Dies ist ein Tutorial für die TensorFlow-Bibliothek. Betrachten Sie es als etwas tiefer als in Artikeln über das Erkennen handgeschriebener Zahlen. Dies ist ein Tutorial zu Optimierungsmethoden. Hier kann man nicht ohne Mathematik auskommen. Es ist okay, wenn du es komplett vergessen hast. Rückruf. Es wird keine formalen Beweise und komplexen Schlussfolgerungen geben, nur das notwendige Minimum für ein intuitives Verständnis. Zunächst ein kleiner Hintergrund darüber, wie dieser Algorithmus bei der Optimierung eines neuronalen Netzwerks hilfreich sein kann.

Vor sechs Monaten bat mich ein Freund zu zeigen, wie man in Python ein neuronales Netzwerk erstellt. Seine Firma produziert Instrumente für geophysikalische Messungen. Während des Bohrens messen mehrere verschiedene Sonden eine Reihe von Signalen, die den Parametern der Umgebung des Bohrlochs zugeordnet sind. In einigen komplexen Fällen können die Umgebungsparameter aus Signalen auch auf einem leistungsstarken Computer über einen langen Zeitraum genau berechnet werden, und es ist erforderlich, die Ergebnisse von Messungen vor Ort zu interpretieren. Es gab die Idee, mehrere hunderttausend Fälle in einem Cluster zu zählen und ein neuronales Netzwerk darauf zu trainieren. Da das neuronale Netzwerk sehr schnell ist, kann es verwendet werden, um Parameter zu bestimmen, die mit den gemessenen Signalen übereinstimmen, direkt während des Bohrvorgangs. Details finden Sie im Artikel:
D. Kushnir, N. Velker, A. Bondarenko, G. Dyatlov & Y. Dashevsky (2018, 29. Oktober). Echtzeitsimulation des Werkzeugs für den tiefen azimutalen Widerstand im 2D-Fehlermodell unter Verwendung neuronaler Netze (russisch). Gesellschaft der Erdölingenieure. doi: 10.2118 / 192573-RU
Eines Abends zeigte ich, wie Keras ein einfaches neuronales Netzwerk implementieren können, und ein Freund bei der Arbeit begann mit dem Training der gezählten Daten. Nach ein paar Tagen diskutierten wir das Ergebnis. Aus meiner Sicht sah er vielversprechend aus, aber ein Freund sagte, er brauche Berechnungen mit der Genauigkeit des Geräts. Und wenn sich herausstellte, dass der mittlere quadratische Fehler bei 1 lag, wurde 1e-3 benötigt. 3 Bestellungen weniger. Tausendmal.
Experimente mit neuronalen Netzwerkarchitekturen, Datennormalisierungs- und Optimierungsansätzen ergaben fast nichts. Ein paar Wochen später rief ein Freund an und sagte, er habe MatLab installiert und das Problem mit der Levenberg-Marquardt- Methode gelöst (im Folgenden werden wir LM nennen). Es wurde für eine lange Zeit (mehrere Tage) optimiert, es funktionierte nicht auf der GPU, aber das Ergebnis war das richtige. Es klang wie eine Herausforderung.
Eine schnelle Suche nach einem vorgefertigten LM-Optimierer für Keras oder TensorFlow ist fehlgeschlagen. Ich bin nur auf die Pyrenn-Bibliothek gestoßen, aber ihre Funktionalität schien mir schlecht. Ich habe beschlossen, es selbst umzusetzen. Auf den ersten Blick sah alles einfach aus, und zwei Abende hätten ausreichen sollen. Es dauerte länger. Es gab zwei Probleme:
- TensorFlow. Eine Reihe von Artikeln, aber fast alle Ebenen "aber schreiben wir
hallo Welt handgeschriebene Ziffernerkennung." - Mathe Ich habe viel vergessen, und die Autoren mathematischer Artikel interessieren sich überhaupt nicht für Leute wie mich: feste Formeln ohne Erklärung, "offensichtlich!" usw.
Infolgedessen schrieb er einen Artikel für diejenigen, die die Mathematik vergessen haben und TensorFlow etwas tiefer verstehen wollen, aber ohne Hardcore. Der Artikel enthält viel Text und wenig Code. Die entgegengesetzte Option, wenn es wenig Text und viel Code gibt, ist hier Jupyter Notebook Levenberg-Marquardt .
Lernen Sie die Rosenbrock-Funktion kennen
Wir werden Trainingsdaten mit der Rosenbrock-Funktion generieren, die häufig als Benchmark für Optimierungsalgorithmen verwendet wird:
f ( x , y ) = ( a - x ) 2 + b ( y - x 2 ) 2
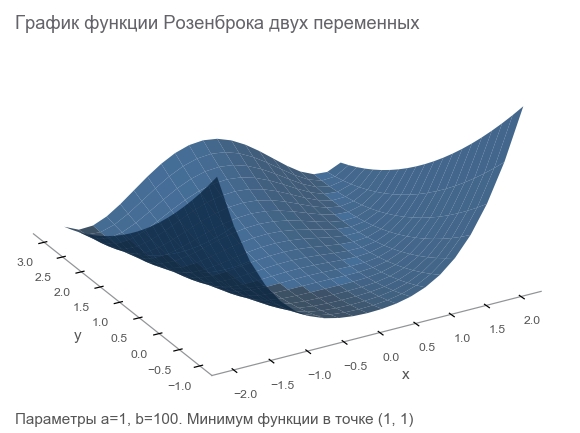
Warum ist sie gut?
- Schöner Zeitplan. Es heißt Rosenbrock-Tal und die unübersetzbare Rosenbrock-Bananenfunktion .
- Das globale Minimum befindet sich in einem langen, schmalen, parabolisch flachen Tal. Ein Tal zu finden ist trivial und ein globales Minimum ist schwierig.
- Es gibt eine mehrdimensionale Option. Es ist nicht so einfach, für viele Variablen eine gute Funktion zu entwickeln.
Wir beginnen mit dem Schreiben von Code, indem wir die für die weitere Arbeit erforderlichen Bibliotheken verbinden:
import numpy as np import tensorflow as tf import math def rosenbrock(x, y, a, b): return (a - x)**2 + b*(y - x**2)**2
Wir geben das Problem an
Da es sich um ein Messgerät handelt, verwenden wir die Analogie weiter. Unser Gerät in einer fiktiven Welt kann Koordinaten messen ( x , y ) und Höhe z . Physiker studierten die Welt und sagten: " Ja, das ist Rosenbrock! Wenn Sie die Koordinaten kennen, können Sie die Höhe genau berechnen, Sie müssen sie nicht messen. " Mit anderen Worten, Wissenschaftler gaben uns ein Modell z = R o s e n b r o c k ( x , y , a , b ) das hängt von den Parametern ab ( a , b ) . Obwohl diese Parameter in einer fiktiven Welt konstant sind, sind sie unbekannt. Sie müssen gefunden werden.
Wir haben eine Reihe von Experimenten durchgeführt, die ergeben haben m Punkte (x1,y1,z1),(x2,y2,z2),...,(xm,ym,zm) ::
Die erste Möglichkeit zur Optimierung besteht darin, die Parameter zu erraten. Wir verwenden die Numpy-Bibliothek:
x, y = data_points[:, 0], data_points[:, 1] z = data_points[:, 2]
Wie kann man verstehen, wie falsch wir sind? Residuen zählen - Fehlergrößen. m Punkte geben m Residuen - Sie benötigen einen integralen Indikator. Wir quadrieren jeden Rest in einem Quadrat und berechnen den Durchschnitt:
MSE(a,b)= frac1m summi=1(zi− widehatzi)2
Dieses Maß für die Nähe wird als mittlerer quadratischer Fehler bezeichnet (im Folgenden als mse bezeichnet ):
[Out]: 3868.2291666666665
Durch Minimierung von mse lösen wir das Problem der kleinsten Quadrate ( Minimierung nichtlinearer Quadrate ):
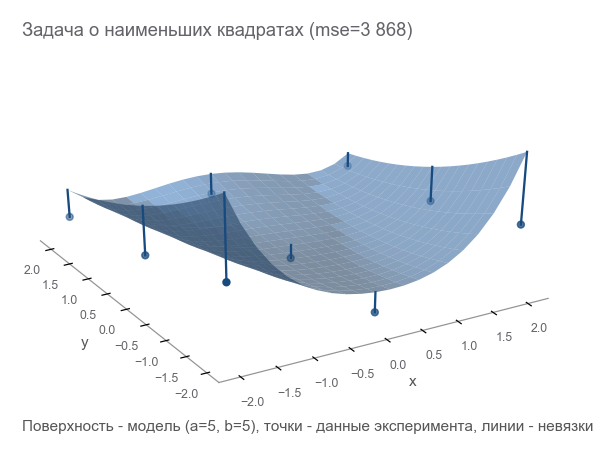
Es ist ersichtlich, dass die Parameter überhaupt nicht geraten haben.
Wir formulieren das Problem auf TensorFlow
Das Modell hat die Form z=Rosenbrock(x,y,a,b) . Wir bringen es auf die Form y=f(x,p) (Normalerweise schreibt Mathe beta statt p Programmierer verwenden jedoch keine Beta). Jetzt hat das Modell die Form y=Rosenbrock(x,p) wo y - Höhe x Ist der Koordinatenvektor zweier Elemente (Komponente) und p - Vektor der Parameter.
Programmierer betrachten Vektoren oft als eindimensionale Arrays. Das ist nicht ganz richtig. Ein Array von Zahlen ist ein Mittel zur Darstellung eines Vektors. Sie können einen Vektor als Array von Dimensionen darstellen N zweidimensionales Array 1 malN und sogar ein Array N mal1 in Fällen, in denen die Tatsache, dass der Vektor ein Spaltenvektor ist (zum Beispiel um eine Matrix damit zu multiplizieren), wichtig ist:
beginbmatrixx1 vdotsxN endbmatrix
TensorFlow verwendet das Konzept des Tensors . Ein Tensor kann wie ein Array eindimensional (zur Darstellung eines Vektors ), zweidimensional (für einen Matrix- oder Spaltenvektor ) und jede größere Dimension sein.
Der TensorFlow-Code unterscheidet sich in seiner Form nicht vom Numpy-Code. Der Inhalt ist riesig. Numpy Code berechnet den mse- Wert . Der TensorFlow-Code führt überhaupt keine Berechnungen durch, sondern bildet ein Datenflussdiagramm , das mse berechnen kann . Ein sehr hirntoleranter Moment ist die Arbeit der Rosenbrock- Funktion. Wir verwenden es in beiden Fällen. Wenn wir jedoch die Numpy-Arrays übergeben, werden die Berechnungen gemäß der Formel ausgeführt und die Zahlen zurückgegeben. Wenn wir die Tensoren an TensorFlow übertragen, bildet dies einen Teilgraphen des Datenstroms und gibt seine Kante in Form eines Tensors zurück. Wunder des Polymorphismus, aber missbrauchen Sie sie nicht:
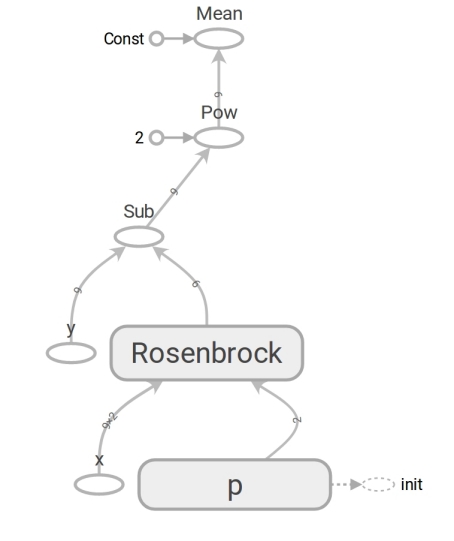
Dank des Vorhandenseins eines solchen Datenflussdiagramms kann insbesondere TensorFlow Ableitungen automatisch berechnen (unter Verwendung der automatischen Differenzierungstechnik im umgekehrten Modus ).
Ein Moment der Mathematik. Blöcke "für diejenigen, die vergessen haben" werden in einem Spoiler versteckt.
Derivat (Nummer eingegeben - Nummer links)Höchstwahrscheinlich erinnern Sie sich an die Definition der Ableitung einer Skalarfunktion (Rückgabe einer Zahl) einer Variablen: z f: mathbbR rightarrow mathbbR Derivat f an der Stelle x in mathbbR definiert als:
f′(x)= limh bis0 fracf(x+h)−f(x)h
Derivate sind eine Methode zur Messung von Veränderungen . Im skalaren Fall zeigt die Ableitung, um wie viel sich die Funktion ändert f wenn x auf einen kleinen Wert ändern varepsilon ::
f(x+ varepsilon) ca.f(x)+ varepsilonf′(x)
Der Einfachheit halber bezeichnen wir y=f(x) und die Ableitung y von x wir werden schreiben wie frac partiellesy partiellesx . Eine solche Aufzeichnung unterstreicht dies frac partiellesy partiellesx - Änderungsrate zwischen Variablen x und y . Genauer gesagt, wenn x wechseln zu varepsilon dann y auf ungefähr ändern varepsilon frac partiellesy partiellesx . Sie können es auch so schreiben:
x rechterPfeilx+ Deltax rechterPfeily rechterPfeil ungefähry+ frac partiellery partiellerx Deltax
Liest als: "Ändern x auf x+ Deltax ändern y bei ungefähr y+ Deltax frac partiellesy partiellesx ". Eine solche Aufzeichnung zeigt deutlich den Zusammenhang zwischen der Änderung x und ändern y .
Wir haben ein Datenflussdiagramm erstellt. Lassen Sie uns die mse-Berechnung ausführen:
[Out]: 3868.2291666666665
Das Ergebnis ist das gleiche wie bei Numpy. Sie haben sich also nicht geirrt.
Beginnen Sie mit der Optimierung
Leider war es nicht möglich, die Parameter zu erraten. Aber dann haben wir:
- Wir setzen das Optimalitätskriterium - den Minimalwert von mse.
- Es wurden variable Parameter bestimmt: Vektor p mit Komponenten a , b Rosenbrock funktioniert.
- Wir haben noch nicht über Einschränkungen nachgedacht, aber sie sind nicht da.
Im letzten Schritt haben wir ein Datenflussdiagramm mit einem Tensor für endliche Verluste ( Verlustfunktion ) erstellt. Ziel der Optimierung ist es, den Wert des Parametervektors zu ermitteln p bei dem der Wert der Verlustfunktion minimal ist. Wir hatten Glück, der Graph dieser Funktion ist sehr einfach (konkav und ohne lokale Minima):
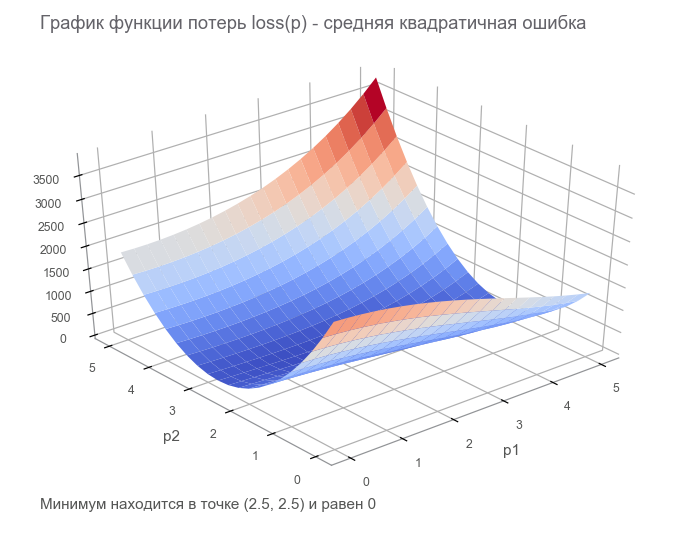
Erste Schritte mit der Optimierung. Zunächst schreiben wir einen verallgemeinerten Zyklus:
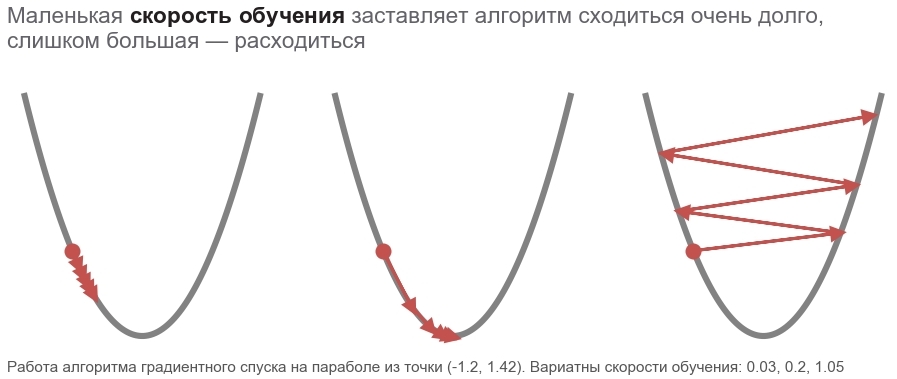
Wir optimieren nach der Methode des schnellsten Gradientenabstiegs (SGD)
Die Aktionen dieser Methode können mit dem Fahren eines gewagten Skifahrers verglichen werden, der immer die Piste hinunterfährt (in der steilsten Richtung). In diesem Fall wird nur die Steigung am Standortpunkt berücksichtigt. Und wenn die Piste stark ist, fliegt der Skifahrer vor dem nächsten Wechsel eine lange Strecke. Mit einer schwachen Steigung bewegt es sich in kleinen Schritten. Vielleicht, wie man wegfliegt in einen Baum (Der Algorithmus divergiert ) und bleibt in einer Grube stecken ( lokales Minimum ).

Sie können wie folgt schreiben (ändern boldsymbolp auf boldsymbolp−... ):
boldsymbolp rightarrow boldsymbolp− alpha[ nablapVerlust( boldsymbolp)]
Fettig boldsymbolp betont, dass dies der Punkt der tatsächlichen Position ist - der Wert des Parametervektors im aktuellen Schritt. Im ersten Schritt ist dies unsere Vermutung (5, 5). Die Formel enthält zwei interessante Punkte: alpha - Lernrate ( Lernrate ), nablapVerlust - Gradient ( Gradient ) der Verlustfunktion durch den Parametervektor.
Farbverlauf (Vektor eingegeben - Nummer links)Stellen Sie sich eine Funktion vor, die einen Vektor als Eingabe verwendet und einen Skalar erzeugt: f: mathbbRN rightarrow mathbbR . Derivat f an der Stelle x in mathbbRN Jetzt Gradient genannt und ist ein Vektor [ nablaxf(x)] in mathbbRN (gelesen als "nabla") bestehend aus partiellen Ableitungen :
nablaxy=( frac partiellesy partiellesx1, frac partiellesy partiellesx2,..., frac partiellesy partiellexN)
Für diesen Fall ist die Aufzeichnung der Abhängigkeit der Änderung der Funktion von der Änderung des Arguments wie folgt:
x rightarrowx+ Deltax Rightarrowy rightarrow ungefähry+ nablaxy cdot Deltax
Der Datensatz hat sich ziemlich verändert, um dies zu berücksichtigen x , Deltax und nablaxy - Vektoren in mathbbRN und y - Skalar. Beim Multiplizieren von Vektoren nablaxy und Deltax Es wird das Skalarprodukt verwendet (die Summe der Produkte der Komponenten).
[Out]: step: 1, current loss: 3868.2291666666665 step: 2, current loss: 1381.5379689135807 [...] ENDED ON STEP: 582, FINAL LOSS: 9.698531012270816e-11 PARAMETERS: [2.50000205 2.49999959]
Es dauerte 582 Schritte:
Bewegung in Richtung des Anti-GradientenWarum bewegen wir uns in die entgegengesetzte Richtung zum Gefälle? Erinnern Sie sich an den Eintrag mit dem Skalarprodukt: x rightarrowx+ Deltax Rightarrowy rightarrow ungefähry+ nablaxy cdot Deltax . Minimieren y . Da das Verhalten der Funktion nur in einer kleinen Nachbarschaft durch die Ableitung bekannt ist, ist es notwendig, sich in kleinen, aber optimalen Schritten zu bewegen, um das Produkt zu minimieren nablaxy cdot Deltax . Nach Schuldefinition ist das Skalarprodukt zweier Vektoren die Zahl, die dem Produkt der Längen dieser Vektoren durch den Kosinus des Winkels zwischen ihnen entspricht : a cdotb= left|a right| left|b right|cos angle(a,b) . Für eine feste Länge von Vektoren erreicht dieses Produkt ein Minimum mit einem Cosinus von -1, d.h. in einem Winkel von 180 Grad, wenn die Vektoren in entgegengesetzte Richtungen gerichtet sind. Dementsprechend ist das minimale Skalarprodukt nablaxy cdot Deltax erreicht wenn Deltax in Richtung des Anti-Gradienten .
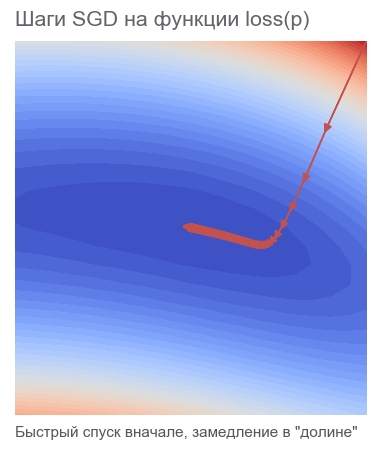
Wir optimieren nach der Adam-Methode
Wir werden nicht weiter auf Gradientenmethoden eingehen, aber es gibt viele Variationen. Sie können darüber im Artikel Methoden zur Optimierung neuronaler Netze lesen. In TensorFlow sind bereits viele Optimierer implementiert. Zum Beispiel Adam:
[Out]: step: 1, current loss: 3868.2291666666665 step: 2, current loss: 34205.72916492336 [...] ENDED ON STEP: 317, FINAL LOSS: 2.424142714263483e-12 PARAMETERS: [2.49999969 2.50000008]
In 317 Schritten verwaltet. Viel schneller.
Wir optimieren nach Newtons Methode
Die Aktionen von Methoden zweiter Ordnung können mit dem Fahren eines rationalen Freeride-Snowboarders verglichen werden, der lange über den nächsten Punkt seiner Route nachdenkt und nicht nur die Steigung am Standort, sondern auch die Krümmung berücksichtigt.
Tatsächlich versuchen sowohl Gradientenabstiegsmethoden als auch Methoden zweiter Ordnung, die Funktion am aktuellen Punkt zu erraten (zu approximieren ). Gradientenmethoden konzentrieren sich nur auf die Steigung des Funktionsgraphen am Punkt - der ersten Ableitung. Methoden zweiter Ordnung berücksichtigen zusätzlich zur Vorspannung die Krümmung , die zweite Ableitung: "Wenn die Krümmung bestehen bleibt, wo wird dann das Minimum sein?" Wir rechnen und gehen dorthin:
Um eine solche Näherung zu konstruieren und den geschätzten Mindestpunkt zu berechnen, können Sie die Taylor-Reihe verwenden . Für den eindimensionalen Fall die Approximation durch ein Polynom zweiter Ordnung am Punkt a sieht so aus:
f(x) ungefährf(a)+ fracf′(a)(x−a)1!+ fracf″(a)(x−a)22!
Das Minimum wird bei erreicht x = a - f r a c f ' ( a ) f ' ' ( a ) . Der mehrdimensionale Fall sieht ernster aus:
Hessische Matrix (eingegebener Vektor - Nummer links)Die hessische Matrix ist eine quadratische Matrix aus zweiten Ableitungen:
\ boldsymbol {H} y_ {x} = \ begin {bmatrix} \ frac {\ partiell ^ 2y} {\ partiell x_1 ^ 2} & \ frac {\ partiell ^ 2y} {\ partiell x_1 \ partiell x_2} & \ cdots & \ frac {\ partiell ^ 2y} {\ partiell x_1 \ partiell x_N} \\ \ frac {\ partiell ^ 2y} {\ partiell x_2 \ partiell x_1} & \ frac {\ partiell ^ 2y} {\ partiell x_2 ^ 2} & \ cdots & \ frac {\ partiell ^ 2y} {\ partiell x_2 \ partiell x_N} \\ \ vdots & \ vdots & \ ddots & \ vdots \\ \ frac {\ partiell ^ 2y} {\ partiell x_N \ partiell x_1} & \ frac {\ partiell ^ 2y} {\ partiell x_N \ partiell x_2} & \ cdots & \ frac {\ partiell ^ 2y} {\ partiell x_N ^ 2} \ end {bmatrix}
Approximation eines Polynoms zweiter Ordnung für eine Funktion eines Vektors durch einen Gradienten und eine hessische Matrix an einem Punkt a sieht so aus:
f(x) ungefährf(a)+(xa) intercal[ nablaxf(a)]+ frac12!(xa) intercal[ boldsymbolH.fx(a)](xa)
Das Minimum wird bei erreicht x=a−[ boldsymbolHfx(a)]−1[ nablaxf(a)] . Die Form stimmt fast mit dem eindimensionalen Fall überein: Wir haben die erste Ableitung durch einen Gradienten ersetzt, die zweite durch eine hessische Matrix und eine Korrektur für die Arbeit mit Vektoren vorgenommen. Es ist unmöglich, einen Vektor durch eine Matrix zu teilen, daher wird eine Multiplikation mit der inversen Matrix verwendet. T bedeutet transponieren . Die Formel impliziert, dass ein Vektor standardmäßig eine Spalte ist. Transponieren verwandelt einen Spaltenvektor in einen Zeilenvektor . Bei der Implementierung in TensorFlow sollte dies berücksichtigt werden, jedoch in umgekehrter Richtung: Standardmäßig ist der Vektor eine Zeichenfolge (eindimensionaler Tensor). Nur für den Fall: Die Transposition ist keine Drehung um 90 Grad, sondern die Umwandlung von Zeilen in Spalten in derselben Reihenfolge.
Der Schritt der Newton-Methode hat also die folgende Form:
boldsymbolp rightarrow boldsymbolp−[ boldsymbolHlossp( boldsymbolp)]−1[ nablaploss( boldsymbolp)]
TensorFlow bietet alles, um diese Methode zu implementieren:
[Out]: step: 1, current loss: 3868.2291666666665 step: 2, current loss: 105.04357496954218 step: 4, current loss: 9.96663526704236 ENDED ON STEP: 6, FINAL LOSS: 5.882202372519996e-20 PARAMETERS: [2.5 2.5]
Genug 6 Schritte:
Optimiert durch den Gauß-Newton-Algorithmus
Newtons Methode hat einen Nachteil - die hessische Matrix. Dank TensorFlow können wir es in einer Codezeile zählen. Johann Karl Friedrich Gauß erwähnte laut Wiki 1809 erstmals seine Methode. Die Berechnung der hessischen Matrix für mehrere Parameter für die Methode der kleinsten Quadrate kann dann viel Zeit in Anspruch nehmen. Nun können wir annehmen, dass der Gauß-Newton-Algorithmus die Approximation der Hessischen Matrix durch die Jacobi-Matrix verwendet , um die Berechnungen zu vereinfachen. Aus geschichtlicher Sicht ist dies jedoch nicht der Fall: Ludwig Otto Hesse (der die nach ihm benannte Matrix entwickelte) wurde 1811 geboren - zwei Jahre nach der ersten Erwähnung des Algorithmus. Und Carl Gustav Jacobi war 5 Jahre alt.
Der Gauß-Newton-Algorithmus funktioniert nicht mit der Verlustfunktion. Es funktioniert mit der Restfunktion r(p) . Diese Funktion verwendet einen Eingabevektor von Parametern p und gibt einen Residuenvektor zurück . In unserem Fall der Vektor p besteht aus 2 Komponenten (Parameter a und b Rosenbrock-Funktionen) und der Restvektor aus m Komponente (entsprechend der Anzahl der Experimente). Die Vektorfunktion des Vektorarguments wird erhalten. Seine Ableitung:
Jacobi-Matrix (Vektor eingegeben - Vektor freigegeben)Stellen Sie sich eine Funktion vor, die einen Vektor als Eingabe verwendet und auch einen Vektor erzeugt: f: mathbbRN rightarrow mathbbRM . Derivat f an der Stelle x hat jetzt Größe N malM , genannt Jacobi-Matrix , und besteht aus allen Kombinationen partieller Ableitungen:
\ boldsymbol {J} y_ {x} = \ begin {pmatrix} \ frac {\ partielle y_ {1}} {\ partielle x_ {1}} & \ cdots & \ frac {\ partielle y_ {1}} {\ partielle x_ {N}} \\ \ vdots & \ ddots & \ vdots \\ \ frac {\ partielle y_ {M}} {\ partielle x_ {1}} & \ cdots & \ frac {\ partielle y_ {M}} {\ partielle x_ {N}} \ end {pmatrix}
Möglicherweise stellen Sie fest, dass die Zeilen der Jacobi-Matrix die Farbverläufe der Komponenten sind y . Artikel (i,j) Matrizen frac partiellesy partiellesx ist gleich frac partielleyi partiellexj und sagt uns, wie viel sich ändern wird yi beim wechseln xj auf einen kleinen Wert. Wie in früheren Fällen können Sie schreiben:
x rechterPfeilx+ Deltax rechterPfeily rechterPfeil ungefähry+ BoldsymbolJyx Deltax
Hier boldsymbolJyx Matrix N malM und Deltax Größenvektor N also das Produkt boldsymbolJyx Deltax Ist das Produkt der Matrix durch den Vektor, was zu einem Vektor der Größe führt M .
Um nicht in der Fülle der Zeichen verwirrt zu werden, nehmen wir das an boldsymbolJr - Jacobi-Matrix der Restfunktionen am aktuellen Punkt boldsymbolp . Dann kann der Gauß-Newton-Algorithmus wie folgt geschrieben werden:
boldsymbolp rightarrow boldsymbolp−[ boldsymbolJ rintercal boldsymbolJr]−1 boldsymbolJ rintercalr( boldsymbolp)
Die Aufzeichnung in der Form stimmt vollständig mit der Aufzeichnung der Newtonschen Methode überein. Nur anstelle der hessischen Matrix wird verwendet boldsymbolJ rintercal boldsymbolJr anstelle des Gradienten boldsymbolJ rintercalr( boldsymbolp) . Als nächstes werden wir sehen, warum eine solche Annäherung verwendet werden kann. Fahren wir in der Zwischenzeit mit der Implementierung auf TensorFlow fort:
[Out]: step: 1, current loss: 3868.2291666666665 step: 2, current loss: 14.653025157673625 step: 4, current loss: 4.3918079172783016e-07 ENDED ON STEP: 4, FINAL LOSS: 3.374364957618591e-17 PARAMETERS: [2.5 2.5]
Genug 4 Schritte. Weniger als bei Newtons Methode.
Wie aus dem Code ersichtlich ist, wird die Verlustfunktion bei der Optimierung nicht nur zum Stoppen und Protokollieren von Kriterien verwendet. Woher weiß der Optimierungsalgorithmus, welche Funktion zu minimieren ist? Die Antwort ist überraschend: auf keinen Fall! Gauß-Newton minimiert nur den mittleren quadratischen Fehler .
Korrigieren Sie den mathematischen Teil des Artikels
Wir wiederholten alle Mathe, die wir brauchten. Lassen Sie es uns ein wenig beheben, um uns weiter nur auf die Programmierung und TensorFlow zu konzentrieren. Möglicherweise benötigen Sie einen Bleistift, um die Abfolge der mathematischen Aktionen zu verfolgen.
Es gibt ein Modell y=f(x,p) wo x - Vektor p - Vektor der Dimensionsparameter n und y - Skalar. Aus den erhaltenen Experimenten m Punkte (x1,y1),...,(xm,ym) ( Datenpaare ). Die Vektorrestfunktion hängt nur vom Parametervektor ab: r(p)=(r1(p),...rm(p)) wo rk(p)=yk− widehatyk=yk−f(xk,p) . , p , xk,yk ? , xk,yk , .
p , ( sum of squared error — sse residual sum-of-squares — rss ) . mse sse , m . . :
loss(p)=r21(p)+⋯+r2m(p)=m∑k=1r2k(p)
p (p) .
, . — . — , r2 2r∂r∂p . :
∇ploss=(m∑k=12rk∂rk∂p1,⋯,m∑k=12rk∂rk∂pn)
. :
[Hlossp]ij=∂2loss∂pi∂pj=m∑k=1(2∂rk∂pi∂rk∂pj+2rk∂2rk∂pi∂pj)
. , , (uv)′=u′v+uv′ .
Großartig! .
, , , — 2rk∂2rk∂pi∂pj . , , rk , . — . , ? -.
:
Jr=(∂r1∂p1⋯∂r1∂pn⋮⋱⋮∂rm∂p1⋯∂pm∂pn)
, , . Beachten Sie Folgendes:
2J⊺rJr≈Hlossp
"" . ( ). , — 2rk∂2rk∂pi∂pj , .
( ):
2J⊺rr=∇ploss
, , - — , mse .
. , , . m (x1,y1),...,(xm,ym) , y=rosenbrock(x,p) . p , .
, : " . - ! ". , , , ( supervised learning ). , . : ( training set ) — ; — ( prediction model ) ; — , .
( multi-layer perceptron neural network mlp ). , , :
- ( starting values ) . Xavier'a, .
- ( overfitting ). — . , . — .
- ( scaling of the input ). , .
9 . 500:
500 . — ( learner ), ( outcome measurement ) ( features ) .
( network diagram ). MatLab:
( input ). W ( weights ) 2x10, b ( bias ) 10, ( activation ). () ( hidden layer ) 10 . , , ( output ).
, , ( tanh ):
h1=tanh(xW1+b1)ˆy=h1W2+b2
:
h1=tanh([x1x2][w(1)1,1⋯w(1)1,10w(1)2,1⋯w(1)2,10]+[b(1)1⋯b(1)10])ˆy=[h(1)1⋯h(1)10][w(2)1,1⋮w(2)1,10]+b2
. W1 "" h1 , - W2 . 41 . , .
m×2 , . - ˆy von m :
Adam
Adam rosenbrock . mse :
[Out]: step: 1, current loss: 671.4242576535694 [...] ENDED ON STEP: 40000, FINAL LOSS: 0.22862158574440725 VALIDATION LOSS: 0.29000289644978866
. : , , .
rosenbrock 2 . :
:
Jrp . , 4 W1,b1,W2,b2 . 4 JrW1,Jrb1,JrW2,Jrb2 tf.concat .
. tf.while_loop , ri , , stack .
ri W1 : [∂ri∂w(1)1,1⋯∂ri∂w(1)1,10∂ri∂w(1)2,1⋯∂ri∂w(1)2,10] . tf.reshape (-1,) [∂ri∂w(1)1,1⋯∂ri∂w(1)1,10∂ri∂w(1)2,1⋯∂ri∂w(1)2,10] .
. - . — TensorFlow . — - - W1,b1,W2,b2 . -. Levenberg-Marquardt Jupyter Notebook rosenbrock_train.py . , TensorFlow . - , ( ) , , .
-
hess_approx grad_approx -. rosenbrock , . :
- : Δp=[Δw(1)1,1⋯Δw(1)2,10Δb(1)1⋯Δb(1)10Δw(2)1,1⋯Δw(2)1,10Δb2]
- :
ΔW1=[Δw(1)1,1⋯Δw(1)2,10] , Δb1=[Δb(1)1⋯Δb(1)10] , ΔW2=[Δw(2)1,1⋯Δw(2)1,10] , Δb2=[Δb2] . - , :
ΔW1=[Δw(1)1,1⋯Δw(1)1,10Δw(1)2,1⋯Δw(1)2,10] , ΔW2=[Δw(2)1,1⋮Δw(2)1,10] - .
[Out]: step: 1, current loss: 548.8468777701685 step: 2, current loss: 49648941.340197295 InvalidArgumentError: Input is not invertible.
- . , . - , .
, .
-
. Matlab trainlm . . MathWorks.
- : p→p−[J⊺rJr]−1J⊺rr(p) . - :
p→p−[J⊺rJr+μI]−1J⊺rr(p)
mu I n ( ). mu , -. , . , LM -.
:
mu = tf.placeholder(tf.float64, shape=[1]) n = tf.add_n(parms_sizes) I = tf.eye(n, dtype=tf.float64)
mu ? LM - . , . , mu , . — , mse . , :
[Out]: step: 1, mu: 3.0 current loss: 692.6211687622557 [...] ENDED ON STEP: 100, FINAL LOSS: 0.012346989371823602 VALIDATION LOSS: 0.01859463694102034
100 LM mse 10 , 40 .
. , . , rosenbrock_train.py .
2D . . . , " " ( curse of dimentionality , Bellman, 1961). . .
:
f(x)=N−1∑i=1[100(xi+1−x2i)2+(1−xi)2],x=[x1⋯xN]∈RN
rosenbrock_train.py get_rand_rosenbrock_points .
-
- : " ! 4 , 300! ". , ( ) -. , , . - . . : ? , . . , - :
- 10 000 6D .
- 3 12, 10, 8 (311 ).
- .
- 3.5 .
. - 2 . LM . 20 .
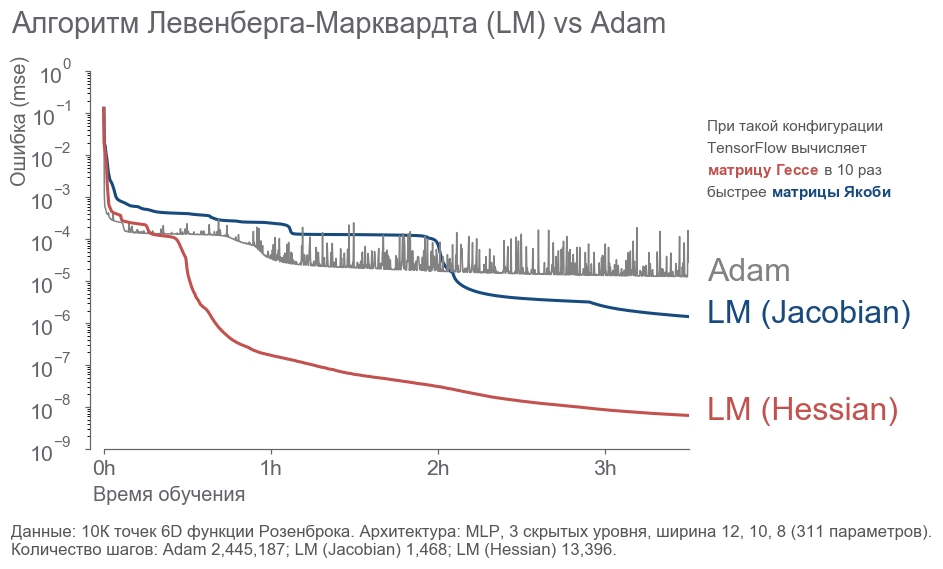
rosenbrock_train.py . . , .
Fazit
, . " ", , . , . , 273 . - , .
, :
- .
- ( ) -:
[1] Petros Drineas, Ravi Kannan, and Michael W. Mahoney. 2006. Fast Monte Carlo Algorithms for Matrices I: Approximating Matrix Multiplication. SIAM J. Comput. 36, 1 (July 2006), 132-157. DOI= http://dx.doi.org/10.1137/S0097539704442684
[2] Adelman, M., & Silberstein, M. (2018). Faster Neural Network Training with Approximate Tensor Operations. CoRR, abs/1805.08079.
, - . , . "".