Eine weitere Abschrift des Berichts mit
Pixonic DevGAMM Talks . Anton Kosyakin ist technischer Produktmanager und arbeitet an der ALICE-Plattform (wie einem Jira für Hotels). Er erklärte, wie sie die vorhandenen Testtools in das Projekt integriert haben, warum Lasttests erforderlich sind, welche Tools die Community anbietet und wie diese Tools in der Cloud ausgeführt werden. Unten finden Sie eine Präsentation und den Text des Berichts.
Wir stellen ein Produkt namens ALICE Platform her und ich werde Ihnen jetzt erklären, wie sie das Problem der Lasttests gelöst haben.

ALICE ist Jira für Hotels. Wir schaffen eine Plattform, die ihnen hilft, mit ihrem Inneren umzugehen. Concierge, Rezeptionist, Reinigungskräfte - sie brauchen auch Tickets. Zum Beispiel: Ein Gast ruft an> sagt, dass Sie den Raum reinigen müssen> der Mitarbeiter erstellt ein Ticket> die Leute, die putzen, wissen, auf wen die Aufgabe gestellt wird> ausführen> den Status ändern.
Wir haben B2B, daher sind die Zahlen möglicherweise nicht beeindruckend - nur 1.000 Hotels, 5.000 DAUs. Für Spiele ist das nicht viel, aber für uns ist es sehr cool, weil es bis zu 8 Prod-Server gibt und sie mit diesen 5.000 aktiven Benutzern kaum fertig werden können. Da passieren etwas andere Dinge unter der Haube - eine Reihe von Datenbanken, Transaktionen usw.

Das Wichtigste: Im vergangenen Jahr sind wir zweimal gewachsen, jetzt haben wir ein Engineering-Team in der Region von 50 Mitarbeitern und planen, die Anwenderbasis 2019 zu verdoppeln. Und das ist die größte Herausforderung, vor der wir stehen.
Ein Beispiel aus dem Leben. Am Freitagabend, nachdem ich eine 60-Stunden-Woche gearbeitet hatte, beendete ich um 23:00 Uhr den letzten Anruf, beendete die Präsentation schnell, stieg in den Zug und kam hierher. Und vor ungefähr fünf Minuten habe ich meine Präsentation ein wenig überarbeitet. Jetzt funktioniert alles für uns, weil wir ein Startup sind und es cool ist. Während ich fuhr, versuchte ein Teil des technischen Teams (wir nennen es Feuer in der Produktion) sicherzustellen, dass das System nicht ausfiel, und gleichzeitig bemerkten die Benutzer dies nicht. Sie haben es geschafft und wir sind gerettet.
Wie Sie sehen, schlafen wir nachts bisher nicht sehr gut. Wir wissen mit Sicherheit, dass unsere Infrastruktur sinken wird. Wir stellen uns der Wahrheit und verstehen dies. Eine Frage: wann? So haben wir verstanden, dass Lasttests der Schlüssel zur Erlösung sind. Darum müssen wir uns kümmern.

Was sind unsere Ziele? Zunächst müssen wir jetzt genau verstehen, wie gut und leistungsfähig unser System ist und wie gut es für aktuelle Benutzer funktioniert. Und dies sollte geschehen, bevor der Benutzer den Vertrag mit uns bricht (und dies kann ein Kunde für 150 Hotels und viel Geld sein), da etwas nicht funktioniert oder sehr langsam ist. Darüber hinaus hat die Vertriebsabteilung einen Plan: doppeltes Wachstum im nächsten Jahr. Und so kam es, dass wir unseren Hauptkonkurrenten gekauft und seine Benutzer zu uns selbst migriert haben.
Und wir müssen wissen, dass all dies standhalten kann. Wissen Sie im Voraus, bevor diese Benutzer kommen und alles fallen wird.
Wir machen auch Veröffentlichungen. Jede Woche. Am Montag. Natürlich erweitern nicht alle Releases die Funktionalität, irgendwo Wartung, irgendwo Fehlerbehebungen, aber wir müssen verstehen, dass Benutzer dies nicht bemerken und ihre Erfahrung nicht schlechter wird.
Aber wir als gute Entwickler sind faule Leute und arbeiten nicht gerne. Daher fragten sie die Community und Google, welche Dienste / Lösungen es für Lasttests gibt. Es gab viele von ihnen. Es gibt einige einfache Dinge, wie Apache Bench, die einfach eine Site in hundert Threads in URL kicken. Es gibt eine böse und seltsame Version von Bees with Machine Guns, bei der alles gleich ist, aber die Instanzen gestartet werden, die fliegen und Ihre Anwendungen platzieren. Es gibt JMeter, dort können Sie einige Skripte schreiben, die in der Cloud ausgeführt werden.

Alles scheint in Ordnung zu sein, aber nachdem wir nachgedacht hatten, wurde uns klar, dass wir wirklich arbeiten und zuerst einige Probleme lösen müssen.

Zunächst müssen Sie reale Szenarien schreiben, die eine vollständige Auslastung simulieren. Auf einigen Systemen ist es ausreichend, zufällige API-Aufrufe mit zufälligen Daten zu generieren. In unserem Fall handelt es sich um lange Benutzerszenarien: Ich habe einen Anruf erhalten, einen Bildschirm geöffnet, alle Daten (wer hat angerufen, was er will) abgerufen und gespeichert. Dann erscheint es in der mobilen Anwendung einer anderen Person, die die Anfrage ausführen wird. Nicht die trivialste Aufgabe.
Und ich möchte Sie daran erinnern, veröffentlicht jede Woche. Die Funktionalität wird aktualisiert, die Skripte müssen wirklich relevant sein. Zuerst müssen Sie sie schreiben und dann auch unterstützen.
Das war aber nicht das größte Problem. Nehmen Sie zum Beispiel Flut.io. Als cooles Tool können Sie Selenium darin ausführen. Wenn Chrome gestartet wird, können Sie es steuern und es wird eine Art Skript ausgeführt. Sie können darin JMeter-Skripte ausführen. Aber wenn wir Selenium in JMeter-Skripten ausführen wollen, fällt plötzlich alles auseinander, weil die Leute, die es zusammengestellt haben, eine Reihe von architektonischen Entscheidungen getroffen haben. Einige Dienste können beispielsweise JUnit ausführen - es ist einfach und unkompliziert, aber einer dieser Dienste hat seine eigene JUnit geschrieben und einige Dinge einfach ignoriert.

Das Problem der Lastgenerierung ist dringend, da jedes Tool auf seine eigene Weise nach der Generierung fragt. Und selbst wenn Sie es geschafft haben, sicherzustellen, dass die Szenarien angemessen sind, stellt sich die Frage: Wie läuft man 2-4 mal mehr? Es scheint zu sein: rennen und alles ist in Ordnung. Aber nein. Diese Anforderungen enthalten alle Arten von IDs - wir erstellen etwas, erhalten eine neue ID, ändern die alte ID und der Test, der die Entität nach ID lädt, ändert ihr Feld in ein anderes. Und 10 Tests, bei denen dieselbe Entität zehnmal geladen wird, sind nicht sehr interessant. Weil es 10 Mal notwendig ist, verschiedene Entitäten zu laden und diese Last korrekt zu skalieren.
OK, wir möchten das Problem der Lasttests lösen, um genau zu verstehen, wie vielen Benutzern die Anwendung standhalten wird und ob unsere Pläne mit den Plänen der Verkaufsabteilung übereinstimmen. Wir haben die auf dem Markt befindlichen Lösungen analysiert und anschließend eine Bestandsaufnahme unserer Nudeln und Sticks durchgeführt.
Da wir jede Woche Releases veröffentlichen, haben wir natürlich einige Tests automatisiert - Integration und etwas anderes. Dafür verwenden wir Gurke. Dies ist ein BDD-Framework für die verhaltensgesteuerte Entwicklung. Das heißt, Wir fragen einige Skripte, die aus Schritten bestehen.

Dank unserer Infrastruktur konnten wir Integrations- und Funktionstests in zwei Modi ausführen: einfach das Backend starten, die API zucken oder Chrome über Selenium ausführen und verwalten.
Wir lieben NewRelic. Es kann einfach den Server überwachen, die Hauptindikatoren. Es wird in die JVM integriert und fängt alle Aufrufe an die Controller und die Endpoint-API ab. Sie haben auch eine Lösung für den Browser, und da wir die meisten Funktionen dort haben, macht es auch etwas im Browser und gibt eine Art von Metriken.

Dementsprechend müssen Sie alles zusammenfügen. Wir haben die Hauptszenarien bereits automatisiert. Unsere Szenarien (weil es wie BDD ist) ahmen echte Benutzer nach und die Last ähnelt der realen Produktion. Gleichzeitig können wir es skalieren. Da dies Teil des Freigabeprozesses ist, wird es immer auf dem neuesten Stand gehalten.

Nehmen wir nun jedes Werkzeug, das derzeit auf dem Markt ist. Sie arbeiten mit denselben Grundelementen: http, API-Aufrufe auf http, JSON, JUnit, das ist alles. Aber sobald wir versuchen, unsere Tests auf Gurke zu beschränken, machen sie dasselbe, arbeiten mit denselben Dingen, aber nichts funktioniert. Wir begannen zu überlegen, wie wir mit dieser Aufgabe umgehen sollten.
Ein kleiner Exkurs, da BDD in der Spieleentwicklung kein sehr beliebter Begriff ist, eher für Unternehmenslösungen.

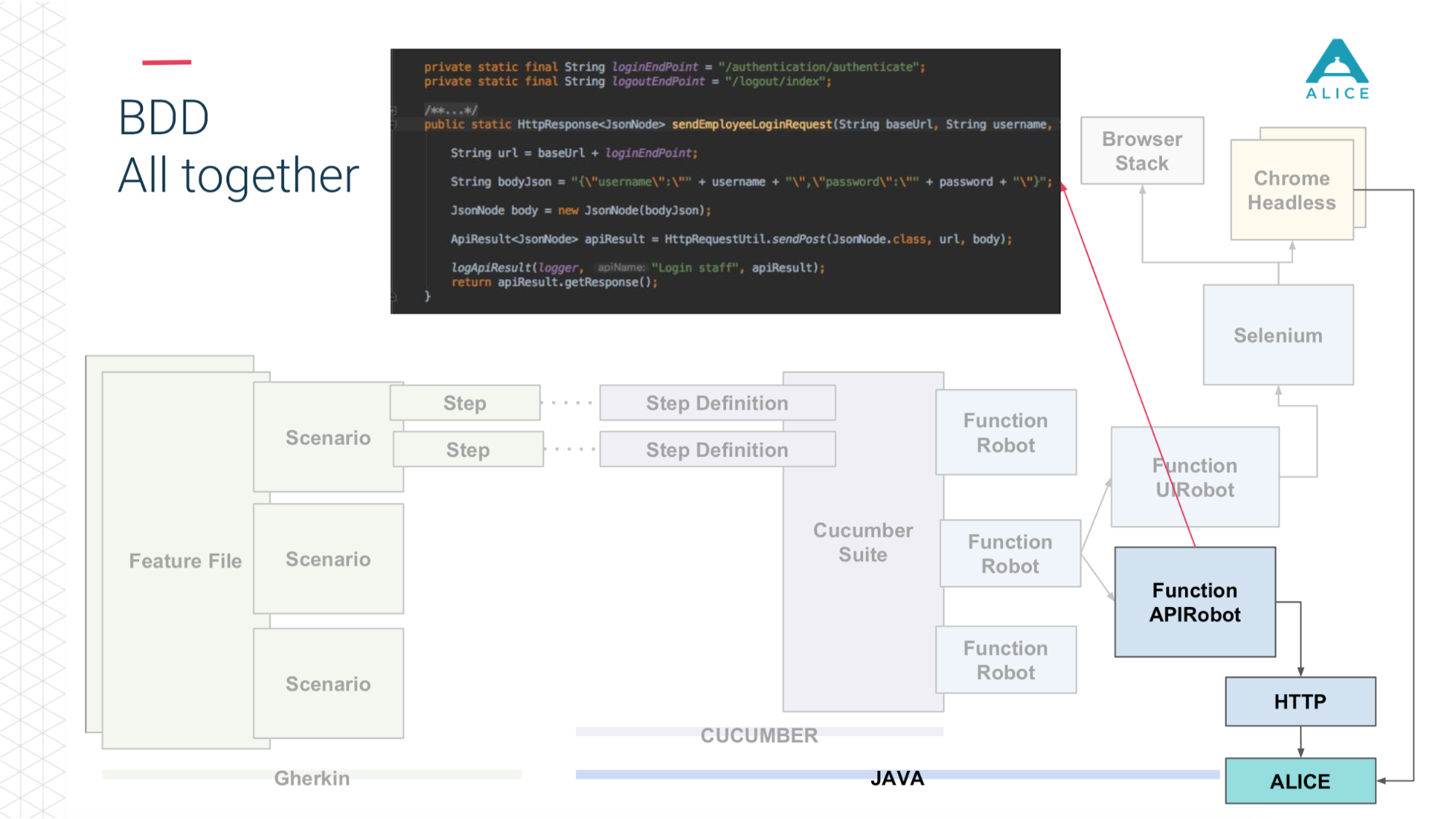
Alle Szenarien beschreiben wirklich ein Verhalten. Das Format der Szenariobeschreibung ist sehr einfach: Gegeben, wann, dann - in Bezug auf BDD namens Gurke. Cucumber ordnet dies mithilfe von Anmerkungen und Attributen Java-Code zu. Er tut, was er im Szenario sieht: Sie müssen der Person einen Apfel geben, lassen Sie uns eine Methode finden, in der dies implementiert wird.
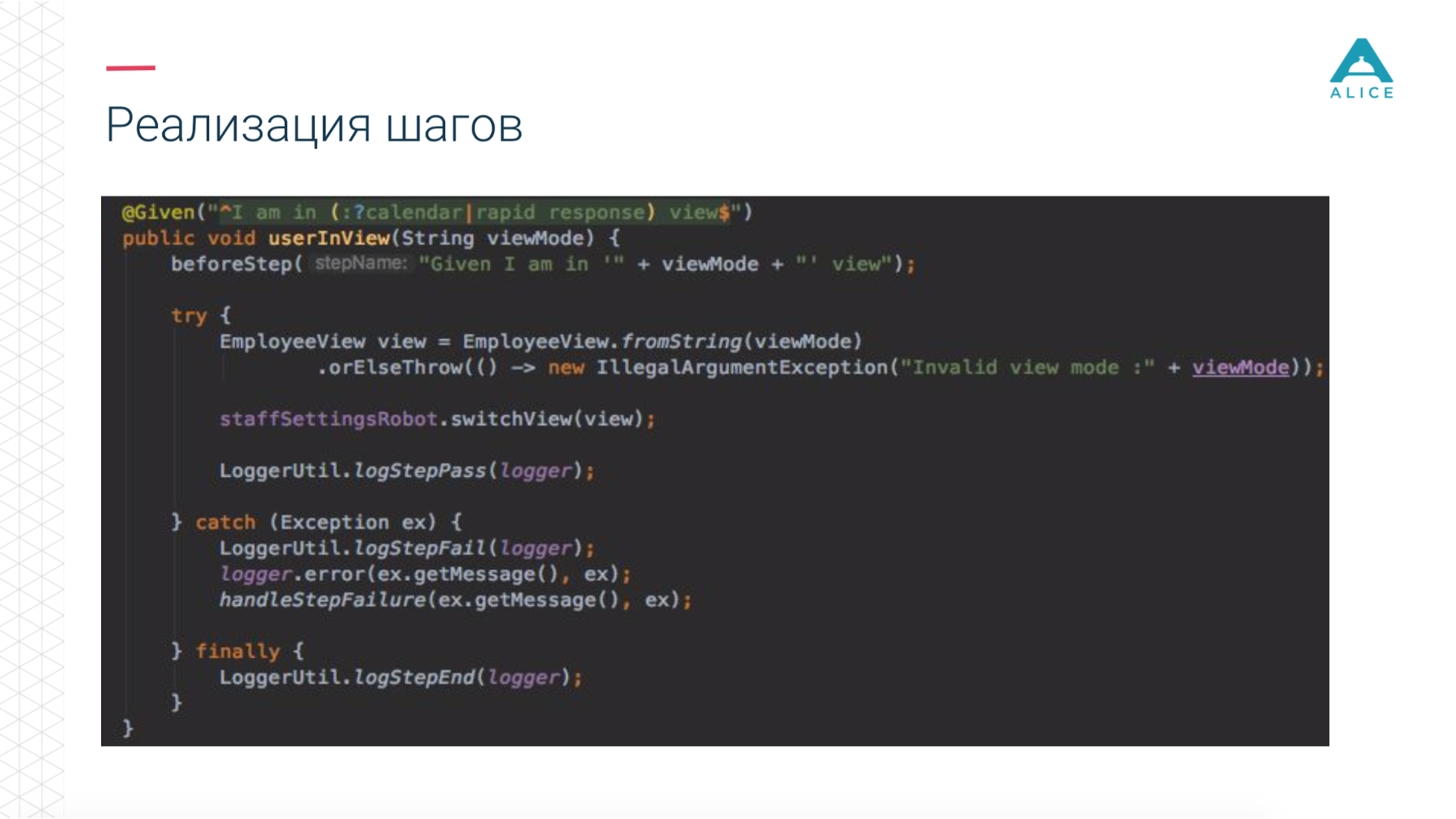
Dann haben wir ein Konzept wie Functional Robot eingeführt. Dies ist ein bestimmter Client für die Anwendung. Er verfügt über Methoden zum Anmelden eines Benutzers, Abmelden, Erstellen eines Tickets, Anzeigen einer Liste von Tickets usw. Und es kann in drei Modi funktionieren: mit einer mobilen Anwendung, einer Webanwendung und nur API-Aufrufen.
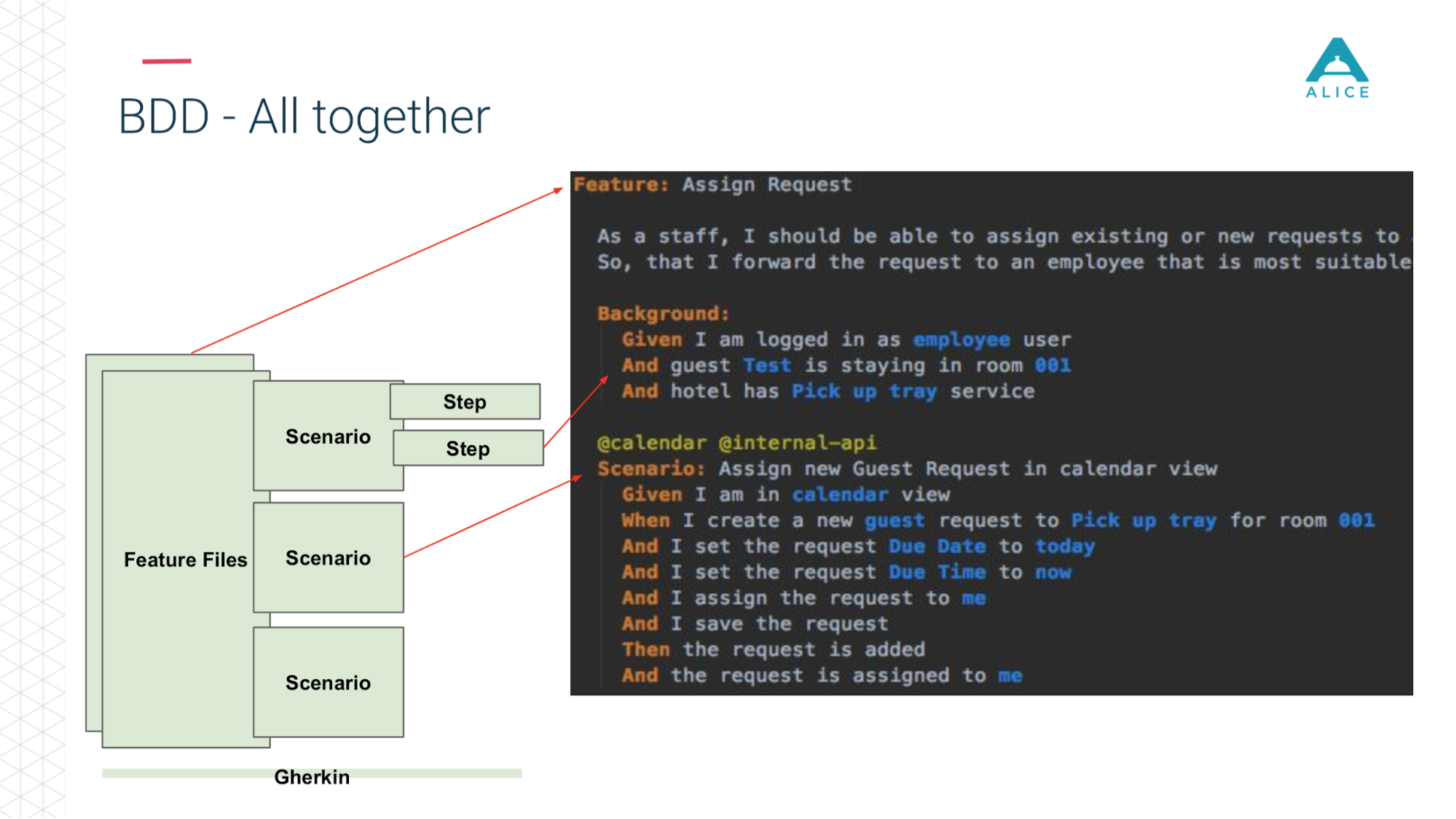
Kurz gesagt das Gleiche auf den Folien. Feature-Dateien sind in Skripte unterteilt, es gibt Schritte und all dies ist in Englisch geschrieben.
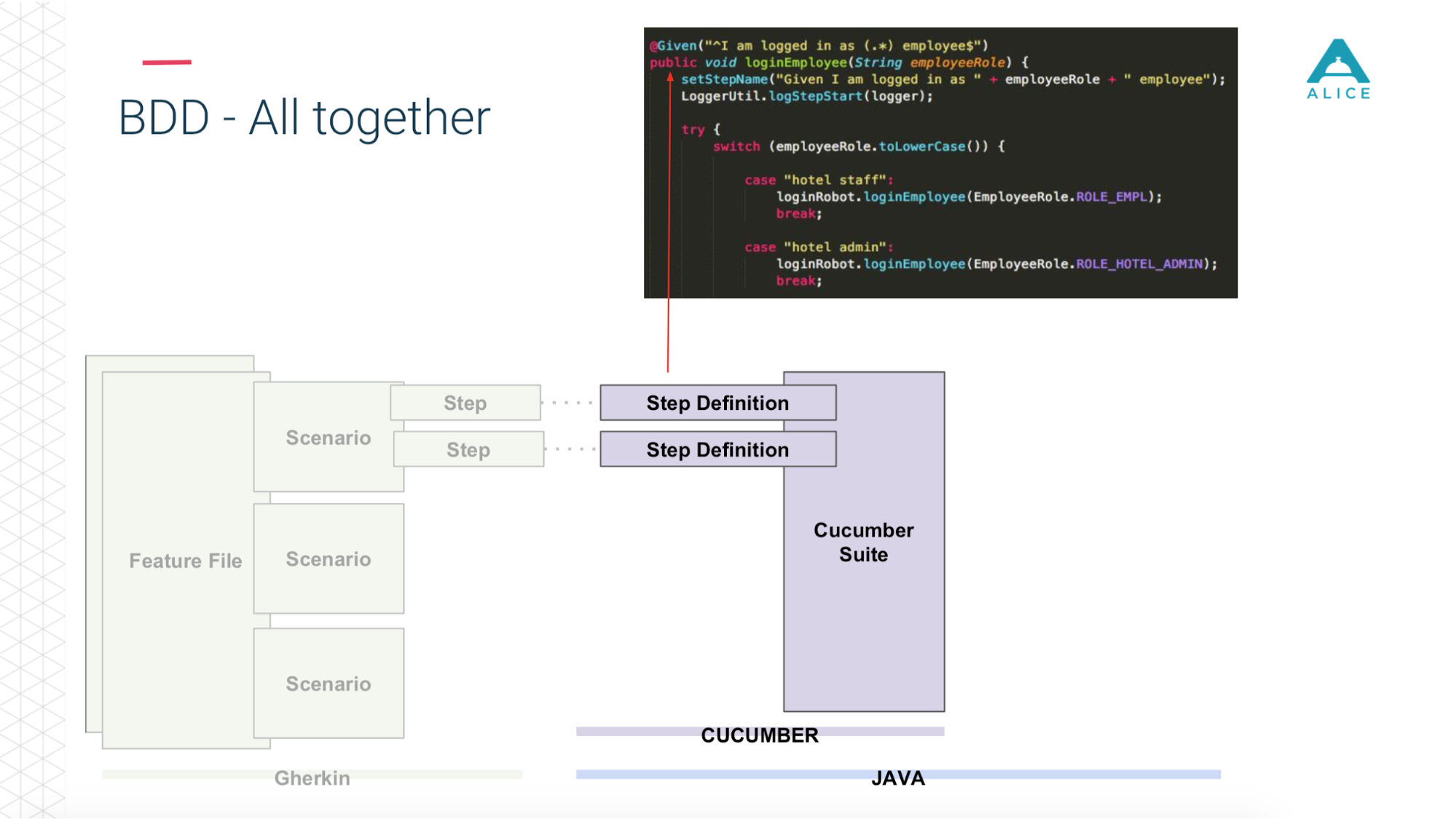
Dann kommt Cucumber, der Java-Code, ins Spiel. Er ordnet diese Skripte dem Code zu, der tatsächlich ausgeführt wird.
Dieser Code verwendet unsere Anwendung.

Und je nachdem, was wir gewählt haben: Entweder über Selenium geht Chrome zur ALICE-Anwendung.

Oder dasselbe über die http-API.
Und dann (dank der Jungs von Yandex für Allure Reports) wird uns all dies wunderschön gezeigt - wie viel Zeit es gedauert hat, welche Tests umgedreht wurden, in welchem Schritt und sogar einen Screenshot anwenden, wenn etwas schief gelaufen ist.
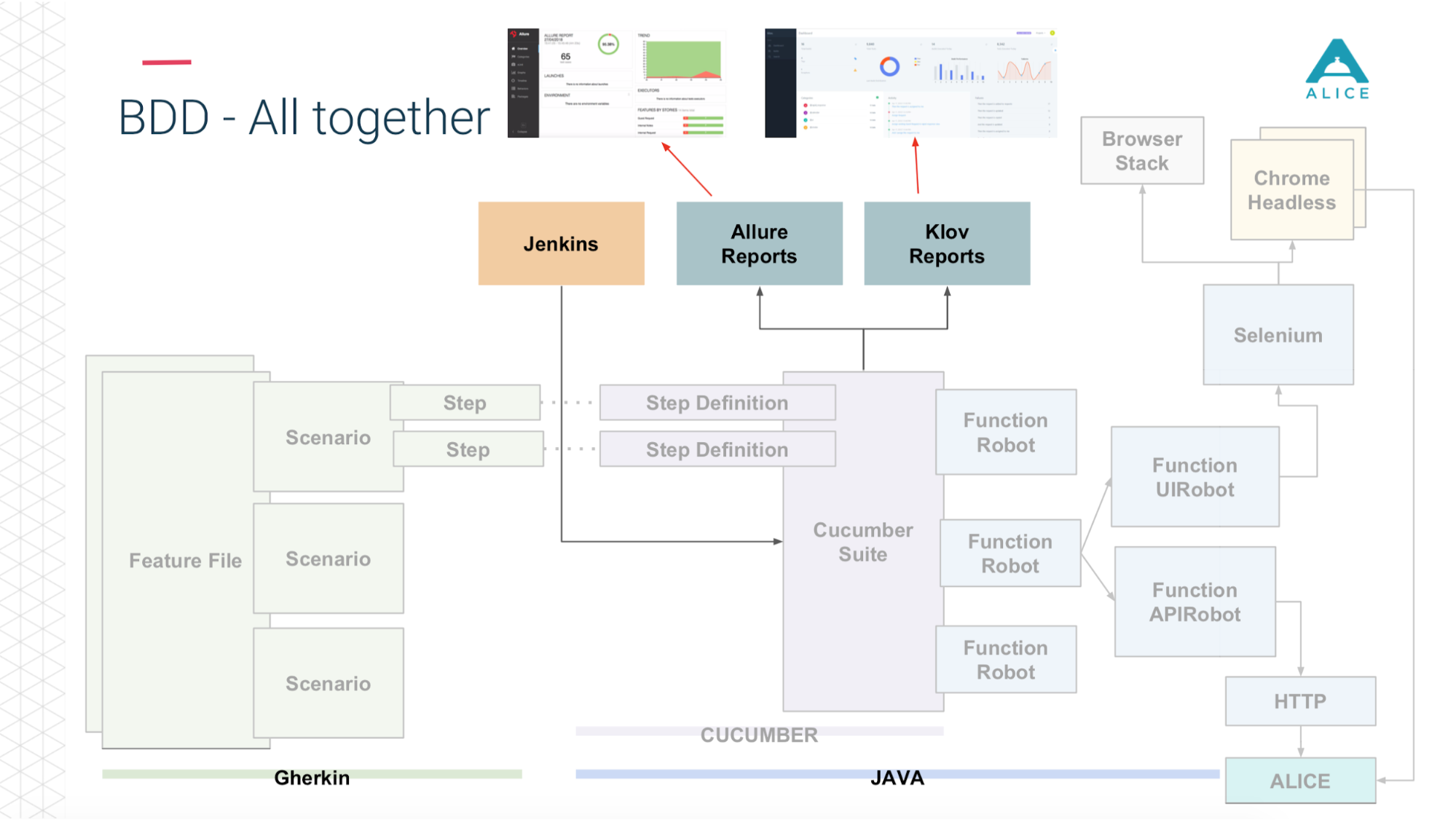
Hier ist eine kurze Zusammenfassung dessen, was wir bereits hatten.
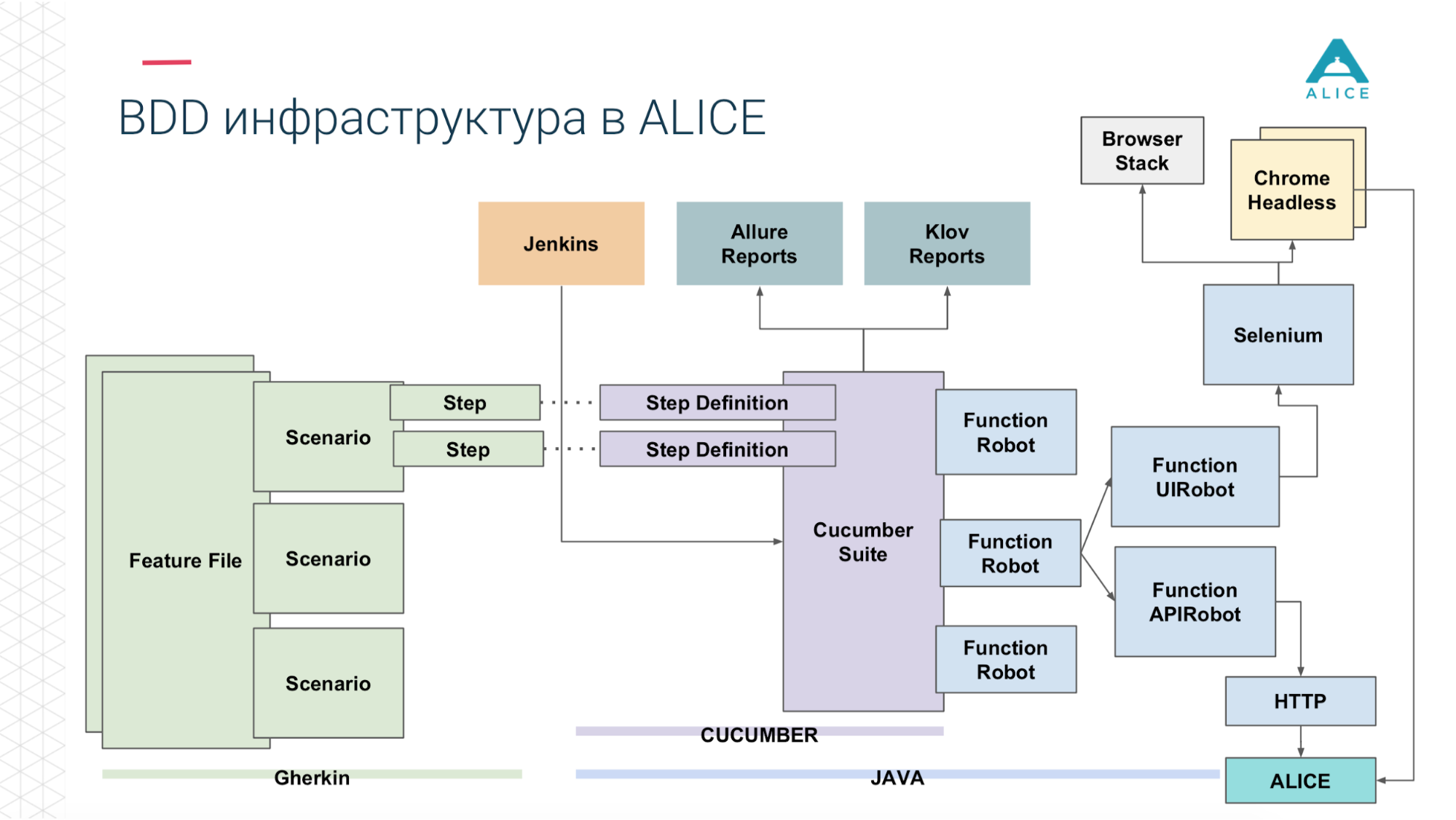
Wie kann man daraus Lasttests erstellen? Wir hatten Jenkins, der die Gurkensuite leitete. Dies sind unsere Tests und sie gingen zu ALICE. Was war das Hauptproblem? Jenkins führt Tests lokal durch, sie können nicht für immer skaliert werden. Ja, wir werden in Amazon gehostet, in der Cloud können wir nach einem extra großen Computer fragen. Wie auch immer, irgendwann werden wir zumindest ins Netzwerk gelangen. Es ist notwendig, diese Last irgendwie zu laden. Danke Amazon, dachte er für uns. Wir können unsere Cucumber Suite in einen Docker-Container packen und den AWS-Service (Fargate) verwenden, um zu sagen: "Und starten Sie sie bitte." Das Problem ist behoben, wir können unsere Tests bereits in der Cloud ausführen.

Führen Sie dann, da wir uns in der Cloud befinden, die Cucumber Suite 5-10-20 aus. Aber es gibt eine Nuance: Jeder Durchlauf aller unserer Funktionstests generiert einen Bericht. Einmal haben wir 400 Tests durchgeführt und 400 Berichte erstellt.
Nochmals vielen Dank an die Jungs von Yandex für Open Source. Wir haben die Dokumentation und den Quellcode gelesen und festgestellt, dass es Möglichkeiten gibt, alle 400 Berichte zu einem zusammenzufassen. Wir haben die Daten leicht korrigiert, einige unserer Erweiterungen geschrieben und alles hat geklappt.
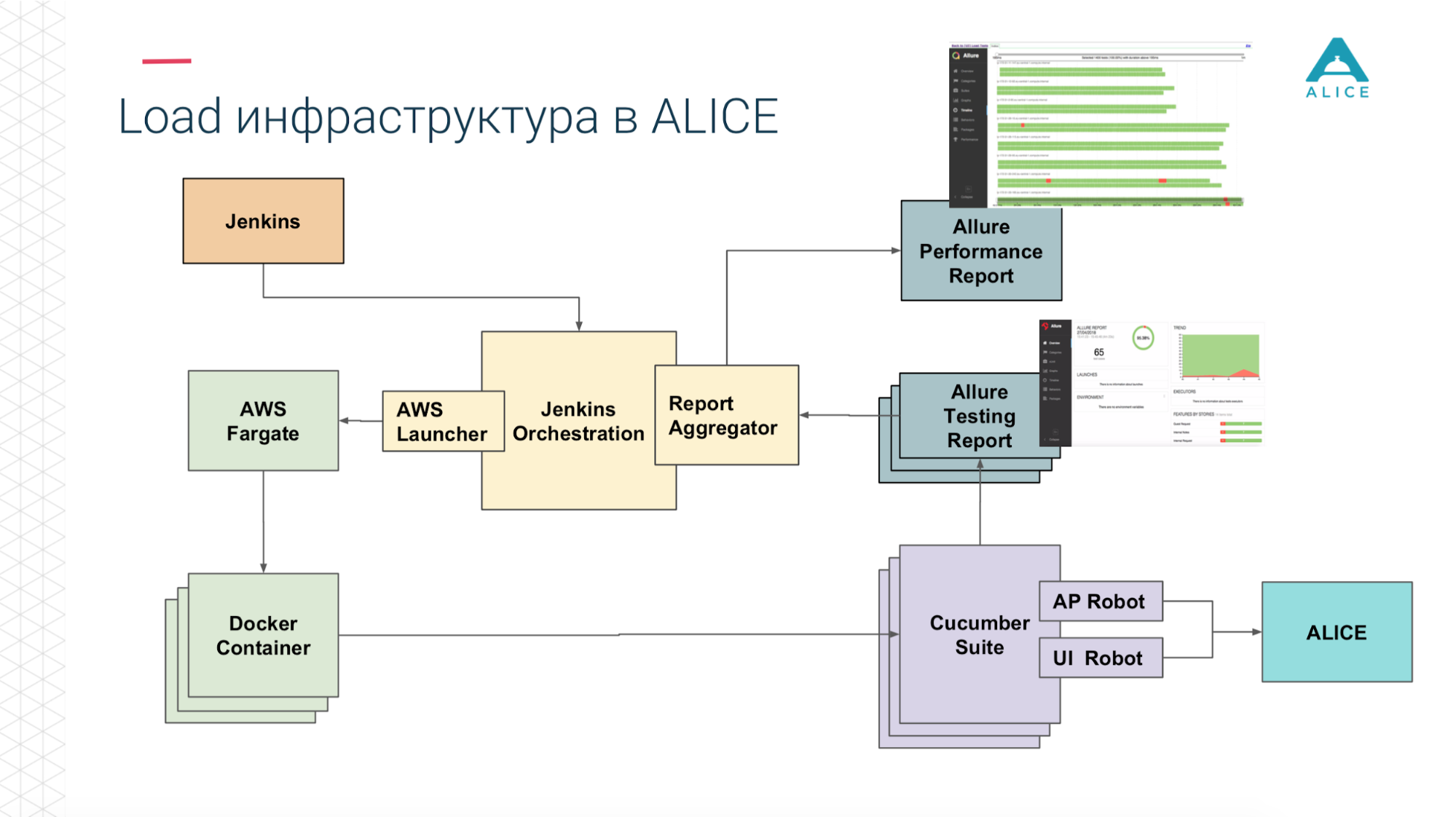
Jetzt von Jenkins sagen wir: "Gib uns 200 Instanzen." Unser bestimmtes Orchestrierungsskript geht an Amazon und sagt "400 Container starten". Jeder von ihnen enthält unsere Integrationstests, sie generieren einen Bericht, der Bericht wird über Aggregator in einem Stück gesammelt, in Jenkins abgelegt, auf den Job angewendet, es funktioniert super.
Aber.
Ich bin mir sicher, dass viele von Ihnen seltsame Dinge von Testern erhalten haben, wie "Ich habe ein Spiel gespielt, bin 10 Mal gesprungen, während dieser Zeit habe ich das Schießen gedrückt und versehentlich die Abschalttaste gedrückt - der Charakter begann zu blinken, in der Luft zu frieren und dann schaltete sich der Computer aus." damit umgehen. " Sie können immer noch einer Person zustimmen und sagen, es ist unmöglich zu reproduzieren. Aber wir haben seelenlose Maschinen, sie erledigen alles sehr schnell und irgendwo, wo die Daten nicht geladen wurden, irgendwo, wo sie nicht sehr schnell gerendert werden, versuchen sie, einen Knopf zu drücken, aber es gibt noch keinen Knopf oder es werden einige Daten verwendet, die noch nicht vom Server heruntergeladen wurden . Alles bricht zusammen und der Test ist fehlerhaft. Obwohl (ich möchte mich darauf konzentrieren) wir Java-Code haben, der Chrome ausführt, der über einen Wrapper eine Verbindung zu einem anderen Java herstellt und etwas tut und trotzdem blitzschnell arbeitet.
Nun, das offensichtliche Problem, das sich daraus ergibt: Wir haben 5.000 Benutzer, und wir haben nur 100 Instanzen unserer Funktionstests gestartet und dieselbe Last erstellt. Dies ist nicht genau das, was wir wollten, da wir planen, dass wir nächsten Monat 6.000 Benutzer haben werden. Es ist schwer zu verstehen, wie viele Threads gestartet werden müssen.
OK, lassen Sie uns unser System humanisieren. So sieht die Benutzeroberfläche aus:

Jemand ruft an, der Concierge möchte auf die Schaltfläche "Neues Ticket erstellen" klicken, ein Fenster erscheint für ihn und er muss alle Felder ausfüllen.
Dies geschieht jedoch nicht sofort. Die reale Person, bis sie die Maus erreicht, bis sie mit dem Tippen beginnt, bis sie etwas auswählt, während sie auf Speichern klickt. Lassen Sie uns also unsere Tests verlangsamen.

Wir haben es Human Mode genannt. Sie müssen nur messen, wie lange der Schritt dauert, und ein wenig "schlafen", wenn er zu schnell war. Gleichzeitig können wir messen, wie viel dieser Schritt im Prinzip gedauert hat - wenn 5 Minuten, dann ist hier wahrscheinlich die Benutzererfahrung unterbrochen.
Da wir einige Tests hatten, haben wir nicht begonnen, jeden unter dieser Sache neu zu schreiben. Sie haben AspectJ genommen, es auf unseren Code gezogen, 5 weitere Codezeilen hinzugefügt, es funktioniert großartig.
Kurze Demo.


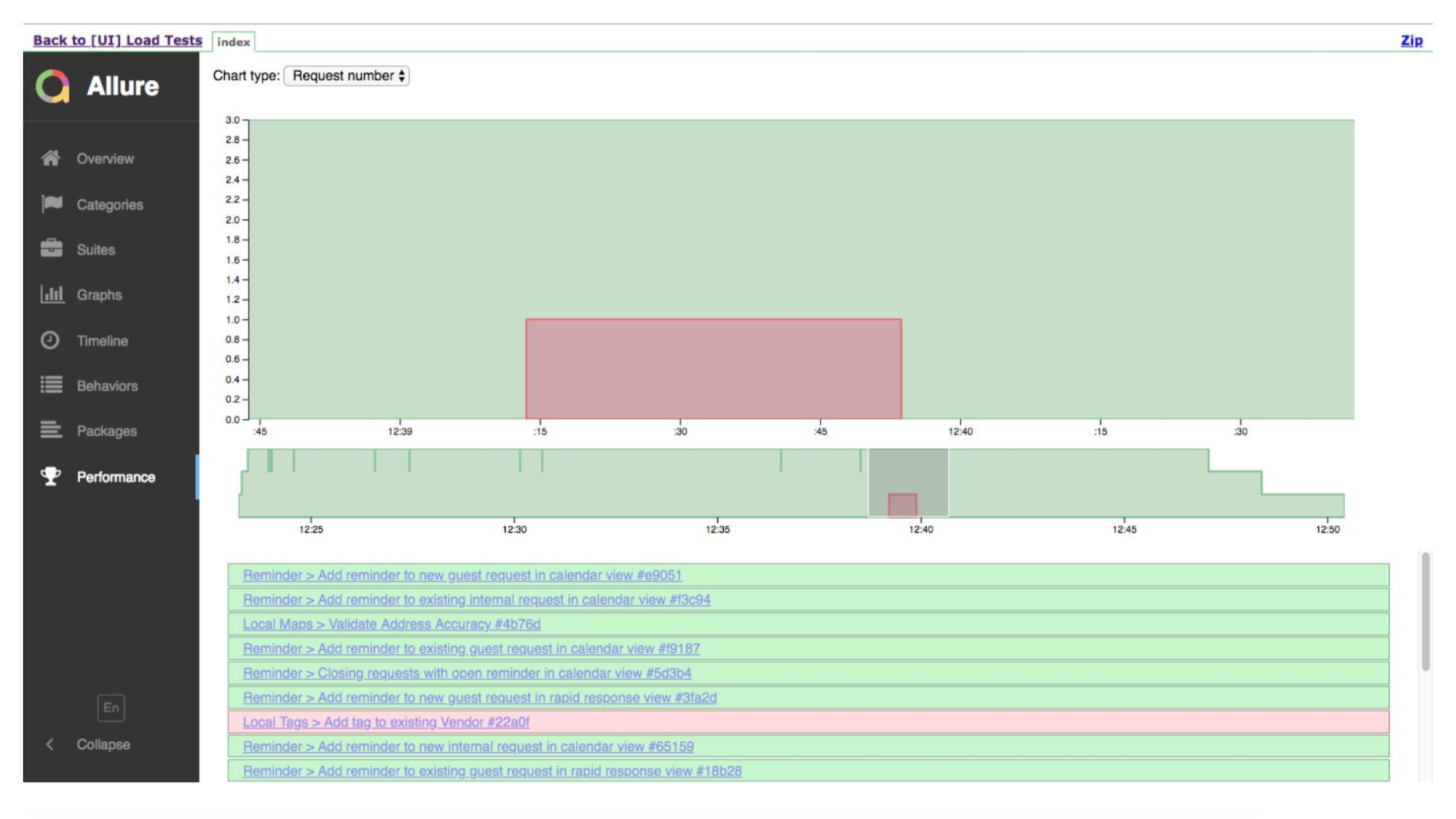
Dies ist ein Timeline-Lauf. Grüne Tests sind gut, irgendwo ist schlecht. Allure zeigt uns die Details, wo es kippt.
Und hier ist die Zeitleiste, die zeigt, dass wir viele Instanzen hatten. Sie führten einen Test durch, irgendwo fiel etwas.
Das System funktioniert wirklich - letzte Woche haben wir die ersten Tests zur Kampfproduktion durchgeführt.
Nun zu den nächsten Schritten, wie wir glauben, kann verbessert werden.

Vor allem möchten wir, dass die Benutzer eine coole Benutzererfahrung haben. Die Idee ist, dass wir eine große Last für unsere Anwendung generieren können und alles einfach zu sein scheint - wir haben die Leistung jeder Anforderung an den Server trivial gemessen, unabhängig davon, ob sie weiterhin schnell reagiert oder Leistungseinbußen einsetzten (der Server begann, eingehende Anforderungen langsamer zu verarbeiten). Aber nein. In der Realität kann der Client / die Anwendung mehrere Anforderungen gleichzeitig an den Server senden. Und warten Sie, bis alle verarbeitet sind. Und wenn eine der Anfragen, die längste, wie sie 5 Sekunden lang funktioniert hat und 5 Sekunden lang weiterarbeitet, ist es uns absolut egal, wie alle anderen funktionieren - so schnell oder auf 4 Sekunden verlangsamt. Immerhin werden wir noch die längsten fünf Sekunden warten. Oder Sie haben ein Ticket erstellt, alles hat in einer Millisekunde funktioniert, aber das Ticket wurde aufgrund interner Index-Caches zu spät im System angezeigt. Der übliche Ansatz wird dieses Problem nicht lösen. Daher möchten wir versuchen, alle Szenarien zu messen und festzustellen, um wie viel sich das Skript zur Ticketerstellung wirklich verschlechtert hat.
Weil Wir haben alle Szenarien, die auf Uskeys basieren. Wir können sie nachahmen, indem wir eine Person an der Rezeption und 10 Reinigungskräfte ausführen. Dann 20 oder 30 Reiniger. Aber die Front der Menschen ist immer noch dieselbe. Das heißt, Wir können durch Verhaltensmuster eine reale Last erzeugen, die einer realistischen Last sehr nahe kommt.
Auch multiregionale Tests. Unser System wird auf der ganzen Welt verwendet (obwohl alles in Amerika gehostet wird) und daher können wir sowohl aus Russland als auch aus Amerika eine Last erzeugen, um zu sehen, welche von ihnen schneller langsamer werden.
Fragen aus dem Publikum
- Sie sind gezwungen, eine große Menge an Logik zu schreiben, und wenn sich etwas ein wenig ändert, brechen Sie in Funktionstests viele Dinge. Es stellt sich heraus, dass Sie fast mehr Zeit benötigen, um die Tests zu unterstützen, als um sie zu entwickeln?"Ja, aber nein." Dies ist BDD, dies sind keine Funktionstests, sie sind näher an Integrationstests. Und was auch immer wir ändern, das Szenario bleibt das gleiche. Ich drücke einen Knopf, sehe ein Fenster, gebe die Nummer des Raumes ein, in dem die Anfrage eingegangen ist, den Namen der Person und das Datum, an dem ein Tisch reserviert werden soll. Wenn sich das Layout ändert, werden die Felder umgekehrt, wenn etwas im Backend passiert, wird der Test gespeichert, da wir uns auf einer sehr hohen Ebene befinden, klicken wir auf die Schaltflächen im Browser. Daher sind wir vor einer Vielzahl von Änderungen geschützt. Es gibt Zeiten, in denen alles kaputt gehen kann. Daher sind diejenigen, die ein neues Feature schreiben, im Release-Verfahren dafür verantwortlich, dass etwas kaputt geht und repariert wird. Bisher gab es solche Probleme jedoch nicht in großer Zahl.
- Und Sie hatten keine Situation, in der nach einem Wechsel alle Tests rot werden.- War es nicht. Theoretisch kann dies passieren, wenn das Skript keine Schaltfläche hat, aber eine andere Möglichkeit, ein Fenster zur Eingabe von Ticketinformationen zu öffnen. Wie ich bereits gezeigt habe, bestehen alle unsere Szenarien aus Schritten. Schritte sind eine Menge von allem, und wenn wir 100 Skripte haben, die auf dieselbe Schaltfläche klicken, ist der Schritt immer noch einer. Und wenn aufgrund dieses speziellen Schritts alles schief gelaufen ist, korrigieren wir es, schreiben es neu und alle Tests werden sofort grün.
Obwohl es uns einmal passiert ist, als wir versehentlich etwas kaputt gemacht haben. Nur 40% des Grüns blieben übrig, zuvor waren es 99%. Das war eine kleine Veränderung. Wir haben einen Schritt (Codezeile) korrigiert und alles wurde wieder grün.
- Obwohl Sie keine Integrationstests haben, sind diese nicht vollständig funktionsfähig. Auf die eine oder andere Weise ist dies eine Art grafische Oberfläche, in der Tasten gedrückt werden. Eine Art Interaktion findet speziell mit der externen Shell statt. Ich verstehe, dass Sie Tests in dieser Form haben, Sie starten einfach viele Threads gleichzeitig. Und was passte nicht zu den Abfragen, die von Standardtools generiert werden: JMeter, Gatling, die in keiner Weise mit der externen Shell interagieren, sondern einfach Anfragen an den Server senden?- Alles ist sehr einfach. Was ist die Architektur unserer Anwendung? Wir haben ein Backend, wir haben ein Frontend. Frontend ist das Web. Es gibt eine mobile Anwendung. Und wenn ich ein Ticket erstelle, ist mein Frontend beispielsweise auch mit Ereignisservern verbunden. Ich erstelle ein Ticket im Backend und alle Leute, die im selben Hotel sitzen, schauen sich Tickets im selben Hotel an. Sie werden von Event-Servern ankommen: Die Jungs werden aktualisieren, die Daten haben sich dort geändert. Und um alles zusammenzusetzen, haben wir einen einzigen Punkt - das ist der Kunde. Es stellt eine Verbindung zu einer großen Anzahl verschiedener Komponenten her. Entweder programmieren wir mit unseren Händen, dass wir im Backend ein Ticket erstellt haben, und stellen dann eine Verbindung zum Ereignisserver her, registrieren uns darauf und warten auf einige Ereignisse. Oder sie haben einfach einen Browser gestartet, in dem bereits alles zusammengestellt wurde, dieser Code bereits geschrieben ist und wir alles tun, was wir brauchen.
- Aber das sind verschiedene Ansätze? Oder wir arbeiten speziell mit dem Server oder mit dem Fenster. Sie können Anforderungen an mehrere Server gleichzeitig simulieren.- Deshalb habe ich Ihnen gesagt, dass wir funktionierende Roboter haben, die aus Tests aufgerufen werden. Es gibt solche, die Chrome aufgreifen und Klicks auf hoher Ebene ausführen. Es gibt solche, die nicht auf die Schaltfläche klicken, es passiert nichts, aber zum Zeitpunkt der Erstellung des Tickets sendet er eine Anfrage an den Server, und wir können dies oder das ausführen. Wir haben uns aus einem einfachen Grund für Chrome entschieden: Wir möchten echte Benutzer so simulieren, wie sie es wirklich verwenden. Während seine Seite geladen wurde, während alles für ihn gerendert wurde, während Java-Skripte und so weiter funktionierten. Wir möchten so nah wie möglich am Benutzer sein, und das ist echtes Web.
- Aber viele Dinge hängen davon ab, welche Art von Benutzer das Internet ist, welche Umgebung. Die Funktionsweise der Anwendung hängt jedoch bereits von Ihnen und Ihrer Seite ab. , : - ?— , - . , , , . , , . YouTube , . , . , .
— . - Selenium Grid ? - .— Cucumber': JAR, JAR Docker image Fargate' , image . flood.io grid Selenium , .
— ? , Chrome, . Internet Explorer 4 ( - ), ? - Android -.— , enterprise. enterprise , requirements. — , , web view. Android web view , .
— , , Load-? ?— .
Environment . . , Load, . 4- , , aliceapp.com. Load- , . , 504, , MySQL ElasticSearch.
— ( ), , ? .— Load- , . Das heißt, .
— , ?— , . , , , .
— , , .. html API?— Selenium DOM- : , , key down , — . .
— ? , ?— . , . QC, , QC. Smoke- -. « -, ». — , , , .
Pixonic DevGAMM Talks