Tödliche 43 Sekunden, die die tägliche Verschlechterung des Dienstes verursachtenLetzte Woche ist auf GitHub ein
Vorfall aufgetreten, der den Dienst für 24 Stunden und 11 Minuten beeinträchtigt hat. Der Vorfall betraf nicht die gesamte Plattform, sondern nur einige interne Systeme, was zur Anzeige veralteter und inkonsistenter Informationen führte. Letztendlich gingen keine Benutzerdaten verloren, aber die manuelle Abstimmung von mehreren Sekunden des Schreibens in die Datenbank ist noch im Gange. Während des größten Teils des Absturzes war GitHub auch nicht in der Lage, Webhooks zu verarbeiten, GitHub-Seiten zu erstellen und zu veröffentlichen.
Wir alle bei GitHub möchten uns aufrichtig für die Probleme entschuldigen, auf die Sie alle gestoßen sind. Wir wissen um Ihr Vertrauen in GitHub und sind stolz darauf, nachhaltige Systeme zu entwickeln, die die hohe Verfügbarkeit unserer Plattform unterstützen. Wir haben Sie mit diesem Vorfall im Stich gelassen und bedauern es zutiefst. Obwohl wir die Probleme aufgrund der Verschlechterung der GitHub-Plattform nicht lange rückgängig machen können, können wir die Gründe für das Geschehen erklären, über die gewonnenen Erkenntnisse und die Maßnahmen sprechen, die es dem Unternehmen ermöglichen, sich in Zukunft besser vor solchen Fehlern zu schützen.
Hintergrund
Die meisten GitHub-Benutzerdienste arbeiten in unseren eigenen
Rechenzentren . Die Topologie des Rechenzentrums soll ein zuverlässiges und erweiterbares Grenznetz vor mehreren regionalen Rechenzentren bieten, die die Arbeit von Computer- und Datenspeichersystemen übernehmen. Trotz der Redundanz, die in die physischen und logischen Komponenten des Projekts integriert ist, ist es immer noch möglich, dass Standorte für einige Zeit nicht miteinander interagieren können.
Am 21. Oktober um 22.52 Uhr UTC führten geplante Reparaturarbeiten zum Austausch fehlerhafter optischer 100G-Geräte zu einem Kommunikationsverlust zwischen dem Netzwerkknoten an der Ostküste (US-Ostküste) und dem Hauptdatenzentrum an der Ostküste. Die Verbindung zwischen ihnen wurde nach 43 Sekunden wiederhergestellt, aber diese kurze Trennung verursachte eine Kette von Ereignissen, die zu einer Beeinträchtigung des Dienstes um 24 Stunden und 11 Minuten führten.
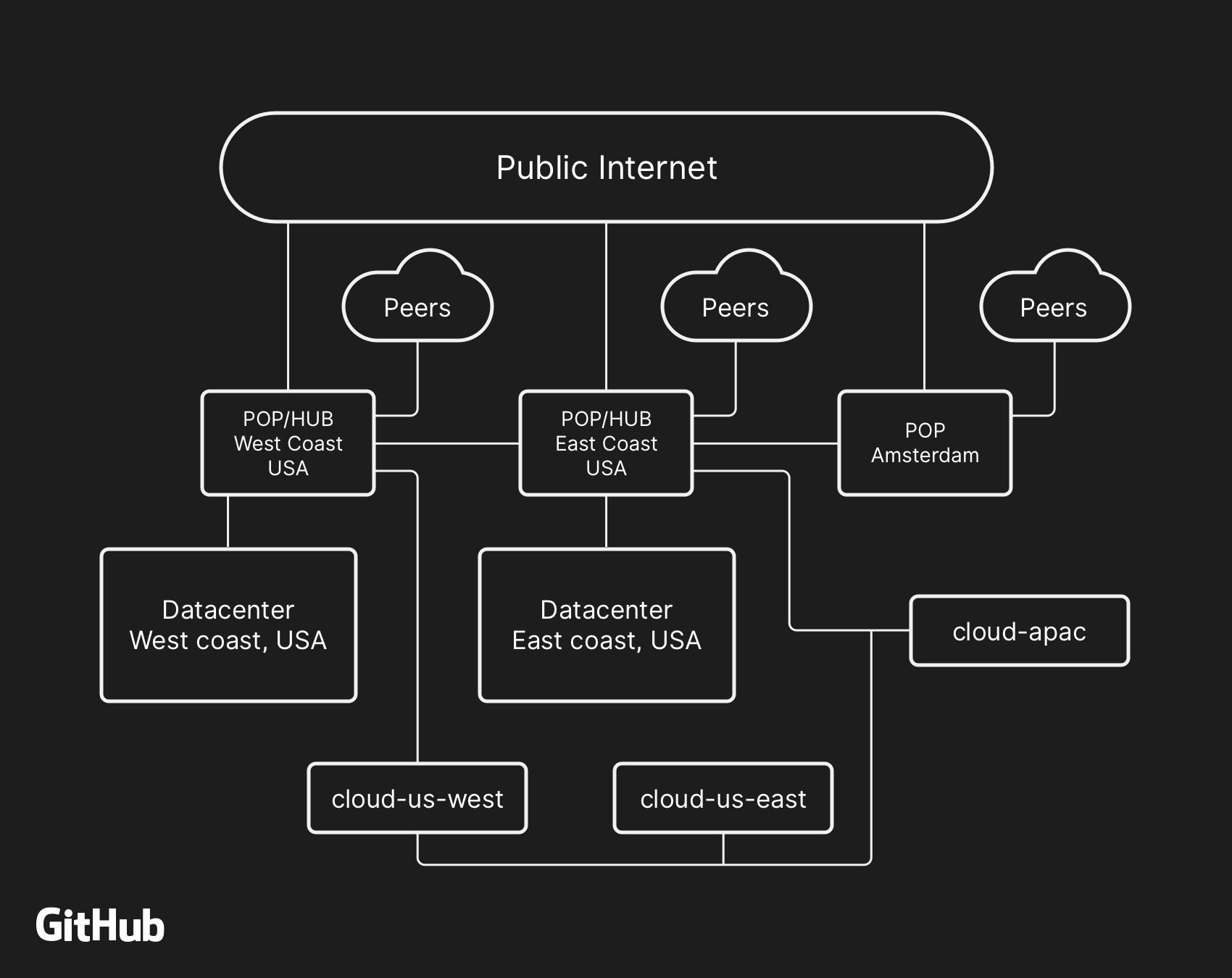 Die übergeordnete Netzwerkarchitektur von GitHub umfasst zwei physische Rechenzentren, drei POPs und Cloud-Speicher in mehreren Regionen, die über Peering verbunden sind
Die übergeordnete Netzwerkarchitektur von GitHub umfasst zwei physische Rechenzentren, drei POPs und Cloud-Speicher in mehreren Regionen, die über Peering verbunden sindIn der Vergangenheit haben wir diskutiert, wie wir
MySQL zum Speichern von GitHub-Metadaten verwenden und wie wir
MySQL hochverfügbar machen können . GitHub verwaltet mehrere MySQL-Cluster mit einer Größe von Hunderten von Gigabyte bis fast fünf Terabyte. Jeder Cluster verfügt über Dutzende von Lesereplikaten zum Speichern anderer Metadaten als Git. Daher bieten unsere Anwendungen Poolanforderungen, Probleme, Authentifizierung, Hintergrundverarbeitung und zusätzliche Funktionen außerhalb des Git-Objektrepositorys. Unterschiedliche Daten in verschiedenen Teilen der Anwendung werden mithilfe der funktionalen Segmentierung in verschiedenen Clustern gespeichert.
Um die Leistung in großem Maßstab zu verbessern, schreiben Anwendungen direkt Schreibvorgänge auf den entsprechenden Primärserver für jeden Cluster, delegieren jedoch in den allermeisten Fällen Leseanforderungen an eine Teilmenge von Replikatservern. Wir verwenden
Orchestrator , um MySQL-Clustertopologien zu verwalten und automatisch ein Failover durchzuführen. Während dieses Vorgangs berücksichtigt Orchestrator eine Reihe von Variablen und wird aus
Gründen der Konsistenz auf
Raft zusammengestellt . Orchestrator kann möglicherweise Topologien implementieren, die von Anwendungen nicht unterstützt werden. Sie müssen daher sicherstellen, dass Ihre Orchestrator-Konfiguration den Erwartungen auf Anwendungsebene entspricht.
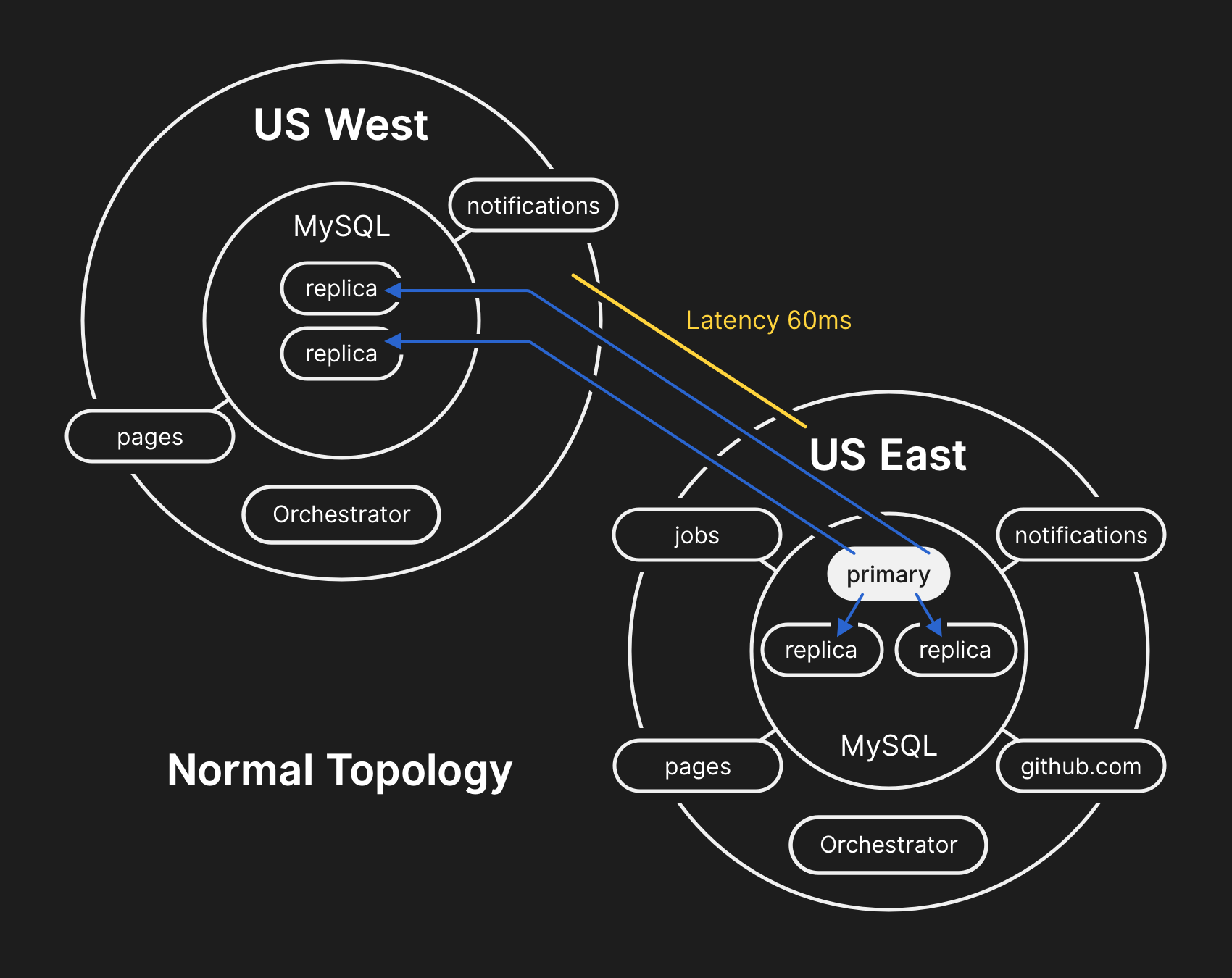 In einer typischen Topologie lesen alle Anwendungen lokal mit geringer Latenz.
In einer typischen Topologie lesen alle Anwendungen lokal mit geringer Latenz.Chronik des Vorfalls
21.10.2018, 22:52 UTC
Während der oben genannten Netzwerktrennung begann Orchestrator im Hauptdatenzentrum mit der Abwahl der Führung gemäß dem Raft-Konsensalgorithmus. Das Rechenzentrum an der Westküste und die öffentlichen Cloud-Knoten von Orchestrator an der Ostküste erzielten einen Konsens - und begannen, Clusterfehler zu ermitteln, um Datensätze an das westliche Rechenzentrum weiterzuleiten. Orchestrator begann im Westen mit der Erstellung einer Datenbankclustertopologie. Nach dem erneuten Herstellen der Verbindung haben die Anwendungen sofort Schreibverkehr an die neuen Primärserver in US West gesendet.
Auf den Datenbankservern im östlichen Rechenzentrum gab es für kurze Zeit Datensätze, die nicht in das westliche Rechenzentrum repliziert wurden. Da die Datenbankcluster in beiden Rechenzentren jetzt Datensätze enthielten, die sich nicht im anderen Rechenzentrum befanden, konnten wir den Primärserver nicht sicher an das östliche Rechenzentrum zurückgeben.
21.10.2018, 22:54 UTC
Unsere internen Überwachungssysteme begannen, Warnungen zu generieren, die auf zahlreiche Systemstörungen hinwiesen. Zu diesem Zeitpunkt antworteten mehrere Ingenieure und arbeiteten daran, eingehende Benachrichtigungen zu sortieren. Um 23:02 Uhr stellten die Ingenieure der ersten Antwortgruppe fest, dass sich die Topologien für zahlreiche Datenbankcluster in einem unerwarteten Zustand befanden. Bei der Abfrage der Orchestrator-API wurde die Datenbankreplikationstopologie angezeigt, die nur Server aus dem westlichen Rechenzentrum enthielt.
21.10.2018, 23:07 UTC
Zu diesem Zeitpunkt entschied sich das Reaktionsteam, die internen Bereitstellungstools manuell zu blockieren, um zusätzliche Änderungen zu verhindern. Um 23:09 Uhr stellte die Gruppe die Site auf
Gelb . Diese Aktion hat der Situation automatisch den Status eines aktiven Vorfalls zugewiesen und eine Warnung an den Vorfallkoordinator gesendet. Um 23:11 Uhr trat der Koordinator der Arbeit bei und beschloss zwei Minuten später,
den Status in Rot zu
ändern .
21.10.2018, 23:13 UTC
Zu diesem Zeitpunkt war klar, dass das Problem mehrere Datenbankcluster betraf. Weitere Entwickler aus der Engineering-Gruppe der Datenbank waren an der Arbeit beteiligt. Sie begannen, den aktuellen Status zu untersuchen, um festzustellen, welche Maßnahmen ergriffen werden mussten, um die US-Ostküstendatenbank manuell als Primärdatenbank für jeden Cluster zu konfigurieren und die Replikationstopologie neu zu erstellen. Dies war nicht einfach, da der westliche Datenbankcluster zu diesem Zeitpunkt fast 40 Minuten lang Datensätze von der Anwendungsebene erhalten hatte. Darüber hinaus gab es im östlichen Cluster mehrere Sekunden von Datensätzen, die nicht im Westen repliziert wurden und die Replikation neuer Datensätze im Osten nicht ermöglichten.
Der Schutz der Privatsphäre und Integrität von Benutzerdaten hat für GitHub oberste Priorität. Aus diesem Grund haben wir beschlossen, dass mehr als 30 Minuten Daten, die im westlichen Rechenzentrum aufgezeichnet wurden, nur eine Lösung für die Situation bieten, um diese Daten zu speichern: Weiterleiten (Fail-Forward). Anwendungen im Osten, die vom Schreiben von Informationen in den westlichen MySQL-Cluster abhängen, können die zusätzliche Verzögerung derzeit jedoch nicht bewältigen, da die meisten ihrer Datenbankaufrufe hin und her übertragen werden. Diese Entscheidung wird dazu führen, dass unser Service für viele Benutzer ungeeignet wird. Wir glauben, dass die langfristige Verschlechterung der Servicequalität es wert war, die Konsistenz der Daten unserer Benutzer sicherzustellen.
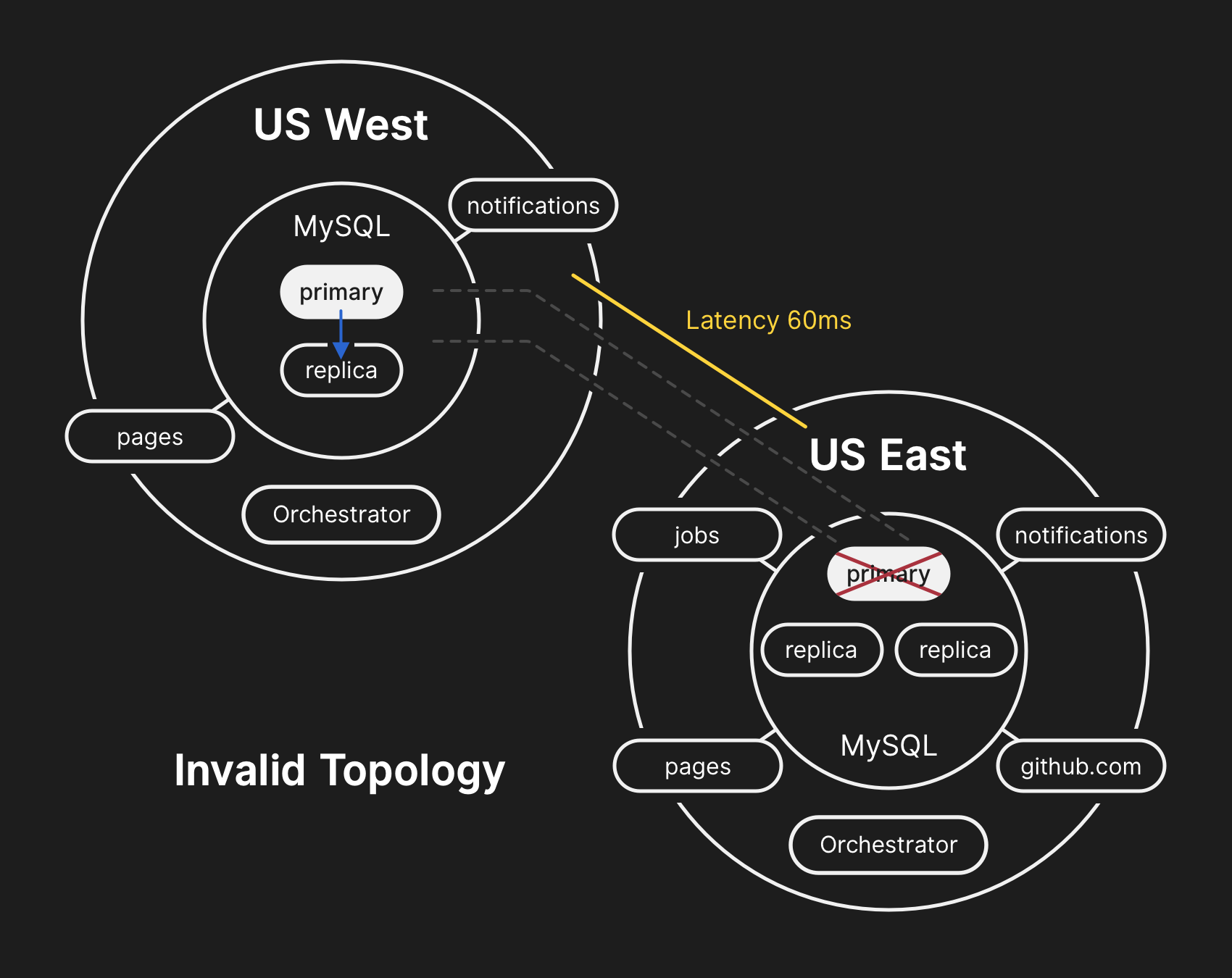 In der falschen Topologie wird die Replikation von West nach Ost verletzt, und Anwendungen können keine Daten aus aktuellen Replikaten lesen, da sie von einer geringen Latenz abhängen, um die Transaktionsleistung aufrechtzuerhalten
In der falschen Topologie wird die Replikation von West nach Ost verletzt, und Anwendungen können keine Daten aus aktuellen Replikaten lesen, da sie von einer geringen Latenz abhängen, um die Transaktionsleistung aufrechtzuerhalten21.10.2018, 23:19 UTC
Anfragen zum Status von Datenbankclustern zeigten, dass die Ausführung von Aufgaben, die Metadaten schreiben, wie z. B. Push-Anforderungen, gestoppt werden muss. Wir haben eine Entscheidung getroffen und absichtlich eine teilweise Verschlechterung des Dienstes vorgenommen, indem wir Webhooks und die Zusammenstellung von GitHub-Seiten ausgesetzt haben, um die Daten, die wir bereits von Benutzern erhalten haben, nicht zu gefährden. Mit anderen Worten, die Strategie bestand darin, Prioritäten zu setzen: Datenintegrität statt Benutzerfreundlichkeit der Website und schnelle Wiederherstellung.
22.10.2008, 00:05 UTC
Die Ingenieure des Reaktionsteams begannen mit der Entwicklung eines Plans zur Behebung von Dateninkonsistenzen und starteten Failover-Verfahren für MySQL. Es war geplant, Dateien aus der Sicherung wiederherzustellen, Replikate an beiden Standorten zu synchronisieren, zu einer stabilen Diensttopologie zurückzukehren und dann die Verarbeitungsjobs in der Warteschlange fortzusetzen. Wir haben den Status aktualisiert, um Benutzer darüber zu informieren, dass wir ein verwaltetes Failover des internen Speichersystems durchführen werden.
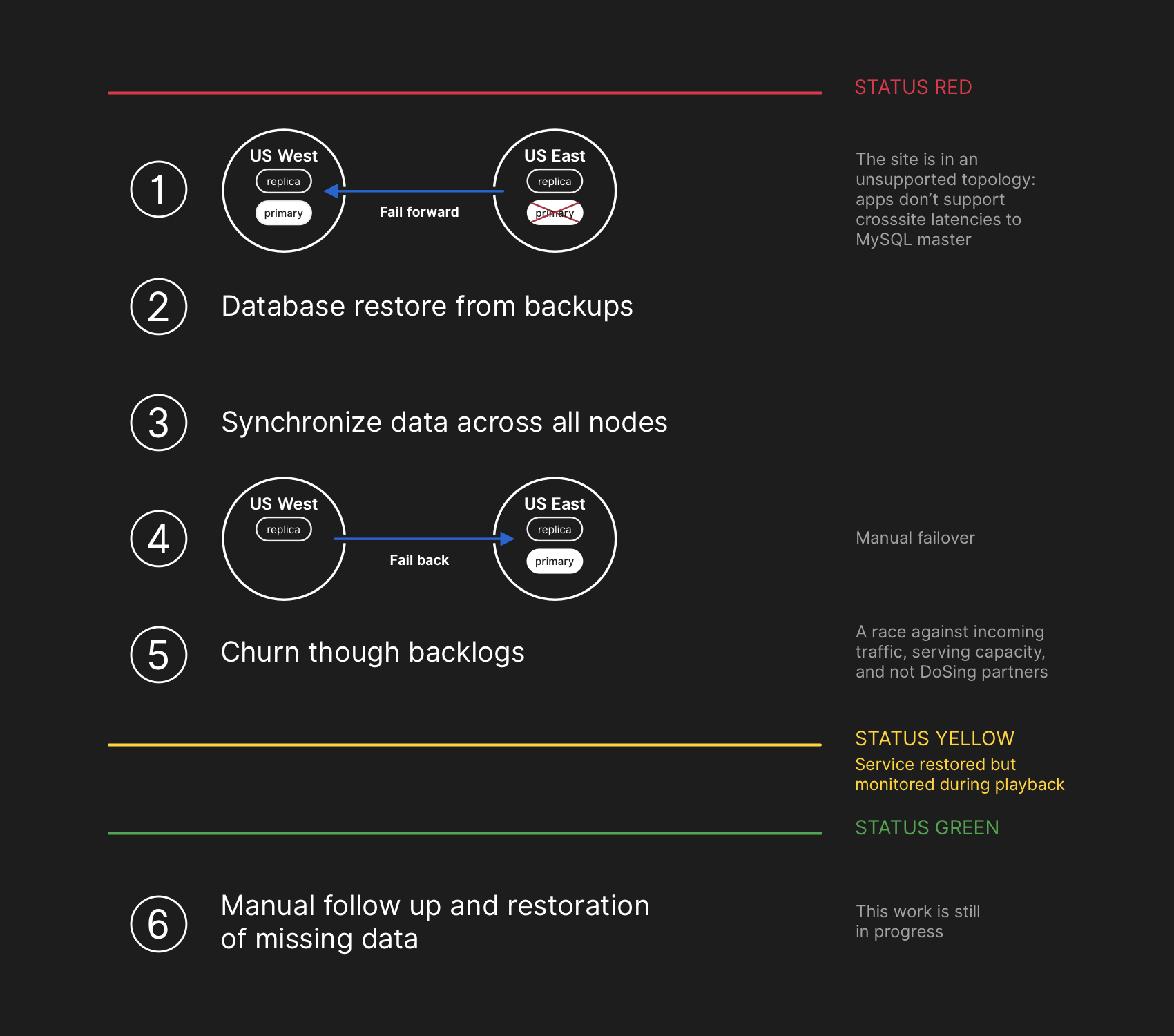 Der Wiederherstellungsplan umfasste das Vorwärtsbewegen, Wiederherstellen von Sicherungen, Synchronisieren, Zurücksetzen und Abarbeiten der Verzögerung, bevor der grüne Status wiederhergestellt wurde
Der Wiederherstellungsplan umfasste das Vorwärtsbewegen, Wiederherstellen von Sicherungen, Synchronisieren, Zurücksetzen und Abarbeiten der Verzögerung, bevor der grüne Status wiederhergestellt wurdeObwohl MySQL-Backups alle vier Stunden erstellt und viele Jahre lang gespeichert werden, befinden sie sich in einem Remote-Cloud-Speicher für Blob-Objekte. Die Wiederherstellung mehrerer Terabyte aus einem Backup dauerte mehrere Stunden. Das Übertragen von Daten vom Remote-Sicherungsdienst hat lange gedauert. Die meiste Zeit wurde damit verbracht, zu entpacken, die Prüfsumme zu überprüfen, große Sicherungsdateien vorzubereiten und auf frisch vorbereitete MySQL-Server hochzuladen. Dieses Verfahren wird täglich getestet, sodass jeder eine gute Vorstellung davon hatte, wie lange die Wiederherstellung dauern würde. Vor diesem Vorfall mussten wir jedoch nie den gesamten Cluster aus einer Sicherung vollständig neu erstellen. Andere Strategien haben immer funktioniert, z. B. verzögerte Replikate.
22.10.2008, 00:41 UTC
Zu diesem Zeitpunkt wurde ein Sicherungsprozess für alle betroffenen MySQL-Cluster eingeleitet, und die Ingenieure verfolgten den Fortschritt. Gleichzeitig untersuchten mehrere Gruppen von Ingenieuren Möglichkeiten, um die Übertragung und Wiederherstellung zu beschleunigen, ohne die Site weiter zu verschlechtern oder das Risiko einer Datenkorruption.
22.10.2008, 06:51 UTC
Mehrere Cluster im östlichen Rechenzentrum haben die Wiederherstellung nach Sicherungen abgeschlossen und begonnen, neue Daten von der Westküste zu replizieren. Dies führte zu einer Verlangsamung des Ladens von Seiten, die landesweit einen Schreibvorgang ausführten. Das Lesen von Seiten aus diesen Datenbankclustern lieferte jedoch tatsächliche Ergebnisse, wenn die Leseanforderung auf ein neu wiederhergestelltes Replikat fiel. Andere größere Datenbankcluster erholten sich weiter.
Unsere Teams haben eine Wiederherstellungsmethode direkt von der Westküste identifiziert, um Bandbreitenbeschränkungen zu überwinden, die durch das Booten von externem Speicher verursacht werden. Es wurde fast zu 100% klar, dass die Wiederherstellung erfolgreich abgeschlossen werden kann, und die Zeit zum Erstellen einer fehlerfreien Replikationstopologie hängt davon ab, wie viel Nachholreplikation erforderlich ist. Diese Schätzung wurde basierend auf der verfügbaren Telemetriereplikation linear interpoliert, und die Statusseite wurde
aktualisiert , um die Wartezeit von zwei Stunden als geschätzte Wiederherstellungszeit festzulegen.
22.10.2008, 07:46 UTC
GitHub hat einen
informativen Blog-Beitrag gepostet. Wir selbst verwenden GitHub-Seiten, und alle Assemblys wurden vor einigen Stunden angehalten, sodass für die Veröffentlichung zusätzlicher Aufwand erforderlich war. Wir entschuldigen uns für die Verzögerung. Wir wollten diese Nachricht viel früher senden und werden in Zukunft Aktualisierungen unter den Bedingungen solcher Einschränkungen veröffentlichen.
22.10.2008, 11:12 UTC
Alle Primärdatenbanken werden erneut in den Osten übertragen. Dies führte dazu, dass die Site viel schneller reagierte, da die Datensätze jetzt an einen Datenbankserver weitergeleitet wurden, der sich im selben physischen Rechenzentrum wie unsere Anwendungsschicht befand. Obwohl dies die Leistung erheblich verbesserte, gab es immer noch Dutzende von Replikaten zum Lesen der Datenbank, die mehrere Stunden hinter der Hauptkopie lagen. Diese verzögerten Replikate haben dazu geführt, dass Benutzer bei der Interaktion mit unseren Diensten inkonsistente Daten sehen. Wir verteilen die Leselast auf einen großen Pool von Lesereplikaten, und jede Anforderung an unsere Dienste hat gute Chancen, mit einer Verzögerung von mehreren Stunden in das Lesereplikat zu gelangen.
Tatsächlich wird die Aufholzeit einer nacheilenden Replik exponentiell und nicht linear reduziert. Als Benutzer in den USA und in Europa aufgrund der erhöhten Belastung von Datensätzen in Datenbankclustern aufwachten, dauerte der Wiederherstellungsprozess länger als erwartet.
22.10.2008, 13:15 UTC
Wir näherten uns der Spitzenlast auf GitHub.com. Das Reaktionsteam besprach die nächsten Schritte. Es war klar, dass die Replikationsverzögerung auf einen konsistenten Zustand zunimmt und nicht abnimmt. Zuvor haben wir begonnen, zusätzliche MySQL-Lesereplikate in der öffentlichen Cloud der Ostküste vorzubereiten. Sobald sie verfügbar waren, wurde es einfacher, den Fluss von Leseanforderungen auf mehrere Server zu verteilen. Durch die Reduzierung der durchschnittlichen Belastung von Lesereplikaten wurde der Replikationsaufholprozess beschleunigt.
22.10.2008, 16:24 UTC
Nach dem Synchronisieren der Replikate kehrten wir zur ursprünglichen Topologie zurück, wodurch die Probleme der Verzögerung und Verfügbarkeit beseitigt wurden. Im Rahmen einer bewussten Entscheidung über die Priorität der Datenintegrität gegenüber einer schnellen Korrektur der Situation haben wir
den roten Status der Site
beibehalten, als wir mit der Verarbeitung der gesammelten Daten begannen.
22.10.2008, 16:45 UTC
In der Wiederherstellungsphase war es notwendig, die mit der Verzögerung verbundene erhöhte Belastung auszugleichen, unsere Ökosystempartner möglicherweise mit Benachrichtigungen zu überlasten und so schnell wie möglich zu einer hundertprozentigen Effizienz zurückzukehren. Mehr als fünf Millionen Hook-Ereignisse und 80.000 Anfragen zum Erstellen von Webseiten blieben in der Warteschlange.
Als wir die Verarbeitung dieser Daten wieder aktiviert haben, haben wir ungefähr 200.000 nützliche Aufgaben mit Webhooks verarbeitet, die die interne TTL überschritten und gelöscht wurden. Als wir davon erfuhren, stoppten wir die Verarbeitung und begannen, die TTL zu erhöhen.
Um eine weitere Verschlechterung der Zuverlässigkeit unserer Statusaktualisierungen zu vermeiden, haben wir den Status der Verschlechterung beibehalten, bis wir die Verarbeitung der gesamten gesammelten Datenmenge abgeschlossen haben und sichergestellt haben, dass die Dienste eindeutig zum normalen Leistungsniveau zurückgekehrt sind.
22.10.2008, 23:03 Uhr UTC
Alle unvollständigen Webhook-Ereignisse und Pages-Assemblys werden verarbeitet und die Integrität und der ordnungsgemäße Betrieb aller Systeme werden bestätigt. Der Status der Site wurde
auf Grün aktualisiert .
Weitere Aktionen
Beheben von Dateninkongruenzen
Während der Wiederherstellung haben wir binäre MySQL-Protokolle mit Einträgen hauptsächlich des Rechenzentrums repariert, die nicht auf das westliche repliziert wurden. Die Gesamtzahl solcher Einträge ist relativ gering. In einem der am stärksten frequentierten Cluster befinden sich beispielsweise in diesen Sekunden nur 954 Datensätze. Wir analysieren derzeit diese Protokolle und ermitteln, welche Einträge automatisch abgeglichen werden können und welche Benutzerunterstützung erfordern. Mehrere Teams nehmen an dieser Arbeit teil, und unsere Analyse hat bereits die Kategorie von Datensätzen ermittelt, die der Benutzer dann wiederholt hat - und die erfolgreich gespeichert wurden. Wie in dieser Analyse angegeben, besteht unser Hauptziel darin, die Integrität und Genauigkeit der auf GitHub gespeicherten Daten zu gewährleisten.
Kommunikation
Um Ihnen während des Vorfalls wichtige Informationen zu übermitteln, haben wir mehrere öffentliche Schätzungen der Wiederherstellungszeit vorgenommen, die auf der Verarbeitungsgeschwindigkeit der gesammelten Daten basieren. Rückblickend berücksichtigten unsere Schätzungen nicht alle Variablen. Wir entschuldigen uns für die Verwirrung und werden uns bemühen, in Zukunft genauere Informationen bereitzustellen.
Technische Maßnahmen
Im Rahmen dieser Analyse wurden eine Reihe technischer Maßnahmen ermittelt. Die Analyse wird fortgesetzt, die Liste kann ergänzt werden.
- Passen Sie die Konfiguration von Orchestrator an, um zu verhindern, dass Primärdatenbanken außerhalb der Region verschoben werden. Orchestrator arbeitete gemäß den Einstellungen, obwohl die Anwendungsschicht eine solche Topologieänderung nicht unterstützte. Die Wahl eines Führers innerhalb einer Region ist normalerweise sicher, aber das plötzliche Auftreten einer Verzögerung aufgrund des Verkehrsflusses über den Kontinent ist zur Hauptursache für diesen Vorfall geworden. Dies ist ein sich abzeichnendes, neues Verhalten des Systems, da wir zuvor nicht auf den internen Teil des Netzwerks dieser Größenordnung gestoßen sind.
- Wir haben die Migration auf das neue Statusberichtssystem beschleunigt, das eine geeignetere Plattform für die Erörterung aktiver Vorfälle mit präziseren und klareren Formulierungen bietet. Obwohl viele Teile von GitHub während des Vorfalls verfügbar waren, konnten wir nur den Status Grün, Gelb und Rot für die gesamte Site auswählen. Wir geben zu, dass dies kein genaues Bild ergibt: Was funktioniert und was nicht. Das neue System zeigt die verschiedenen Komponenten der Plattform an, sodass Sie den Status jedes Dienstes kennen.
- Einige Wochen vor diesem Vorfall haben wir eine unternehmensweite Engineering-Initiative gestartet, um die Bereitstellung von GitHub-Datenverkehr aus mehreren Rechenzentren mithilfe der Aktiv / Aktiv / Aktiv-Architektur zu unterstützen. Ziel dieses Projekts ist es, die N + 1-Redundanz auf Rechenzentrumsebene zu unterstützen, um dem Ausfall eines Rechenzentrums ohne Einmischung von außen standzuhalten. Dies ist eine Menge Arbeit und wird einige Zeit in Anspruch nehmen, aber wir glauben, dass mehrere gut vernetzte Rechenzentren in verschiedenen Regionen einen guten Kompromiss darstellen. Der jüngste Vorfall hat diese Initiative noch weiter vorangetrieben.
- Wir werden unsere Annahmen aktiver überprüfen. GitHub wächst schnell und hat in den letzten zehn Jahren eine beträchtliche Komplexität aufgebaut. Es wird immer schwieriger, den historischen Kontext von Kompromissen und getroffenen Entscheidungen zu erfassen und an die neue Generation von Mitarbeitern weiterzugeben.
Organisatorische Maßnahmen
Dieser Vorfall hat unser Verständnis der Zuverlässigkeit der Website stark beeinflusst. Wir haben gelernt, dass eine Verschärfung der Betriebskontrolle oder eine Verbesserung der Reaktionszeiten in einem so komplexen Dienstleistungssystem wie dem unseren keine ausreichenden Garantien für Zuverlässigkeit sind. Um diese Bemühungen zu unterstützen, werden wir auch eine systematische Praxis zum Testen von Fehlerszenarien beginnen, bevor sie tatsächlich auftreten. Diese Arbeit umfasst die gezielte Fehlerbehebung und den Einsatz von Chaos-Engineering-Tools.
Fazit
Wir wissen, wie Sie sich in Ihren Projekten und Ihrem Geschäft auf GitHub verlassen. Wir kümmern uns mehr als jeder andere um die Verfügbarkeit unseres Service und die Sicherheit Ihrer Daten.
Die Analyse dieses Vorfalls wird weiterhin eine Gelegenheit finden, Ihnen besser zu dienen und Ihr Vertrauen zu rechtfertigen.