Bevor ein Kunde Geldtransfers in ePayments vornehmen kann, muss er eine Überprüfung durchlaufen. Er stellt uns seine persönlichen Daten zur Verfügung und lädt Dokumente hoch, um seine Identität und Adresse zu überprüfen. Und wir prüfen, ob sie den Anforderungen unserer Aufsichtsbehörde entsprechen. Der Fluss der Anträge auf Überprüfung wurde immer größer, und es wurde für uns schwierig, einen solchen Fluss von Dokumenten zu verarbeiten. Wir befürchteten, dass das Verfahren viel Zeit in Anspruch nehmen und alle für Kunden angemessenen Bedingungen übertreffen würde. Dann beschlossen wir, ein Verifizierungssystem zu schaffen, das auf tiefem Lernen basiert.

Bildungsprogramm über Regulierungsbehörden und ihre Anforderungen
Um elektronisches Geld auszugeben, benötigen Sie eine Regulierungslizenz. Wenn Sie beispielsweise in Russland ein Zahlungssystem eröffnen, wird die Zentralbank der Russischen Föderation zu Ihrer Regulierungsbehörde. ePayments ist ein englisches Zahlungssystem. Unsere Aufsichtsbehörde ist die Financial Conduct Authority (FCA), eine Behörde, die dem britischen Finanzministerium Bericht erstattet. Die FCA stellt sicher, dass wir die Geldwäschebekämpfungsrichtlinie (AML) einhalten, die die KYC-Verfahren (Know Your Customer) enthält.
Laut KYC sind wir bestrebt zu überprüfen, wer unser Kunde ist und ob er mit sozial gefährlichen Gruppen in Verbindung steht. Daher haben wir zwei Verpflichtungen:
- Identifizierung und Bestätigung der Kundenidentität.
- Abgleich seiner Daten mit verschiedenen Listen: Terroristen, Sanktionspersonen, Regierungsmitglieder und viele andere.
Die KYC-Anforderungen werden von Jahr zu Jahr strenger und detaillierter. Zu Beginn des Jahres 2017 konnten ePayments-Kunden ohne Bestätigung noch Zahlungen erhalten oder Überweisungen vornehmen. Dies ist erst möglich, wenn sie ihre Identität bestätigt haben.
Manuelle Überprüfung
Vor ein paar Jahren haben wir es alleine geschafft. Die Russen schickten einen Scan bestimmter Seiten des Passes, um ihre Identität zu bestätigen, und einen Scan des Mietvertrags, eine Quittung für die Zahlung von Wohnraum und kommunalen Dienstleistungen, um die Adresse zu bestätigen. Erinnern Sie sich bitte an das Spiel Papers? Als Zollbeamter prüfen Sie darin Dokumente anhand der immer komplexer werdenden Anforderungen der Regierung. Unsere Kundenabteilung hat es jeden Tag bei der Arbeit gespielt.

Kunden werden ohne Besuch im Büro aus der Ferne überprüft. Um das Verfahren zu beschleunigen, haben wir neue Mitarbeiter eingestellt, aber dies ist eine Sackgasse. Dann kam die Idee, einen Teil der Arbeit des neuronalen Netzes anzuvertrauen. Wenn sie mit Gesichtserkennung gut zurechtkommt, dann kommt sie mit unseren Aufgaben zurecht. Aus geschäftlicher Sicht sollte ein schnelles Verifizierungssystem in der Lage sein:
- Klassifizieren Sie ein Dokument. Wir erhalten einen Personalausweis und einen Adressnachweis. Das System sollte beantworten, was es am Eingang erhalten hat: einen Reisepass eines Bürgers der Russischen Föderation, einen Mietvertrag oder etwas anderes.
- Vergleichen Sie Gesicht in Foto und Dokument. Wir bitten Kunden, Selfies mit einem Personalausweis zu senden, um sicherzustellen, dass sie selbst im Zahlungssystem registriert sind.
- Text extrahieren. Das Ausfüllen von Dutzenden von Feldern mit einem Smartphone ist nicht sehr praktisch. Es ist viel einfacher, wenn die Anwendung alles für Sie erledigt hat.
- Überprüfen Sie die Bilddateien auf Fotomontage. Wir dürfen Betrüger nicht vergessen, die betrügerisch in das System eindringen wollen.
Am Ausgang sollte das System ein gewisses Maß an Vertrauen in den Client anzeigen: hoch, mittel oder niedrig. Wenn wir uns auf eine solche Abstufung konzentrieren, werden wir Kunden mit längeren Zeiträumen schnell überprüfen und nicht verärgern.
Dokumentklassifizierer
Die Aufgabe dieses Moduls ist es, sicherzustellen, dass der Benutzer ein gültiges Dokument sendet und eine Antwort gibt, was genau er hochgeladen hat: einen Reisepass eines kasachischen Bürgers, einen Mietvertrag oder eine Quittung für die Zahlung von Wohnraum und kommunalen Dienstleistungen.
Der Klassifikator empfängt die Eingabedaten:
- Foto oder Dokument scannen
- Land des Wohnsitzes
- Art des vom Kunden angegebenen Dokuments (Personalausweis oder Adressnachweis)
- Extrahierter Text (mehr dazu weiter unten)
Am Ausgang gibt der Klassifikator an, was er erhalten hat (Reisepass, Führerschein usw.) und wie sicher er von der richtigen Antwort ist.

Die Lösung läuft jetzt auf der Wide Residual Network-Architektur. Wir sind nicht sofort zu ihr gekommen. Die erste Version des Schnellverifizierungssystems basierte auf der Architektur, zu der uns VGG inspiriert hat. Sie hatte zwei offensichtliche Probleme: eine große Anzahl von Parametern (ungefähr 130 Millionen) und eine Instabilität der Position des Dokuments. Je mehr Parameter vorhanden sind, desto schwieriger ist es, ein solches neuronales Netzwerk zu trainieren - es verallgemeinert das Wissen schlecht. Das Dokument auf dem Foto sollte zentriert sein, da sonst der Klassifikator auf die Proben geschult werden müsste, in denen er sich in verschiedenen Teilen des Fotos befindet. Infolgedessen haben wir VGG aufgegeben und beschlossen, auf eine andere Architektur umzusteigen.
Residual Network (ResNet) war cooler als VGG. Dank des
Überspringens von Verbindungen können Sie eine große Anzahl von Ebenen erstellen und eine hohe Genauigkeit erzielen. ResNet hat nur etwa 1 Million Parameter, und die Position des Dokuments war ihr gleichgültig. Unabhängig davon, wo es sich im Bild befindet, hat die Lösung für diese Architektur die Klassifizierung übernommen.
Während wir die Lösung mit einer Datei fertigstellten, wurde eine neue Architekturänderung, das Wide Residual Network (WRN), veröffentlicht. Der Hauptunterschied zu ResNet ist ein Schritt zurück in Bezug auf die Tiefe. WRN hat weniger Schichten, aber mehr Faltungsfilter. Dies ist die beste neuronale Netzwerkarchitektur für die meisten Aufgaben, und unsere Lösung arbeitet daran.
Einige nützliche Lösungen
Problem Nummer 1. Der Klassifikator musste trainiert werden. Wir mussten viele russische, kasachische und belarussische Pässe und Führerscheine herunterladen. Aber natürlich können Sie keine Kundendokumente nehmen. Es gibt Beispiele im Netzwerk, aber es gibt zu wenige, um das neuronale Netzwerk erfolgreich zu trainieren.
Lösung. Unsere technische Abteilung hat eine Stichprobe von mehr als 8000 Stichproben jedes Typs erstellt. Wir erstellen eine Dokumentvorlage und multiplizieren sie mit vielen Zufallsstichproben. Dann erzeugen wir eine zufällige Position des Dokuments im Raum relativ zur Kamera unter Berücksichtigung seines mathematischen Modells und seiner Eigenschaften: Brennweite, Matrixauflösung usw. Bei der Erzeugung eines künstlichen Fotos wird ein zufälliges Bild aus dem fertigen Datensatz als Hintergrund ausgewählt. Danach wird ein Dokument mit perspektivischen Verzerrungen zufällig auf dem Bild platziert. In einer solchen Stichprobe war unser neuronales Netzwerk gut trainiert und definierte das Dokument „im Kampf“ perfekt. Die Ergebnisse finden Sie am Ende des Artikels.
Problem Nummer 2. Banale Einschränkung der Rechenressourcen und des Speichers. Es macht keinen Sinn, ein tiefes neuronales Netzwerk für die Eingabe großer Bilder zu verwenden. Und Fotos von modernen Smartphones sind genau das.
Lösung. Vor dem Anwenden auf die Eingabe wird das Foto auf eine Größe von ungefähr 300 x 300 Pixel komprimiert. Aus dem Bild dieser Erlaubnis kann man leicht ein Ausweisdokument von einem anderen unterscheiden. Um dieses Problem zu lösen, können wir die Standard-Wide ResNet-Architektur verwenden.
Problem Nummer 3. Mit Dokumenten, die die Adresse des Wohnsitzes bestätigen, ist alles komplizierter. Der Mietvertrag oder Kontoauszug kann nur durch den Text auf dem Blatt unterschieden werden. Nach dem Reduzieren der Bildgröße auf die gleichen 300 x 300 Pixel sieht jedes dieser Dokumente gleich aus - wie ein A4-Blatt mit unleserlichem Text.
Lösung. Um beliebige Dokumente zu klassifizieren, haben wir Änderungen an der Architektur des neuronalen Netzwerks selbst vorgenommen. Darin erschien eine zusätzliche Eingangsschicht von Neuronen, die mit der Ausgangsschicht verbunden ist. Die Neuronen dieser Eingabeebene erhalten eine Vektoreingabe, die den zuvor erkannten Text unter Verwendung des
Bag-of-Words- Modells beschreibt.
Zuerst haben wir ein neuronales Netzwerk trainiert, um Identitätsdokumente zu klassifizieren. Wir haben die Gewichte des trainierten Netzwerks verwendet, als wir ein anderes Netzwerk mit einer zusätzlichen Ebene initialisiert haben, um beliebige Dokumente zu klassifizieren. Diese Lösung hatte eine hohe Genauigkeit, aber die Texterkennung dauerte einige Zeit. Der Unterschied in der Verarbeitungsgeschwindigkeit zwischen verschiedenen Modulen und der Klassifizierungsgenauigkeit ist in Tabelle Nr. 2 ersichtlich.
Gesichtserkennung
Wie kann man ein Zahlungssystem austricksen, das Dokumente prüft? Sie können den Reisepass eines anderen ausleihen und sich damit registrieren. Um sicherzustellen, dass sich der Kunde selbst registriert, bitten wir Sie, ein Selfie mit einem Personalausweis zu machen. Und das Erkennungsmodul sollte das Gesicht auf dem Dokument und das Gesicht auf dem Selfie vergleichen und antworten, dies ist eine oder zwei verschiedene Personen.
Wie vergleiche ich 2 Gesichter, wenn Sie ein Auto sind und wie ein Auto denken? Verwandeln Sie ein Foto in eine Reihe von Parametern und vergleichen Sie deren Werte miteinander. So funktionieren neuronale Netze, die Gesichter erkennen. Sie nehmen ein Bild auf und verwandeln es in einen 128-dimensionalen (zum Beispiel) Vektor. Wenn Sie ein weiteres Gesichtsbild an die Eingabe senden und sie zum Vergleich auffordern, verwandelt das neuronale Netzwerk das zweite Gesicht in einen Vektor und berechnet den Abstand zwischen ihnen.
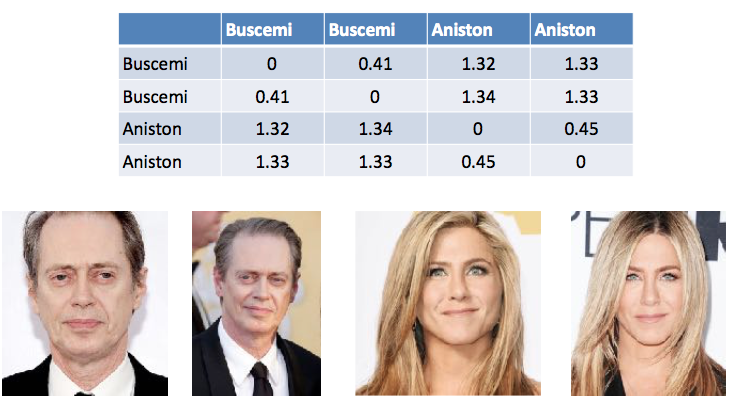 Tabelle 1. Ein Beispiel für die Berechnung der Differenz zwischen Vektoren bei der Gesichtserkennung. Steve Buscemi unterscheidet sich von sich selbst in verschiedenen Fotos um 0,44. Und von Jennifer Aniston - durchschnittlich 1,33.
Tabelle 1. Ein Beispiel für die Berechnung der Differenz zwischen Vektoren bei der Gesichtserkennung. Steve Buscemi unterscheidet sich von sich selbst in verschiedenen Fotos um 0,44. Und von Jennifer Aniston - durchschnittlich 1,33.Natürlich gibt es Unterschiede zwischen dem Aussehen einer Person im Leben und dem eines Passes. Wir haben auch den Abstand zwischen den Vektoren ausgewählt und an realen Personen getestet, um ein Ergebnis zu erzielen. In jedem Fall wird die endgültige Entscheidung jetzt von der Person getroffen, und ein Kommentar des Systems ist nur eine Empfehlung.
Texterkennung
In den Dokumenten befinden sich Textfelder, die dem Klassifizierer helfen, zu verstehen, was sich davor befindet. Für den Benutzer ist es praktisch, wenn der Text aus demselben Reisepass automatisch übertragen wird und nicht manuell eingegeben werden muss, von wem und wann er ausgestellt wurde. Zu diesem Zweck haben wir das folgende Modul erstellt: Erkennung und Textextraktion.
Auf einigen Dokumenten, zum Beispiel neuen Pässen der Russischen Föderation, gibt es eine maschinenlesbare Zone (MRZ). Die Verwendung ist einfach, Informationen aufzunehmen - es ist einfach, schwarzen Text auf einem weißen Hintergrund zu lesen, der leicht zu erkennen ist. Darüber hinaus verfügt MRZ über ein bekanntes Format, dank dessen es einfacher ist, die erforderlichen Daten zu erhalten.

Wenn die Aufgabe Dokumente mit MRZ enthält, wird es für uns einfacher. Der gesamte Prozess liegt im Bereich Computer Vision. Wenn diese Zone nicht vorhanden ist, müssen Sie nach dem Erkennen des Textes ein interessantes Problem lösen - um zu verstehen, und welche Informationen haben wir erkannt? Zum Beispiel ist "15. Mai 1999" das Geburtsdatum oder das Ausstellungsdatum? In dieser Phase können Sie auch einen Fehler machen. MRZ ist gut, weil es eindeutig dekodiert ist. Wir wissen immer, nach welchen Informationen und in welchem Teil der MRZ wir suchen müssen. Es ist sehr bequem für uns. Aber MRZ war nicht das beliebteste Dokument, mit dem das Netzwerk arbeiten wird - der Pass der Russischen Föderation.
Für die Texterkennung brauchten wir eine sehr effektive Lösung. Der Text muss aus dem Bild entfernt werden, das von der Kamera des Telefons aufgenommen wurde, und nicht von den professionellsten Fotografen. Wir haben Google Tesseract und mehrere kostenpflichtige Lösungen getestet. Es kam nichts heraus - entweder funktionierte es schlecht oder es war unangemessen teuer. Infolgedessen haben wir begonnen, unsere eigene Lösung zu entwickeln. Jetzt beenden wir seine Tests. Die Lösung zeigt anständige Ergebnisse - Sie können unten darüber lesen. Wir werden etwas später über das Modul zur Überprüfung auf Fotomontage sprechen, wenn genaue Forschungsergebnisse zu Testproben und zum „Kampf“ vorliegen.
Ergebnis
Das System wird derzeit im Segment der Anträge auf Überprüfung aus Russland getestet. Das Segment wird durch Zufallsstichprobe bestimmt, die Ergebnisse werden gespeichert und mit den Entscheidungen des Kundenabteilungsbetreibers für einen bestimmten Kunden verglichen.
| Land | Klassifizierertyp | Genauigkeit | Arbeitszeit, s |
| Russland | Ausweis | 99,96% | 0,41 |
| Russland | Benutzerdefiniertes Dokument | 98,62% | 6.89 |
| Kasachstan | Ausweis | 99,51% | 0,47 |
| Kasachstan | Benutzerdefiniertes Dokument | 97,25% | 7.66 |
| Weißrussland | Ausweis | 98,63% | 0,46 |
| Weißrussland | Benutzerdefiniertes Dokument | 98,63% | 9.66 |
Tabelle 2. Die Genauigkeit des Klassifikators von Dokumenten (die korrekte Klassifizierung des Dokuments im Vergleich zur Bewertung des Bedieners).Einer der großen Vorteile des maschinellen Lernens besteht darin, dass das neuronale Netzwerk wirklich lernt und weniger Fehler macht. In Kürze werden wir die Tests für das Segment beenden und das Verifizierungssystem im Kampfmodus starten. 30% der Anträge auf Überprüfung gehen an elektronische Zahlungen aus Russland, Kasachstan und Weißrussland. Nach unseren Schätzungen wird der Start dazu beitragen, die Belastung der Kundenabteilung um 20 bis 25% zu verringern. In Zukunft kann die Lösung auf europäische Länder skaliert werden.
Auf der Suche nach einem Job?
Wir suchen Mitarbeiter für ein Büro in St. Petersburg. Wenn Sie an einem internationalen Projekt mit einem großen Pool an ehrgeizigen Aufgaben interessiert sind, warten wir auf Sie. Wir haben nicht genug Leute, die keine Angst haben, sie zu realisieren. Unten finden Sie Links zu offenen Stellen auf hh.ru.