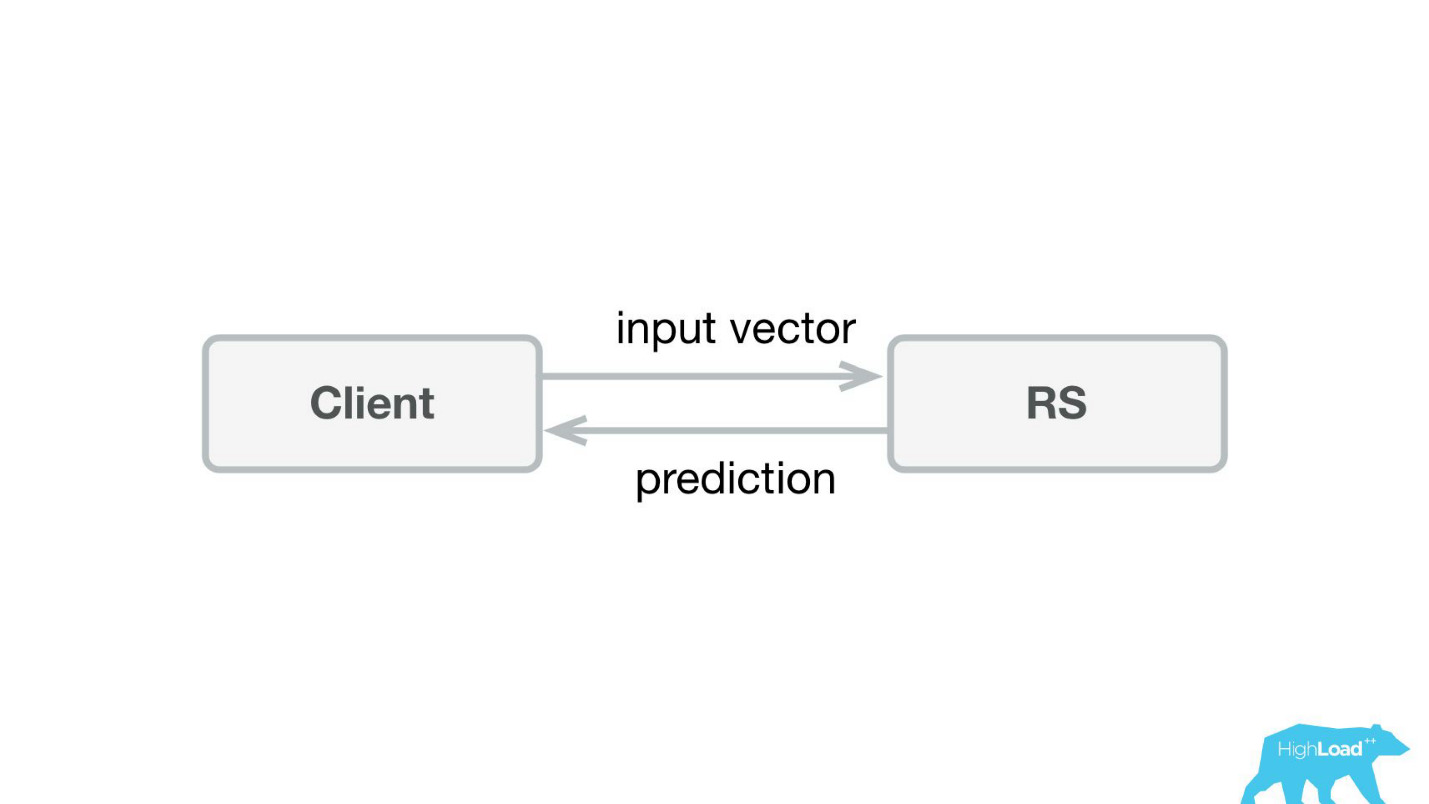
Wir haben eine kleine Anwendung in Scala + Akka + Spray geschrieben, die einfach eingehende Vektoren nahm und die Vorhersage zurückgab. Tatsächlich bin ich ein bisschen gerissen - das System war etwas komplizierter, weil wir es irgendwie überwachen und ausrollen mussten. In Wirklichkeit sah alles so aus:
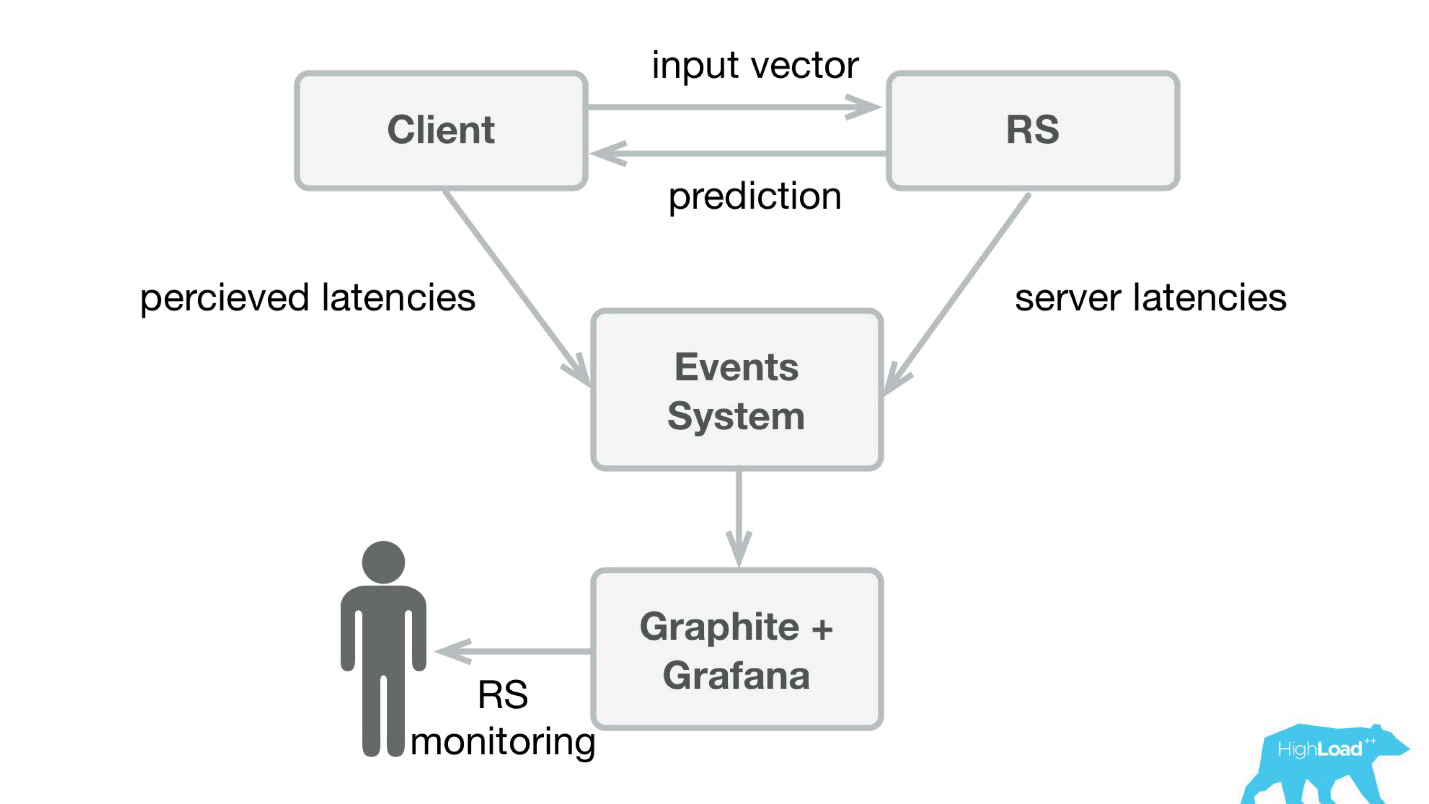
Booking.com hat ein Event-System - so etwas wie ein Magazin für alle Systeme. Es ist sehr einfach, dort zu schreiben, und dieser Stream ist sehr einfach umzuleiten. Zuerst mussten wir Client-Telemetrie mit wahrgenommenen Latenzen und detaillierten Informationen von der Serverseite an Graphite und Grafana senden.

Wir haben einfache Client-Bibliotheken für Perl erstellt - den gesamten RPC in einem lokalen Aufruf versteckt, mehrere Modelle dort abgelegt und der Dienst gestartet. Der Verkauf eines solchen Produkts war recht einfach, da wir die Möglichkeit hatten
, komplexere Modelle vorzustellen und viel weniger Zeit zu verbringen .
Datenwissenschaftler begannen mit viel weniger Einschränkungen zu arbeiten, und in einigen Fällen reduzierte sich die Arbeit der Rückstände auf eine einzige Zeile.
Produktvorhersagen
Aber lassen Sie uns kurz darauf zurückkommen, wie wir diese Vorhersagen im Produkt verwendet haben.
Es gibt ein Modell, das Vorhersagen basierend auf bekannten Fakten macht. Basierend auf dieser Vorhersage ändern wir irgendwie die Benutzeroberfläche. Dies ist natürlich nicht das einzige Szenario für den Einsatz von maschinellem Lernen in unserem Unternehmen, aber durchaus üblich.
Was ist das Problem beim Starten solcher Funktionen? Die Sache ist, dass dies zwei Dinge in einer Flasche sind: ein Modell und eine Änderung in der Benutzeroberfläche. Es ist sehr schwierig, die Effekte von beiden zu trennen.
Stellen Sie sich vor, Sie starten das Abzeichen „Günstiges Angebot“ als Teil eines AB-Experiments. Wenn es nicht startet - es gibt keine statistisch signifikante Änderung der Zielmetriken - ist nicht bekannt, wo das Problem liegt: ein unverständliches, kleines, unauffälliges Abzeichen oder ein schlechtes Modell.
Darüber hinaus können sich Modelle verschlechtern, und dafür kann es viele Gründe geben. Was gestern funktioniert hat, funktioniert heute nicht unbedingt. Außerdem sind wir ständig im Kaltstartmodus und verbinden ständig neue Städte und Hotels. Menschen aus neuen Städten kommen zu uns. Wir müssen irgendwie verstehen, dass sich das Modell in diesen Teilen des eingehenden Raums immer noch gut verallgemeinert.

Der wahrscheinlich zuletzt bekannte Fall der Modellverschlechterung war die Geschichte mit Alex. Höchstwahrscheinlich begann sie infolge der Umschulung, zufällige Geräusche als Aufforderung zum Lachen zu verstehen, und begann nachts zu kichern, was die Besitzer erschreckte.
Vorhersageüberwachung
Um die Vorhersagen zu überwachen, haben wir unser System leicht modifiziert (Abbildung unten). Auf die gleiche Weise haben wir vom Ereignissystem aus den Stream nach Hadoop umgeleitet und begonnen, zusätzlich zu allem, was wir zuvor gespeichert haben, alle Eingabevektoren und alle von unserem System gemachten Vorhersagen zu speichern. Dann haben wir sie mit Oozie in MySQL zusammengefasst und von dort mit einer kleinen Webanwendung denjenigen gezeigt, die an qualitativen Merkmalen der Modelle interessiert sind.
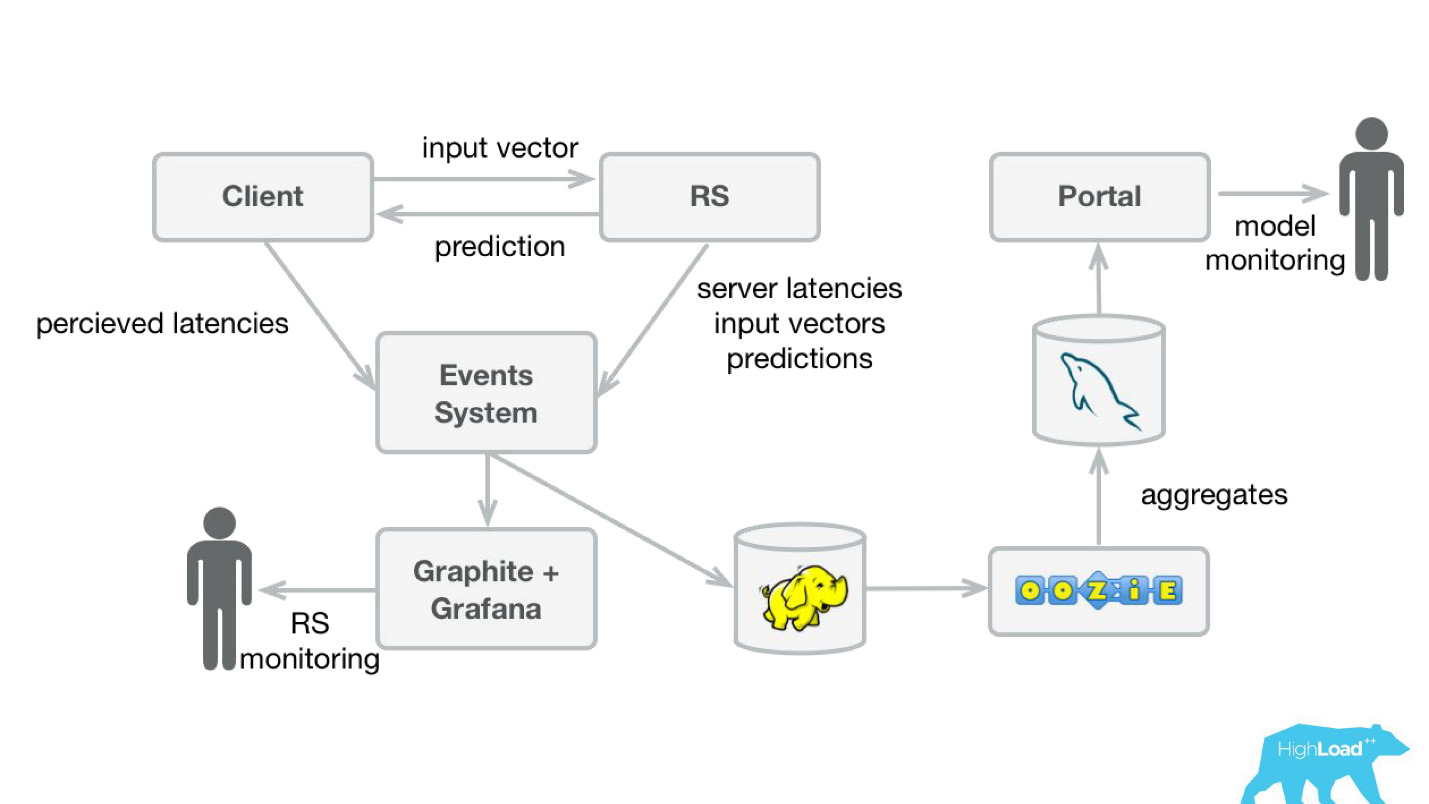
Es ist jedoch wichtig herauszufinden, was dort gezeigt werden soll. Die Sache ist, dass es in unserem Fall sehr schwierig ist, die üblichen Metriken zu berechnen, die im Modelltraining verwendet werden, da wir oft eine große Verzögerung bei den Etiketten haben.
Betrachten Sie dies als Beispiel. Wir möchten vorhersagen, ob der Benutzer alleine oder mit der Familie in den Urlaub fährt. Wir brauchen diese Vorhersage, wenn eine Person ein Hotel wählt, aber wir können die Wahrheit erst in einem Jahr herausfinden. Gerade nach dem Urlaub erhält der Benutzer eine Einladung, eine Bewertung abzugeben, wobei sich unter anderem die Frage stellt, ob er alleine oder mit seiner Familie dort war.
Das heißt, Sie müssen alle im Laufe des Jahres gemachten Vorhersagen irgendwo speichern, damit Sie schnell Übereinstimmungen mit den eingehenden Etiketten finden können. Es klang nach einer sehr ernsten, vielleicht sogar schweren Investition. Bis wir dieses Problem gelöst haben, haben wir uns daher entschlossen, etwas Einfacheres zu tun.
Es stellte sich heraus, dass dies „einfacher“ nur ein
Histogramm der Vorhersagen des Modells war.
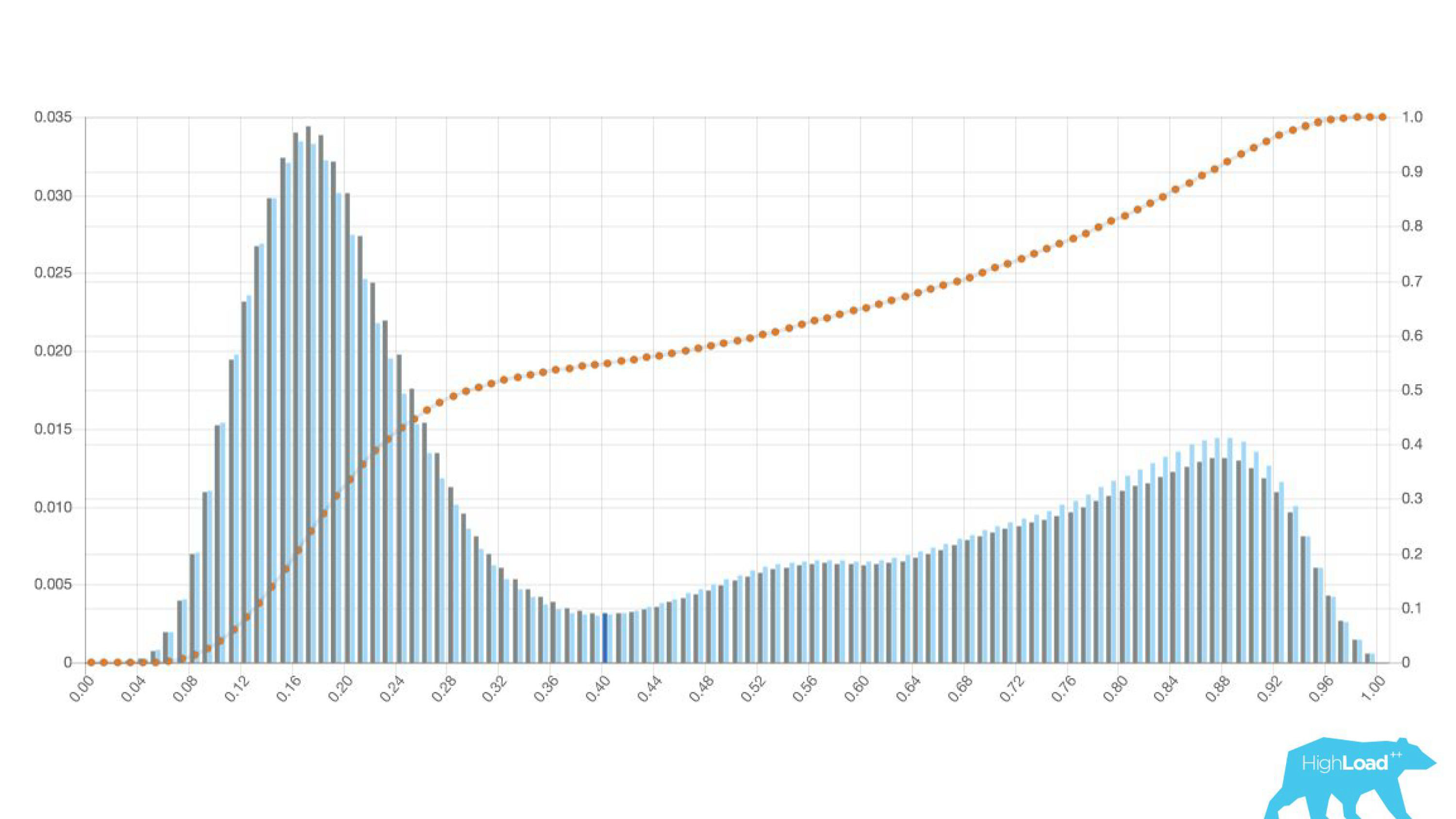
Oben in der Grafik befindet sich eine logistische Regression, die vorhersagt, ob der Benutzer das Datum seiner Reise ändern wird oder nicht. Es ist zu sehen, dass es die Benutzer gut in zwei Klassen unterteilt: Auf der linken Seite ist der Hügel diejenigen, die dies nicht tun werden; Der Hügel rechts ist derjenige, der es tut.
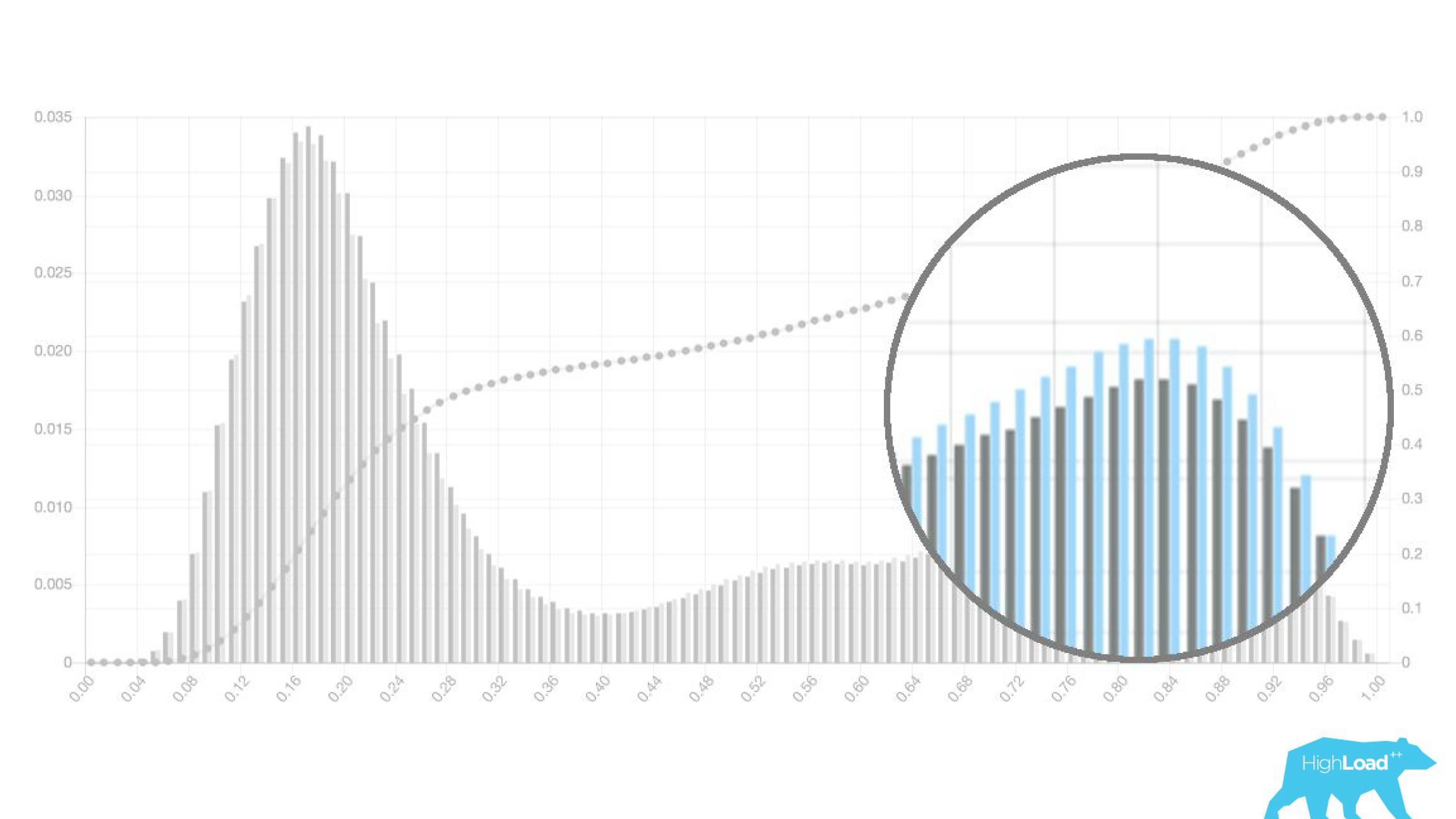
Tatsächlich zeigen wir sogar zwei Diagramme: eines für den aktuellen Zeitraum und das andere für den vorherigen. Es ist deutlich zu sehen, dass das Modell diese Woche (dies ist ein Wochen-Chart) eine Änderung der Daten etwas häufiger vorhersagt. Es ist schwer sicher zu sagen, ob es sich um Saisonalität oder um dieselbe Verschlechterung im Laufe der Zeit handelt.
Dies führte zu einer Änderung in der Arbeit von Datenhändlern, die aufhörten, andere Personen einzubeziehen, und begannen, ihre Modelle schneller zu iterieren. Sie schickten Modelle zusammen mit Backend-Ingenieuren im Trockenlauf in die Produktion. Das heißt, die Vektoren wurden gesammelt, das Modell machte eine Vorhersage, aber diese Vorhersagen wurden in keiner Weise verwendet.
Im Falle eines Abzeichens haben wir wie bisher einfach nichts angezeigt, sondern Statistiken gesammelt. Dadurch konnten wir keine Zeit mit fehlgeschlagenen Projekten im Voraus verschwenden. Wir haben Zeit für das Front-End und Designer für andere Experimente frei gemacht.
Solange das Rechenzentrum nicht sicher ist, ob das Modell wie gewünscht funktioniert, bezieht es andere einfach nicht in diesen Prozess ein.Es ist interessant zu sehen, wie sich die Grafiken in verschiedenen Abschnitten ändern.
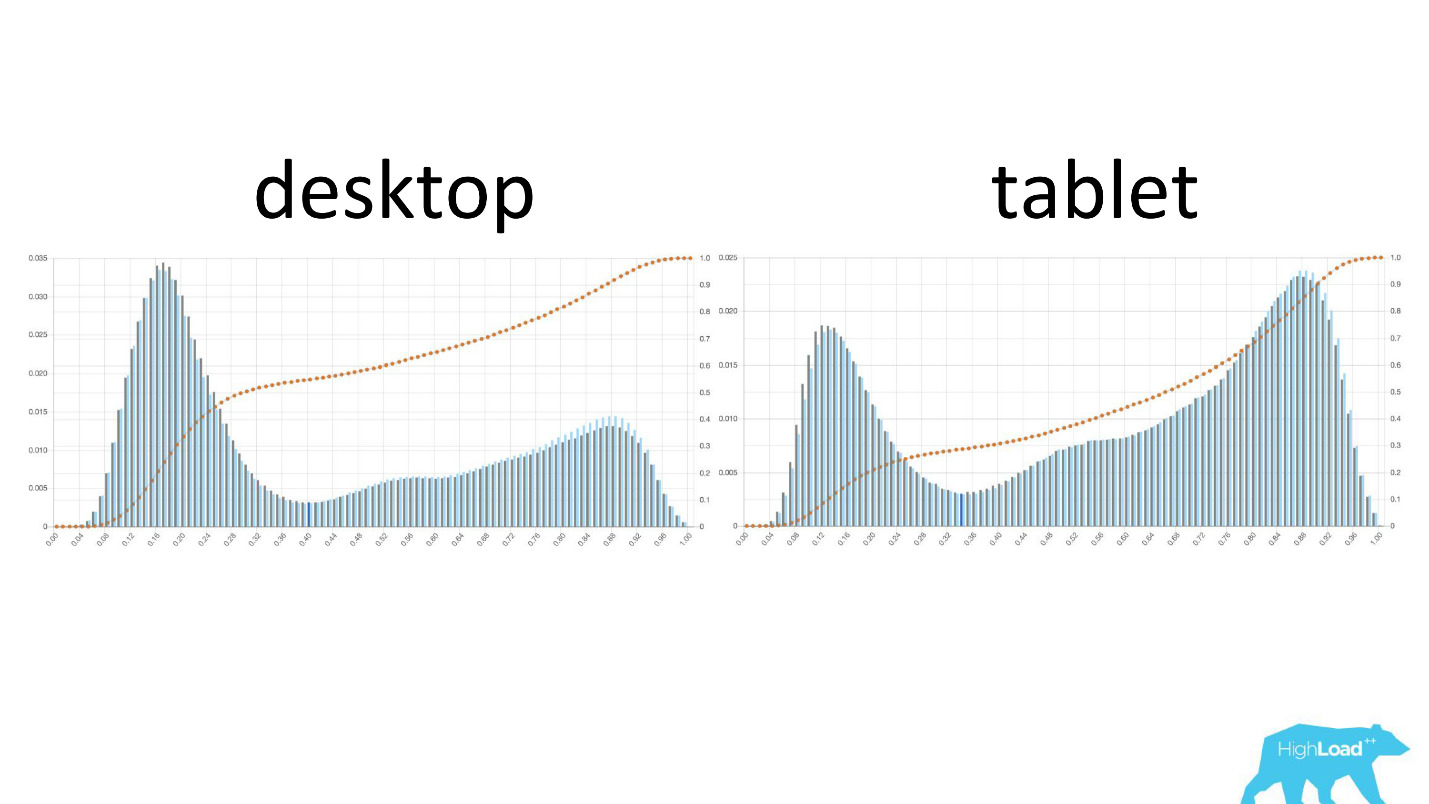
Links ist die Wahrscheinlichkeit, dass sich die Daten auf dem Desktop ändern, rechts auf Tablets. Es ist deutlich zu sehen, dass das Modell auf Tablets eine wahrscheinlichere Änderung der Daten vorhersagt. Dies ist höchstwahrscheinlich auf die Tatsache zurückzuführen, dass das Tablet häufig für die Reiseplanung und seltener für Reservierungen verwendet wird.
Es ist auch interessant zu sehen, wie sich diese Diagramme ändern, wenn Benutzer sich durch den Verkaufstrichter bewegen.
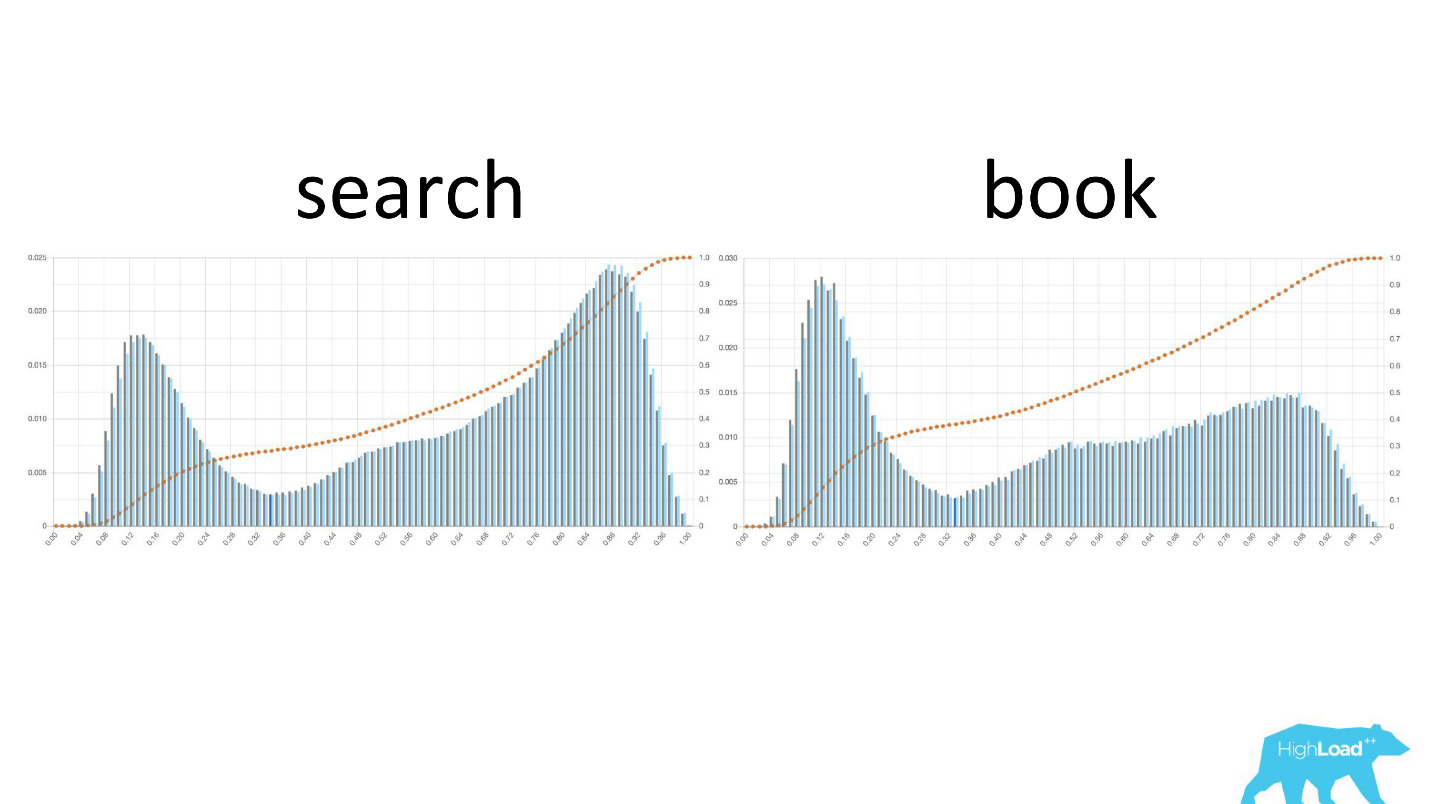
Links ist die Wahrscheinlichkeit der Datumsänderung auf der Suchseite, rechts auf der ersten Buchungsseite. Es ist zu sehen, dass eine viel größere Anzahl von Personen, die sich bereits für einen Termin entschieden haben, auf die Buchungsseite gelangt.
Aber das waren gute Grafiken. Wie sehen die schlechten aus? Auf sehr unterschiedliche Weise. Manchmal ist es nur Rauschen, manchmal ist es ein riesiger Hügel, was bedeutet, dass das Modell keine zwei Klassen von Vorhersagen effektiv trennen kann.

Manchmal sind das riesige Gipfel.
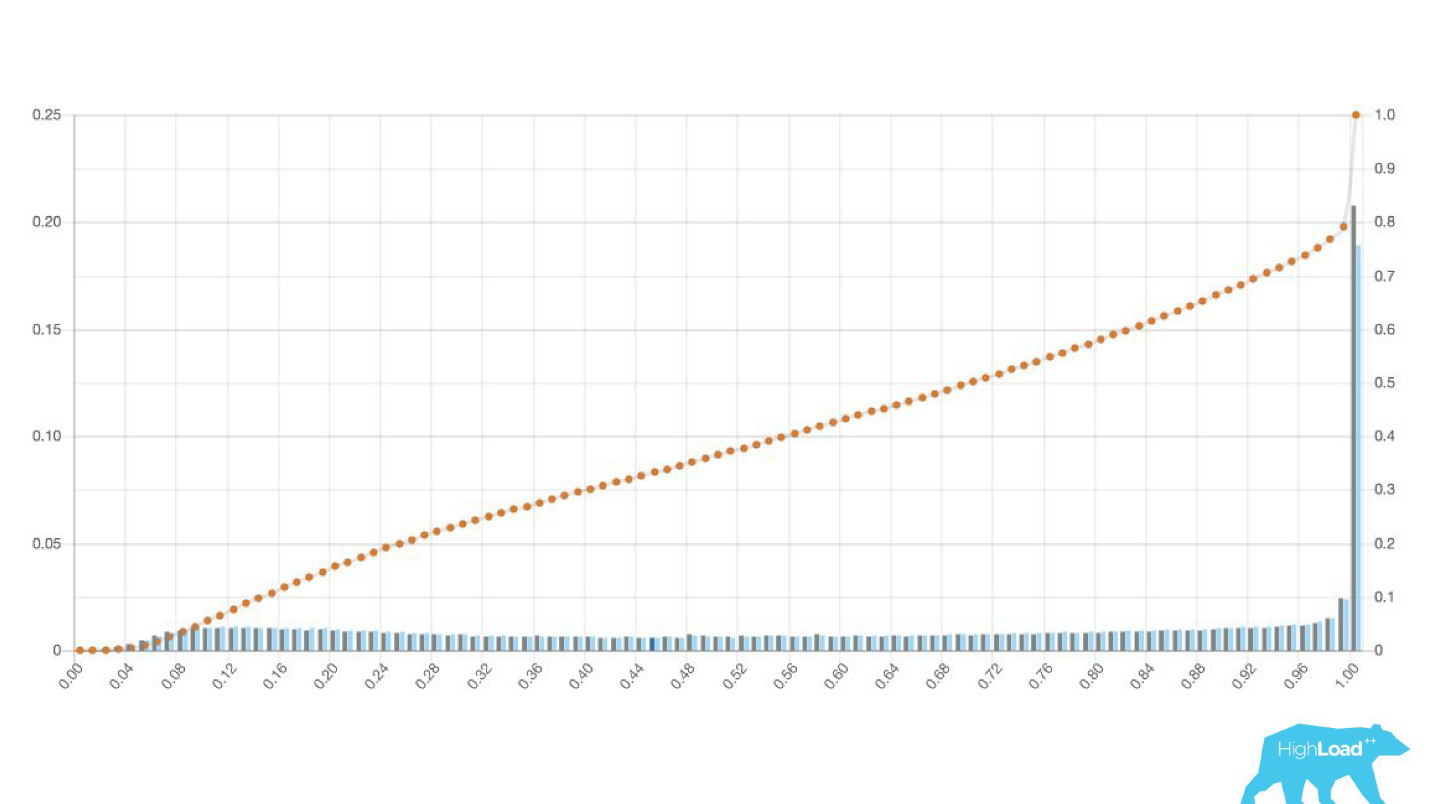
Dies ist auch eine logistische Regression, und bis zu einem gewissen Punkt zeigte sich ein schönes Bild mit zwei Hügeln, aber eines Morgens wurde es so.
Um zu verstehen, was im Inneren passiert ist, müssen Sie verstehen, wie die logistische Regression berechnet wird.
Kurzanleitung
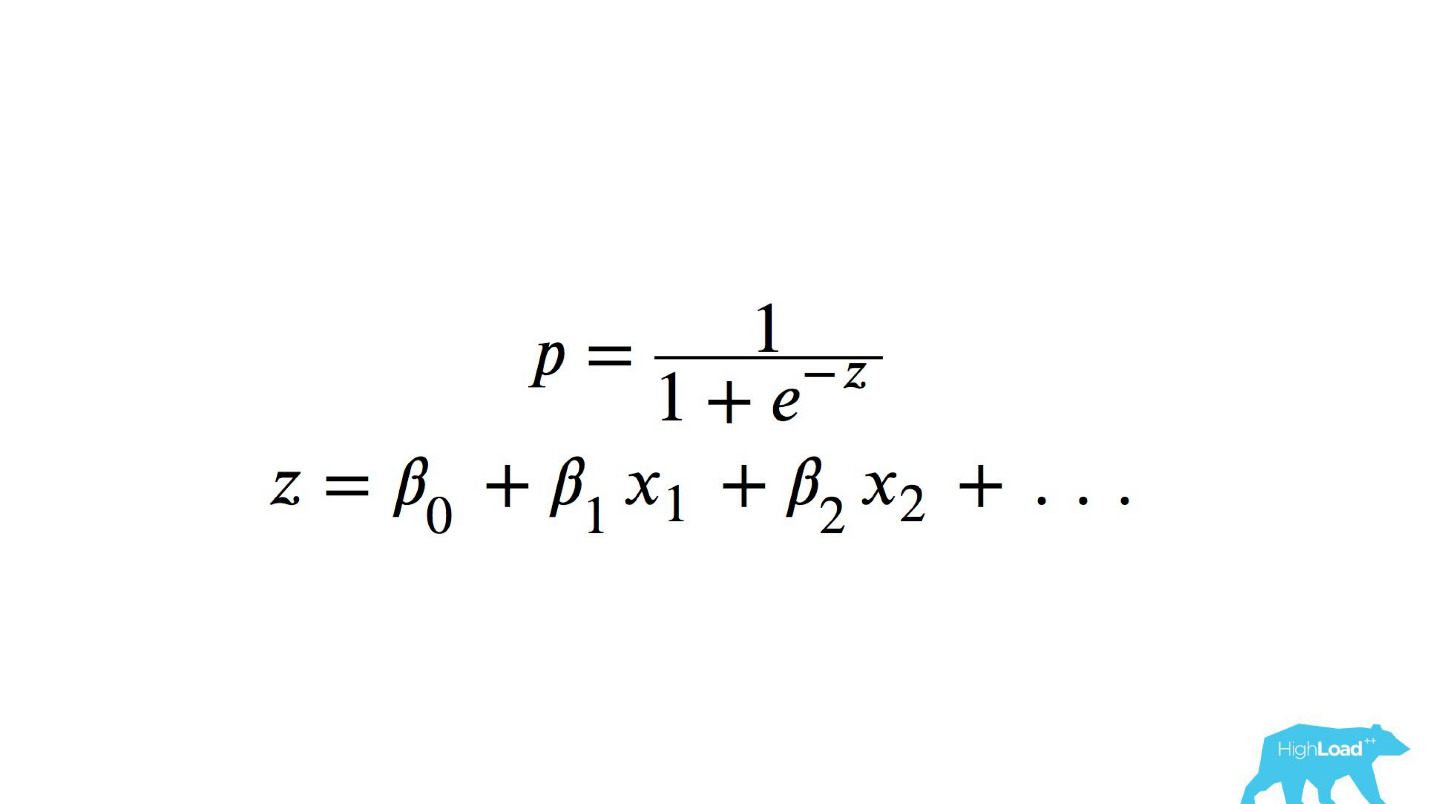
Dies ist eine logistische Funktion des Skalarprodukts, wobei x
n einige Merkmale sind. Eines dieser Merkmale war der Preis für eine Nacht in einem Hotel (in Euro).
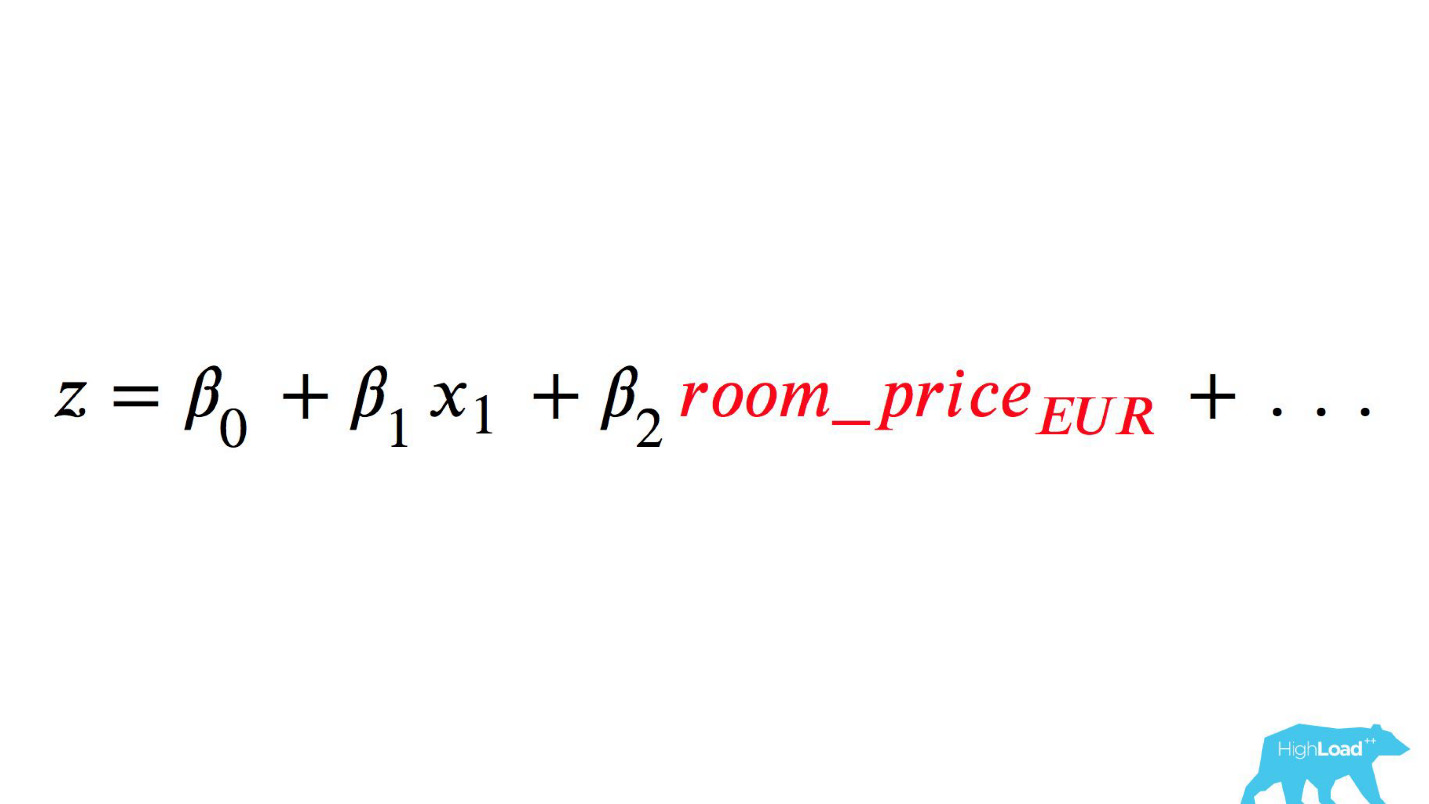
Dieses Modell zu nennen wäre ungefähr so:
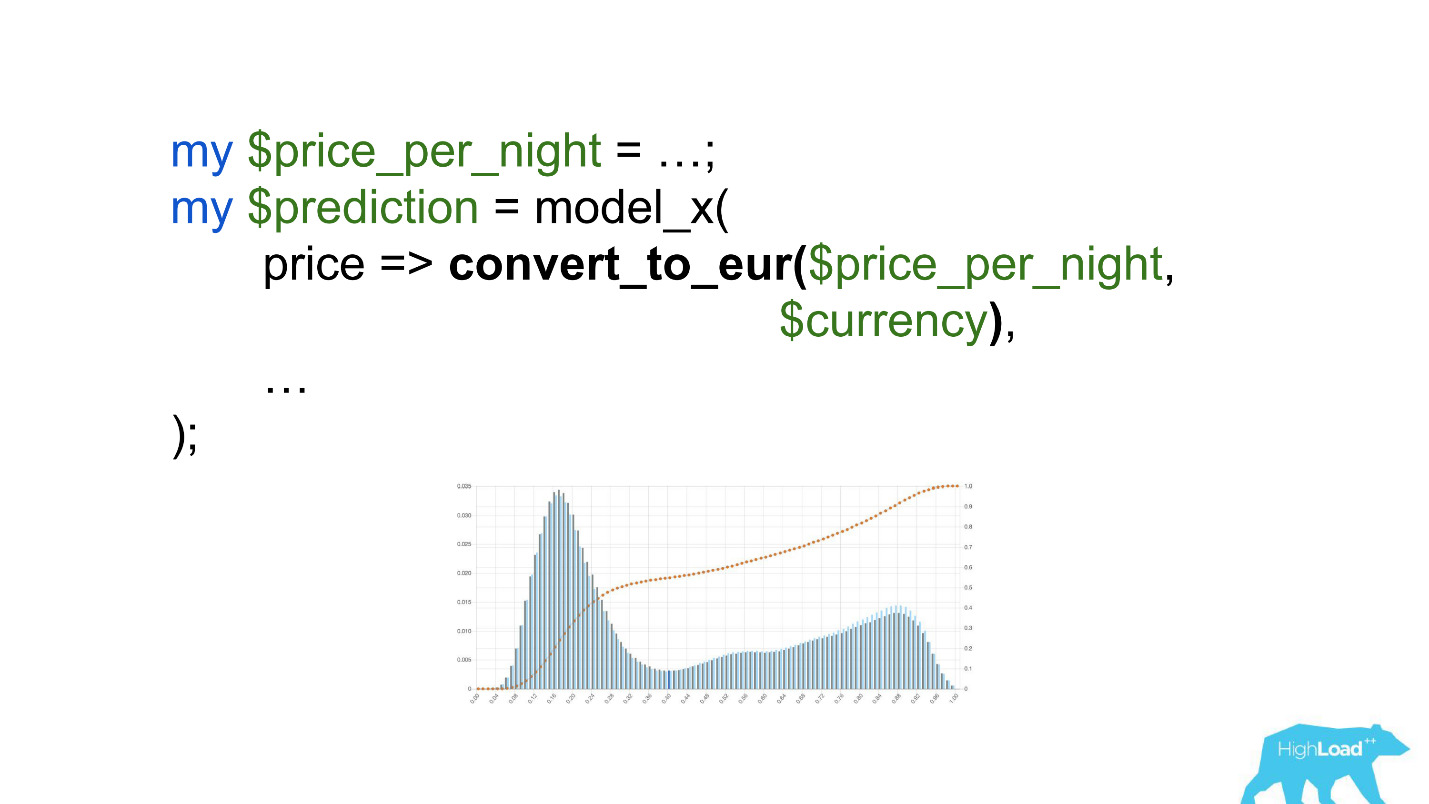
Achten Sie auf die Auswahl. Es war notwendig, den Preis in Euro umzurechnen, aber der Entwickler vergaß es.
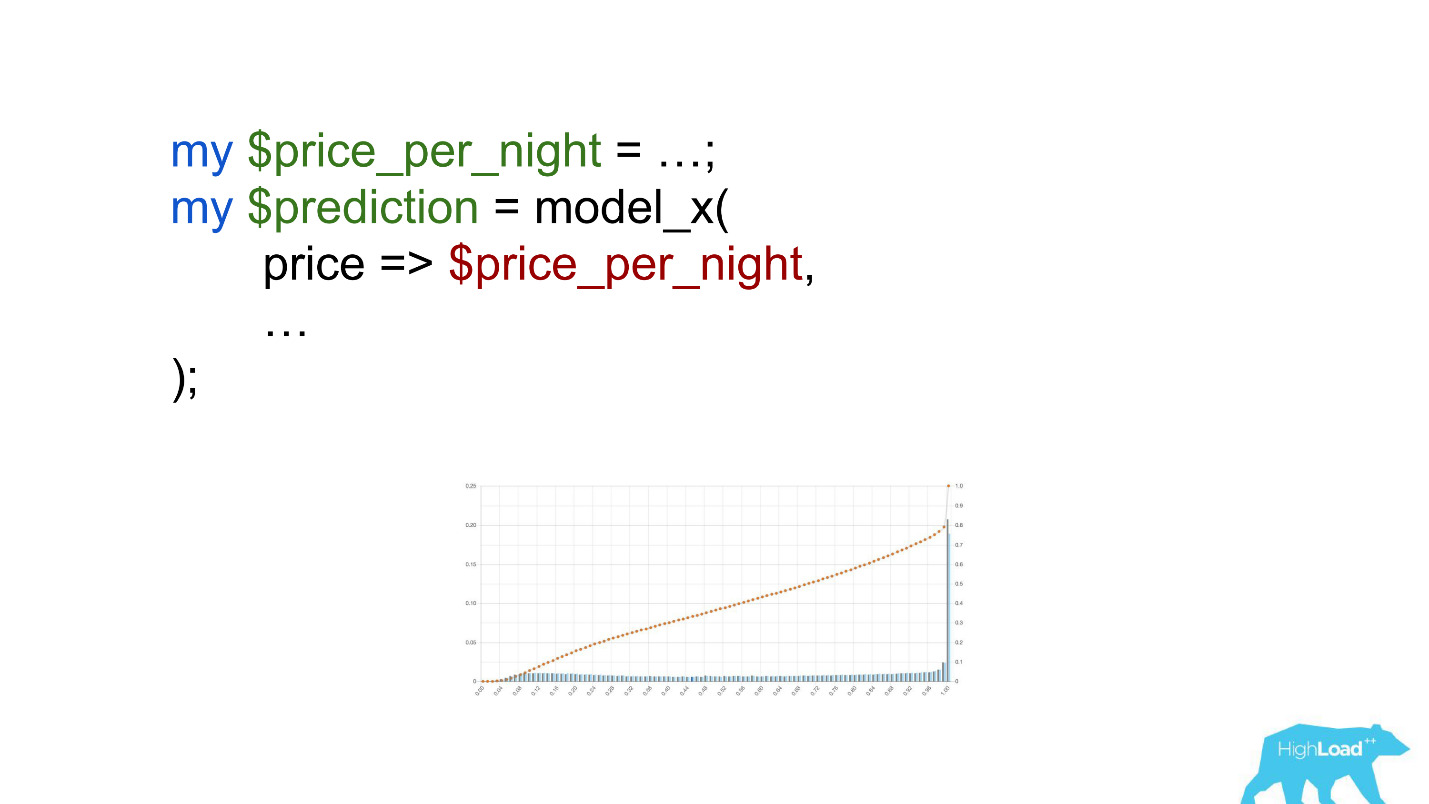
Währungen wie Rupien oder Rubel multiplizierten das Skalarprodukt um ein Vielfaches und zwangen dieses Modell daher, viel häufiger einen Wert nahe der Einheit zu erzeugen, den wir auf dem Diagramm sehen.
Schwellenwerte
Ein weiteres nützliches Merkmal dieser Histogramme war die Möglichkeit einer bewussten und optimalen Auswahl von Schwellenwerten.
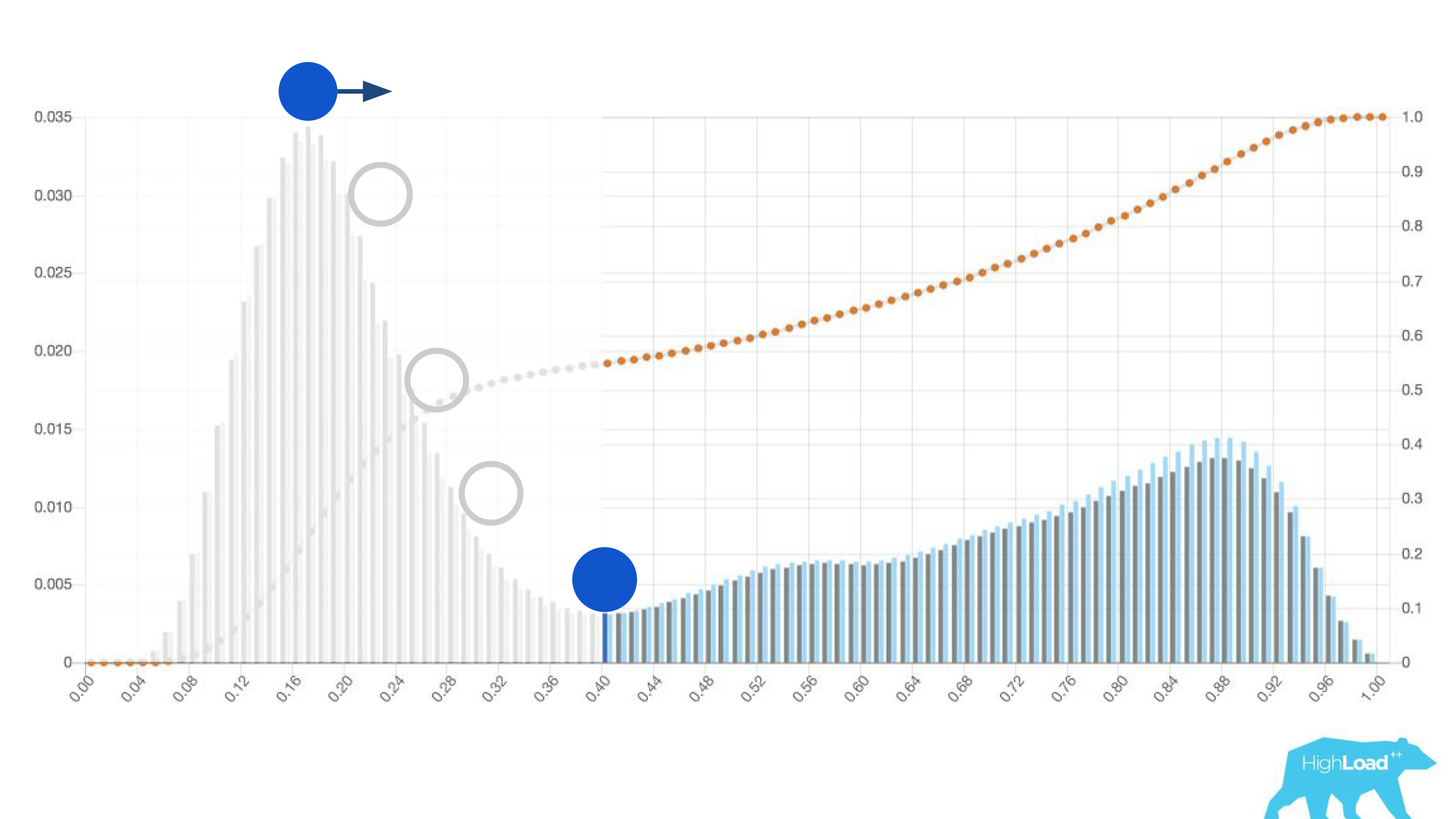
Wenn Sie den Ball in diesem Histogramm auf den höchsten Hügel legen, drücken Sie ihn und stellen Sie sich vor, wo er aufhören wird. Dies ist der Punkt, der für die Klassentrennung optimal ist. Alles rechts ist eine Klasse, alles links ist eine andere.
Wenn Sie diesen Punkt jedoch verschieben, können Sie sehr interessante Effekte erzielen. Angenommen, wir möchten ein Experiment ausführen, das die Benutzeroberfläche irgendwie ändert, wenn das Modell "Ja" sagt. Wenn Sie diesen Punkt nach rechts verschieben, wird das Publikum unseres Experiments reduziert. Immerhin ist die Anzahl der Personen, die diese Vorhersage erhalten haben, der Bereich unter der Kurve. In der Praxis ist die Genauigkeit von Vorhersagen jedoch viel höher. Wenn nicht genügend statische Leistung vorhanden ist, können Sie das Publikum Ihres Experiments erhöhen, aber die Genauigkeit der Vorhersagen verringern.
Zusätzlich zu den Vorhersagen selbst haben wir begonnen, die Eingabewerte in den Vektoren zu überwachen.
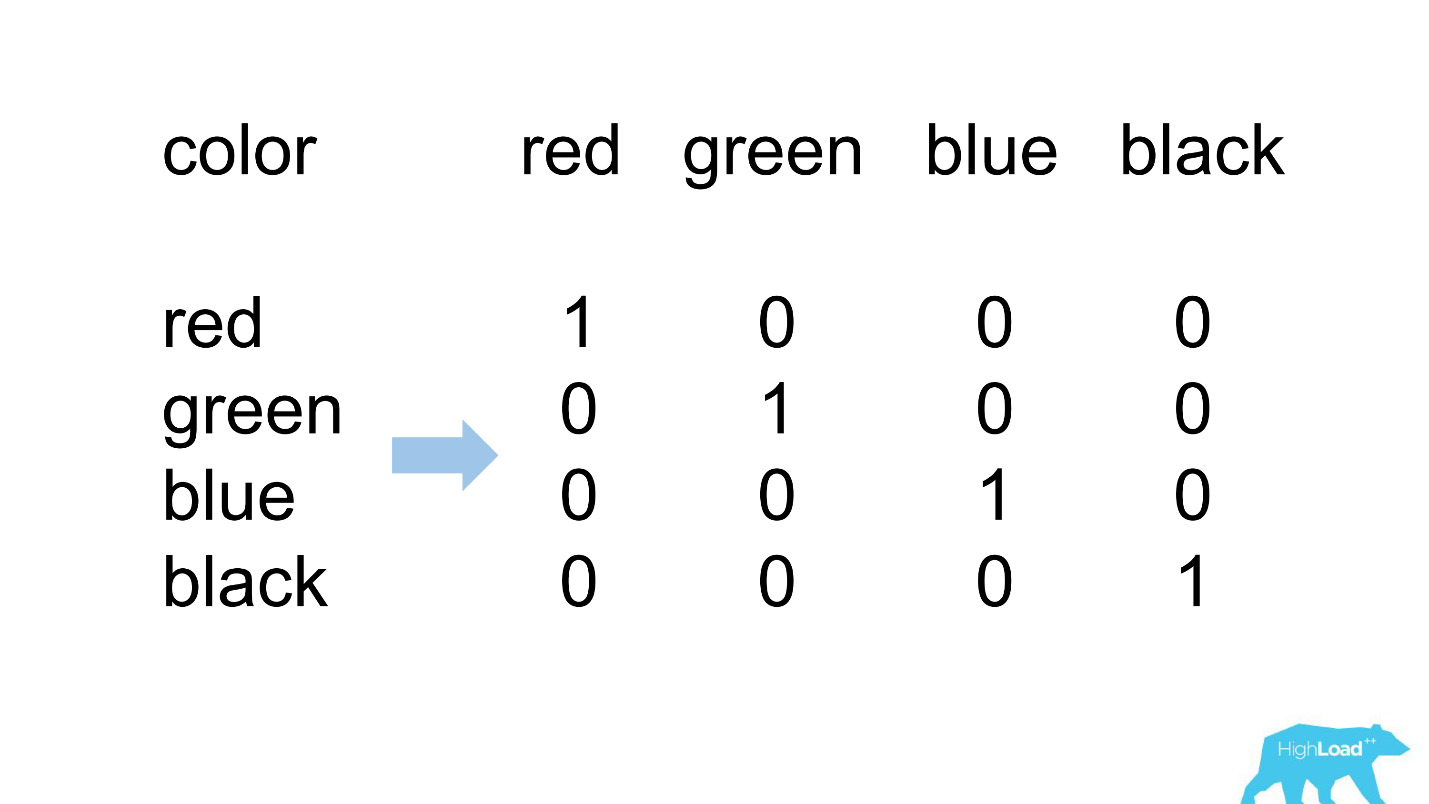
Eine heiße Codierung
Die meisten Funktionen unserer einfachsten Modelle sind kategorisch. Dies bedeutet, dass dies keine Zahlen sind, sondern bestimmte Kategorien: die Stadt, aus der der Benutzer stammt, oder die Stadt, in der er ein Hotel sucht. Wir verwenden One Hot Encoding und wandeln jeden der möglichen Werte in eine Einheit in einem binären Vektor um. Da wir zunächst nur unseren eigenen Rechenkern verwendeten, war es einfach, Situationen zu identifizieren, in denen im eingehenden Vektor kein Platz für die eingehende Kategorie vorhanden ist, dh das Modell hat diese Daten während des Trainings nicht gesehen.
So sieht es normalerweise aus.

destination_id - die Stadt, in der der Benutzer ein Hotel sucht. Natürlich hat das Modell nicht etwa 5% der Werte gesehen, da wir ständig neue Städte verbinden. besucher_cty_id = 23,32%, weil Datenwissenschaftler manchmal bewusst weniger verbreitete Städte weglassen.
In einem schlechten Fall könnte es so aussehen:

Sofort 3 Eigenschaften, 100% der Werte, die das Modell noch nie gesehen hat. Meistens geschieht dies aufgrund der Verwendung anderer als der im Training verwendeten Formate oder einfach banaler Tippfehler.
Mit Hilfe von Dashboards erkennen und korrigieren wir solche Situationen jetzt sehr schnell.
Showcase für maschinelles Lernen
Lassen Sie uns über andere Probleme sprechen, die wir gelöst haben. Nachdem wir Client-Bibliotheken erstellt und überwacht hatten, gewann der Service sehr schnell an Dynamik. Wir waren buchstäblich überwältigt von Anwendungen aus verschiedenen Teilen des Unternehmens: „Lassen Sie uns auch dieses Modell verbinden! Lass uns den alten aktualisieren! “ Wir haben gerade genäht, tatsächlich hat jede neue Entwicklung aufgehört.
Wir sind aus der Situation herausgekommen, indem wir
einen Selbstbedienungskiosk für Datenwissenschaftler gebaut haben . Jetzt können Sie einfach zu unserem Portal gehen, das wir zunächst nur zur Überwachung verwendet haben, und buchstäblich durch Klicken auf die Schaltfläche das Modell in die Produktion laden. In wenigen Minuten wird sie arbeiten und Vorhersagen geben.
Es gab noch ein Problem.
Booking.com hat ungefähr 200 IT-Teams. Wie kann man das Team in einem ganz anderen Teil des Unternehmens wissen lassen, dass es ein Modell gibt, das ihnen helfen könnte? Sie wissen vielleicht einfach nicht, dass es ein solches Team überhaupt gibt. Wie finde ich heraus, welche Modelle es gibt und wie man sie benutzt? Traditionell ist die externe Kommunikation in unseren Teams mit PO (Product Owner) verbunden. Dies bedeutet nicht, dass wir keine anderen horizontalen Verbindungen haben, nur PO tut dies mehr als andere. Es ist jedoch offensichtlich, dass auf einer solchen Skala die Eins-zu-Eins-Kommunikation nicht skaliert. Sie müssen etwas dagegen tun.
Wie kann die Kommunikation erleichtert werden?Plötzlich wurde uns klar, dass das Portal, das wir ausschließlich für die Überwachung erstellt haben, allmählich zu einem Schaufenster des maschinellen Lernens in unserem Unternehmen wird.
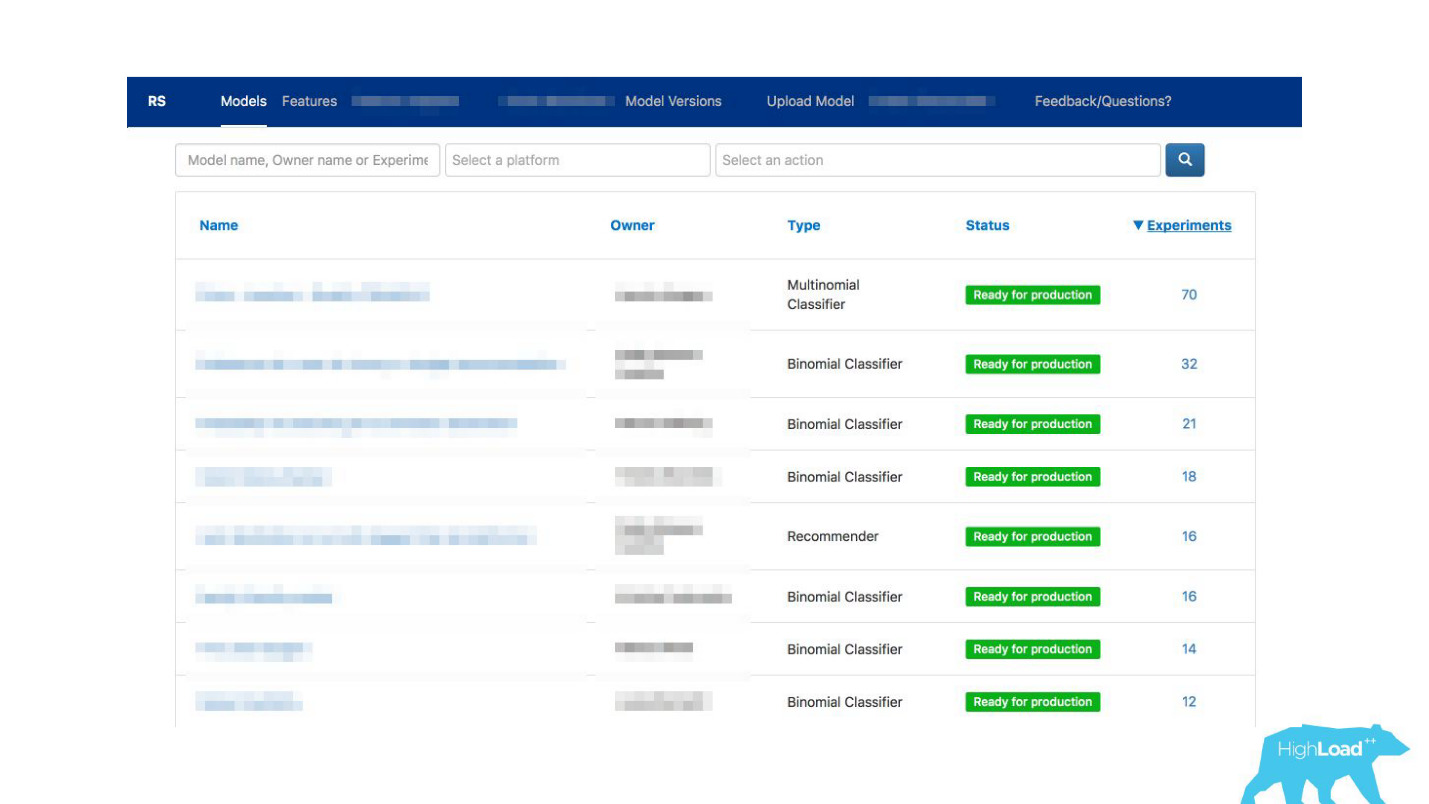
Wir haben Datenwissenschaftlern ermöglicht, ihre Modelle detailliert zu beschreiben. Wenn es viele Modelle gab, haben wir Themen- und Bereichsbezeichnungen für eine bequeme Gruppierung hinzugefügt.
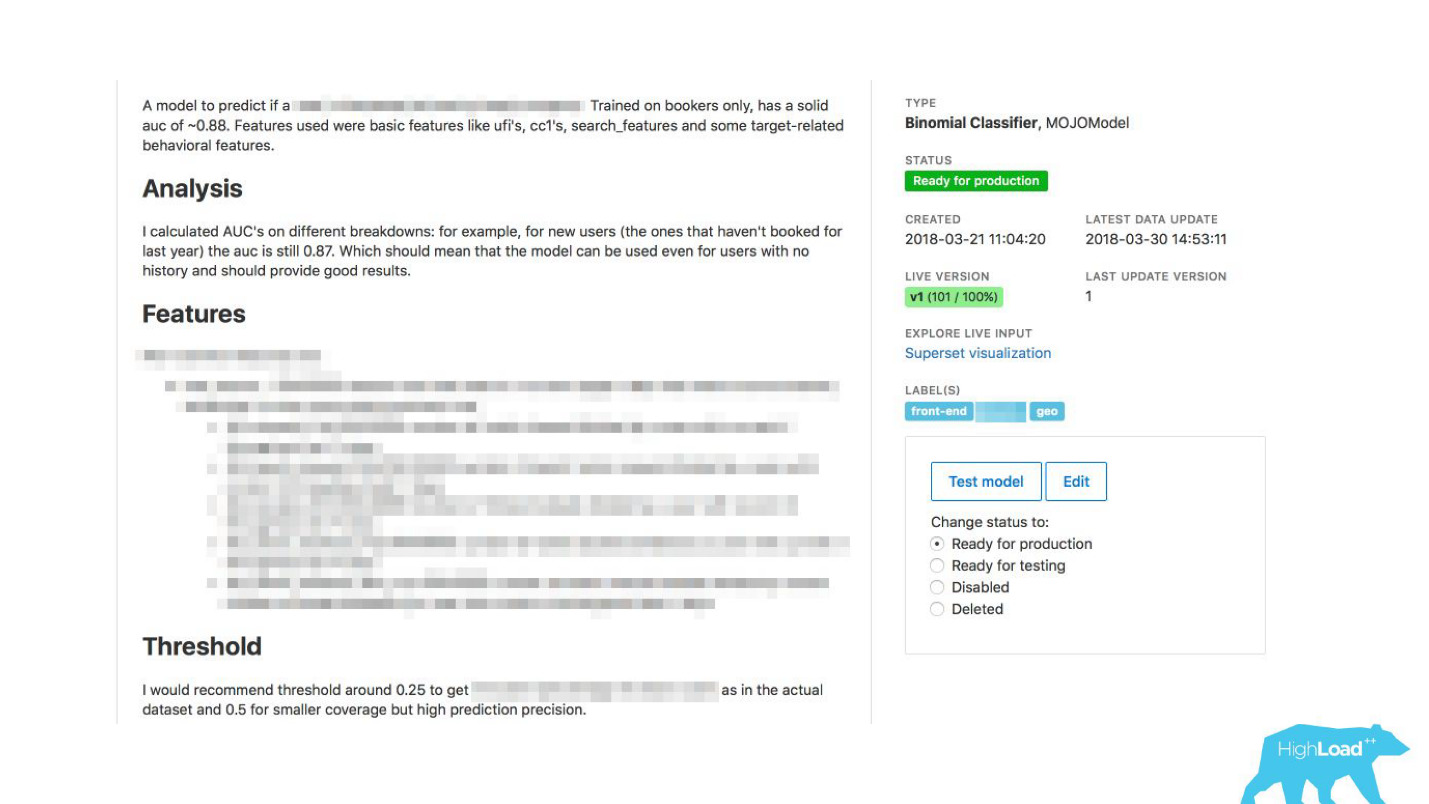
Wir haben unser Tool mit ExperimentTool verknüpft. Dies ist ein Produkt in unserem Unternehmen, das A / B-Experimente bereitstellt und die gesamte Geschichte des Experimentierens speichert.

Zusammen mit der Beschreibung des Modells können Sie jetzt auch sehen, was andere Teams zuvor mit diesem Modell gemacht haben und wie erfolgreich. Es hat alles verändert.
Im Ernst, dies hat die Funktionsweise der IT verändert, da Sie auch in Situationen, in denen kein Datenwissenschaftler im Team ist, maschinelles Lernen verwenden können.
Beispielsweise verwenden viele Teams dies während Brainstorming-Sitzungen. Wenn sie neue Produktideen entwickeln, wählen sie einfach die Modelle aus, die zu ihnen passen, und verwenden sie. Hierfür ist nichts Kompliziertes erforderlich.
Was hat es für uns verschüttet? Derzeit liefern wir auf dem Höhepunkt etwa 200.000 Vorhersagen pro Sekunde mit einer Latenz von weniger als 20 bis 30 ms, einschließlich HTTP-Roundtrip, und der Platzierung von mehr als 200 Modellen.
Es scheint, dass es ein so einfacher Spaziergang im Park war: Wir haben einen wunderbaren Job gemacht, alles funktioniert, alle sind glücklich!
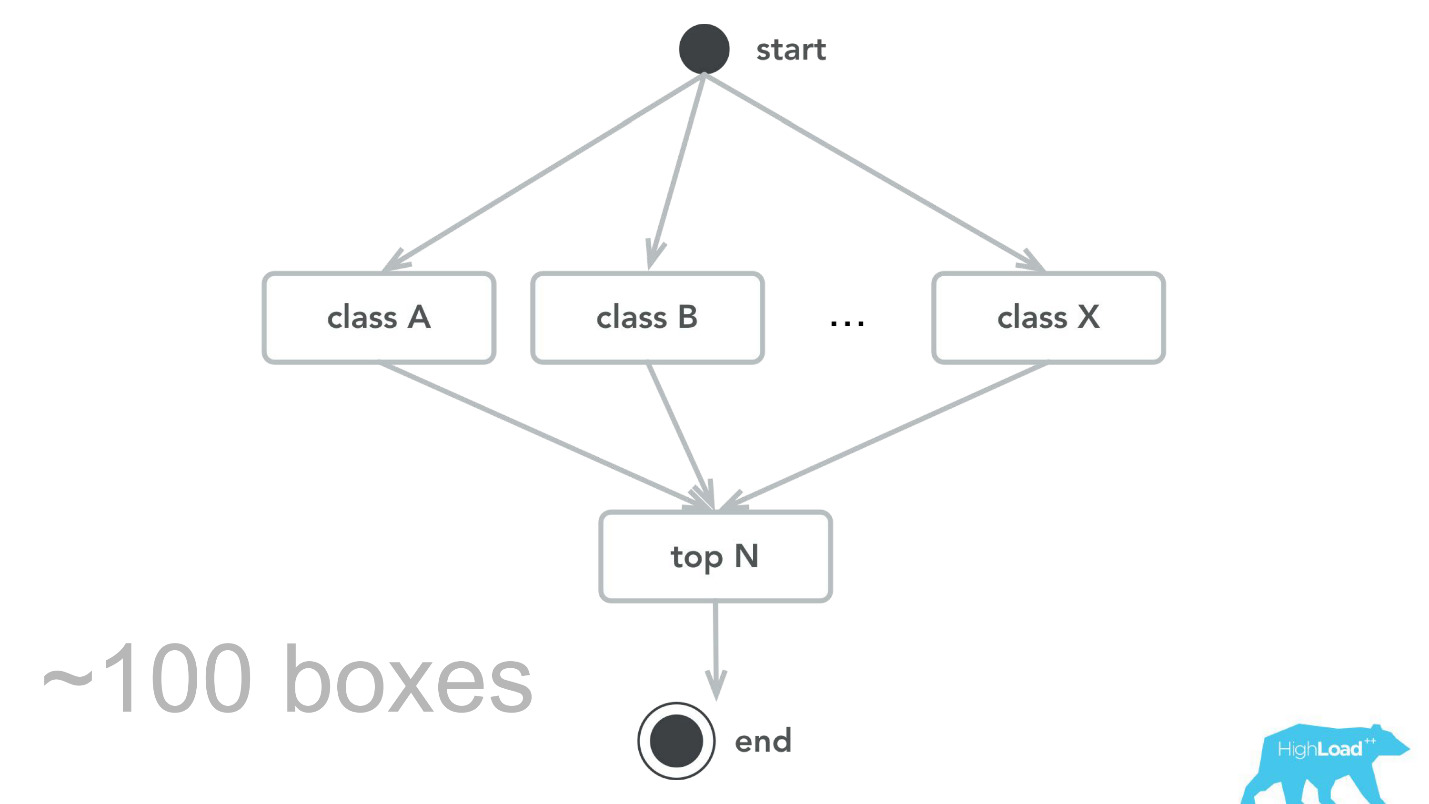
Das passiert natürlich nicht. Es gab Fehler. Zu Beginn haben wir zum Beispiel eine kleine Zeitbombe gepflanzt. Aus irgendeinem Grund haben wir angenommen, dass die meisten unserer Modelle Empfehlungssysteme mit starken Eingabevektoren sind, und der Scala + Akka-Stapel wurde genau deshalb ausgewählt, weil es mit seiner Hilfe sehr einfach ist, parallele Berechnungen zu organisieren. In Wirklichkeit erwies sich der Aufwand für all diese Parallelisierung zum Sammeln als höher als der mögliche Gewinn. Irgendwann verarbeiteten unsere 100 Maschinen nur noch 100.000 RPS, und es traten Fehler mit ganz charakteristischen Symptomen auf: Die CPU-Auslastung ist gering, es treten jedoch Zeitüberschreitungen auf.
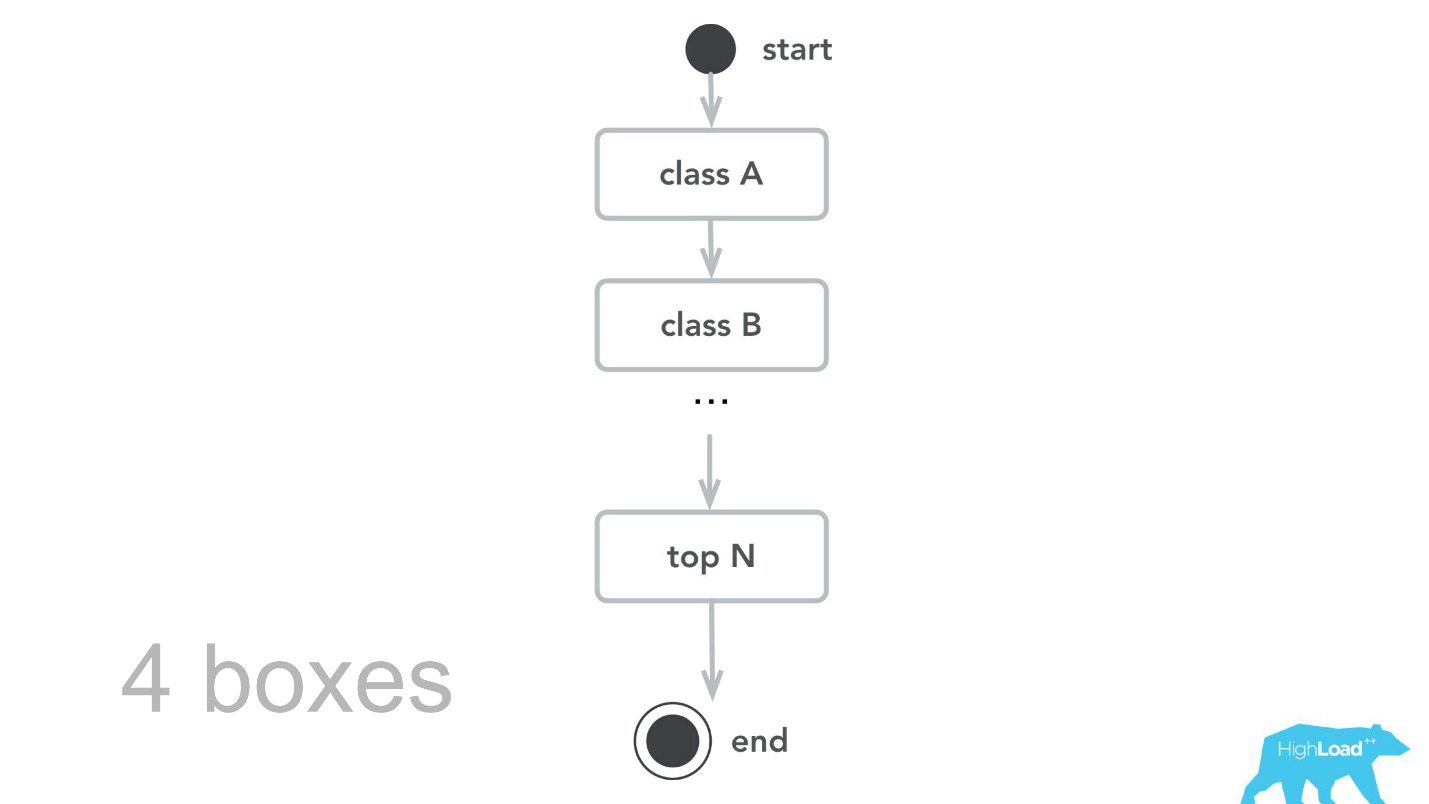
Dann kehrten wir zu unserem Rechenkern zurück, überprüften, machten Benchmarks und stellten als Ergebnis von Kapazitätstests fest, dass wir für denselben Verkehr nur 4 Maschinen benötigen. , , -, , , , 100 000 RPS 4 .
- , , . - , , , .
— , . , ID , . , 0.
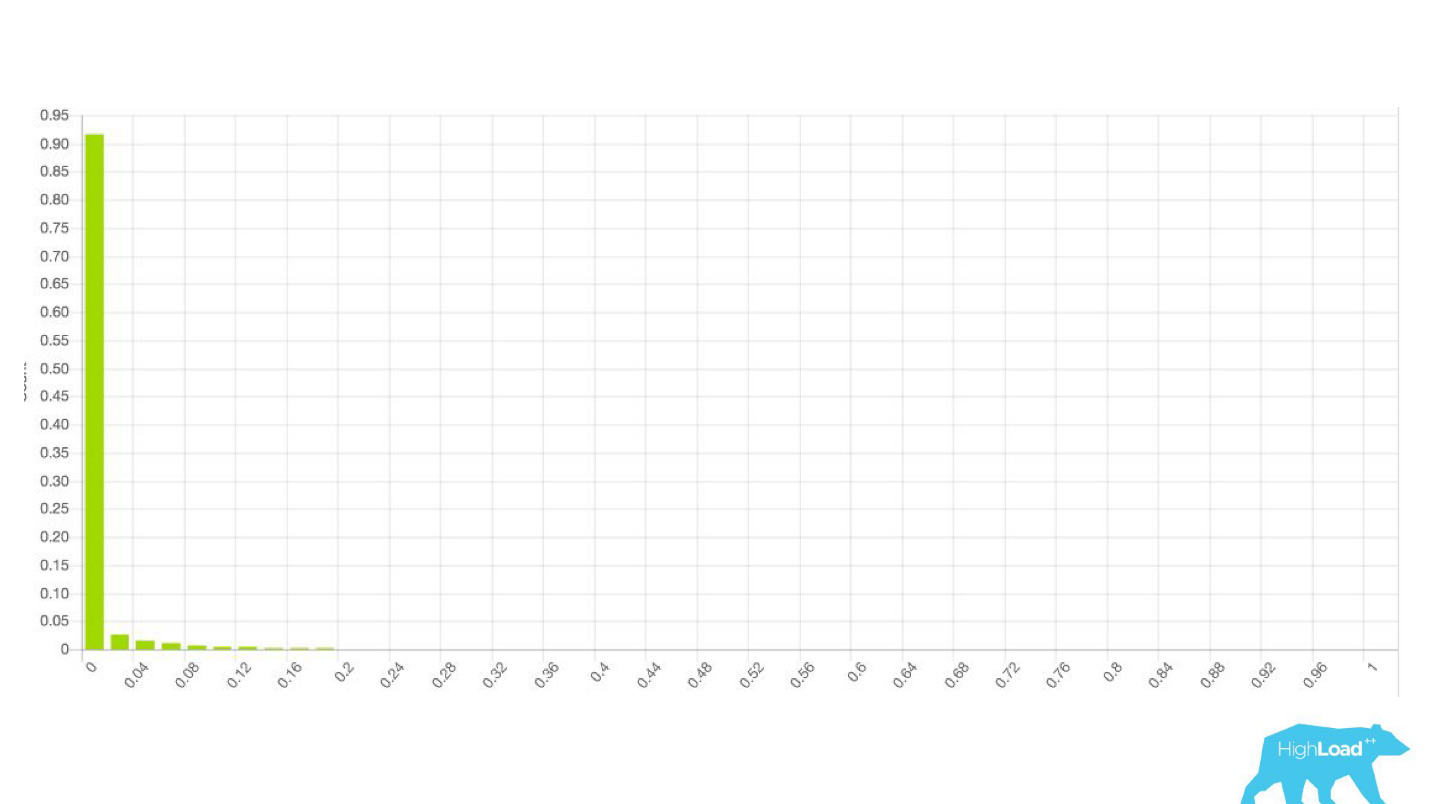
— , — .
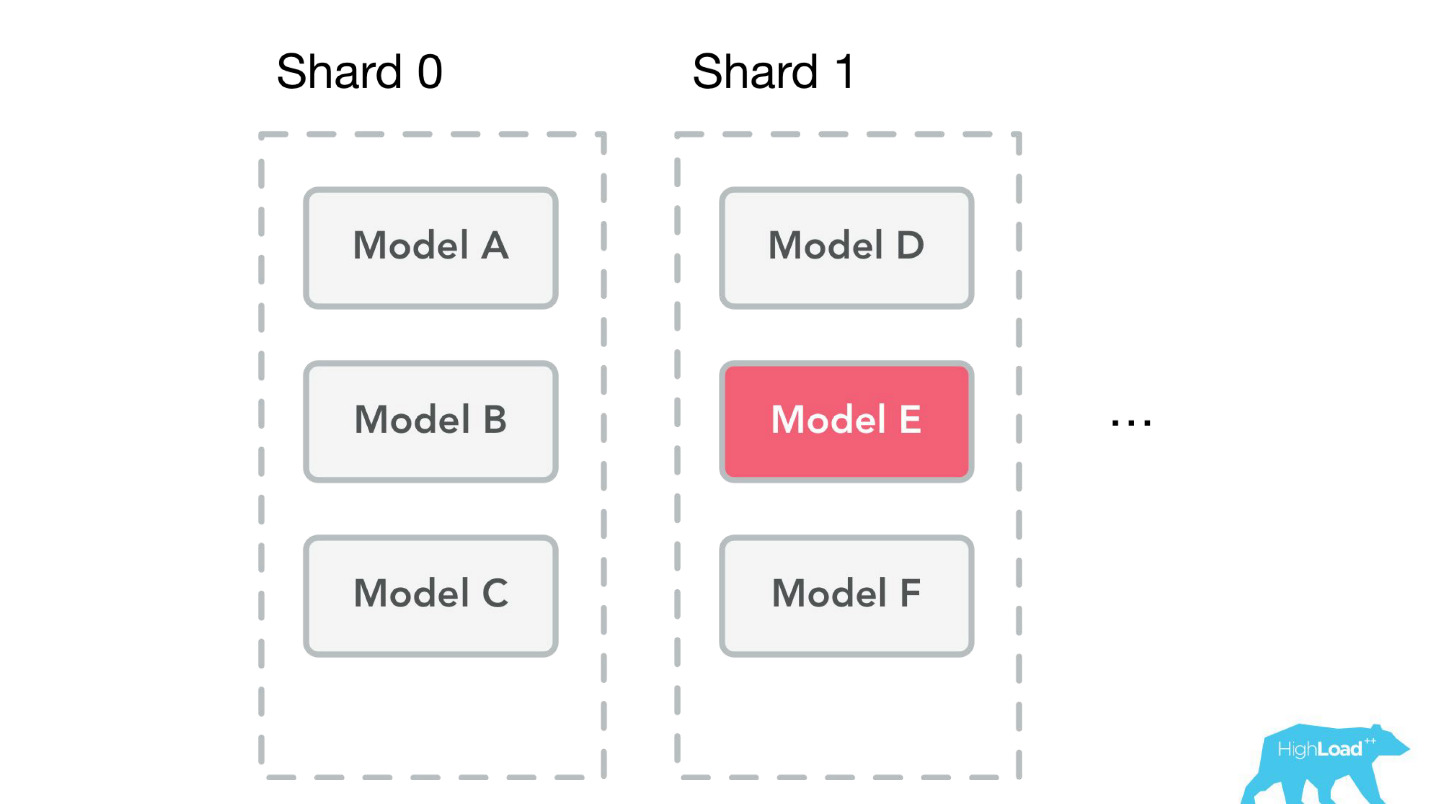
, . , . , — , . , , , - .
, — ID . — 49-51%. , . , , . , .
Zukunftspläne
- , . Label based metrics, precision recall .
- More tools & integrations
, . , Perl Java, , , . Spark, .
- Reusable training pipelines
.
, -. , , , , ,
steaming — - , , .
. pipeline, , . , , .
. ,
, 50 , . , . , , .
Start small
, , Booking.com, , , — !
, , MySQL. , , . - . B . , , - — .
, ?
Monitor
— , -, .
— . — , . , , , . : , . , , , — !
Organization footprint
, . , . , .
(Don't) Follow our steps
- , , , . , - , . , . — , , ? , , , ?
, , !HighLoad++ 2018, 8 9 , 135 , . 9 - . , .