Hinweis perev. A: Der Originalartikel wurde von Vertretern von BlueData verfasst, einem Unternehmen, das von Mitarbeitern von VMware gegründet wurde. Sie ist darauf spezialisiert, die Bereitstellung von Lösungen für Big Data-Analysen und maschinelles Lernen in verschiedenen Umgebungen einfacher (einfacher, schneller, billiger) zu machen. Die jüngste Initiative des Unternehmens namens BlueK8s , bei der die Autoren eine Galaxie von Open Source-Tools zusammenstellen möchten, "um statusbehaftete Anwendungen bereitzustellen und diese in Kubernetes zu verwalten", soll ebenfalls dazu beitragen. Der Artikel ist dem ersten von ihnen gewidmet - KubeDirector, der laut den Autoren einem Enthusiasten im Bereich Big Data, der keine spezielle Ausbildung in Kubernetes hat, hilft, Anwendungen wie Spark, Cassandra oder Hadoop in K8s bereitzustellen. Eine kurze Anleitung dazu finden Sie im Artikel. Beachten Sie jedoch, dass das Projekt einen frühen Bereitschaftsstatus hat - Pre-Alpha.
KubeDirector ist ein Open Source-Projekt, das den Start von Clustern aus komplexen skalierbaren Stateful-Anwendungen in Kubernetes vereinfachen soll. KubeDirector wird mithilfe des CRD-Frameworks (
Custom Resource Definition ) implementiert, verwendet die nativen Kubernetes-API-Erweiterungsfunktionen und stützt sich auf deren Philosophie. Dieser Ansatz bietet eine transparente Integration in das Benutzer- und Ressourcenmanagement in Kubernetes sowie in vorhandene Clients und Dienstprogramme.
Das kürzlich angekündigte KubeDirector-Projekt ist Teil einer größeren Open Source-Initiative für Kubernetes namens BlueK8s. Jetzt freue ich mich, die Verfügbarkeit von frühem (Pre-Alpha)
KubeDirector- Code bekannt zu geben. Dieser Beitrag zeigt, wie es funktioniert.
KubeDirector bietet folgende Funktionen:
- Sie müssen den Code nicht ändern, um andere Stateful-Anwendungen als Cloud-native von Kubernetes auszuführen. Mit anderen Worten, es ist nicht erforderlich, vorhandene Anwendungen zu zerlegen, um sie an das Mikroservice-Architekturmuster anzupassen.
- Native Unterstützung zum Speichern von anwendungsspezifischer Konfiguration und Status.
- Anwendungsunabhängiges Bereitstellungsmuster, das die Startzeit neuer statusbehafteter Anwendungen in Kubernetes minimiert.
Mit KubeDirector können Datenwissenschaftler, die an verteilte Anwendungen mit intensiver Datenverarbeitung wie Hadoop, Spark, Cassandra, TensorFlow, Caffe2 usw. gewöhnt sind, diese in Kubernetes mit minimalem Lernaufwand ausführen, ohne Code auf Go schreiben zu müssen. Wenn diese Anwendungen von KubeDirector gesteuert werden, werden sie durch einfache Metadaten und die zugehörigen Konfigurationen definiert. Anwendungsmetadaten sind als
KubeDirectorApp Ressource definiert.
Um die Komponenten von KubeDirector zu verstehen, klonen Sie das Repository auf
GitHub mit einem Befehl wie dem folgenden:
git clone http://<userid>@github.com/bluek8s/kubedirector.
Die
KubeDirectorApp Definition für die Spark 2.2.1-Anwendung befindet sich in der
kubedirector/deploy/example_catalog/cr-app-spark221e2.json :
~> cat kubedirector/deploy/example_catalog/cr-app-spark221e2.json
{ "apiVersion": "kubedirector.bluedata.io/v1alpha1", "kind": "KubeDirectorApp", "metadata": { "name" : "spark221e2" }, "spec" : { "systemctlMounts": true, "config": { "node_services": [ { "service_ids": [ "ssh", "spark", "spark_master", "spark_worker" ], …
Die Anwendungsclusterkonfiguration ist als
KubeDirectorCluster Ressource definiert.
Die
KubeDirectorCluster Definition für das Spark 2.2.1-Clusterbeispiel ist unter
kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yaml :
~> cat kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yaml
apiVersion: "kubedirector.bluedata.io/v1alpha1" kind: "KubeDirectorCluster" metadata: name: "spark221e2" spec: app: spark221e2 roles: - name: controller replicas: 1 resources: requests: memory: "4Gi" cpu: "2" limits: memory: "4Gi" cpu: "2" - name: worker replicas: 2 resources: requests: memory: "4Gi" cpu: "2" limits: memory: "4Gi" cpu: "2" - name: jupyter …
Starten Sie Spark auf Kubernetes mit KubeDirector
Das Starten von Spark-Clustern in Kubernetes mit KubeDirector ist einfach.
kubectl version mit dem Befehl
kubectl version sicher, dass Kubernetes ausgeführt wird (Version 1.9 oder höher):
~> kubectl version Client Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T18:02:47Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"} Server Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T17:53:03Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"}
Stellen Sie den KubeDirector-Dienst bereit und
KubeDirectorApp Ressourcendefinitionen mithilfe der folgenden Befehle:
cd kubedirector make deploy
Infolgedessen wird es unter mit KubeDirector gestartet:
~> kubectl get pods NAME READY STATUS RESTARTS AGE kubedirector-58cf59869-qd9hb 1/1 Running 0 1m
Zeigen Sie die Liste der in KubeDirector installierten Anwendungen an, indem Sie
kubectl get KubeDirectorApp :
~> kubectl get KubeDirectorApp NAME AGE cassandra311 30m spark211up 30m spark221e2 30m
Jetzt können Sie den Spark 2.2.1-Cluster mit der Beispieldatei für
KubeDirectorCluster und dem
kubectl create -f deploy/example_clusters/cr-cluster-spark211up.yaml . Überprüfen Sie, ob es gestartet wurde:
~> kubectl get pods NAME READY STATUS RESTARTS AGE kubedirector-58cf59869-djdwl 1/1 Running 0 19m spark221e2-controller-zbg4d-0 1/1 Running 0 23m spark221e2-jupyter-2km7q-0 1/1 Running 0 23m spark221e2-worker-4gzbz-0 1/1 Running 0 23m spark221e2-worker-4gzbz-1 1/1 Running 0 23m
Spark erschien auch in der Liste der laufenden Dienste:
~> kubectl get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 21s svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 20s svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 20s svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 20s svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 20s
Wenn Sie in Ihrem Browser auf Port 31533 zugreifen, wird die Spark Master-Benutzeroberfläche angezeigt:
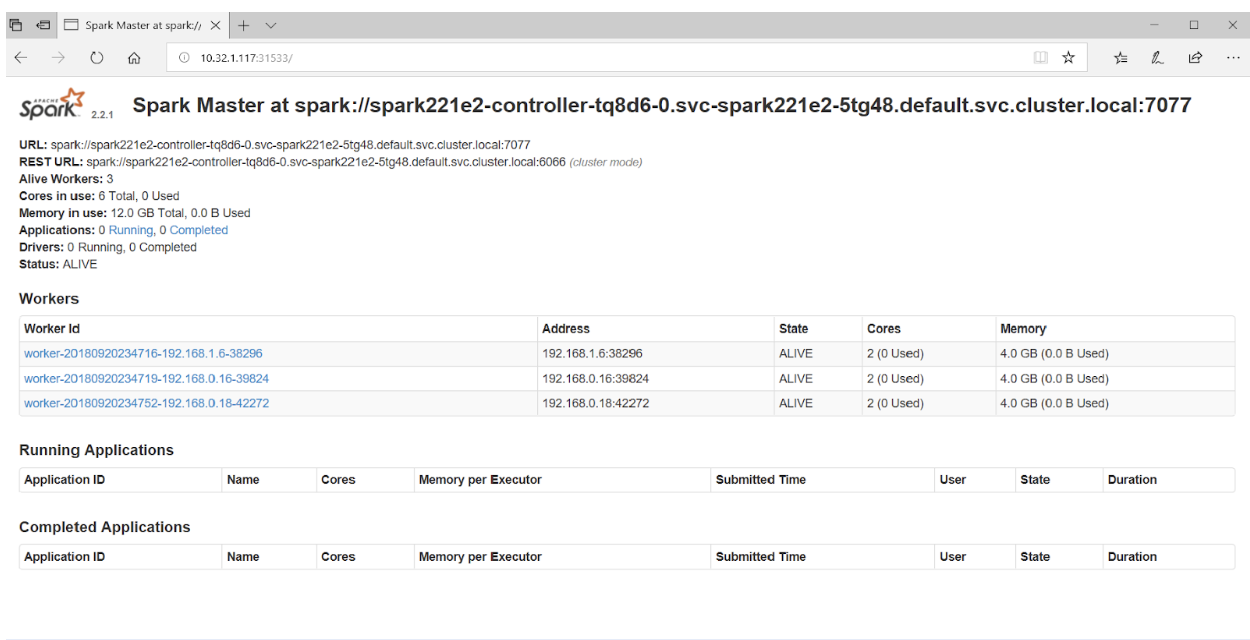
Das ist alles! Im obigen Beispiel haben wir neben dem Spark-Cluster auch das
Jupyter-Notizbuch bereitgestellt.
Um eine andere Anwendung (z. B. Cassandra) zu starten, geben Sie einfach eine andere Datei mit
KubeDirectorApp :
kubectl create -f deploy/example_clusters/cr-cluster-cassandra311.yaml
Stellen Sie sicher, dass der Cassandra-Cluster gestartet wurde:
~> kubectl get pods NAME READY STATUS RESTARTS AGE cassandra311-seed-v24r6-0 1/1 Running 0 1m cassandra311-seed-v24r6-1 1/1 Running 0 1m cassandra311-worker-rqrhl-0 1/1 Running 0 1m cassandra311-worker-rqrhl-1 1/1 Running 0 1m kubedirector-58cf59869-djdwl 1/1 Running 0 1d spark221e2-controller-tq8d6-0 1/1 Running 0 22m spark221e2-jupyter-6989v-0 1/1 Running 0 22m spark221e2-worker-d9892-0 1/1 Running 0 22m spark221e2-worker-d9892-1 1/1 Running 0 22m
Kubernetes führt jetzt den Spark-Cluster (mit Jupyter Notebook) und den Cassandra-Cluster aus. Die Liste der Dienste kann mit dem Befehl
kubectl get service :
~> kubectl get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d svc-cassandra311-seed-v24r6-0 NodePort 10.96.94.204 <none> 22:31131/TCP,9042:30739/TCP 3m svc-cassandra311-seed-v24r6-1 NodePort 10.106.144.52 <none> 22:30373/TCP,9042:32662/TCP 3m svc-cassandra311-vhh29 ClusterIP None <none> 8888/TCP 3m svc-cassandra311-worker-rqrhl-0 NodePort 10.109.61.194 <none> 22:31832/TCP,9042:31962/TCP 3m svc-cassandra311-worker-rqrhl-1 NodePort 10.97.147.131 <none> 22:31454/TCP,9042:31170/TCP 3m svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 24m svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 24m svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 24m svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 24m svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 24m
PS vom Übersetzer
Wenn Sie sich für das KubeDirector-Projekt interessieren, sollten Sie auch auf
dessen Wiki achten. Leider war es nicht möglich, eine öffentliche Roadmap zu finden.
Probleme auf GitHub geben jedoch Aufschluss über den Fortschritt des Projekts und die Ansichten der Hauptentwickler. Für diejenigen, die sich für KubeDirector interessieren, bieten die Autoren außerdem Links zu
Slack Chat und
Twitter .
Lesen Sie auch in unserem Blog: