Kontrollierte Bildsynthese und -bearbeitung mit dem neuen TL-GAN Beispiel für eine kontrollierte Synthese in meinem TL-GAN-Modell (transparentes Latent-Space-GAN, generativ-inhaltliches Netzwerk mit transparentem verborgenem Raum)
Beispiel für eine kontrollierte Synthese in meinem TL-GAN-Modell (transparentes Latent-Space-GAN, generativ-inhaltliches Netzwerk mit transparentem verborgenem Raum)Alle Code- und Online-Demos sind auf
der Projektseite verfügbar.
Wir trainieren den Computer, um Fotos wie beschrieben aufzunehmen
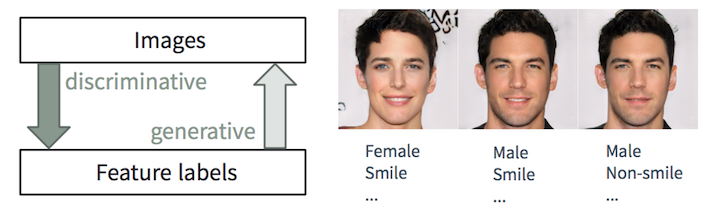 Diskriminierende und generative Aufgaben
Diskriminierende und generative AufgabenEs fällt einem Menschen leicht,
ein Bild zu
beschreiben . Wir lernen es schon in jungen Jahren. Beim maschinellen Lernen ist dies die Aufgabe der
diskriminanten Klassifizierung / Regression, d.h. Vorhersage von Merkmalen aus Eingabebildern. Die jüngsten Fortschritte bei ML / AI-Methoden, insbesondere bei Deep-Learning-Modellen, zeichnen sich bei diesen Aufgaben aus und erreichen oder übertreffen manchmal die menschlichen Fähigkeiten. Dies zeigt sich in Aufgaben wie der visuellen Objekterkennung (z. B. von AlexNet bis ResNet gemäß ImageNet-Klassifizierung) und der Erkennung / Segmentierung Objekte (z. B. von RCNN zu YOLO im COCO-Datensatz) usw.
Die umgekehrte Aufgabe
, aus der Beschreibung realistische Bilder zu
erstellen, ist jedoch viel komplizierter und erfordert eine langjährige Ausbildung in Grafikdesign. Beim maschinellen Lernen ist dies eine
generative Aufgabe, die viel komplizierter ist als diskriminierende Aufgaben, da das generative Modell auf der Grundlage kleinerer Anfangsdaten viel mehr Informationen (z. B. ein Vollbild mit einem bestimmten Detaillierungs- und Variationsgrad) generieren sollte.
Trotz der Komplexität beim Erstellen solcher Anwendungen sind
generative Modelle (mit einer gewissen Kontrolle) in vielen Fällen äußerst nützlich:
- Erstellung von Inhalten : Stellen Sie sich vor, eine Werbefirma erstellt automatisch attraktive Bilder, die dem Inhalt und dem Stil der Webseite entsprechen, auf der diese Bilder eingefügt werden. Der Designer sucht Inspiration, indem er den Algorithmus anordnet, 20 Schuhmuster zu generieren, die mit den Zeichen „Ruhe“, „Sommer“ und „Leidenschaft“ verbunden sind. Mit dem neuen Spiel können Sie aus einer einfachen Beschreibung realistische Avatare erstellen.
- Intelligente Bearbeitung basierend auf Inhalten : Der Fotograf ändert mit wenigen Klicks den Gesichtsausdruck, die Anzahl der Falten und die Frisur auf dem Foto. Ein Künstler in einem Hollywood-Studio konvertiert Aufnahmen, die an einem wolkigen Abend aufgenommen wurden, als wären sie an einem hellen Morgen aufgenommen worden, mit Sonnenlicht auf der linken Seite des Bildschirms.
- Datenerweiterung : Ein Drohnenentwickler kann realistische Videos für ein bestimmtes Unfallszenario synthetisieren, um den Trainingsdatensatz zu erweitern. Eine Bank kann bestimmte Arten von Betrugsdaten synthetisieren, die im vorhandenen Datensatz schlecht dargestellt sind, um das Betrugsbekämpfungssystem zu verbessern.
In diesem Artikel werden wir über unsere jüngste Arbeit namens
Transparent Latent-Space GAN (TL-GAN) sprechen, die die Funktionalität der modernsten Modelle erweitert und eine neue Schnittstelle bietet. Wir arbeiten derzeit an einem Dokument mit weiteren technischen Details.
Übersicht über generative Modelle
Die Deep-Learning-Community verbessert schnell generative Modelle. Unter ihnen können drei vielversprechende Typen unterschieden werden:
autoregressive Modelle ,
Variations-Autoencoder (VAE) und
generative kontradiktorische Netzwerke (GAN) (siehe Abbildung unten). Wenn Sie an den Details interessiert sind, lesen Sie bitte den ausgezeichneten OpenAI-Blogartikel.
 Vergleich generativer Netzwerke. Bild vom STAT946F17-Kurs an der University of Waterloo
Vergleich generativer Netzwerke. Bild vom STAT946F17-Kurs an der University of WaterlooDerzeit werden Bilder von
höchster Qualität von GAN-Netzwerken erzeugt (fotorealistisch und vielfältig, mit überzeugenden Details in hoher Auflösung). Schauen Sie sich das atemberaubende pg-GAN-Netzwerk (
progressiv wachsendes GAN ) von Nvidia an. Daher konzentrieren wir uns in diesem Artikel auf GAN-Modelle.
 Von Nvidia erzeugtes synthetisches pg-GAN . Keines der Bilder ist realitätsbezogen.
Von Nvidia erzeugtes synthetisches pg-GAN . Keines der Bilder ist realitätsbezogen.GAN Model Issue Management
 Zufällige und kontrollierte BilderzeugungDie Originalversion von GAN
Zufällige und kontrollierte BilderzeugungDie Originalversion von GAN und viele darauf basierende populäre Modelle (wie
DC-GAN und
pg-GAN ) unterrichten Modelle
ohne Lehrer . Nach dem Training nimmt das generative neuronale Netzwerk zufälliges Rauschen als Eingabe und erzeugt ein fotorealistisches Bild, das kaum vom Trainingsdatensatz zu unterscheiden ist. Wir können die Funktionen der generierten Bilder jedoch nicht zusätzlich steuern. In den meisten Anwendungen (z. B. in den im ersten Abschnitt beschriebenen Szenarien) möchten Benutzer Muster mit
beliebigen Attributen (z. B. Alter, Haarfarbe, Gesichtsausdruck usw.) erstellen. Konfigurieren Sie im Idealfall jede Funktion reibungslos.
Für eine solche kontrollierte Synthese wurden zahlreiche GAN-Varianten erstellt. Sie können bedingt in zwei Typen unterteilt werden: Stilübertragungsnetzwerke und bedingte Generatoren.
Stilübertragungsnetzwerke
Übertragungsnetzwerke im CycleGAN- und
pix2pix- Stil sind darauf trainiert, ein Bild von einem Bereich (einer Domäne) in einen anderen zu übertragen: zum Beispiel von einem Pferd zu einem Zebra, von einer Skizze zu Farbbildern. Infolgedessen können wir ein bestimmtes Vorzeichen zwischen zwei diskreten Zuständen nicht reibungslos ändern (z. B. einen kleinen Bart im Gesicht hinzufügen). Darüber hinaus ist ein Netzwerk für eine Übertragungsart ausgelegt, sodass zehn verschiedene neuronale Netzwerke erforderlich sind, um zehn Funktionen zu konfigurieren.
Zustandsgeneratoren
Bedingte Generatoren -
bedingte GAN ,
AC-GAN und Stack-GAN - untersuchen während des Trainings gleichzeitig Bilder und Beschriftungen von Objekten, sodass Sie Bilder mit der Einstellung von Attributen generieren können. Wenn Sie dem Generierungsprozess neue Funktionen hinzufügen möchten, müssen Sie das gesamte GAN-Modell neu trainieren, was enorme Rechenressourcen und Zeit erfordert (z. B. mehrere Tage bis Wochen auf derselben K80-GPU mit einem idealen Satz von Hyperparametern). Um die Schulung abzuschließen, ist es außerdem erforderlich, sich auf einen Datensatz zu verlassen, der alle benutzerdefinierten Objektbezeichnungen enthält, und keine unterschiedlichen Bezeichnungen aus mehreren Datensätzen zu verwenden.
Unser generativ-wettbewerbsfähiges Netzwerk mit transparentem verborgenem Raum (
Transparent Latent-Space GAN , TL-GAN) verwendet einen anderen Ansatz für die kontrollierte Erzeugung - und löst diese Probleme. Es bietet die Möglichkeit,
eine oder mehrere Funktionen nahtlos über ein einziges Netzwerk zu
konfigurieren . Darüber hinaus können Sie in weniger als einer Stunde effektiv neue benutzerdefinierte Funktionen hinzufügen.
TL-GAN: Ein neuer und effektiver Ansatz zur kontrollierten Synthese und Bearbeitung
Machen Sie diesen mysteriösen transparenten verborgenen Raum
Nehmen Sie das pvGAN-Modell von Nvidia, das hochauflösende fotorealistische Bilder von Gesichtern erzeugt, wie im vorherigen Abschnitt gezeigt. Alle Merkmale des erzeugten 1024 × 1024px-Bildes werden ausschließlich durch den 512-dimensionalen Rauschvektor im verborgenen Raum bestimmt (als niedrigdimensionale Darstellung des Bildinhalts).
Wenn wir also verstehen, was einen verborgenen Raum ausmacht (d. H. Ihn transparent macht), können wir den Erzeugungsprozess vollständig steuern .
 TL-GAN-Motivation: Den verborgenen Raum für die Verwaltung des Generierungsprozesses verstehen
TL-GAN-Motivation: Den verborgenen Raum für die Verwaltung des Generierungsprozesses verstehenBeim Experimentieren mit dem vorab trainierten pg-GAN-Netzwerk stellte ich fest, dass versteckter Raum tatsächlich zwei gute Eigenschaften hat:
- Es ist gut gefüllt, das heißt, die meisten Punkte im Raum erzeugen vernünftige Bilder.
- Es ist ziemlich kontinuierlich, dh die Interpolation zwischen zwei Punkten in einem verborgenen Raum führt normalerweise zu einem reibungslosen Übergang der entsprechenden Bilder.
Die Intuition sagt, dass es im verborgenen Raum Richtungen gibt, die die Attribute vorhersagen, die wir brauchen (zum Beispiel einen Mann / eine Frau). Wenn ja, werden die Einheitsvektoren dieser Richtungen zu Achsen zur Steuerung des Erzeugungsprozesses (männlicheres oder weiblicheres Gesicht).
Ansatz: Erweiterung der Funktionsachse
Um diese Attributachse in einem verborgenen Raum zu finden,
konstruieren wir eine Verbindung zwischen dem verborgenen Vektor und Tag-Labels mit Lehrerausbildung zu zweit
. Das Problem besteht nun darin, wie diese Paare abgerufen werden können, da vorhandene Datensätze nur Bilder enthalten
und entsprechende Objektbezeichnungen
.
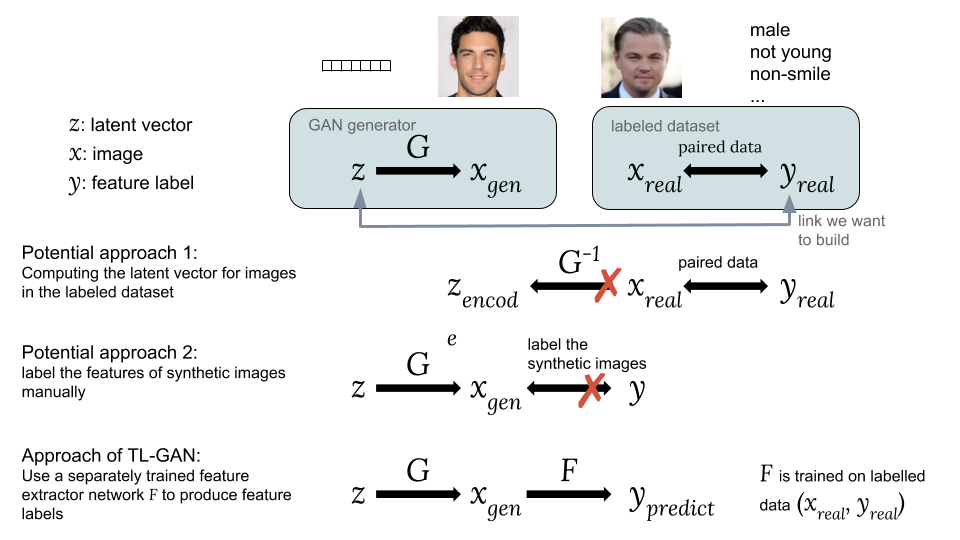 Möglichkeiten, einen versteckten Vektor z mit einem Tag-Label y zu verknüpfenMögliche Ansätze:Eine Möglichkeit besteht darin, die entsprechenden versteckten Vektoren zu berechnen Bilder aus einem vorhandenen Datensatz mit für uns interessanten Labels . Das GAN bietet jedoch keine einfache Möglichkeit zur Berechnung , was es schwierig macht, diese Idee umzusetzen.
Möglichkeiten, einen versteckten Vektor z mit einem Tag-Label y zu verknüpfenMögliche Ansätze:Eine Möglichkeit besteht darin, die entsprechenden versteckten Vektoren zu berechnen Bilder aus einem vorhandenen Datensatz mit für uns interessanten Labels . Das GAN bietet jedoch keine einfache Möglichkeit zur Berechnung , was es schwierig macht, diese Idee umzusetzen.
Die zweite Möglichkeit besteht darin, synthetische Bilder zu erzeugen Verwenden eines GAN aus einem zufälligen versteckten Vektor wie . Das Problem besteht darin, dass synthetische Bilder nicht mit Tags versehen sind, sodass es schwierig ist, einen zugänglichen Satz von mit Tags versehenen Daten zu verwenden.Die Hauptinnovation unseres TL-GAN-Modells ist das
Training eines separaten Extraktors (Klassifikator für diskrete Etiketten oder Regressor für kontinuierliche) mit dem Modell
Verwenden eines vorhandenen Satzes von markierten Daten (
,
) und starten Sie dann in einer Reihe von geschulten GAN-Generatoren
mit Feature-Extraktionsnetzwerk
. Auf diese Weise können Sie Feature-Labels vorhersagen.
synthetische Bilder
Verwenden eines geschulten Merkmalsextraktionsnetzwerks (Extraktor). Somit wird durch synthetische Bilder eine Verbindung zwischen hergestellt
und
wie
und
.
Jetzt haben wir einen gepaarten versteckten Vektor und Features. Sie können das Regressormodell trainieren
um alle Achsen der Features zu öffnen und den Bilderzeugungsprozess zu steuern.
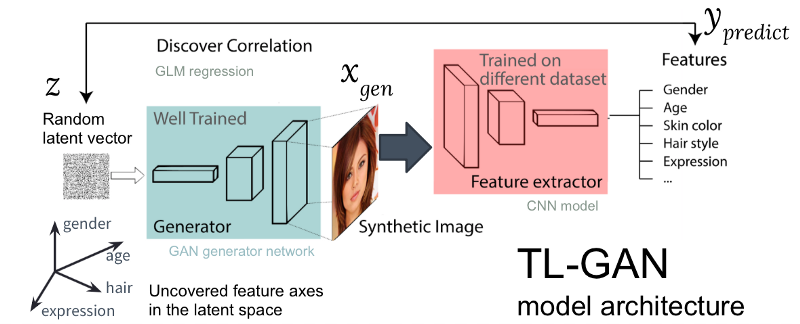 Abbildung: Die Architektur unseres TL-GAN-Modells
Abbildung: Die Architektur unseres TL-GAN-ModellsDie obige Abbildung zeigt die Architektur des TL-GAN-Modells, das fünf Schritte enthält:
- Das Studium der Verteilung . Wir wählen ein gut ausgebildetes GAN-Modell und ein generatives Netzwerk. Ich habe das gut ausgebildete pg-GAN (von Nvidia) genommen, das die beste Gesichtserzeugung bietet.
- Klassifizierung . Wir wählen ein vorab trainiertes Modell zum Extrahieren von Merkmalen aus (der Extraktor kann ein Faltungsnetzwerk oder andere Modelle der Bildverarbeitung sein) oder trainieren unseren eigenen Extraktor mithilfe eines Satzes markierter Daten. Ich habe ein einfaches Faltungs-Neuronales Netzwerk mit dem CelebA-Kit trainiert (über 30.000 Gesichter mit 40 Tags).
- Generation . Wir erstellen mehrere zufällige versteckte Vektoren, durchlaufen den trainierten GAN-Generator, um synthetische Bilder zu erstellen, und verwenden dann den trainierten Merkmalsextraktor, um Merkmale für jedes Bild zu erzeugen.
- Korrelation . Wir verwenden das generalisierte lineare Modell (GLM), um eine Regression zwischen versteckten Vektoren und Merkmalen zu implementieren. Die Steigung der Regressionslinie wird zur Achse der Merkmale .
- Forschung . Wir beginnen mit einem versteckten Vektor, bewegen ihn entlang einer oder mehrerer Achsen der Zeichen und untersuchen, wie sich dies auf die Erzeugung von Bildern auswirkt.
Ich habe den Prozess stark optimiert: Bei einem vorab trainierten GAN-Modell
dauert die Identifizierung von Feature-Achsen auf einer Maschine mit einer GPU
nur eine Stunde . Dies wird durch verschiedene technische Tricks erreicht, darunter das Übertragen von Schulungen, das Reduzieren der Bildgröße, das vorläufige Zwischenspeichern synthetischer Bilder usw.
Ergebnisse
Mal sehen, wie diese einfache Idee funktioniert.
Verschieben eines versteckten Vektors entlang der Achsen von Objekten
Zuerst habe ich geprüft, ob die erkannten Merkmalsachsen verwendet werden können, um das entsprechende Merkmal des erzeugten Bildes zu steuern. Erstellen Sie dazu einen zufälligen Vektor
im verborgenen Raum des GAN und erzeugen ein synthetisches Bild
Weitergabe durch ein generatives Netzwerk
. Dann bewegen wir den verborgenen Vektor entlang einer Merkmalsachse
(ein Einheitsvektor im verborgenen Raum, der beispielsweise dem Geschlecht des Gesichts entspricht) in einiger Entfernung
zu einer neuen Position
und generieren Sie ein neues Bild
. Idealerweise sollte sich das entsprechende Merkmal des neuen Bildes in die erwartete Richtung ändern.
Die Ergebnisse der Bewegung eines Vektors entlang mehrerer Attributachsen (Geschlecht, Alter usw.) sind nachstehend aufgeführt. Es funktioniert überraschend gut! Sie können
das Bild zwischen einem Mann / einer Frau, einem jungen Mann / einem alten Mann usw.
reibungslos transformieren .
 Die ersten Ergebnisse der Bewegung eines verborgenen Vektors entlang verwickelter Merkmalsachsen
Die ersten Ergebnisse der Bewegung eines verborgenen Vektors entlang verwickelter MerkmalsachsenEnträtseln der korrelierten Merkmalsachsen
In den obigen Beispielen ist der Nachteil der ursprünglichen Methode sichtbar, nämlich die verwirrte Achse der Attribute. Wenn Sie beispielsweise das Gesichtshaar reduzieren müssen, werden die generierten Gesichter weiblicher, was nicht das erwartete Ergebnis ist. Das Problem ist, dass Geschlecht und Bart inhärent miteinander
korrelieren . Eine Änderung eines Merkmals führt zu einer Änderung eines anderen. Ähnliches geschah mit anderen Merkmalen wie Haar und lockigem Haar. Wie in der folgenden Abbildung gezeigt, ist die ursprüngliche Achse des Attributs "Bart" im verborgenen Raum nicht senkrecht zur Achse "Boden".
Um das Problem zu lösen, habe ich die Techniken der einfachen linearen Algebra verwendet. Insbesondere projizierte er die Bartachse in eine neue Richtung, orthogonal zur Bodenachse, wodurch ihre Korrelation effektiv beseitigt wird und somit möglicherweise diese beiden Zeichen auf den erzeugten Flächen entwirrt werden können.
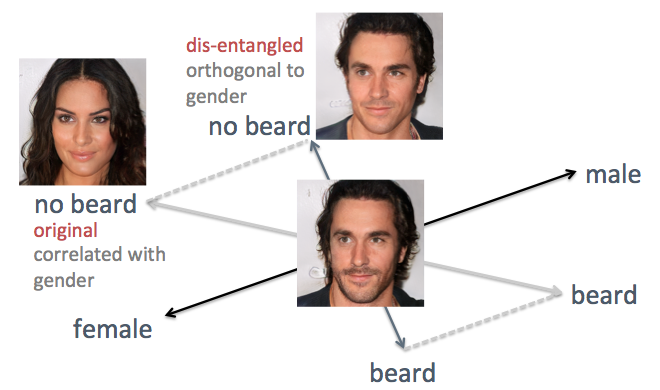 Enträtseln der korrelierten Merkmalsachsen mit linearen Algebra-Techniken
Enträtseln der korrelierten Merkmalsachsen mit linearen Algebra-TechnikenIch habe diese Methode auf dieselbe Person angewendet. Dieses Mal werden die Achsen von Geschlecht und Alter als unterstützende Achsen ausgewählt, wobei alle anderen Achsen so projiziert werden, dass sie orthogonal zu Geschlecht und Alter werden. Gesichter werden erzeugt, indem der verborgene Vektor entlang der neu erzeugten Merkmalsachsen verschoben wird (siehe Abbildung unten). Wie erwartet wirken Zeichen wie Frisuren und Bärte jetzt nicht mehr auf den Boden.
 Verbessertes Ergebnis beim Verschieben eines verborgenen Vektors entlang entwirrter Merkmalsachsen
Verbessertes Ergebnis beim Verschieben eines verborgenen Vektors entlang entwirrter MerkmalsachsenFlexible interaktive Bearbeitung
Um zu sehen, wie flexibel unser TL-GAN-Modell den Bilderzeugungsprozess steuern kann, habe ich eine interaktive grafische Oberfläche mit einer reibungslosen Änderung der Werte von Objekten entlang verschiedener Achsen erstellt, wie unten gezeigt.
Interaktive Bearbeitung mit TL-GANUnd wieder funktioniert das Modell überraschend gut, wenn Sie das Bild entlang der Achse der Zeichen ändern!
Zusammenfassung
Dieses Projekt demonstriert eine neue Methode zur Verwaltung eines generativen Modells ohne Lehrer, wie z. B. das GAN (generative adversarial network). Mit einem vorab trainierten GAN-Generator (pg-GAN von Nvidia) machte ich seinen verborgenen Raum transparent, indem ich die Achsen wichtiger Merkmale zeigte. Wenn sich ein Vektor in einem verborgenen Raum entlang einer solchen Achse bewegt, wird das entsprechende Bild entlang dieser Funktion transformiert, wodurch eine kontrollierte Synthese und Bearbeitung ermöglicht wird.
Diese Methode hat klare Vorteile:
- Effizienz: Um einen neuen Tag-Tuner für den Generator hinzuzufügen, müssen Sie das GAN-Modell nicht neu trainieren. Das Hinzufügen von Tunern für 40 Tags dauert also weniger als eine Stunde.
- Flexibilität: Sie können jeden Feature-Extraktor verwenden, der für jedes Dataset trainiert wurde, und einem gut trainierten GAN weitere Features hinzufügen.
Ein paar Worte zur Ethik
Diese Arbeit ermöglicht es Ihnen, die Bilderzeugung im Detail zu steuern, hängt jedoch weitgehend von den Eigenschaften des Datensatzes ab. Das Training auf Fotos von Hollywoodstars bedeutet, dass das Modell sehr gut Fotos von meist weißen und attraktiven Menschen erzeugt. Dies führt dazu, dass Benutzer Gesichter erstellen können, die nur einen kleinen Teil der Menschheit repräsentieren. Wenn Sie diesen Dienst als echte Anwendung bereitstellen, ist es ratsam, den ursprünglichen Datensatz zu erweitern, um die Vielfalt unserer Benutzer zu berücksichtigen.
Obwohl das Tool im kreativen Prozess sehr hilfreich sein kann, müssen Sie sich an die Möglichkeiten erinnern, es für unangemessene Zwecke zu verwenden. Wenn wir realistische Gesichter jeglicher Art erstellen, inwieweit können wir dann der Person vertrauen, die wir auf dem Bildschirm sehen? Heute ist es wichtig, solche Themen zu diskutieren. Wie wir in jüngsten Beispielen der
Deepfake- Technologie gesehen haben, schreitet die KI rasant voran.
Daher ist es für die Menschheit von entscheidender Bedeutung, eine Diskussion darüber zu beginnen, wie solche Anwendungen am besten bereitgestellt werden können.
Online-Demo und Code
Der gesamte Code und die Online-Demos für diese Arbeit sind auf
der GitHub-Seite verfügbar.
Wenn Sie mit dem Modell im Browser spielen möchten
Sie müssen keinen Code, kein Modell oder keine Daten herunterladen. Folgen Sie einfach den Anweisungen in
diesem Readme-
Abschnitt . Sie können die Gesichter im Browser wie im Video gezeigt ändern.
Wenn Sie den Code ausprobieren möchten
Gehen Sie einfach zur Readme-Seite des GitHub-Repositorys. Code, der auf Anaconda Python 3.6 mit Tensorflow und Keras kompiliert wurde.
Wenn Sie dazu beitragen möchten
Willkommen zurück! Sie können gerne eine Poolanfrage stellen oder ein Problem auf GitHub melden.
Über mich
Ich habe kürzlich an der Brown University in rechnergestützter und kognitiver Neurobiologie promoviert und einen Master in Informatik mit Spezialisierung auf maschinelles Lernen erworben. In der Vergangenheit habe ich untersucht, wie Neuronen im Gehirn Informationen gemeinsam verarbeiten, um Funktionen auf hoher Ebene wie die visuelle Wahrnehmung zu erreichen. Ich mag den algorithmischen Ansatz zur Analyse, Simulation und Implementierung von Intelligenz sowie zur Verwendung von KI zur Lösung komplexer Probleme der realen Welt. Ich suche aktiv einen Job als ML / AI-Forscher in der Technologiebranche.
Danksagung
Diese Arbeit wurde in drei Wochen als Projekt für
das InSight AI-Stipendienprogramm durchgeführt . Ich danke dem Programmdirektor
Emmanuel Amaisen und
Matt Rubashkin für die allgemeine Führung, insbesondere Emmanuel für seine Vorschläge und die Bearbeitung des Artikels. Ich danke auch allen Insight-Mitarbeitern für die hervorragende Lernumgebung und anderen Insight AI-Programmteilnehmern, von denen ich viel gelernt habe.
Besonderer Dank geht an Rubin Xia für die vielen Tipps und Inspirationen, als ich mich für die Entwicklung des Projekts entschieden habe, und für die enorme Hilfe bei der Strukturierung und Bearbeitung dieses Artikels.