Das erste, was uns begegnet, wenn wir über proaktive Optimierung sprechen, ist, dass nicht bekannt ist, was optimiert werden muss. "Tu das, ich weiß nicht was."
- Es gibt keinen klassischen Algorithmus.
- Das Problem ist noch nicht aufgetreten (unbekannt), und man kann nur raten, wo es sein könnte.
- Wir müssen einige potenzielle Schwachstellen im System finden.
- Versuchen Sie, die Abfrageleistung an diesen Stellen zu optimieren.
Die Hauptziele einer proaktiven Optimierung
Die Hauptaufgaben der proaktiven Optimierung unterscheiden sich von den Aufgaben der reaktiven Optimierung und lauten wie folgt:
- Engpässe in der Datenbank beseitigen;
- Verringerung des Ressourcenverbrauchs der Datenbank.
Der letzte Moment ist der grundlegendste. Bei der reaktiven Optimierung haben wir nicht die Aufgabe, den Ressourcenverbrauch insgesamt zu reduzieren, sondern nur die Reaktionszeit der Funktionalität auf akzeptable Grenzen zu bringen.
Wenn Sie mit Kampfservern arbeiten, haben Sie eine gute Vorstellung davon, was Leistungsvorfälle bedeuten. Sie müssen alles beenden und das Problem schnell lösen. RNKO Payment Center LLC arbeitet mit vielen Agenten zusammen, und es ist sehr wichtig, dass sie so wenig Probleme wie möglich haben. Alexander Makarov von HighLoad ++ Siberia erklärte, was getan wurde, um die Anzahl der Leistungsvorfälle erheblich zu reduzieren. Proaktive Optimierung kam zur Rettung. Und warum und wie es auf einem Kampfserver produziert wird, lesen Sie unten.
 Über den Sprecher:
Über den Sprecher: Alexander Makarov (
AL_IG_Makarov ), Leitender Administrator der Oracle-Datenbank, RNKO Payment Center LLC. Trotz der Position gibt es nur sehr wenig Verwaltung als solche. Die Hauptaufgaben beziehen sich auf die Wartung des Komplexes und seine Entwicklung, insbesondere auf die Lösung von Leistungsproblemen.
Ist die Optimierung einer Kampfdatenbank proaktiv?
Zunächst werden wir uns mit den Begriffen befassen, die in diesem Bericht als "proaktive Leistungsoptimierung" bezeichnet werden. Manchmal können Sie den Standpunkt vertreten, dass eine proaktive Optimierung darin besteht, dass die Analyse von Problembereichen bereits vor dem Start der Anwendung durchgeführt wird. Beispielsweise stellen wir fest, dass einige Abfragen nicht optimal funktionieren, da nicht genügend Index vorhanden ist oder die Abfrage einen ineffizienten Algorithmus verwendet und diese Arbeit auf Testservern ausgeführt wird.
Trotzdem haben wir vom RNCO dieses Projekt
auf Kampfservern durchgeführt. Oft hörte ich: „Wie so? Du machst es auf einem Kampfserver - das heißt, es ist keine proaktive Leistungsoptimierung! “ Hier müssen wir an den Ansatz erinnern, der in ITIL gepflegt wird. Aus ITIL-Sicht haben wir:
- Leistungsvorfälle sind das, was bereits passiert ist;
- die Maßnahmen, die wir ergreifen, um das Auftreten von Leistungsstörungen zu verhindern.
In diesem Sinne sind unsere Handlungen proaktiv. Trotz der Tatsache, dass wir das Problem auf einem Kampfserver lösen, ist das Problem selbst noch nicht aufgetreten: Der Vorfall ist nicht aufgetreten, wir sind nicht ausgeführt worden und haben nicht versucht, dieses Problem in kurzer Zeit zu lösen.
In diesem Bericht wird Proaktivität als
Proaktivität im Sinne von ITIL verstanden . Wir lösen das Problem, bevor ein Leistungsvorfall auftritt.
Bezugspunkt
Das RNKO "Payment Center" bedient zwei große Systeme:
- RBS-Retail Bank;
- CFT Bank.
Die Art der Last auf diesen Systemen ist gemischt (DSS + OLTP): Es gibt etwas, das sehr schnell funktioniert, es gibt Berichte, es gibt mittlere Lasten.
Wir sind mit der Tatsache konfrontiert, dass nicht sehr oft, aber mit einer bestimmten Häufigkeit, Leistungsvorfälle auftraten. Diejenigen, die mit Kampfservern arbeiten, stellen sich vor, was es ist. Dies bedeutet, dass Sie alles beenden und das Problem schnell lösen müssen, da der Client zu diesem Zeitpunkt den Service nicht erhalten kann, etwas entweder überhaupt nicht oder nur sehr langsam funktioniert.
Da viele Agenten und Kunden an unsere Organisation gebunden sind, ist dies für uns sehr wichtig. Wenn wir Leistungsvorfälle nicht schnell lösen können, leiden unsere Kunden auf die eine oder andere Weise. Zum Beispiel können sie keine Karte auffüllen oder eine Überweisung vornehmen. Daher haben wir uns gefragt, was getan werden kann, um selbst diese seltenen Leistungsvorfälle zu beseitigen. In einem Modus zu arbeiten, in dem Sie alles fallen lassen und ein Problem lösen müssen - das ist nicht ganz richtig. Wir verwenden Sprints und erstellen einen Sprint-Arbeitsplan. Das Vorhandensein von Leistungsstörungen ist auch eine Abweichung vom Arbeitsplan.
Damit muss etwas getan werden!
Optimierungsansätze
Wir haben über die Technologie der proaktiven Optimierung nachgedacht und sie verstanden. Bevor ich jedoch über proaktive Optimierung spreche, muss ich einige Worte zur klassischen reaktiven Optimierung sagen.
Reaktive Optimierung
Das Szenario ist einfach: Es gibt einen Kampfserver, auf dem etwas passiert ist: Sie haben einen Bericht gestartet, Clients erhalten Anweisungen, zu diesem Zeitpunkt gibt es laufende Aktivitäten in der Datenbank, und plötzlich hat sich jemand entschlossen, ein umfangreiches Verzeichnis zu aktualisieren. Das System beginnt langsamer zu werden. In diesem Moment kommt der Kunde und sagt: "Ich kann dies oder das nicht tun" - wir müssen einen Grund finden, warum er dies nicht tun kann.
Klassischer Aktionsalgorithmus:- Reproduzieren Sie das Problem.
- Suchen Sie die Problemstelle.
- Optimieren Sie den Problemort.
Im Rahmen des reaktiven Ansatzes besteht die Hauptaufgabe nicht darin, die Grundursache selbst zu finden und zu beseitigen, sondern das System normal funktionieren zu lassen. Die Beseitigung der Grundursache kann später behandelt werden. Die Hauptsache ist, den Server schnell wiederherzustellen, damit der Client den Dienst empfangen kann.
Die Hauptziele der reaktiven Optimierung
Bei der reaktiven Optimierung können zwei Hauptziele unterschieden werden:
1.
Verkürzung der Reaktionszeit .
Eine Aktion, z. B. das Empfangen eines Berichts, einer Anweisung oder einer Transaktion, muss für eine bestimmte Zeit ausgeführt werden. Es muss sichergestellt werden, dass der Zeitpunkt des Empfangs des Dienstes an die für den Kunden akzeptablen Grenzen zurückkehrt. Vielleicht arbeitet der Service etwas langsamer als gewöhnlich, aber für den Kunden ist dies akzeptabel. Dann glauben wir, dass der Leistungsvorfall beseitigt wurde, und beginnen, an der Grundursache zu arbeiten.
2.
Erhöhung der Anzahl der verarbeiteten Objekte pro Zeiteinheit während der Stapelverarbeitung .
Während der Stapelverarbeitung von Transaktionen muss die Verarbeitungszeit eines Objekts aus dem Paket reduziert werden.
Vorteile eines reaktiven Ansatzes:●
Eine Vielzahl von Werkzeugen und Techniken ist das Hauptvorteil eines reaktiven Ansatzes.
Wir können die Überwachungstools verwenden, um das Problem direkt zu verstehen: Es ist nicht genügend CPU, Threads, Speicher vorhanden oder das Festplattensystem ist ausgerutscht, oder die Protokolle werden langsam verarbeitet. Es gibt viele Tools und Techniken, um das aktuelle Leistungsproblem in der Oracle-Datenbank zu untersuchen.
● Die
gewünschte Reaktionszeit ist ein weiteres Plus.
Während dieser Arbeit bringen wir die Situation auf eine akzeptable Reaktionszeit, dh wir versuchen nicht, sie auf den Mindestwert zu reduzieren, sondern erreichen einen bestimmten Wert und beenden diese Aktion, weil wir glauben, akzeptable Grenzen erreicht zu haben.
Nachteile des reaktiven Ansatzes:- Leistungsvorfälle bleiben bestehen - dies ist das größte Minus des reaktiven Ansatzes, da wir die Grundursache nicht immer erreichen können. Sie hätte irgendwo fern bleiben und irgendwo tiefer liegen können, obwohl wir eine akzeptable Leistung erzielt hatten.
Und wie geht man mit Leistungsvorfällen um, wenn sie noch nicht aufgetreten sind? Versuchen wir zu formulieren, wie eine proaktive Optimierung durchgeführt werden kann, um solche Situationen zu verhindern.
Proaktive Optimierung
Das erste, was uns begegnet, ist, dass nicht bekannt ist, was optimiert werden muss. "Tu das, ich weiß nicht was."
- Es gibt keinen klassischen Algorithmus.
- Das Problem ist noch nicht aufgetreten (unbekannt), und man kann nur raten, wo es sein könnte.
- Wir müssen einige potenzielle Schwachstellen im System finden.
- Versuchen Sie, die Abfrageleistung an diesen Stellen zu optimieren.
Die Hauptziele einer proaktiven Optimierung
Die Hauptaufgaben der proaktiven Optimierung unterscheiden sich von den Aufgaben der reaktiven Optimierung und lauten wie folgt:
- Engpässe in der Datenbank beseitigen;
- Verringerung des Ressourcenverbrauchs der Datenbank.
Der letzte Moment ist der grundlegendste. Bei der reaktiven Optimierung haben wir nicht die Aufgabe, den Ressourcenverbrauch insgesamt zu reduzieren, sondern nur die Reaktionszeit der Funktionalität auf akzeptable Grenzen zu bringen.
Wie finde ich Engpässe in der Datenbank?
Wenn wir über dieses Problem nachdenken, entstehen sofort viele Unteraufgaben. Es ist notwendig durchzuführen:
- CPU-Test
- Lasttests für Lesevorgänge / Datensätze;
- Stresstests nach Anzahl der aktiven Sitzungen;
- Lasttests an ... etc.
Wenn wir versuchen, diese Probleme in einem Testkomplex zu simulieren, können wir feststellen, dass das auf dem Testserver aufgetretene Problem nichts mit dem Kampfproblem zu tun hat. Dafür gibt es viele Gründe, angefangen mit der Tatsache, dass Testserver normalerweise schwächer sind. Es ist gut, wenn es möglich ist, den Testserver zu einer exakten Kopie des Kampfservers zu machen. Dies garantiert jedoch nicht, dass die Last auf dieselbe Weise reproduziert wird, da Sie die Benutzeraktivität und viele weitere Faktoren, die sich auf die endgültige Last auswirken, genau reproduzieren müssen. Wenn Sie versuchen, diese Situation zu simulieren, garantiert im Großen und Ganzen niemand, dass genau dasselbe passiert, was auf dem Kampfserver passieren wird.
Wenn in einem Fall das Problem auftrat, weil eine neue Registrierung eingetroffen ist, kann es in dem anderen Fall auftreten, weil der Benutzer einen großen Bericht mit einer großen Sortierung gestartet hat, wodurch der temporäre Tabellenbereich gefüllt wurde, und als Folglich begann das System langsamer zu werden. Das heißt, die Gründe können unterschiedlich sein und es ist nicht immer möglich, sie vorherzusagen. Daher haben
wir Versuche, auf Testservern nach Engpässen zu suchen, fast von Anfang an
aufgegeben . Wir haben uns nur auf den Kampfserver und das, was darauf geschah, verlassen.
Was ist in diesem Fall zu tun? Versuchen wir zu verstehen, welche Ressourcen am wahrscheinlichsten fehlen.
Verringern des Ressourcenverbrauchs der Datenbank
Aufgrund der uns zur Verfügung stehenden Industriekomplexe wird der
häufigste Mangel an Ressourcen bei Festplattenlesungen und CPUs beobachtet . Daher werden wir zunächst genau in diesen Bereichen nach Schwachstellen suchen.
Die zweite wichtige Frage: Wie sucht man nach etwas?
Die Frage ist sehr nicht trivial. Wir verwenden Oracle Enterprise Edition mit der Option Diagnostic Pack und haben ein solches Tool für uns gefunden -
AWR-Berichte (in anderen Editionen von Oracle können Sie
STATSPACK-Berichte verwenden ). In PostgreSQL gibt es ein Analogon - pgstatspack, es gibt
pg_profile von Andrey Zubkov. Das letzte Produkt, so wie ich es verstehe, erschien und begann erst im letzten Jahr zu entwickeln. Für MySQL konnte ich keine ähnlichen Tools finden, aber ich bin kein MySQL-Experte.
Der Ansatz selbst ist nicht an eine bestimmte Art von Datenbank gebunden. Wenn es möglich ist, Informationen über die Systemlast aus einem Bericht zu erhalten, können Sie mit der Technik, über die ich jetzt sprechen werde,
an jeder Basis an einer proaktiven Optimierung arbeiten.
Optimierung der Top 5 Operationen
Die proaktive Optimierungstechnologie, die wir im Payment Center RNCO entwickelt haben und einsetzen, besteht aus vier Phasen.
Stufe 1. Wir erhalten den AWR-Bericht für den größtmöglichen Zeitraum.Es wird die größtmögliche Zeit benötigt, um die Last an verschiedenen Wochentagen zu mitteln, da sie manchmal sehr unterschiedlich ist. Zum Beispiel kommen Registries der letzten Woche am Dienstag bei der RBS-Retail Bank an, sie werden verarbeitet, und den ganzen Tag haben wir eine durchschnittliche Auslastung von etwa zwei bis drei Mal. An anderen Tagen ist die Belastung geringer.
Wenn Sie wissen, dass das System einige Besonderheiten aufweist - an manchen Tagen ist die Last größer, an manchen Tagen geringer -, müssen Sie Berichte für diese Zeiträume separat erhalten und separat damit arbeiten, wenn wir bestimmte Zeitintervalle optimieren möchten . Wenn Sie die Gesamtsituation auf dem Server optimieren müssen, können Sie einen umfangreichen Bericht für den Monat abrufen und sehen, was die Ressourcen des Servers tatsächlich verbrauchen.
Manchmal treten sehr unerwartete Situationen auf. Im Fall der CFT Bank befindet sich beispielsweise eine Anforderung, die die Berichtsserverwarteschlange überprüft, möglicherweise unter den Top 10. Darüber hinaus ist diese Anforderung offiziell und führt keine Geschäftslogik aus, sondern prüft nur, ob ein Bericht über die Ausführung vorliegt oder nicht.
Stufe 2. Wir schauen uns Abschnitte an:- SQL nach verstrichener Zeit geordnet - SQL-Abfragen sortiert nach Laufzeit;
- SQL geordnet nach CPU-Zeit - für die CPU-Auslastung;
- SQL sortiert nach Gets - nach logischen Lesungen;
- Von Reads geordnetes SQL - für physische Lesungen.
Die verbleibenden Abschnitte von SQL, die nach geordnet sind, werden nach Bedarf untersucht.
Stufe 3. Wir bestimmen übergeordnete Operationen und Anforderungen, die von ihnen abhängen.Der AWR-Bericht enthält separate Abschnitte, in denen je nach Oracle-Version in jedem dieser Abschnitte 15 oder mehr Top-Abfragen angezeigt werden. Diese Abfragen von Oracle im AWR-Bericht zeigen jedoch ein Durcheinander.
Zum Beispiel gibt es eine übergeordnete Operation, in der sich drei Top-Abfragen befinden können. Oracle im AWR-Bericht zeigt sowohl die übergeordnete Operation als auch alle diese drei Abfragen an. Daher müssen Sie eine Analyse dieser Liste durchführen und feststellen, auf welche betriebsspezifischen Anforderungen Bezug genommen wird, und sie gruppieren.
Stufe 4. Wir optimieren die Top 5 Operationen.Nach einer solchen Gruppierung ist die Ausgabe eine Liste von Operationen, aus denen Sie die schwierigsten auswählen können. Wir sind auf 5 Operationen beschränkt (keine Anfragen, nämlich Operationen). Wenn das System komplexer ist, können Sie mehr nehmen.
Häufige Fehler beim Entwurf von Abfragen
Während der Anwendung dieser Technik haben wir eine kleine Liste typischer Konstruktionsfehler zusammengestellt. Einige Fehler sind so einfach, dass es den Anschein hat, als könnten sie nicht sein.
●
Fehlender Index → Vollständiger ScanEs gibt sehr zufällige Fälle, in denen beispielsweise kein Index für das Kampfschema vorhanden ist. Wir hatten ein konkretes Beispiel, bei dem eine Abfrage lange Zeit ohne Index schnell funktionierte. Es gab jedoch einen vollständigen Scan, und als die Größe der Tabelle allmählich zunahm, begann die Abfrage langsamer zu arbeiten, und von Quartal zu Quartal dauerte es etwas länger. Am Ende haben wir auf ihn geachtet und es stellte sich heraus, dass der Index nicht da ist.
●
Große Auswahl → Vollständiger ScanDer zweite häufige Fehler ist ein großes Datenmuster - der klassische Fall eines vollständigen Scans. Jeder weiß, dass ein vollständiger Scan nur verwendet werden sollte, wenn dies wirklich gerechtfertigt ist. Manchmal kommt es vor, dass ein vollständiger Scan auftritt, auf den Sie verzichten können, z. B. wenn Sie die Filterbedingungen vom pl / sql-Code auf die Abfrage übertragen.
●
Ineffektiver Index → Long INDEX RANGE SCANVielleicht ist dies sogar der häufigste Fehler, für den sie aus irgendeinem Grund sehr wenig sagen - der sogenannte ineffiziente Index (langer Index-Scan, langer INDEX-BEREICH-SCAN). Zum Beispiel haben wir eine Tabelle für Registrierungen. In der Anfrage versuchen wir, alle Registrierungen dieses Agenten zu finden und letztendlich eine Filterbedingung hinzuzufügen, beispielsweise für einen bestimmten Zeitraum oder mit einer bestimmten Nummer oder einem bestimmten Kunden. In solchen Situationen wird der Index aus Gründen der universellen Verwendung normalerweise nur auf dem Feld "Agent" erstellt. Das Ergebnis ist das folgende Bild: Im ersten Arbeitsjahr hatte der Agent beispielsweise 100 Einträge in dieser Tabelle, im nächsten Jahr bereits 1.000, in einem anderen Jahr möglicherweise 10.000 Einträge. Nach einiger Zeit werden diese Datensätze zu 100.000. Offensichtlich beginnt die Anforderung langsam zu arbeiten, da Sie in der Anforderung nicht nur die Agentenkennung selbst, sondern auch einen zusätzlichen Filter hinzufügen müssen, in diesem Fall nach Datum. Andernfalls wird sich herausstellen, dass die Stichprobengröße von Jahr zu Jahr zunimmt, da die Anzahl der Register für diesen Agenten zunimmt. Dieses Problem muss auf Indexebene behoben werden. Wenn es zu viele Daten gibt, sollten wir bereits in Richtung Partitionierung denken.
●
Unnötige Verteilungscode-VerzweigungenDies ist auch ein merkwürdiger Fall, aber es passiert trotzdem. Wir schauen uns die Top-Abfragen an und sehen dort einige seltsame Abfragen. Wir kommen zu den Entwicklern und sagen: "Wir haben einige Anfragen gefunden. Lassen Sie uns das herausfinden und sehen, was dagegen getan werden kann." Der Entwickler denkt nach, kommt dann nach einer Weile und sagt: „Dieser Codezweig sollte sich nicht auf Ihrem System befinden. Sie nutzen diese Funktionalität nicht. “ Dann empfiehlt der Entwickler, dass Sie eine spezielle Einstellung aktivieren, um diesen Abschnitt des Codes zu umgehen.
Fallstudien
Jetzt möchte ich zwei Beispiele aus unserer Praxis betrachten. Wenn wir uns mit den wichtigsten Fragen befassen, denken wir natürlich zunächst daran, dass es etwas Mega-Schweres, Nicht-Triviales mit komplexen Operationen geben sollte. In der Tat ist dies nicht immer der Fall. Manchmal gibt es Fälle, in denen sehr einfache Abfragen in die Top-Operationen fallen.
Beispiel 1
select * from (select o.* from rnko_dep_reestr_in_oper o where o.type_oper = 'proc' and o.ean_rnko in (select l.ean_rnko from rnko_dep_link l where l.s_rnko = :1) order by o.date_oper_bnk desc, o.date_reg desc) where ROWNUM = 1
In diesem Beispiel besteht eine Abfrage nur aus zwei Tabellen, und dies sind keine schweren Tabellen - nur einige Millionen Datensätze. Es scheint einfacher zu sein? Die Anfrage traf jedoch ganz oben.
Versuchen wir herauszufinden, was mit ihm los ist.
Unten sehen Sie ein Bild aus der Enterprise Manager Cloud Control - Daten zu den Statistiken dieser Anforderung (Oracle verfügt über ein solches Tool). Es ist ersichtlich, dass diese Anforderung regelmäßig belastet wird (oberes Diagramm). Die Nummer 1 auf der Seite zeigt an, dass durchschnittlich nicht mehr als eine Sitzung ausgeführt wird. Das grüne Diagramm zeigt, dass die
Anfrage nur die CPU verwendet , was doppelt interessant ist.

Versuchen wir herauszufinden, was hier los ist.

Oben finden Sie eine Tabelle mit Statistiken auf Anfrage. Fast 700.000 Starts - das wird niemanden überraschen. Das Zeitintervall zwischen der ersten Ladezeit am 15. Dezember und der letzten Ladezeit am 22. Dezember (siehe vorheriges Bild) beträgt jedoch eine Woche. Wenn Sie die Anzahl der Starts pro Sekunde zählen, stellt sich heraus, dass die
Abfrage durchschnittlich jede Sekunde ausgeführt wird .
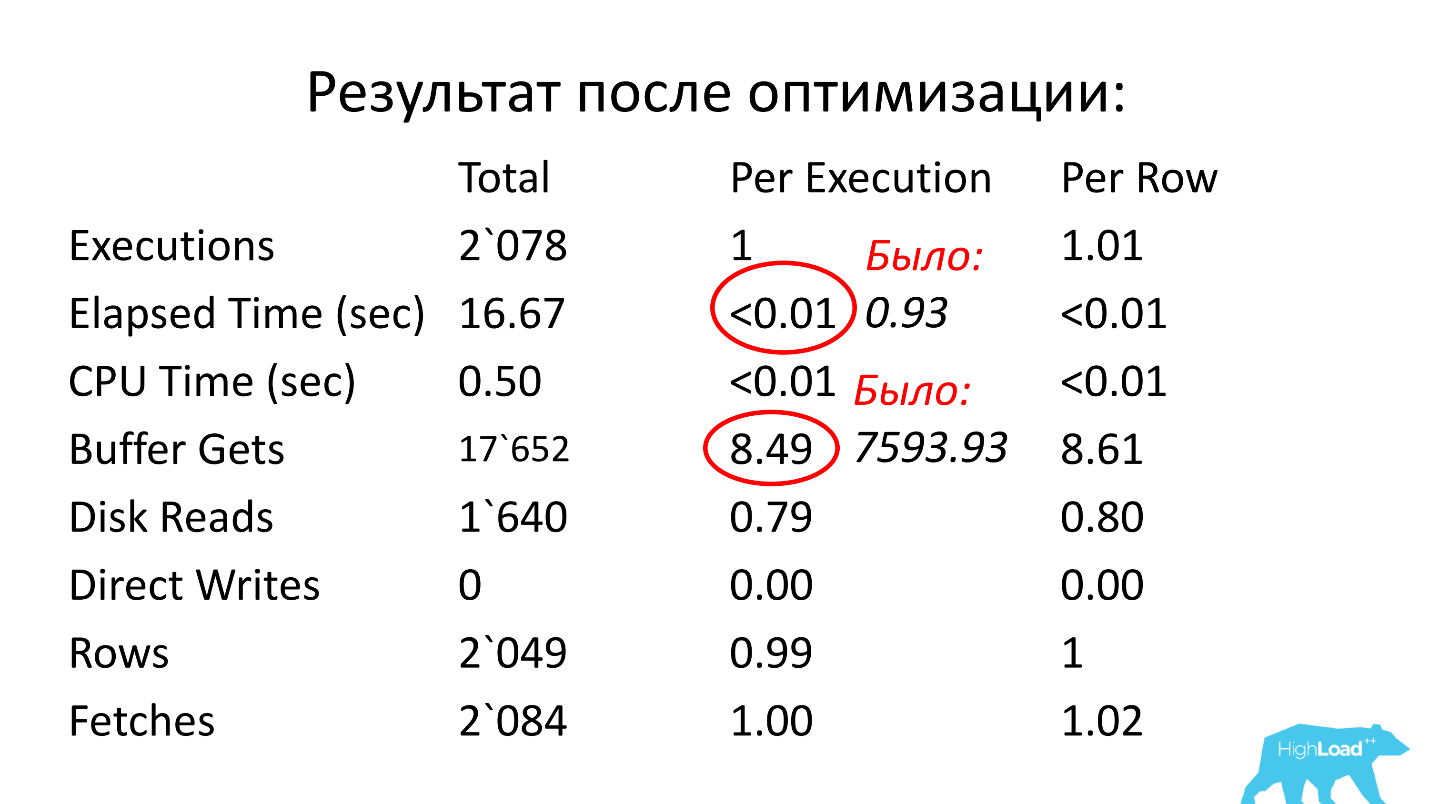
Wir schauen weiter. Die Abfrageausführungszeit beträgt 0,93 Sekunden, d.h. weniger als eine Sekunde, das ist großartig. Wir können uns freuen - die Anfrage ist nicht schwer. Trotzdem hat er die Spitze erreicht, was bedeutet, dass er viele Ressourcen verbraucht. Wo verbraucht es viele Ressourcen?
Die Tabelle enthält eine Zeile für logische Lesungen. Wir sehen, dass für einen Start fast 8.000 Blöcke benötigt werden (normalerweise ist 1 Block 8 KB groß). Es stellt sich heraus, dass die Anforderung, die einmal pro Sekunde ausgeführt wird, ungefähr 64 MB Daten aus dem Speicher lädt. Hier stimmt etwas nicht, wir müssen verstehen.
Schauen wir uns den Plan an: Es gibt einen vollständigen Scan. Nun, lass uns weitermachen.
Plan hash value: 634977963
In der Tabelle rnko_dep_reestr_in_oper gibt es nur 5 Millionen Zeilen und ihre durchschnittliche Zeilenlänge beträgt 150 Byte. Es stellte sich jedoch heraus, dass nicht genügend Index für das zu verbindende Feld vorhanden ist - die Unterabfrage ist über das Feld ean_rnko mit der Anforderung verbunden, für das es keinen Index gibt!
Selbst wenn er auftaucht, wird die Situation tatsächlich nicht sehr gut sein. Dieser lange Index-Scan (langer INDEX-BEREICH-SCAN) wird ausgeführt. ean_rnko ist die interne Kennung des Agenten. Agentenregister werden akkumuliert, und jedes Jahr erhöht sich die Datenmenge, die diese Anfrage auswählt, und die Anfrage wird langsamer.
Lösung: Erstellen Sie einen Index für die Felder ean_rnko und date_reg und bitten Sie die Entwickler, die Scan-Tiefe in dieser Anforderung nach Datum zu begrenzen. Dann können Sie zumindest teilweise garantieren, dass die Abfrageleistung ungefähr an den gleichen Grenzen bleibt, da die Stichprobengröße auf ein festes Zeitintervall begrenzt ist und nicht die gesamte Tabelle gelesen werden muss. Dies ist ein sehr wichtiger Punkt, schauen Sie, was passiert ist.
Nach der Optimierung betrug die Betriebszeit weniger als eine Hundertstelsekunde (0,93), die Anzahl der Blöcke war durchschnittlich 8,5- bis 1000-mal kürzer als zuvor.
Beispiel 2
select count(1) from loy$barcodes t where t.id_processing = :b1 and t.id_rec_out is null and not t.barcode is null and t.status = 'u' and not t.id_card is null
Ich begann die Geschichte damit, dass normalerweise etwas Kompliziertes in der Abfrage oben erwartet wird. Oben ist ein Beispiel für eine „komplexe“ Abfrage, die an eine Tabelle (!) Geht und auch in die Top-Abfragen gelangt ist :) Es gibt einen Index für das Feld ID_PROCESSING!
Diese Abfrage enthält 3 IS NULL-Bedingungen. Wie wir wissen, werden solche Bedingungen nicht indiziert (in diesem Fall können Sie den Index nicht verwenden). Außerdem gibt es nur zwei Bedingungen des Gleichheitstyps (von ID_PROCESSING und STATUS).
Wahrscheinlich würde der Entwickler, der sich diese Abfrage ansehen würde, zunächst vorschlagen, einen Index für ID_PROCESSING und STATUS zu erstellen. Angesichts der Datenmenge, die ausgewählt wird (es werden viele davon sein), funktioniert diese Lösung jedoch nicht.
Die Anforderung verbraucht jedoch viele Ressourcen, was bedeutet, dass etwas getan werden muss, damit sie schneller funktioniert. Versuchen wir, die Gründe herauszufinden.

Die obigen Statistiken beziehen sich auf einen Tag, aus dem hervorgeht, dass die Anforderung alle 5 Minuten gestartet wird. Der Hauptressourcenverbrauch ist das Lesen von CPU und Festplatte. Unten in der Grafik mit Statistiken über die Anzahl der Abfragestarts ist zu sehen, dass alles in Ordnung ist - die Anzahl der Starts ändert sich im Laufe der Zeit fast nicht -, eine ziemlich stabile Situation.

Und wenn Sie weiter schauen, können Sie feststellen, dass die Abfragezeit manchmal sehr unterschiedlich ist - mehrmals, was bereits von Bedeutung ist.
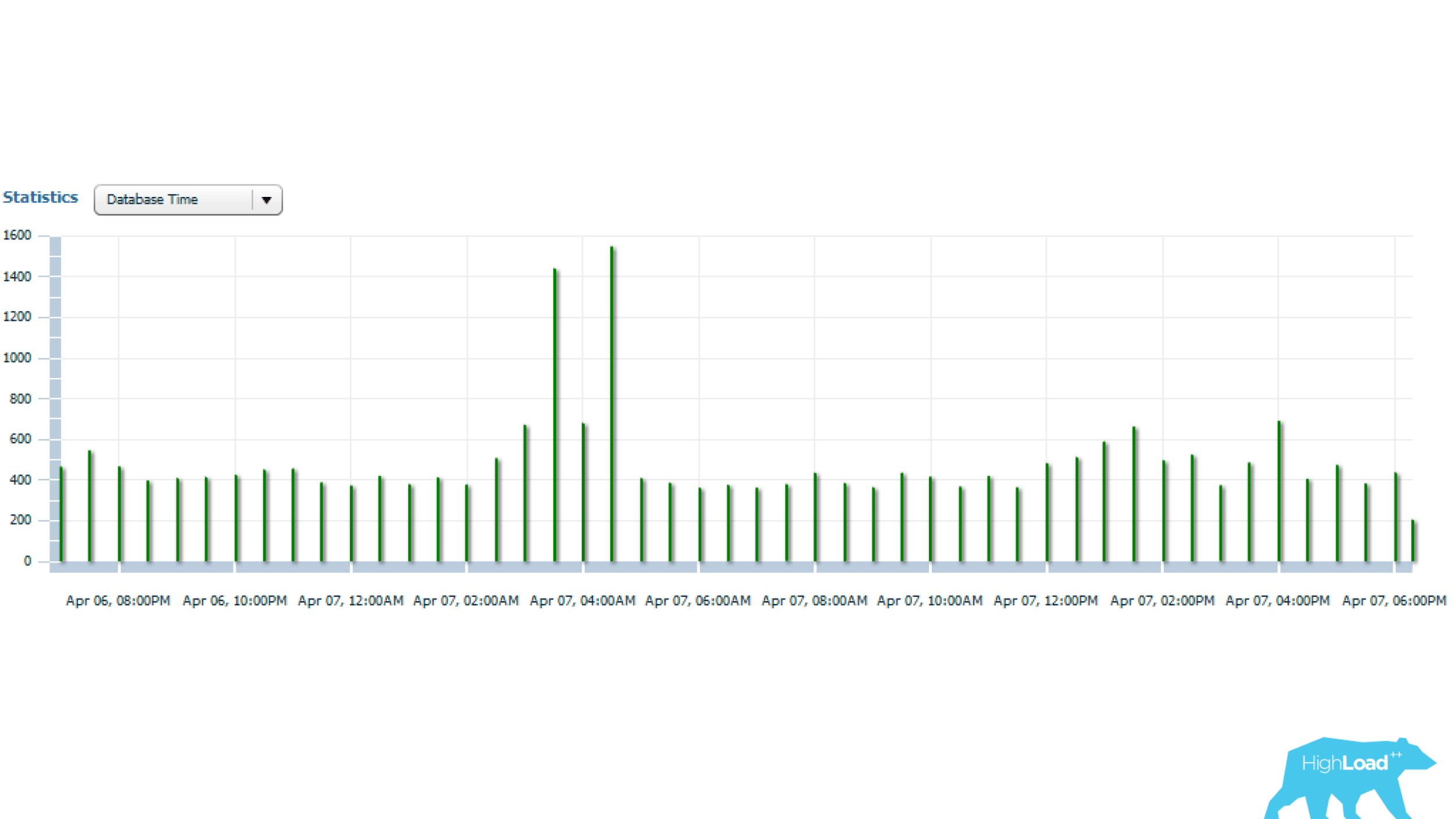
Lassen Sie es uns als nächstes herausfinden.
Oracle Enterprise Manager verfügt über ein SQL-Monitoring-Dienstprogramm. Mit diesem Dienstprogramm können Sie den Ressourcenverbrauch auf Anfrage in Echtzeit anzeigen.

Oben Bericht für problematische Anfrage. Zunächst sollte uns die Tatsache interessieren, dass der INDEX RANGE SCAN (unterste Zeile) in der Spalte Aktuelle Zeilen 17 Millionen Zeilen enthält. Wahrscheinlich eine Überlegung wert.
Wenn wir uns den Umsetzungsplan genauer ansehen, stellt sich heraus, dass nach dem nächsten Punkt im Plan von diesen 17 Millionen Zeilen nur noch 1705 übrig sind. Die Frage ist, warum 17 Millionen ausgewählt wurden. In der endgültigen Stichprobe blieben etwa 0,01%
, dh offensichtlich ineffizient, es wurden unnötige Arbeiten durchgeführt . Darüber hinaus wird diese Arbeit alle 5 Minuten durchgeführt. Hier ist das Problem! Daher traf diese Anfrage die Top-Abfragen.
Versuchen wir, dieses nicht triviale Problem zu lösen. Der Index, der sich von Anfang an selbst bittet, ist ineffizient. Sie müssen sich also etwas Kniffliges einfallen lassen und die IS NULL-Bedingungen umgehen.
Neuer Index
Wir haben uns mit den Entwicklern beraten, überlegt und sind zu dieser Entscheidung gekommen: Wir haben einen Funktionsindex erstellt, in dem sich eine ID_PROCESSING-Spalte befindet, die die Bedingung der Gleichheit in der Anforderung enthält, und wir haben alle anderen Felder als Argumente für diese Funktion aufgenommen:
create index gc.loy$barcod_unload_i on gc.loy$barcodes (gc.loy_barcodes_ic_unload(id_rec_out, barcode, id_card, status), id_processing); function loy_barcodes_ic_unload( pIdRecOut in loy$barcodes.id_rec_out%type, pBarcode in loy$barcodes.barcode%type, pIdCard in loy$barcodes.id_card%type, pStatus in loy$barcodes.status%type) return varchar2 deterministic is vRes varchar2(1) := ''; begin if pIdRecOut is null and pBarcode is not null and pIdCard is not null and pStatus = 'U' then vRes := pStatus; end if; return vRes; end loy_barcodes_ic_unload;
Diese Funktion ist typdeterministisch, dh sie gibt bei demselben Parametersatz immer dieselbe Antwort. Wir haben dafür gesorgt, dass diese Funktion immer einen Wert zurückgibt - in diesem Fall "U". Wenn alle diese Bedingungen erfüllt sind, wird "U" ausgegeben, wenn sie nicht erfüllt sind - NULL. Ein solcher Funktionsindex ermöglicht es, Daten effektiv zu filtern.
Die Anwendung dieses Index führte zu folgendem Ergebnis:
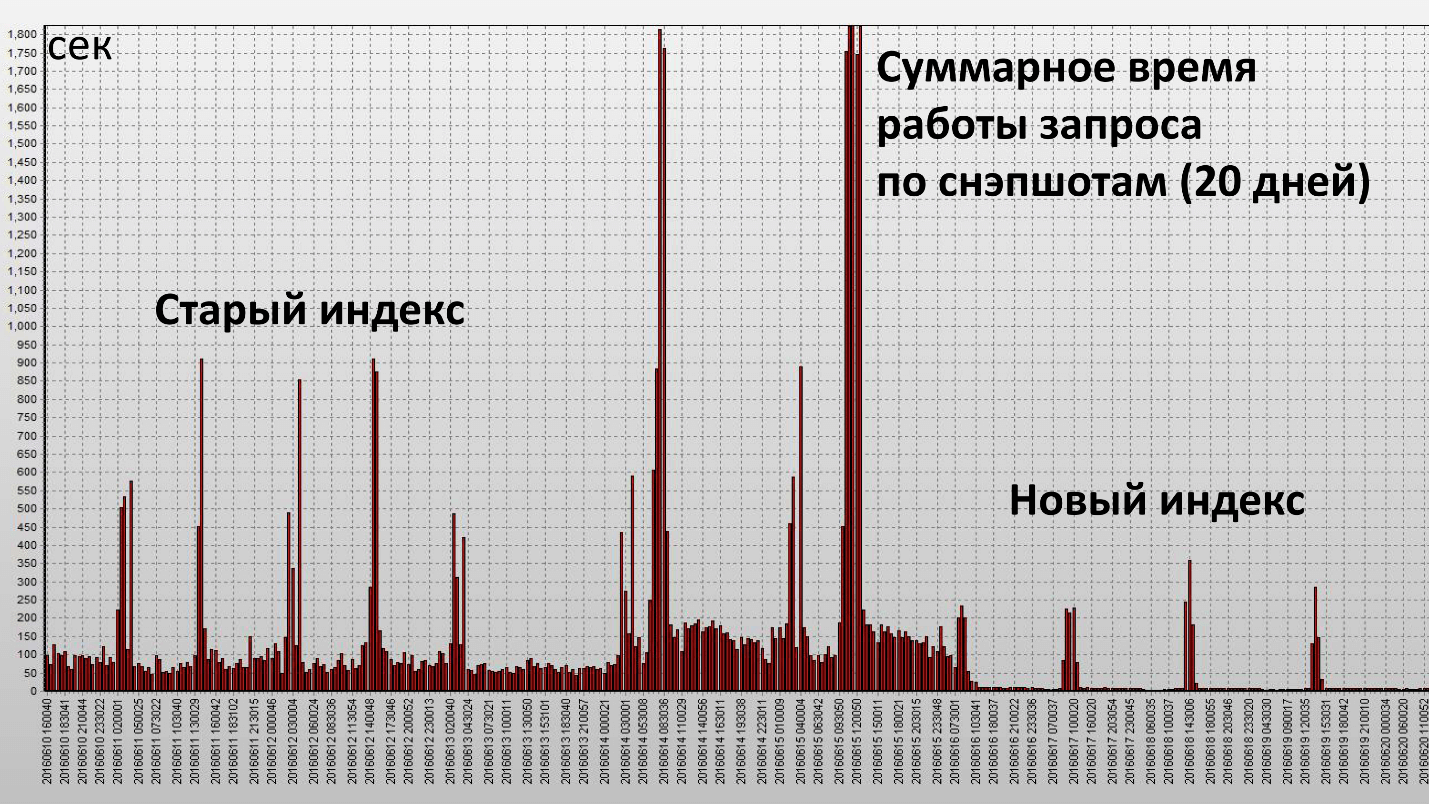
Hier ist eine Spalte ein Schnappschuss, sie werden jede halbe Stunde der Datenbank erstellt. Wir haben unser Ziel erreicht und dieser Index war wirklich effektiv. Sehen wir uns die quantitativen Merkmale an:
Durchschnittliche Anforderungsstatistik
|
| Vorher
| NACHHER
|
Verstrichene Zeit, sek
| 143,21
| 60.7
|
CPU-Zeit, sek
| 33.23
| 45,38
|
Puffer wird blockiert
| 6`288`237.67
| 1`589`836
|
Block zum Lesen der Festplatte
| 266`600.33
| 2'680
|
Die Betriebszeit verringerte sich um das 2,5-fache und der Ressourcenverbrauch (Buffer Gets) um etwa das 4. Die Anzahl der von der Festplatte gelesenen Datenblöcke nahm erheblich ab.
Proaktive Optimierungsergebnisse
Wir haben bekommen:
- Reduzierung der Belastung der Datenbank;
- Verbesserung der Stabilität der Datenbank;
- eine signifikante Reduzierung der Anzahl von Software-Performance-Vorfällen.
Leistungsvorfälle wurden um das Zehnfache verringert . Dies ist ein subjektiver Betrag, bevor die Vorfälle 1-2 Mal im Monat im Komplex der RBS-Retail Bank auftraten, aber jetzt haben wir sie praktisch vergessen.
Dies wirft die Frage auf: Was ist mit Software-Performance-Vorfällen? Wir haben uns nicht direkt mit ihnen befasst?
Zurück zum letzten Zeitplan. Wenn Sie sich erinnern, dass ein vollständiger Scan durchgeführt wurde, musste eine große Anzahl von Blöcken im Speicher gespeichert werden. Da die Anforderung regelmäßig ausgeführt wurde, wurden alle diese Blöcke im Oracle-Cache gespeichert. Es stellt sich heraus, dass Sie zu diesem Zeitpunkt einen Cache zum Speichern von Datenblöcken benötigen, wenn zu diesem Zeitpunkt eine hohe Auslastung der Datenbank auftritt und beispielsweise jemand beginnt, den Speicher aktiv zu nutzen. Daher wird ein Teil der Daten für unsere Anfrage verdrängt, was bedeutet, dass wir physische Messungen durchführen müssen. Wenn Sie physische Messungen durchführen, erhöht sich die Laufzeit der Abfrage sofort enorm.
Das logische Lesen funktioniert mit dem Speicher, es geschieht schnell und der Zugriff auf die Festplatte ist langsam (wenn Sie sich die Zeit ansehen, Millisekunden). Wenn Sie Glück haben und diese Daten im Cache des Betriebssystems oder im Array-Cache vorhanden sind, sind es immer noch einige zehn Mikrosekunden. Das Lesen aus dem Oracle-Cache ist viel schneller.
Als wir den vollständigen Scan loswurden, verschwand die Notwendigkeit, eine so große Anzahl von Blöcken im Cache (Puffer-Cache) zu speichern. Wenn diese Ressourcen fehlen, ist die Anforderung mehr oder weniger stabil. Es gibt keine so großen Spitzen mehr wie beim alten Index.
Zusammenfassung der proaktiven Optimierung:- Die anfängliche Abfrageoptimierung sollte auf Testservern durchgeführt werden, um zu sehen, wie die Abfragen und ihre Geschäftslogik funktionieren, um nichts Überflüssiges zu tun. Diese Arbeiten bleiben erhalten.
- In regelmäßigen Abständen, jedoch alle paar Monate, ist es sinnvoll, Berichte bei voller Auslastung vom Server zu entfernen, nach den wichtigsten Abfragen und Vorgängen in der Datenbank zu suchen und diese zu optimieren.
Es gibt viele Tools zum Abrufen von Statistiken in einer Oracle-Datenbank:- AWR-Bericht (DBMS_WORKLOAD_REPOSITORY.awr_report_html);
- Enterprise Manager Cloud Control 12c (SQL-Details);
- Aktiver SQL-Detailbericht (DBMS_PERF.report_sql);
- SQL-Überwachung (Registerkarte in EMCC);
- SQL-Überwachungsbericht (DBMS_SQLTUNE.report_sql_monitor *).
Einige dieser Tools funktionieren in der Konsole, dh sie sind nicht an den Enterprise Manager gebunden.
Beispiele für Oracle-Tools zum Sammeln von Statistiken Bonus: Die Spezialisten von RNCO „Payment Center“ und CFT waren gut auf die Konferenz in Nowosibirsk vorbereitet, machten einige nützliche Berichte und organisierten auch ein echtes Exit-Radio. Zwei Tage lang gelang es Experten, Rednern und Organisatoren, das CFT-Radio zu besuchen. Sie können zum sibirischen Sommer zurückkehren, indem Sie Einträge
hinzufügen. Hier sind die Links zu den Blöcken:
Kubernetes: Vor- und Nachteile ;
Data Science & Maschinelles Lernen ;
DevOps .
Bei HighLoad ++ in Moskau, das bereits am 8. und 9. November stattfindet, wird es noch interessantere Dinge geben. Das Programm enthält Berichte zu allen Aspekten der Arbeit an hoch belasteten Projekten, Meisterklassen, Besprechungen und Veranstaltungen von Partnern , die fachkundige Ratschläge austauschen und etwas Überraschendes finden. Schreiben Sie unbedingt über die interessantesten und benachrichtigen Sie im Newsletter , verbinden Sie sich!