Als ich mit Verbesserungen für das Prognosemodell von
Guess.js experimentierte, begann ich mich eingehend mit Deep Learning zu befassen: wiederkehrende neuronale Netze (RNNs), insbesondere LSTMs, aufgrund ihrer
„unangemessenen Wirksamkeit“ in dem Bereich, in dem Guess.js arbeitet. Gleichzeitig fing ich an, mit Faltungs-Neuronalen Netzen (CNNs) herumzuspielen, die auch häufig für Zeitreihen verwendet werden. CNNs werden üblicherweise zum Klassifizieren, Erkennen und Erkennen von Bildern verwendet.
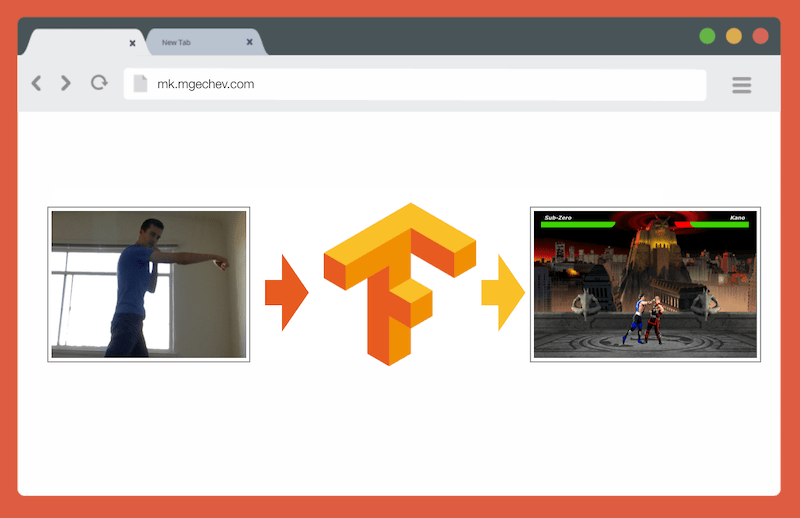 Verwalten von MK.js mit TensorFlow.js
Verwalten von MK.js mit TensorFlow.jsDer Quellcode für diesen Artikel und MK.js befinden sich auf meinem GitHub . Ich habe keinen Trainingsdatensatz veröffentlicht, aber Sie können Ihren eigenen erstellen und das Modell wie unten beschrieben trainieren!
Nachdem ich mit CNN gespielt hatte, erinnerte ich mich an ein
Experiment, das ich vor einigen Jahren durchgeführt hatte, als Browserentwickler die
getUserMedia API veröffentlichten. Darin diente die Kamera des Benutzers als Controller zum Spielen des kleinen JavaScript-Klons von Mortal Kombat 3. Sie finden dieses Spiel im
GitHub-Repository . Als Teil des Experiments habe ich einen grundlegenden Positionierungsalgorithmus implementiert, der das Bild in die folgenden Klassen klassifiziert:
- Linker oder rechter Schlag
- Linker oder rechter Kick
- Schritte nach links und rechts
- Kniebeugen
- Keine der oben genannten
Der Algorithmus ist so einfach, dass ich ihn in wenigen Sätzen erklären kann:
Der Algorithmus fotografiert den Hintergrund. Sobald der Benutzer im Frame erscheint, berechnet der Algorithmus die Differenz zwischen dem Hintergrund und dem aktuellen Frame mit dem Benutzer. So wird die Position der Benutzerfigur bestimmt. Der nächste Schritt besteht darin, den Körper des Benutzers in Weiß auf Schwarz anzuzeigen. Danach werden vertikale und horizontale Histogramme erstellt, die die Werte für jedes Pixel summieren. Basierend auf dieser Berechnung bestimmt der Algorithmus die aktuelle Position des Körpers.
Das Video zeigt, wie das Programm funktioniert.
GitHub- Quellcode.
Obwohl der winzige MK-Klon erfolgreich funktioniert hat, ist der Algorithmus alles andere als perfekt. Ein Rahmen mit Hintergrund ist erforderlich. Für einen ordnungsgemäßen Betrieb muss der Hintergrund während der Ausführung des Programms dieselbe Farbe haben. Eine solche Einschränkung bedeutet, dass Änderungen in Licht, Schatten und anderen Dingen stören und zu einem ungenauen Ergebnis führen. Schließlich erkennt der Algorithmus die Aktion nicht; Er klassifiziert den neuen Rahmen nur als die Position des Körpers aus einem vordefinierten Satz.
Dank des Fortschritts in der Web-API, nämlich WebGL, habe ich mich entschlossen, durch Anwenden von TensorFlow.js zu dieser Aufgabe zurückzukehren.
Einführung
In diesem Artikel werde ich meine Erfahrungen bei der Erstellung eines Algorithmus zur Klassifizierung von Körperpositionen mithilfe von TensorFlow.js und MobileNet teilen. Betrachten Sie die folgenden Themen:
- Sammlung von Trainingsdaten zur Bildklassifizierung
- Datenerweiterung mit imgaug
- Lernen mit MobileNet übertragen
- Binäre Klassifikation und N-Primärklassifikation
- Trainieren Sie das Bildklassifizierungsmodell von TensorFlow.js in Node.js und verwenden Sie es in einem Browser
- Ein paar Worte zur Klassifizierung von Aktionen mit LSTM
In diesem Artikel reduzieren wir das Problem auf die Bestimmung der Position des Körpers anhand eines Frames, im Gegensatz zum Erkennen von Aktionen anhand einer Folge von Frames. Wir werden mit einem Lehrer ein Modell für tiefes Lernen entwickeln, das auf der Grundlage des Bildes von der Webcam des Benutzers die Bewegungen einer Person bestimmt: Tritt, Bein oder nichts davon.
Am Ende des Artikels können wir ein Modell für das Spielen von
MK.js erstellen :

Zum besseren Verständnis des Artikels sollte der Leser mit den grundlegenden Konzepten von Programmierung und JavaScript vertraut sein. Ein grundlegendes Verständnis von tiefem Lernen ist ebenfalls nützlich, aber nicht notwendig.
Datenerfassung
Die Genauigkeit des Deep-Learning-Modells hängt stark von der Qualität der Daten ab. Wir müssen uns bemühen, wie in der Produktion einen umfangreichen Datensatz zu sammeln.
Unser Modell sollte Schläge und Tritte erkennen können. Dies bedeutet, dass wir Bilder von drei Kategorien sammeln müssen:
In diesem Experiment halfen mir zwei Freiwillige (
@lili_vs und
@gsamokovarov ) beim Sammeln von Fotos. Wir haben 5 QuickTime-Videos auf meinem MacBook Pro aufgenommen, die jeweils 2-4 Kicks und 2-4 Kicks enthalten.
Dann extrahieren wir mit ffmpeg einzelne Frames aus den Videos und speichern sie als
jpg Bilder:
ffmpeg -i video.mov $filename%03d.jpgUm den obigen Befehl auszuführen, müssen Sie zuerst
ffmpeg auf dem Computer
installieren .
Wenn wir das Modell trainieren möchten, müssen wir die Eingabedaten und die entsprechenden Ausgabedaten bereitstellen, aber zu diesem Zeitpunkt haben wir nur eine Reihe von Bildern von drei Personen in verschiedenen Posen. Um die Daten zu strukturieren, müssen Sie Frames in drei Kategorien einteilen: Schläge, Tritte und andere. Für jede Kategorie wird ein separates Verzeichnis erstellt, in das alle entsprechenden Bilder verschoben werden.
Daher sollte es in jedem Verzeichnis ungefähr 200 Bilder geben, die den folgenden ähnlich sind:

Bitte beachten Sie, dass das Verzeichnis "Sonstige" viel mehr Bilder enthält, da relativ wenige Bilder Fotos von Schlägen und Tritten enthalten und in den verbleibenden Bildern Personen das Video laufen, sich umdrehen oder steuern. Wenn wir zu viele Bilder einer Klasse haben, laufen wir Gefahr, das Modell zu unterrichten, das auf diese bestimmte Klasse ausgerichtet ist. In diesem Fall kann das neuronale Netzwerk bei der Klassifizierung eines Bildes mit Auswirkung immer noch die Klasse „Andere“ bestimmen. Um diese Verzerrung zu verringern, können Sie einige Fotos aus dem Verzeichnis "Andere" entfernen und das Modell mit einer gleichen Anzahl von Bildern aus jeder Kategorie trainieren.
Der
1.jpg 2.jpg weisen wir die Nummern in den Katalognummern von
1 bis
190 , sodass das erste Bild
1.jpg , das zweite
2.jpg usw. ist.
Wenn wir das Modell in nur 600 Fotos trainieren, die in derselben Umgebung mit denselben Personen aufgenommen wurden, erreichen wir keine sehr hohe Genauigkeit. Um das Beste aus unseren Daten herauszuholen, erstellen Sie am besten einige zusätzliche Stichproben mithilfe der Datenerweiterung.
Datenerweiterung
Datenerweiterung ist eine Technik, die die Anzahl der Datenpunkte erhöht, indem neue Punkte aus einem vorhandenen Satz synthetisiert werden. In der Regel wird Augmentation verwendet, um die Größe und Vielfalt des Trainingssatzes zu erhöhen. Wir übertragen die Originalbilder in die Pipeline der Transformationen, die neue Bilder erstellen. Sie können sich den Transformationen nicht zu aggressiv nähern: Aus einem Schlag sollten nur andere Handschläge generiert werden.
Akzeptable Transformationen sind Rotation, Farbinversion, Unschärfe usw. Es gibt ausgezeichnete Open-Source-Tools zur Datenerweiterung. Zum Zeitpunkt des Schreibens dieses Artikels in JavaScript gab es nicht allzu viele Optionen, daher habe ich die in Python -
imgaug implementierte Bibliothek
verwendet . Es verfügt über eine Reihe von Augmentern, die probabilistisch angewendet werden können.
Hier ist die Datenerweiterungslogik für dieses Experiment:
np.random.seed(44) ia.seed(44) def main(): for i in range(1, 191): draw_single_sequential_images(str(i), "others", "others-aug") for i in range(1, 191): draw_single_sequential_images(str(i), "hits", "hits-aug") for i in range(1, 191): draw_single_sequential_images(str(i), "kicks", "kicks-aug") def draw_single_sequential_images(filename, path, aug_path): image = misc.imresize(ndimage.imread(path + "/" + filename + ".jpg"), (56, 100)) sometimes = lambda aug: iaa.Sometimes(0.5, aug) seq = iaa.Sequential( [ iaa.Fliplr(0.5),
Dieses Skript verwendet die Hauptmethode mit drei
for Schleifen - eine für jede Bildkategorie. In jeder Iteration, in jeder der Schleifen, rufen wir die Methode
draw_single_sequential_images : Das erste Argument ist der Dateiname, das zweite ist der Pfad, das dritte ist das Verzeichnis, in dem das Ergebnis gespeichert werden soll.
Danach lesen wir das Image von der Festplatte und wenden eine Reihe von Transformationen darauf an. Ich habe die meisten Transformationen im obigen Code-Snippet dokumentiert, daher werden wir sie nicht wiederholen.
Für jedes Bild werden 16 weitere Bilder erstellt. Hier ist ein Beispiel, wie sie aussehen:

Bitte beachten Sie, dass wir im obigen Skript Bilder auf
100x56 Pixel
100x56 . Wir tun dies, um die Datenmenge und dementsprechend die Anzahl der Berechnungen zu reduzieren, die unser Modell während des Trainings und der Auswertung durchführt.
Modellbau
Erstellen Sie jetzt ein Modell für die Klassifizierung!
Da es sich um Bilder handelt, verwenden wir ein Faltungsnetzwerk (CNN). Es ist bekannt, dass diese Netzwerkarchitektur zur Bilderkennung, Objekterkennung und Klassifizierung geeignet ist.
Lerntransfer
Das Bild unten zeigt das beliebte CNN VGG-16, mit dem Bilder klassifiziert werden.
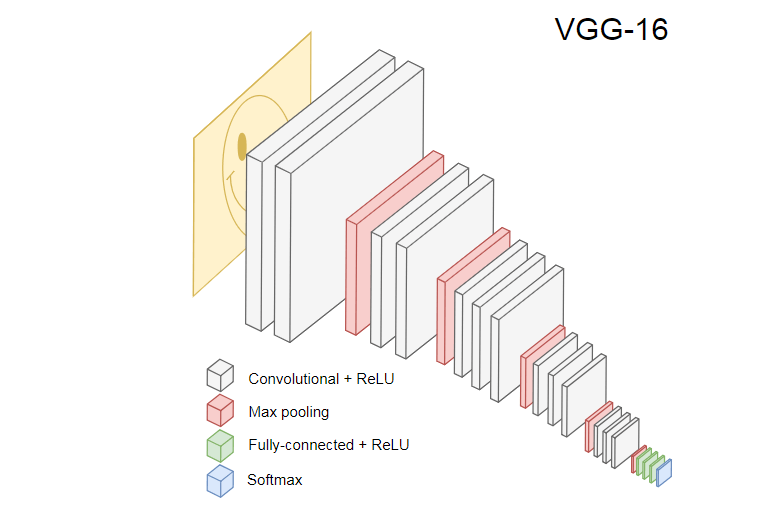
Das neuronale Netzwerk VGG-16 erkennt 1000 Bildklassen. Es hat 16 Ebenen (ohne die Pooling- und Ausgabeebenen). Ein solches mehrschichtiges Netzwerk ist in der Praxis schwer zu trainieren. Dies erfordert einen großen Datensatz und viele Stunden Schulung.
Versteckte Ebenen trainierten CNN erkennen verschiedene Elemente von Bildern aus dem Trainingssatz, beginnend an den Rändern, bis hin zu komplexeren Elementen wie Formen, einzelnen Objekten usw. Ein trainiertes CNN im Stil von VGG-16 zum Erkennen eines großen Satzes von Bildern muss verborgene Ebenen haben, die viele Funktionen aus dem Trainingssatz gelernt haben. Solche Funktionen sind den meisten Bildern gemeinsam und werden dementsprechend für verschiedene Aufgaben wiederverwendet.
Mit dem Lerntransfer können Sie ein vorhandenes und geschultes Netzwerk wiederverwenden. Wir können die Ausgabe von jeder der Schichten des vorhandenen Netzwerks nehmen und als Eingabe in das neue neuronale Netzwerk übertragen. Durch das Unterrichten des neu geschaffenen neuronalen Netzwerks kann im Laufe der Zeit gelernt werden, neue Merkmale einer höheren Ebene zu erkennen und Bilder aus Klassen, die das ursprüngliche Modell noch nie zuvor gesehen hatte, korrekt zu klassifizieren.
Nehmen Sie für unsere Zwecke das neuronale
MobileNet- Netzwerk aus dem
Paket @ tensorflow-models / mobilet . MobileNet ist genauso leistungsfähig wie VGG-16, aber viel kleiner, was die direkte Verteilung, dh die Netzwerkausbreitung (Forward Propagation), beschleunigt und die Downloadzeit im Browser verkürzt. MobileNet wurde anhand des
ILSVRC-2012-CLS-Bildklassifizierungsdatensatzes geschult.
Bei der Entwicklung eines Modells mit Lerntransfer haben wir zwei Möglichkeiten:
- Die Ausgabe, von welcher Ebene des Quellmodells als Eingabe für das Zielmodell verwendet werden soll.
- Wie viele Ebenen aus dem Zielmodell werden wir gegebenenfalls trainieren?
Der erste Punkt ist sehr wichtig. Abhängig von der ausgewählten Ebene erhalten wir Features auf einer niedrigeren oder höheren Abstraktionsebene als Eingabe für unser neuronales Netzwerk.
Wir werden keine Schichten von MobileNet trainieren. Wir
global_average_pooling2d_1 Ausgabe von
global_average_pooling2d_1 und übergeben sie als Eingabe an unser kleines Modell. Warum habe ich diese bestimmte Ebene gewählt? Empirisch. Ich habe einige Tests durchgeführt, und diese Ebene funktioniert recht gut.
Modelldefinition
Die anfängliche Aufgabe bestand darin, das Bild in drei Klassen zu klassifizieren: Hand, Fuß und andere Bewegungen. Lösen wir zunächst das kleinere Problem: Wir werden feststellen, ob sich im Rahmen ein Handschlag befindet oder nicht. Dies ist ein typisches Problem der binären Klassifizierung. Zu diesem Zweck können wir das folgende Modell definieren:
import * as tf from '@tensorflow/tfjs'; const model = tf.sequential(); model.add(tf.layers.inputLayer({ inputShape: [1024] })); model.add(tf.layers.dense({ units: 1024, activation: 'relu' })); model.add(tf.layers.dense({ units: 1, activation: 'sigmoid' })); model.compile({ optimizer: tf.train.adam(1e-6), loss: tf.losses.sigmoidCrossEntropy, metrics: ['accuracy'] });
Ein solcher Code definiert ein einfaches Modell, eine Schicht mit
1024 Einheiten und
ReLU Aktivierung sowie eine Ausgabeeinheit, die die
sigmoid Aktivierungsfunktion durchläuft. Letzteres gibt eine Zahl von
0 bis
1 , abhängig von der Wahrscheinlichkeit eines Handschlags in diesem Rahmen.
Warum habe ich
1024 Einheiten für die zweite Stufe und eine Trainingsgeschwindigkeit von
1e-6 ? Nun, ich habe verschiedene Optionen ausprobiert und festgestellt, dass solche Optionen am besten funktionieren. Die Spear-Methode scheint nicht der beste Ansatz zu sein, aber in hohem Maße funktionieren Hyperparameter-Einstellungen in Deep Learning - basierend auf unserem Verständnis des Modells verwenden wir die Intuition, um orthogonale Parameter zu aktualisieren und empirisch zu überprüfen, wie das Modell funktioniert.
Die
compile kompiliert die Ebenen und bereitet das Modell für das Training und die Bewertung vor. Hier geben wir bekannt, dass wir den
adam Optimierungsalgorithmus verwenden möchten. Wir erklären auch, dass wir den Verlust (Verlust) aus der Kreuzentropie berechnen und angeben, dass wir die Genauigkeit des Modells bewerten möchten. TensorFlow.js berechnet dann die Genauigkeit anhand der folgenden Formel:
Accuracy = (True Positives + True Negatives) / (Positives + Negatives)Wenn Sie Schulungen vom ursprünglichen MobileNet-Modell übertragen, müssen Sie diese zuerst herunterladen. Da es nicht praktikabel ist, unser Modell mit mehr als 3.000 Bildern in einem Browser zu trainieren, verwenden wir Node.js und laden das neuronale Netzwerk aus der Datei.
Laden Sie MobileNet
hier herunter. Der Katalog enthält die Datei
model.json , die die Architektur des Modells enthält - Ebenen, Aktivierungen usw. Die restlichen Dateien enthalten Modellparameter. Sie können das Modell mit diesem Code aus einer Datei laden:
export const loadModel = async () => { const mn = new mobilenet.MobileNet(1, 1); mn.path = `file://PATH/TO/model.json`; await mn.load(); return (input): tf.Tensor1D => mn.infer(input, 'global_average_pooling2d_1') .reshape([1024]); };
Beachten Sie, dass wir in der
loadModel Methode eine Funktion zurückgeben, die einen eindimensionalen Tensor als Eingabe akzeptiert und
mn.infer(input, Layer) zurückgibt. Die
infer Methode verwendet einen Tensor und eine Ebene als Argumente. Die Ebene bestimmt, von welcher verborgenen Ebene die Ausgabe erfolgen soll. Wenn Sie
model.json öffnen und
global_average_pooling2d_1 global_average_pooling2d_1 global_average_pooling2d_1 , finden Sie einen solchen Namen auf einer der Ebenen.
Jetzt müssen Sie einen Datensatz zum Trainieren des Modells erstellen. Dazu müssen wir alle Bilder in MobileNet durch die
infer Methode führen und ihnen Beschriftungen zuweisen:
1 für Bilder mit Strichen und
0 für Bilder ohne Striche:
const punches = require('fs') .readdirSync(Punches) .filter(f => f.endsWith('.jpg')) .map(f => `${Punches}/${f}`); const others = require('fs') .readdirSync(Others) .filter(f => f.endsWith('.jpg')) .map(f => `${Others}/${f}`); const ys = tf.tensor1d( new Array(punches.length).fill(1) .concat(new Array(others.length).fill(0))); const xs: tf.Tensor2D = tf.stack( punches .map((path: string) => mobileNet(readInput(path))) .concat(others.map((path: string) => mobileNet(readInput(path)))) ) as tf.Tensor2D;
Im obigen Code lesen wir zuerst die Dateien in Verzeichnissen mit und ohne Treffer. Dann bestimmen wir den eindimensionalen Tensor, der die Ausgabeetiketten enthält. Wenn wir
n Bilder mit Strichen und
m andere Bilder haben, hat der Tensor
n Elemente mit einem Wert von 1 und
m Elemente mit einem Wert von 0.
In
xs infer wir
infer Ergebnisse des Aufrufs der
infer Methode für einzelne Bilder zusammen. Beachten Sie, dass wir für jedes Bild die
readInput Methode aufrufen. Hier ist seine Implementierung:
export const readInput = img => imageToInput(readImage(img), TotalChannels); const readImage = path => jpeg.decode(fs.readFileSync(path), true); const imageToInput = image => { const values = serializeImage(image); return tf.tensor3d(values, [image.height, image.width, 3], 'int32'); }; const serializeImage = image => { const totalPixels = image.width * image.height; const result = new Int32Array(totalPixels * 3); for (let i = 0; i < totalPixels; i++) { result[i * 3 + 0] = image.data[i * 4 + 0]; result[i * 3 + 1] = image.data[i * 4 + 1]; result[i * 3 + 2] = image.data[i * 4 + 2]; } return result; };
readInput ruft zuerst die Funktion
readImage und delegiert anschließend den Aufruf an
imageToInput . Die Funktion
readImage liest ein Image von der Festplatte und decodiert dann jpg mit dem Paket
jpeg-js aus dem Puffer. In
imageToInput konvertieren wir das Bild in einen dreidimensionalen Tensor.
Infolgedessen sollte für jedes
i von
0 bis
TotalImages ys[i] gleich
1 wenn
xs[i] dem Bild mit einem Treffer entspricht, andernfalls
0 .
Modelltraining
Jetzt ist das Modell bereit für das Training! Rufen Sie die
fit :
await model.fit(xs, ys, { epochs: Epochs, batchSize: parseInt(((punches.length + others.length) * BatchSize).toFixed(0)), callbacks: { onBatchEnd: async (_, logs) => { console.log('Cost: %s, accuracy: %s', logs.loss.toFixed(5), logs.acc.toFixed(5)); await tf.nextFrame(); } } });
Die obigen Codeaufrufe
fit zu drei Argumenten:
xs , ys und das Konfigurationsobjekt. Im Konfigurationsobjekt legen wir fest, wie viele Epochen das Modell, die Paketgröße und der Rückruf, den TensorFlow.js nach der Verarbeitung jedes Pakets generiert, trainiert werden.
Die Paketgröße bestimmt
xs und
ys für das Training des Modells in einer Ära. Für jede Epoche wählt TensorFlow.js eine Teilmenge von
xs und den entsprechenden Elementen aus
ys , führt eine direkte Verteilung durch, empfängt die Ausgabe der Schicht mit
sigmoid Aktivierung und führt dann basierend auf dem Verlust eine Optimierung unter Verwendung des
adam Algorithmus durch.
Nach dem Starten des Trainingsskripts sehen Sie ein ähnliches Ergebnis wie das folgende:
Kosten: 0,84212, Genauigkeit: 1,00000
eta = 0,3> ---------- acc = 1,00 Verlust = 0,84 Kosten: 0,79740, Genauigkeit: 1,00000
eta = 0,2 => --------- acc = 1,00 Verlust = 0,80 Kosten: 0,81533, Genauigkeit: 1,00000
eta = 0,2 ==> -------- acc = 1,00 Verlust = 0,82 Kosten: 0,64303, Genauigkeit: 0,50000
eta = 0,2 ===> ------- acc = 0,50 Verlust = 0,64 Kosten: 0,51377, Genauigkeit: 0,00000
eta = 0,2 ====> ------ acc = 0,00 Verlust = 0,51 Kosten: 0,46473, Genauigkeit: 0,50000
eta = 0,1 =====> ----- acc = 0,50 Verlust = 0,46 Kosten: 0,50872, Genauigkeit: 0,00000
eta = 0,1 ======> ---- acc = 0,00 Verlust = 0,51 Kosten: 0,62556, Genauigkeit: 1,00000
eta = 0,1 =======> --- acc = 1,00 Verlust = 0,63 Kosten: 0,65133, Genauigkeit: 0,50000
eta = 0,1 ========> - acc = 0,50 Verlust = 0,65 Kosten: 0,63824, Genauigkeit: 0,50000
eta = 0.0 ===========>
293 ms 14675us / Schritt - acc = 0,60 Verlust = 0,65
Epoche 3/50
Kosten: 0,44661, Genauigkeit: 1,00000
eta = 0,3> ---------- acc = 1,00 Verlust = 0,45 Kosten: 0,78060, Genauigkeit: 1,00000
eta = 0,3 => --------- acc = 1,00 Verlust = 0,78 Kosten: 0,79208, Genauigkeit: 1,00000
eta = 0,3 ==> -------- acc = 1,00 Verlust = 0,79 Kosten: 0,49072, Genauigkeit: 0,50000
eta = 0,2 ===> ------- acc = 0,50 Verlust = 0,49 Kosten: 0,62232, Genauigkeit: 1,00000
eta = 0,2 ====> ------ acc = 1,00 Verlust = 0,62 Kosten: 0,82899, Genauigkeit: 1,00000
eta = 0,2 =====> ----- acc = 1,00 Verlust = 0,83 Kosten: 0,67629, Genauigkeit: 0,50000
eta = 0,1 ======> ---- acc = 0,50 Verlust = 0,68 Kosten: 0,62621, Genauigkeit: 0,50000
eta = 0,1 =======> --- acc = 0,50 Verlust = 0,63 Kosten: 0,46077, Genauigkeit: 1,00000
eta = 0,1 ========> - acc = 1,00 Verlust = 0,46 Kosten: 0,62076, Genauigkeit: 1,00000
eta = 0.0 ===========>
304 ms 15221us / Schritt - acc = 0,85 Verlust = 0,63
Beachten Sie, wie die Genauigkeit mit der Zeit zunimmt und der Verlust abnimmt.
In meinem Datensatz zeigte das Modell nach dem Training eine Genauigkeit von 92%. Beachten Sie, dass die Genauigkeit aufgrund der kleinen Trainingsdaten möglicherweise nicht sehr hoch ist.
Ausführen des Modells in einem Browser
Im vorherigen Abschnitt haben wir das binäre Klassifizierungsmodell trainiert. Führen Sie es jetzt in einem Browser aus und stellen Sie eine Verbindung zu
MK.js her !
const video = document.getElementById('cam'); const Layer = 'global_average_pooling2d_1'; const mobilenetInfer = m => (p): tf.Tensor<tf.Rank> => m.infer(p, Layer); const canvas = document.getElementById('canvas'); const scale = document.getElementById('crop'); const ImageSize = { Width: 100, Height: 56 }; navigator.mediaDevices .getUserMedia({ video: true, audio: false }) .then(stream => { video.srcObject = stream; });
Der obige Code enthält mehrere Erklärungen:
video enthält einen Link zum HTML5 video auf der SeiteLayer enthält den Namen des Layers aus MobileNet, von dem die Ausgabe abgerufen und als Eingabe für unser Modell übergeben werden sollmobilenetInfer- Eine Funktion, die eine Instanz von MobileNet verwendet und eine andere Funktion zurückgibt. Die zurückgegebene Funktion akzeptiert Eingaben und gibt die entsprechende Ausgabe von der angegebenen MobileNet-Schicht zurück.canvasGibt das Element an HTML5 canvas, mit dem Frames aus dem Video extrahiert werdenscale- eine andere canvas, mit der einzelne Frames skaliert werden
Danach erhalten wir den Videostream von der Kamera des Benutzers und legen ihn als Quelle für das Element fest video.Der nächste Schritt besteht darin, einen Graustufenfilter zu implementieren, canvasder seinen Inhalt akzeptiert und konvertiert: const grayscale = (canvas: HTMLCanvasElement) => { const imageData = canvas.getContext('2d').getImageData(0, 0, canvas.width, canvas.height); const data = imageData.data; for (let i = 0; i < data.length; i += 4) { const avg = (data[i] + data[i + 1] + data[i + 2]) / 3; data[i] = avg; data[i + 1] = avg; data[i + 2] = avg; } canvas.getContext('2d').putImageData(imageData, 0, 0); };
Als nächsten Schritt verbinden wir das Modell mit MK.js: let mobilenet: (p: any) => tf.Tensor<tf.Rank>; tf.loadModel('http://localhost:5000/model.json').then(model => { mobileNet .load() .then((mn: any) => mobilenet = mobilenetInfer(mn)) .then(startInterval(mobilenet, model)); });
Im obigen Code laden wir zuerst das oben trainierte Modell und laden dann MobileNet herunter. Wir übergeben MobileNet an die Methode mobilenetInfer, um die Ausgabe der verborgenen Netzwerkschicht zu berechnen. Danach rufen wir die Methode startIntervalmit zwei Netzwerken als Argumente auf. const startInterval = (mobilenet, model) => () => { setInterval(() => { canvas.getContext('2d').drawImage(video, 0, 0); grayscale(scale .getContext('2d') .drawImage( canvas, 0, 0, canvas.width, canvas.width / (ImageSize.Width / ImageSize.Height), 0, 0, ImageSize.Width, ImageSize.Height )); const [punching] = Array.from(( model.predict(mobilenet(tf.fromPixels(scale))) as tf.Tensor1D) .dataSync() as Float32Array); const detect = (window as any).Detect; if (punching >= 0.4) detect && detect.onPunch(); }, 100); };
Der interessanteste Teil beginnt in der Methode startInterval! Zuerst führen wir ein Intervall aus, in dem jeder 100mseine anonyme Funktion aufruft. Darin wird das canvasVideo mit dem aktuellen Frame zuerst darüber gerendert. Dann reduzieren wir die Rahmengröße auf 100x56und wenden einen Graustufenfilter darauf an.Der nächste Schritt besteht darin, den Frame an MobileNet zu übertragen, die Ausgabe von der gewünschten verborgenen Ebene abzurufen und als Eingabe für die Methode predictunseres Modells zu übertragen. Das gibt einen Tensor mit einem Element zurück. Mit erhalten dataSyncwir den Wert vom Tensor und weisen ihn einer Konstanten zu punching.Schließlich prüfen wir: Wenn die Wahrscheinlichkeit eines Handschlags größer ist 0.4, rufen wir die onPunchglobale Objektmethode auf Detect. MK.js stellt ein globales Objekt mit drei Methoden bereit:onKick, onPunchUnd onStanddass wir verwendet werden können , einen der Charaktere zu steuern.Fertig!
Hier ist das Ergebnis!
Tritt- und Armerkennung mit N-Klassifizierung
Im nächsten Abschnitt werden wir ein intelligenteres Modell erstellen: ein neuronales Netzwerk, das Schläge, Tritte und andere Bilder erkennt. Beginnen wir dieses Mal mit der Vorbereitung des Trainingssets: const punches = require('fs') .readdirSync(Punches) .filter(f => f.endsWith('.jpg')) .map(f => `${Punches}/${f}`); const kicks = require('fs') .readdirSync(Kicks) .filter(f => f.endsWith('.jpg')) .map(f => `${Kicks}/${f}`); const others = require('fs') .readdirSync(Others) .filter(f => f.endsWith('.jpg')) .map(f => `${Others}/${f}`); const ys = tf.tensor2d( new Array(punches.length) .fill([1, 0, 0]) .concat(new Array(kicks.length).fill([0, 1, 0])) .concat(new Array(others.length).fill([0, 0, 1])), [punches.length + kicks.length + others.length, 3] ); const xs: tf.Tensor2D = tf.stack( punches .map((path: string) => mobileNet(readInput(path))) .concat(kicks.map((path: string) => mobileNet(readInput(path)))) .concat(others.map((path: string) => mobileNet(readInput(path)))) ) as tf.Tensor2D;
Nach wie vor lesen wir zuerst die Kataloge mit Bildern von Schlägen von Hand, Fuß und anderen Bildern. Danach bilden wir im Gegensatz zum letzten Mal das erwartete Ergebnis in Form eines zweidimensionalen Tensors und nicht eindimensional. Wenn wir n Bilder mit einem Stempel, m Bilder mit einem Kick und k andere Bilder, die Tensor yswird nElemente des Wertes [1, 0, 0], mdie Elemente mit dem Wert [0, 1, 0]und kGegenstände mit Wert [0, 0, 1].Ein Vektor von nElementen, in dem es n - 1Elemente mit einem Wert 0und ein Element mit einem Wert gibt 1, nennen wir einen einheitlichen Vektor (One-Hot-Vektor).Danach bilden wir den EingangstensorxsStapeln der Ausgabe jedes Bildes aus MobileNet.Hier müssen Sie die Modelldefinition aktualisieren: const model = tf.sequential(); model.add(tf.layers.inputLayer({ inputShape: [1024] })); model.add(tf.layers.dense({ units: 1024, activation: 'relu' })); model.add(tf.layers.dense({ units: 3, activation: 'softmax' })); await model.compile({ optimizer: tf.train.adam(1e-6), loss: tf.losses.sigmoidCrossEntropy, metrics: ['accuracy'] });
Die einzigen zwei Unterschiede zum Vorgängermodell sind:- Die Anzahl der Einheiten in der Ausgabeebene
- Aktivierungen in der Ausgabeebene
Es gibt drei Einheiten in der Ausgabeebene, da wir drei verschiedene Kategorien von Bildern haben:Bei diesen drei Einheiten softmaxwird die Aktivierung ausgelöst , wodurch ihre Parameter in einen Tensor mit drei Werten umgewandelt werden. Warum drei Einheiten für die Ausgabeschicht? Jede der drei Werte für drei Klassen können durch zwei Bits dargestellt werden: 00, 01, 10. Die Summe der Werte des erstellten Tensors softmaxist 1, dh wir erhalten niemals 00, sodass wir keine Bilder einer der Klassen klassifizieren können.Nachdem 500ich das Modell im Laufe der Zeit trainiert hatte , erreichte ich eine Genauigkeit von ca. 92%! Das ist nicht schlecht, aber vergessen Sie nicht, dass das Training mit einem kleinen Datensatz durchgeführt wurde.Der nächste Schritt ist das Ausführen des Modells in einem Browser! Da die Logik dem Ausführen des Modells für die binäre Klassifizierung sehr ähnlich ist, sehen Sie sich den letzten Schritt an, in dem die Aktion basierend auf der Ausgabe des Modells ausgewählt wird: const [punch, kick, nothing] = Array.from((model.predict( mobilenet(tf.fromPixels(scaled)) ) as tf.Tensor1D).dataSync() as Float32Array); const detect = (window as any).Detect; if (nothing >= 0.4) return; if (kick > punch && kick >= 0.35) { detect.onKick(); return; } if (punch > kick && punch >= 0.35) detect.onPunch();
Zuerst rufen wir MobileNet mit einem reduzierten Rahmen in Graustufen auf, dann übertragen wir das Ergebnis unseres trainierten Modells. Das Modell gibt einen eindimensionalen Tensor zurück, den wir in Float32Arrayc konvertieren dataSync. Im nächsten Schritt wandeln wir Array.fromein typisiertes Array in ein JavaScript-Array um. Dann extrahieren wir die Wahrscheinlichkeiten, dass ein Schuss mit einer Hand, ein Tritt oder nichts auf dem Rahmen vorhanden ist.Wenn die Wahrscheinlichkeit des dritten Ergebnisses überschritten wird 0.4, kehren wir zurück. Andernfalls 0.32senden wir , wenn die Wahrscheinlichkeit eines Tritts höher ist, einen Trittbefehl an MK.js. Wenn die Wahrscheinlichkeit eines Tritts höher 0.32und höher ist als die Wahrscheinlichkeit eines Tritts, senden wir die Aktion eines Tritts.Im Allgemeinen ist das alles! Das Ergebnis ist unten dargestellt:
Aktionserkennung
Wenn Sie einen großen und vielfältigen Datensatz über Personen sammeln, die mit Händen und Füßen schlagen, können Sie ein Modell erstellen, das sich hervorragend für einzelne Frames eignet. Aber ist das genug? Was ist, wenn wir noch weiter gehen und zwei verschiedene Arten von Tritten unterscheiden wollen: von einer Kurve und von einem Rücken (Rücktritt).Wie in den folgenden Frames zu sehen ist, sehen beide Striche zu einem bestimmten Zeitpunkt aus einem bestimmten Winkel gleich aus:
 Wenn Sie jedoch die Leistung betrachten, sind die Bewegungen völlig unterschiedlich:
Wenn Sie jedoch die Leistung betrachten, sind die Bewegungen völlig unterschiedlich: Wie können Sie ein neuronales Netzwerk trainieren, um die Abfolge von Frames und nicht nur einen Frame zu analysieren?Zu diesem Zweck können wir eine andere Klasse neuronaler Netze untersuchen, die als wiederkehrende neuronale Netze (RNNs) bezeichnet werden. Zum Beispiel eignen sich RNNs hervorragend für die Arbeit mit Zeitreihen:
Wie können Sie ein neuronales Netzwerk trainieren, um die Abfolge von Frames und nicht nur einen Frame zu analysieren?Zu diesem Zweck können wir eine andere Klasse neuronaler Netze untersuchen, die als wiederkehrende neuronale Netze (RNNs) bezeichnet werden. Zum Beispiel eignen sich RNNs hervorragend für die Arbeit mit Zeitreihen:- Natural Language Processing (NLP), wobei jedes Wort vom vorherigen und nachfolgenden abhängt
- Vorhersage der nächsten Seite basierend auf Ihrem Browserverlauf
- Rahmenerkennung
Die Implementierung eines solchen Modells würde den Rahmen dieses Artikels sprengen. Schauen wir uns jedoch eine Beispielarchitektur an, um eine Vorstellung davon zu erhalten, wie all dies zusammenarbeitet.Die Kraft von RNN
Das folgende Diagramm zeigt das Modell der Erkennung von Aktionen: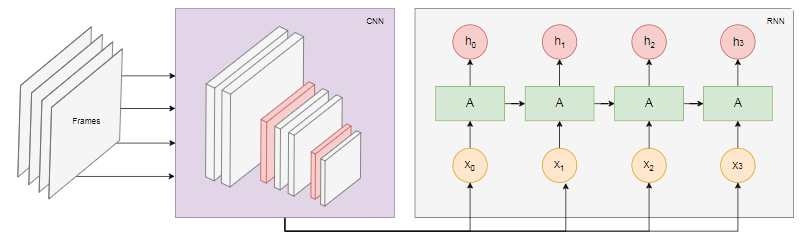 Wir nehmen die letzten
Wir nehmen die letzten nBilder aus dem Video und übertragen sie an CNN. Der CNN-Ausgang für jeden Rahmen wird als Eingangs-RNN übertragen. Ein wiederkehrendes neuronales Netzwerk bestimmt die Beziehungen zwischen einzelnen Frames und erkennt, welcher Aktion sie entsprechen.Fazit
In diesem Artikel haben wir ein Bildklassifizierungsmodell entwickelt. Zu diesem Zweck haben wir einen Datensatz gesammelt: Wir haben Videobilder extrahiert und sie manuell in drei Kategorien unterteilt. Dann wurden die Daten durch Hinzufügen von Bildern mit imgaug erweitert .Danach haben wir erklärt, was Lerntransfer ist, und das trainierte MobileNet- Modell aus dem @ tensorflow-models / mobilet- Paket für unsere Zwecke verwendet . Wir haben MobileNet aus einer Datei im Node.js-Prozess geladen und eine zusätzliche dichte Schicht trainiert, in der Daten aus der verborgenen MobileNet-Schicht eingespeist wurden. Nach dem Training haben wir eine Genauigkeit von mehr als 90% erreicht!Um dieses Modell in einem Browser zu verwenden, haben wir es zusammen mit MobileNet heruntergeladen und alle 100 ms damit begonnen, Frames von der Webcam des Benutzers zu kategorisieren. Wir haben das Modell mit dem Spiel verbundenMK.js und verwendete die Modellausgabe, um eines der Zeichen zu steuern.Schließlich haben wir uns angesehen, wie das Modell verbessert werden kann, indem es mit einem wiederkehrenden neuronalen Netzwerk kombiniert wird, um Aktionen zu erkennen.Ich hoffe, Ihnen hat dieses kleine Projekt nicht weniger gefallen als mir!