In den Kommentaren
zu unserem letzten Artikel gab es viele Fragen zu den Technologien, die wir verwenden. In diesem Artikel werde ich - Igor Mosyagin, F & E-Entwickler von Lamoda - darüber berichten. Unter dem Schnitt finden Sie eine umfassende Liste von Sprachen, Tools, Plattformen und Technologien, die uns durch die Hände gegangen sind. Das Frontend, das Backend, die Datenbank, die Nachrichtenbroker, die Caches sowie die Überwachung, Entwicklung und der Ausgleich sind eine detaillierte Darstellung dessen, was wir heute verwenden und was wir aufgegeben haben.
Meine Kollegen und ich sind bereit, in den Kommentaren oder am Stand des Unternehmens auf der HighLoad ++ 2018 zu diskutieren.
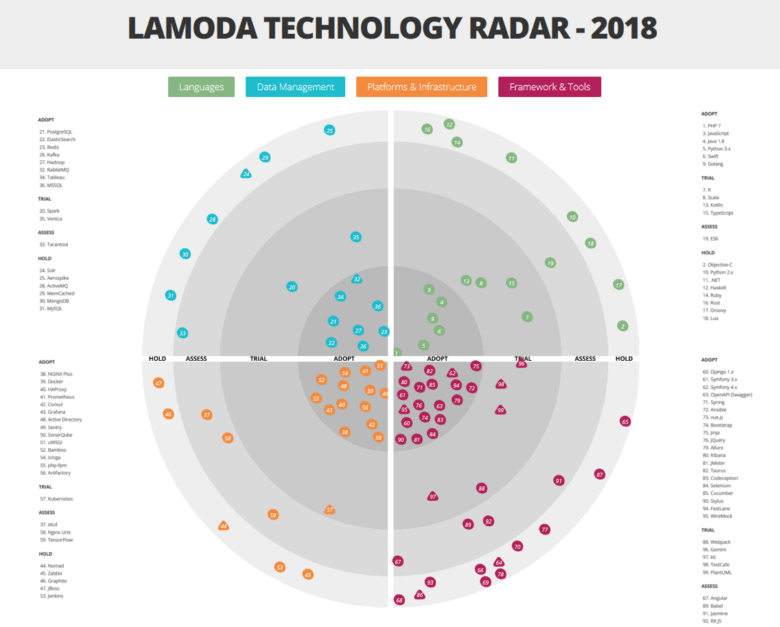
Sehen Sie sich das Radar hier groß und detailliert an.Wie bereits erwähnt, sind in Lamoda eine Vielzahl unterschiedlicher Technologien und Tools involviert. Und das ist kein Zufall. Ansonsten können wir die Last nicht bewältigen! Wir haben ein großes automatisiertes Lager. Unser Callcenter wird von 500 Mitarbeitern bedient. Dank der von uns erstellten Prozesse können wir den Kunden innerhalb von 5 Minuten nach Auftragserteilung zurückrufen. Unser Lieferservice arbeitet in 15-Minuten-Intervallen. Zusätzlich zu unseren eigenen Systemen verfügen wir über eine B2B-Integration mit anderen Online-Shops. Bei einer Vielzahl von Aufgaben und den Anforderungen eines so dynamischen Geschäfts wie E-Commerce ist das Wachstum des technischen Stacks unvermeidlich, da wir jedes Problem mit den am besten geeigneten Technologien lösen möchten. Vielfalt ist unvermeidlich. Wir werden unten über die Hauptvertreter unseres Stacks sprechen. Aber beginnen wir mit Mechanismen, die es uns ermöglichen, uns nicht in dieser Vielfalt zu verlieren.
Grundlagen der Architektur
Wir bewegen uns aktiv in Richtung Microservice-Architektur. Die meisten Systeme wurden bereits nach dieser Ideologie gebaut - vor zwei Jahren haben wir mit unseren Problemen und ihren Lösungen eine Übergangsphase durchlaufen. Wir werden uns jedoch nicht mit den Details dieses Prozesses befassen - ein Bericht von Andrey Evsyukov "
Merkmale von Microservices am Beispiel einer E-Com-Plattform " wird viel mehr darüber erzählen.
Um die technologische Vielfalt nicht zu verschärfen, haben wir eine „Diktatur bewährter Praktiken“ eingeführt, nach der den Entwicklern neuer Chips empfohlen wird, die Technologien und Werkzeuge zu verwenden, die bereits irgendwo im Unternehmen eingesetzt werden. Die meisten Dienste kommunizieren über die API miteinander (wir verwenden unsere Modifikation der zweiten Version des JSONRPC-Standards), aber wenn die Geschäftslogik dies zulässt, verwenden wir auch den Datenbus für die Interaktion.
Die Verwendung anderer Technologien ist nicht verboten. Jede neue Idee sollte jedoch in einem speziell geschaffenen Architekturkomitee getestet werden, dem Führungskräfte der Hauptbereiche angehören.
In Anbetracht des nächsten Vorschlags gibt das Komitee entweder grünes Licht für das Experiment oder bietet eine Art Ersatz aus dem vorhandenen Stapel an. Diese Entscheidung hängt übrigens weitgehend von den aktuellen Umständen im Geschäft ab. Wenn beispielsweise ein Team am Vorabend des Black Friday-Verkaufs ankündigt, dass es Technologie in die Produktion einführen wird, von der das Komitee noch nie zuvor gehört hat, wird dies höchstwahrscheinlich abgelehnt. Auf der anderen Seite kann dasselbe Experiment grünes Licht erhalten, wenn eine neue Technologie oder ein neues Tool unter weniger kritischen Geschäftsbedingungen eingeführt wird und die Implementierung mit Tests außerhalb der Produktion beginnt.
Das Architekturkomitee ist auch für die Wartung des Technologieradars verantwortlich und nimmt alle 2-3 Monate die erforderlichen Änderungen vor. Mit dieser Ressource soll den Teams eine Vorstellung davon vermittelt werden, über welche Fachkenntnisse das Unternehmen bereits verfügt.
Aber kommen wir zum interessantesten - zur Analyse der Sektoren unseres Radars.
Es ist erwähnenswert, dass wir eine leicht nicht standardmäßige Interpretation der Kategorien der Technologieeinführung verwenden:
- ADOPT - Technologien und Tools, die implementiert und aktiv genutzt werden;
- TRIAL - Technologien und Tools, die die Testphase bereits bestanden haben und sich auf die Arbeit mit der Produktion vorbereiten (oder sogar bereits dort arbeiten);
- ASSESS - Testwerkzeuge, die derzeit evaluiert werden und die Produktion noch nicht beeinflussen. Mit ihrer Teilnahme werden nur Testprojekte durchgeführt;
- HOLD - in dieser Kategorie verfügen wir über Fachwissen, aber die genannten Tools werden nur mit Unterstützung bestehender Systeme verwendet - es werden keine neuen Projekte auf diesen gestartet.
Entwicklung
PHP - Python - Los
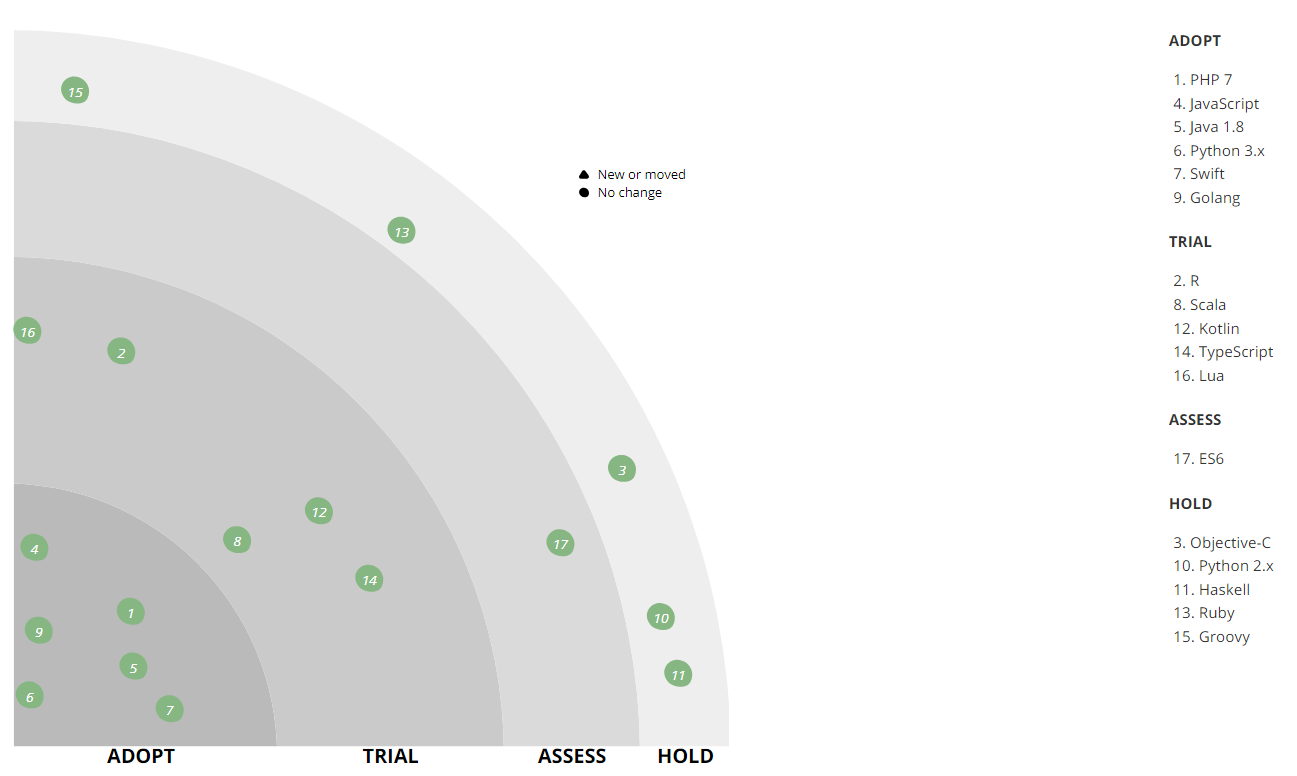
Die erste Sprache, auf die wir eingehen wollen, ist PHP. Heute löst es nur einen Teil der Backend-Aufgaben des Geschäfts, und anfangs arbeitete das gesamte Backend an PHP. Als das Geschäft im Front-End expandierte, machte sich ein Mangel an Geschwindigkeit und Produktivität bemerkbar - damals verwendeten wir PHP 5, also ersetzte Python es (zuerst 2.x und dann 3.x). Mit PHP können Sie jedoch umfangreiche Geschäftsmodelle schreiben. Daher ist diese Sprache im Backoffice geblieben, um verschiedene betriebliche Prozesse zu automatisieren, insbesondere die Integration in Online-Shops oder Lieferservices von Drittanbietern sowie die Automatisierung eines Content-Studios, das Produktkarten erstellt. Jetzt verwenden wir bereits PHP 7. In PHP haben wir viele Bibliotheken für den internen Gebrauch geschrieben: Integration und Wrapper über unsere Infrastruktur, Integrationsschicht zwischen Diensten, verschiedene wiederverwendete Helfer. Der erste Stapel von Bibliotheken wurde bereits als Open Source auf
github.com verwendet , und der Rest, der "ausgereifteste", wird bald eintreffen. Eine der ersten war eine Zustandsmaschine, die, in fast allen Anwendungen vorhanden, dies bei der Bestellung sicherstellt, bevor alle notwendigen Aktionen gesendet werden.
Im Laufe der Zeit ist Python auch für ein Store-Backend nicht mehr ausreichend. Jetzt bevorzugen wir einen produktiveren und leichteren Go.
Vielleicht war der Übergang zu Go eine wichtige Änderung, da dadurch viel Hardware und Personal gespart wurde - die Effizienz hat sich erheblich erhöht. Die ersten, die die ersten Projekte auf Go machten, waren RnD, sie wollten sich nicht mit den technischen Einschränkungen von Python befassen. Dann gab es im mobilen Entwicklungsteam Leute, die ihn kannten und ihn zur Produktion beförderten. Nach ihrer Einreichung haben wir Tests durchgeführt und waren mit dem Ergebnis mehr als zufrieden. In anderen Fällen sank das Laden der Clusterknoten erheblich, nachdem ein Teil des Projekts von Python nach Go umgeschrieben wurde. Durch das Umschreiben der Rabattberechnungs-Engine für den Warenkorb von Python auf Go konnten wir beispielsweise achtmal mehr Anforderungen bei gleichen Hardwarekapazitäten verarbeiten, und die durchschnittliche API-Antwortzeit wurde um das 25-fache reduziert. Das heißt, Go erwies sich als effizienter als Python (wenn Sie es richtig schreiben), auch wenn es für den Entwickler nicht so praktisch ist.
Da die mobile Entwicklung mit Dutzenden interner APIs interagieren musste, wurde ein Codegenerator erstellt, den ein Client gemäß der Beschreibung des API-Dienstes (gemäß der Swagger-Spezifikation) auf Go generieren kann. So begann Go allmählich, mit vorhandenen Diensten und Tools zu korrespondieren, insbesondere mit denen, die den „Engpass“ für die Last verursachten. Wir haben dem Entwickler des mobilen Backends nicht nur das Leben erleichtert, sondern auch die Befolgung interner Konventionen zum Entwickeln von APIs, zum Benennen von Methoden, zum Übergeben von Parametern und dergleichen vereinfacht. Diese Standardisierung hat die Entwicklung und Implementierung neuer Dienste für alle Teams erleichtert.
Go wird bereits heute fast überall - in allen Echtzeitinteraktionen mit Benutzern - im Backend der Site und in mobilen Anwendungen sowie in den Diensten verwendet, mit denen sie verknüpft sind. Und wo keine schnelle Verarbeitung und Reaktion erforderlich ist, beispielsweise bei Aufgaben der Interaktion mit Data Warehouse, bleibt Python bestehen, da es für Datenverarbeitungsaufgaben nicht gleichwertig ist (obwohl es hier eine Go-Penetration gibt).
Wie Sie auf dem Radar sehen können, haben wir Java im Asset. Es wird im Warehouse Management System (WMS) verwendet und hilft, Bestellungen schnell zu sammeln. Bisher haben wir dort einen ziemlich alten Stack und ein altes Architekturmodell - einen Monolithen, der sich auf Wildfly 10 und 8 Java Hotspot dreht, und es gibt auch Remoting und Rich Client auf der
Netbeans Application Platform (jetzt wird diese Funktionalität auf das Web übertragen). Hier in unserem Arsenal haben wir Standardspeicher für das Unternehmen und sogar unsere eigene Überwachung. Leider haben wir kein Tool gefunden, das den Betrieb des Lagers und wichtige Prozesse darauf gut visualisieren kann (wenn beispielsweise ein Abschnitt überlastet ist), und haben ein solches Tool selbst erstellt.
Wir verwenden Python als Hauptsprache für maschinelles Lernen: Wir erstellen Empfehlungssysteme und ordnen den Katalog, korrigieren Tippfehler in Suchanfragen und lösen auch andere Probleme in Verbindung mit Spark in einem Hadoop-Cluster (PySpark). Python hilft uns, die Berechnung interner Metriken und AB-Tests zu automatisieren.
Frontend und mobile Entwicklung
Das Frontend des Desktop-Onlineshops sowie der mobilen Websites ist in JavaScript geschrieben. Jetzt wechselt das Frontend schrittweise zur ES6-Spezifikation und erstellt entsprechende neue Projekte. Wir verwenden vue.js als Hauptframework, werden jedoch im Abschnitt "Tools" ausführlicher darauf eingehen.
Die Anwendungsentwicklung für mobile Plattformen ist eine separate Einheit im Unternehmen, die Backend-Gruppen sowie Android- und iOS-Anwendungen mit eigenen Technologie-Stacks und -Tools umfasst, die aufgrund von Plattformunterschieden bei weitem nicht immer in der gesamten Einheit vereinheitlicht werden können.
Seit zwei Jahren werden auf Kotlin alle neuen Android-Entwicklungen durchgeführt, mit denen wir präziseren und verständlicheren Code schreiben können. Zu den am häufigsten verwendeten Funktionen nennen unsere Entwickler: Smartcast, versiegelte Klassen, Erweiterungsfunktionen, typsichere Builder (DSL) und stdlib-Funktionen.
Auf Swift ist die iOS-Entwicklung im Gange, die Objective-C ersetzt hat.
Spezielle Sprachen
Der Aufgabenbereich von Lamoda beschränkt sich nicht nur auf die Entwicklung eines "Showcase" für verschiedene Plattformen. Wir haben eine Reihe von Sprachen, die nur in ihren Systemen verwendet werden, dort gut funktionieren, aber nicht in anderen Teilen der Infrastruktur implementiert werden:
- R - wird für Datenverarbeitungs- und Berichtsskripte im Rahmen von Business Intelligence (BI) verwendet. Es ist nicht in Produktion und wird nicht mehr für neue Aufgaben verwendet, aber wir haben immer noch eine Reihe solcher Skripte. Bei der Lösung von Problemen mit R haben wir festgestellt, dass diese Sprache nicht für hoch geladene Anwendungen geeignet ist. Bei neuen Aufgaben verwenden wir Python und andere Technologien, die mit R nicht kompatibel sind.
- Scala - wird vom Entwicklungsbüro in Vilnius zur Entwicklung eines Call-Center-Automatisierungssystems verwendet. Ursprünglich wurde dieses System in PHP geschrieben, aber während des Übergangs zu einer Microservice-Architektur wurden einige Komponenten in Scala neu geschrieben. Außerdem schreibt das Data Engineering-Team Spark-Jobs.
- TypeScript, das wir uns ansehen. Delivery ist bereits mit seiner Hilfe implementiert, und in Zukunft werden wir TypeScript + vue.js im Frontend verwenden.
- Lua wird verwendet, um nginx zu konfigurieren (über die nginx-API), in anderen Projekten ist dies nicht der Fall und wird es auch nie sein.
- Wir sind ein Modeunternehmen und folgen der Mode für funktionale Programmierung. Beispielsweise ist in Haskell ein Sortiergeräte-Emulator in einem unserer Lager geschrieben.
Datenverwaltung
DBMS, Datensuche und -analyse
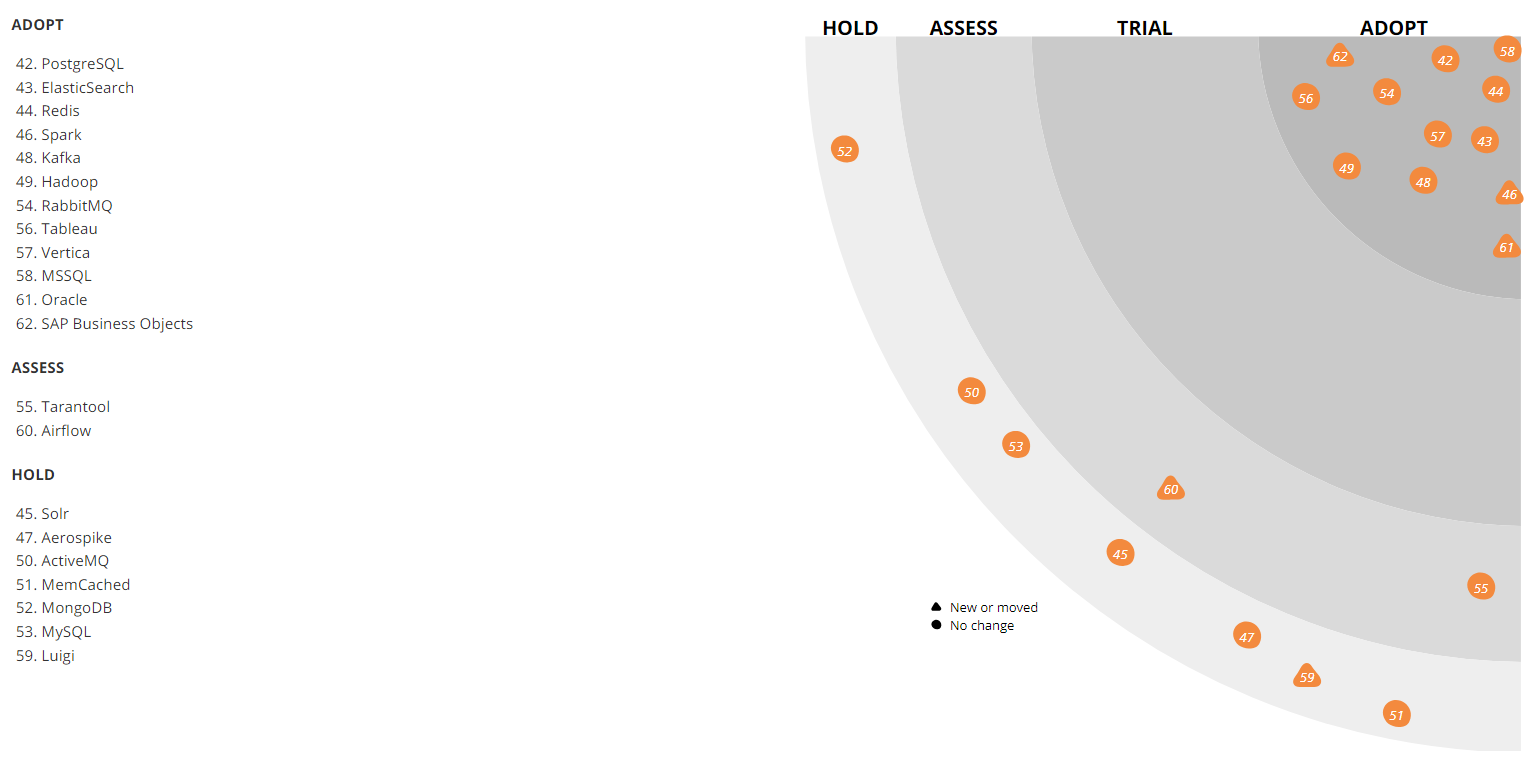
Wie viele der unterschiedlichsten Datenbanken, die wir in PostgreSQL implementiert haben, wird es überall dort verwendet, wo relationale Datenbanken zum Speichern eines Verzeichnisses benötigt werden. Es ist ziemlich einfach, Spezialisten für diese Technologie zu finden, außerdem stehen viele verschiedene Dienste zur Verfügung.
Natürlich ist PostgreSQL nicht das einzige DBMS, das in unserer IT-Infrastruktur zu finden ist. Auf einigen älteren Systemen wird beispielsweise MySQL verwendet, während WMS etwas MongoDB enthält. Für hohe Lasten und Skalierungen (unter Berücksichtigung des restlichen Technologie-Stacks) verwenden wir sie jedoch nicht für neue Projekte. Im Allgemeinen ist PostgreSQL unser Alles.
Der Aerospike ist auch auf dem Radar sichtbar. Wir haben es ziemlich aktiv genutzt, aber dann hat sich die Lizenzvereinbarung für das Produkt geändert, sodass sich herausstellte, dass die "unsere" Version etwas gekürzt wurde. Jetzt sahen wir ihn jedoch wieder an. Vielleicht werden wir unsere Einstellung zum Instrument überdenken und es aktiver nutzen. Jetzt wird Aerospike im Aggregationsservice für Ereignisse zum Anzeigen von Seiten und in der Arbeit des Benutzers mit dem Warenkorb sowie im Social-Proof-Service verwendet ("5 Personen haben dieses Produkt diese Woche zu den Favoriten hinzugefügt"). Jetzt geben wir noch steilere Empfehlungen dazu ab.
Apache Solr wird zur Suche nach Produktionsdaten verwendet. Parallel dazu verwenden wir auch ElasticSearch. Beide Lösungen sind Open Source, aber wenn wir früher, als wir gerade die Suche implementierten, Apache Solr bereits die dritte oder vierte Version hatten und aktiv entwickelten und ElasticSearch nicht einmal die erste stabile Version hatte - es war zu früh, um sie für die Produktion zu verwenden. Jetzt haben sich die Rollen geändert - es ist viel einfacher, Lösungen für ElasticSearch zu finden, und neue Leute sind zu uns gekommen, die sich gut darauf vorbereiten können. Im Produkt haben wir jedoch Solr, und wir werden zumindest bis zum Black Friday 2018 nicht zu einer anderen Lösung übergehen.
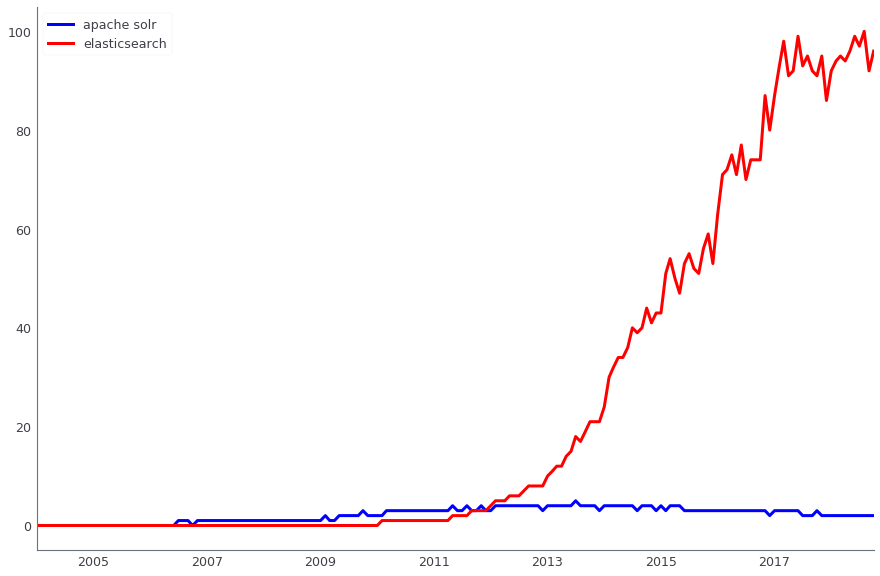 Vergleich der Dynamik von Suchanfragen Apache Solr (blau) und ElasticSearch (rot) gemäß Google Trends
Vergleich der Dynamik von Suchanfragen Apache Solr (blau) und ElasticSearch (rot) gemäß Google TrendsDie Datenanalyse erfolgt in mehreren Systemen, insbesondere verwenden wir Apache Hadoop aktiv. Gleichzeitig wird das Vertica-Spalten-DBMS zum Speichern von Data Marts (mit einem Gesamtvolumen von ca. 4 TB) verwendet. Über diese Vitrinen wird eine finanzielle, betriebliche und kommerzielle Berichterstattung aufgebaut. Für viele unserer ETL-Aufgaben haben wir zuvor Luigi verwendet, jetzt wechseln wir zu Apache Airflow. Wir verwenden Pentaho auch für die relationale Speicherung, in der etwa tausend reguläre ETL-Aufgaben ausgeführt werden.
Ein Teil der Analyse und Datenaufbereitung für andere Systeme wird in Spark durchgeführt. In einigen Ländern ist dies nicht nur ein Analysetool, sondern auch Teil unserer Lambda-Architektur.
Eine wichtige Rolle in der IT-Infrastruktur spielen ERP-Systeme: Microsoft Dynamics AX und 1C. Als DBMS wird Microsoft SQL Server verwendet. Und für die Berichterstellung sind ihre Komponenten wie Analysedienste und Berichterstellungsdienste.
Caching
Für das Caching verwenden wir Redis. Zuvor wurde diese Aufgabe von MemCached ausgeführt. Sie konnte nicht als Schlüsselwertspeicher mit einem regelmäßigen Speicherauszug auf der Festplatte verwendet werden. Daher haben wir sie abgebrochen.
Nachrichtenwarteschlangen
Als Eventbroker verwenden wir zwei Tools gleichzeitig - Apache Kafka und RabbitMQ.
Apache Kafka ist ein Tool, mit dem wir Zehntausende von Nachrichten in verschiedenen Systemen verarbeiten können, in denen Messaging benötigt wird. Für einige hoch ausgelastete Teile des Systems werden separate Kafka-Cluster bereitgestellt - beispielsweise für Benutzerereignisse oder die Protokollierung (wir hatten einen guten
Bericht über die Protokollierung bei Highload ++ 2017 ). Mit Kafka können Sie mit minimalem Eisenverbrauch 6000.000 Massenmeldungen pro Sekunde verarbeiten.
In internen Systemen verwenden wir RabbitMQ für verzögerte Aktionen.
Plattformen und Infrastruktur

Kontinuierliche Lieferung
Für die Bereitstellung wird Kubernetes verwendet, das das Nomad + Consul-Bundle von Hashicorp ersetzt. Der vorherige Stack funktionierte bei Hardware-Upgrades sehr schlecht. Als unser Ops-Team die physischen Server änderte, auf denen sich die Knoten drehten und die Container gespeichert waren, brach es regelmäßig ab und stürzte ab, ohne aufsteigen zu wollen. Zu diesem Zeitpunkt gab es keine stabile Version. Außerdem haben wir zu diesem Zeitpunkt nicht die neueste Version verwendet - 0.5.6, die noch aktualisiert werden musste. Das Upgrade auf die letzte Beta erforderte einige Arbeit. Daher wurde beschlossen, es aufzugeben und zu den populäreren Kubernetes zu wechseln.
Jetzt werden Nomad und Consul immer noch in der Qualitätssicherung eingesetzt, aber in Zukunft sollte er auch zu Kubernetes wechseln.
Um eine kontinuierliche Lieferung zu implementieren, werden Docker-Container verwendet, auf die wir vor zwei Jahren migriert sind. Für unsere hoch ausgelasteten Services (Warenkorb, Katalog, Website, Auftragsverwaltungssystem) ist es wichtig, schnell einige zusätzliche Container eines Service abzuholen, sodass wir überall Container haben. Und Docker ist eine der beliebtesten Containerisierungsmethoden, daher ist seine Präsenz auf dem Radar ziemlich logisch.
Als Build-Server und kontinuierliche Integration wird Bamboo in Verbindung mit Jira und Bitbucket (Standard-Stack) bereitgestellt.
Jenkins wird auch im Radar erwähnt. Wir haben mit ihm experimentiert, aber wir werden ihn nicht in neue Projekte hineinziehen. Es ist ein großartiges Werkzeug, aber es passt einfach nicht auf unseren Stapel, weil wir bereits Bambus haben.
Mit Bambus-Docker-Containern gesammelte werden im Repository unter der Kontrolle von Artifactory gespeichert.
Prozessmanagement und Balancing
Wir verwenden NGINX Plus, jedoch nicht im Hinblick auf das Balancing, da die Metriken für unsere Aufgaben nicht ausreichen. Er kann zum Beispiel nicht sagen, welche Anfrage am häufigsten weitergeleitet wird oder einfriert. Daher wird HAProxy verwendet, um die Last auszugleichen. In Verbindung mit nginx kann es schnell und effizient arbeiten, ohne den Prozessor und den Speicher zu laden. Darüber hinaus sind die von uns benötigten Metriken sofort einsatzbereit. HAproxy kann Statistiken nach Knoten, nach der Anzahl der Verbindungen im Moment, nach der Auslastung der Bandbreite und vielem mehr anzeigen.
UWSGI wird zum Ausführen synchroner Python-Anwendungen verwendet. Php-fpm wurde als Prozessmanager für alle PHP-Dienste verwendet.
Überwachung
Wir verwenden Prometheus, um Metriken von unseren Anwendungen und Hostmaschinen (virtuellen Maschinen) sowie der
Zeitreihendatenbank für die Anwendung zu erfassen. Wir sammeln Protokolle, dafür verwenden wir den ELK-Stack, als Warnsystem verwenden wir Icinga, das sowohl für ELK als auch für Prometheus konfiguriert ist. Sie sendet Benachrichtigungen per Post und SMS. Der 6911-Support erhält die gleichen Warnungen und beschließt, diensthabende Ingenieure anzuziehen.
Prometheus ist fast überall involviert, und dafür haben wir Bibliotheken für alle Sprachen, die es ermöglichen, nur ein paar Codezeilen zu verwenden, um seine Metriken mit dem Projekt zu verbinden. Beispielsweise ist eine Bibliothek für PHP
in Open Source verfügbar .
Grafana wird verwendet, um die Überwachungsergebnisse in Form von schönen Dashboards visuell anzuzeigen. Grundsätzlich sammeln wir alle Dashboards von Prometheus, obwohl manchmal auch andere Systeme als Quellen dienen können.
Um Fehler zu erkennen und automatisch zu aggregieren, verwenden wir Sentry, das in Jira integriert ist und es einfach macht, einen Task-Tracker für jedes Produktionsproblem zu starten. Er weiß, wie man den Fehler mit einem Backtrack und zusätzlichen Informationen erfasst, daher ist es praktisch, ein Debüt zu geben.
Statistiken zum Code der erstellten Pull-Anforderungen werden mit SonarQube erfasst.
Frameworks und Tools

Während der Entwicklung der Lamoda-IT-Infrastruktur haben wir mit fast drei Dutzend verschiedenen Tools experimentiert, sodass diese Kategorie die „umfangreichste“ auf unserem Radar ist. Bisher werden aktiv genutzt:
- Symfony 3.x und in jüngerer Zeit - Symfony 4.x - für die Entwicklung in PHP;
- Django und die Jinja Template Engine für die Python-Entwicklung. Jinja wird übrigens auch für die Konfiguration in Ansible verwendet;
- Flasche - für interne Dienste (zusammen mit Django), aber in der Produktion ziehen wir sie nicht;
- Frühling - in der Java-Entwicklung;
- Bootstrap - für eine Vielzahl interner Tools in der Webentwicklung (Admin-Panel, hausgemachte Dashboards usw.);
- jQuery - für js Entwicklung;
- OpenAPI (Swagger) - zur Dokumentation aller API-Dienste, einschließlich die für die obige Codegenerierung auf Go verwendet werden;
- Webpack - zum Packen von JS und Minimieren von CSS;
- Selen - zum Testen des Frontends;
- WireMock, JMeter, Allure und andere werden ebenfalls zum Testen verwendet.
- Ansible - für das Konfigurationsmanagement;
- Kibana - zur Visualisierung von Suchergebnissen in ElasticSearch.
Ich möchte die JavaScript-Entwicklung separat behandeln. Wir haben, wie viele, ein ganzes Feld von Experimenten.
Die Site für JavaScript verwendet ein selbst geschriebenes Framework. Am Frontend wurden im Rahmen von Aufgaben, die für das Geschäft nicht kritisch sind, Experimente mit verschiedenen Frameworks durchgeführt - Angular, ReactJS, vue.js. In diesem „Wettrüsten“ scheint vue.js, das ursprünglich im Automatisierungssystem des Content-Studios verwendet wurde, führend zu sein, und jetzt kommt es allmählich überall hin.Im trockenen Rückstand
, GO, PHP, Java, JavaScript, PostgreSQL, Docker Kubernetes.
, . , , . -, . , , , .