
Hier ist das erste ursprünglich russischsprachige Buch, in dem die Geheimnisse der Verarbeitung von Big Data (Big Data) in den Clouds anhand realer Beispiele untersucht werden.
Der Schwerpunkt liegt auf Microsoft Azure- und AWS-Lösungen. Alle Arbeitsphasen werden berücksichtigt - das Abrufen von Daten, die für die Verarbeitung in der Cloud vorbereitet wurden, mithilfe von Cloud-Speicher- und Cloud-Datenanalysetools. Besonderes Augenmerk wird auf SAAS-Services gelegt. Die Vorteile von Cloud-Technologien im Vergleich zu Lösungen, die auf dedizierten Servern oder virtuellen Maschinen bereitgestellt werden, werden demonstriert.
Das Buch richtet sich an ein breites Publikum und wird als hervorragende Ressource für die Entwicklung von Azure, Docker und anderen unverzichtbaren Technologien dienen, ohne die moderne Unternehmen undenkbar sind.
Wir laden Sie ein, die Passage "Direkter Download von Streaming-Daten" zu lesen.
10.1. Allgemeine Architektur
Im vorherigen Kapitel haben wir die Situation untersucht, in der viele Clientanwendungen eine große Anzahl von Nachrichten senden müssen, die dynamisch verarbeitet, im Repository abgelegt und dann erneut verarbeitet werden müssen. Gleichzeitig ist es erforderlich, die Logik des Datenverarbeitungs- und Speicherflusses ändern zu können, ohne den Clientcode ändern zu müssen. Und schließlich sollten Kunden aus Sicherheitsgründen das Recht haben, nur eines zu tun - Nachrichten zu senden oder zu empfangen, aber in keiner Weise Daten zu lesen oder Datenbanken zu löschen, und sie sollten keine direkten Rechte zum Schreiben dieser Daten haben.
Solche Aufgaben sind in Systemen, die mit IoT-Geräten arbeiten, die über eine Internetverbindung verbunden sind, sowie in Online-Protokollanalysesystemen sehr häufig. Zusätzlich zu den oben aufgeführten Anforderungen an unseren dedizierten Service gibt es zwei weitere Anforderungen, die sich auf die Besonderheiten des „Internet der Dinge“ und die Gewährleistung einer zuverlässigen Nachrichtenverarbeitung beziehen. Erstens muss das Interaktionsprotokoll zwischen dem Client und dem Dienstempfänger sehr einfach sein, damit es auf einem Gerät mit begrenzten Rechenkapazitäten und sehr begrenztem Speicher implementiert werden kann (z. B. Arduino, Intel Edison, STM32 Discovery und andere „unangemessene“ Plattformen, wie z wie zuvor RaspberryPi). Die nächste Anforderung ist die zuverlässige Nachrichtenübermittlung unabhängig von möglichen Fehlern bei den Verarbeitungsdiensten. Dies ist eine stärkere Anforderung als die Anforderung einer hohen Zuverlässigkeit. Um die allgemeine Zuverlässigkeit des gesamten Systems zu gewährleisten, muss die Zuverlässigkeit aller seiner Komponenten hoch genug sein, und das Hinzufügen einer neuen Komponente führt nicht zu einer spürbaren Zunahme der Anzahl von Fehlern. Zusätzlich zum Fehler in der Cloud-Infrastruktur kann ein Fehler im vom Benutzer erstellten Dienst auftreten. Und selbst dann sollte die Nachricht verarbeitet werden, sobald der Benutzerdienst wiederhergestellt ist. Zu diesem Zweck muss der Nachrichtenfluss-Empfangsdienst die Nachricht zuverlässig speichern, bis sie verarbeitet wird oder bis ihre Lebensdauer abläuft (dies ist erforderlich, um einen Speicherüberlauf während eines kontinuierlichen Nachrichtenflusses zu verhindern). Ein Dienst mit diesen Eigenschaften wird als Event Hub bezeichnet. Für IoT-Geräte gibt es spezialisierte Hubs (IoT Hub), die eine Reihe anderer Eigenschaften aufweisen, die für die Verwendung in Verbindung mit Geräten des Internet der Dinge sehr wichtig sind (z. B. bidirektionale Kommunikation von einem Punkt aus, integriertes Nachrichtenrouting, „digitale Doppel“ des Geräts und eine Reihe von andere). Diese Dienste sind jedoch immer noch spezialisiert, und wir werden sie nicht im Detail betrachten.
Bevor wir uns dem Konzept der Nachrichtenkonzentration zuwenden, wenden wir uns den zugrunde liegenden Ideen zu.
Angenommen, wir haben eine Nachrichtenquelle (z. B. Anforderungen von einem Client) und einen Dienst, der diese verarbeiten soll. Die Verarbeitung einer einzelnen Anforderung nimmt Zeit in Anspruch und erfordert Rechenressourcen (CPU, Speicher, IOPS). Darüber hinaus können während der Verarbeitung einer Anforderung die verbleibenden Anforderungen nicht verarbeitet werden. Damit Clientanwendungen nicht einfrieren, während auf die Freigabe eines Dienstes gewartet wird, müssen sie mithilfe eines zusätzlichen Dienstes getrennt werden, der für das Speichern von Nachrichten verantwortlich ist, während sie in der Warteschlange auf die Verarbeitung warten. Diese Trennung ist auch notwendig, um die allgemeine Zuverlässigkeit des Systems zu erhöhen. In der Tat sendet der Client eine Nachricht an das System, aber der Verarbeitungsdienst kann "fallen", aber die Nachricht sollte nicht verloren gehen. Sie muss in einem Dienst gespeichert werden, der zuverlässiger als der Verarbeitungsdienst ist. Die einfachste Version eines solchen Dienstes heißt Warteschlange (Abb. 10.1).
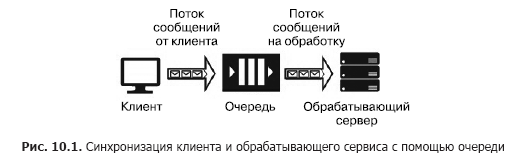
Der Warteschlangendienst funktioniert wie folgt: Der Client kennt die URL der Warteschlange und verfügt über Zugriffsschlüssel. Mithilfe des SDK oder der API der Warteschlange platziert der Client eine Nachricht, die den Zeitstempel, die Kennung und den Nachrichtentext mit einer Nutzlast im JSON-, XML- oder Binärformat enthält.
Der Programmcode des Dienstes enthält einen Zyklus, der die Warteschlange „abhört“ und bei jedem Schritt die nächste Nachricht abruft. Wenn sich eine Nachricht in der Warteschlange befindet, wird sie extrahiert und verarbeitet. Wenn der Dienst die Nachricht erfolgreich verarbeitet, wird sie aus der Warteschlange entfernt. Wenn während der Verarbeitung ein Fehler auftritt, wird dieser nicht gelöscht und kann erneut verarbeitet werden, wenn eine neue Version des Dienstes mit dem korrigierten Code gestartet wird. Die Warteschlange dient zum Synchronisieren eines Clients (oder einer Gruppe ähnlicher Clients) und genau eines Verarbeitungsdienstes (obwohl sich dieser in einem Servercluster oder in einer Serverfarm befinden kann). Zu den Cloud-Warteschlangendiensten gehören die Azure-Speicherwarteschlange, die Azure-Dienstbuswarteschlange und AWS SQS. Zu den auf virtuellen Maschinen gehosteten Diensten gehören RabbitMQ, ZeroMQ, MSMQ, IBM MQ usw.
Unterschiedliche Warteschlangendienste garantieren unterschiedliche Arten der Nachrichtenübermittlung:
- Mindestens einmalige Nachrichtenübermittlung
- streng einmalige Lieferung;
- Zustellung von Nachrichten unter Beibehaltung der Bestellung;
- Zustellung von Nachrichten ohne Aufrechterhaltung der Bestellung.
Die Warteschlange bietet eine zuverlässige Zustellung von Nachrichten von einer Quelle an einen Verarbeitungsdienst, dh eine Eins-zu-Eins-Interaktion. Was aber, wenn mehrere Dienste übermittelt werden müssen? In diesem Fall müssen Sie einen Dienst namens "topic" (topic) verwenden (Abb. 10.2).
Ein wichtiges Element dieser Architektur sind „Abonnements“. Dies ist der Pfad, der in dem Abschnitt registriert ist, über den die Nachricht gesendet wird. Nachrichten werden vom Client im Thema veröffentlicht und an eines der Abonnements übertragen, aus denen sie von einem der Dienste extrahiert und von diesem verarbeitet werden. Themen bieten eine Eins-zu-Viele-Interaktionsarchitektur für den Kundenservice. Beispiele für solche Dienste sind das Azure Service Bus-Thema und AWS SNS.
Nehmen wir nun an, dass es eine große Anzahl heterogener Clients gibt, die viele Nachrichten an verschiedene Dienste senden müssen, dh wir müssen ein Viele-zu-Viele-Interaktionssystem aufbauen. Natürlich kann eine solche Architektur aus mehreren Abschnitten erstellt werden, aber eine solche Konstruktion ist nicht skalierbar und erfordert Verwaltungs- und Überwachungsaufwand. Es gibt jedoch separate Dienste - Nachrichtenkonzentratoren (Abb. 10.3).
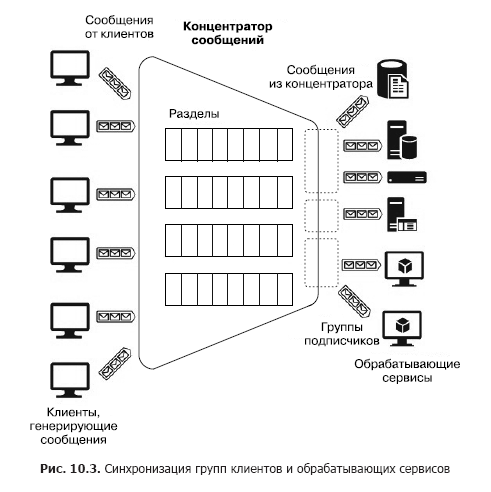
Der Hub akzeptiert Nachrichten von vielen Clients. Alle Clients können Nachrichten an einen gemeinsamen Service-Endpunkt senden oder über spezielle Schlüssel eine separate Verbindung zu verschiedenen Endpunkten herstellen. Mit diesen Schlüsseln können Sie Clients flexibel verwalten: Trennen Sie einige, trennen Sie neue usw. Innerhalb des Hubs befinden sich auch Partitionen. In diesem Fall können sie jedoch auf alle Clients verteilt werden, um die Produktivität zu steigern (Round Robin - „mit zyklischer Addition“), oder der Client kann Nachrichten in einem der Abschnitte veröffentlichen. Auf der anderen Seite werden Verarbeitungsdienste zu Verbrauchergruppen zusammengefasst. Ein oder mehrere Dienste können mit einer Gruppe verbunden werden. Somit ist ein Nachrichtenkonzentrator der flexibelste Dienst, der als Warteschlange, Abschnitt oder Gruppe von Warteschlangen oder als Satz von Abschnitten konfiguriert werden kann. Im Allgemeinen bietet ein Nachrichtenkonzentrator eine Viele-zu-Viele-Beziehung zwischen Clients und Diensten. Zu diesen Hubs gehören Apache Kafka, Azure Event Hub und AWS Kinesis Stream.
Bevor wir uns mit Cloud-basierten PaaS-Diensten befassen, werden wir uns mit einem sehr leistungsstarken und bekannten Dienst befassen - Apache Kafka. In Cloud-Umgebungen kann auf sie als Distribution zugegriffen werden, die direkt in einem Cluster einer virtuellen Maschine oder über den HDInsight-Dienst bereitgestellt wird. Apache Kafka ist also ein Dienst, der die folgenden Funktionen bietet:
- Veröffentlichen und Abonnieren eines Nachrichtenflusses
- zuverlässige Speicherung von Nachrichten;
- Anwendung von Streaming-Nachrichtenverarbeitungsdiensten von Drittanbietern.
Physisch läuft Kafka in einem Cluster von einem oder mehreren Servern. Kafka bietet eine API für die Interaktion mit externen Clients (Abb. 10.4).
Betrachten Sie diese APIs der Reihe nach.
- Mit Hersteller-APIs können Clientanwendungen Nachrichtenflüsse in einem oder mehreren Kafka-Themen veröffentlichen.
- Mit Consumer-APIs können Clientanwendungen ein oder mehrere Themen abonnieren und Nachrichtenflüsse verarbeiten, die von Themen an Clients übermittelt werden.
- Mit den Stream-Prozessor-APIs können Anwendungen als Streaming-Prozessor mit dem Kafka-Cluster interagieren. Quellen für einen Prozessor können ein oder mehrere Themen sein. In diesem Fall werden die verarbeiteten Nachrichten auch in einem oder mehreren Themen platziert.
- Die Connector-APIs helfen dabei, externe Datenquellen (z. B. RDB) als Nachrichtenquellen (z. B. Datenänderungsereignisse in der Datenbank abzufangen) und als Empfänger zu verbinden.
In Kafka erfolgt die Interaktion zwischen Clients und Cluster über TCP, was durch die vorhandenen SDKs für verschiedene Programmiersprachen, einschließlich .Net, erleichtert wird. Die grundlegenden SDK-Sprachen sind jedoch Java und Scala.
In einem Cluster erfolgt die Speicherung von Nachrichtenflüssen (in der Kafka-Terminologie auch als Einträge bezeichnet) logisch in Objekten, die als Themen bezeichnet werden (Abb. 10.5). Jeder Datensatz besteht aus einem Schlüssel, einem Wert und einem Zeitstempel. Ein Thema ist im Wesentlichen eine Folge von Datensätzen (Nachrichten), die von Kunden veröffentlicht wurden. Kafka-Themen unterstützen von 0 bis zu mehreren Abonnenten. Jedes Thema wird physisch als partitioniertes Protokoll dargestellt. Jeder Abschnitt ist eine geordnete Folge von Datensätzen, zu denen ständig neue hinzugefügt werden, die am Eingang von Kafka ankommen.
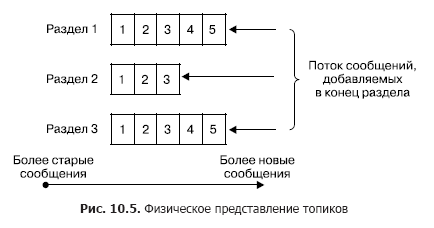
Jeder Eintrag im Abschnitt entspricht einer Nummer in der Sequenz, die auch als Offset bezeichnet wird und diese Nachricht in der Sequenz eindeutig identifiziert. Im Gegensatz zur Warteschlange löscht Kafka die Nachricht nicht nach der Verarbeitung des Dienstes, sondern nach der Lebensdauer der Nachrichten. Dies ist eine sehr wichtige Eigenschaft, die es verschiedenen Verbrauchern ermöglicht, von einem Thema zu lesen. Darüber hinaus ist jedem Verbraucher eine Vorspannung zugeordnet (Abb. 10.6). Und jeder Lesevorgang führt nur zu einer Wertsteigerung für jeden Kunden und wird vom Kunden genau bestimmt.
Im Normalfall erhöht sich dieser Versatz um eins, nachdem eine Nachricht aus dem Thema erfolgreich gelesen wurde. Bei Bedarf kann der Client diesen Offset verschieben und den Lesevorgang wiederholen.
Die Verwendung des Abschnittskonzepts verfolgt die folgenden Ziele.
Erstens bieten Abschnitte die Möglichkeit, Themen zu skalieren, wenn ein Thema nicht in denselben Knoten passt. Gleichzeitig hat jeder Abschnitt einen führenden Knoten (verwechseln Sie ihn nicht mit dem Hauptknoten des gesamten Clusters) und null oder mehrere nachfolgende Knoten. Der Kopfknoten ist für die Verarbeitung von Lese- / Schreibvorgängen verantwortlich, während die Follower seine passiven Kopien sind. Wenn der Masterknoten ausfällt, wird einer der Nachfolgeknoten automatisch zum Hauptknoten. Jeder Clusterknoten ist für einige Abschnitte der Lead und für andere ein Follower. Zweitens erhöht eine solche Replikation die Leseleistung aufgrund der Möglichkeit paralleler Leseoperationen.
Der Produzent kann die Nachricht explizit oder implizit im Round-Robin-Modus (dh mit einheitlicher Füllung) in ein beliebiges Thema seiner Wahl einfügen. Verbraucher sind in sogenannten Verbrauchergruppen zusammengefasst, und jede im Thema veröffentlichte Nachricht wird an einen Kunden in jeder Verbrauchergruppe übermittelt. In diesem Fall können Clients physisch auf einem oder mehreren Servern / virtuellen Maschinen gehostet werden. Im Einzelnen ist die Nachrichtenübermittlung wie folgt. Für alle Kunden, die derselben Verbrauchergruppe angehören, können Nachrichten zwischen Kunden verteilt werden, um die Auslastung zu optimieren. Wenn Kunden verschiedenen Verbrauchergruppen angehören, wird jede Nachricht an jede Gruppe gesendet. Die Trennung von Nachrichten von Abschnitten durch verschiedene Verbrauchergruppen ist in Abb. 2 dargestellt. 10.7.
Jetzt werde ich kurz die wichtigsten Parameter für die Zustellung und Speicherung von Nachrichten beschreiben, die von Kafka garantiert werden.
- Vom Hersteller an ein bestimmtes Thema gesendete Nachrichten werden ausschließlich in der Reihenfolge hinzugefügt, in der sie gesendet wurden.
- Der Client sieht die Nachrichtenreihenfolge in dem Thema, das beim Speichern der Nachrichten empfangen wurde. Infolgedessen werden Nachrichten vom Hersteller an den Verbraucher ausschließlich in der Reihenfolge geliefert, in der sie eingehen.
- Die N-fache Replikation des Themas stellt die Stabilität des Themas gegenüber dem Ausfall von N - 1 Knoten ohne Leistungsverlust sicher.
Daher kann der Apache Kafka-Dienst in den folgenden Modi verwendet werden.
- Dienst - Nachrichtenbroker (Warteschlange) oder Veröffentlichungsdienst - Nachrichtenabonnement (Thema). In der Tat basiert Kafka auf einer Gruppe von Themen, die mit einem Abonnenten in eine Warteschlange umgewandelt werden können. (Es sollte beachtet werden: Im Gegensatz zu den üblichen Nachrichtenbrokerdiensten, die auf dem Prinzip der Warteschlangen basieren, werden Kafka-Nachrichten erst nach Ablauf ihrer Lebensdauer gelöscht, während die Broker das Peek-Delete-Prinzip implementieren, dh das Abrufen und Löschen nach erfolgreicher Verarbeitung. ) Das Prinzip der Verbrauchergruppen fasst diese beiden Konzepte zusammen, und die Fähigkeit, Nachrichten in allen Themenbereichen mit der Verteilung von Round Robin zu veröffentlichen, macht Kafka zu einem universellen Multi-Mode-Nachrichtenbroker.
- Dienst zur Analyse von Streaming-Nachrichten. Dies ist dank der in Kafka enthaltenen API für Streaming-Prozessoren möglich, mit der Sie komplexe Systeme erstellen können, die auf der Grundlage von Event Driven erstellt wurden, mit Diensten, die Nachrichten filtern oder darauf antworten, sowie Diensten, die Nachrichten aggregieren.
All diese Eigenschaften ermöglichen es, Kafka als Schlüsselkomponente einer Plattform zu verwenden, die mit Streaming-Daten arbeitet und über hervorragende Funktionen zum Aufbau komplexer Nachrichtenverarbeitungssysteme verfügt. Gleichzeitig ist Kafka in Bezug auf die Bereitstellung und Konfiguration eines Clusters aus mehreren Knoten recht kompliziert, was einen erheblichen Verwaltungsaufwand erfordert. Da die Kafka zugrunde liegenden Ideen jedoch sehr gut zum Erstellen von Systemen, zum Streamen von Nachrichten und zum Empfangen von Nachrichten geeignet sind, bieten Cloud-Anbieter PaaS-Dienste an, die diese Ideen implementieren und alle Schwierigkeiten beim Erstellen und Verwalten eines Kafka-Clusters verbergen. Da diese Dienste hinsichtlich der Anpassung und Erweiterung über die für Dienste zugewiesenen Grenzen hinaus eine Reihe von Einschränkungen aufweisen, bieten Cloud-Anbieter spezielle IaaS / PaaS-Dienste für die physische Bereitstellung von Kafka in einem Cluster für virtuelle Maschinen an. In diesem Fall hat der Benutzer nahezu vollständige Konfigurations- und Erweiterungsfreiheit. Diese Dienste umfassen Azure HDInsight. Es wurde bereits oben erwähnt. Es wurde erstellt, um einerseits dem Benutzer selbst Dienste aus dem Hadoop-Ökosystem ohne externe Wrapper bereitzustellen und andererseits die Schwierigkeiten zu beseitigen, die sich aus der direkten Installation, Verwaltung und Konfiguration von IaaS ergeben. Docker Hosting ist ein wenig auseinander. Da dies ein äußerst wichtiges Thema ist, werden wir es betrachten, aber zuerst die PaaS-Dienste kennenlernen, die mit den Grundkonzepten von Kafka implementiert wurden.
10.2. Azure-Ereignis-Hub
Betrachten Sie den Azure Event Hub-Nachrichten-Hub-Dienst. Es ist ein Dienst, der auf dem PaaS-Modell basiert. Verschiedene Clientgruppen können als Nachrichtenquellen für den Azure Event Hub fungieren (Abbildung 10.8). Zunächst einmal handelt es sich um eine sehr große Gruppe von Cloud-Diensten, deren Ausgaben oder Trigger so konfiguriert werden können, dass Nachrichten direkt an den Event Hub gesendet werden. Dies können Stream Analytics-Jobs, Event Grid und eine wichtige Gruppe von Diensten sein, die Ereignisse umleiten - Protokolle im Event Hub (hauptsächlich mithilfe des AppService erstellt: API-App, Web-App, Mobile App und Funktions-App).
An den Hub übermittelte Nachrichten können direkt erfasst und im Blob-Speicher oder im Data Lake-Speicher gespeichert werden.
Die nächste Gruppe von Quellen sind externe Software-Clients oder -Geräte, für die es kein Azure Event Hub-SDK gibt und die nicht direkt in Azure-Dienste integriert werden können. Zu diesen Clients gehören hauptsächlich IoT-Geräte. Sie können Nachrichten über HTTPS oder AMQP an den Event Hub senden. Überlegungen zum Anschließen dieser Geräte gehen über den Rahmen unseres Buches hinaus.
Schließlich die Software-Clients, die Nachrichten generieren und diese mithilfe des Azure Event Hub SDK an den Event Hub senden. Diese Gruppe umfasst Azure PowerShell und die Azure-CLI.
Als Nachrichtenempfänger (Verbraucher - „Verbraucher“) vom Event Hub können Stream Analytics Job oder der Event Grid-Integrationsdienst verwendet werden. Darüber hinaus ist es möglich, Nachrichten von Software-Clients mithilfe des Azure Event Hub SDK zu empfangen. Verbraucher stellen über das AMQP 1.0-Protokoll eine Verbindung zum Event Hub her.
Berücksichtigen Sie die grundlegenden Konzepte des Azure Event Hub, die erforderlich sind, um zu verstehen, wie er verwendet und konfiguriert wird. Jede Quelle (in der Dokumentation auch als Herausgeber bezeichnet), die eine Nachricht an den Hub sendet, muss das HTTPS- oder AMQP 1.0-Protokoll verwenden. Die Wahl eines Protokolls wird durch den Client-Typ, das Kommunikationsnetzwerk und die Anforderungen an die Nachrichtenrate bestimmt. AMQP erfordert eine permanente Verbindung zwischen zwei bidirektionalen TCP-Sockets. Es wird durch die Verwendung des TLS-Transportschicht-Verschlüsselungsprotokolls oder von SSL / TLS geschützt. , , AMQP , HTTPS, . HTTPS.
, SAS (Shared Access Signature) tokens. SAS- SAS . SAS-, ( ).
256 . , .
, Event Hub. , , , -. EventHub (partitions). EventHub — , « — » (FIFO) (. 10.9).
— Event Hub. Event Hub 2 32 , Event Hub. , .
( ) , ( , — . ), (retention period), . . . , Azure Event Hub (offset). — , , , , . . Azure Event Hub SDK , , . -, .
, , , , . Azure Event Hub SDK , . , Storage Account. Azure, Event Hub, .
Event Hub (partition key), . — . , ( ) . , (round robin).
. , (consumer group) (. 10.11). . (view) ( ) , , . , . — 20, , .
. , . , (throughput unit). :
. , . . . ! , , , Event Hub.
(namespace) (. 10.12).
»Weitere Informationen zum Buch finden Sie auf
der Website des Herausgebers»
Inhalt»
Auszug20%
Rabatt- Gutschein für
Straßenhändler -
BigData