
Dieser Artikel ist Teil
der Chronik der Softwarearchitektur , einer Reihe von Artikeln zur Softwarearchitektur. In ihnen schreibe ich darüber, was ich über Softwarearchitektur gelernt habe, was ich darüber denke und wie ich Wissen benutze. Der Inhalt dieses Artikels ist möglicherweise sinnvoller, wenn Sie die vorherigen Artikel in der Reihe lesen.
Nach meinem Universitätsabschluss begann ich als Highschool-Lehrer zu arbeiten, aber vor einigen Jahren kündigte ich und ging zu den Vollzeit-Softwareentwicklern.
Seitdem hatte ich immer das Gefühl, dass ich die „verlorene“ Zeit wiederherstellen und so schnell wie möglich so viel wie möglich herausfinden muss. Deshalb begann ich mich ein wenig mit Experimenten zu beschäftigen, viel zu lesen und zu schreiben, wobei ich besonders auf das Design und die Architektur der Software achtete. Deshalb schreibe ich diese Artikel, um mir beim Studium zu helfen.
In den letzten Artikeln habe ich über viele Konzepte und Prinzipien gesprochen, die ich gelernt habe, und ein wenig darüber, wie ich darüber nachdenke. Aber ich stelle sie mir als Fragmente eines großen Puzzles vor.
In diesem Artikel geht es darum, wie ich all diese Fragmente zusammengesetzt habe. Ich denke, ich sollte ihnen einen Namen geben, also werde ich sie
explizite Architektur nennen . Darüber hinaus werden alle diese Konzepte
„im Kampf getestet“ und in der Produktion auf hochzuverlässigen Plattformen eingesetzt. Eine davon ist eine SaaS-E-Commerce-Plattform mit Tausenden von Online-Shops auf der ganzen Welt, die andere ist eine Handelsplattform, die in zwei Ländern mit einem Nachrichtenbus betrieben wird, der mehr als 20 Millionen Nachrichten pro Monat verarbeitet.
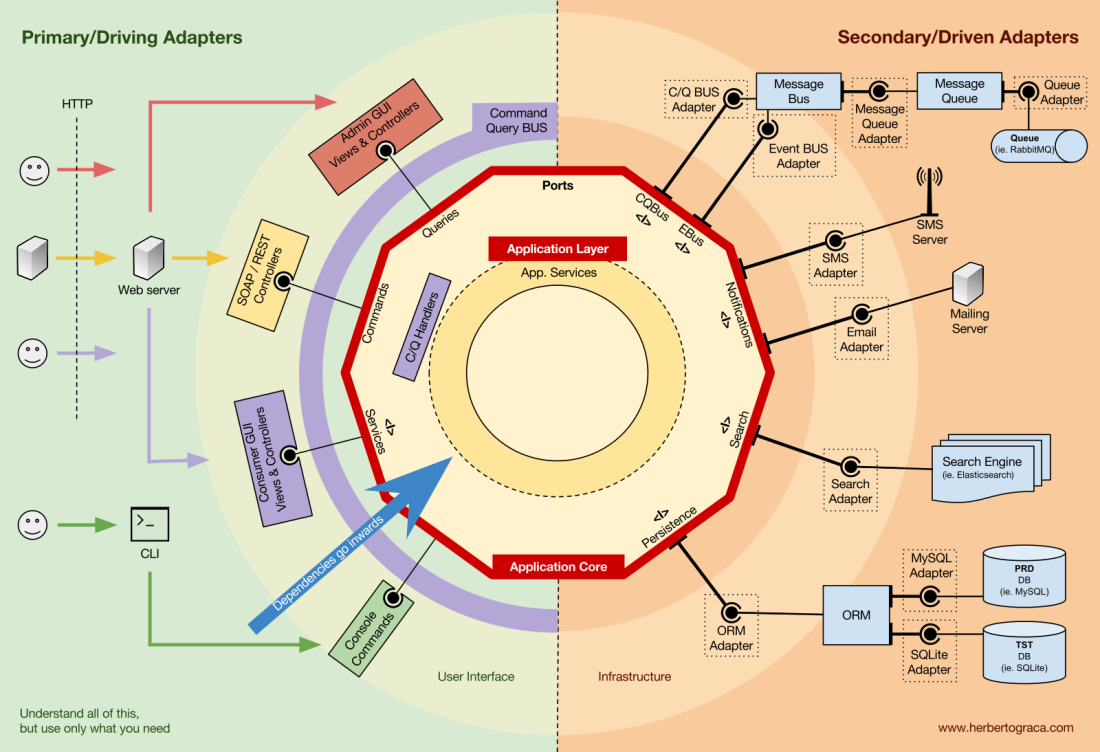
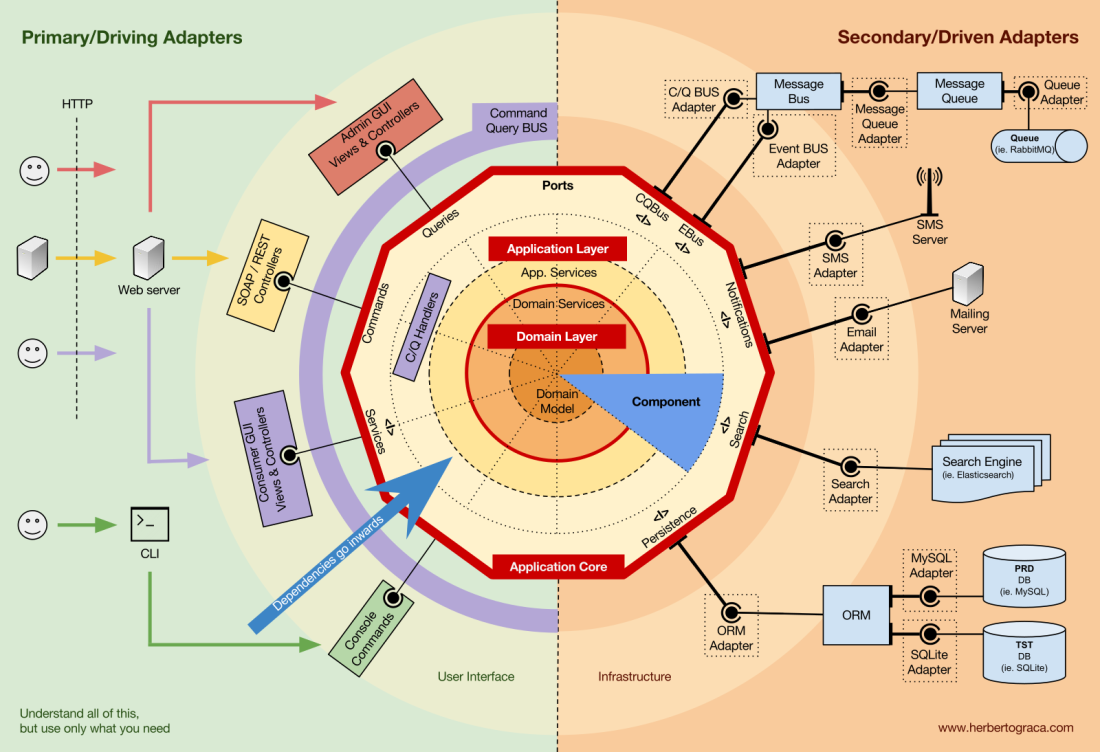
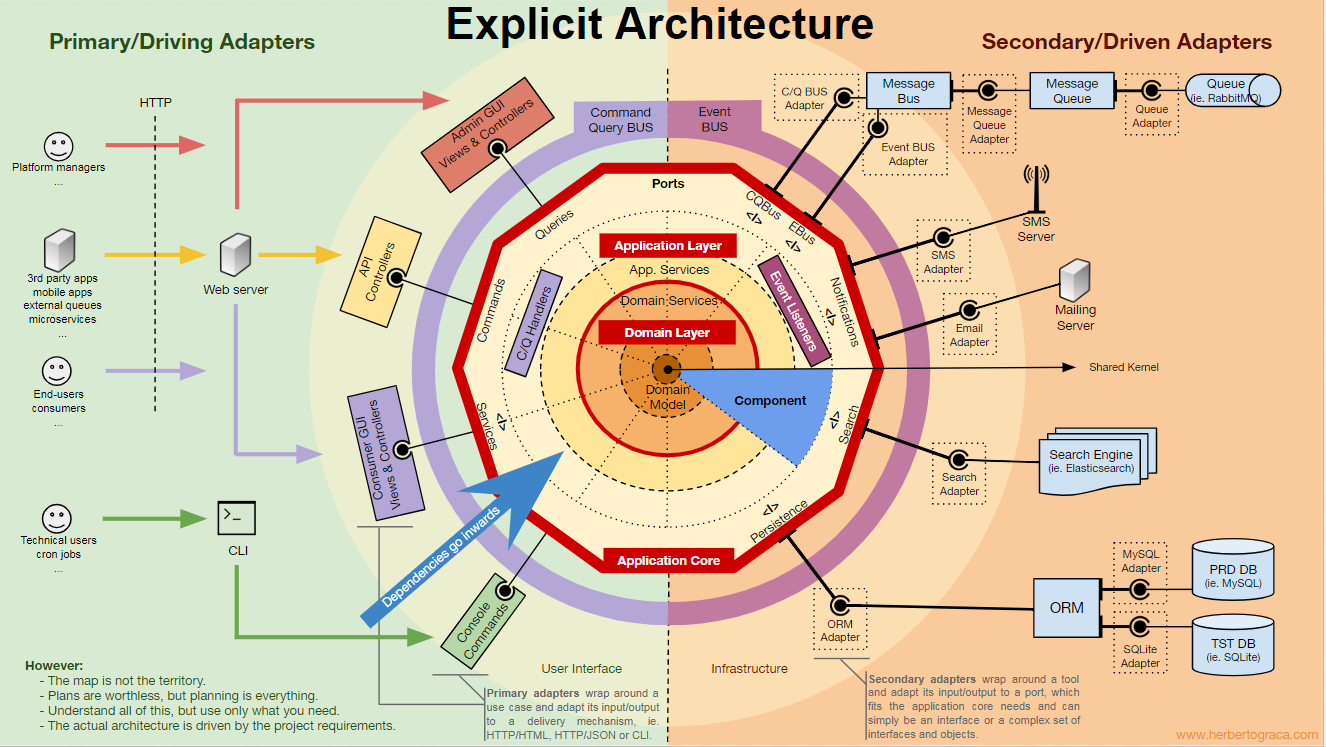
Grundlegende Blöcke des Systems
Beginnen wir mit dem
Abrufen der EBI- und
Ports & Adapter- Architekturen. Beide trennen klar den internen und externen Code der Anwendung sowie die Adapter zum Verbinden des internen und externen Codes.
Darüber hinaus definiert die
Ports & Adapter- Architektur explizit die drei grundlegenden Codeblöcke im System:
- Auf diese Weise können Sie die Benutzeroberfläche unabhängig von ihrem Typ ausführen.
- Systemgeschäftslogik oder Anwendungskern . Es wird von der Benutzeroberfläche verwendet, um echte Transaktionen durchzuführen.
- Der Infrastrukturcode , der den Kern unserer Anwendung mit Tools wie der Datenbank, der Suchmaschine oder APIs von Drittanbietern verbindet.
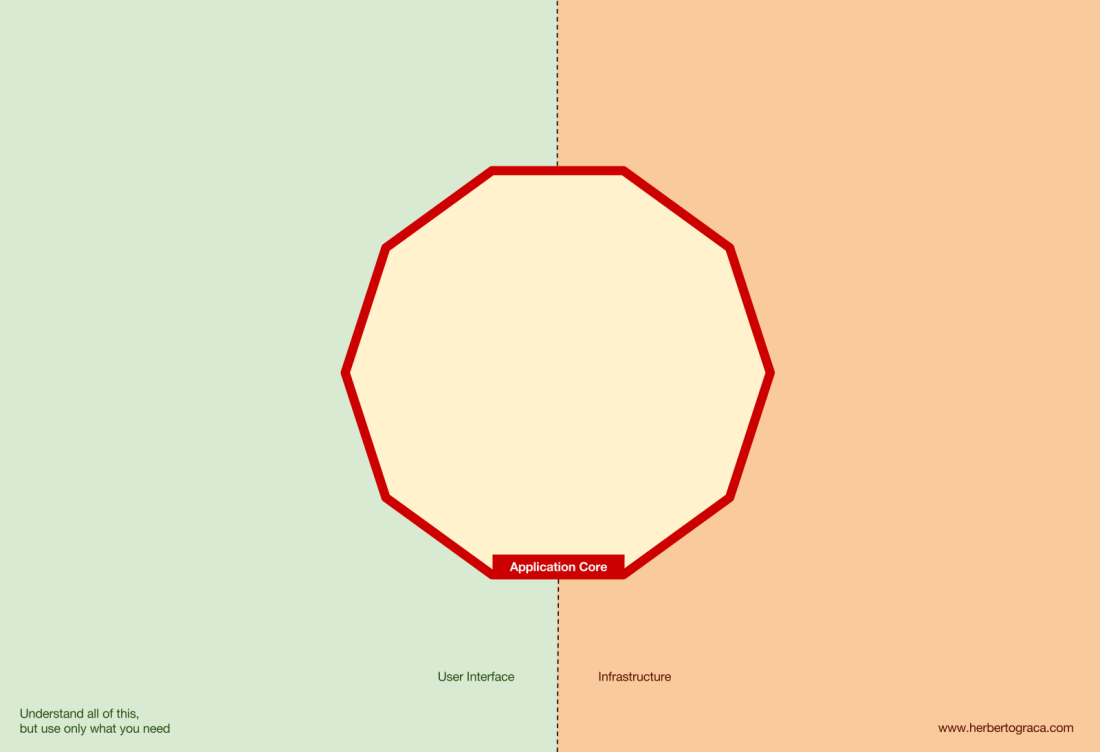
Der Kern der Anwendung ist das Wichtigste, worüber man nachdenken muss. Mit diesem Code können Sie echte Aktionen im System ausführen, dh dies ist unsere Anwendung. Es können mehrere Benutzeroberflächen (eine progressive Webanwendung, eine mobile Anwendung, eine CLI, eine API usw.) damit arbeiten, alles läuft auf einem Kern.
Wie Sie sich vorstellen können, geht ein typischer Ausführungsfluss vom Code in der Benutzeroberfläche über den Anwendungskern zum Infrastrukturcode zurück zum Anwendungskern und schließlich wird die Antwort an die Benutzeroberfläche gesendet.

Die Werkzeuge
Weit entfernt vom wichtigsten Kernel-Code gibt es immer noch Tools, die die Anwendung verwendet. Zum Beispiel die Datenbankmaschine, die Suchmaschine, der Webserver und die CLI-Konsole (obwohl die beiden letzteren auch Übermittlungsmechanismen sind).
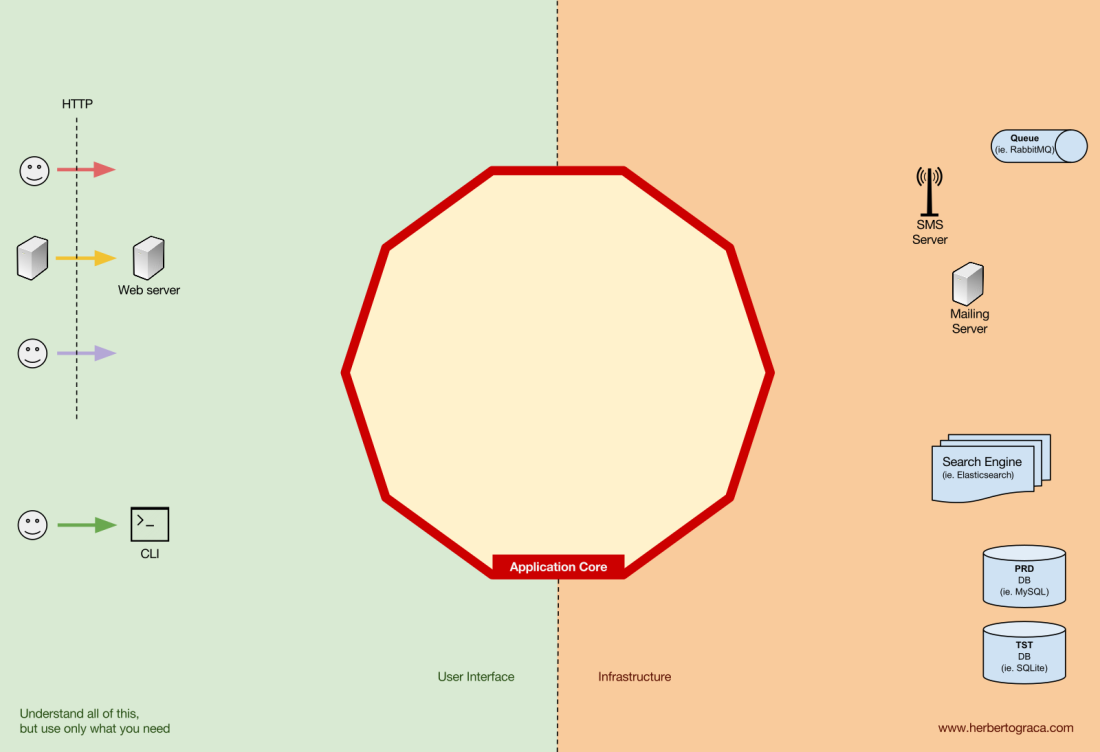
Es erscheint seltsam, die CLI-Konsole im selben Themenbereich wie das DBMS zu platzieren, da sie einen anderen Zweck hat. Tatsächlich sind beide Tools von der Anwendung verwendet. Der Hauptunterschied besteht darin, dass die CLI-Konsole und der Webserver
die Anwendung anweisen, etwas zu tun . Der DBMS-Kernel
empfängt im Gegenteil
Befehle von der Anwendung . Dies ist ein sehr wichtiger Unterschied, da dies einen großen Einfluss darauf hat, wie wir Code schreiben, um diese Tools mit dem Anwendungskern zu verbinden.
Verbinden von Tools und Bereitstellungsmechanismen mit dem Anwendungskern
Codeblöcke, die Tools mit dem Anwendungskern verbinden, werden als Adapter (
Ports & Adapter-Architektur ) bezeichnet. Sie ermöglichen es der Geschäftslogik, mit einem bestimmten Tool zu interagieren und umgekehrt.
Adapter, die die Anwendung anweisen, etwas zu tun, werden als
Primär- oder Steueradapter bezeichnet , während Adapter, die die Anwendung anweisen, etwas zu tun, als
sekundäre oder verwaltete Adapter bezeichnet werden .
Ports
Diese
Adapter werden jedoch nicht zufällig erstellt, sondern entsprechen einem bestimmten Einstiegspunkt im
Port des Anwendungskerns. Ein Port ist
nichts anderes als eine Spezifikation, wie das Tool den Anwendungskern verwenden kann oder umgekehrt. In den meisten Sprachen und in seiner einfachsten Form wird dieser Port eine Schnittstelle sein, aber tatsächlich kann er aus mehreren Schnittstellen und DTO bestehen.
Es ist wichtig zu beachten, dass sich
Ports (Schnittstellen) innerhalb der Geschäftslogik und Adapter außerhalb befinden. Damit diese Vorlage ordnungsgemäß funktioniert, ist es äußerst wichtig, Ports entsprechend den Anforderungen des Anwendungskerns zu erstellen und nicht nur die Tool-APIs nachzuahmen.
Primär- oder Steueradapter
Primär- oder Steueradapter
wickeln sich um einen Port und teilen dem Anwendungskern mit, was zu tun ist.
Sie wandeln alle Daten aus dem Übermittlungsmechanismus in Methodenaufrufe im Anwendungskern um.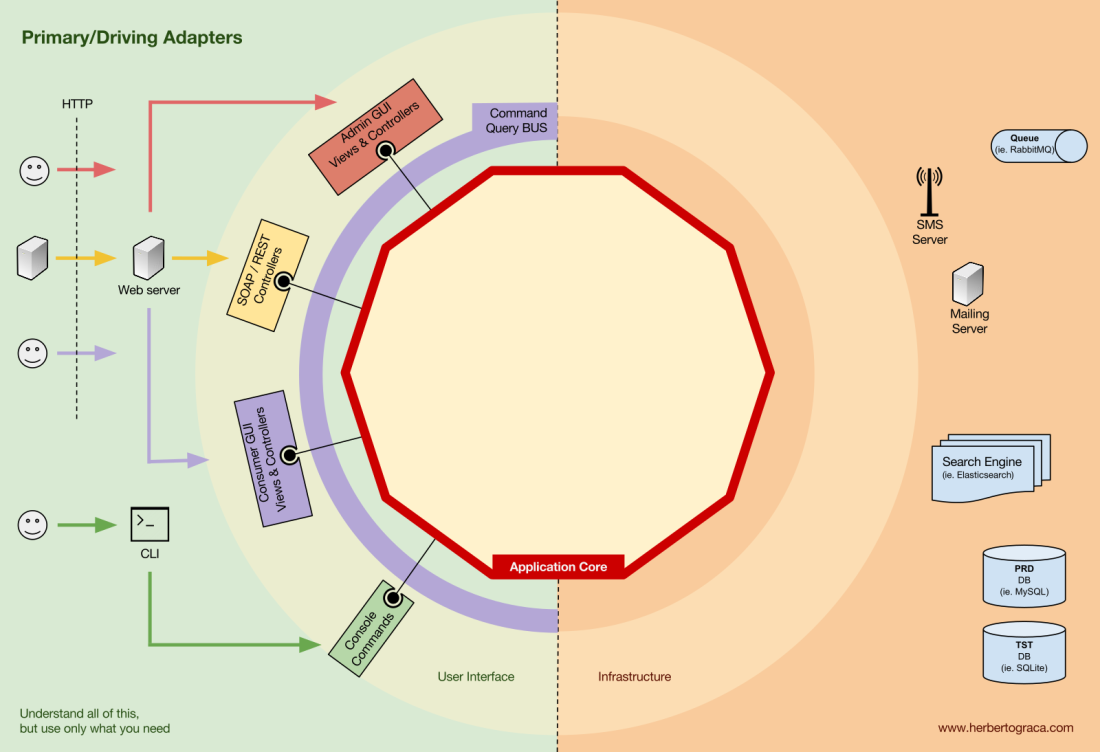
Mit anderen Worten, unsere Steuerungsadapter sind Controller oder Konsolenbefehle. Sie sind in ihren Konstruktor mit einem Objekt eingebettet, dessen Klasse die Schnittstelle (Port) implementiert, die ein Controller- oder Konsolenbefehl benötigt.
In einem spezifischeren Beispiel kann der Port die Dienstschnittstelle oder die Repository-Schnittstelle sein, die der Controller benötigt. Eine bestimmte Implementierung eines Dienstes, Repositorys oder einer Anforderung wird dann implementiert und in der Steuerung verwendet.
Darüber hinaus kann der Port ein Befehlsbus oder eine Abfragebusschnittstelle sein. In diesem Fall wird eine bestimmte Implementierung des Befehls- oder Anforderungsbusses in die Steuerung eingegeben, die dann einen Befehl oder eine Anforderung erstellt und an den entsprechenden Bus weiterleitet.
Sekundäre oder verwaltete Adapter
Im Gegensatz zu Steueradaptern, die einen Port
umschließen, implementieren
verwaltete Adapter einen Port und eine Schnittstelle und geben dann den Anwendungskern ein, in dem der Port benötigt wird (mit Typ).

Zum Beispiel haben wir eine native Anwendung, die Daten speichern muss. Wir erstellen eine Persistenzschnittstelle mit einer Methode zum
Speichern eines Datenarrays und einer Methode zum
Löschen einer Zeile in einer Tabelle anhand ihrer ID. Von nun an benötigen wir im Konstruktor überall dort, wo die Anwendung Daten speichern oder löschen muss, ein Objekt, das die von uns definierte Persistenzschnittstelle implementiert.
Erstellen Sie nun einen MySQL-spezifischen Adapter, der diese Schnittstelle implementiert. Es wird Methoden zum Speichern des Arrays und zum Löschen der Zeile in der Tabelle geben, und wir werden es überall dort einführen, wo die Persistenzschnittstelle erforderlich ist.
Wenn wir uns irgendwann dazu entschließen, den Datenbankanbieter beispielsweise auf PostgreSQL oder MongoDB zu ändern, müssen wir nur einen neuen Adapter erstellen, der die für PostgreSQL spezifische Persistenzschnittstelle implementiert, und anstelle des alten einen neuen Adapter einführen.
Kontrollinversion
Ein charakteristisches Merkmal dieser Vorlage ist, dass die Adapter von einem bestimmten Tool und einem bestimmten Port abhängen (durch Implementierung einer Schnittstelle). Unsere Geschäftslogik hängt jedoch nur vom Port (Schnittstelle) ab, der den Anforderungen der Geschäftslogik entspricht und nicht von einem bestimmten Adapter oder Tool abhängt.
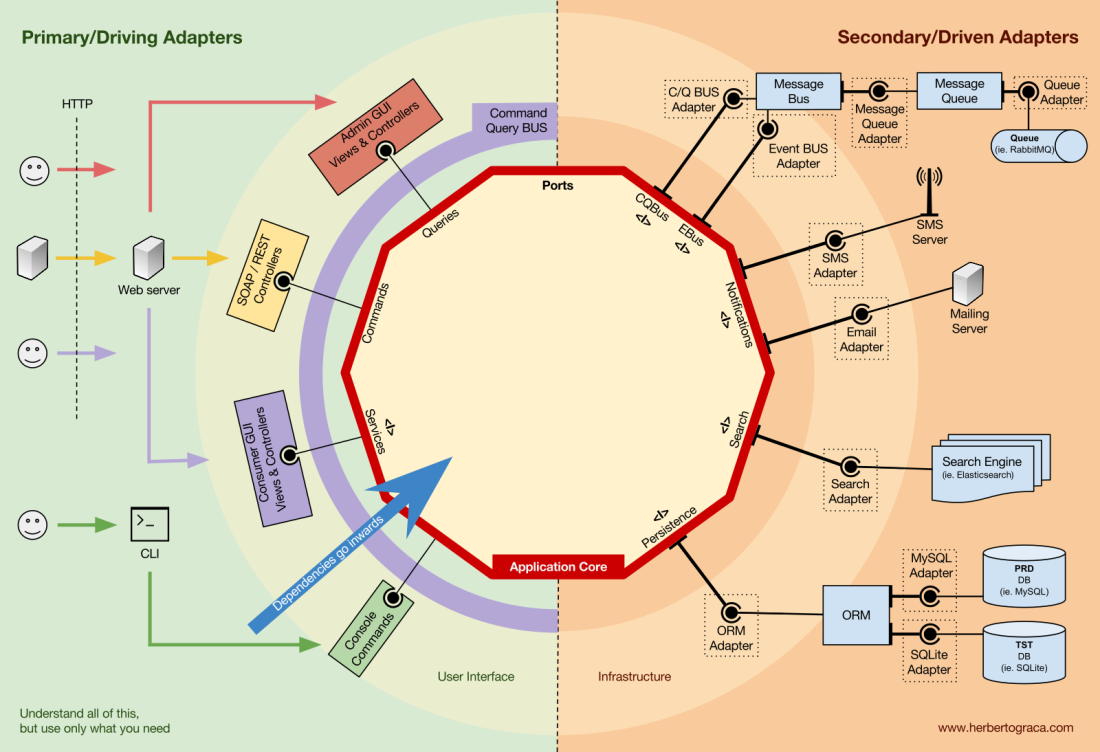
Dies bedeutet, dass die Abhängigkeiten auf das Zentrum gerichtet sind, dh es gibt eine
Umkehrung des Steuerprinzips auf architektonischer Ebene .
Auch hier ist
es unbedingt erforderlich, dass die Ports gemäß den Anforderungen des Anwendungskerns erstellt werden und nicht nur die Tool-APIs nachahmen .
Organisation des Anwendungskerns
Die Onion-Architektur nimmt die DDD-Schichten auf und integriert sie in die
Port- und Adapterarchitektur . Diese Ebenen sollen der Geschäftslogik, dem Inneren des „Sechsecks“ von Ports und Adaptern, Ordnung verleihen. Nach wie vor ist die Richtung der Abhängigkeiten zur Mitte gerichtet.
Anwendungsschicht (Anwendungsschicht)
Anwendungsfälle sind Prozesse, die über eine oder mehrere Benutzeroberflächen im Kernel gestartet werden können. Beispielsweise kann ein CMS eine Benutzeroberfläche für reguläre Benutzer, eine andere unabhängige Benutzeroberfläche für CMS-Administratoren, eine andere CLI und eine Web-API haben. Diese Benutzeroberflächen (Anwendungen) können eindeutige oder häufige Anwendungsfälle auslösen.
Anwendungsfälle werden auf Anwendungsebene definiert - der ersten Ebene von DDD und der Onion-Architektur.
Diese Schicht enthält Anwendungsdienste (und ihre Schnittstellen) als erstklassige Objekte sowie Port- und Adapterschnittstellen (Ports), einschließlich ORM-Schnittstellen, Suchmaschinenschnittstellen, Messaging-Schnittstellen usw. In dem Fall, in dem wir sie verwenden Der Befehlsbus und / oder der Anforderungsbus sind auf dieser Ebene die entsprechenden Befehls- und Anforderungshandler.
Anwendungsdienste und / oder Befehlshandler enthalten die Bereitstellungslogik eines Anwendungsfalls, eines Geschäftsprozesses. Ihre Rolle ist in der Regel wie folgt:
- Verwenden Sie das Repository, um nach einer oder mehreren Entitäten zu suchen.
- Bitten Sie diese Entitäten, eine Domänenlogik auszuführen.
- Verwenden Sie den Speicher, um Entitäten erneut zu speichern und Datenänderungen effektiv zu speichern.
Befehlshandler können auf zwei Arten verwendet werden:
- Sie können Logik zum Ausführen eines Anwendungsfalls enthalten.
- Sie können als einfache Teile einer Verbindung in unserer Architektur verwendet werden, die einen Befehl erhalten und einfach die im Anwendungsdienst vorhandene Logik aufrufen.
Welcher Ansatz verwendet werden soll, hängt vom Kontext ab, zum Beispiel:
- Wir haben bereits Anwendungsdienste und jetzt wird der Befehlsbus hinzugefügt?
- Können Sie mit dem Befehlsbus eine Klasse / Methode als Handler angeben oder müssen Sie vorhandene Klassen oder Schnittstellen erweitern oder implementieren?
Diese Ebene enthält auch auslösende
Anwendungsereignisse , die ein Ergebnis eines Anwendungsfalls darstellen. Diese Ereignisse lösen eine Logik aus, die ein Nebeneffekt eines Anwendungsfalls ist, z. B. das Senden von E-Mails, das Benachrichtigen einer Drittanbieter-API, das Senden einer Push-Benachrichtigung oder sogar das Starten eines anderen Anwendungsfalls, der zu einer anderen Komponente der Anwendung gehört.
Domänenebene
Weiter innen gibt es eine Domain-Ebene. Objekte auf dieser Ebene enthalten Daten und Logik zum Verwalten dieser Daten, die für die Domäne selbst spezifisch und unabhängig von den Geschäftsprozessen sind, die diese Logik auslösen. Sie sind unabhängig und kennen die Anwendungsebene überhaupt nicht.
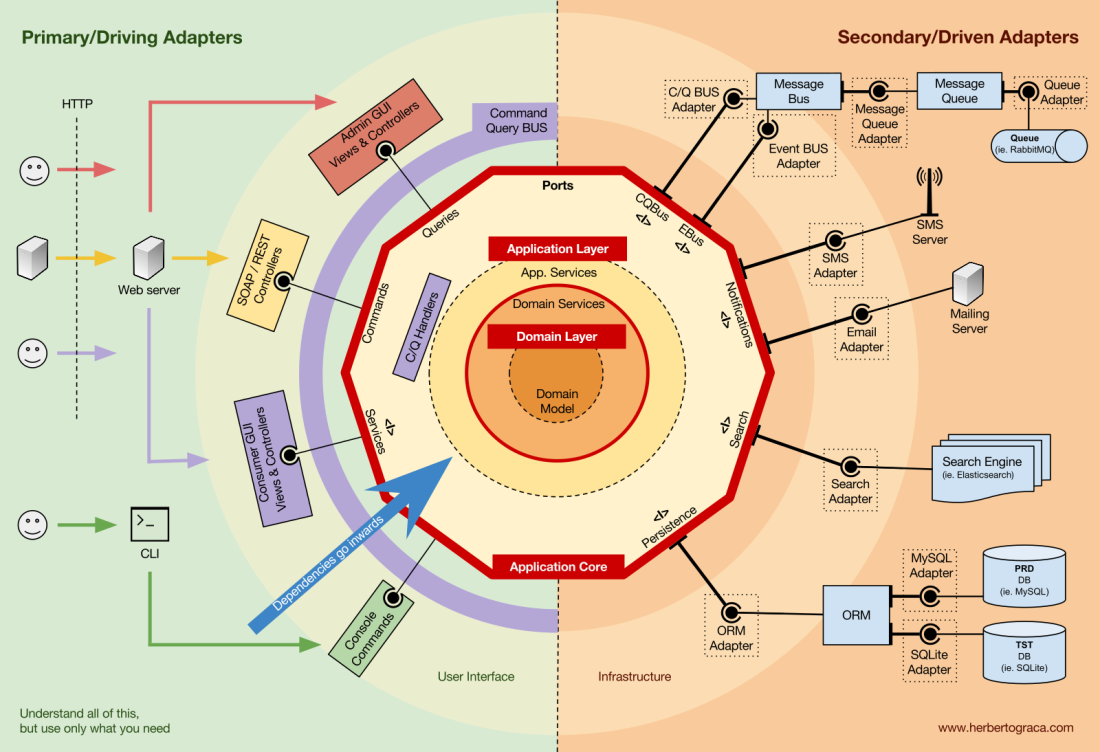
Domänendienste
Wie oben erwähnt, ist die Rolle des Anwendungsdienstes:
- Verwenden Sie das Repository, um nach einer oder mehreren Entitäten zu suchen.
- Bitten Sie diese Entitäten, eine Domänenlogik auszuführen.
- Verwenden Sie den Speicher, um Entitäten erneut zu speichern und Datenänderungen effektiv zu speichern.
Manchmal stoßen wir jedoch auf eine Domänenlogik, die verschiedene Entitäten desselben oder unterschiedlichen Typs umfasst, und diese Domänenlogik gehört nicht zu den Entitäten selbst, dh die Logik liegt nicht in ihrer direkten Verantwortung.
Daher besteht unsere erste Reaktion möglicherweise darin, diese Logik außerhalb der Entitäten im Anwendungsdienst zu platzieren. Dies bedeutet jedoch, dass in anderen Fällen die Domänenlogik nicht wiederverwendet wird: Die Domänenlogik muss außerhalb der Anwendungsebene bleiben!
Die Lösung besteht darin, einen Domänendienst zu erstellen, dessen Aufgabe darin besteht, eine Reihe von Entitäten abzurufen und eine Geschäftslogik darauf auszuführen. Ein Domänendienst gehört zu einer Domänenebene und weiß daher nichts über Klassen auf Anwendungsebene, wie z. B. Anwendungsdienste oder Repositorys. Andererseits kann es andere Domänendienste und natürlich Domänenmodellobjekte verwenden.
Domänenmodell
Im Zentrum steht das Domain-Modell. Es hängt von nichts außerhalb dieses Kreises ab und enthält Geschäftsobjekte, die etwas in der Domäne darstellen. Beispiele für solche Objekte sind in erster Linie Entitäten sowie Wertobjekte, Aufzählungen und alle im Domänenmodell verwendeten Objekte.
Domänenereignisse werden auch im Domänenmodell gespeichert. Wenn sich ein bestimmter Datensatz ändert, werden diese Ereignisse ausgelöst, die neue Werte der geänderten Eigenschaften enthalten. Diese Ereignisse sind beispielsweise ideal für die Verwendung im Event-Sourcing-Modul.
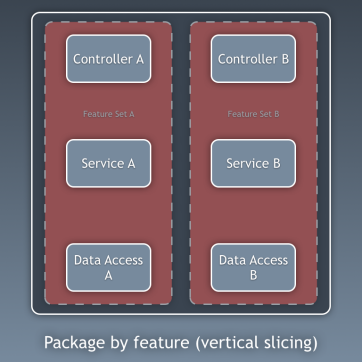
Komponenten
Bisher haben wir Code in Schichten isoliert, aber dies ist eine zu detaillierte Code-Isolierung. Ebenso wichtig ist es, das Bild allgemeiner zu betrachten. Wir sprechen über die Aufteilung des Codes in Subdomänen und
verwandte Kontexte gemäß den Ideen von Robert Martin, die in
schreiender Architektur ausgedrückt werden [das heißt, die Architektur sollte über die Anwendung selbst "schreien" und nicht darüber, welche Frameworks sie verwendet - ca. trans.]. Sie sprechen über das Organisieren von Paketen nach Funktion oder Komponente, nicht nach Ebene, und Simon Brown hat dies in seinem Artikel
„Komponentenpakete und Testen gemäß Architektur“ in seinem Blog recht gut erklärt:
Ich bin ein Befürworter der Organisation von Komponentenpaketen und möchte das Diagramm von Simon Brown schamlos wie folgt ändern:
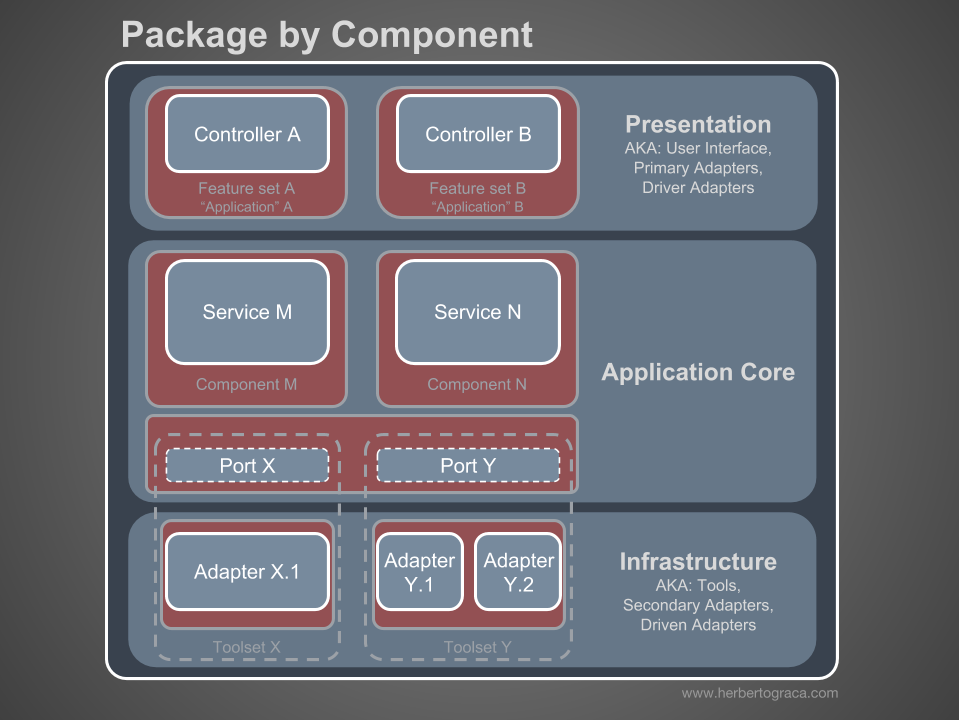
Diese Abschnitte des Codes sind für alle zuvor beschriebenen Ebenen übergreifend, und dies sind die
Komponenten unserer Anwendung. Beispiele für Komponenten sind Abrechnung, Benutzer, Überprüfung oder Konto, sie sind jedoch immer einer Domäne zugeordnet. Eingeschränkte Kontexte wie Autorisierung und / oder Authentifizierung sollten als externe Tools betrachtet werden, für die wir einen Adapter erstellen und uns hinter einem Port verstecken.
Komponententrennung
Genau wie bei feinkörnigen Codeeinheiten (Klassen, Schnittstellen, Eigenschaften, Mixins usw.) profitieren große Einheiten (Komponenten) von einer schwachen Kopplung und einer engen Konnektivität.
Um Klassen zu trennen, verwenden wir die Abhängigkeitsinjektion, führen Abhängigkeiten in die Klasse ein, anstatt sie innerhalb der Klasse zu erstellen, und invertieren die Abhängigkeiten, wodurch die Klasse von Abstraktionen (Schnittstellen und / oder abstrakten Klassen) anstelle bestimmter Klassen abhängig wird. Dies bedeutet, dass die abhängige Klasse nichts über die spezifische Klasse weiß, die sie verwenden wird, und keinen Verweis auf den vollständigen Namen der Klassen hat, von denen sie abhängt.
In ähnlicher Weise weiß bei vollständig getrennten Komponenten jede Komponente nichts über eine andere Komponente. Mit anderen Worten, es gibt keine Verknüpfung zu einem feinkörnigen Codeblock einer anderen Komponente, auch nicht zur Schnittstelle! Dies bedeutet, dass Abhängigkeitsinjektion und Abhängigkeitsinversion nicht ausreichen, um Komponenten zu trennen. Wir benötigen eine Art Architekturkonstruktion. Ereignisse, ein gemeinsamer Kern, eventuelle Konsistenz und sogar ein Erkennungsdienst können erforderlich sein!
Auslöselogik in anderen Komponenten
Wenn eine unserer Komponenten (Komponente B) etwas tun muss, wenn in einer anderen Komponente (Komponente A) etwas anderes passiert, können wir nicht einfach einen direkten Aufruf von Komponente A an die Klasse / Methode von Komponente B durchführen, weil dann wird A mit B verbunden.
Wir können jedoch den Ereignismanager verwenden, um das Anwendungsereignis auszulösen, das an alle Komponenten gesendet wird, die es abhören, einschließlich B, und der Ereignis-Listener in B löst die gewünschte Aktion aus. Dies bedeutet, dass Komponente A vom Ereignismanager abhängt, jedoch von Komponente B getrennt ist.
Wenn das Ereignis selbst in A "lebt", bedeutet dies, dass B über die Existenz von A Bescheid weiß und damit verbunden ist. Um diese Abhängigkeit zu beseitigen, können wir eine Bibliothek mit einer Reihe von Funktionen des Anwendungskerns erstellen, die von allen Komponenten
gemeinsam genutzt werden - einem
gemeinsamen Kern . Dies bedeutet, dass beide Komponenten vom gemeinsamen Kern abhängen, aber voneinander getrennt sind. Ein gemeinsamer Kern enthält Funktionen wie Anwendungs- und Domänenereignisse, kann jedoch auch Spezifikationsobjekte und alles enthalten, was für die Freigabe sinnvoll ist. Gleichzeitig sollte es eine Mindestgröße haben, da sich alle Änderungen im gemeinsamen Kernel auf alle Anwendungskomponenten auswirken. Wenn wir ein polyglottes System haben, beispielsweise ein Ökosystem von Mikrodiensten in verschiedenen Sprachen, sollte der gemeinsame Kern nicht von der Sprache abhängen, damit alle Komponenten ihn verstehen. Anstelle eines gemeinsamen Kernels mit einer Ereignisklasse enthält er beispielsweise eine Beschreibung des Ereignisses (dh einen Namen, Eigenschaften, möglicherweise sogar Methoden, obwohl sie im Spezifikationsobjekt nützlicher wären) in einer universellen Sprache wie JSON, damit alle Komponenten / Mikrodienste es interpretieren können und vielleicht sogar automatisch ihre eigenen spezifischen Implementierungen generieren.
Dieser Ansatz funktioniert sowohl in monolithischen als auch in verteilten Anwendungen wie Mikroservice-Ökosystemen. Wenn Ereignisse jedoch nur asynchron übermittelt werden können, reicht dieser Ansatz nicht für Kontexte aus, in denen die Triggerlogik in anderen Komponenten sofort funktionieren sollte! Hier muss Komponente A einen direkten HTTP-Aufruf an Komponente B durchführen. In diesem Fall benötigen wir einen Erkennungsdienst, um die Komponenten zu trennen. Komponente A fragt sie, wohin sie die Anforderung senden soll, um die gewünschte Aktion einzuleiten. Alternativ können Sie eine Anforderung an den Erkennungsdienst senden, der diese an den entsprechenden Dienst weiterleitet und schließlich eine Antwort an den Anforderer zurückgibt.
Dieser Ansatz ordnet Komponenten einem Erkennungsdienst zu, ordnet sie jedoch nicht miteinander zu.Daten von anderen Komponenten abrufen
Aus meiner Sicht darf die Komponente keine Daten ändern, die sie nicht „besitzt“, kann jedoch Daten anfordern und verwenden.Gemeinsamer Datenspeicher für Komponenten
Wenn die Komponente Daten verwenden muss, die zu einer anderen Komponente gehören (z. B. muss die Abrechnungskomponente den Namen des Kunden verwenden, der zur Kontenkomponente gehört), enthält sie das Anforderungsobjekt für den Datenspeicher. Das heißt, die Abrechnungskomponente kann über jeden Datensatz Bescheid wissen, muss jedoch schreibgeschützte Daten aus anderen Ländern verwenden.Separate Datenspeicherung für die Komponente
In diesem Fall wird dieselbe Vorlage angewendet, die Datenspeicherebene wird jedoch komplizierter. Das Vorhandensein von Komponenten mit einem eigenen Data Warehouse bedeutet, dass jedes Data Warehouse Folgendes enthält:- Ein Datensatz, den eine Komponente besitzt und ändern kann, wodurch sie zur einzigen Quelle der Wahrheit wird.
- Ein Dataset, das eine Kopie der Daten anderer Komponenten ist, die nicht selbst geändert werden können, die jedoch für die Funktionalität der Komponente erforderlich sind. Diese Daten sollten aktualisiert werden, wenn sie sich in der Eigentümerkomponente ändern.
Jede Komponente erstellt eine lokale Kopie der benötigten Daten von anderen Komponenten, die bei Bedarf verwendet werden. Wenn sich Daten in der Komponente ändern, zu der sie gehören, löst diese Eigentümerkomponente ein Domänenereignis aus, das Datenänderungen enthält. Komponenten, die eine Kopie dieser Daten enthalten, hören dieses Domänenereignis ab und aktualisieren ihre lokale Kopie entsprechend.Kontrollfluss
Wie oben erwähnt, geht der Kontrollfluss vom Benutzer zum Anwendungskern, zu den Infrastruktur-Tools und dann wieder zum Anwendungskern - und zurück zum Benutzer. Aber wie genau arbeiten die Klassen zusammen? Wer hängt von wem ab? Wie komponieren wir sie?Wie Onkel Bob werde ich in meinem Artikel über saubere Architektur versuchen, den Ablauf der UMLish-Schemaverwaltung zu erklären ...Ohne Befehls- / Anforderungsbus
Wenn wir den Befehlsbus nicht verwenden, hängen die Controller entweder vom Anwendungsdienst oder vom Abfrageobjekt ab.[Nachtrag 18.11.2017] Ich habe das DTO, mit dem ich Daten aus der Anfrage zurückgebe, vollständig übersprungen und es jetzt hinzugefügt. Dank MorphineAdministered , das ein Leerzeichen anzeigte . In der obigen Abbildung verwenden wir die Schnittstelle für den Anwendungsdienst, obwohl wir sagen können, dass sie nicht wirklich benötigt wird, da der Anwendungsdienst Teil unseres Anwendungscodes ist. Wir wollen die Implementierung jedoch nicht ändern, obwohl wir ein vollständiges Refactoring durchführen können. Das Abfrageobjekt enthält eine optimierte Abfrage, die einfach einige Rohdaten zurückgibt, die dem Benutzer angezeigt werden. Diese Daten werden an das DTO zurückgegeben, das in das ViewModel eingebettet ist. Dieses ViewModel verfügt möglicherweise über eine Ansichtslogik und wird zum Auffüllen der Ansicht verwendet.Auf der anderen Seite enthält der Anwendungsdienst eine Anwendungsfalllogik, die ausgelöst wird, wenn wir etwas auf dem System tun und nicht nur einige Daten anzeigen möchten. Der Anwendungsdienst hängt von Repositorys ab, die Entitäten zurückgeben, die die zu initiierende Logik enthalten. Es kann auch vom Domänendienst abhängen, den Domänenprozess über mehrere Entitäten hinweg zu koordinieren. Dies ist jedoch ein seltener Fall.Nach dem Parsen des Anwendungsfalls kann der Anwendungsdienst das gesamte System benachrichtigen, dass ein Anwendungsfall aufgetreten ist. Anschließend hängt es vom Ereignis-Dispatcher ab, das Ereignis auszulösen.Es ist interessant festzustellen, dass wir Schnittstellen sowohl auf der Persistenz-Engine als auch auf Repositorys hosten. Dies mag überflüssig erscheinen, dient jedoch unterschiedlichen Zwecken:
Das Abfrageobjekt enthält eine optimierte Abfrage, die einfach einige Rohdaten zurückgibt, die dem Benutzer angezeigt werden. Diese Daten werden an das DTO zurückgegeben, das in das ViewModel eingebettet ist. Dieses ViewModel verfügt möglicherweise über eine Ansichtslogik und wird zum Auffüllen der Ansicht verwendet.Auf der anderen Seite enthält der Anwendungsdienst eine Anwendungsfalllogik, die ausgelöst wird, wenn wir etwas auf dem System tun und nicht nur einige Daten anzeigen möchten. Der Anwendungsdienst hängt von Repositorys ab, die Entitäten zurückgeben, die die zu initiierende Logik enthalten. Es kann auch vom Domänendienst abhängen, den Domänenprozess über mehrere Entitäten hinweg zu koordinieren. Dies ist jedoch ein seltener Fall.Nach dem Parsen des Anwendungsfalls kann der Anwendungsdienst das gesamte System benachrichtigen, dass ein Anwendungsfall aufgetreten ist. Anschließend hängt es vom Ereignis-Dispatcher ab, das Ereignis auszulösen.Es ist interessant festzustellen, dass wir Schnittstellen sowohl auf der Persistenz-Engine als auch auf Repositorys hosten. Dies mag überflüssig erscheinen, dient jedoch unterschiedlichen Zwecken:- Die Persistenzschnittstelle ist eine Abstraktionsschicht über ORM, sodass wir ORM austauschen können, ohne den Anwendungskern zu ändern.
- persistence-. , MySQL MongoDB. persistence- , ORM, . , , , , , , MongoDB SQL.
C /
Wenn unsere Anwendung den Befehls- / Anforderungsbus verwendet, bleibt das Diagramm nahezu unverändert, außer dass die Steuerung jetzt vom Bus sowie von Befehlen oder Anforderungen abhängt. Hier wird eine Instanz eines Befehls oder einer Anforderung erstellt und an den Bus übergeben, der den geeigneten Handler zum Empfangen und Verarbeiten des Befehls findet.In der folgenden Abbildung verwendet der Befehlshandler den Anwendungsdienst. Dies ist jedoch nicht immer erforderlich, da der Handler in den meisten Fällen die gesamte Logik des Anwendungsfalls enthält. Alles, was wir tun müssen, ist, die Logik aus dem Handler in einen separaten Anwendungsdienst zu extrahieren, wenn wir dieselbe Logik in einem anderen Handler wiederverwenden müssen.[Nachtrag 18.11.2017] Ich habe das DTO, mit dem ich Daten aus der Anfrage zurückgebe, vollständig übersprungen und es jetzt hinzugefügt. Vielen DankMorphineAdministered , das ein Leerzeichen anzeigt . Möglicherweise haben Sie bemerkt, dass es keine Abhängigkeiten zwischen Bus, Befehl, Anforderung und Handlern gibt. Tatsächlich müssen sie nicht voneinander wissen, um eine gute Trennung zu gewährleisten. Das Verfahren zum Weiterleiten des Busses an einen bestimmten Handler zum Verarbeiten eines Befehls oder einer Anforderung wird in einer einfachen Konfiguration konfiguriert. In beiden Fällen zeigen alle Pfeile - Abhängigkeiten, die die Kernelgrenze der Anwendung überschreiten - nach innen. Wie bereits erläutert, ist dies die Grundregel der Ports & Adapter-, Zwiebel- und Clean-Architektur.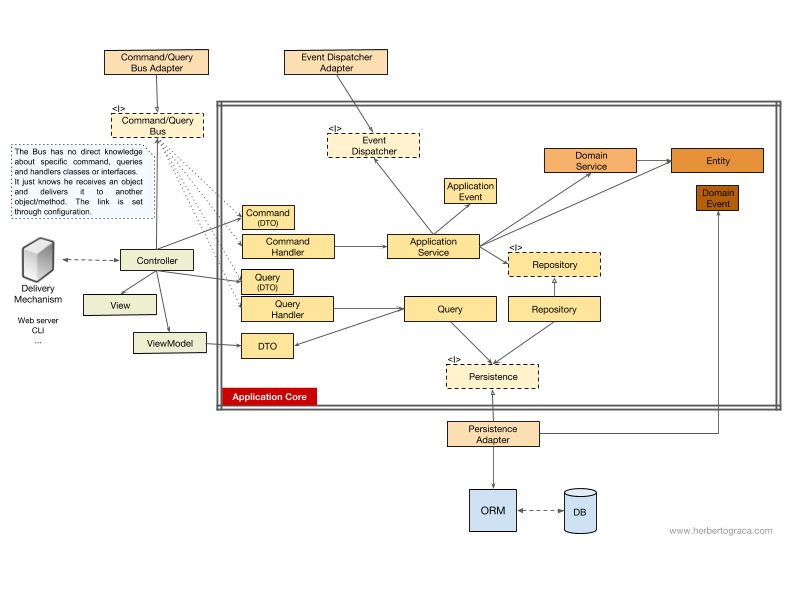

Fazit
Wie immer besteht das Ziel darin, eine getrennte Codebasis mit hoher Konnektivität zu erhalten, in der Sie einfach, schnell und sicher Änderungen vornehmen können.Pläne sind nutzlos, aber Planung ist alles. - Eisenhower
Diese Infografik ist eine Konzeptkarte. Wenn Sie all diese Konzepte kennen und verstehen, können Sie eine gesunde Architektur und eine funktionsfähige Anwendung planen.Allerdings:Eine Karte ist kein Gebiet. - Alfred Korzybsky
Mit anderen Worten, dies sind nur Empfehlungen! Eine Anwendung ist ein Gebiet, eine Realität, ein spezifischer Anwendungsfall, in dem wir unser Wissen anwenden müssen, und sie bestimmt, wie die reale Architektur aussehen wird!Wir müssen all diese Muster verstehen, aber auch immer darüber nachdenken und verstehen, was genau unsere Anwendung benötigt und wie weit wir gehen können, um Trennung und Verbundenheit zu erreichen. Diese Entscheidung hängt von vielen Faktoren ab, die von den funktionalen Anforderungen des Projekts über den Zeitpunkt der Anwendungsentwicklung, die Lebensdauer, die Erfahrung des Entwicklungsteams usw. reichen.So stelle ich mir das alles vor.Diese Ideen werden im nächsten Artikel ausführlicher behandelt: „Mehr als nur konzentrische Schichten . “