
Eine so romantische Sache wie ein Sternenhimmel und eine so harte Sache wie die Optimierung des Speicherverbrauchs durch eine iOS-Anwendung können durchaus zusammenpassen: Es lohnt sich, diesen Sternenhimmel in eine AR-Anwendung zu schieben, und die Frage nach dem gleichen Verbrauch wird sich sofort stellen.
In so vielen anderen Fällen ist es nützlich, die Speichernutzung zu minimieren. Dieser Text am Beispiel eines kleinen Projekts zeigt Optimierungsmethoden, die in völlig unterschiedlichen iOS-Anwendungen (und nicht nur in iOS-) nützlich sein können.
Der Beitrag wurde auf der Grundlage einer Abschrift des Berichts von
Conrad Filer von der Piter-Konferenz Mobius 2018 erstellt. Wir fügen das Video und dann eine Textversion in der ersten Person bei:
Freut mich, alle willkommen zu heißen! Mein Name ist Conrad Filer und unter dem spektakulären Namen "Eine Million Sterne in einem iPhone" werden wir diskutieren, wie Sie die Speichergröße Ihrer iOS-Anwendung minimieren können. Bunt und in Beispielen.
Warum optimieren?
Was ermutigt uns generell zur Optimierung, was genau möchten wir erreichen? Das wollen wir nicht:
Wir möchten nicht, dass der Benutzer wartet. Das heißt, der erste Grund ist die
Verkürzung der Startzeit .
Ein weiterer Grund ist
die Verbesserung der Qualität .

Wir können über die Qualität von Bildern, Ton und sogar KI sprechen. "Optimierte KI" bedeutet, dass Sie mehr erreichen können - berechnen Sie beispielsweise das Spiel für eine größere Anzahl von Zügen vorwärts.
Der dritte Grund ist sehr wichtig:
Einsparung von Batteriestrom . Durch die Optimierung wird der Akku weniger entladen. Hier ist ein interessanter Vergleich, wenn auch aus der Android-Welt. Hier verglichen Vulkan und OpenGL ES:

Die zweite ist schlechter für mobile Plattformen optimiert. Wenn Sie die Geschwindigkeit des Batterieverbrauchs beobachten, können Sie feststellen, dass OpenGL ES für ein ähnliches Bild viel mehr Ressourcen verbraucht hat als Vulkan.
Welche Art der Optimierung kann hier helfen? Wenn der Benutzer beispielsweise in einem rundenbasierten Spiel über seinen Zug nachdenkt, können Sie die FPS auf Null reduzieren. Wenn Sie eine 3D-Engine haben, ist es absolut ratsam, einfach alles auszuschalten, während der Benutzer nur auf den Bildschirm schaut.
Darüber hinaus gibt es Zeiten, in denen Sie ohne einen optimierten Ansatz die eine oder andere erweiterte Funktion nicht implementieren können: Sie wird einfach nicht abgerufen.
Kein Fanatismus
Wenn man über Optimierung spricht, kann man sich nur an die These von Donald Knuth erinnern: „Wir sollten beispielsweise in 97% der Fälle die geringe Effizienz vergessen: Vorzeitige Optimierung ist die Wurzel aller Übel. Obwohl wir unsere Fähigkeiten in diesen kritischen 3% nicht aufgeben sollten. "
In 97% der Fälle sollten wir uns nicht um Effizienz kümmern, sondern vor allem darum, wie wir unseren Code verständlich, sicher und testbar machen können. Wir entwickeln immer noch für mobile Geräte und nicht für Raumschiffe. Die Unternehmen, in denen wir arbeiten, sollten nicht zu viel für die Unterstützung des von uns geschriebenen Codes bezahlen. Darüber hinaus ist die Arbeitszeit des Entwicklers mit Kosten verbunden. Wenn Sie sie für die Optimierung von nicht wesentlichen Dingen ausgeben, geben Sie das Geld des Unternehmens aus. Nun, die Tatsache, dass gut optimierter Code schwieriger zu verstehen ist, können Sie anhand der Beispiele sehen, die ich Ihnen heute zeigen werde.
Im Allgemeinen sollten Sie nach Bedarf sinnvoll priorisieren und optimieren.
Die Ansätze
Wenn wir an der Optimierung arbeiten, überwachen wir normalerweise entweder die Leistung (lesen: Prozessorlast) oder die Menge des verwendeten Speichers. Oft stehen diese beiden Optionen in Konflikt, und Sie müssen ein Gleichgewicht zwischen ihnen finden.
Im Fall des Prozessors können wir die Anzahl der Prozessorzyklen reduzieren, die für unsere Operationen erforderlich sind. Wie Sie wissen, sorgen weniger Prozessorzyklen für weniger Ladezeit, weniger Batterieverbrauch, bessere Qualität usw.
Für iOS-Entwickler bietet Xcode Instruments ein praktisches Time Profiler-Tool. Sie können damit die Anzahl der CPU-Zyklen verfolgen, die von verschiedenen Teilen Ihrer Anwendung verbracht wurden. In diesem Bericht geht es nicht um Tools, daher werde ich jetzt nicht auf Details eingehen. Es gab ein gutes Video von WWDC dazu.
Sie können ein anderes Ziel wählen - Optimierung aus Gründen des Gedächtnisses. Wir werden versuchen sicherzustellen, dass unsere Anwendung beim Start in die kleinstmögliche Anzahl von RAM-Zellen passt. Denken Sie daran, dass die umfangreichsten Anwendungen die ersten Kandidaten für ein erzwungenes Herunterfahren beim Reinigen sind, das das Betriebssystem ausführen muss. Dies wirkt sich daher darauf aus, wie lange Ihre Anwendung im Hintergrund bleibt.
Es ist auch wichtig, dass die RAM-Ressource für verschiedene Geräte ebenfalls unterschiedlich ist. Wenn Sie sich beispielsweise für die Entwicklung für die Apple Watch entschieden haben, ist nicht genügend Speicher vorhanden, und Sie können damit auch optimieren.
Schließlich macht manchmal eine kleine Menge an Speicher das Programm auch sehr schnell. Ich werde ein Beispiel geben. Hier sind die Strukturen unterschiedlicher Größe in Bytes:

Element8 enthält 8 Bytes, Element16 - 16 usw.

Wir werden Arrays erstellen, eines für jeden unserer Strukturtypen. Die Dimension aller Arrays ist gleich - 10.000 Elemente. Jede Struktur enthält eine andere Anzahl von Feldern (ansteigend); Feld n ist das erste Feld und ist dementsprechend in allen Strukturen vorhanden.
Versuchen wir nun Folgendes: Für jedes Array berechnen wir die Summe aller seiner Felder n. Das heißt, jedes Mal werden wir die gleiche Anzahl von Elementen (10.000 Stück) summieren. Der einzige Unterschied besteht darin, dass für jede Summe die Variable n aus Strukturen unterschiedlicher Größe extrahiert wird. Uns interessiert, ob die Summierung dieselbe Zeit dauert.
Das Ergebnis ist folgendes:
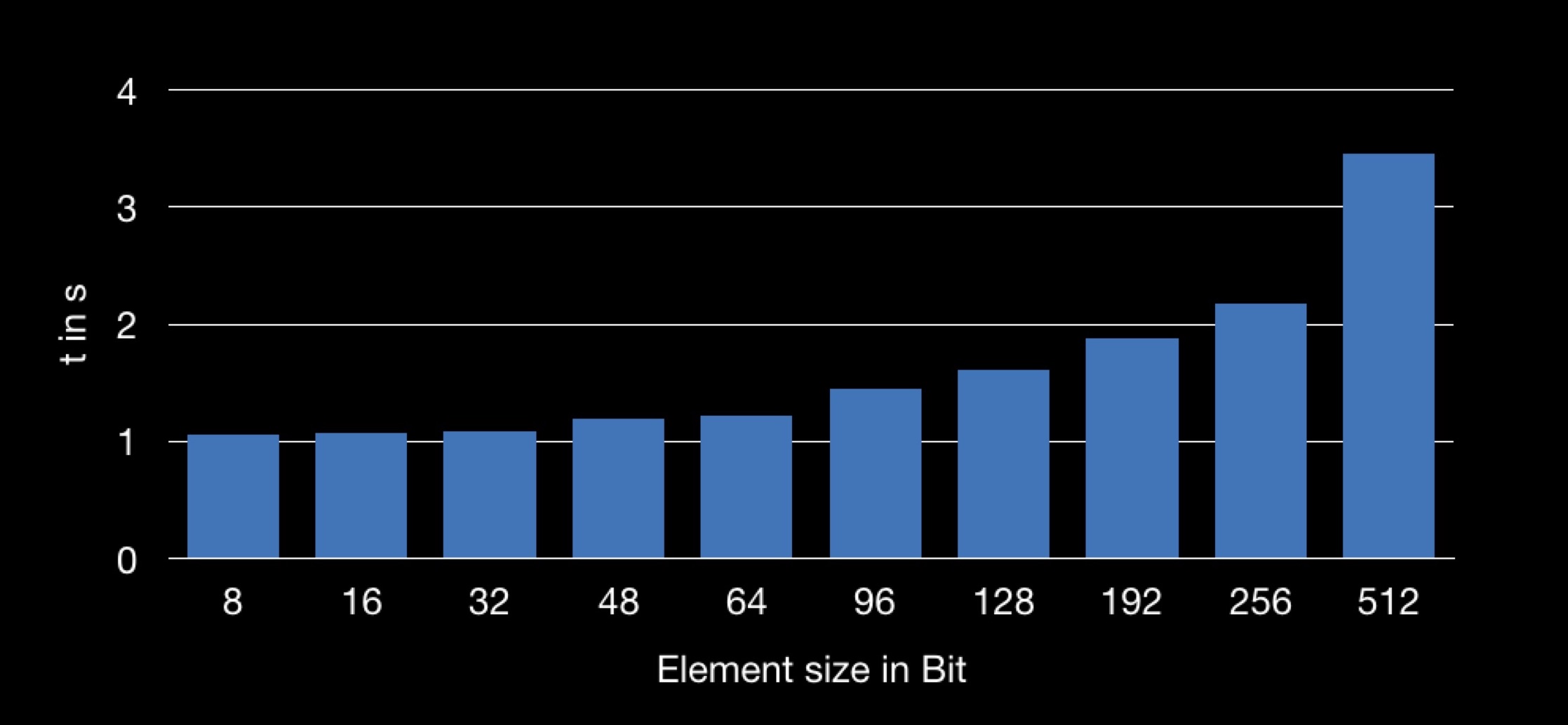
Die Grafik zeigt die Abhängigkeit der Summationszeit von der Größe der im Array verwendeten Struktur. Es stellt sich heraus, dass das Abrufen des Feldes n von einer größeren Struktur länger ist und daher die Summierungsoperation länger dauert.
Viele von Ihnen haben bereits verstanden, warum dies geschieht.
Der Prozessor verfügt über L1-, L2-Caches (manchmal sogar L3 und L4). Der Prozessor greift direkt und schnell auf diese Art von Speicher zu.
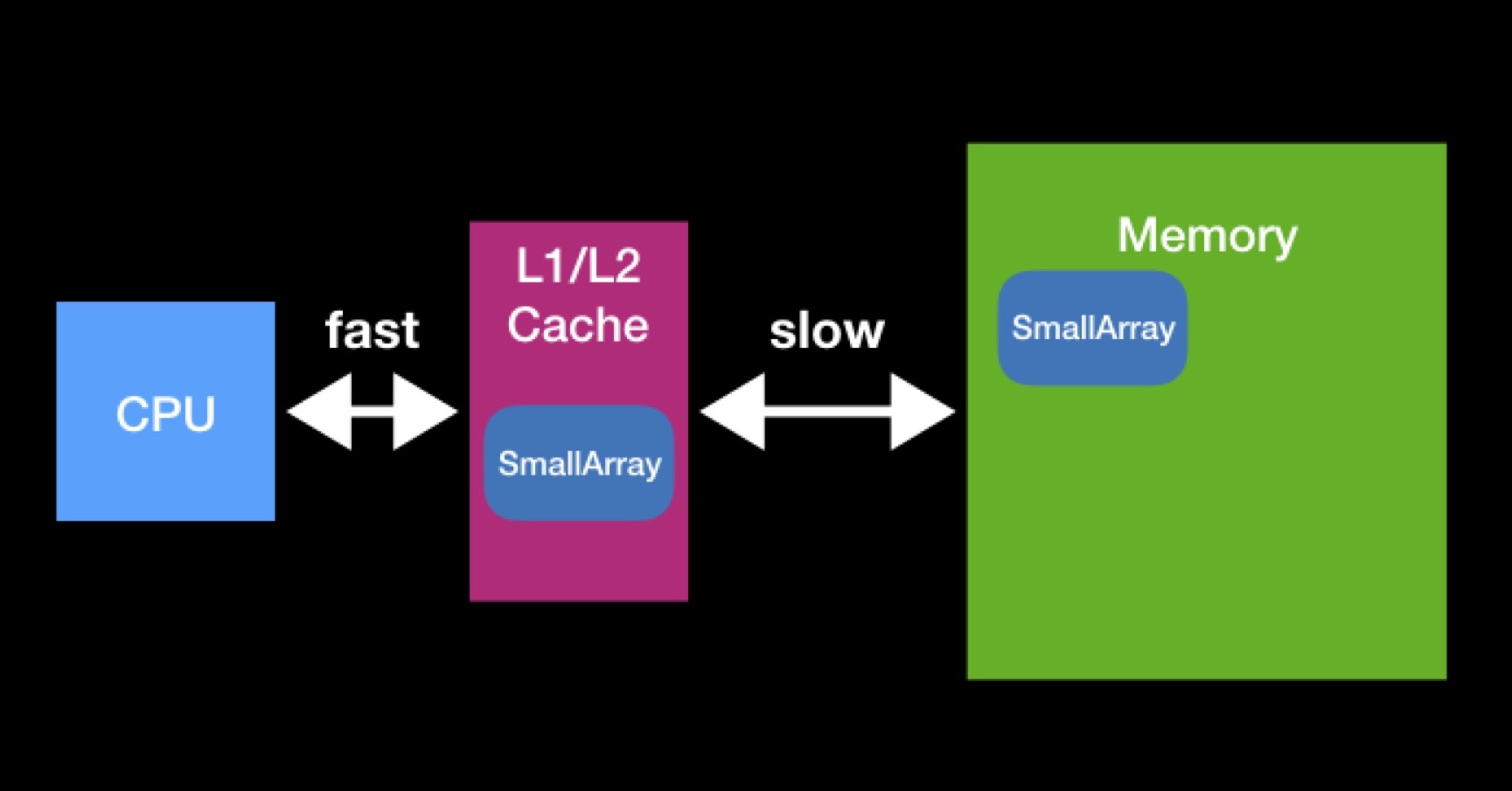
Es gibt Caches, um die Wiederverwendung von Daten zu beschleunigen. Angenommen, wir arbeiten mit Arrays. Wenn das vom Prozessor benötigte Array bereits in einem der Caches vorhanden ist, wurde es vom Prozessor bereits früher benötigt. In diesem Moment forderte er sie aus dem Hauptspeicher an, legte sie in den Cache, führte alle erforderlichen Operationen mit ihnen durch, wonach diese Daten liegen blieben (keine Zeit hatten, von anderen gelöscht zu werden).
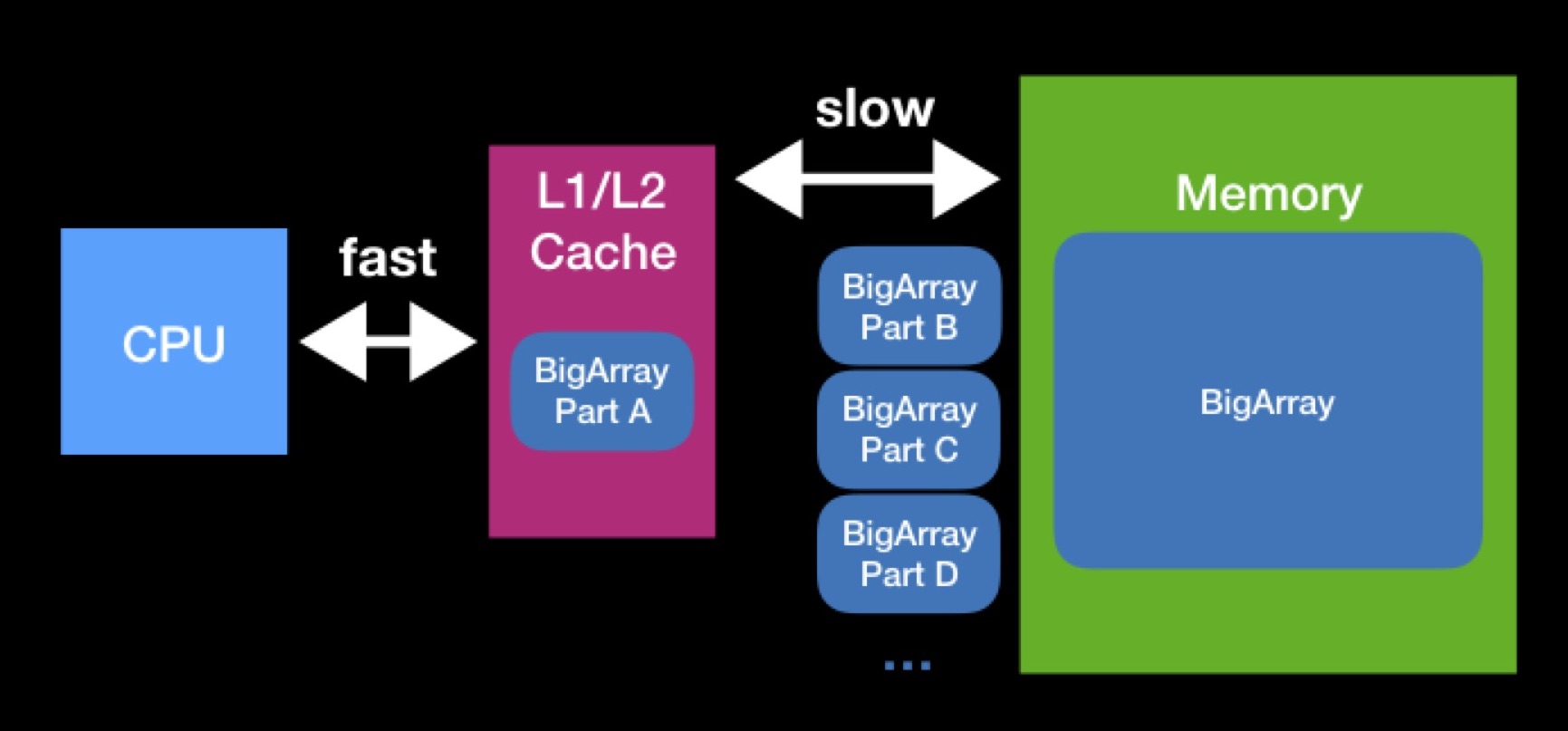
Die Größe der L1-, L2-Caches ist nicht so groß. Das Array, das der Prozessor zum Arbeiten benötigt, kann größer sein. Um die Operation für ein solches Array vollständig auszuführen, müssen wir es in Teilen in den Cache entladen und diese Teile einzeln bearbeiten. Aufgrund ständiger Anforderungen an den Hauptspeicher dauert die Verarbeitung unseres Arrays viel länger.
Versuchen Sie beim Programmieren von Datenstrukturen, die Caches zu berücksichtigen. Es ist möglich, dass Sie durch Reduzieren der Größe Ihrer Datenstruktur die erfolgreiche Cache-Kapazität erreichen und die Operationen beschleunigen, die in Zukunft daran ausgeführt werden. Die Interaktion mit dem Hauptspeicher war, ist und bleibt höchstwahrscheinlich ein wesentlicher Faktor für die Produktivität - selbst wenn Sie für moderne Hochleistungsgeräte auf Swift schreiben.
CPU vs RAM: verzögerte Initialisierung
Obwohl in einigen Fällen, wenn der verwendete Speicher reduziert wird, das Programm schneller zu arbeiten beginnt, gibt es Fälle, in denen diese beiden Metriken im Gegenteil in Konflikt stehen. Ich werde ein Beispiel mit dem Konzept der verzögerten Initialisierung geben.
Angenommen, wir haben eine makeHeavyObject () -Methode, die ein großes Objekt zurückgibt. Diese Methode initialisiert die Variable lazilyCalculated.

Der Modifikator "Lazy" setzt die Variable "LazyCalculated" auf "Lazy Initialization". Dies bedeutet, dass ihm nur dann ein Wert zugewiesen wird, wenn der erste Aufruf während der Ausführung erfolgt. Dann funktioniert die Methode makeHeavyObject () und das resultierende Objekt wird der Variablen lazilyCalculated zugewiesen.
Was ist das Plus hier? Ab dem Moment der Initialisierung (wenn auch später, aber es wird ausgeführt) befindet sich ein Objekt im Speicher. Sein Wert wird gezählt, er ist einsatzbereit - stellen Sie einfach eine Anfrage. Eine andere Sache ist, dass unser Objekt groß ist und ab dem Moment der Initialisierung den Löwenanteil der Zellen im Gedächtnis einnimmt.
Sie können auch in die andere Richtung gehen - speichern Sie den Wert des Feldes überhaupt nicht:

Bei jedem Link zum Feld lazilyCalculated wird die Methode makeHeavyObject () erneut ausgeführt. Der Wert wird an den Abfragepunkt zurückgegeben, während er nicht im Speicher abgelegt wird. Wie Sie sehen können, ist das Speichern einer Variablen optional.
Was ist teurer - ein großes Objekt im Speicher zu speichern, aber keine CPU-Zeit zu verschwenden oder die Methode jedes Mal aufzurufen, wenn wir unser Feld benötigen, während gleichzeitig Speicherplatz gespart wird? Sollten Sie einen vorgefertigten Wert zur Hand haben oder diesen im laufenden Betrieb berechnen? Diese Art von Dilemma tritt häufig auf, wo immer Sie Ihre Berechnungen durchführen - auf einem Remote-Server oder auf Ihrem lokalen Computer, unabhängig davon, mit welchem Cache Sie arbeiten müssen. Sie müssen eine Entscheidung treffen, die auf den Systembeschränkungen in diesem speziellen Fall basiert.
Optimierungszyklus

Was auch immer Sie optimieren, Ihre Arbeit basiert in der Regel auf demselben Algorithmus. Zunächst untersuchen Sie den Code, das Profil / die Kennzahl (in Xcode mit den entsprechenden Tools) und versuchen, die Engpässe zu identifizieren. Ordnen Sie die Methoden im Wesentlichen danach an, wie lange die Ausführung dauert. Schauen Sie sich dann die oberen Zeilen an, um festzustellen, was optimiert werden soll.
Wenn Sie ein Objekt auswählen, stellen Sie sich die Aufgabe (oder stellen wissenschaftlich gesehen eine Hypothese auf): Durch Anwendung dieser oder anderer Optimierungsmethoden können Sie den ausgewählten Code schneller arbeiten lassen.
Als nächstes versuchen Sie zu optimieren. Nach jeder Änderung sehen Sie sich die Leistungsindikatoren an und bewerten, wie effektiv die Änderung war und wie weit Sie vorankommen konnten.
Genau wie in einer wissenschaftlichen Arbeit: Spekulation, Experiment, Analyse der Ergebnisse. Sie durchlaufen diesen Aktionszyklus immer wieder. Die Praxis zeigt, dass die auf diese Weise konstruierte Arbeit es Ihnen wirklich ermöglicht, die Botneks einzeln zu eliminieren.
Unit-Tests

Kurz zu Unit-Tests: Wir haben einige Funktionen, die wir testen, einige Eingabedateneingaben und Ausgabedatenausgaben; Wenn wir als Eingabe Eingaben erhalten, sollte unsere Funktion immer Ausgaben zurückgeben, und keine unserer Optimierungen sollte diese Eigenschaft verletzen.
Unit-Tests helfen uns, die Aufschlüsselung zu verfolgen. Wenn unsere Funktion als Reaktion auf Eingaben keine Ausgabe mehr zurückgibt, haben wir entweder direkt oder indirekt den alten Arbeitsablauf unserer Funktion geändert.
Versuchen Sie nicht einmal, mit der Optimierung zu beginnen, wenn Sie nicht einen großzügigen Teil der Komponententests in Ihren Code geschrieben haben. Sie sollten in der Lage sein, einen Regressionstest durchzuführen. Wenn Sie sich GitHub my Commits in meiner Beispielanwendung ansehen, auf die ich noch eingehen werde, können Sie sehen, dass einige meiner Optimierungen Fehler mit sich gebracht haben.
Und jetzt zum lustigen Teil, gehen wir weiter zu den Sternen.
Millionen Sterne
Es gibt eine große (riesige) Datenbank, die eine Million Sterne beschreibt. Darüber hinaus habe ich mehrere Anwendungen erstellt. Einer von ihnen verwendet Augmented Reality und zeichnet in Echtzeit Sterne von der Kamera des Telefons auf das Bild. Jetzt werde ich es in Aktion demonstrieren:
Ohne Lichter der Stadt kann eine Person bis zu 8.000 Sterne am Himmel unterscheiden. Ich würde ungefähr 1,8 MB benötigen, um 8.000 Datensätze zu speichern. Im Prinzip akzeptabel. Aber ich wollte die Sterne hinzufügen, die eine Person durch ein Teleskop sehen kann - es stellte sich heraus, dass es ungefähr 120.000 Sterne waren (laut dem sogenannten Hipparcos-Katalog, der inzwischen veraltet ist). Dies erforderte bereits 27 MB. Und unter den modernen gemeinfreien Katalogen finden Sie einen mit rund 2.500.000 Sternen. Eine solche Datenbank würde bereits etwa 560 MB belegen. Wie Sie sehen, wird bereits viel Speicher benötigt. Wir wollen aber nicht nur eine Datenbank, sondern eine darauf basierende Anwendung, in der es ARKit, SceneKit und andere Dinge gibt, die ebenfalls Speicher benötigen.
Was tun?
Wir werden die Sterne optimieren.
MemoryLayout-Tool
Sie können die Größe des gesamten Programms bewerten. Für Schmuckarbeiten wie die Optimierung benötigen Sie jedoch Tools zum Schätzen der Größe jeder einzelnen Datenstruktur.
Mit Swift können Sie dies ganz einfach tun - mithilfe von MemoryLayout <> -Objekten. Sie deklarieren ein MemoryLayout <> und geben die für Sie interessante Datenstruktur als generischen Typ an. Unter Bezugnahme auf die Eigenschaften des empfangenen Objekts können Sie nun eine Reihe nützlicher Informationen zu Ihrer Struktur erhalten.

Die size-Eigenschaft gibt die Anzahl der Bytes an, die von einer Instanz der Struktur belegt werden.
Nun zur Schritt-Eigenschaft. Möglicherweise haben Sie bemerkt, dass die Größe des Arrays in der Regel nicht der Summe der Größen seiner Bestandteile entspricht, sondern diese überschreitet. Offensichtlich bleibt etwas „Luft“ zwischen den Elementen im Speicher. Um den Abstand zwischen aufeinanderfolgenden Elementen in einem benachbarten Array abzuschätzen, verwenden wir die Eigenschaft stride. Wenn Sie es mit der Anzahl der Elemente im Array multiplizieren, erhalten Sie seine Größe.
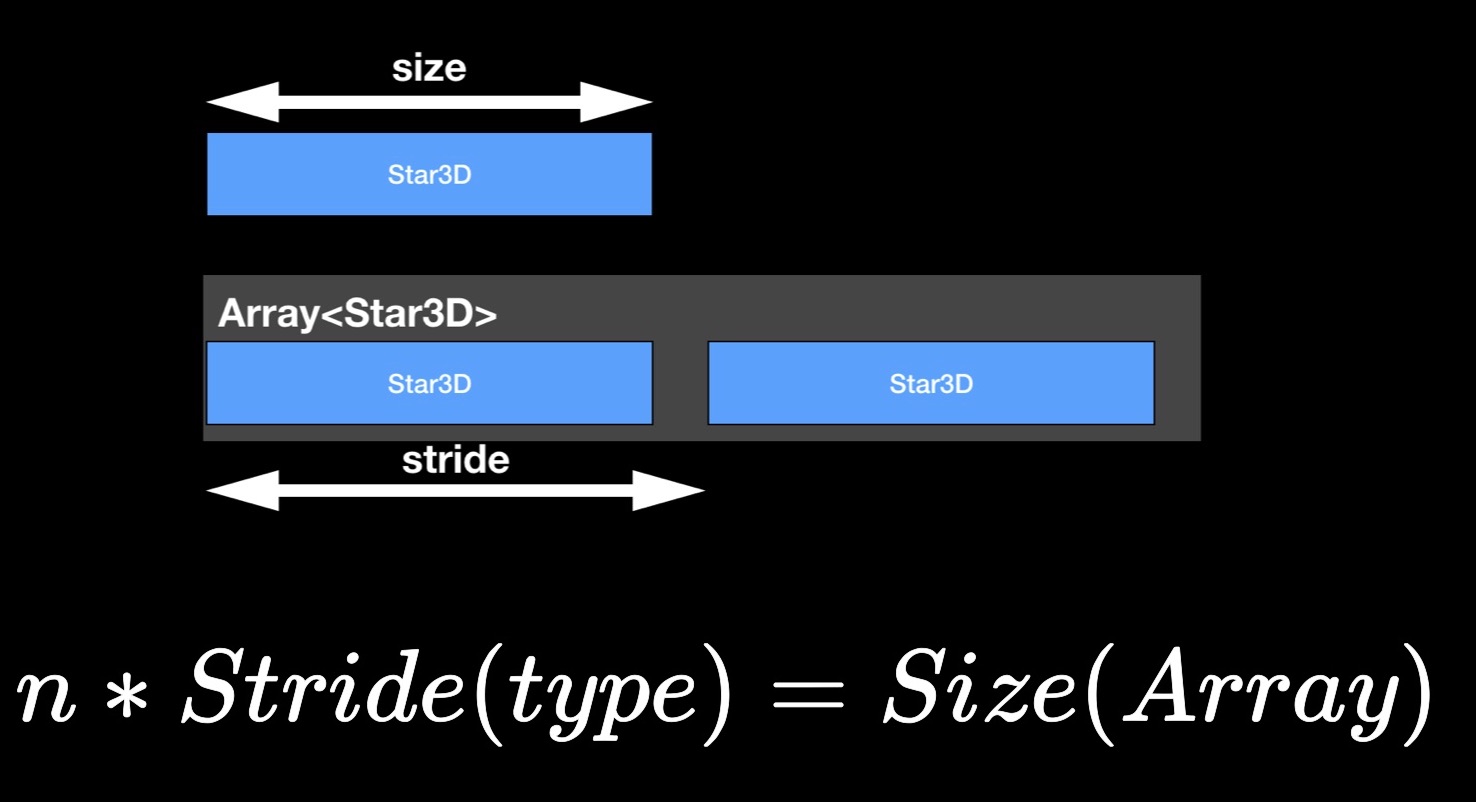
StarData, unsere experimentelle Struktur, in ihrem ursprünglichen, nicht optimierten Zustand:
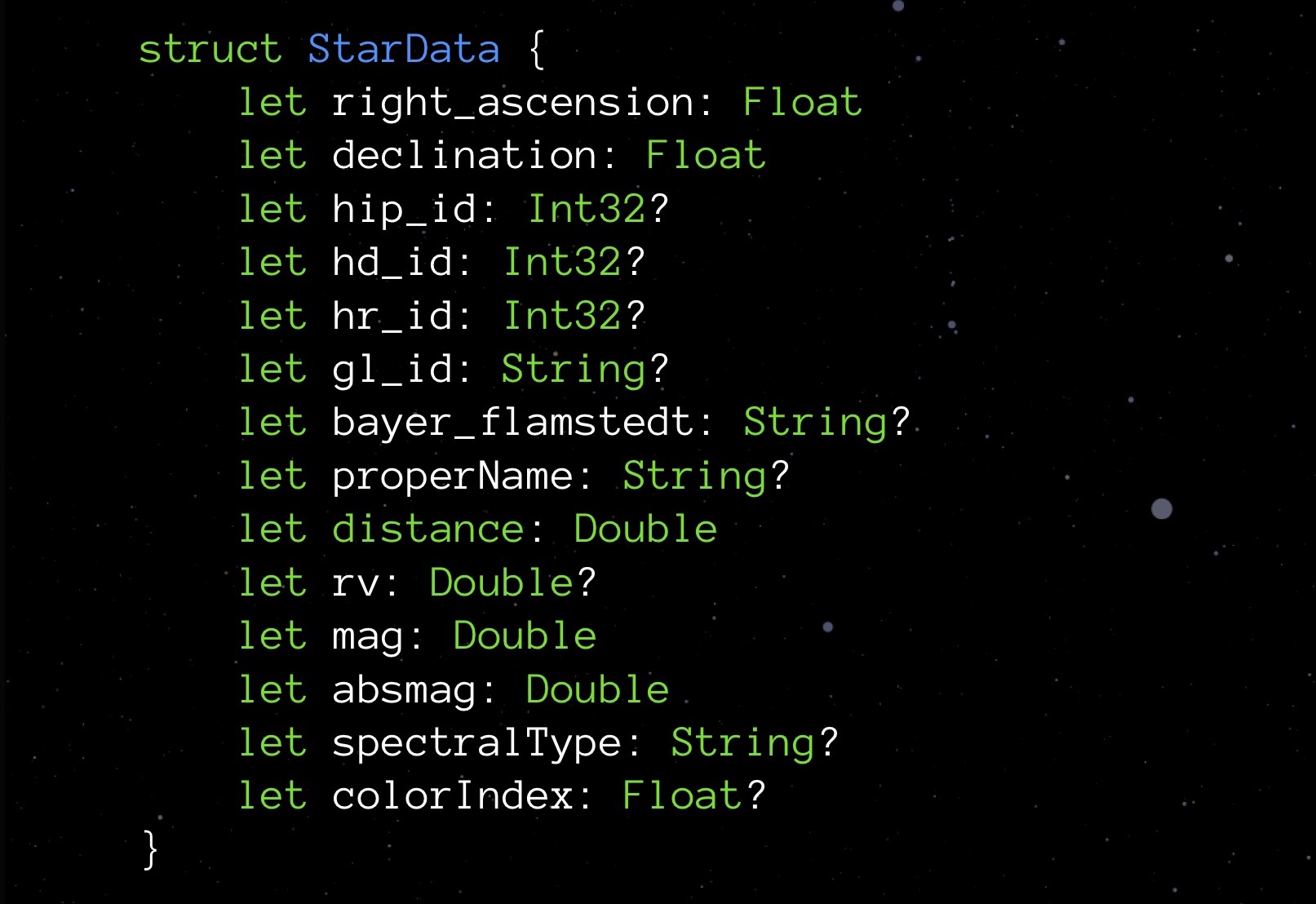
Hier ist eine Datenstruktur zum Speichern von Daten über einen Stern. Sie müssen sich nicht mit den Bedeutungen der einzelnen Elemente befassen. Es ist jetzt wichtiger, auf die Typen zu achten: Float-Variablen, die die Koordinaten des Sterns speichern (tatsächlich Breiten- und Längengrad), mehrere Int32 für verschiedene IDs, String zum Speichern von Namen und Namen verschiedener Klassifikationen; Es gibt einen Abstand, eine Farbe und einige andere Größen, die für die korrekte Anzeige eines Sterns erforderlich sind.
Wir bitten um die Schritt-Eigenschaft:

Im Moment wiegt unsere Struktur 208 Bytes. Eine Million solcher Strukturen benötigt 250 MB - das ist, wie Sie wissen, zu viel. Daher ist eine Optimierung erforderlich.
Korrigieren Sie int
Die Tatsache, dass es verschiedene Arten von Int gibt, wird in den ersten Programmierstunden erklärt. Das für uns bekannteste Int in Swift heißt Int8. Es belegt 8 Bit (1 Byte) und kann Werte von -128 bis einschließlich 127 speichern. Es gibt auch andere Ints:
- Int16 hat eine Größe von 2 Bytes und einen Wertebereich von -32.768 bis 32.767.
- Int32 mit einer Größe von 4 Bytes reicht der Wertebereich von -2.147.483.648 bis 2.147.483.647;
- Int64 (oder nur Int) ist 8 Byte groß, der Wertebereich reicht von -9.223.372.036.854.775.808 bis 9.223.372.036.854.775.807.
Wahrscheinlich denken diejenigen von Ihnen, die sich mit Webentwicklung befasst und sich mit SQL befasst haben, bereits darüber nach. Aber ja, wählen Sie zuerst das optimale Int. In diesem Projekt habe ich mich, noch bevor ich mir Gedanken über die Optimierung gemacht habe, ein wenig vorzeitig optimiert (was, wie ich Ihnen gerade sagte, nicht erforderlich ist).
Schauen wir uns zum Beispiel Felder mit ID an. Wir wissen, dass wir ungefähr eine Million Sterne haben werden - nicht ein paar Zehntausende, aber keine Milliarde. Für solche Felder ist es daher am besten, Int32 zu wählen. Dann wurde mir klar, dass 4 Bytes für Float hier ausreichen. Double belegt 8, String alle 24, addiert alles - es stellt sich heraus, 152 Bytes. Wenn Sie sich erinnern, sagte uns früher MemoryLayout das 208. Warum? Wir müssen tiefer graben.
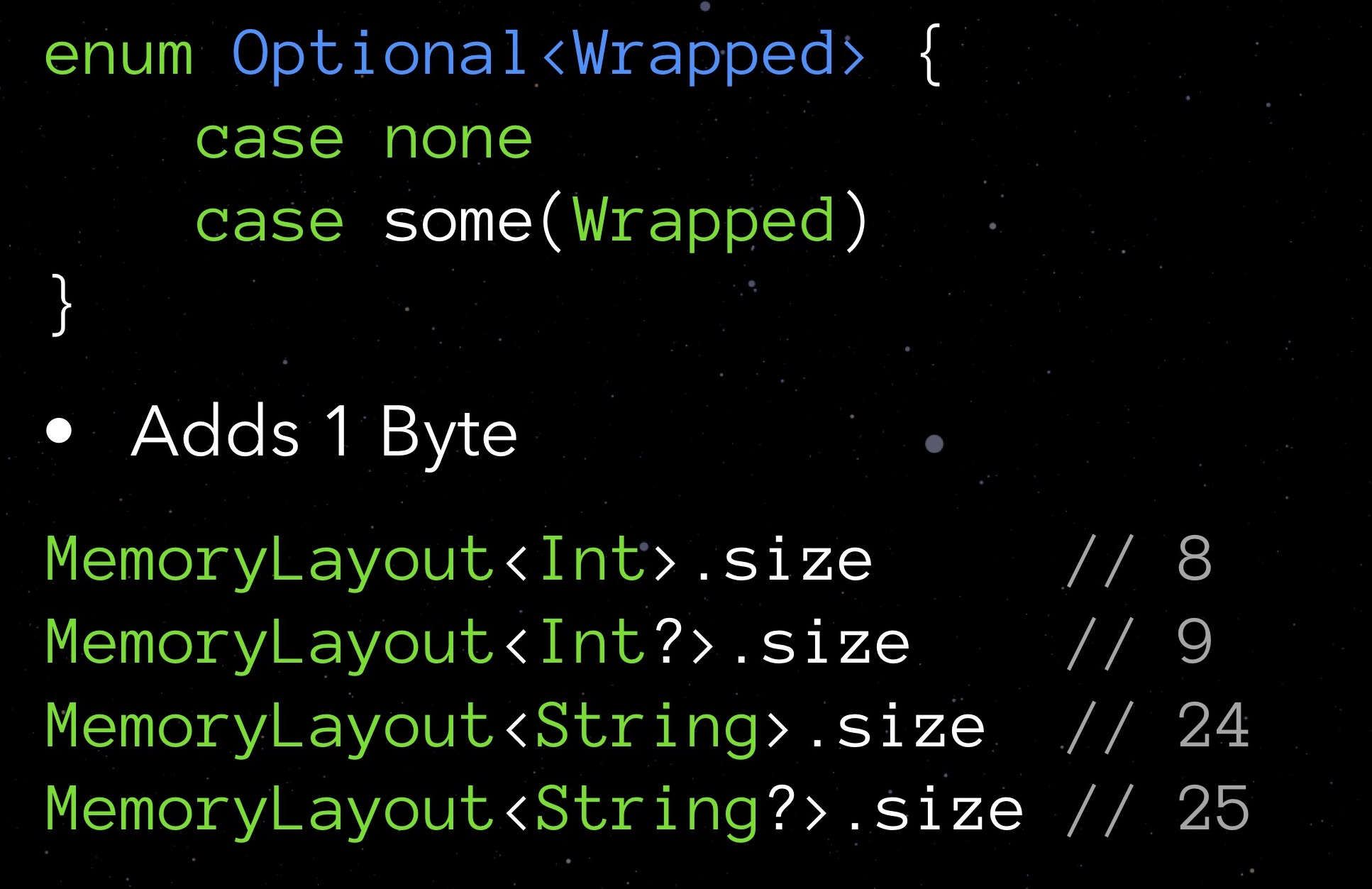
Schauen wir uns zunächst Optional an. Optionale Typen unterscheiden sich darin, dass sie Null speichern, wenn kein Wert zugewiesen ist. Dies gewährleistet Sicherheit bei der Interaktion mit Objekten. Wie Sie wissen, kostet eine solche Kennzahl nicht kostenlos: Wenn Sie die size-Eigenschaft eines optionalen Typs anfordern, werden Sie feststellen, dass ein solcher Typ immer ein Byte mehr benötigt. Wir zahlen für die Möglichkeit, sich für das Nullfeld zu registrieren.
Wir möchten kein zusätzliches Byte für eine Variable ausgeben. Gleichzeitig gefällt uns die Idee, die in optional enthalten ist, sehr gut. Was soll ich mir einfallen lassen? Versuchen wir, unsere Struktur umzusetzen.
Wählen wir einen Wert aus, der für ein bestimmtes Feld vernünftigerweise als "ungültig" angesehen werden kann und gleichzeitig für den deklarierten Typ geeignet ist. Für getHipId (Int32) kann es beispielsweise der Wert "-1" sein. Dies bedeutet, dass unser Feld nicht initialisiert wird. Hier ist ein solches Fahrrad optional, das auf ein zusätzliches Byte bei Null verzichtet.
Mit einem solchen Trick haben wir natürlich auch eine potenzielle Verwundbarkeit. Um uns vor Fehlern zu schützen, erstellen wir einen Getter für das Feld, der unsere neue Logik unabhängig verwaltet und den Feldwert auf Gültigkeit überprüft.

Ein solcher Getter abstrahiert uns die Komplexität einer erfundenen Lösung vollständig.
Wenden Sie sich an unsere StarData. Ersetzen Sie alle optionalen Typen durch reguläre und sehen Sie, was Schritt zeigt:
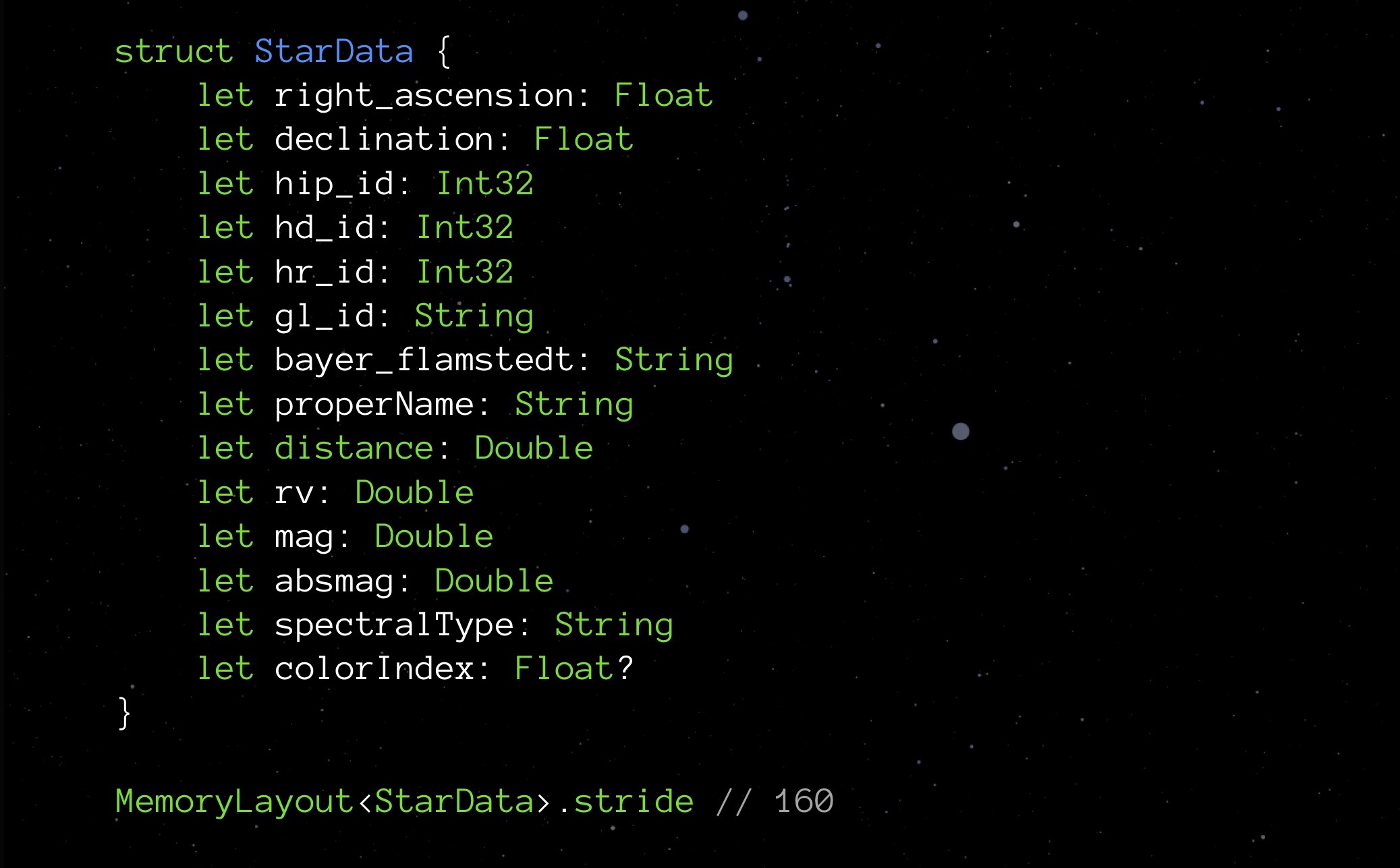
Es stellt sich heraus, dass wir beim Eliminieren der Optionen nicht 9 Bytes (ein Byte für jede der neun Optionen), sondern 48 Bytes gespeichert haben. Die Überraschung ist angenehm, aber ich würde gerne wissen, warum dies passiert ist. Und es geschah aufgrund der Ausrichtung der Daten im Speicher.
Datenausrichtung
Denken Sie daran, dass wir vor Swift in Objective-C geschrieben haben und es auf C basierte - und diese Situation geht auch auf C zurück.
Durch das Platzieren von Strukturen im Speicher platzieren moderne Prozessoren ihre Elemente nicht in einem kontinuierlichen Strom (nicht „Schulter an Schulter“), sondern in einem Gitter, das inhomogen durch Hohlräume verdünnt ist. Dies ist Datenausrichtung. Sie können den Zugriff auf die erforderlichen Datenelemente im Speicher vereinfachen und beschleunigen.
Datenausrichtungsregeln gelten je nach Typ für jede Variable:
- Eine Variable vom Typ char kann am 1., 2., 3., 4. usw. beginnen. Bytes, da es nur ein Byte an sich benötigt;
- Eine kurze Variable benötigt 2 Bytes, sodass sie am 2., 4., 6., 8. usw. beginnen kann. ein Byte (d. h. von jedem geraden Byte);
- Eine Variable vom Typ float benötigt 4 Bytes, was bedeutet, dass sie mit jedem 4., 8., 12., 16. usw. beginnen kann. ein Byte (d. h. jedes vierte Byte);
- Variablen vom Typ Double und String belegen jeweils 8 Byte, sodass sie mit dem 8., 16., 24., 32. usw. beginnen können. Bytes
- usw.
MemoryLayout <> -Objekte verfügen über eine Ausrichtungseigenschaft, die die entsprechende Ausrichtungsregel für den angegebenen Typ zurückgibt.
Könnten wir Kenntnisse über Ausrichtungsregeln anwenden, um Code zu optimieren? Schauen wir uns ein Beispiel an. Es gibt eine Benutzerstruktur: Für Vorname und Nachname verwenden wir eine reguläre Zeichenfolge, für Mittelname - eine optionale Zeichenfolge (der Benutzer hat möglicherweise keinen solchen Namen). Im Speicher wird eine Instanz einer solchen Struktur wie folgt platziert:

Wie Sie sehen können, verpflichten Sie die Ausrichtungsregeln, die nächsten 7 Bytes zu überspringen und 80 Bytes für die gesamte Struktur auszugeben, da der optionale mittlere Name 25 Bytes belegt (anstelle von Vielfachen von 8 24 Bytes). Unabhängig davon, wie Sie Blöcke mit Zeichenfolgen austauschen, ist es hier unmöglich, mit einer geringeren Anzahl von Bytes zu rechnen.
Und jetzt ein Beispiel für eine fehlgeschlagene Ausrichtung:
 Die BadAligned-Struktur deklariert zuerst isHidden vom Typ Bool (1 Byte), dann die Größe vom Typ Double (8 Byte), isInteractable vom Typ Bool (1 Byte) und schließlich das Alter vom Typ Int (ebenfalls 8 Byte). In dieser Reihenfolge deklariert, werden unsere Variablen so im Speicher abgelegt, dass die Gesamtstruktur 32 Bytes belegt.Versuchen wir, die Reihenfolge der Deklaration der Felder zu ändern. Wir ordnen sie in aufsteigender Reihenfolge des belegten Volumens an und sehen, wie sich das Bild im Speicher ändert.
Die BadAligned-Struktur deklariert zuerst isHidden vom Typ Bool (1 Byte), dann die Größe vom Typ Double (8 Byte), isInteractable vom Typ Bool (1 Byte) und schließlich das Alter vom Typ Int (ebenfalls 8 Byte). In dieser Reihenfolge deklariert, werden unsere Variablen so im Speicher abgelegt, dass die Gesamtstruktur 32 Bytes belegt.Versuchen wir, die Reihenfolge der Deklaration der Felder zu ändern. Wir ordnen sie in aufsteigender Reihenfolge des belegten Volumens an und sehen, wie sich das Bild im Speicher ändert.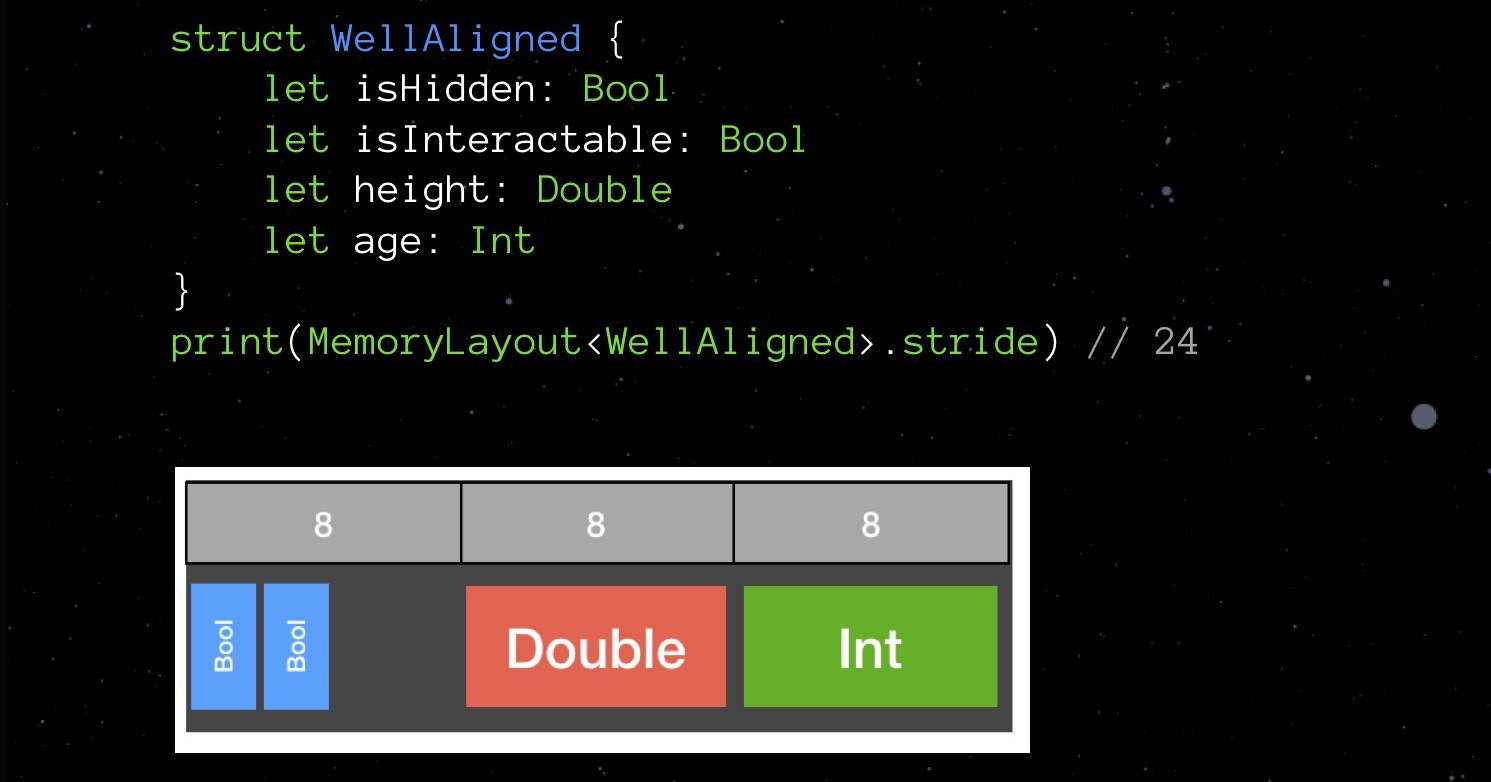 Unsere Struktur benötigt nicht 32 Bytes, sondern 24. Sparen Sie 25%.Klingt nach einem Tetris-Spiel, nicht wahr? Swift verdankt die C-Sprache seinen Vorfahren. Wenn Sie Felder in einer großen Datenstruktur zufällig deklarieren, verbrauchen Sie mit größerer Wahrscheinlichkeit mehr Speicher als Sie könnten, wenn Ausrichtungsregeln gegeben sind. Versuchen Sie daher, sich an sie zu erinnern und beim Schreiben von Code zu berücksichtigen - dies ist nicht so schwierig.Wenden wir uns noch einmal unseren StarData zu. Versuchen wir, die Felder in der Reihenfolge des zunehmenden belegten Volumens anzuordnen.
Unsere Struktur benötigt nicht 32 Bytes, sondern 24. Sparen Sie 25%.Klingt nach einem Tetris-Spiel, nicht wahr? Swift verdankt die C-Sprache seinen Vorfahren. Wenn Sie Felder in einer großen Datenstruktur zufällig deklarieren, verbrauchen Sie mit größerer Wahrscheinlichkeit mehr Speicher als Sie könnten, wenn Ausrichtungsregeln gegeben sind. Versuchen Sie daher, sich an sie zu erinnern und beim Schreiben von Code zu berücksichtigen - dies ist nicht so schwierig.Wenden wir uns noch einmal unseren StarData zu. Versuchen wir, die Felder in der Reihenfolge des zunehmenden belegten Volumens anzuordnen.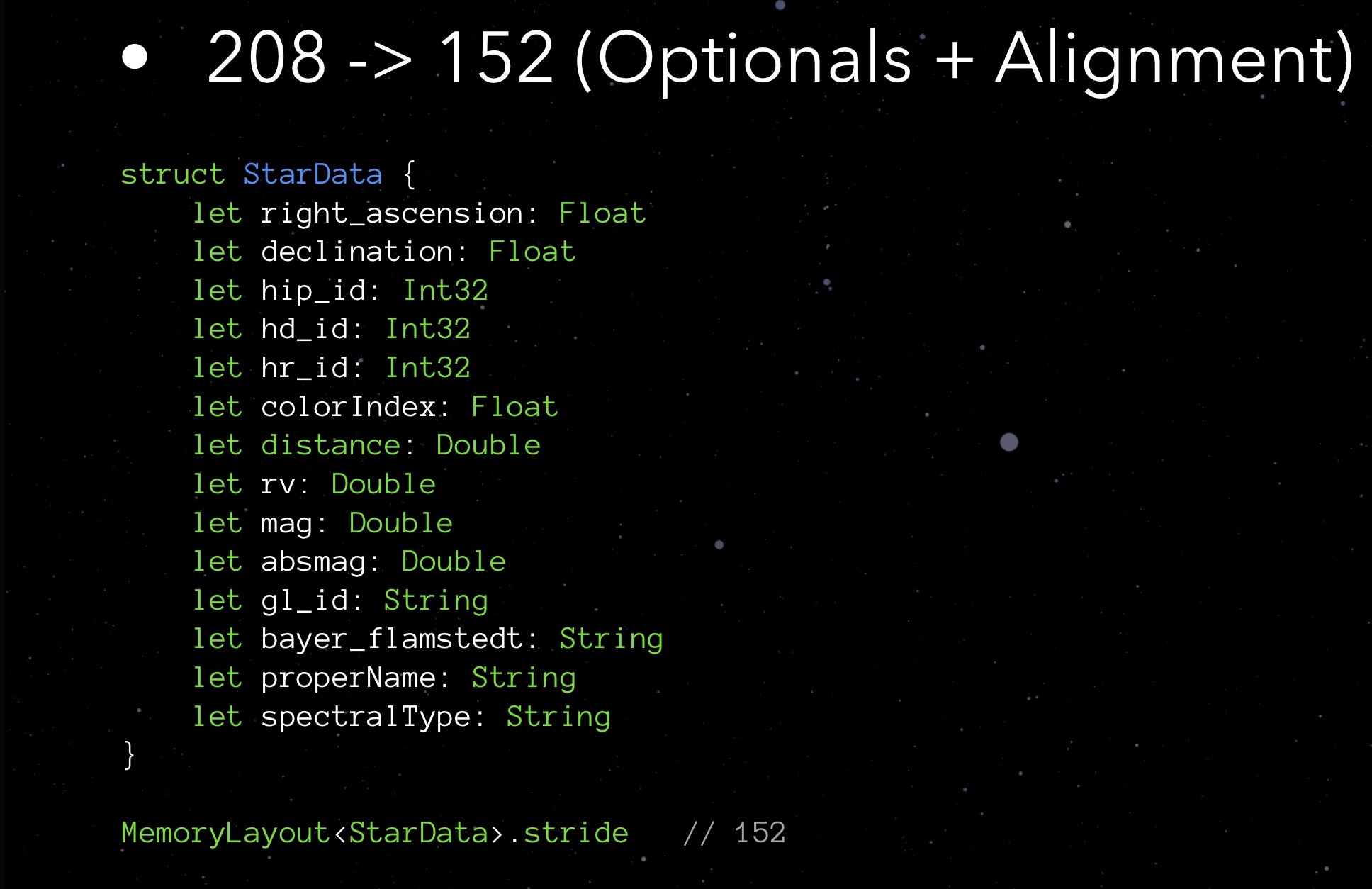 Zuerst Float und Int32, dann Double und String. Nicht so komplizierter Tetris!Der Schritt, den wir erhalten haben, beträgt 152 Bytes. Das heißt, durch die Optimierung der Implementierung von Optionen und die Arbeit mit der Ausrichtung konnten wir die Größe der Struktur von 208 auf 152 Byte reduzieren.Nähern wir uns der Grenze unserer Optimierungsmöglichkeiten? Wahrscheinlich ja. Es gibt jedoch noch etwas, das Sie und ich nicht ausprobiert haben - etwas ist um eine Größenordnung komplizierter, aber es kann Sie manchmal mit seinem Ergebnis in Erstaunen versetzen.
Zuerst Float und Int32, dann Double und String. Nicht so komplizierter Tetris!Der Schritt, den wir erhalten haben, beträgt 152 Bytes. Das heißt, durch die Optimierung der Implementierung von Optionen und die Arbeit mit der Ausrichtung konnten wir die Größe der Struktur von 208 auf 152 Byte reduzieren.Nähern wir uns der Grenze unserer Optimierungsmöglichkeiten? Wahrscheinlich ja. Es gibt jedoch noch etwas, das Sie und ich nicht ausprobiert haben - etwas ist um eine Größenordnung komplizierter, aber es kann Sie manchmal mit seinem Ergebnis in Erstaunen versetzen.Domain Logic Accounting
Versuchen Sie, sich auf die Besonderheiten Ihres Dienstes zu konzentrieren. Erinnern Sie sich an mein Beispiel mit Schach: Die Idee, den FPS-Indikator zu variieren, wenn sich nichts auf dem Bildschirm ändert, ist nur eine Optimierung unter Berücksichtigung der Domänenlogik der Anwendung.Schauen Sie sich StarData noch einmal an. Unser offensichtlicher „Engpass“ sind Felder vom Typ String, die wirklich viel Platz beanspruchen. Und hier sind die Einzelheiten wie folgt: Während der Laufzeit bleiben die meisten dieser Zeilen leer! Nur 146 Sterne haben einen "echten" Namen, der im Feld "Eigenname" angegeben ist. Und gl_id ist die ID des Sterns. Der Gliese-Katalog mit 3801 Sternen ist ebenfalls weit von einer Million entfernt. bayer_flamstedt - Flemsteads Bezeichnungen - werden den 3064. Sternen zugeordnet. Der Spektraltyp spectralType ist 4307 mi. Es stellt sich heraus, dass für die meisten Sterne die eingegebenen Zeichenfolgenvariablen leer sind und jeweils 24 Byte belegen.Ich habe mir den folgenden Ausweg ausgedacht. Lassen Sie uns ein assoziatives Array als zusätzliche Struktur erhalten. Als Schlüssel - eine eindeutige numerische Kennung vom Typ Int16 als Wert, abhängig vom Vorhandensein der charakteristischen Zeichenfolge - entweder deren Wert oder -1.In unseren StarData neben ProperName, gl_id, bayer_flamstedt und spectralType schreiben wir den Index, der dem Schlüssel im Array entspricht. Wenn nötig, holen Sie sich die eine oder andere Zeichenfolge, wir fordern den Wert vom Array über den Index an. Es ist nicht erforderlich, dies manuell zu tun - wir implementieren besser einen praktischen sicheren Getter: Getter ist hier sehr wichtig - es verbirgt die Komplexität unserer eigenen Implementierung vor uns. Ein Array kann als privat registriert werden, jetzt ist es nicht erforderlich, über seine Existenz Bescheid zu wissen.Natürlich hat diese Lösung ein Minus. Das Speichern von Speicher kann die Prozessorlast nur beeinflussen. Mit diesem Schema sind wir gezwungen, ständig auf unser assoziatives Array zuzugreifen. und in den meisten Fällen - vergebens, da die meisten Zeilen leer bleiben und Anfragen "-1" zurückgeben.Daher musste ich das Konzept der Anwendung leicht ändern. Es wurde beschlossen, dem Benutzer nur dann Informationen über den Stern bereitzustellen, wenn er auf diesen Stern klickt. Erst dann wird die Abfrage an das assoziative Array ausgeführt und die empfangenen Daten werden auf dem Bildschirm angezeigt.Trotz der Abstraktion durch Getter müssen wir zugeben, dass wir durch die Einführung eines assoziativen Arrays den Code immer noch erheblich kompliziert haben. Dies geschieht normalerweise während der Optimierung. Daher ist es wichtig, qualitativ hochwertige Unit-Tests durchzuführen, um sicherzustellen, dass unser assoziatives Array nicht zu einem unerwarteten Zeitpunkt versagt.Insgesamt: Schritt gibt uns jetzt 64 Bytes!Ist das alles Nein, jetzt müssen wir noch einmal über Ausrichtungsregeln nachdenken: Felder vom Typ Int16 höher anordnen.
Getter ist hier sehr wichtig - es verbirgt die Komplexität unserer eigenen Implementierung vor uns. Ein Array kann als privat registriert werden, jetzt ist es nicht erforderlich, über seine Existenz Bescheid zu wissen.Natürlich hat diese Lösung ein Minus. Das Speichern von Speicher kann die Prozessorlast nur beeinflussen. Mit diesem Schema sind wir gezwungen, ständig auf unser assoziatives Array zuzugreifen. und in den meisten Fällen - vergebens, da die meisten Zeilen leer bleiben und Anfragen "-1" zurückgeben.Daher musste ich das Konzept der Anwendung leicht ändern. Es wurde beschlossen, dem Benutzer nur dann Informationen über den Stern bereitzustellen, wenn er auf diesen Stern klickt. Erst dann wird die Abfrage an das assoziative Array ausgeführt und die empfangenen Daten werden auf dem Bildschirm angezeigt.Trotz der Abstraktion durch Getter müssen wir zugeben, dass wir durch die Einführung eines assoziativen Arrays den Code immer noch erheblich kompliziert haben. Dies geschieht normalerweise während der Optimierung. Daher ist es wichtig, qualitativ hochwertige Unit-Tests durchzuführen, um sicherzustellen, dass unser assoziatives Array nicht zu einem unerwarteten Zeitpunkt versagt.Insgesamt: Schritt gibt uns jetzt 64 Bytes!Ist das alles Nein, jetzt müssen wir noch einmal über Ausrichtungsregeln nachdenken: Felder vom Typ Int16 höher anordnen. Jetzt ist alles. Wie Sie sehen, konnten wir mit einer kleinen Anzahl von im Wesentlichen einfachen Methoden die Größe der StarData-Struktur von 208 auf 56 Byte reduzieren. Eine Million Sterne belegen jetzt nicht mehr 500 MB, sondern 130. Viermal weniger!Vergessen Sie nicht die Gefahren einer vorzeitigen Optimierung. Wenn Ihre Benutzerdatenstruktur für etwa 20 Benutzer verwendet wird, werden Sie dort nicht so viel gewinnen, dass es sinnvoll ist, dies zu tun. Noch wichtiger ist, dass der nächste Entwickler den Code bequem pflegen kann. Bitte sagen Sie später nicht "dieser Typ auf der Konferenz sagte, dass die Reihenfolge genau das sein sollte"! Mach das nicht nur zum Spaß. Für mich sind solche Dinge gute Unterhaltung, ich weiß nicht wie für Sie.
Jetzt ist alles. Wie Sie sehen, konnten wir mit einer kleinen Anzahl von im Wesentlichen einfachen Methoden die Größe der StarData-Struktur von 208 auf 56 Byte reduzieren. Eine Million Sterne belegen jetzt nicht mehr 500 MB, sondern 130. Viermal weniger!Vergessen Sie nicht die Gefahren einer vorzeitigen Optimierung. Wenn Ihre Benutzerdatenstruktur für etwa 20 Benutzer verwendet wird, werden Sie dort nicht so viel gewinnen, dass es sinnvoll ist, dies zu tun. Noch wichtiger ist, dass der nächste Entwickler den Code bequem pflegen kann. Bitte sagen Sie später nicht "dieser Typ auf der Konferenz sagte, dass die Reihenfolge genau das sein sollte"! Mach das nicht nur zum Spaß. Für mich sind solche Dinge gute Unterhaltung, ich weiß nicht wie für Sie.Schnelle Compiler-Optimierung
Die meisten Programmierer kennen den Schmerz eines langen (unerträglich langen) Zusammenbaus eines Projekts. Sie haben gerade eine kleine Änderung am Code vorgenommen und lehnen sich jetzt zurück und warten, bis der Build abgeschlossen ist.Der Erstellungsprozess kann Ihnen jedoch etwas über Ihren Code erzählen. Dies ist ein ausgezeichneter Indikator für Botnekov. Sie müssen ihn nur an die Arbeit anpassen.Persönlich habe ich die Kompilierung in Xcode recherchiert. Als Werkzeug habe ich den folgenden Befehl verwendet: Dieser Befehl weist xCode an, die Kompilierungszeit jeder Funktion zu verfolgen und in die Datei culprits.txt zu schreiben. Der Inhalt der Datei wird auf dem Weg sortiert.
Dieser Befehl weist xCode an, die Kompilierungszeit jeder Funktion zu verfolgen und in die Datei culprits.txt zu schreiben. Der Inhalt der Datei wird auf dem Weg sortiert. Mit meinem einfachen Instrument konnte ich interessante Dinge beobachten. Einige Methoden können bis zu 2 Sekunden lang kompiliert werden, wobei nur drei Codezeilen enthalten sind. Was könnte der Grund sein?Zum Beispiel eine Typ-Compiler-Ausgabe. Wenn Sie Typen nicht explizit angeben, muss Swift sie selbst erkennen. Diese (ich muss sagen, nicht triviale) Operation erfordert Prozessorzeit, daher ist es aus Sicht des Compilers immer besser, den Typ anzugeben. Durch explizites Schreiben der Typen konnte ich die Erstellungszeit der Anwendung einmal von 5 auf 2 (!) Minuten reduzieren.Aber es gibt ein "aber": Code ohne Typen ist noch besser lesbar. Und wir haben bereits über Prioritäten gesprochen. Optimieren Sie nicht im Voraus: Die Lesbarkeit von Code wird zunächst teurer.
Mit meinem einfachen Instrument konnte ich interessante Dinge beobachten. Einige Methoden können bis zu 2 Sekunden lang kompiliert werden, wobei nur drei Codezeilen enthalten sind. Was könnte der Grund sein?Zum Beispiel eine Typ-Compiler-Ausgabe. Wenn Sie Typen nicht explizit angeben, muss Swift sie selbst erkennen. Diese (ich muss sagen, nicht triviale) Operation erfordert Prozessorzeit, daher ist es aus Sicht des Compilers immer besser, den Typ anzugeben. Durch explizites Schreiben der Typen konnte ich die Erstellungszeit der Anwendung einmal von 5 auf 2 (!) Minuten reduzieren.Aber es gibt ein "aber": Code ohne Typen ist noch besser lesbar. Und wir haben bereits über Prioritäten gesprochen. Optimieren Sie nicht im Voraus: Die Lesbarkeit von Code wird zunächst teurer.Serveroption
Bisher habe ich meine Anwendung nur mit Augmented Reality erwähnt. Aber basierend auf einer Million Sternen habe ich auch eine Serveranwendung auf Swift erstellt. Sie können ihn und seinen Code auf GitHub sehen . Dies ist ein API-Dienst, mit dem Sie Informationen über Sterne aus meiner riesigen Datenbank erhalten können. Ich konnte es mit denselben Methoden optimieren, die ich für die Anwendung auf ARkit verwendet habe. Das Ergebnis in diesem Fall wurde für mich buchstäblich greifbar: Als ich das Volumen auf 500 MB reduzierte, hatte ich die Möglichkeit, es auf einen kostenlosen Bluemix-Server zu stellen. Infolgedessen kostet mich mein Service absolut kostenlos.Zusammenfassend
Abschließend eine kurze Zusammenfassung der wichtigsten Gedanken, die ich Ihnen heute ansprechen wollte:- . . , , , ?
- , unit-. , unit-. , . Unit- , .
- . , . , : — .
- Arbeiten Sie mit der Domänenlogik Ihrer Anwendung. Das mächtigste Optimierungswerkzeug ist die geschickte Arbeit mit Domänenlogik. Kennen Sie die Funktionen der Arbeit, die Besonderheiten Ihrer Anwendung - versuchen Sie, diese zu berücksichtigen, und suchen Sie nach Ihren "persönlichen" Lösungen.
- RAM vs. CPU Geben Sie Ihr Bestes, um das Gleichgewicht zwischen Speicher- und Prozessorauslastung zu halten. Dies ist immer sehr schwierig, aber es ist immer noch möglich, in jedem Einzelfall ein bestimmtes Optimum zu finden.
Wenn Ihnen dieser Bericht von der Mobius-Konferenz gefallen hat, beachten Sie bitte, dass Mobius 2018 Moskau vom 8. bis 9. Dezember stattfindet , wo es auch viele interessante Dinge geben wird. Seit dem 1. November sind die Ticketpreise gestiegen, daher ist es sinnvoll, jetzt eine Entscheidung zu treffen!