Reinforced Learning (RL) ist eine der vielversprechendsten Techniken des maschinellen Lernens, die aktiv entwickelt werden. Hier erhält der KI-Agent eine positive Belohnung für die richtigen Aktionen und eine negative Belohnung für die falschen. Diese Methode von
Zuckerbrot und Peitsche ist einfach und universell. Damit brachte DeepMind dem
DQN- Algorithmus das Spielen alter Atari-Videospiele und
AlphaGoZero das Spielen des alten Go-Spiels bei. So brachte OpenAI dem
OpenAI-Five- Algorithmus das Spielen des modernen Dota-Videospiels bei, und Google brachte Roboterhänden das
Erfassen neuer Objekte bei . Trotz des Erfolgs von RL gibt es immer noch viele Probleme, die die Wirksamkeit dieser Technik verringern.
RL-Algorithmen
finden es schwierig, in einer Umgebung
zu arbeiten, in der der Agent selten Feedback erhält. Dies ist jedoch typisch für die reale Welt. Stellen Sie sich zum Beispiel vor, Sie suchen Ihren Lieblingskäse in einem großen Labyrinth wie einem Supermarkt. Sie suchen und suchen eine Abteilung mit Käse, können diese aber nicht finden. Wenn Sie bei jedem Schritt weder eine "Peitsche" noch eine "Karotte" bekommen, ist es unmöglich zu sagen, ob Sie sich in die richtige Richtung bewegen. Was hindert Sie daran, für immer herumzuwandern, wenn Sie keine Belohnung erhalten? Nichts als vielleicht deine Neugier. Es motiviert zum Umzug in die Lebensmittelabteilung, die ungewohnt aussieht.
Die wissenschaftliche Arbeit
„Episodische Neugier durch Erreichbarkeit“ ist das Ergebnis einer Zusammenarbeit zwischen
dem Google Brain-Team DeepMind und
der Swiss Higher Technical School in Zürich . Wir bieten ein neues episodisches, auf dem Gedächtnis basierendes RL-Belohnungsmodell an. Sie sieht aus wie eine Neugier, mit der Sie die Umgebung erkunden können. Da der Agent nicht nur die Umgebung untersuchen, sondern auch das anfängliche Problem lösen muss, fügt unser Modell der anfänglich spärlichen Belohnung einen Bonus hinzu. Die kombinierte Belohnung ist nicht mehr spärlich, sodass die Standard-RL-Algorithmen daraus lernen können. Unsere Neugiermethode erweitert somit das Spektrum der Aufgaben, die mit RL gelöst werden können.
 Gelegentliche Neugier durch Erreichbarkeit: Beobachtungsdaten werden dem Speicher hinzugefügt, die Belohnung wird basierend darauf berechnet, wie weit die aktuelle Beobachtung von ähnlichen Beobachtungen im Speicher entfernt ist. Der Agent erhält eine größere Belohnung für Beobachtungen, die noch nicht im Gedächtnis vorhanden sind.
Gelegentliche Neugier durch Erreichbarkeit: Beobachtungsdaten werden dem Speicher hinzugefügt, die Belohnung wird basierend darauf berechnet, wie weit die aktuelle Beobachtung von ähnlichen Beobachtungen im Speicher entfernt ist. Der Agent erhält eine größere Belohnung für Beobachtungen, die noch nicht im Gedächtnis vorhanden sind.Die Hauptidee der Methode besteht darin, die Beobachtungen des Agenten über die Umgebung im episodischen Gedächtnis zu speichern und den Agenten für das Anzeigen der Beobachtungen zu belohnen, die noch nicht im Gedächtnis vorhanden sind. "Mangel an Gedächtnis" ist die Definition von Neuheit in unserer Methode. Die Suche nach solchen Beobachtungen bedeutet die Suche nach einem Fremden. Ein solches Verlangen, nach einem Fremden zu suchen, führt den KI-Agenten an neue Orte, verhindert so das Wandern im Kreis und hilft ihm letztendlich, über das Ziel zu stolpern. Wie wir später diskutieren, kann unser Wortlaut den Agenten von dem unerwünschten Verhalten abhalten, dem einige andere Formulierungen unterliegen. Zu unserer großen Überraschung hat dieses Verhalten einige Ähnlichkeiten mit dem, was ein Laie "Aufschub" nennen würde.
Vorherige Neugier
Obwohl in der Vergangenheit viele Versuche unternommen wurden, Neugierde zu formulieren
[1] [2] [3] [4] , konzentrieren wir uns in diesem Artikel auf einen natürlichen und sehr beliebten Ansatz: Neugierde durch Überraschung basierend auf Prognosen. Diese Technik wird in einem kürzlich erschienenen Artikel beschrieben:
„Untersuchen einer Umgebung mithilfe von Neugierde durch Vorhersagen unter eigener Kontrolle“ (normalerweise als ICM bezeichnet). Um den Zusammenhang zwischen Überraschung und Neugier zu veranschaulichen, verwenden wir wieder die Analogie, Käse in einem Supermarkt zu finden.
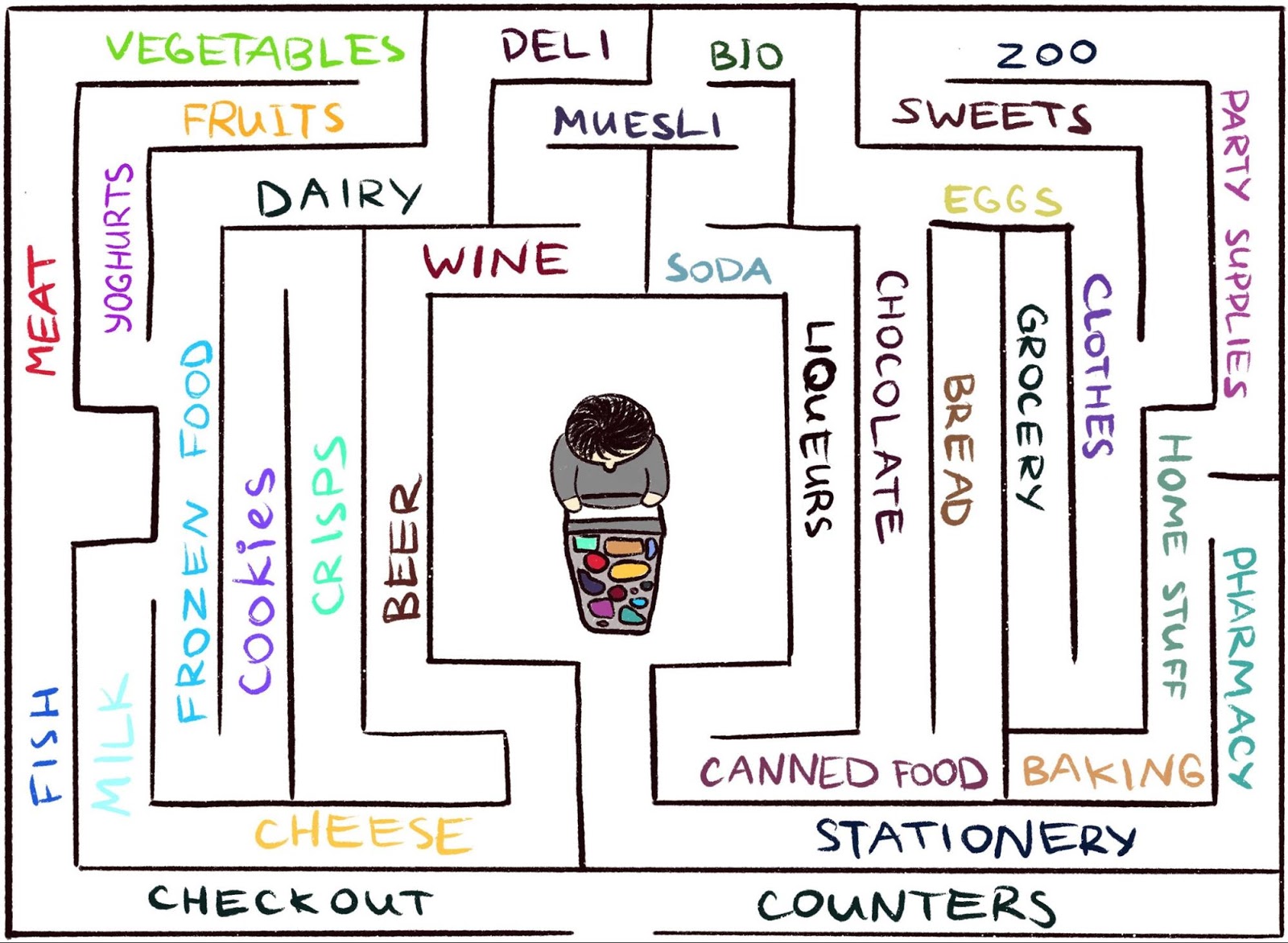 Illustration von Indira Pasko , lizenziert unter CC BY-NC-ND 4.0
Illustration von Indira Pasko , lizenziert unter CC BY-NC-ND 4.0Wenn Sie durch den Laden schlendern, versuchen Sie, die Zukunft vorherzusagen (
"Jetzt bin ich in der Fleischabteilung, also denke ich, dass die Abteilung um die Ecke die Abteilung für Fisch ist, sie sind normalerweise in der Nähe dieser Supermarktkette" ). Wenn die Prognose falsch ist, sind Sie überrascht (
"Eigentlich gibt es eine Abteilung für Gemüse. Ich habe das nicht erwartet!" ) - und auf diese Weise erhalten Sie eine Belohnung. Dies erhöht die Motivation in der Zukunft, wieder um die Ecke zu schauen und neue Orte zu erkunden, um zu überprüfen, ob Ihre Erwartungen wahr sind (und möglicherweise über Käse zu stolpern).
In ähnlicher Weise erstellt die ICM-Methode ein Vorhersagemodell für die Dynamik der Welt und gibt dem Agenten eine Belohnung, wenn das Modell keine guten Vorhersagen trifft - ein Marker für Überraschung oder Neuheit. Bitte beachten Sie, dass das Erkunden neuer Orte nicht direkt in der Neugier des ICM zum Ausdruck kommt. Für die ICM-Methode ist die Teilnahme nur eine Möglichkeit, mehr „Überraschungen“ zu erzielen und so Ihre Gesamtbelohnung zu maximieren. Wie sich herausstellt, gibt es in einigen Umgebungen andere Möglichkeiten, sich selbst zu überraschen, was zu unerwarteten Ergebnissen führt.
Ein Agent mit einem auf Überraschung basierenden Neugier-System friert ein, wenn er sich mit einem Fernseher trifft. Animation aus Deepak Pataks Video, lizenziert unter CC BY 2.0Die Gefahr des Aufschubs
In dem Artikel
„Eine groß angelegte Studie zum neugierigen Lernen“ zeigen die Autoren der ICM-Methode zusammen mit OpenAI-Forschern eine versteckte Gefahr der Maximierung der Überraschung: Agenten können lernen, sich dem Aufschieben hinzugeben, anstatt etwas Nützliches für die Aufgabe zu tun. Um zu verstehen, warum dies geschieht, betrachten Sie ein Gedankenexperiment, das die Autoren als „Problem des Fernsehrauschens“ bezeichnen. Hier wird der Agent in ein Labyrinth gebracht, um einen sehr nützlichen Gegenstand zu finden (wie in unserem Beispiel „Käse“). Die Umgebung verfügt über einen Fernseher und der Agent über eine Fernbedienung. Es gibt eine begrenzte Anzahl von Kanälen (jeder Kanal hat eine separate Übertragung), und jedes Drücken auf der Fernbedienung schaltet das Fernsehgerät auf einen zufälligen Kanal um. Wie wird sich ein Agent in einer solchen Umgebung verhalten?
Wenn Neugierde auf der Grundlage von Überraschungen entsteht, wird ein Kanalwechsel mehr Belohnungen bringen, da jeder Wechsel unvorhersehbar und unerwartet ist. Es ist wichtig zu beachten, dass selbst nach einem zyklischen Scan aller verfügbaren Kanäle eine zufällige Auswahl eines Kanals sicherstellt, dass jede neue Änderung immer noch unerwartet ist. Der Agent sagt voraus, dass nach dem Umschalten des Kanals TV angezeigt wird, und die Prognose wird höchstwahrscheinlich falsch sein, was zu Überraschungen führen wird. Es ist wichtig zu beachten, dass die Änderung immer noch unvorhersehbar ist, selbst wenn der Agent bereits jede Übertragung auf jedem Kanal gesehen hat. Aus diesem Grund bleibt der Agent, anstatt nach einem sehr nützlichen Gegenstand zu suchen, letztendlich vor dem Fernseher - ähnlich wie beim Aufschieben. Wie kann man den Wortlaut der Neugier ändern, um dieses Verhalten zu verhindern?
Episodische Neugier
In dem Artikel
„Episodische Neugier durch Erreichbarkeit“ untersuchen wir ein auf episodischem Gedächtnis basierendes Neugiermodell, das weniger anfällig für sofortiges Vergnügen ist. Warum so? Wenn wir das obige Beispiel nehmen, werden nach einiger Zeit beim Umschalten der Kanäle alle Übertragungen schließlich im Speicher landen. Dadurch verliert der Fernseher seine Attraktivität: Auch wenn die Reihenfolge, in der die Programme auf dem Bildschirm angezeigt werden, zufällig und unvorhersehbar ist, sind sie alle im Speicher! Dies ist der Hauptunterschied zu der Methode, die auf Überraschung basiert: Unsere Methode versucht nicht einmal, die Zukunft vorherzusagen, sie ist schwer vorherzusagen (oder sogar unmöglich). Stattdessen untersucht der Agent die Vergangenheit und prüft, ob im Speicher Beobachtungen
wie die aktuelle vorhanden sind. Daher ist unser Agent nicht anfällig für sofortige Freuden, die ein "Fernsehgeräusch" verursachen. Der Agent muss die Welt außerhalb des Fernsehers erkunden, um mehr Belohnungen zu erhalten.
Aber wie entscheiden wir, ob ein Agent dasselbe sieht, was im Speicher gespeichert ist? Eine genaue Übereinstimmungsprüfung ist sinnlos: In einer realen Umgebung sieht ein Agent selten zweimal dasselbe. Selbst wenn der Agent beispielsweise in denselben Raum zurückkehrt, sieht er diesen Raum immer noch aus einem anderen Blickwinkel.
Anstatt nach genauen Übereinstimmungen zu suchen, verwenden wir ein
tiefes neuronales Netzwerk , das darauf trainiert ist, zu messen, wie ähnlich zwei Erfahrungen sind. Um dieses Netzwerk zu trainieren, müssen wir erraten, wie genau die Beobachtungen rechtzeitig stattgefunden haben. Die zeitliche Nähe ist ein guter Indikator dafür, ob zwei Beobachtungen als Teil derselben betrachtet werden sollten. Ein solches Lernen führt zu einem allgemeinen Konzept der Neuheit durch Erreichbarkeit, das unten dargestellt wird.
 Das Erreichbarkeitsdiagramm definiert die Neuheit. In der Praxis ist dieses Diagramm nicht verfügbar. Daher trainieren wir den Approximator für neuronale Netze, um die Anzahl der Schritte zwischen den Beobachtungen abzuschätzen
Das Erreichbarkeitsdiagramm definiert die Neuheit. In der Praxis ist dieses Diagramm nicht verfügbar. Daher trainieren wir den Approximator für neuronale Netze, um die Anzahl der Schritte zwischen den Beobachtungen abzuschätzenExperimentelle Ergebnisse
Um die Leistung verschiedener Ansätze zur Beschreibung von Neugier zu vergleichen, haben wir sie in zwei visuell reichhaltigen 3D-Umgebungen getestet:
ViZDoom und
DMLab . Unter diesen Bedingungen erhielt der Agent verschiedene Aufgaben, z. B. ein Ziel im Labyrinth zu finden, gute Objekte zu sammeln und schlechte zu vermeiden. In der DMLab-Umgebung ist der Agent standardmäßig mit einem fantastischen Gadget wie einem Laser ausgestattet. Wenn das Gadget jedoch für eine bestimmte Aufgabe nicht benötigt wird, kann der Agent es nicht frei verwenden. Interessanterweise hat der ICM-Agent den Laser überraschenderweise sehr oft verwendet, auch wenn es nutzlos war, die Aufgabe zu erledigen! Wie im Fall des Fernsehers zog er es vor, Zeit damit zu verbringen, an den Wänden zu schießen, anstatt nach einem wertvollen Gegenstand im Labyrinth zu suchen, da dies viele Belohnungen in Form von Überraschungen brachte. Theoretisch sollte das Ergebnis eines Wandschusses vorhersehbar sein, aber in der Praxis ist es zu schwierig vorherzusagen. Dies erfordert wahrscheinlich tiefere Kenntnisse der Physik, als sie dem Standard-KI-Agenten zur Verfügung stehen.

Im Gegensatz zu ihm hat unser Agent vernünftiges Verhalten beherrscht, um die Umwelt zu untersuchen. Dies geschah, weil er nicht versucht, das Ergebnis seiner Handlungen vorherzusagen, sondern nach Beobachtungen sucht, die „weiter“ von denen entfernt sind, die sich im episodischen Gedächtnis befinden. Mit anderen Worten, der Agent verfolgt implizit Ziele, die mehr Aufwand erfordern als ein einfacher Schuss auf die Wand.
Unsere Methode demonstriert intelligentes Umwelterkundungsverhalten.Es ist interessant zu beobachten, wie unser Ansatz zur Belohnung einen in einem Kreis laufenden Agenten bestraft, da der Agent nach Abschluss des ersten Kreises keine neuen Beobachtungen findet und daher keine Belohnung erhält:
Belohnungsvisualisierung: Rot entspricht einer negativen Belohnung, Grün einer positiven. Von links nach rechts: Prämienkarte, Karte mit Speicherorten, Ansicht aus der ersten PersonGleichzeitig trägt unsere Methode zu einer guten Untersuchung der Umwelt bei:
Belohnungsvisualisierung: Rot entspricht einer negativen Belohnung, Grün einer positiven. Von links nach rechts: Prämienkarte, Karte mit Speicherorten, Ansicht aus der ersten PersonWir hoffen, dass unsere Arbeit zu einer neuen Forschungswelle beiträgt, die über den Rahmen der Überraschungstechnik hinausgeht, um Agenten über intelligenteres Verhalten aufzuklären. Für eine eingehende Analyse unserer Methode werfen Sie bitte einen Blick auf den
Vorabdruck der wissenschaftlichen Arbeit .
Danksagung:
Dieses Projekt ist das Ergebnis einer Zusammenarbeit zwischen dem Google Brain-Team DeepMind und der Swiss Higher Technical School in Zürich. Hauptforschungsgruppe: Nikolay Savinov, Anton Raichuk, Rafael Marinier, Damien Vincent, Mark Pollefeys, Timothy Lillirap und Sylvain Zheli. Wir möchten Olivier Pietkin, Carlos Riquelme, Charles Blundell und Sergey Levine für die Erörterung dieses Dokuments danken. Wir danken Indira Pasco für die Hilfe bei den Abbildungen.
Literaturhinweise:
[1]
"Die Untersuchung der Umwelt basierend auf dem Zählen mit Modellen der neuronalen Dichte" , Georg Ostrovsky, Mark G. Bellemar, Aaron Van den Oord, Remy Munoz
[2]
„ Zählbasierte
Lernumgebungen für tiefes Lernen mit Verstärkung“ , Khaoran Tan, Rain Huthuft, Davis Foot, Adam Knock, Xi Chen, Yan Duan, John Schulman, Philip de Turk und Peter Abbel
[3]
„Lernen ohne Lehrer, um Ziele für intern motivierte Forschung zu finden“, Alexander Pere, Sebastien Forestier, Olivier Sigot und Pierre-Yves Udaye
[4]
"VIME: Intelligenz zur Maximierung von Informationsänderungen", Rein Huthuft, Xi Chen, Yan Duan, John Schulman, Philippe de Turk, Peter Abbel