 Dieser Artikel ist Teil der Chronik der Softwarearchitektur , einer Reihe von Artikeln zur Softwarearchitektur. In ihnen schreibe ich darüber, was ich über Softwarearchitektur gelernt habe, was ich darüber denke und wie ich Wissen benutze. Der Inhalt dieses Artikels ist möglicherweise sinnvoller, wenn Sie die vorherigen Artikel in der Reihe lesen.
Dieser Artikel ist Teil der Chronik der Softwarearchitektur , einer Reihe von Artikeln zur Softwarearchitektur. In ihnen schreibe ich darüber, was ich über Softwarearchitektur gelernt habe, was ich darüber denke und wie ich Wissen benutze. Der Inhalt dieses Artikels ist möglicherweise sinnvoller, wenn Sie die vorherigen Artikel in der Reihe lesen.In einem
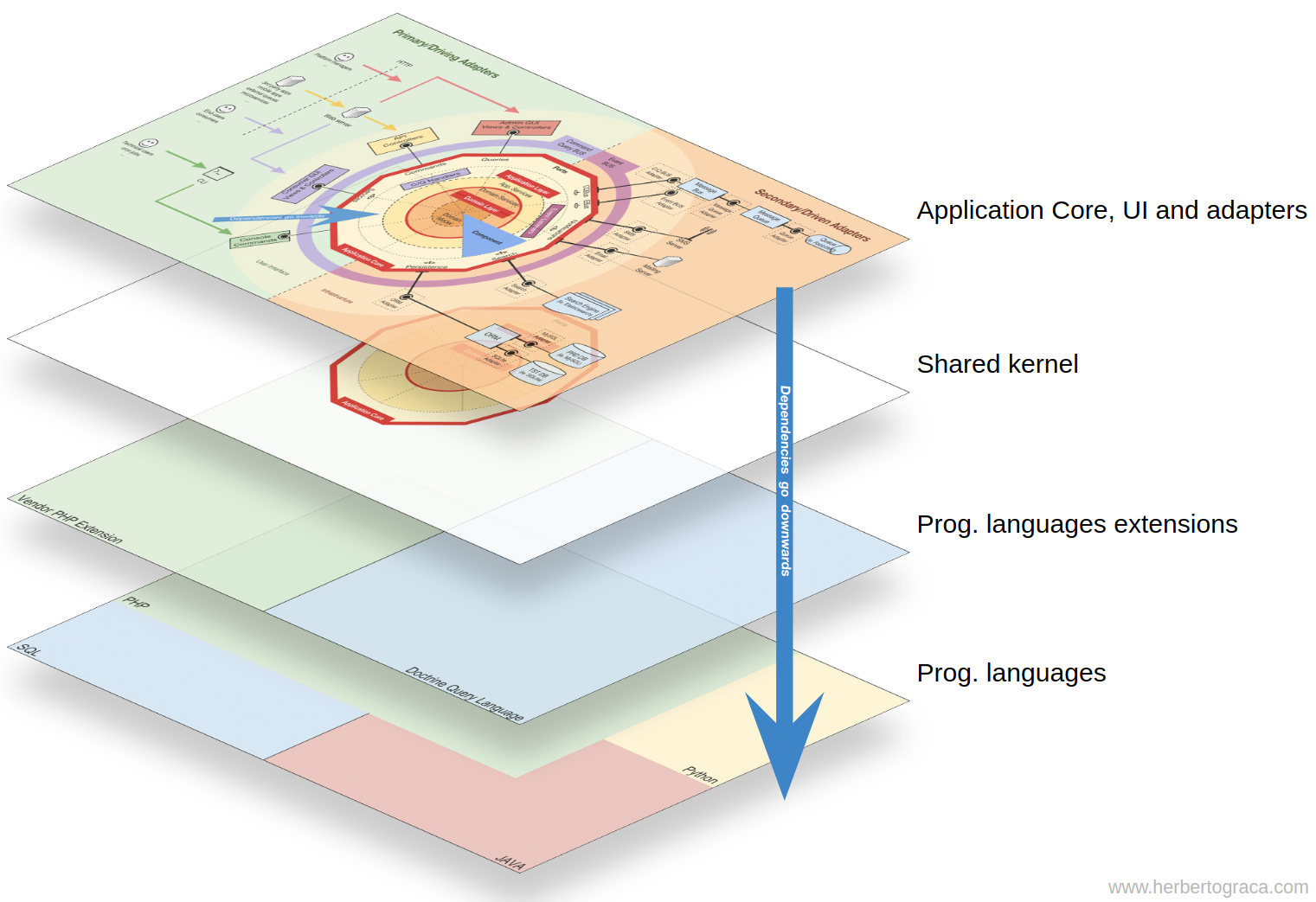
früheren Artikel der Reihe habe ich eine Konzeptkarte veröffentlicht, die die Beziehungen zwischen Codetypen zeigt.
Aber es schien mir immer, dass sich dort nicht alles sehr gut widerspiegelt, ich wusste einfach nicht, wie ich es besser machen sollte. Es geht um einen gemeinsamen Kern.
Darüber hinaus sind einige weitere Gedanken aufgetaucht, die ich in diesem kurzen Artikel skizzieren werde.
In der Infografik aus dem letzten Artikel dieser Reihe, genau in der Mitte des Diagramms, sehen wir den gemeinsamen Kern. Es scheint sich innerhalb der Domänenschicht und über den konischen Abschnitten zu befinden, bei denen es sich um begrenzte Kontexte handelt.

Trotz seiner Position meinte ich nicht, dass der gemeinsame Kern vom Rest des Codes abhängt oder dass der gemeinsame Kern eine weitere Schicht innerhalb der Domänenebene ist.
Was ist ein gemeinsamer Kern ?!
Der gemeinsame Kern, wie er von Eric Evans, dem
Vater von DDD, definiert wurde, ist Code, den das Entwicklungsteam auf mehrere begrenzte Kontexte aufteilt:
[...] eine Teilmenge des Domain-Modells, das die beiden Teams gemeinsam verwendet haben. Natürlich enthält der gemeinsame Kern zusammen mit dieser Teilmenge des Modells eine Teilmenge der Code- oder Datenbankarchitektur, die diesem Teil des Modells zugeordnet ist. Dieses eindeutig allgemeine Material hat einen besonderen Status und sollte nicht ohne Rücksprache mit einem anderen Team geändert werden.
- "Common Kernel" , DDD-Wiki von Ward Cunningham
Somit kann es sich um jede Art von Code handeln: Code auf Domänenebene, Code auf Anwendungsebene, Bibliotheken ... was auch immer.

Im Kontext unserer Konzeptkarte präsentiere ich sie jedoch als Teilmenge, als einen bestimmten Codetyp. In meiner Concept Map enthält der gemeinsame Kern Code für die Domänen- und Anwendungsebene, der in begrenzten Kontexten gemeinsam genutzt wird, sodass eine Kommunikation zwischen eingeschränkten Kontexten möglich ist.
Dies bedeutet beispielsweise, dass Ereignisse in einem oder mehreren eingeschränkten Kontexten ausgelöst und in anderen eingeschränkten Kontexten abgehört werden. Zusammen mit diesen Ereignissen müssen wir alle Datentypen gemeinsam nutzen, die von diesen Ereignissen verwendet werden, z. B. Entitätskennungen, Wertobjekte, Aufzählungen usw. Komplexe Objekte wie Entitäten sollten nicht direkt von Ereignissen verwendet werden, da sie schwierig sein können Serialisieren / Deserialisieren in / aus der Warteschlange, daher sollte der generische Code nicht weit verbreitet sein.
Wenn wir ein mehrsprachiges System von Mikrodiensten haben, sollte der gemeinsame Kern in JSON, XML, YAML usw. beschreibend sein, damit alle Mikrodienste ihn verstehen können.
Infolgedessen ist dieser gemeinsame Kern vollständig vom Rest der Codebasis und von den Komponenten getrennt. Das ist großartig, denn dann sind die Komponenten, obwohl sie mit dem gemeinsamen Kern verbunden sind, voneinander getrennt. Generischer Code wird explizit identifiziert und kann einfach in eine separate Bibliothek abgerufen werden.
Es ist auch sehr praktisch, wenn wir uns entscheiden, einen der begrenzten Kontexte in einen vom Monolithen getrennten Mikrodienst zu extrahieren. Wir wissen genau, was gemeinsam ist, und können den gemeinsamen Kern einfach in die Bibliothek extrahieren, die sowohl im Monolithen als auch im Mikroservice installiert wird.
Zusammenfassend hängt der Anwendungskern in meiner Konzeptübersicht von einem gemeinsamen Kern ab, der Code aus der Domänen- und Anwendungsebene enthält, die von begrenzten Kontexten gemeinsam genutzt werden.
Wenn Sprache nicht genug ist ...
Wir haben also den Anwendungscode mit allen konzentrischen Schichten, und der Anwendungskern hängt vom gemeinsamen Kern ab, der sich unter all diesem Code befindet.
Wir können auch sagen, dass all dieser Code von den verwendeten Programmiersprachen abhängt, aber es ist eine so offensichtliche Tatsache, dass wir dazu neigen, ihn vollständig zu ignorieren.
Es stellt sich jedoch die Frage: "Was ist, wenn die Sprachkonstrukte nicht ausreichen ?!" Nun, offensichtlich erstellen wir diese Sprachkonstrukte selbst und kompensieren so die Fehler der Sprache. Ich habe jedoch wichtige Anschlussfragen: „Wie und wo kann die Existenz dieses Codes gerechtfertigt werden? Wie kann man klar angeben, wann und wie man es benutzt? “
Was ich selbst gesehen und getan habe, war ein Paket namens Utils oder Commons, in dem sich dieser Code befindet. Aber am Ende wird der gesamte Code dort abgelegt, und wir wissen nicht, wo wir ihn ablegen sollen! Alle Arten von Code für unterschiedliche Zwecke und Benutzerfreundlichkeit (eingewickelt in einen direkt verwendeten Adapter ...) werden letztendlich dort abgelegt. Das Paket hat keine konzeptionelle Bedeutung, keine Kohärenz, keine Kohärenz, keine Klarheit, viele Unklarheiten.
Ich möchte die Utils and Commons-Pakete aufgeben!
Alle Pakete müssen konzeptionellen Zusammenhalt haben! Es sollte klar sein, wann und wie das Paket zu verwenden ist! Keine Mehrdeutigkeit!
Wenn eine Anwendung beispielsweise auf besondere Weise mit der Befehlszeilenschnittstelle interagiert, können Sie sie anstelle von 'Acme / Util / SpecialCli' im Namespace unter 'Acme / App / Infrastructure / Cli / SpecialCli' platzieren. Dies besagt, dass dieses Paket mit der CLI verknüpft ist und Teil der Acme App-App-Infrastruktur ist. Die Zugehörigkeit zur App-Infrastruktur besagt auch, dass der Anwendungskern einen Port enthält, dem dieses Paket entspricht.
Wenn wir dieses Paket als etwas betrachten, das der Sprache selbst fehlt, können wir es alternativ in den entsprechenden Namespace einfügen, z. B. 'Acme / PhpExtension / SpecialCli'. Dies zeigt, dass dieses Paket als Teil der Sprache selbst betrachtet werden sollte und daher sein Code wie jedes Sprachkonstrukt direkt in der Codebasis verwendet werden sollte. Wenn ein anderes Unternehmen von diesem Paket abhängig ist, kann es natürlich sinnvoll sein, sich nicht direkt darauf zu verlassen, aber es ist sicherer, einen Port / Adapter zu erstellen, damit er es gegen etwas anderes austauschen kann. Wenn wir das Paket besitzen, können wir es als Teil der Sprache betrachten, da das Risiko, es durch eine andere Alternative ersetzen zu müssen, nicht so groß ist. Kompromisse sind immer das Richtige.
Ein weiteres Beispiel dafür, was als Teil der Sprache betrachtet werden kann, sind die eindeutigen UUIDs in PHP. Es ist durchaus möglich, sie sich außerhalb der Sprache vorzustellen, da jedes Mal, wenn es eine neue Version gibt, dies ein Albtraum mit Codeunterstützung ist. Dies ist jedoch ein sehr allgemeines Konzept, ein umfassendes und ausreichend konsistentes Konzept, um Teil der Sprache zu sein.
Warum also nicht eine UUID-Implementierung erstellen und wie ein Teil von PHP selbst verwenden? Wie verwenden wir ein DateTime-Objekt ?! Während wir die Implementierung kontrollieren, sehe ich keine Mängel.
Was ist mit der Doctrine Query Language (DQL)? (Doctrine ist der Hibernate-Port in PHP) Können wir DQL so betrachten, als wäre es SQL, Elasticsearch QL oder Mongo QL?
Fazit
Auf Makroebene sehe ich also vier grundlegende Codetypen, und ich denke, es ist wichtig, sie in der Organisation der Codebasis klar darzustellen, damit nicht viel Schmutz entsteht.
Für mich ist die unbestreitbare Wahrheit, dass
Architektur immer existiert, die einzige Frage ist, ob wir sie kontrollieren oder nicht ?!Lassen Sie uns
den Code also ganz oder teilweise
in Übereinstimmung mit der Architektur auf einer Konzeptkarte organisieren - meiner oder einer anderen. Die Hauptsache ist, den Code so zu organisieren, dass das Projekt durch die Struktur und Organisation des Codes explizit über seine Architektur berichtet.