Mein Name ist Andrey Polyakov, ich bin der Leiter der API- und SDK-Dokumentationsgruppe bei Yandex. Heute möchte ich Ihnen einen Bericht mitteilen, den ich und meine Kollegin, die leitende Dokumentationsentwicklerin Julia Pivovarova, vor einigen Wochen beim sechsten Hyperbaton gelesen haben.
Svetlana Kayushina, Leiterin der Abteilung Dokumentation und Lokalisierung:
- Das Volumen des Programmcodes in der Welt ist in den letzten Jahren erheblich gewachsen und wächst weiter. Dies wirkt sich auf die Arbeit von technischen Redakteuren aus, die mit immer mehr Aufgaben bei der Entwicklung der Programmdokumentation und der Dokumentation von Code konfrontiert sind. Wir konnten dieses Thema nicht ignorieren, wir haben ihm einen ganzen Abschnitt gewidmet. Dies sind drei verwandte Berichte zur Vereinheitlichung der Softwareentwicklung. Ich lade unsere Spezialisten für die Dokumentation von Softwareschnittstellen und Bibliotheken zu Andrei Polyakov und Julia Pivovarova ein. Ich gebe ihnen das Wort.
- Hallo allerseits! Heute werden Julia und ich Ihnen erzählen, wie wir in Yandex einen neuen Blick auf die Dokumentation der API und des SDK bekommen haben. Der Bericht wird aus vier Teilen bestehen, der Überwachungsbericht, wir werden diskutieren, wir werden reden.
Lassen Sie uns über die Vereinheitlichung der API und des SDK sprechen, wie wir dazu gekommen sind, was wir dort gemacht haben. Wir werden die Erfahrungen mit der Verwendung eines Universalgenerators, eines für alle Sprachen, teilen und Ihnen erklären, warum er nicht zu uns passte, was die Fallstricke waren und warum wir auf die Erstellung von Dokumentationen durch native Generatoren umgestellt haben.
Am Ende werden wir beschreiben, wie unsere Prozesse aufgebaut wurden.
Beginnen wir mit der Vereinigung. Jeder denkt an die Vereinigung, wenn mehr als zwei Personen in einem Team sind: Jeder schreibt anders, jeder hat seine eigenen Ansätze, und das ist logisch. Es ist besser, alle Regeln am Strand zu besprechen, bevor Sie mit dem Schreiben von Dokumentationen beginnen, aber nicht jeder kann dies tun.
Wir haben eine Expertengruppe zusammengestellt, um unsere Dokumentation zu analysieren. Wir haben dies getan, um unsere Ansätze zu systematisieren. Jeder schreibt auf unterschiedliche Weise, und wir stimmen zu, im gleichen Stil zu schreiben. Dies ist der zweite Punkt, für den wir versuchen wollten, die Dokumentation einheitlich zu gestalten, damit der Benutzer eine Benutzererfahrung in der gesamten Yandex-Dokumentation hatte, nämlich in der technischen.
Die Arbeit war in drei Phasen unterteilt. Wir haben eine Beschreibung der Technologien zusammengestellt, die wir in Yandex verwenden. Wir haben versucht, diejenigen herauszustellen, die wir irgendwie vereinheitlichen können. Und bildete auch die allgemeine Struktur von Standarddokumenten und -vorlagen.

Kommen wir zur Beschreibung der Technologien. Wir begannen zu untersuchen, welche Technologien in Yandex verwendet werden. Es gibt so viele von ihnen, dass wir es satt haben, sie in eine Art Notizbuch zu schreiben, und deshalb haben wir nur die grundlegendsten ausgewählt, die am häufigsten verwendet werden und denen technische Redakteure am häufigsten begegnen, und begonnen, sie zu beschreiben.
Was versteht man unter Technologiebeschreibung? Wir haben die Hauptpunkte und das Wesen jeder Technologie identifiziert. Wenn wir über Programmiersprachen sprechen, dann ist dies eine Beschreibung von Entitäten wie einer Klasse, einer Eigenschaft, Schnittstellen usw. Wenn wir über Protokolle sprechen, dann beschreiben wir HTTP-Methoden, wir sprechen über das Format des Fehlercodes, des Antwortcodes usw., die wir erstellt haben ein Glossar, das folgende Dinge enthält: Begriffe auf Russisch, Begriffe auf Englisch, Nuancen der Verwendung. Zum Beispiel sprechen wir nicht über eine SDK-Methode, mit der Sie etwas tun können. Er tut etwas, wenn der Programmierer einen Stift zieht, gibt es eine Antwort.
Zusätzlich zu den Nuancen enthielt die Beschreibung auch Standardstrukturen, Standard-Sprachumdrehungen, die wir in der Dokumentation verwenden, damit der technische Redakteur einen bestimmten Wortlaut übernehmen und weiter verwenden kann.
Darüber hinaus schreiben technische Redakteure häufig Code, Snippets und Beispiele. Dazu haben wir auch unseren Styleguide für jede Technologie beschrieben. Wir haben uns an die Entwicklerhandbücher in Yandex gewandt. Wir haben auf den Designcode, die Beschreibung der Kommentare, die Einrückung und all das geachtet. Wir tun dies so, dass, wenn ein technischer Redakteur einem Programmierer einen Code oder ein schriftliches Beispiel vorlegt, der Programmierer das Wesentliche und nicht das Design betrachtet, was die Zeit verkürzt. Und wenn ein technischer Redakteur über Yandex-Styleguides schreiben kann, ist das sehr cool. Vielleicht möchte er später Programmierer werden. Der vorherige Bericht befasste sich mit verschiedenen Untersuchungen. Sie können beispielsweise in Programmierer wechseln.
Wir haben auch einen schnellen Einstieg für Tech-Autoren entwickelt: Wie man eine Entwicklungsumgebung einrichtet, wenn er mit neuen Technologien vertraut wird. Wenn der SDK des technischen Redakteurs beispielsweise in C # geschrieben ist, kommt er, richtet die Entwicklungsumgebung ein, liest Handbücher und macht sich mit der Terminologie vertraut. Wir haben auch Links zu offiziellen Dokumentationen und RFC hinterlassen, falls vorhanden. Wir haben einen Einstiegspunkt für technische Redakteure geschaffen, und es sieht ungefähr so aus.
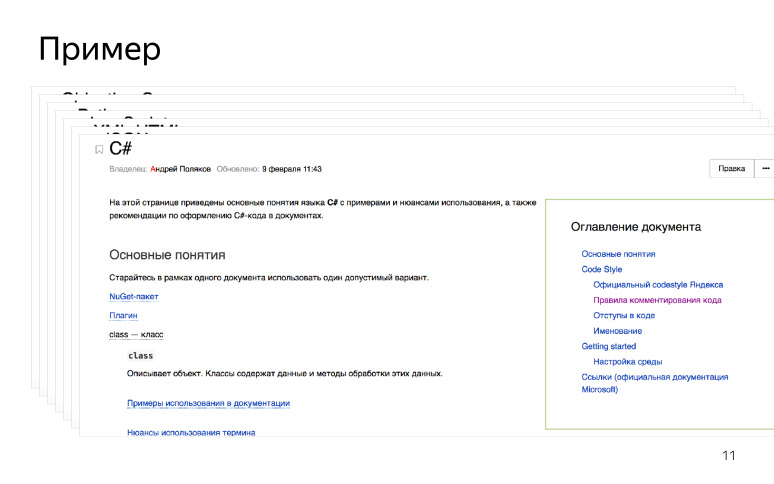
Wenn ein technischer Redakteur eintrifft, lernt er eine neue Technologie und beginnt, sie zu dokumentieren.
Nachdem wir die Technologien beschrieben hatten, beschrieben wir die Struktur der HTTP-API.
Wir haben viele verschiedene HTTP-APIs, und alle werden unterschiedlich beschrieben. Lassen Sie uns eine Vereinbarung treffen und dasselbe tun!
Wir haben die Hauptabschnitte identifiziert, die in jeder HTTP-API enthalten sein werden:

"Übersicht" oder "Einführung": Warum wird diese API benötigt, was können Sie damit tun, auf welchen Host zugegriffen werden muss, um eine Antwort zu erhalten.
"Schnellstart", wenn eine Person einige Schritte durchläuft und am Ende ein erfolgreiches Ergebnis erhält, um zu verstehen, wie diese API funktioniert.
"Verbindung / Autorisierung". Viele APIs erfordern ein Autorisierungstoken oder einen API-Schlüssel. Dies ist ein wichtiger Punkt, daher haben wir beschlossen, dass dies ein obligatorischer Bestandteil aller APIs ist.
"Einschränkungen / Limits", wenn wir über Limits für die Anzahl der Anfragen oder für die Größe des Anfragetexts usw. sprechen.
"Referenz", Referenz. Ein sehr großer Teil, der alle HTTP-Handles enthält, die der Benutzer abrufen und ein Ergebnis erzielen kann.
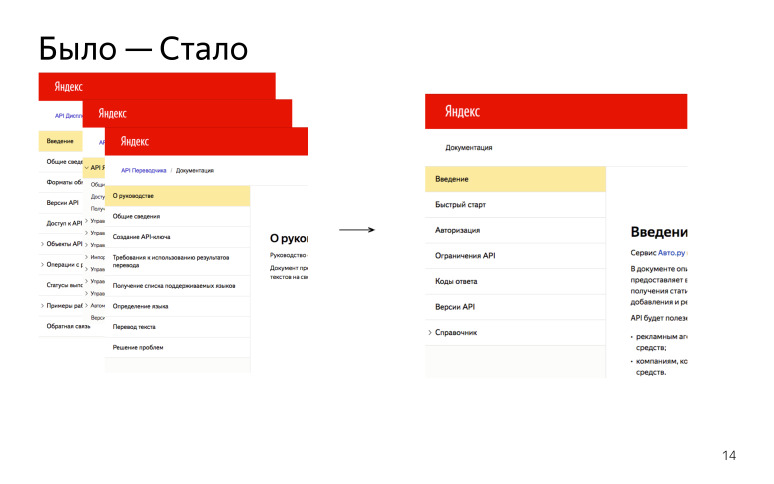
Infolgedessen hatten wir viele verschiedene APIs, die unterschiedlich beschrieben wurden. Jetzt versuchen wir, alles auf die gleiche Weise zu schreiben. Ein solcher Gewinn.
Als wir tief in die Verzeichnisse gingen, stellten wir fest, dass das HTTP-Handle fast immer dasselbe ist. Sie ziehen es, das heißt, Sie stellen eine Anfrage, der Server gibt eine Antwort zurück - voila. Versuchen wir es zu vereinheitlichen. Wir haben eine Vorlage geschrieben, die versucht, alle Fälle abzudecken. Der technische Redakteur nimmt die Vorlage und belässt die erforderlichen Teile in der Vorlage, wenn er eine PUT-Anfrage hat. Wenn er eine GET-Anfrage hat, verwendet er nur die Teile, die für die GET-Anfrage benötigt werden. Eine gemeinsame Vorlage für alle Anforderungen, die wiederverwendet werden können. Jetzt müssen Sie keine Dokumentstruktur von Grund auf neu erstellen, sondern können einfach eine vorgefertigte Vorlage erstellen.

Jeder Stift beschreibt, wofür er ist, was er tut. Es gibt einen Abschnitt „Anforderungsformat“, der Pfadparameter, Abfrageparameter und alles enthält, was im Anforderungshauptteil enthalten ist, wenn es gesendet wird. Wir haben auch den Abschnitt „Antwortformat“ hervorgehoben: Wir schreiben ihn, wenn es einen Antworttext gibt. In einem separaten Abschnitt haben wir „Antwortcodes“ hervorgehoben, da die Antwort vom Server unabhängig vom Hauptteil erfolgt. Und verließ den Abschnitt "Beispiel". Wenn wir eine Art SDK mit dieser API bereitstellen, sagen wir, dass Sie dieses SDK wie folgt verwenden, ein solches Handle ziehen und eine solche Methode aufrufen. Normalerweise hinterlassen wir eine Art cURL-Beispiel, in dem der Benutzer einfach sein Token einfügt. Und wenn wir einen Prüfstand haben, nimmt er einfach die Anfrage und führt sie aus. Und bekommt eine Art Ergebnis.

Es stellt sich heraus, dass es viele Stifte gab, die auf unterschiedliche Weise beschrieben wurden, und jetzt wollen wir alles in eine einzige Form bringen.
Nachdem wir mit der HTTP-API fertig waren, gingen wir zum mobilen SDK über.
Es gibt eine allgemeine Dokumentstruktur, die ungefähr gleich ist:
- "Einführung", wo wir sagen, dass dieses SDK hier für solche Zwecke verwendet wird, integrieren Sie es für solche Zwecke für sich selbst, es ist für solche Betriebssysteme geeignet, wir haben solche und solche Versionen usw.
- "Verbindung". Im Gegensatz zur HTTP-API geht es nicht nur darum, wie Sie den Schlüssel für die Verwendung des SDK erhalten, sondern bei Bedarf auch darum, wie Sie die Bibliothek in unser Projekt integrieren können.
- "Anwendungsbeispiele." Der größte Volumenabschnitt. Meistens möchten Entwickler zur Dokumentation kommen und nicht viele Informationen lesen. Sie möchten ein Stück kopieren, es in sich selbst einfügen und alles wird für sie funktionieren. Daher haben wir diesen Teil als sehr wichtig erachtet und ihn dem obligatorischen Abschnitt zugeordnet.

- "Verzeichnis", Referenz, aber im Gegensatz zur HTTP-API-Referenz können wir hier nicht alles vereinheitlichen, da wir hauptsächlich Verzeichnisse generieren und später im Bericht darüber sprechen werden.
- "Releases" oder Änderungsverlauf, Änderungsprotokoll. Mobile SDKs haben normalerweise einen kurzen Veröffentlichungszyklus. Alle zwei Wochen wird eine neue Version veröffentlicht. Und es wäre besser für den Benutzer, darüber zu sprechen, was sich geändert hat, ob es sich lohnt, es zu aktualisieren oder nicht.
Gleichzeitig enthält die API sowohl die erforderlichen Abschnitte, die wir sehen, als auch die Abschnitte, die wir empfehlen. Wenn die API häufig aktualisiert wird, geben Sie an, dass Sie auch den Änderungsverlauf einfügen, der sich in der API geändert hat. Und oft werden unsere APIs selten aktualisiert, und es ist sinnlos, dies als erforderlichen Abschnitt anzugeben.

Wir hatten also viele SDKs, die auf unterschiedliche Weise beschrieben wurden. Wir haben versucht, sie in ungefähr den gleichen Stil umzuwandeln. Natürlich gibt es zusätzliche Unterschiede, die nur diesem SDK oder dieser HTTP-API eigen sind. Hier haben wir die Wahlfreiheit. Wir sagen nicht, dass außer diesen Abschnitten niemand getan werden kann. Natürlich ist es möglich, dass wir einfach versuchen, die überall aufgeführten Abschnitte zu erstellen, damit klar ist, dass der Benutzer, wenn er in der Dokumentation zu einem anderen SDK wechselt, weiß, was im Abschnitt "Verbindung" beschrieben wird.
Also haben wir uns Vorlagen ausgedacht, Anleitungen zusammengestellt. Was ist unser Aktionsplan jetzt? Wir haben beschlossen, dass wir, wenn wir die API skalieren, die Stifte oder das SDK ändern, neue Vorlagen verwenden, eine neue Struktur erstellen und mit der Arbeit beginnen.
Wenn wir die Dokumentation von Grund auf neu schreiben, nehmen wir natürlich wieder eine neue Struktur, nehmen neue Vorlagen und arbeiten daran.
Und wenn die API veraltet ist, selten aktualisiert wird oder niemand sie unterstützt, aber vorhanden ist, wiederholen Sie sie ein wenig ressourcenintensiv. Wir haben nur beschlossen, es zu belassen, bis es so war, aber wenn die Ressourcen erscheinen, werden wir definitiv zu ihnen zurückkehren, wir werden das alles gut und schön machen.
Was sind die Vorteile der Vereinigung? Sie sollten für alle offensichtlich sein:
"UX", wir denken darüber nach, dass sich der Benutzer in unserer Dokumentation wie zu Hause fühlt. Er kam und weiß, was in den Abschnitten beschrieben ist, in denen er Berechtigungen, Anwendungsbeispiele und Beschreibungen des Stifts finden kann. Es ist toll.
Für Tech-Autoren ermöglicht die Beschreibung der Technologie, einen bestimmten Einstiegspunkt zu bestimmen, an den er kommt, und beginnt, sich mit dieser Technologie vertraut zu machen. Wenn er sie nicht kennt, beginnt er, die Terminologie zu verstehen und sich darauf einzulassen.
Der nächste Punkt ist die Austauschbarkeit. Wenn der technische Redakteur in den Urlaub gefahren ist oder einfach aufgehört hat zu schreiben, weiß ein anderer technischer Redakteur beim Eingeben des Dokuments, wie es im Inneren funktioniert. Es ist sofort klar, was in der Verbindung beschrieben wird, wo nach Informationen zur SDK-Integration gesucht werden kann. Das Verstehen und Vornehmen einer kleinen Überarbeitung eines Dokuments wird einfacher. Es ist klar, dass jedes Projekt seine eigenen Besonderheiten hat. Sie können nicht einfach ein Projekt dokumentieren, ohne es vollständig zu kennen. Gleichzeitig ist die Struktur, dh die Dateinavigation, ungefähr gleich.
Und natürlich die allgemeine Terminologie. Diese Terminologie, die wir für Sprachen zusammengestellt haben, haben wir mit den Entwicklern und Übersetzern vereinbart. Wir sagen, dass wir C # haben, es gibt einen solchen Begriff, wir verwenden ihn so. Wir haben die Entwickler gefragt, welche Terminologie sie verwendet haben, und wollten an dieser Stelle eine Synchronisation erreichen. Wir haben Vereinbarungen getroffen, und wenn wir das nächste Mal mit der Dokumentation kommen, wissen die Entwickler, dass wir mit ihnen Bedingungen und Richtlinien vereinbart haben. Wir verwenden diese Vorlagen und berücksichtigen die Nuancen ihrer Verwendung. Und die Übersetzer wissen wiederum, dass wir das SDK in C # oder Objective-C beschreiben, sodass diese Terminologie der Beschreibung im Handbuch entspricht.
Die Handbücher wurden in Wiki-Seiten geschrieben. Wenn also Sprachen, Technologien und Protokolle aktualisiert werden, kann dies problemlos zu einem vorhandenen Dokument hinzugefügt werden. Idylle.
Je früher Sie beginnen, sich zu vereinen und zuzustimmen, desto besser. Es ist besser, als dass es kein Vermächtnis an Dokumentation gibt, das in einem anderen Stil geschrieben ist und den Fluss des Benutzers in der Dokumentation unterbricht. Mach alles lieber früher.
Entwickler anziehen. Dies sind die Personen, für die Sie Unterlagen schreiben. Wenn Sie selbst eine Art Leitfaden geschrieben haben, wird es ihnen vielleicht nicht gefallen. Es ist besser, ihnen zuzustimmen, damit Sie ein gemeinsames Verständnis der Terminologie haben: Was Sie in die Dokumentation schreiben, wie Sie es schreiben.
Und auch mit Übersetzern verhandeln, alle müssen es übersetzen. Wenn sie anders übersetzen als die Entwickler es gewohnt sind, kommt es erneut zu Konflikten. (
Hier ist ein Link zu einem Videofragment mit Fragen und Antworten - ca. Ed.) Wir fahren fort.
Julia:
- Hallo, mein Name ist Julia, ich arbeite seit fünf Jahren in Yandex und dokumentiere die API und das SDK in Andreys Gruppe. Normalerweise spricht jeder über eine gute Erfahrung, wie großartig sie ist. Ich werde Ihnen sagen, wie wir eine nicht ganz erfolgreiche Strategie gewählt haben. Zu dieser Zeit schien es erfolgreich zu sein, aber dann kam eine harte Realität und wir hatten ein wenig Pech.
Wir hatten anfangs mehrere mobile SDKs, die hauptsächlich in zwei Sprachen geschrieben wurden: Objective-C und Java. Wir haben ihnen manuell Dokumentation geschrieben. Im Laufe der Zeit wuchsen Klassen, Protokolle und Schnittstellen. Es gab immer mehr von ihnen, und wir erkannten, dass wir dieses Geschäft automatisieren mussten. Wir haben uns angesehen, was Technologien sind.
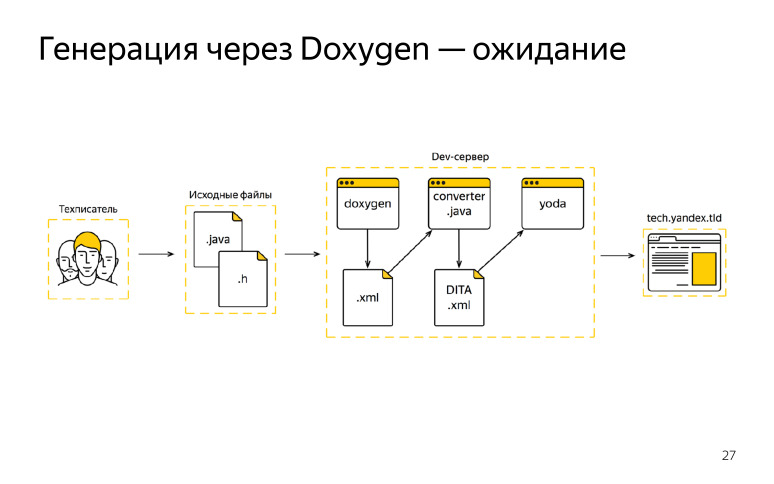
Zu dieser Zeit mochten wir Doxygen, es entsprach unseren Bedürfnissen, wie es uns schien, und wir wählten es als einen einzigen Generator. Und wir haben ein solches Schema gezeichnet, das wir erwartet hatten, wir wollten irgendwie daran arbeiten.
Was hatten wir? Der technische Redakteur kam zur Arbeit, erhielt den Quellcode vom Entwickler, begann seine Kommentare zu schreiben, Änderungen vorzunehmen, nachdem die Dokumentation an unseren Devserver gesendet werden musste, dort haben wir Doxygen ausgeführt, das XML-Format erhalten, aber es entsprach nicht unserem DITA-XML-Standard. Wir wussten davon vorher, schrieben einen bestimmten Konverter.
Nachdem wir die Ausgabe von Doxygen erhalten hatten, haben wir alles durch den Konverter geleitet und bereits unser Format erhalten. Dann wurde der Dokumentationssammler verbunden und wir haben dies alles auf einer externen Domain veröffentlicht. Wir hatten sogar ein paar Iterationen Glück, alles hat für uns geklappt, wir waren begeistert. Aber dann ging etwas schief. Der technische Redakteur machte sich ebenfalls an die Arbeit, erhielt Aufgaben und Quellcodes vom Entwickler und nahm dort seine Korrekturen vor. Danach ging er zum Entwickler, startete Doxygen und es gab ein Feuer.
Wir beschlossen herauszufinden, was los war. Dann haben wir festgestellt, dass Doxygen nicht für alle Sprachen geeignet ist. Wir mussten den Code analysieren, über den er stolperte. Wir fanden Konstrukte, die Doxygen nicht unterstützte und die er nicht unterstützen wollte.
Wir haben beschlossen, da wir an diesem Schema arbeiten, ein Vorverarbeitungsskript zu schreiben und diese Konstrukte irgendwie durch das zu ersetzen, was Doxygen akzeptiert, oder sie irgendwie zu ignorieren.

Unser Zyklus begann so auszusehen. Wir haben die Quellen erhalten, sie in den Devserver aufgenommen, dann das Vorverarbeitungsskript verbunden, den gesamten Überschuss aus dem Code herausgeschnitten, dann Doxygen in das Geschäft aufgenommen, das Doxygen-Ausgabeformat erhalten, auch den Konverter gestartet, unsere endgültigen DITA-XML-Dateien erhalten, dann den Dokumentationssammler verbunden und Wir haben unsere Dokumentation auf einer externen Domain veröffentlicht. Es scheint, dass alles gut aussieht. Ein Skript hinzugefügt, was ist da oben? Anfangs gab es nichts. Das Skript enthielt drei Zeilen, dann fünf, zehn Zeilen, und alles wuchs auf Hunderte von Zeilen an. Wir haben festgestellt, dass wir anfangen, die meiste Zeit nicht damit zu verbringen, Dokumentation zu schreiben, sondern den Code zu analysieren, nach dem zu suchen, was nicht wohin kriecht, und das Skript einfach endlosen Stammgästen hinzuzufügen, vor Wahnsinn zu sitzen und darüber nachzudenken, was los ist.
Wir erkannten, dass wir etwas ändern mussten, irgendwie aufhören mussten, bevor es zu spät war und bis unser Veröffentlichungszyklus bis zum Ende durchlief.
Zum Beispiel sah das Vorverarbeitungsskript zunächst so aus und war harmlos.

Warum haben wir diesen Weg ursprünglich gewählt? Warum schien er gut zu sein?

Ein Generator ist großartig, hat ihn genommen, einmal angeschlossen, eingerichtet und funktioniert. Es schien ein guter Ansatz zu sein. Darüber hinaus können Sie eine einzige Kommentarsyntax für alle Sprachen gleichzeitig verwenden. Sie haben eine Art Leitfaden geschrieben, ihn einmal verwendet, alle diese Konstruktionen sofort in den Code eingefügt und Ihre Arbeit erledigt, Kommentare geschrieben und sich nicht irgendwie auf die Syntax festgelegt.

Dies stellte sich jedoch als einer der großen Nachteile heraus. Die Entwickler haben unsere gemeinsame Syntax nicht unterstützt, sie sind es gewohnt, ihre IDEs zu verwenden, es gibt bereits native Generatoren und ihre Syntax stimmte nicht mit unserer überein. Dies war ein Stolperstein.
Doxygen unterstützte auch neue Funktionen in Sprachen schlecht. Er hat einen selektiven Ansatz, da er selbst in C ++ geschrieben ist, unterstützt er hauptsächlich C-ähnliche Sprachen und der Rest nach dem Restprinzip. Und die Sprachen werden verbessert, Doxygen hält nicht ganz mit und es ist für uns ziemlich unpraktisch geworden.
Dann passierte ein ziemliches Unglück. Ein neues Team kam zu uns und sagte, dass wir über Swift schreiben und Doxygen überhaupt nicht mit ihm befreundet ist. Wir haben erkannt, dass alles Zeit ist, anzuhalten und sich etwas Neues auszudenken. Dann kamen noch ein paar Teams und wir stellten fest, dass unser Schema überhaupt nicht skalierbar ist. Und wir fügen ständig etwas hinzu, wir haben mehrere dieser Skripte, sie leben in verschiedenen Zweigen und das wars. Wir haben erkannt, dass wir akzeptieren müssen, was wir Pech hatten, neue Ansätze und Lösungen ausprobieren müssen, um sie zu finden. Andrey wird dir davon erzählen.
„Wir haben festgestellt, dass in unserem Fall irgendwo ein Universalgenerator auftauchte, aber als wir anfingen, alles zu skalieren, funktionierte der Plan größtenteils nicht. Sie kamen kühl hoch und stimmten allen zu, die es tun, aber es hat nicht geklappt.
Infolgedessen haben wir begonnen, ein neues Schema zu entwickeln. Sie war mit einheimischen Generatoren zusammen. Was haben wir jetzt in der Schaltung? ( , ), , Objective-C Java, , .
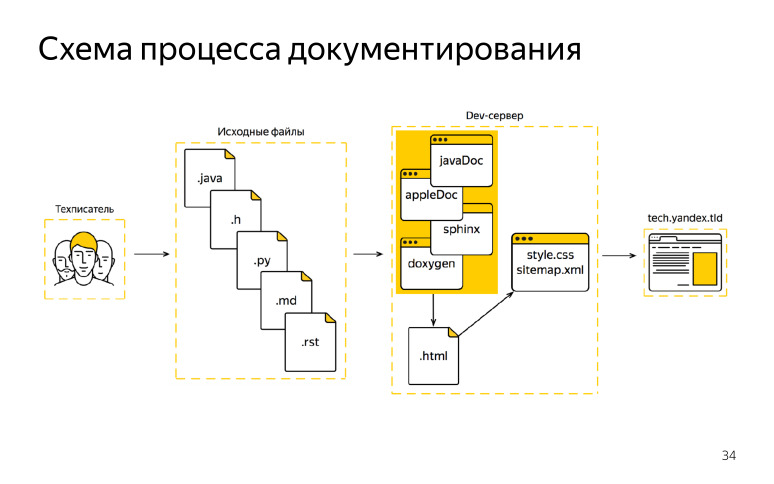
, DITA XML, , , , XML. HTML, . — JavaDoc, AppleDoc, Jazzy. HTML, . HTML, , . , HTML . , , , HTML, . XML , . .
.
— . Doxygen , , . Objective-C, , Java . . , , IDE , IntelliSense, , , , SDK, , . .
, , SDK , , , , HTML, . , , , , , .
. , - , . XML , XML . Doxygen , XML . HTML, XML . . — .
, , . 1500 , : HTML, CSS, .
, , .
. (
— . .)
, , .
— . , . -, . , . ? .
? -, , , , .
- , - , . .
? -, , , , .
. , , , , , , , .
, . , , , , , , .
? — , , , , , . . Bitbucket, - . , .

, . . - , - , , , , , , . , , , , .
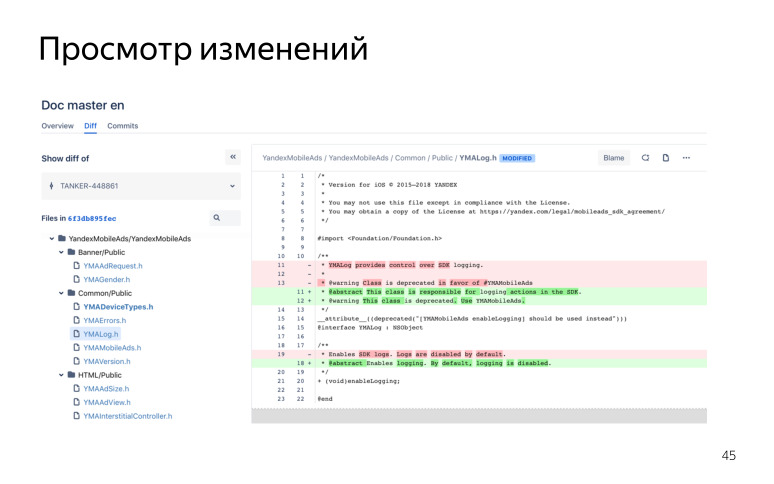
, , .
, SDK , - , , . -, , , , .
, . . — , , .
, . . .
, , , , , , .

, .
. - , . .

, , , , . . , , , - . , . , , .
, .
. , . , , .
, , , — . , , , .
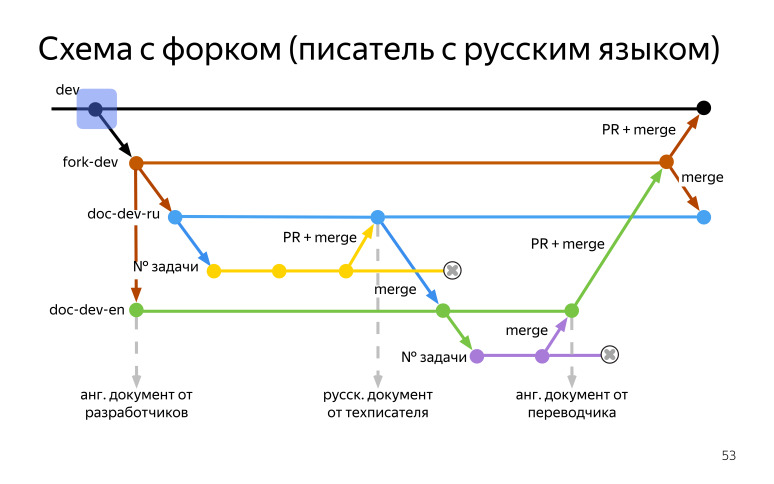
dev , (fork-dev) , . , doc-dev-en, . , , - , , .
(fork-dev) (doc-dev-ru) . , - . . , , doc-dev-ru, . , , - , .
, . (doc-dev-en). , , (doc-dev-en), , . , (fork-dev). , , , , . , , . , dev . , , , .
(fork-dev), , . (fork-dev), , (doc-dev-en), . , , , . , .

, , . dev, (fork-dev) , (doc-dev-ru) (doc-dev-en) . (doc-dev-en), (doc-dev-ru) . , .
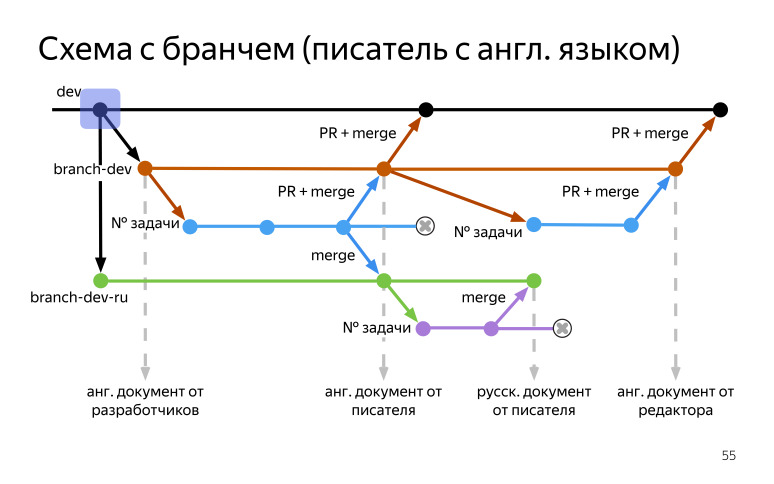
. dev , , (branch-dev). (branch-dev-ru), (branch-dev). , . , . — , — - , , , , .
, , . , , (branch-dev) . , , .
dev. , , , , . .
(branch-dev-ru), , (branch-dev-ru), . .
. (branch-dev), . , , , , , , , , . , , . , , .

, , , , . .
, ? , , . . . , - , . . , .
, , , , , .
, . . . . , , .
— — . — .
. . , . , , , , , , . .
, . . . . , . , . - , . — . .
Prozesse sollten für alle gleich bequem sein. Deshalb haben wir keine Diktatur, wir kommen zu den Entwicklern und sagen: Lass uns den Brunch durcharbeiten. Und sie sagen, dass sie durch Gabeln arbeiten. Wir sagen: Nun, aber wir sind uns einig, dass wir auch Gabeln durcharbeiten. Es muss vereinbart werden, dass alle an diesem Prozess Beteiligten - bei der Lokalisierung, dem Schreiben des Codes und der Dokumentation im Code - eine vereinbarte Position haben. Es ist praktisch, wenn jeder seinen Verantwortungsbereich versteht - und nicht, wenn der technische Redakteur mit geschlossenen Augen arbeitet und den Code nicht sieht oder keinen Zugriff auf das Repository hat. Das ist alles