Maschinelles Lernen wird immer zugänglicher, es gibt mehr Möglichkeiten, diese Technologie mithilfe von „Standardkomponenten“ anzuwenden. Mit Transfer Learning können Sie beispielsweise die Erfahrungen bei der Lösung eines Problems nutzen, um ein anderes, ähnliches Problem zu lösen. Das neuronale Netzwerk wird zuerst mit einer großen Datenmenge und dann mit dem Zielsatz trainiert.

In diesem Artikel werde ich Ihnen am Beispiel der Erkennung von Bildern mit Lebensmitteln die Verwendung der Transfer-Lernmethode erläutern. Ich werde auf
dem Workshop "
Maschinelles Lernen und Neuronale Netze für Entwickler" über andere Tools für maschinelles Lernen sprechen.
Wenn wir vor der Aufgabe der Bilderkennung stehen, können Sie den vorgefertigten Service nutzen. Wenn Sie das Modell jedoch anhand Ihres eigenen Datensatzes trainieren müssen, müssen Sie dies selbst tun.
Für typische Aufgaben wie die Bildklassifizierung können Sie die vorgefertigte Architektur (AlexNet, VGG, Inception, ResNet usw.) verwenden und das neuronale Netzwerk auf Ihre Daten trainieren. Es gibt bereits Implementierungen solcher Netzwerke unter Verwendung verschiedener Frameworks. In diesem Stadium können Sie eines davon als Black Box verwenden, ohne sich eingehend mit dessen Funktionsprinzip zu befassen.
Tiefe neuronale Netze erfordern jedoch große Datenmengen für die Konvergenz des Lernens. Und oft gibt es in unserer speziellen Aufgabe nicht genügend Daten, um alle Schichten des neuronalen Netzwerks richtig zu trainieren. Transfer Learning löst dieses Problem.
Transferlernen zur Bildklassifizierung
Die neuronalen Netze, die zur Klassifizierung verwendet werden, enthalten normalerweise
N Ausgangsneuronen in der letzten Schicht, wobei
N die Anzahl der Klassen ist. Ein solcher Ausgabevektor wird als eine Menge von Wahrscheinlichkeiten der Zugehörigkeit zu einer Klasse behandelt. Bei unserer Aufgabe, Lebensmittelbilder zu erkennen, kann die Anzahl der Klassen von der im Originaldatensatz abweichen. In diesem Fall müssen wir diese letzte Schicht vollständig wegwerfen und eine neue mit der richtigen Anzahl von Ausgangsneuronen einfügen
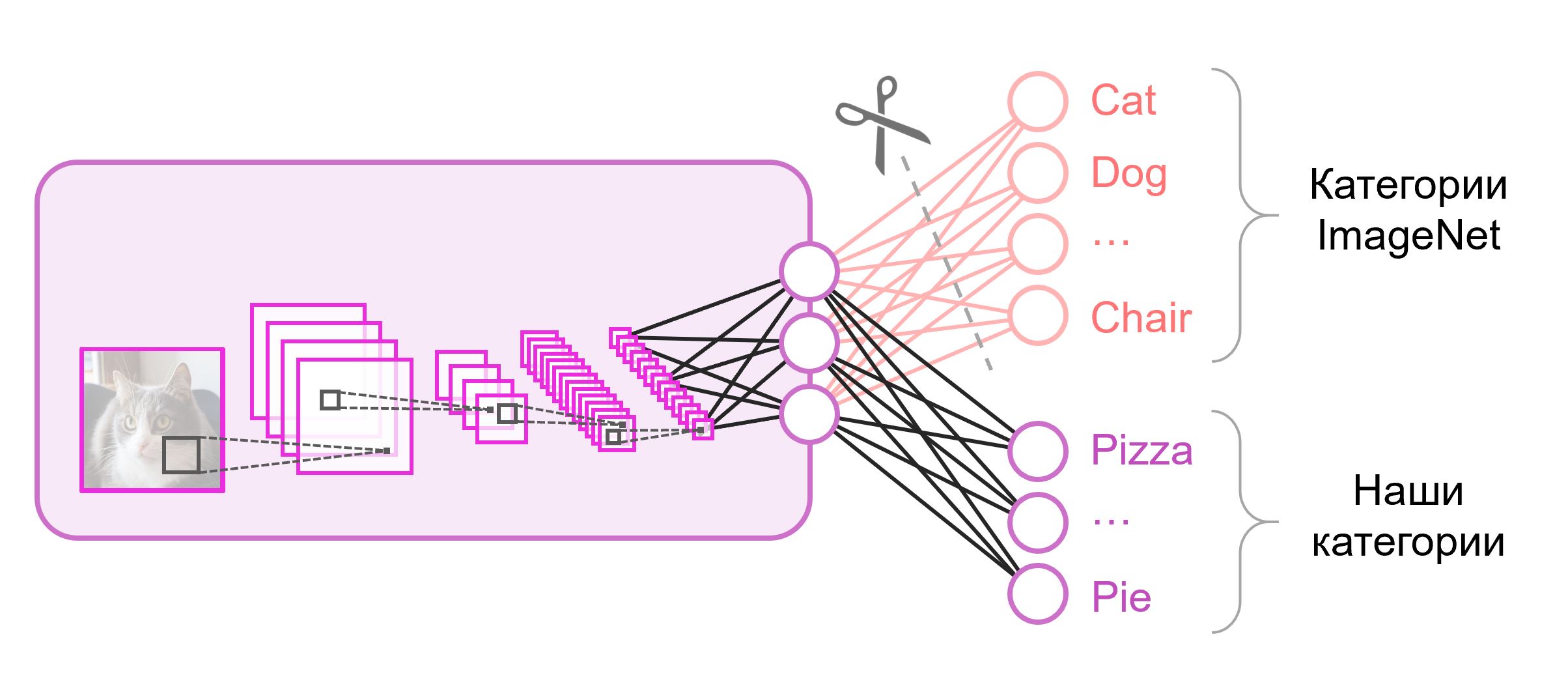
Oft wird am Ende von Klassifizierungsnetzwerken eine vollständig verbundene Schicht verwendet. Da wir diese Schicht ersetzt haben, funktioniert es nicht, vorab trainierte Gewichte zu verwenden. Sie müssen ihn von Grund auf neu trainieren und seine Gewichte mit zufälligen Werten initialisieren. Wir laden Gewichte für alle anderen Ebenen aus einem vorab trainierten Schnappschuss.
Es gibt verschiedene Strategien zur Weiterbildung des Modells. Wir werden Folgendes verwenden: Wir werden das gesamte Netzwerk von Ende zu Ende (
Ende zu Ende ) trainieren und die vorab trainierten Gewichte nicht korrigieren, damit sie sich ein wenig anpassen und sich an unsere Daten anpassen können. Dieser Vorgang wird als
Feinabstimmung bezeichnet .
Strukturelle Komponenten
Um das Problem zu lösen, benötigen wir die folgenden Komponenten:
- Beschreibung des neuronalen Netzwerkmodells
- Lernpipeline
- Interferenzpipeline
- Vorgeübte Gewichte für dieses Modell
- Daten für Training und Validierung
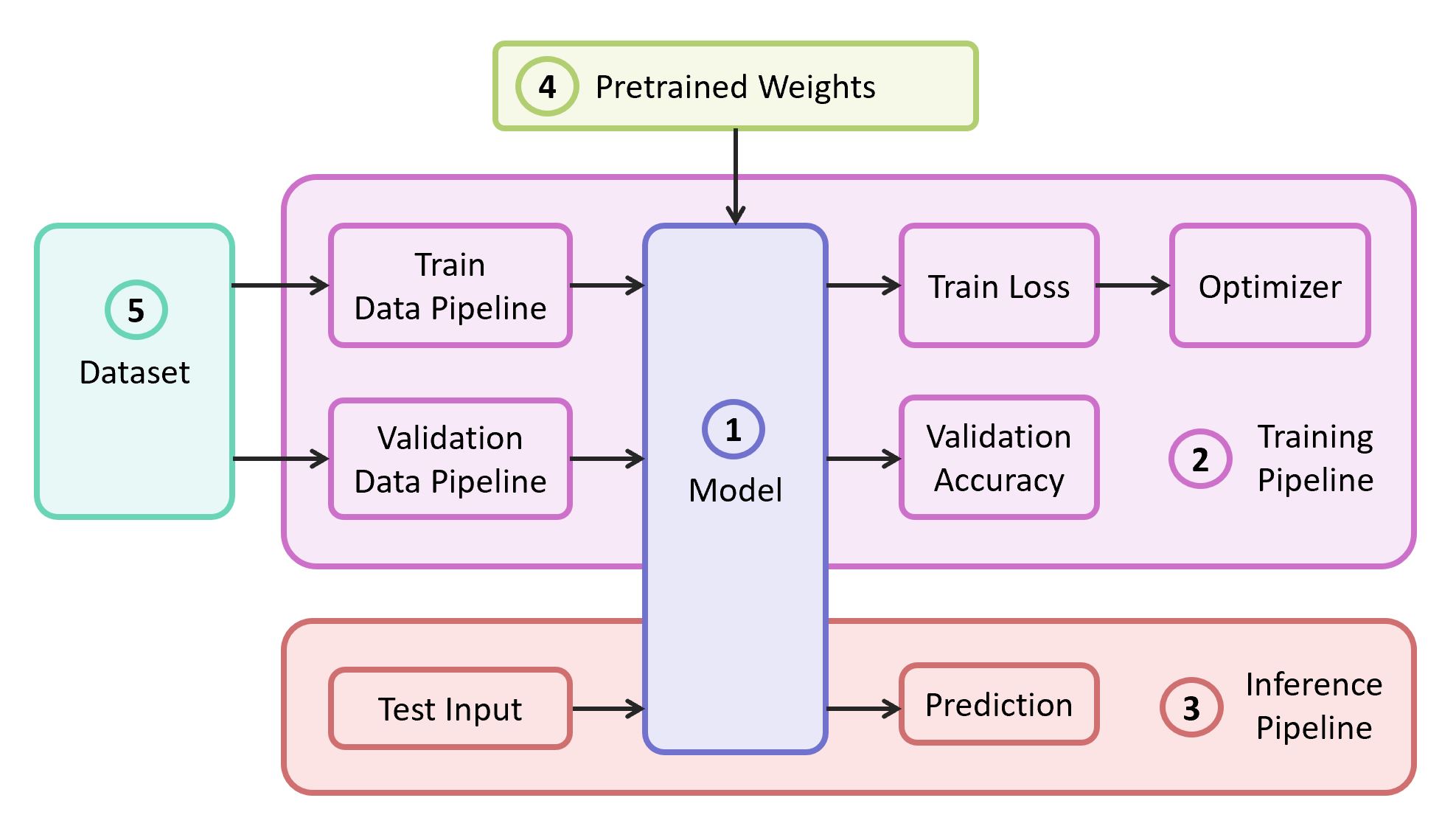
In unserem Beispiel nehme ich die Komponenten (1), (2) und (3) aus
meinem eigenen Repository , das den leichtesten Code enthält - Sie können es leicht herausfinden, wenn Sie möchten. Unser Beispiel wird auf dem beliebten
TensorFlow- Framework implementiert. Vorgeübte Gewichte (4), die für das ausgewählte Gerüst geeignet sind, können gefunden werden, wenn sie einer der klassischen Architekturen entsprechen. Als Datensatz (5) zur Demonstration werde ich
Food-101 nehmen .
Modell
Als Modell verwenden wir das klassische neuronale
VGG- Netzwerk (genauer gesagt
VGG19 ). Trotz einiger Nachteile weist dieses Modell eine relativ hohe Qualität auf. Darüber hinaus ist es einfach zu analysieren. Bei TensorFlow Slim sieht die Modellbeschreibung recht kompakt aus:
import tensorflow as tf import tensorflow.contrib.slim as slim def vgg_19(inputs, num_classes, is_training, scope='vgg_19', weight_decay=0.0005): with slim.arg_scope([slim.conv2d], activation_fn=tf.nn.relu, weights_regularizer=slim.l2_regularizer(weight_decay), biases_initializer=tf.zeros_initializer(), padding='SAME'): with tf.variable_scope(scope, 'vgg_19', [inputs]): net = slim.repeat(inputs, 2, slim.conv2d, 64, [3, 3], scope='conv1') net = slim.max_pool2d(net, [2, 2], scope='pool1') net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], scope='conv2') net = slim.max_pool2d(net, [2, 2], scope='pool2') net = slim.repeat(net, 4, slim.conv2d, 256, [3, 3], scope='conv3') net = slim.max_pool2d(net, [2, 2], scope='pool3') net = slim.repeat(net, 4, slim.conv2d, 512, [3, 3], scope='conv4') net = slim.max_pool2d(net, [2, 2], scope='pool4') net = slim.repeat(net, 4, slim.conv2d, 512, [3, 3], scope='conv5') net = slim.max_pool2d(net, [2, 2], scope='pool5')
Die auf ImageNet trainierten und mit TensorFlow kompatiblen Gewichte für VGG19 werden aus dem Repository auf GitHub im Abschnitt
Vorgefertigte Modelle heruntergeladen.
mkdir data && cd data wget http://download.tensorflow.org/models/vgg_19_2016_08_28.tar.gz tar -xzf vgg_19_2016_08_28.tar.gz
Datacet
Als Trainings- und Validierungsbeispiel verwenden wir den öffentlichen
Food-101- Datensatz, der mehr als 100.000 Lebensmittelbilder enthält und in 101 Kategorien unterteilt ist.

Laden Sie den Datensatz herunter und entpacken Sie ihn:
cd data wget http://data.vision.ee.ethz.ch/cvl/food-101.tar.gz tar -xzf food-101.tar.gz
Die Datenpipeline in unserem Training ist so konzipiert, dass wir aus dem Datensatz Folgendes analysieren müssen:
- Liste der Klassen (Kategorien)
- Tutorial: Eine Liste der Pfade zu Bildern und eine Liste der richtigen Antworten
- Validierungssatz: Liste der Pfade zu Bildern und Liste der richtigen Antworten
Wenn Ihr Datensatz, dann müssen Sie für
Zug und
Validierung die Sätze selbst brechen. Food-101 hat bereits eine solche Partition, und diese Informationen werden im
meta Verzeichnis gespeichert.
DATASET_ROOT = 'data/food-101/' train_data, val_data, classes = data.food101(DATASET_ROOT) num_classes = len(classes)
Alle für die Datenverarbeitung verantwortlichen Hilfsfunktionen werden in eine separate Datei
data.py :
data.py from os.path import join as opj import tensorflow as tf def parse_ds_subset(img_root, list_fpath, classes): ''' Parse a meta file with image paths and labels -> img_root: path to the root of image folders -> list_fpath: path to the file with the list (eg train.txt) -> classes: list of class names <- (list_of_img_paths, integer_labels) ''' fpaths = [] labels = [] with open(list_fpath, 'r') as f: for line in f: class_name, image_id = line.strip().split('/') fpaths.append(opj(img_root, class_name, image_id+'.jpg')) labels.append(classes.index(class_name)) return fpaths, labels def food101(dataset_root): ''' Get lists of train and validation examples for Food-101 dataset -> dataset_root: root of the Food-101 dataset <- ((train_fpaths, train_labels), (val_fpaths, val_labels), classes) ''' img_root = opj(dataset_root, 'images') train_list_fpath = opj(dataset_root, 'meta', 'train.txt') test_list_fpath = opj(dataset_root, 'meta', 'test.txt') classes_list_fpath = opj(dataset_root, 'meta', 'classes.txt') with open(classes_list_fpath, 'r') as f: classes = [line.strip() for line in f] train_data = parse_ds_subset(img_root, train_list_fpath, classes) val_data = parse_ds_subset(img_root, test_list_fpath, classes) return train_data, val_data, classes def imread_and_crop(fpath, inp_size, margin=0, random_crop=False): ''' Construct TF graph for image preparation: Read the file, crop and resize -> fpath: path to the JPEG image file (TF node) -> inp_size: size of the network input (eg 224) -> margin: cropping margin -> random_crop: perform random crop or central crop <- prepared image (TF node) ''' data = tf.read_file(fpath) img = tf.image.decode_jpeg(data, channels=3) img = tf.image.convert_image_dtype(img, dtype=tf.float32) shape = tf.shape(img) crop_size = tf.minimum(shape[0], shape[1]) - 2 * margin if random_crop: img = tf.random_crop(img, (crop_size, crop_size, 3)) else:
Modelltraining
Der Modell-Trainingscode besteht aus folgenden Schritten:
- Bau von Zug- / Validierungsdaten -Pipelines
- Erstellen von Zug- / Validierungsgraphen (Netzwerken)
- Anhängen der Klassifizierungsfunktion von Verlusten ( Kreuzentropieverlust ) über Zuggraph
- Der Code, der benötigt wird, um die Genauigkeit der Vorhersagen auf der Validierungsprobe während des Trainings zu berechnen
- Logik zum Laden vorab trainierter Waagen aus einem Schnappschuss
- Schaffung verschiedener Strukturen für das Training
- Der Lernzyklus selbst (iterative Optimierung)
Die letzte Ebene des Diagramms besteht aus der erforderlichen Anzahl von Neuronen und wird aus der Liste der Parameter ausgeschlossen, die aus dem vorab trainierten Schnappschuss geladen wurden.
Modell Trainingscode import numpy as np import tensorflow as tf import tensorflow.contrib.slim as slim tf.logging.set_verbosity(tf.logging.INFO) import model import data
Nach dem Start des Trainings können Sie den Fortschritt mithilfe des TensorBoard-Dienstprogramms anzeigen, das im Lieferumfang von TensorFlow enthalten ist und zur Visualisierung verschiedener Metriken und anderer Parameter dient.
tensorboard --logdir checkpoints/
Am Ende des Trainings bei TensorBoard sehen wir ein nahezu perfektes Bild: eine Verringerung des Zugverlusts und eine Erhöhung der
Validierungsgenauigkeit
Als Ergebnis erhalten wir den gespeicherten Snapshot in
checkpoints/vgg19_food , den wir beim Testen unseres Modells verwenden (
Inferenz ).
Modellprüfung
Testen Sie jetzt unser Modell. Dafür:
- Wir konstruieren einen neuen Graphen, der speziell für die Inferenz entwickelt wurde (
is_training=False ). - Laden Sie trainierte Gewichte aus einem Schnappschuss
- Laden Sie das eingegebene Testbild herunter und verarbeiten Sie es vor.
- Lassen Sie uns das Bild durch das neuronale Netzwerk fahren und die Vorhersage erhalten
inference.py import sys import numpy as np import imageio from skimage.transform import resize import tensorflow as tf import model
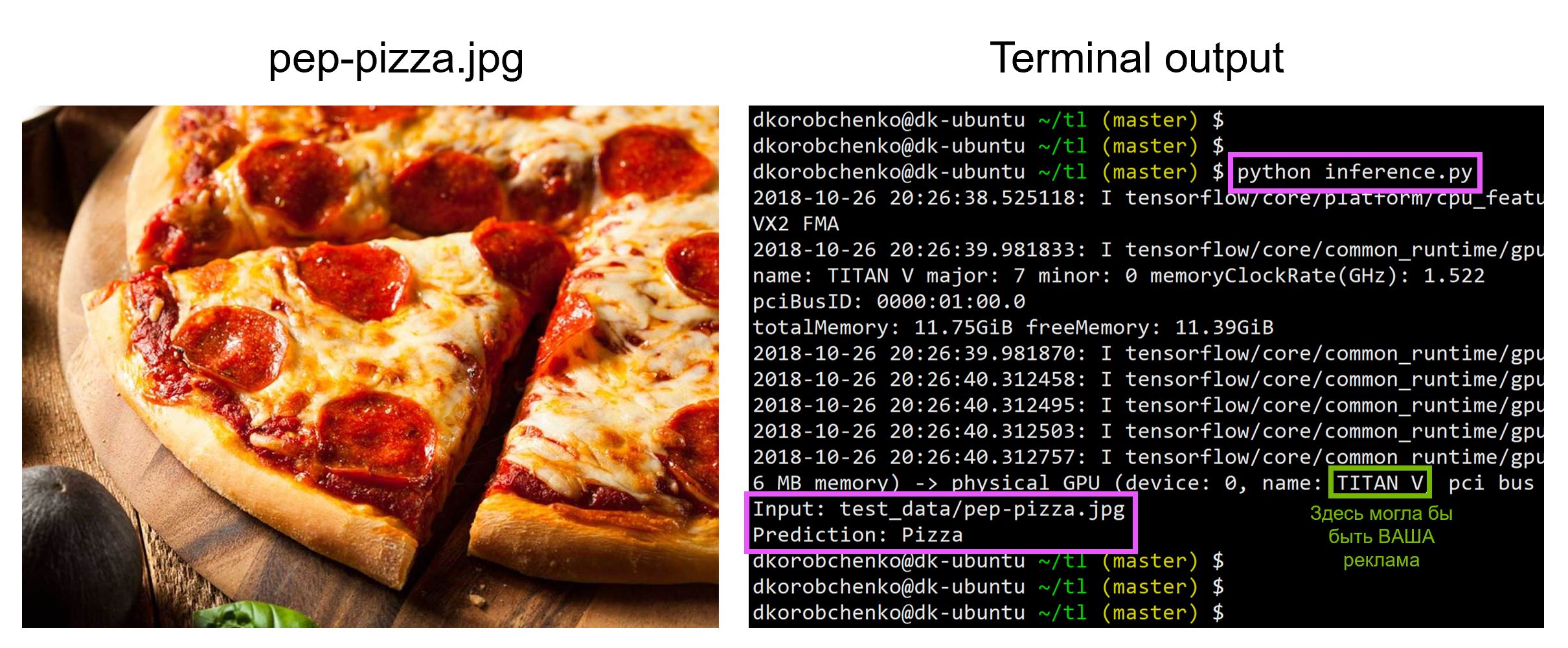
Der gesamte Code, einschließlich der Ressourcen zum Erstellen und Ausführen eines Docker-Containers mit allen erforderlichen Versionen von Bibliotheken, befindet sich in
diesem Repository. Zum Zeitpunkt des Lesens des Artikels enthält der Code im Repository möglicherweise Aktualisierungen.
Beim Workshop
„Maschinelles Lernen und Neuronale Netze für Entwickler“ werde ich andere Aufgaben des maschinellen Lernens analysieren und die Schüler werden ihre Projekte am Ende der intensiven Sitzung vorstellen.