Warum sind einige APIs bequemer zu verwenden als andere? Was können wir als Front-End-Anbieter auf unserer Seite tun, um mit einer API von akzeptabler Qualität zu arbeiten? Heute werde ich den Lesern von Habr sowohl über technische Optionen als auch über organisatorische Maßnahmen berichten, die Front-End- und Back-End-Anbietern helfen, eine gemeinsame Sprache zu finden und effektive Arbeit aufzubauen.

In diesem Herbst wird Yandex.Market 18 Jahre alt. Während dieser ganzen Zeit hat sich die Affiliate-Oberfläche des Marktes weiterentwickelt. Kurz gesagt, dies ist das Admin-Panel, mit dem Geschäfte Kataloge hochladen, mit dem Sortiment arbeiten, Statistiken folgen, auf Bewertungen reagieren usw. können. Die Besonderheiten des Projekts sind so, dass Sie viel mit verschiedenen Backends interagieren müssen. Daten können jedoch nicht immer an einem Ort von einem bestimmten Backend abgerufen werden.
Symptome eines Problems
Stellen Sie sich vor, es gab ein Problem. Der Manager geht mit der Aufgabe zu den Designern - sie zeichnen das Layout. Dann geht er zum Backend - sie machen einige
Stifte und schreiben eine Liste von Parametern und das Antwortformat in das interne Wiki.
Dann geht der Manager mit den Worten „Ich habe Ihnen eine API gebracht“ zum Frontend und bietet an, alles schnell zu skripten, da seiner Meinung nach fast die gesamte Arbeit bereits erledigt ist.
Sie sehen sich die Dokumentation an und sehen Folgendes:
№ | ---------------------- 53 | feed_shoffed_id 54 | fesh 55 | filter-currency 56 | showVendors
Merken Sie nichts Seltsames? Kamel, Schlange und Kebab Fall in einem Stift. Ich spreche nicht über den Parameter fesh. Was ist überhaupt Fleisch? Ein solches Wort gibt es nicht einmal. Versuchen Sie zu erraten, bevor Sie den Spoiler öffnen.
SpoilerFesh ist ein Filter nach Geschäfts-ID. Sie können mehrere durch Kommas getrennte Bezeichner übergeben. Einer ID kann ein Minuszeichen vorangestellt werden. Dies bedeutet, dass dieser Speicher von den Ergebnissen ausgeschlossen werden sollte.
Gleichzeitig kann ich von JavaSctipt aus natürlich nicht über die gepunktete Notation auf die Eigenschaften eines solchen Objekts zugreifen. Ganz zu schweigen von der Tatsache, dass Sie sich offensichtlich in Ihrem Leben an einen anderen Ort gewandt haben, wenn Sie mehr als 50 Parameter an einem Ort haben.
Es gibt viele Optionen für eine unbequeme API. Ein klassisches Beispiel - die API sucht und gibt Ergebnisse zurück:
result: [ {id: 1, name: 'IPhone 8'}, {id: 2, name: 'IPhone 8 Plus'}, {id: 3, name: 'IPhone X'}, ] result: {id: 1, name: 'IPhone 8'} result: null
Wenn die Ware gefunden wird, erhalten wir ein Array. Wenn ein Produkt gefunden wird, erhalten wir ein Objekt mit diesem Produkt. Wenn nichts gefunden wird, erhalten wir bestenfalls null. Im schlimmsten Fall antwortet das Backend mit 404 oder sogar 400 (Bad Request).
Situationen sind einfacher. Beispielsweise müssen Sie eine Liste der Geschäfte in einem Backend und die Geschäftseinstellungen in einem anderen Backend abrufen. In einigen Stiften sind nicht genügend Daten vorhanden, in einigen Daten sind zu viele vorhanden. Das alles auf dem Client zu filtern oder mehrere Ajax-Anfragen zu stellen, ist eine schlechte Idee.
Was können die Lösungen für dieses Problem sein? Was können wir als Front-End-Anbieter auf unserer Seite tun, um mit einer API von akzeptabler Qualität zu arbeiten?
Frontend Backend
Wir verwenden den React / Redux-Client in der Partnerschnittstelle. Unter dem Client befindet sich Node.js, das viele Hilfsprogramme ausführt und es beispielsweise auf die InitialState-Seite für Editoren wirft. Wenn Sie ein serverseitiges Rendering haben, spielt es keine Rolle, mit welchem Client-Framework es höchstwahrscheinlich von einem Knoten gerendert wird. Was aber, wenn Sie noch einen Schritt weiter gehen und den Client im Backend nicht direkt kontaktieren, sondern Ihre Proxy-API auf dem Knoten so gestalten, dass sie maximal auf die Clientanforderungen zugeschnitten ist?
Diese Technik wird als BFF (Backend For Frontend) bezeichnet. Dieser Begriff wurde erstmals 2015 von SoundCloud eingeführt. Die Idee kann wie folgt schematisch dargestellt werden:
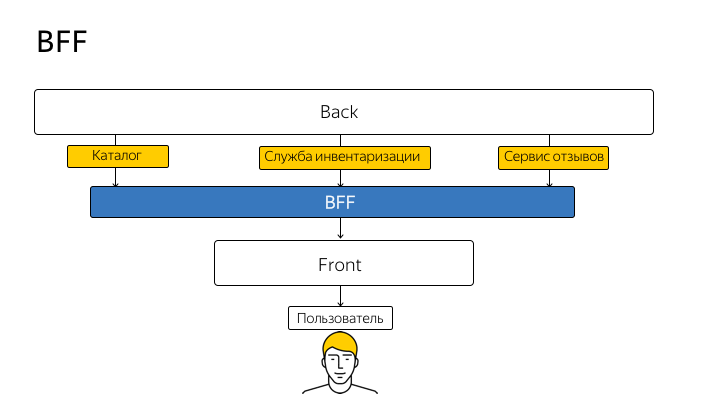
Sie hören also auf, vom Client-Code direkt zur API zu wechseln. Jedes Handle, jede Methode der realen API, die Sie auf dem Knoten und vom Client duplizieren, wird ausschließlich an den Knoten gesendet. Der Knoten leitet die Anforderung bereits an die reale API weiter und gibt eine Antwort an Sie zurück.
Dies gilt nicht nur für primitive Get-Anfragen, sondern allgemein für alle Anfragen, auch mit mehrteiligen / Formulardaten. Beispielsweise lädt ein Geschäft eine XLS-Datei mit seinem Katalog über ein Formular auf einer Site hoch. In dieser Implementierung wird das Verzeichnis also nicht direkt in die API geladen, sondern in Ihr Nod-Handle, das Proxys an ein echtes Backend überträgt.
Erinnern Sie sich an dieses Beispiel mit Ergebnis, als das Backend null, ein Array oder ein Objekt zurückgab? Jetzt können wir es wieder normalisieren - so etwas:
function getItems (response) { if (isNull(response)) return [] if (isObject(response)) return [response] return response }
Dieser Code sieht schrecklich aus. Weil er schrecklich ist. Aber wir müssen das noch tun. Wir haben die Wahl: Machen Sie es auf dem Server oder auf dem Client. Ich wähle einen Server.
Wir können auch alle diese Kebab- und Schlangenfälle in einem für uns geeigneten Stil abbilden und bei Bedarf sofort den Standardwert festlegen.
query: { 'feed_shoffer_id': 'feedShofferId', 'pi-from': 'piFrom', 'show-urls': ({showUrls = 'offercard'}) => showUrls, }
Welche weiteren Vorteile erhalten wir?
- Filtern . Der Kunde erhält nur das, was er braucht, nicht mehr und nicht weniger.
- Aggregation Sie müssen kein Client-Netzwerk und keine Batterie verschwenden, um mehrere Ajax-Anfragen zu stellen. Ein spürbarer Geschwindigkeitsgewinn aufgrund der Tatsache, dass das Öffnen einer Verbindung ein teurer Vorgang ist.
- Caching Ihr wiederholter aggregierter Anruf zieht niemanden erneut an, sondern gibt einfach 304 Not Modified zurück.
- Daten verstecken . Beispielsweise verfügen Sie möglicherweise über Token, die zwischen Backends benötigt werden und nicht an den Client gesendet werden sollten. Der Kunde hat möglicherweise nicht das Recht, überhaupt über die Existenz dieser Token Bescheid zu wissen, ganz zu schweigen von deren Inhalt.
- Microservices . Wenn Sie einen Monolithen auf der Rückseite haben, ist BFF der erste Schritt zu Microservices.
Nun zu den Nachteilen.
- Zunehmende Schwierigkeit . Jede Abstraktion ist eine weitere Ebene, die codiert, bereitgestellt und unterstützt werden muss. Ein weiterer beweglicher Teil des Mechanismus, der möglicherweise ausfällt.
- Duplizieren von Griffen. Beispielsweise können mehrere Endpunkte denselben Aggregationstyp ausführen.
- BFF ist eine Grenzschicht , die allgemeines Routing, Einschränkungen der Benutzerrechte, Abfrageprotokollierung usw. unterstützen soll.
Um diese Minuspunkte auszugleichen, reicht es aus, einfache Regeln einzuhalten. Die erste besteht darin, Front-End- und Geschäftslogik zu trennen. Ihre BFF sollte die Geschäftslogik der Kern-API nicht ändern. Zweitens sollte Ihre Ebene Daten nur dann konvertieren, wenn dies unbedingt erforderlich ist. Wir sprechen nicht von einer in sich geschlossenen umfassenden API, sondern nur von einem Proxy, der die Lücke füllt und die Backend-Fehler korrigiert.
GraphQL
Ähnliche Probleme werden von GraphQL gelöst. Mit GraphQL haben Sie anstelle vieler "dummer" Endpunkte einen intelligenten Stift, der mit komplexen Abfragen arbeiten und Daten in der Form generieren kann, in der der Client sie anfordert.
Gleichzeitig kann GraphQL über REST arbeiten, d. H. Die Datenquelle ist nicht die Datenbank, sondern die Rest-API. Aufgrund des deklarativen Charakters von GraphQL und der Tatsache, dass all dies mit React and Editors befreundet ist, wird Ihr Client einfacher.
Tatsächlich sehe ich GraphQL als eine Implementierung von BFF mit seinem Protokoll und seiner strengen Abfragesprache.
Dies ist eine ausgezeichnete Lösung, hat jedoch mehrere Nachteile, insbesondere bei der Typisierung, bei der Differenzierung von Rechten, und im Allgemeinen ist es ein relativ neuer Ansatz. Daher haben wir noch nicht darauf umgestellt, aber in Zukunft scheint es mir der optimalste Weg zu sein, eine API zu erstellen.
Beste Freunde für immer
Ohne organisatorische Änderungen funktioniert keine technische Lösung ordnungsgemäß. Sie benötigen noch Dokumentation, garantiert, dass sich das Antwortformat nicht plötzlich ändert usw.
Es versteht sich, dass wir alle im selben Boot sitzen. Für einen abstrakten Kunden, egal ob es sich um einen Manager oder Ihren Manager handelt, spielt es im Großen und Ganzen keine Rolle - Sie haben dort GraphQL oder BFF. Für ihn ist es wichtiger, dass das Problem gelöst wird und keine Fehler auf dem Produkt auftreten. Für ihn gibt es keinen großen Unterschied, aufgrund dessen Fehler ein Fehler im Produkt aufgetreten ist - durch den Fehler der Vorder- oder Rückseite. Daher müssen Sie mit Backdern verhandeln.
Darüber hinaus sind die Fehler im Hintergrund, über die ich zu Beginn des Berichts gesprochen habe, nicht immer auf böswillige Handlungen zurückzuführen. Es ist möglich, dass der Parameter fesh auch eine Bedeutung hat.

Achten Sie auf das Datum des Commits. Es stellte sich heraus, dass Fesh zuletzt seinen siebzehnten Geburtstag feierte.
Sehen Sie links einige seltsame Bezeichner? Dies ist SVN, einfach weil es 2001 keine Gita gab. Kein Github als Service, sondern ein Gith als Versionskontrollsystem. Er erschien erst 2005.
Die Dokumentation
Wir müssen uns also nicht mit dem Backend streiten, sondern zustimmen. Dies kann nur geschehen, wenn wir eine einzige Quelle der Wahrheit finden. Diese Quelle sollte die Dokumentation sein.
Das Wichtigste dabei ist, die Dokumentation zu schreiben, bevor wir mit der Arbeit an der Funktionalität beginnen. Wie bei einer Ehevereinbarung ist es besser, sich auf alles am Ufer zu einigen.
Wie funktioniert es Relativ gesehen werden drei: Manager, Front-End und Back-End. Fronteder ist mit dem Themenbereich bestens vertraut, daher ist seine Teilnahme von entscheidender Bedeutung. Sie sammeln und beginnen über die API nachzudenken: Auf welche Weise, welche Antworten sollten zurückgegeben werden, bis hin zum Namen und Format der Felder.
Prahlerei
Eine gute Option für die API-Dokumentation ist das Swagger- Format, das jetzt OpenAPI heißt. Es ist besser, Swagger im YAML-Format zu verwenden, da es im Gegensatz zu JSON besser von Menschen gelesen wird, aber es gibt keinen Unterschied für die Maschine.
Infolgedessen werden alle Vereinbarungen im Swagger-Format festgelegt und in einem gemeinsamen Repository veröffentlicht. Die Dokumentation für das Sales Backend muss sich im Assistenten befinden.
Der Master ist vor Commits geschützt, der Code gelangt nur über den Anforderungspool in ihn, Sie können ihn nicht übertragen. Der Vertreter des Frontteams ist verpflichtet, eine Überprüfung des Anforderungspools durchzuführen. Ohne sein Upgrade geht der Code nicht an den Master. Dies schützt Sie ohne vorherige Ankündigung vor unerwarteten API-Änderungen.
Also hast du dich zusammengetan, schrieb Swagger, also hast du den Vertrag tatsächlich unterschrieben. Von diesem Moment an können Sie als Front-End Ihre Arbeit beginnen, ohne auf die Erstellung einer echten API warten zu müssen. Was war der Punkt der Trennung zwischen Client und Server, wenn wir nicht parallel arbeiten können und Cliententwickler auf Serverentwickler warten müssen? Wenn wir einen „Vertrag“ haben, können wir diese Angelegenheit sicher parallelisieren.
Faker.js
Faker eignet sich hervorragend für diese Zwecke. Dies ist eine Bibliothek zum Generieren einer großen Menge gefälschter Daten. Es können verschiedene Arten von Daten generiert werden: Daten, Namen, Adressen usw., all dies ist gut lokalisiert, es gibt Unterstützung für die russische Sprache.
Gleichzeitig ist der Fälscher mit der Prahlerei befreundet, und Sie können den Mock-Server ruhig anheben, der auf der Grundlage des Swagger-Schemas falsche Antworten auf den erforderlichen Pfaden generiert.
Validierung
Swagger kann in ein JSON-Schema konvertiert werden. Mithilfe von Tools wie Ajv können Sie Backend-Antworten direkt zur Laufzeit, in Ihrer BFF validieren und Tester, Backender selbst, bei Unstimmigkeiten usw. melden.
Angenommen, ein Tester findet einen Fehler auf der Site. Wenn beispielsweise auf eine Schaltfläche geklickt wird, geschieht nichts. Was macht der Tester? Er legt ein Ticket an das Frontend: "Dies ist Ihr Knopf, er wird nicht gedrückt, reparieren Sie ihn."
Wenn sich zwischen Ihnen und dem Back ein Validator befindet, weiß der Tester, dass die Taste tatsächlich gedrückt wird. Nur das Backend sendet die falsche Antwort. Falsch - dies ist eine Antwort, die die Front nicht erwartet, das heißt, sie entspricht nicht dem „Vertrag“. Und hier ist es bereits notwendig, entweder die Rückseite zu reparieren oder den Vertrag zu ändern.
Schlussfolgerungen
- Wir sind aktiv am Design der API beteiligt. Wir gestalten die API so, dass sie nach 17 Jahren bequem verwendet werden kann.
- Wir benötigen Swagger-Dokumentation. Keine Dokumentation - der Backend-Vorgang wurde nicht abgeschlossen.
- Es gibt eine Dokumentation - wir veröffentlichen sie in Git, und alle Änderungen an der API sollten vom Vertreter des Frontteams aktualisiert werden.
- Wir erhöhen den gefälschten Server und beginnen an der Front zu arbeiten, ohne auf die echte API zu warten.
- Wir setzen den Knoten unter das Frontend und validieren alle Antworten. Außerdem können wir Daten aggregieren, normalisieren und zwischenspeichern.
Siehe auch
→ So erstellen Sie eine REST-ähnliche API in einem großen Projekt
→ Backend Im Frontend
→ Verwenden von GraphQL als BFF-Musterimplementierung