Hallo habr.
In einem Projekt, in dem eine ziemlich große dynamische Liste gespeichert und verarbeitet werden musste, begannen die Tester, sich über Speichermangel zu beschweren. Eine einfache Möglichkeit, das Problem mit "wenig Blut" durch Hinzufügen nur einer Codezeile zu beheben, wird unten beschrieben. Das Ergebnis im Bild:
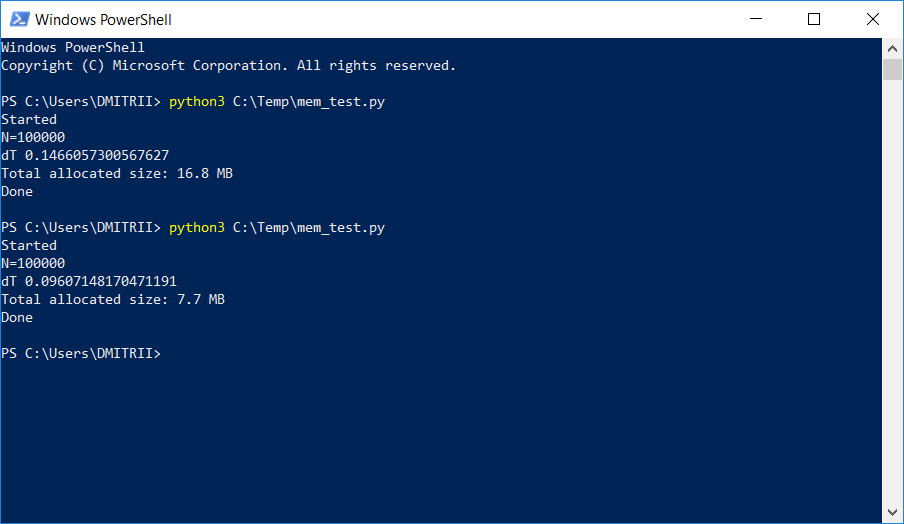
Wie es funktioniert, weiter unter dem Schnitt.
Stellen Sie sich ein einfaches Trainingsbeispiel vor: Erstellen Sie eine DataItem-Klasse, die
persönliche Daten zu einer Person enthält, z. B. Name, Alter und Adresse.
class DataItem(object): def __init__(self, name, age, address): self.name = name self.age = age self.address = address
Die "Kinder" -Frage ist, wie viel nimmt ein solches Objekt in Erinnerung?
Versuchen wir die Lösung in der Stirn:
d1 = DataItem("Alex", 42, "-") print ("sys.getsizeof(d1):", sys.getsizeof(d1))
Wir erhalten eine Antwort von 56 Bytes. Es scheint ein bisschen, ziemlich zufrieden.
Wir überprüfen jedoch ein anderes Objekt, in dem sich mehr Daten befinden:
d2 = DataItem("Boris", 24, "In the middle of nowhere") print ("sys.getsizeof(d2):", sys.getsizeof(d2))
Die Antwort ist wieder 56. An diesem Punkt verstehen wir, dass hier etwas nicht stimmt und nicht alles so einfach ist, wie es auf den ersten Blick scheint.
Die Intuition versagt uns nicht und alles ist wirklich nicht so einfach. Python ist eine sehr flexible Sprache mit dynamischer Typisierung und speichert für seine Arbeit viele zusätzliche Daten. Was für sich genommen viel ausmacht. Nur als Beispiel gibt sys.getsizeof ("") 33 zurück - ja, bis zu 33 Bytes pro Leerzeile! Und sys.getsizeof (1) gibt 24 - 24 Bytes für eine Ganzzahl zurück (ich fordere C-Programmierer auf, sich vom Bildschirm zu entfernen und nicht weiter zu lesen, um nicht das Vertrauen in das Schöne zu verlieren). Bei komplexeren Elementen wie einem Wörterbuch gibt sys.getsizeof (dict ()) 272 Byte zurück - und dies gilt für ein
leeres Wörterbuch. Ich werde nicht weiter weitermachen, ich hoffe, das Prinzip ist klar
und RAM-Hersteller müssen auch ihre Chips verkaufen .
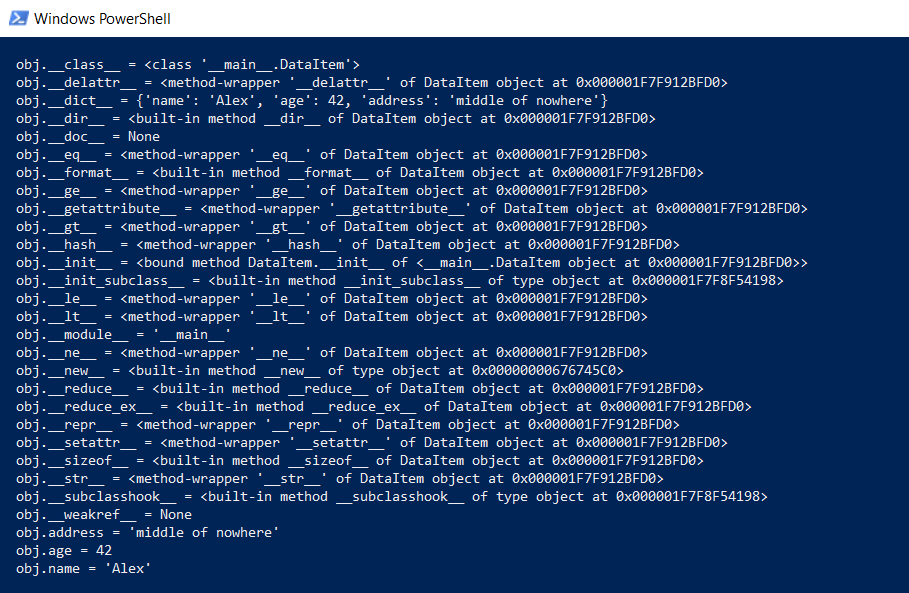
Aber zurück zu unserer DataItem-Klasse und der "Kind" -Frage. Wie lange dauert eine solche Klasse im Gedächtnis? Zunächst zeigen wir den gesamten Inhalt der Klasse auf einer niedrigeren Ebene an:
def dump(obj): for attr in dir(obj): print(" obj.%s = %r" % (attr, getattr(obj, attr)))
Diese Funktion zeigt an, was „unter der Haube“ verborgen ist, damit alle Python-Funktionen (Typisierung, Vererbung und andere Extras) funktionieren können.
Das Ergebnis ist beeindruckend:
Wie viel kostet das alles? Auf github gab es eine Funktion, die die tatsächliche Datenmenge berechnet und rekursiv für alle Objekte getizeof aufruft.
def get_size(obj, seen=None):
Wir versuchen es:
d1 = DataItem("Alex", 42, "-") print ("get_size(d1):", get_size(d1)) d2 = DataItem("Boris", 24, "In the middle of nowhere") print ("get_size(d2):", get_size(d2))
Wir erhalten 460 bzw. 484 Bytes, was eher der Wahrheit entspricht.
Mit dieser Funktion können eine Reihe von Experimenten durchgeführt werden. Ich frage mich zum Beispiel, wie viel Daten aufgenommen werden, wenn Sie die DataItem-Strukturen in die Liste aufnehmen. Die Funktion get_size ([d1]) gibt 532 Bytes zurück - anscheinend ist dies die "gleiche" 460 + etwas Overhead. Get_size ([d1, d2]) gibt jedoch 863 Bytes zurück - weniger als 460 + 484 separat. Noch interessanter ist das Ergebnis für get_size ([d1, d2, d1]) - wir erhalten 871 Bytes, nur ein bisschen mehr, d. H. Python ist intelligent genug, um nicht ein zweites Mal Speicher für dasselbe Objekt zuzuweisen.
Nun wenden wir uns dem zweiten Teil der Frage zu: Ist es möglich, den Speicherverbrauch zu reduzieren? Ja, das kannst du. Python ist ein Interpreter, und wir können unsere Klasse jederzeit erweitern, indem wir beispielsweise ein neues Feld hinzufügen:
d1 = DataItem("Alex", 42, "-") print ("get_size(d1):", get_size(d1)) d1.weight = 66 print ("get_size(d1):", get_size(d1))
Das ist großartig, aber wenn wir diese Funktionalität
nicht benötigen , können wir den Interpreter zwingen, die Objekte der Klasse mithilfe der Direktive __slots__ aufzulisten:
class DataItem(object): __slots__ = ['name', 'age', 'address'] def __init__(self, name, age, address): self.name = name self.age = age self.address = address
Weitere
Informationen finden Sie in der Dokumentation (
RTFM ), in der es heißt, dass "__slots__ es uns ermöglicht, Datenelemente (wie Eigenschaften) explizit zu deklarieren und die Erstellung von __dict__ und __weakref__ zu verweigern. Der durch die Verwendung von __dict__ eingesparte Speicherplatz
kann erheblich sein ".
Überprüfen Sie: Ja, wirklich signifikant, get_size (d1) gibt ... 64 Bytes anstelle von 460 zurück, d. H. 7 mal weniger. Als Bonus werden Objekte etwa 20% schneller erstellt (siehe den ersten Screenshot des Artikels).
Leider wird bei wirklicher Verwendung ein so großer Speichergewinn nicht auf andere Gemeinkosten zurückzuführen sein. Erstellen wir ein Array für 100.000, indem wir einfach Elemente hinzufügen und den Speicherverbrauch ermitteln:
data = [] for p in range(100000): data.append(DataItem("Alex", 42, "middle of nowhere")) snapshot = tracemalloc.take_snapshot() top_stats = snapshot.statistics('lineno') total = sum(stat.size for stat in top_stats) print("Total allocated size: %.1f MB" % (total / (1024*1024)))
Wir haben 16,8 MB ohne __slots__ und 6,9 MB damit. Natürlich nicht siebenmal, aber trotzdem recht gut, da die Codeänderung minimal war.
Nun zu den Mängeln. Das Aktivieren von __slots__ verbietet die Erstellung aller Elemente, einschließlich __dict__, was bedeutet, dass beispielsweise ein solcher Code zum Übersetzen einer Struktur in json nicht funktioniert:
def toJSON(self): return json.dumps(self.__dict__)
Es ist jedoch einfach zu beheben. Generieren Sie Ihr Diktat einfach programmgesteuert und sortieren Sie alle Elemente in der Schleife:
def toJSON(self): data = dict() for var in self.__slots__: data[var] = getattr(self, var) return json.dumps(data)
Es wird auch unmöglich sein, der Klasse dynamisch neue Variablen hinzuzufügen, aber in meinem Fall war dies nicht erforderlich.
Und der letzte Test für heute. Es ist interessant zu sehen, wie viel Speicher das gesamte Programm benötigt. Fügen Sie am Ende des Programms eine Endlosschleife hinzu, damit es nicht geschlossen wird, und sehen Sie den Speicherverbrauch im Windows-Task-Manager.
Ohne __slots__:
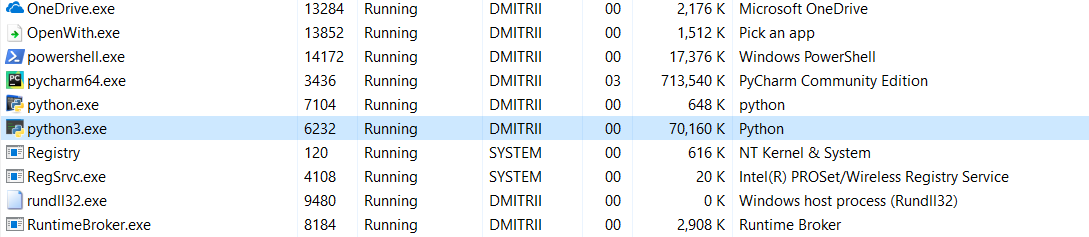
16,8 MB wurden auf wundersame Weise (Bearbeitung - eine Erklärung des Wunders unten) auf 70 MB (ich hoffe, C-Programmierer sind noch nicht auf den Bildschirm zurückgekehrt?).
Mit aktivierten __slots__:

Aus 6,9 MB wurden 27 MB ... schließlich haben wir Speicherplatz gespart. 27 MB statt 70 MB sind nicht so schlecht für das Ergebnis des Hinzufügens einer Codezeile.
Bearbeiten : In den Kommentaren (danke an robert_ayrapetyan für den Test) wurde vorgeschlagen, dass die Tracemalloc-Debugging-Bibliothek viel zusätzlichen Speicherplatz beansprucht. Anscheinend werden
jedem erstellten Objekt zusätzliche Elemente hinzugefügt. Wenn Sie es deaktivieren, ist der Gesamtspeicherverbrauch viel geringer. Der Screenshot zeigt zwei Optionen:
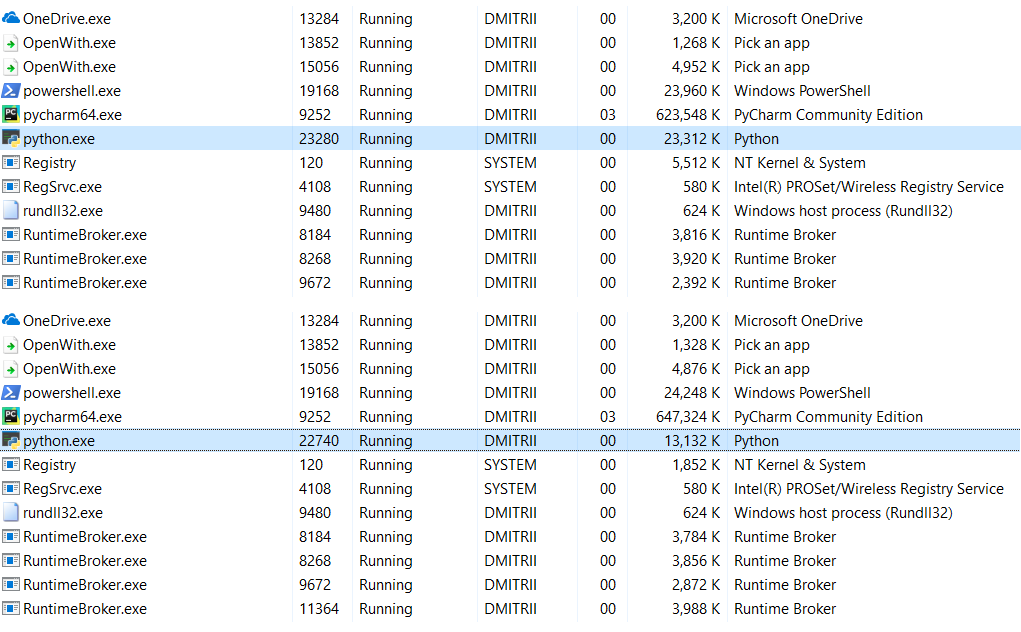
Was tun, wenn Sie noch mehr Speicherplatz sparen müssen? Dies ist mit der
Numpy- Bibliothek möglich, mit der Sie Strukturen im C-Stil erstellen können. In meinem Fall wäre jedoch eine tiefere Verfeinerung des Codes erforderlich, und die erste Methode hat sich als ausreichend erwiesen.
Es ist seltsam, dass die Verwendung von __slots__ bei Habré nie im Detail untersucht wurde. Ich hoffe, dieser Artikel wird diese Lücke ein wenig füllen.
Anstelle einer Schlussfolgerung.
Dieser Artikel scheint Pythons Anti-Werbung zu sein, ist es aber überhaupt nicht. Python ist sehr zuverlässig (Sie müssen sich
sehr bemühen, ein Python-Programm zu löschen), eine Sprache, die leicht lesbar und leicht zu schreiben ist. Diese Vorteile überwiegen in vielen Fällen die Nachteile. Wenn Sie jedoch maximale Leistung und Effizienz benötigen, können Sie in C ++ geschriebene Bibliotheken wie numpy verwenden, die recht schnell und effizient mit Daten arbeiten.
Vielen Dank für Ihre Aufmerksamkeit und guten Code :)