
Auf der KI-Konferenz wird
Vladimir Ivanov vivanov879 , Sr. über den Einsatz von verstärktem Lernen sprechen
Deep Learning Ingenieur bei Nvidia . Der Experte beschäftigt sich mit maschinellem Lernen in der Testabteilung: „Ich analysiere die Daten, die wir beim Testen von Videospielen und Hardware sammeln. Dafür benutze ich maschinelles Lernen und Computer Vision. Der Hauptteil der Arbeit besteht in der Bildanalyse, Datenbereinigung vor dem Training, Datenmarkierung und Visualisierung der erhaltenen Lösungen. “
In dem heutigen Artikel erklärt Vladimir anhand von Videospielbeispielen, warum verstärktes Lernen in autonomen Autos eingesetzt wird, und spricht darüber, wie ein Agent in einer sich ändernden Umgebung geschult wird.
In den letzten Jahren hat die Menschheit eine riesige Datenmenge gesammelt. Einige Datensätze werden gemeinsam genutzt und manuell angelegt. Zum Beispiel das CIFAR-Dataset, in dem jedes Bild signiert ist und zu welcher Klasse es gehört.
Es gibt Datensätze, in denen Sie nicht nur dem gesamten Bild, sondern jedem Pixel im Bild eine Klasse zuweisen müssen. Wie zum Beispiel in CityScapes.

Was diese Aufgaben verbindet, ist, dass sich ein lernendes neuronales Netzwerk nur die Muster in den Daten merken muss. Daher lernt das neuronale Netzwerk mit ausreichend großen Datenmengen und im Fall von CIFAR mit 80 Millionen Bildern, zu verallgemeinern. Infolgedessen kommt sie gut mit der Klassifizierung von Bildern zurecht, die sie noch nie zuvor gesehen hatte.
Im Rahmen der Unterrichtstechnik mit dem Lehrer, der zum Markieren von Bildern arbeitet, ist es jedoch unmöglich, Probleme zu lösen, bei denen wir die Note nicht vorhersagen, sondern Entscheidungen treffen wollen. Wie zum Beispiel beim autonomen Fahren, bei dem es darum geht, den Endpunkt der Route sicher und zuverlässig zu erreichen.
Bei den Klassifizierungsproblemen haben wir die Unterrichtstechnik mit dem Lehrer verwendet - wenn jedem Bild eine bestimmte Klasse zugewiesen wurde. Was aber, wenn wir kein solches Markup haben, aber es einen Agenten und eine Umgebung gibt, in der er bestimmte Aktionen ausführen kann? Lassen Sie es zum Beispiel ein Videospiel sein, und wir können auf die Steuerpfeile klicken.

Diese Art von Problem sollte mit einem Verstärkungstraining gelöst werden. In der allgemeinen Erklärung des Problems möchten wir lernen, wie die richtige Abfolge von Aktionen ausgeführt wird. Es ist von grundlegender Bedeutung, dass der Agent in der Lage ist, immer wieder Aktionen auszuführen und so die Umgebung zu erkunden, in der er sich befindet. Und anstatt der richtigen Antwort, was in einer bestimmten Situation zu tun ist, erhält er eine Belohnung für eine korrekt erledigte Aufgabe. Im Fall eines autonomen Taxis erhält der Fahrer beispielsweise für jede Fahrt einen Bonus.
Kehren wir zu einem einfachen Beispiel zurück - einem Videospiel. Nehmen Sie etwas Einfaches, wie das Atari-Tischtennisspiel.
Wir werden das Tablet auf der linken Seite steuern. Wir werden gegen den Computer spielen, der nach den Regeln auf der rechten Seite programmiert ist. Da wir mit einem Bild arbeiten und neuronale Netze am erfolgreichsten Informationen aus Bildern extrahieren, wenden wir ein Bild auf die Eingabe eines dreischichtigen neuronalen Netzes mit einer Kernelgröße von 3 x 3 an. Am Ausgang muss sie eine von zwei Aktionen auswählen: Bewegen Sie das Brett nach oben oder unten.
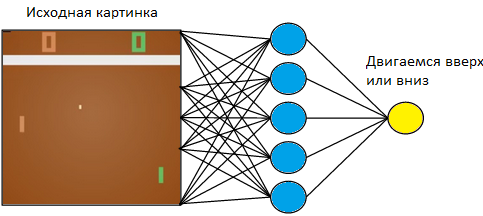
Wir trainieren das neuronale Netzwerk, um Aktionen auszuführen, die zum Sieg führen. Die Trainingstechnik ist wie folgt. Wir lassen das neuronale Netz ein paar Runden Tischtennis spielen. Dann beginnen wir, die gespielten Spiele zu sortieren. In den Spielen, in denen sie gewonnen hat, markieren wir die Bilder mit der Aufschrift „Up“, wo sie den Schläger hob, und „Down“, wo sie sie senkte. In verlorenen Spielen machen wir das Gegenteil. Wir markieren die Bilder, auf denen sie die Tafel mit dem Etikett „Up“ abgesenkt und dort, wo sie sie angehoben hat, „Down“. So reduzieren wir das Problem auf den Ansatz, den wir bereits kennen - das Training mit einem Lehrer. Wir haben eine Reihe von Bildern mit Tags.
Mit dieser Trainingstechnik lernt unser Agent in ein paar Stunden, einen nach den Regeln programmierten Computerspieler zu schlagen.
Was tun mit autonomem Fahren? Tatsache ist, dass Tischtennis ein sehr einfaches Spiel ist. Und es kann Tausende von Bildern pro Sekunde erzeugen. In unserem Netzwerk gibt es jetzt nur noch 3 Schichten. Daher ist der Lernprozess blitzschnell. Das Spiel generiert eine große Datenmenge und wir verarbeiten sie sofort. Beim autonomen Fahren ist das Sammeln von Daten viel länger und teurer. Autos sind teuer und mit einem Auto erhalten wir nur 60 Bilder pro Sekunde. Außerdem steigt der Fehlerpreis. In einem Videospiel könnten wir es uns leisten, zu Beginn des Trainings Spiel für Spiel zu spielen. Aber wir können es uns nicht leisten, das Auto zu verderben.
In diesem Fall helfen wir dem neuronalen Netzwerk zu Beginn des Trainings. Wir befestigen die Kamera am Auto, setzen einen erfahrenen Fahrer ein und nehmen Fotos von der Kamera auf. Für jedes Bild abonnieren wir den Lenkwinkel des Autos. Wir werden das neuronale Netzwerk trainieren, um das Verhalten eines erfahrenen Fahrers zu kopieren. So haben wir die Aufgabe wieder auf den bereits bekannten Unterricht mit einem Lehrer reduziert.
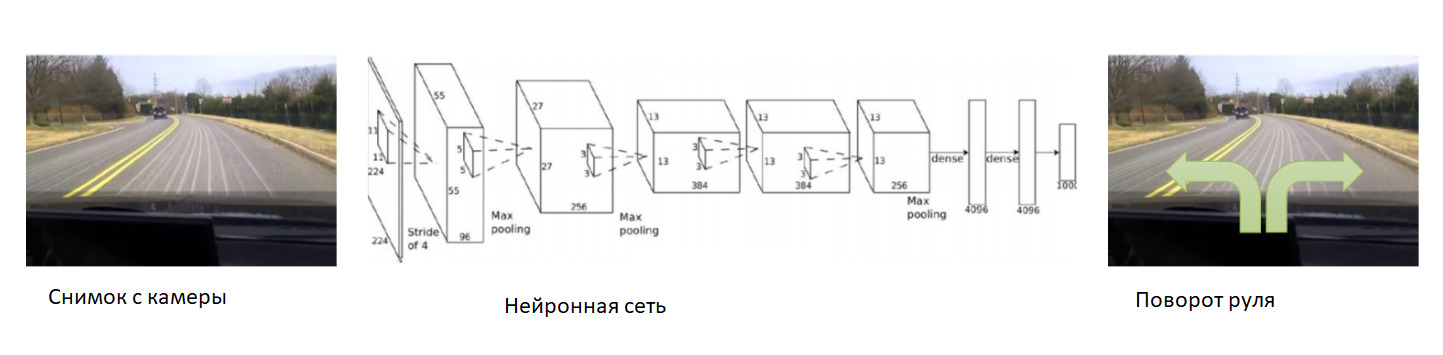
Mit einem ausreichend großen und vielfältigen Datensatz, der verschiedene Landschaften, Jahreszeiten und Wetterbedingungen umfasst, lernt das neuronale Netzwerk, wie das Auto genau gesteuert werden kann.
Es gab jedoch ein Problem mit den Daten. Sie sind sehr lang und teuer zu sammeln. Verwenden wir einen Simulator, in dem die gesamte Physik der Fahrzeugbewegung implementiert wird - zum Beispiel DeepDrive. Wir können es lernen, ohne Angst zu haben, ein Auto zu verlieren.

In diesem Simulator haben wir Zugriff auf alle Indikatoren des Autos und der Welt. Außerdem sind alle Personen, Autos, ihre Geschwindigkeiten und Entfernungen zu ihnen markiert.

Aus Sicht des Ingenieurs können Sie in einem solchen Simulator sicher neue Trainingstechniken ausprobieren. Was soll ein Forscher tun? Zum Beispiel das Studieren verschiedener Optionen für den Gradientenabstieg bei Lernproblemen mit Verstärkung. Um eine einfache Hypothese zu testen, möchte ich keine Spatzen aus einer Kanone schießen und einen Agenten in einer komplexen virtuellen Welt ausführen und dann tagelang auf Simulationsergebnisse warten. In diesem Fall nutzen wir unsere Rechenleistung effizienter. Lassen Sie die Agenten einfacher sein. Nehmen Sie zum Beispiel ein vierbeiniges Spinnenmodell. Im Mujoco-Simulator sieht es so aus:

Wir haben ihm die Aufgabe gestellt, mit der höchstmöglichen Geschwindigkeit in eine bestimmte Richtung zu laufen - zum Beispiel nach rechts. Die Anzahl der beobachteten Parameter für eine Spinne ist ein 39-dimensionaler Vektor, der die Position und Geschwindigkeit aller ihrer Gliedmaßen aufzeichnet. Im Gegensatz zum neuronalen Netzwerk für Tischtennis, bei dem nur ein Neuron am Ausgang vorhanden war, befinden sich acht am Ausgang (da die Spinne in diesem Modell 8 Gelenke hat).
In solch einfachen Modellen können verschiedene Hypothesen über die Unterrichtstechnik getestet werden. Vergleichen wir zum Beispiel die Lerngeschwindigkeit in Abhängigkeit von der Art des neuronalen Netzwerks. Sei es ein einschichtiges neuronales Netzwerk, ein dreischichtiges neuronales Netzwerk, ein Faltungsnetzwerk und ein wiederkehrendes Netzwerk:
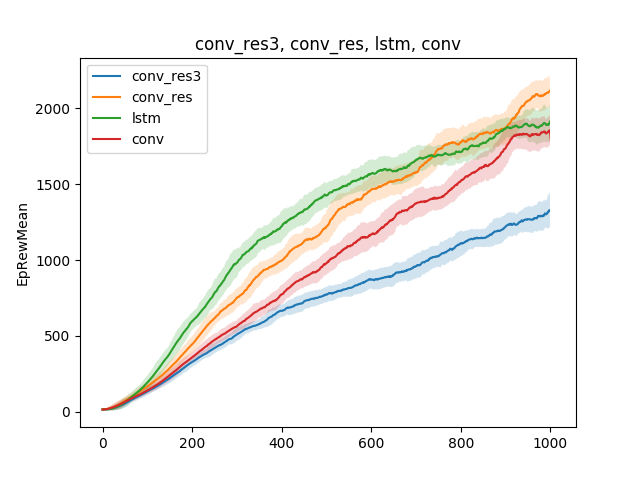
Die Schlussfolgerung kann wie folgt gezogen werden: Da das Spinnenmodell und die Aufgabe recht einfach sind, sind die Trainingsergebnisse für verschiedene Modelle ungefähr gleich. Ein dreischichtiges Netzwerk ist zu komplex und lernt daher schlechter.
Trotz der Tatsache, dass der Simulator mit einem einfachen Spinnenmodell arbeitet, kann das Training je nach der Aufgabe, die der Spinne gestellt wird, Tage dauern. In diesem Fall animieren wir mehrere hundert Spinnen gleichzeitig auf einer Oberfläche anstatt auf einer und lernen aus den Daten, die wir von allen erhalten. Wir werden das Training also um das Hundertfache beschleunigen. Hier ist ein Beispiel für die Flex-Engine.
Das einzige, was sich in Bezug auf die Optimierung neuronaler Netze geändert hat, ist die Datenerfassung. Wenn wir nur eine Spinne liefen, erhielten wir nacheinander Daten. Ein Lauf nach dem anderen.

Jetzt kann es vorkommen, dass einige Spinnen gerade das Rennen starten, während andere schon lange laufen.
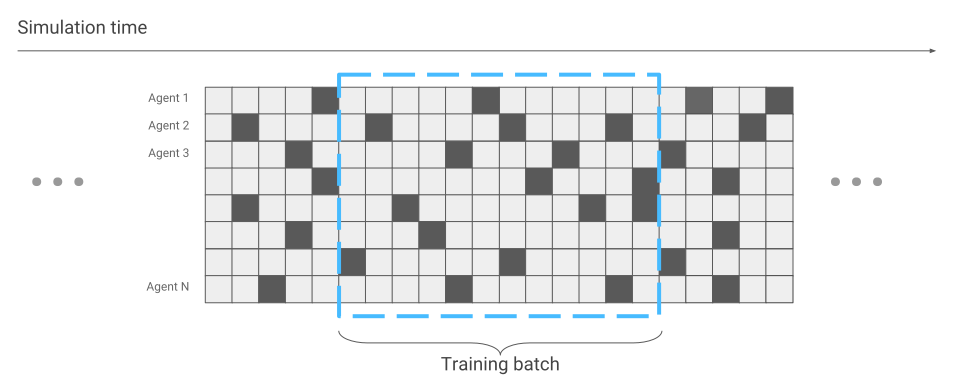
Wir werden dies bei der Optimierung des neuronalen Netzwerks berücksichtigen. Ansonsten bleibt alles beim Alten. Infolgedessen wird das Training hunderte Male beschleunigt, je nach Anzahl der Spinnen, die gleichzeitig auf dem Bildschirm angezeigt werden.
Da wir einen effektiven Simulator haben, versuchen wir, komplexere Probleme zu lösen. Zum Beispiel über unwegsames Gelände laufen.

Da die Umgebung in diesem Fall aggressiver geworden ist, sollten wir die Aufgaben während des Trainings ändern und komplizieren. Es ist schwer zu lernen, aber im Kampf einfach. Zum Beispiel alle paar Minuten, um das Gelände zu wechseln. Lassen Sie uns außerdem externe Agenten an den Agenten weiterleiten. Lassen Sie uns zum Beispiel Bälle auf ihn werfen und den Wind ein- und ausschalten. Dann lernt der Agent, auch auf Oberflächen zu laufen, die er noch nie getroffen hat. Zum Beispiel Treppen steigen.

Da wir so effektiv gelernt haben, in Simulationen zu laufen, sollten wir die Techniken des Verstärkungstrainings in Wettbewerbsdisziplinen überprüfen. Zum Beispiel bei Schießspielen. Die VizDoom-Plattform bietet eine Welt, in der Sie schießen, Waffen sammeln und die Gesundheit wieder auffüllen können. In diesem Spiel werden wir auch ein neuronales Netzwerk verwenden. Erst jetzt hat sie fünf Ausgänge: vier für Bewegung und einen für Schießen.
Damit das Training effektiv ist, nehmen wir es schrittweise. Von einfach bis komplex. Am Eingang erhält das neuronale Netzwerk ein Bild, und bevor es anfängt, etwas Bewusstes zu tun, muss es lernen, zu verstehen, woraus die Welt besteht. Wenn sie in einfachen Szenarien studiert, lernt sie zu verstehen, welche Objekte auf der Welt leben und wie sie mit ihnen interagieren. Beginnen wir mit dem Bindestrich:
Nachdem der Agent dieses Szenario gemeistert hat, wird er verstehen, dass es Feinde gibt, und sie sollten erschossen werden, da Sie Punkte für sie erhalten. Dann werden wir ihn in einem Szenario trainieren, in dem die Gesundheit ständig abnimmt und Sie sie wieder auffüllen müssen.

Hier erfährt er, dass er gesund ist und wieder aufgefüllt werden muss, da der Agent im Todesfall eine negative Belohnung erhält. Außerdem wird er lernen, dass Sie es sammeln können, wenn Sie sich dem Thema nähern. Im ersten Szenario konnte sich der Agent nicht bewegen.
Und im letzten, dritten Szenario lassen wir ihn mit den Bots schießen, die nach den Spielregeln programmiert sind, damit er seine Fähigkeiten verbessern kann.

Während des Trainings in diesem Szenario ist die richtige Auswahl der Belohnungen, die der Agent erhält, sehr wichtig. Wenn Sie beispielsweise nur für besiegte Rivalen eine Belohnung geben, ist das Signal sehr selten: Wenn nur wenige Spieler anwesend sind, erhalten wir alle paar Minuten Punkte. Verwenden wir daher die Kombination der vorherigen Belohnungen. Der Agent erhält eine Belohnung für jede nützliche Aktion, unabhängig davon, ob er die Gesundheit verbessert, Patronen auswählt oder einen Gegner trifft.
Infolgedessen ist ein Agent, der mit ausgewählten Belohnungen trainiert wurde, stärker als seine rechenintensiveren Gegner. 2016 gewann ein solches System den VizDoom-Wettbewerb mit einem Vorsprung von mehr als der Hälfte der vom zweiten Platz erzielten Punkte. Das Zweitplatzierte Team verwendete auch ein neuronales Netzwerk, nur mit einer großen Anzahl von Ebenen und zusätzlichen Informationen von der Spiel-Engine während des Trainings. Zum Beispiel Informationen darüber, ob sich Feinde im Sichtfeld des Agenten befinden.
Wir haben Lösungsansätze untersucht, bei denen es wichtig ist, Entscheidungen zu treffen. Viele Aufgaben mit diesem Ansatz bleiben jedoch ungelöst. Zum Beispiel das Questspiel Montezuma Revenge.
Hier müssen Sie nach Schlüsseln suchen, um die Türen zu benachbarten Räumen zu öffnen. Wir bekommen selten Schlüssel und öffnen noch seltener Räume. Es ist auch wichtig, sich nicht von Fremdkörpern ablenken zu lassen. Wenn Sie das System wie in den vorherigen Aufgaben trainieren und Belohnungen für geschlagene Feinde vergeben, wird der rollende Schädel einfach immer wieder ausgeschaltet und die Karte nicht untersucht. Wenn Sie interessiert sind, kann ich in einem separaten Artikel über die Lösung solcher Probleme sprechen.
Sie können die Rede von Vladimir Ivanov auf der AI-Konferenz am 22. November hören . Ein detailliertes Programm und Tickets finden Sie auf der
offiziellen Website der Veranstaltung.
Lesen Sie hier das Interview mit Vladimir.