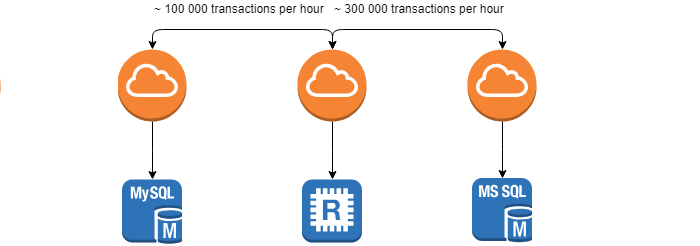
Bei der Entwicklung und Verwendung verteilter Systeme stehen wir vor der Aufgabe, die Integrität und Identität von Daten zwischen Systemen zu überwachen - der Aufgabe der Abstimmung .
Die vom Kunden festgelegten Anforderungen sind die Mindestzeit für diesen Vorgang. Je früher die Diskrepanz festgestellt wird, desto einfacher ist es, die Folgen zu beseitigen. Die Aufgabe wird erheblich dadurch erschwert, dass die Systeme ständig in Bewegung sind (~ 100.000 Transaktionen pro Stunde) und 0% der Abweichungen nicht erreicht werden können.
Hauptidee
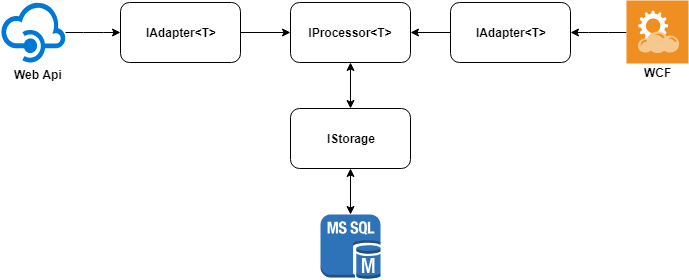
Die Hauptidee der Lösung kann im folgenden Diagramm beschrieben werden.
Wir betrachten jedes der Elemente separat.
Datenadapter
Jedes der Systeme ist für seinen eigenen Themenbereich ausgelegt. Infolgedessen können die Beschreibungen von Objekten erheblich variieren. Wir müssen nur einen bestimmten Satz von Feldern aus diesen Objekten vergleichen.
Um den Vergleich zu vereinfachen, bringen wir die Objekte in ein einziges Format, indem wir für jede Datenquelle einen Adapter schreiben. Wenn Sie die Objekte in ein einziges Format bringen, kann sich der Speicherbedarf erheblich verringern, da nur die zu vergleichenden Felder gespeichert werden.
Unter der Haube kann der Adapter eine beliebige Datenquelle haben: HttpClient , SqlClient , DynamoDbClient usw.
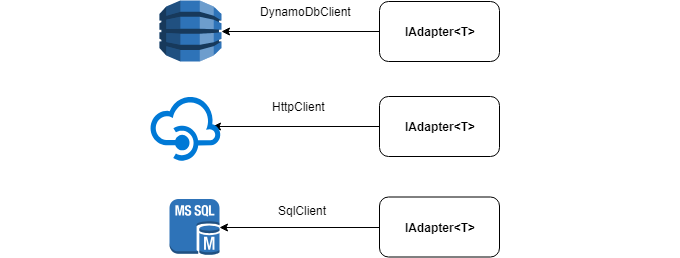
Das Folgende ist die IAdapter- Schnittstelle, die Sie implementieren möchten:
public interface IAdapter<T> where T : IModel { int Id { get; } Task<IEnumerable<T>> GetItemsAsync(ISearchModel searchModel); } public interface IModel { Guid Id { get; } int GetHash(); }
Lagerung
Die Datenabstimmung kann erst beginnen, nachdem alle Daten gelesen wurden, da die Adapter sie in zufälliger Reihenfolge zurückgeben können.
In diesem Fall reicht die RAM-Größe möglicherweise nicht aus, insbesondere wenn Sie mehrere Abstimmungen gleichzeitig ausführen, was auf große Zeitintervalle hinweist.
Betrachten Sie die IStorage- Schnittstelle
public interface IStorage { int SourceAdapterId { get; } int TargetAdapterId { get; } int MaxWriteCapacity { get; } Task InitializeAsync(); Task<int> WriteItemsAsync(IEnumerable<IModel> items, int adapterId); Task<IEnumerable<IResultModel>> GetDifferenceAsync(ISearchDifferenceModel model); } public interface ISearchDifferenceModel { int Offset { get; } int Limit { get; } }
Repository. MS SQL-basierte Implementierung
Wir haben IStorage mit MS SQL implementiert, wodurch wir den Vergleich vollständig auf der Db-Serverseite durchführen konnten.
Um die angeforderten Werte zu speichern, erstellen Sie einfach die folgende Tabelle:
CREATE TABLE [dbo].[Storage_1540747667] ( [id] UNIQUEIDENTIFIER NOT NULL, [adapterid] INT NOT NULL, [qty] INT NOT NULL, [price] INT NOT NULL, CONSTRAINT [PK_Storage_1540747667] PRIMARY KEY ([id], [adapterid]) )
Jeder Datensatz enthält Systemfelder ( [id] , [adapterId] ) und Vergleichsfelder ( [Menge] , [Preis] ). Ein paar Worte zu Systemfeldern:
[id] - eindeutige Kennung des Eintrags, die in beiden Systemen gleich ist
[adapterId] - Kennung des Adapters, über den der Datensatz empfangen wurde
Da Abstimmungsprozesse parallel gestartet werden können und sich überschneidende Intervalle haben, erstellen wir für jeden eine Tabelle mit einem eindeutigen Namen. Wenn die Abstimmung erfolgreich war, wird diese Tabelle gelöscht, andernfalls wird ein Bericht mit einer Liste von Datensätzen gesendet, in denen es Abweichungen gibt.
Repository. Wertevergleich
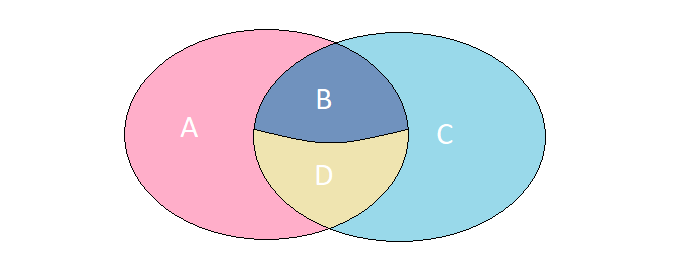
Stellen Sie sich vor, wir haben zwei Mengen, deren Elemente eine absolut identische Menge von Feldern haben. Betrachten Sie 4 mögliche Fälle ihrer Überschneidung:
A. A. Elemente sind nur im linken Satz vorhanden.
B. B. Elemente sind in beiden Mengen vorhanden, haben jedoch unterschiedliche Bedeutungen.
S. Elemente sind nur im richtigen Satz vorhanden.
D. Elemente sind in beiden Mengen vorhanden und haben dieselbe Bedeutung.
In einem bestimmten Problem müssen wir die in den Fällen A, B, C beschriebenen Elemente finden . Sie können das gewünschte Ergebnis in einer Abfrage an MS SQL über FULL OUTER JOIN erhalten :
select [s1].[id], [s1].[adapterid] from [dbo].[Storage_1540758006] as [s1] full outer join [dbo].[Storage_1540758006] as [s2] on [s2].[id] = [s1].[id] and [s2].[adapterid] != [s1].[adapterid] and [s2].[qty] = [s1].[qty] and [s2].[price] = [s1].[price] where [s2].[id] is nul
Die Ausgabe dieser Anforderung kann 4 Arten von Datensätzen enthalten, die die ursprünglichen Anforderungen erfüllen
| # | id | Adapter-ID | Kommentar |
|---|
| 1 | guid1 | adp1 | Der Datensatz ist nur im linken Satz vorhanden. Fall A. |
| 2 | guid2 | adp2 | Der Datensatz ist nur im richtigen Satz vorhanden. Fall C. |
| 3 | guid3 | adp1 | Datensätze sind in beiden Sätzen vorhanden, haben jedoch unterschiedliche Bedeutungen. Fall B. |
| 4 | guid3 | adp2 | Datensätze sind in beiden Sätzen vorhanden, haben jedoch unterschiedliche Bedeutungen. Fall B. |
Repository. Hashing
Durch Hashing von verglichenen Objekten können Sie die Kosten für Schreib- und Vergleichsvorgänge erheblich senken. Besonders wenn es darum geht, Dutzende von Feldern zu vergleichen.
Es stellte sich heraus, dass dies die universellste Methode zum Hashing einer serialisierten Darstellung eines Objekts ist.
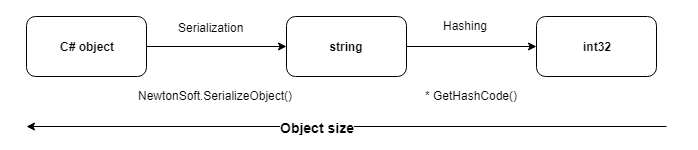
1. Für das Hashing verwenden wir die Standardmethode GetHashCode () , die int32 zurückgibt und für alle primitiven Typen überschrieben wird.
2. In diesem Fall ist die Wahrscheinlichkeit von Kollisionen unwahrscheinlich, da nur Datensätze mit denselben Kennungen verglichen werden.
Betrachten Sie die in dieser Optimierung verwendete Tabellenstruktur:
CREATE TABLE [dbo].[Storage_1540758006] ( [id] UNIQUEIDENTIFIER NOT NULL, [adapterid] INT NOT NULL, [hash] INT NOT NULL, CONSTRAINT [PK_Storage_1540758006] PRIMARY KEY ([id], [adapterid], [hash]) )
Der Vorteil einer solchen Struktur sind die konstanten Kosten für das Speichern eines Datensatzes (24 Byte), die nicht von der Anzahl der verglichenen Felder abhängen.
Natürlich ändert sich das Vergleichsverfahren und wird viel einfacher.
select [s1].[id], [s1].[adapterid] from [dbo].[Storage_1540758006] as [s1] full outer join [dbo].[Storage_1540758006] as [s2] on [s2].[id] = [s1].[id] and [s2].[adapterid] != [s1].[adapterid] and [s2].[hash] = [s1].[hash] where [s2].[id] is null
CPU
In diesem Abschnitt werden wir über eine Klasse sprechen, die die gesamte Geschäftslogik der Versöhnung enthält, nämlich:
1. Paralleles Lesen von Daten von Adaptern
2. Daten-Hashing
3. gepufferte Aufzeichnung von Werten in der Datenbank
4. Lieferung der Ergebnisse
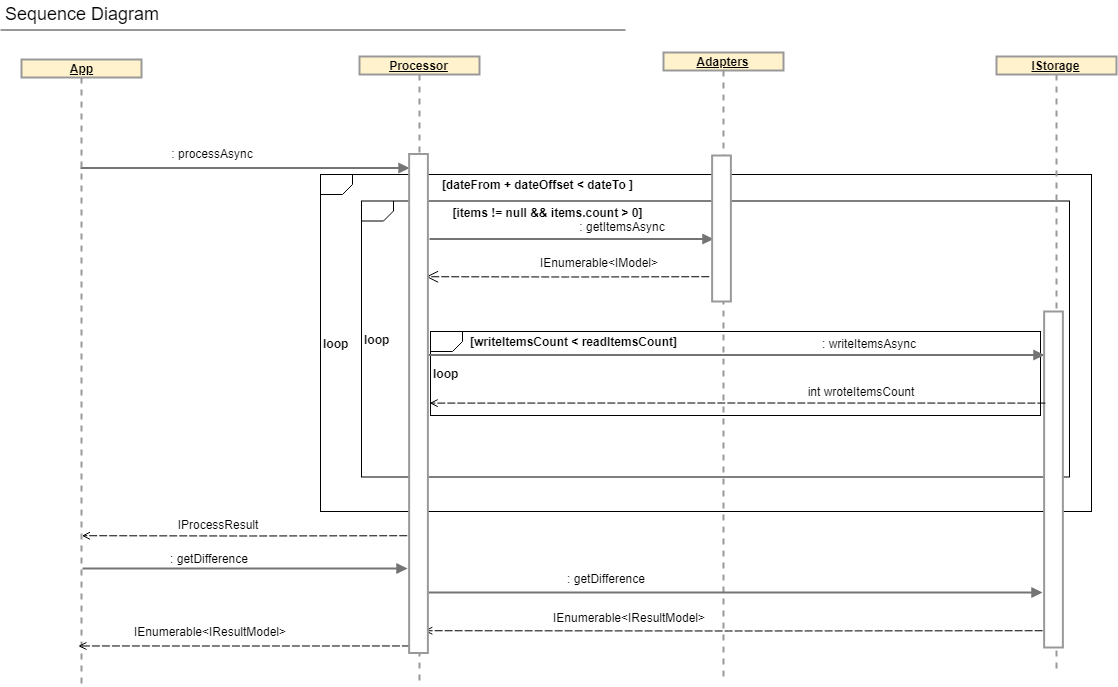
Eine umfassendere Beschreibung des Abstimmungsprozesses erhalten Sie anhand des Sequenzdiagramms und der IProzessor- Schnittstelle .
public interface IProcessor<T> where T : IModel { IAdapter<T> SourceAdapter { get; } IAdapter<T> TargetAdapter { get; } IStorage Storage { get; } Task<IProcessResult> ProcessAsync(); Task<IEnumerable<IResultModel>> GetDifferenceAsync(ISearchDifferenceModel model); }
Danksagung
Vielen Dank an meine Kollegen von der MySale Group für das Feedback: AntonStrakhov , Nesstory , Barlog_5 , Kostya Krivtsun und VeterManve - der Autor der Idee.