Was ist die GraphQL-Abfragesprache? Welche Vorteile bietet diese Technologie und welche Probleme werden Entwickler bei ihrer Verwendung haben? Wie kann man GraphQL effektiv nutzen? Über all das unter dem Schnitt.

Der Artikel basiert auf dem Einführungsbericht von
Vladimir Tsukur (
volodymyrtsukur ) von der
Joker 2017- Konferenz.
Mein Name ist Vladimir, ich leite die Entwicklung einer der Abteilungen bei WIX. Mehr als hundert Millionen WIX-Benutzer erstellen Websites in verschiedene Richtungen - von Visitenkarten-Websites und Geschäften bis hin zu komplexen Webanwendungen, in denen Sie Code und beliebige Logik schreiben können. Als lebendiges Beispiel für ein Projekt auf WIX möchte ich Ihnen den erfolgreichen Site Store
unicornadoptions.com zeigen , der die Möglichkeit bietet, ein Kit zum Zähmen eines Einhorns zu erwerben - ein großartiges Geschenk für ein Kind.

Ein Besucher dieser Website kann ein Kit auswählen, mit dem er ein Einhorn zähmen möchte, z. B. Pink, und dann sehen, was genau in diesem Kit enthalten ist: Spielzeug, Zertifikat, Abzeichen. Ferner hat der Käufer die Möglichkeit, Waren in den Warenkorb zu legen, deren Inhalt anzuzeigen und eine Bestellung aufzugeben. Dies ist ein einfaches Beispiel für eine Store-Site, und wir haben viele solcher Sites, Hunderttausende. Alle von ihnen basieren auf derselben Plattform mit einem Backend und einer Reihe von Clients, die wir mithilfe der API unterstützen. Es geht um die API, die weiter diskutiert wird.
Einfache API und ihre Probleme
Stellen wir uns vor, welche Allzweck-API (dh eine API für alle Stores auf der Plattform) wir erstellen könnten, um Store-Funktionen bereitzustellen. Konzentrieren wir uns ausschließlich auf die Datenerfassung.
Für eine Produktseite auf einer solchen Website sollten der Produktname, der Preis, die Bilder, die Beschreibung, zusätzliche Informationen und vieles mehr zurückgegeben werden. In einer Komplettlösung für Geschäfte unter WIX gibt es mehr als zwei Dutzend solcher Datenfelder. Die Standardlösung für eine solche Aufgabe zusätzlich zur HTTP-API besteht darin, die Ressource
/products/:id zu beschreiben, die die Produktdaten für die
GET Anforderung zurückgibt. Das Folgende ist ein Beispiel für Antwortdaten:
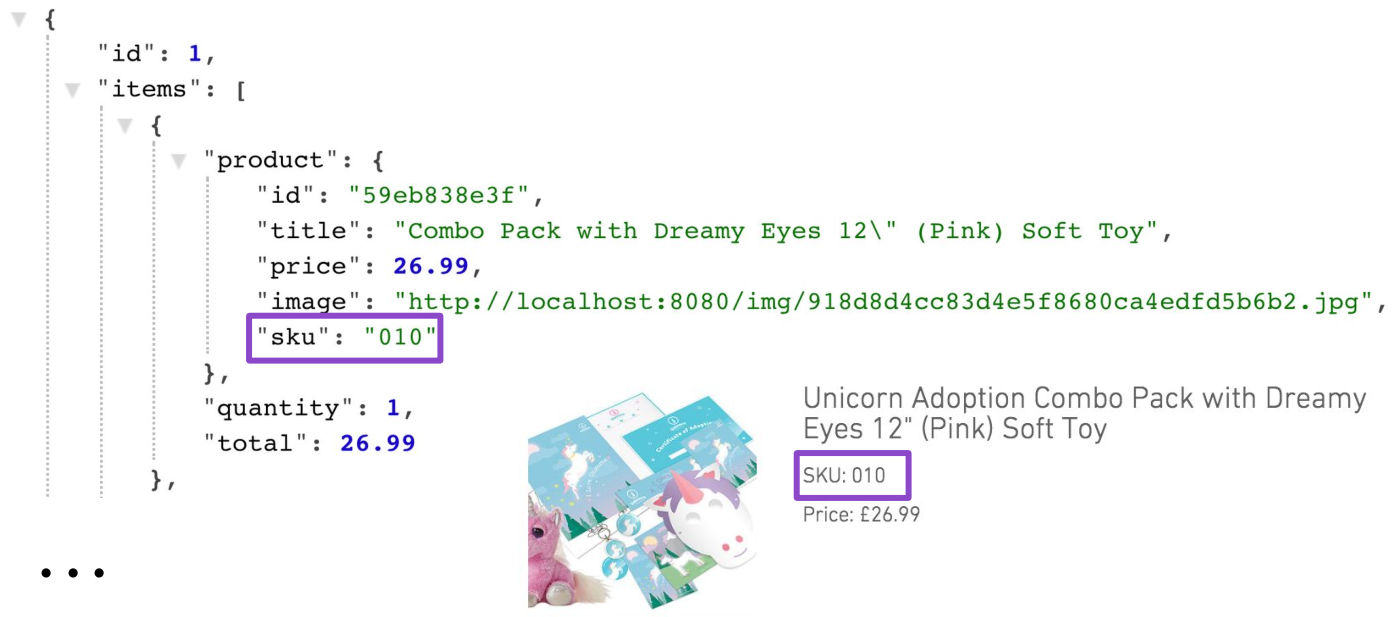
{ "id": "59eb83c0040fa80b29938e3f", "title": "Combo Pack with Dreamy Eyes 12\" (Pink) Soft Toy", "price": 26.99, "description": "Spread Unicorn love amongst your friends and family by purchasing a Unicorn adoption combo pack today. You'll receive your very own fabulous adoption pack and a 12\" Dreamy Eyes (Pink) cuddly toy. It makes the perfect gift for loved ones. Go on, you know you want to, adopt today!", "sku":"010", "images": [ "http://localhost:8080/img/918d8d4cc83d4e5f8680ca4edfd5b6b2.jpg", "http://localhost:8080/img/f343889c0bb94965845e65d3f39f8798.jpg", "http://localhost:8080/img/dd55129473e04f489806db0dc6468dd9.jpg", "http://localhost:8080/img/64eba4524a1f4d5d9f1687a815795643.jpg", "http://localhost:8080/img/5727549e9131440dbb3cd707dce45d0f.jpg", "http://localhost:8080/img/28ae9369ec3c442dbfe6901434ad15af.jpg" ] }

Schauen wir uns jetzt die Produktkatalogseite an. Für diese Seite benötigen Sie die Ressourcensammlung
/ products . Aber nur bei der Anzeige der Produktkollektion auf der Katalogseite werden nicht alle Produktdaten benötigt, sondern nur Preis, Name und Hauptbild. Zum Beispiel sind die Beschreibung, zusätzliche Informationen, Hintergrundbilder usw. für uns nicht von Interesse.

Angenommen, wir verwenden der Einfachheit halber dasselbe Produktdatenmodell für die Ressourcen
/products und
/products/:id . Im Falle einer Sammlung solcher Produkte wird es möglicherweise mehrere geben. Das Antwortschema kann wie folgt dargestellt werden:
GET /products [ { title price images description info ... } ]
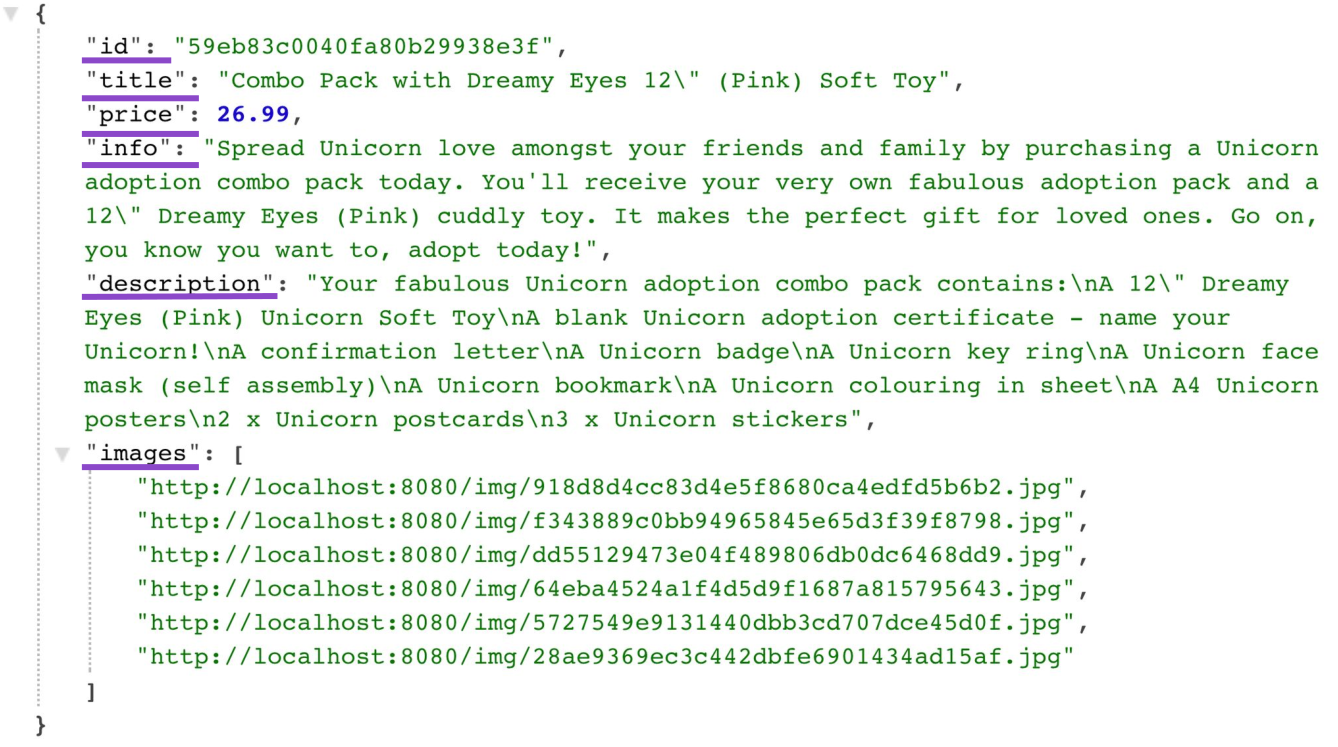
Schauen wir uns nun die „Nutzdaten“ der Antwort vom Server für die Produktsammlung an. Folgendes wird vom Client in mehr als zwei Dutzend Feldern tatsächlich verwendet:
{
"id": "59eb83c0040fa80b29938e3f",
"title": "Combo Pack with Dreamy Eyes 12\" (Pink) Soft Toy",
"price": 26.99,
"info": "Spread Unicorn love amongst your friends and family by purchasing a Unicorn adoption combo pack today. You'll receive your very own fabulous adoption pack and a 12\" Dreamy Eyes (Pink) cuddly toy. It makes the perfect gift for loved ones. Go on, you know you want to, adopt todayl",
" description": "Your fabulous Unicorn adoption combo pack contains:\nA 12\" Dreamy Eyes (Pink) Unicorn Soft Toy\nA blank Unicorn adoption certificate — name your Unicorn!\nA confirmation letter\nA Unicorn badge\nA Unicorn key ring\nA Unicorn face mask (self assembly)\nA Unicorn bookmark\nA Unicorn colouring in sheet\nA A4 Unicorn posters\n2 x Unicorn postcards\n3 x Unicorn stickers",
"images": [
"http://localhost:8080/img/918d8d4cc83d4e5f8680ca4edfd5b6b2.jpg",
"http://localhost:8080/img/f343889c0bb94965845e65d3f39f8798.jpg",
"http://localhost:8080/img/dd55129473604f489806db0dC6468dd9.jpg",
"http://localhost:8080/img/64eba4524a1f4d5d9f1687a815795643.jpg",
"http://localhost:8080/img/5727549e9l3l440dbb3cd707dce45d0f.jpg",
"http://localhost:8080/img/28ae9369ec3c442dbfe6901434ad15af.jpg"
],
...
}Wenn ich das Produktmodell einfach halten möchte, indem ich dieselben Daten zurückgebe, habe ich natürlich ein Problem mit dem Abrufen von Daten, das in einigen Fällen mehr Daten enthält, als ich benötige. In diesem Fall wurde dies auf der Produktkatalogseite angezeigt. Im Allgemeinen benötigen jedoch alle Benutzeroberflächenbildschirme, die in irgendeiner Weise mit dem Produkt verbunden sind, möglicherweise nur einen Teil (nicht alle) der Daten.
Schauen wir uns jetzt die Warenkorbseite an. Im Warenkorb befinden sich neben den Produkten selbst auch deren Menge (in diesem Warenkorb), Preis sowie die Gesamtkosten der gesamten Bestellung:

Wenn wir den Ansatz der einfachen Modellierung der HTTP-API fortsetzen, kann der Warenkorb durch die Ressource
/ carts /: id dargestellt werden , deren Darstellung sich auf die Ressourcen der Produkte bezieht, die diesem Warenkorb hinzugefügt wurden:
{ "id": 1, "items": [ { "product": "/products/59eb83c0040fa80b29938e3f", "quantity": 1, "total": 26.99 }, { "product": "/products/59eb83c0040fa80b29938e40", "quantity": 2, "total": 25.98 }, { "product": "/products/59eb88bd040fa8125aa9c400", "quantity": 1, "total": 26.99 } ], "subTotal": 79.96 }
Um beispielsweise einen Warenkorb mit drei Produkten am Frontend zu zeichnen, müssen Sie vier Anforderungen stellen: eine zum Laden des Warenkorbs selbst und drei Anforderungen zum Laden von Produktdaten (Name, Preis und Artikelnummer).
Das zweite Problem, das wir hatten, ist das Unterholen. Die Differenzierung der Verantwortlichkeiten zwischen dem Warenkorb und den Produktressourcen hat dazu geführt, dass zusätzliche Anfragen gestellt werden müssen. Hier gibt es offensichtlich eine Reihe von Nachteilen: Aufgrund
einer größeren Anzahl von Anfragen landen wir den Akku des Mobiltelefons schneller und erhalten die vollständige Antwort langsamer. Auch die Skalierbarkeit unserer Lösung wirft Fragen auf.
Natürlich ist diese Lösung nicht für die Produktion geeignet. Eine Möglichkeit, das Problem zu beheben, besteht darin, Projektionsunterstützung für den Korb hinzuzufügen. Eine dieser Projektionen könnte zusätzlich zu den Daten des Warenkorbs selbst Daten zu Produkten zurückgeben. Darüber hinaus ist diese Projektion sehr spezifisch, da Sie auf der Warenkorbseite die Inventarnummer (SKU) des Produkts benötigen. Nirgendwo sonst wurde eine SKU benötigt.
GET /carts/1?projection=with-products
Eine solche „Anpassung“ von Ressourcen für eine bestimmte Benutzeroberfläche endet normalerweise nicht, und wir beginnen, andere Projektionen zu generieren: kurze Informationen zum Warenkorb, die Korbprojektion für das mobile Web und danach die Projektion für Einhörner.

(Im Allgemeinen können Sie als Benutzer im WIX Designer konfigurieren, welche Produktdaten auf der Produktseite angezeigt werden sollen und welche Daten im Warenkorb angezeigt werden sollen.)
Und hier erwarten uns Schwierigkeiten: Wir rahmen den Garten ein und suchen nach komplexen Lösungen. Aus API-Sicht gibt es für eine solche Aufgabe nur wenige Standardlösungen, die normalerweise stark vom Framework oder der HTTP-Ressourcenbeschreibungsbibliothek abhängen.
Was noch wichtiger ist, jetzt wird es schwieriger zu arbeiten, denn wenn sich die Anforderungen auf der Client-Seite ändern, muss das Backend sie ständig „einholen“ und befriedigen.
Schauen wir uns als „Kirsche auf dem Kuchen“ ein weiteres wichtiges Thema an. Bei einer einfachen HTTP-API hat der Serverentwickler keine Ahnung, welche Art von Daten der Client verwendet. Wird der Preis verwendet? Beschreibung? Ein oder alle Bilder?
Dementsprechend stellen sich mehrere Fragen. Wie arbeite ich mit veralteten / veralteten Daten? Woher weiß ich, welche Daten nicht mehr verwendet werden? Wie ist es relativ sicher, Daten aus der Antwort zu entfernen, ohne die meisten Clients zu beschädigen? Mit der üblichen HTTP-API gibt es keine Antwort auf diese Fragen. Trotz der Tatsache, dass wir optimistisch sind und die API einfach zu sein scheint, sieht die Situation nicht so heiß aus. Dieser Bereich von API-Problemen gilt nicht nur für WIX. Eine große Anzahl von Unternehmen musste sich mit ihnen befassen. Jetzt ist es interessant, eine mögliche Lösung zu finden.
GraphQL. Starten Sie
Im Jahr 2012 hatte Facebook bei der Entwicklung einer mobilen Anwendung ein ähnliches Problem. Die Ingenieure wollten die Mindestanzahl mobiler Anwendungsaufrufe an den Server erreichen, während sie bei jedem Schritt nur die erforderlichen Daten und nur diese erhielten. Das Ergebnis ihrer Bemühungen war GraphQL, das auf der React Conf-Konferenz 2015 vorgestellt wurde. GraphQL ist eine Abfragebeschreibungssprache sowie eine Laufzeitumgebung für diese Abfragen.

Betrachten Sie einen typischen Ansatz für die Arbeit mit GraphQL-Servern.
Wir beschreiben das Schema
Das Datenschema in GraphQL definiert die Typen und Beziehungen zwischen ihnen und dies auf stark typisierte Weise. Stellen Sie sich zum Beispiel ein einfaches Modell eines sozialen Netzwerks vor.
User kennt Freunde
friends . Benutzer leben in der Stadt, und die Stadt kennt ihre Einwohner über das
citizens . Folgendes ist ein Graph eines solchen Modells in GraphQL:
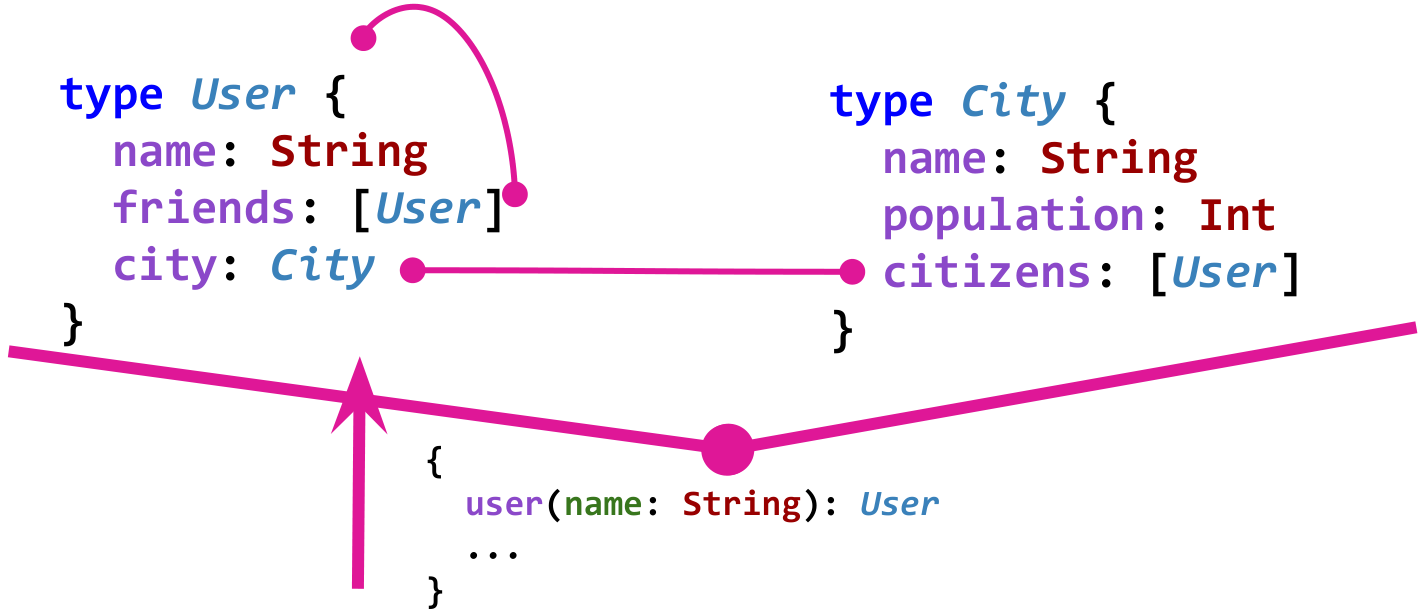
Damit das Diagramm nützlich ist, werden natürlich auch die sogenannten „Einstiegspunkte“ benötigt. Ein solcher Einstiegspunkt könnte beispielsweise darin bestehen, einen Benutzer mit Namen zu erhalten.
Daten anfordern
Mal sehen, was die GraphQL-Abfragesprache ausmacht. Lassen Sie uns diese Frage in diese Sprache übersetzen:
„Für einen Benutzer namens Vanya Unicorn möchte ich die Namen seiner Freunde sowie den Namen und die Bevölkerung der Stadt kennen, in der Vanya lebt.“ { user(name: "Vanya Unicorn") { friends { name } city { name population } } }
Und hier kommt die Antwort vom GraphQL-Server:
{ "data": { "user": { "friends": [ { "name": "Lena" }, { "name": "Stas" } ] "city": { "name": "Kyiv", "population": 2928087 } } } }
Beachten Sie, dass das Anforderungsformular mit dem Antwortformular übereinstimmt. Es besteht das Gefühl, dass diese Abfragesprache für JSON erstellt wurde. Mit starker Eingabe. All dies geschieht in einer HTTP-POST-Anforderung - Sie müssen nicht mehrere Anrufe beim Server tätigen.
Mal sehen, wie es in der Praxis aussieht. Öffnen wir die Standardkonsole für den GraphQL-Server, der als Graph
i QL ("graph") bezeichnet wird. Um einen Warenkorb anzufordern, erfülle ich die folgende Anfrage:
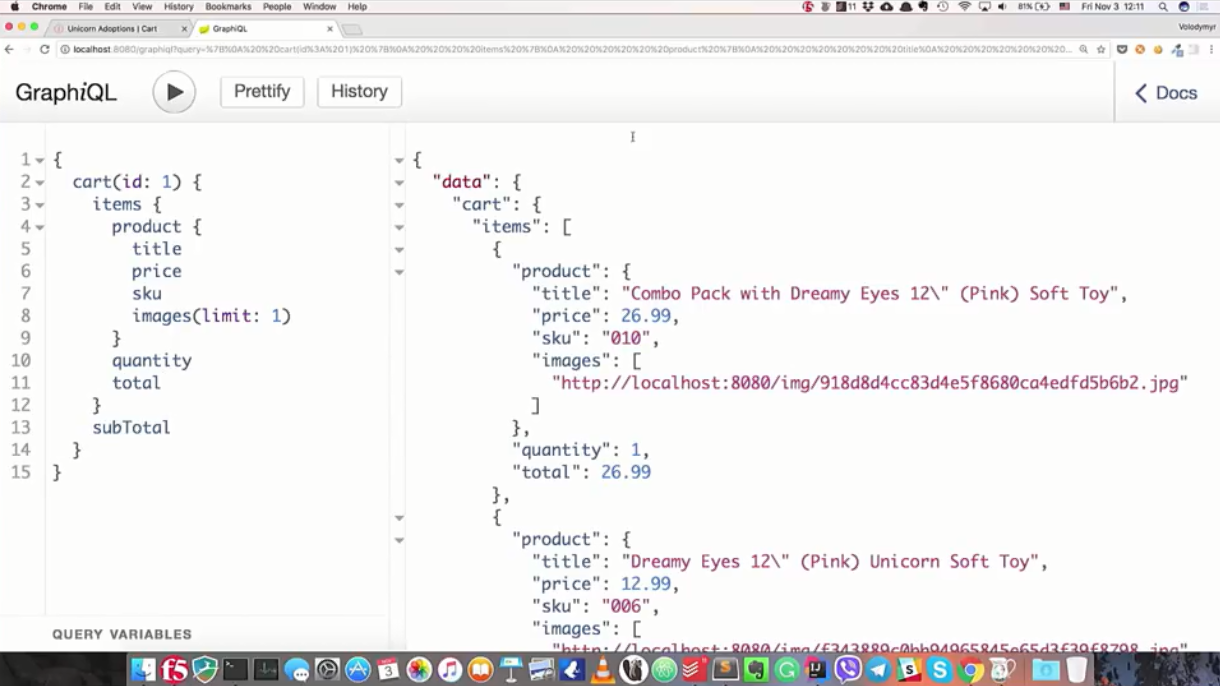
"Ich möchte einen Warenkorb mit der Kennung 1 erhalten. Ich interessiere mich für alle Positionen dieses Warenkorbs und für Produktinformationen." Aus den Informationen geht hervor, dass Name, Preis, Inventarnummer und Bilder wichtig sind (und nur die ersten). Ich interessiere mich auch für die Menge dieser Produkte, ihren Preis und die Gesamtkosten im Warenkorb .
" { cart(id: 1) { items { product { title price sku images(limit: 1) } quantity total } subTotal } }
Nach erfolgreichem Abschluss der Anfrage erhalten wir genau das, was gefragt wurde:
Hauptvorteile
- Flexible Probenahme. Der Kunde kann eine Anfrage für seine spezifischen Anforderungen stellen.
- Effektive Probenahme. Die Antwort gibt nur die angeforderten Daten zurück.
- Schnellere Entwicklung. Viele Änderungen auf dem Client können auftreten, ohne dass auf der Serverseite Änderungen vorgenommen werden müssen. Anhand unseres Beispiels können Sie beispielsweise ganz einfach eine andere Ansicht des Warenkorbs für das mobile Web anzeigen.
- Nützliche Analyse. Da der Client die Felder in der Anforderung explizit angeben muss, weiß der Server genau, welche Felder wirklich benötigt werden. Und dies sind wichtige Informationen für die Abschreibungspolitik.
- Funktioniert auf jeder Datenquelle und jedem Transport. Es ist wichtig, dass Sie mit GraphQL über jede Datenquelle und jeden Transport hinweg arbeiten können. In diesem Fall ist HTTP kein Allheilmittel, GraphQL kann auch über WebSocket funktionieren, und wir werden diesen Punkt etwas später ansprechen.
Heute kann ein GraphQL-Server in fast jeder Sprache erstellt werden. Die vollständigste Version des GraphQL-Servers ist
GraphQL.js für die Node-Plattform. In der Java-Community ist die Referenzimplementierung
GraphQL Java .
Erstellen Sie die GraphQL-API
Lassen Sie uns sehen, wie Sie einen GraphQL-Server anhand eines konkreten Lebensbeispiels erstellen.
Stellen Sie sich eine vereinfachte Version eines Online-Shops vor, die auf einer Microservice-Architektur mit zwei Komponenten basiert:
- Warenkorbservice für die Arbeit mit einem benutzerdefinierten Warenkorb. Speichert Daten in einer relationalen Datenbank und verwendet SQL für den Zugriff auf Daten. Sehr einfacher Service, ohne zu viel Magie :)
- Produkt-Service, der den Zugriff auf den Produktkatalog ermöglicht, aus dem tatsächlich der Warenkorb gefüllt wird. Bietet eine HTTP-API für den Zugriff auf Produktdaten.
Beide Dienste werden zusätzlich zum klassischen Spring Boot implementiert und enthalten bereits die gesamte Grundlogik.
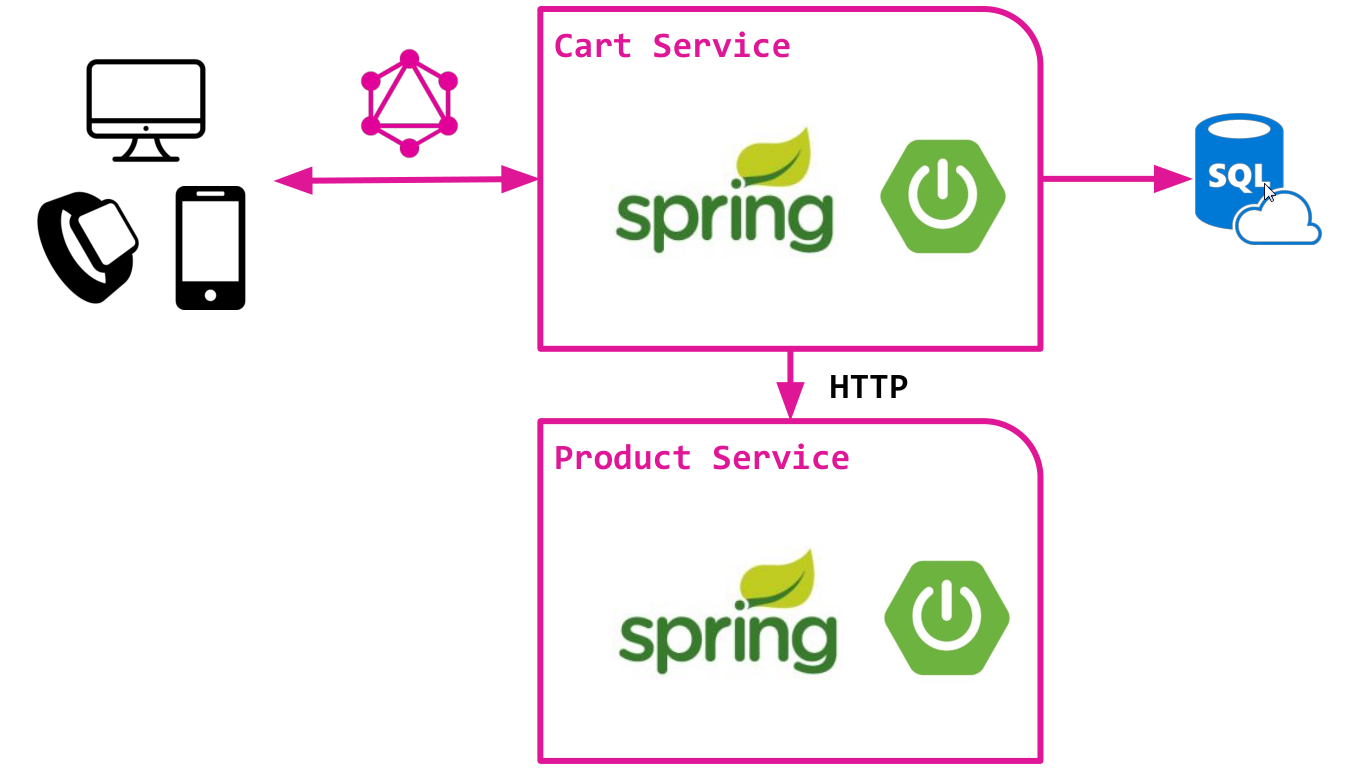
Wir beabsichtigen, die GraphQL-API zusätzlich zum Cart-Service zu erstellen. Diese API bietet Zugriff auf Warenkorbdaten und hinzugefügte Produkte.
Erste Version
Die bereits erwähnte GraphQL-Referenzimplementierung für das Java-Ökosystem - GraphQL Java - wird uns dabei helfen.
Fügen Sie
pom.xml: einige Abhängigkeiten hinzu
pom.xml: <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphql-java</artifactId> <version>9.3</version> </dependency> <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphql-java-tools</artifactId> <version>5.2.4</version> </dependency> <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphql-spring-boot-starter</artifactId> <version>5.0.2</version> </dependency> <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphiql-spring-boot-starter</artifactId> <version>5.0.2</version> </dependency>
Zusätzlich zu dem zuvor erwähnten
graphql-java benötigen wir eine
graphql-java-tools, Bibliothek mit
graphql-java-tools, sowie Spring Boot-Starter für GraphQL, die die ersten Schritte zum Erstellen eines GraphQL-Servers erheblich vereinfachen:
- graphql-spring-boot-Starter bietet einen Mechanismus zum schnellen Verbinden von GraphQL Java mit Spring Boot.
- graphiql-spring-boot-Starter fügt eine interaktive Graph i QL-Webkonsole hinzu, um GraphQL-Abfragen auszuführen.
Der nächste wichtige Schritt ist die Bestimmung des graphQL-Dienstschemas, unseres Graphen. Die Knoten dieses Diagramms werden mithilfe von
Typen und die Kanten mithilfe von
Feldern beschrieben . Eine leere Diagrammdefinition sieht folgendermaßen aus:
schema { }
Wie Sie sich erinnern, gibt es in diesem Schema „Einstiegspunkte“ oder Abfragen der obersten Ebene. Sie werden über das
Abfragefeld im Schema definiert. Rufen Sie unseren Typ für
EntryPoints- Einstiegspunkte an:
schema { query: EntryPoints }
Wir definieren darin eine Korbsuche nach Kennung als ersten Einstiegspunkt:
type EntryPoints { cart(id: Long!): Cart }
Cart ist in GraphQL nichts anderes als ein
Feld .
id ist ein Parameter dieses Feldes mit dem Skalartyp
Long . Ausrufezeichen
! Nach Angabe des Typs ist der Parameter erforderlich.
Es ist Zeit,
Cart zu identifizieren und
Cart :
type Cart { id: Long! items: [CartItem!]! subTotal: BigDecimal! }
Zusätzlich zur Standard-
id der Warenkorb seine
subTotal und den Betrag für alle
subTotal . Beachten Sie, dass
Elemente als Liste definiert
sind , wie in eckigen Klammern
[] . Elemente dieser Liste sind
CartItem Typen. Das Vorhandensein eines Ausrufezeichens nach dem Namen des Feldtyps
! zeigt an, dass das Feld erforderlich ist. Dies bedeutet, dass der Server zustimmt, einen nicht leeren Wert für dieses Feld zurückzugeben, wenn einer angefordert wurde.
Es bleibt die Definition des
CartItem Typs zu
CartItem , die einen Link zum Produkt (
productId ) enthält, wie oft es dem Warenkorb hinzugefügt wird (
quantity ) und die Menge des Produkts, berechnet anhand der Anzahl (
total ):
type CartItem { productId: String! quantity: Int! total: BigDecimal! }
Hier ist alles einfach - alle Felder von Skalartypen sind obligatorisch.
Dieses Schema wurde nicht zufällig gewählt. Der Cart-Service hat den Cart-Warenkorb und seine
CartItem Elemente bereits mit genau denselben Feldnamen und -typen wie im GraphQL-Schema definiert. Das Wagenmodell verwendet die Lombok-Bibliothek zum automatischen Generieren von Gettern / Setzern, Konstruktoren und anderen Methoden. JPA wird für die Persistenz in der Datenbank verwendet.
Cart :
import lombok.Data; import javax.persistence.*; import java.math.BigDecimal; import java.util.ArrayList; import java.util.List; @Entity @Data public class Cart { @Id @GeneratedValue private Long id; @ElementCollection(fetch = FetchType.EAGER) private List<CartItem> items = new ArrayList<>(); public BigDecimal getSubTotal() { return getItems().stream() .map(Item::getTotal) .reduce(BigDecimal.ZERO, BigDecimal::add); } }
CartItem Klasse:
import lombok.AllArgsConstructor; import lombok.Data; import javax.persistence.Column; import javax.persistence.Embeddable; import java.math.BigDecimal; @Embeddable @Data @AllArgsConstructor public class CartItem { @Column(nullable = false) private String productId; @Column(nullable = false) private int quantity; @Column(nullable = false) private BigDecimal total; }
Der Korb (
Cart ) und die Basket-Elemente (
CartItem ) werden daher sowohl im GraphQL-Diagramm als auch im Code beschrieben und sind je nach Feldsatz und Typ „miteinander kompatibel“. Dies reicht jedoch immer noch nicht aus, damit unser Service funktioniert.
Wir müssen genau klären, wie der Einstiegspunkt "
cart(id: Long!): Cart " funktioniert. Erstellen Sie dazu eine äußerst einfache Java-Konfiguration für Spring mit einer Bean vom Typ GraphQLQueryResolver. GraphQLQueryResolver beschreibt nur die "Einstiegspunkte" im Schema. Wir definieren eine Methode mit einem Namen, der mit dem Feld am Einstiegspunkt (
cart ) identisch ist, machen sie nach Parametertyp kompatibel und verwenden
cartService , um denselben Warenkorb anhand der Kennung zu finden:
@Bean public GraphQLQueryResolver queryResolver() { return new GraphQLQueryResolver () { public Cart cart(Long id) { return cartService.findCart(id); } } }
Diese Änderungen reichen aus, um eine funktionierende Anwendung zu erhalten. Nach dem Neustart des Cart-Dienstes in der GraphiQL-Konsole wird die folgende Abfrage erfolgreich ausgeführt:
{ cart(id: 1) { items { productId quantity total } subTotal } }
Hinweis
- Wir verwenden die Skalartypen
Long und String als eindeutige Kennungen für den Warenkorb und das Produkt. GraphQL hat für solche Zwecke einen speziellen Typ - ID . Semantisch ist dies eine bessere Wahl für eine echte API. Werte vom Typ ID können als Schlüssel für das Caching verwendet werden.
- In dieser Phase der Entwicklung unserer Anwendung sind die internen und externen Domänenmodelle vollständig identisch. Wir sprechen über die
CartItem Cart und CartItem und ihre direkte Verwendung in GraphQL-Resolvern. In Kampfanwendungen wird empfohlen, diese Modelle zu trennen. Für GraphQL-Resolver muss ein vom internen Themenbereich getrenntes Modell vorhanden sein.
Die API nützlich machen
Wir haben also das erste Ergebnis erzielt, und das ist wunderbar. Aber jetzt ist unsere API zu primitiv. Bisher gibt es beispielsweise keine Möglichkeit, nützliche Daten zu einem Produkt anzufordern, z. B. Name, Preis, Artikel, Bilder usw. Stattdessen gibt es nur eine
productId . Lassen Sie uns die API wirklich nützlich machen und das Produktkonzept vollständig unterstützen. So sieht seine Definition im Diagramm aus:
type Product { id: String! title: String! price: BigDecimal! description: String sku: String! images: [String!]! }
Fügen Sie
CartItem das erforderliche Feld
CartItem , und
productId Feld productId als veraltet:
type Item { quantity: Int! product: Product! productId: String! @deprecated(reason: "don't use it!") total: BigDecimal! }
Wir haben das Schema herausgefunden. Und jetzt ist es Zeit zu beschreiben, wie die Auswahl für das
product funktionieren wird. Wir haben uns zuvor auf Getter in den
CartItem Cart und
CartItem , mit denen GraphQL Java Werte automatisch binden konnte. An dieser Stelle sei jedoch daran erinnert, dass nur die
product in der
CartItem Klasse nicht:
@Embeddable @Data @AllArgsConstructor public class CartItem { @Column(nullable = false) private String productId; @Column(nullable = false) private int quantity; @Column(nullable = false) private BigDecimal total; }
Wir haben die Wahl:
- Fügen Sie die Produkteigenschaft zu CartItem hinzu und lernen Sie, wie Produktdaten empfangen werden.
- Bestimmen Sie, wie Sie das Produkt erhalten, ohne die CartItem- Klasse zu ändern.
Der zweite Weg ist vorzuziehen, da das Modell der Beschreibung der internen Domäne (
CartItem Klasse) in diesem Fall nicht mit Details zur Implementierung der Graph
i QL-API behandelt wird.
Um dieses Ziel zu erreichen, hilft die GraphQLResolver-Markierungsoberfläche. Durch die Implementierung können Sie festlegen (oder überschreiben), wie die Feldwerte für Typ
T So sieht die entsprechende Bean in der Spring-Konfiguration aus:
@Bean public GraphQLResolver<CartItem> cartItemResolver() { return new GraphQLResolver<CartItem>() { public Product product(CartItem item) { return http.getForObject("http://localhost:9090/products/{id}", Product.class, item.getProductId()); } }; }
Der Name der
product wurde nicht zufällig gewählt. GraphQL Java sucht nach Daten-Downloader-Methoden nach Feldnamen, und wir mussten nur einen Loader für das
product definieren! Ein als Parameter übergebenes Objekt vom Typ
CartItem definiert den Kontext, in dem das Produkt ausgewählt wird. Weiter ist eine Frage der Technologie. Mit einem
http Client wie
RestTemplate wir eine GET-Anforderung an den Produktservice und konvertieren das Ergebnis in ein
Product , das folgendermaßen aussieht:
@Data public class Product { private String id; private String title; private BigDecimal price; private String description; private String sku; private List<String> images; }
Diese Änderungen sollten ausreichen, um ein interessanteres Beispiel zu implementieren, das die tatsächliche Beziehung zwischen dem Warenkorb und den hinzugefügten Produkten enthält.
Nach dem Neustart der Anwendung können Sie eine neue Abfrage in der Graph
i QL-Konsole versuchen.
{ cart(id: 1) { items { product { title price sku images } quantity total } subTotal } }
Und hier ist das Ergebnis der Abfrageausführung:

Obwohl
productId als
@deprecated markiert wurde,
@deprecated Abfragen, die dieses Feld
@deprecated , weiterhin. Die Graph
i QL-Konsole bietet jedoch keine automatische Vervollständigung für solche Felder und hebt deren Verwendung auf besondere Weise hervor:

Es ist Zeit, den Dokument-Explorer anzuzeigen, der Teil der Graph
i QL-Konsole ist, die auf der Grundlage des GraphQL-Schemas erstellt wurde und Informationen zu allen definierten Typen anzeigt. So sieht der Dokument-Explorer für den
CartItem Typ aus:

Aber zurück zum Beispiel. Um die gleiche Funktionalität wie in der ersten Demo zu erreichen, ist die Anzahl der zurückgegebenen Bilder immer noch nicht ausreichend begrenzt. Für einen Warenkorb benötigen Sie beispielsweise nur ein Bild für jedes Produkt:
images(limit: 1)
Ändern Sie dazu das Schema und fügen Sie dem
Produkttyp einen neuen Parameter für das Bildfeld hinzu:
type Product { id: ID! title: String! price: BigDecimal! description: String sku: String! images(limit: Int = 0): [String!]! }
Und im Anwendungscode werden wir ihn wieder verwenden GraphQLResolver, nur diesmal nach Typ Product: @Bean public GraphQLResolver<Product> productResolver() { return new GraphQLResolver<Product>() { public List<String> images(Product product, int limit) { List<String> images = product.getImages(); int normalizedLimit = limit > 0 ? limit : images.size(); return images.subList(0, Math.min(normalizedLimit, images.size())); } }; }
Ich mache erneut darauf aufmerksam, dass der Name der Methode nicht zufällig ist: Er stimmt mit dem Namen des Feldes überein images. Das Kontextobjekt ermöglicht Productden Zugriff auf Bilder und limitist ein Parameter des Felds selbst.Wenn der Kunde nichts als Wert für angegeben hat limit, gibt unser Service alle Bilder des Produkts zurück. Wenn der Client einen bestimmten Wert angegeben hat, gibt der Service genau so viel zurück (jedoch nicht mehr als im Produkt enthalten).Wir kompilieren das Projekt und warten, bis der Server neu gestartet wird. Wenn Sie die Schaltung in der Konsole neu starten und die Anforderung ausführen, sehen Sie, dass eine vollständige Anforderung wirklich funktioniert. { cart(id: 1) { items { product { title price sku images(limit: 1) } quantity total } subTotal } }
Stimmen Sie zu, das alles ist sehr cool. In kurzer Zeit haben wir nicht nur gelernt, was GraphQL ist, sondern auch ein einfaches Microservice-System übertragen, um eine solche API zu unterstützen. Und es war uns egal, woher die Daten stammten: Sowohl die SQL- als auch die HTTP-APIs passen gut unter ein Dach.Code-First- und GraphQL SPQR-Ansatz
Möglicherweise haben Sie bemerkt, dass während des Entwicklungsprozesses einige Unannehmlichkeiten aufgetreten sind, nämlich die Notwendigkeit, das GraphQL-Schema und den Code ständig synchron zu halten. Typänderungen mussten immer an zwei Stellen durchgeführt werden. In vielen Fällen ist es bequemer, den Code-First-Ansatz zu verwenden. Das Wesentliche ist, dass das Schema für GraphQL automatisch aus dem Code generiert wird. In diesem Fall müssen Sie die Schaltung nicht separat warten. Jetzt werde ich zeigen, wie es aussieht.Nur die Grundfunktionen von GraphQL Java reichen uns nicht aus, wir benötigen auch die GraphQL SPQR-Bibliothek. Die gute Nachricht ist, dass GraphQL SPQR ein Add-On für GraphQL Java ist und keine alternative Implementierung des GraphQL-Servers in Java.Fügen Sie die gewünschte Abhängigkeit hinzu zu pom.xml: <dependency> <groupId>io.leangen.graphql</groupId> <artifactId>spqr</artifactId> <version>0.9.8</version> </dependency>
Hier ist der Code, der dieselbe GraphQL SPQR-basierte Funktionalität für den Warenkorb implementiert: @Component public class CartGraph { private final CartService cartService; @Autowired public CartGraph(CartService cartService) { this.cartService = cartService; } @GraphQLQuery(name = "cart") public Cart cart(@GraphQLArgument(name = "id") Long id) { return cartService.findCart(id); } }
Und für das Produkt: @Component public class ProductGraph { private final RestTemplate http; @Autowired public ProductGraph(RestTemplate http) { this.http = http; } @GraphQLQuery(name = "product") public Product product(@GraphQLContext CartItem cartItem) { return http.getForObject( "http://localhost:9090/products/{id}", Product.class, cartItem.getProductId() ); } @GraphQLQuery(name = "images") public List<String> images(@GraphQLContext Product product, @GraphQLArgument(name = "limit", defaultValue = "0") int limit) { List<String> images = product.getImages(); int normalizedLimit = limit > 0 ? limit : images.size(); return images.subList(0, Math.min(normalizedLimit, images.size())); } }
Die Annotation @GraphQLQuery wird verwendet, um Feldlademethoden zu kennzeichnen. Die Anmerkung @GraphQLContextdefiniert die Art der Auswahl für das Feld. Und die Anmerkung @GraphQLArgumentmarkiert deutlich die Argumentparameter. All dies sind Teile eines Mechanismus, mit dem GraphQL SPQR automatisch ein Schema generieren kann. Wenn Sie nun die alte Java-Konfiguration und das alte Java-Schema löschen und den Cart-Dienst mit den neuen Chips von GraphQL SPQR neu starten, können Sie sicherstellen, dass alles auf die gleiche Weise wie zuvor funktioniert.Wir lösen das Problem von N + 1
Es ist Zeit , zu b sehen auf lshih Detail , wie die Umsetzung der gesamten Anfrage „unter der Haube“. Wir haben die GraphQL-API schnell erstellt, aber funktioniert sie effizient?Betrachten Sie das folgende Beispiel: Das Abrufen des Warenkorbs
Abrufen des Warenkorbs carterfolgt in einer SQL-Abfrage an die Datenbank. Daten auf itemsund werden subtotaldort zurückgegeben, da die Warenkorbelemente mit der gesamten Sammlung geladen werden, basierend auf der eifrigen Abruf-JPA-Strategie: @Data public class Cart { @ElementCollection(fetch = FetchType.EAGER) private List<Item> items = new ArrayList<>(); ... }
 Wenn es darum geht, Daten zu Produkten herunterzuladen, werden Anfragen nach einem Produktservice genauso ausgeführt wie in diesem Produktkorb. Wenn sich drei verschiedene Produkte im Warenkorb befinden, erhalten wir drei Anfragen an die HTTP-API des Produktservices. Wenn zehn davon vorhanden sind, muss derselbe Service zehn solcher Anfragen beantworten.
Wenn es darum geht, Daten zu Produkten herunterzuladen, werden Anfragen nach einem Produktservice genauso ausgeführt wie in diesem Produktkorb. Wenn sich drei verschiedene Produkte im Warenkorb befinden, erhalten wir drei Anfragen an die HTTP-API des Produktservices. Wenn zehn davon vorhanden sind, muss derselbe Service zehn solcher Anfragen beantworten. Hier ist die Kommunikation zwischen dem Cart-Service und dem Product-Service in Charles Proxy:
Hier ist die Kommunikation zwischen dem Cart-Service und dem Product-Service in Charles Proxy: Dementsprechend kehren wir zum klassischen N + 1-Problem zurück. Genau die, von der sie sich am Anfang des Berichts so sehr bemüht haben, wegzukommen. Zweifellos haben wir Fortschritte, da genau eine Anforderung zwischen dem Endclient und unserem System ausgeführt wird. Innerhalb des Server-Ökosystems muss die Leistung jedoch deutlich verbessert werden.Ich möchte dieses Problem lösen, indem ich alle richtigen Produkte in einer Anfrage erhalte. Glücklicherweise unterstützt der Produktservice diese Funktion bereits über einen Parameter
Dementsprechend kehren wir zum klassischen N + 1-Problem zurück. Genau die, von der sie sich am Anfang des Berichts so sehr bemüht haben, wegzukommen. Zweifellos haben wir Fortschritte, da genau eine Anforderung zwischen dem Endclient und unserem System ausgeführt wird. Innerhalb des Server-Ökosystems muss die Leistung jedoch deutlich verbessert werden.Ich möchte dieses Problem lösen, indem ich alle richtigen Produkte in einer Anfrage erhalte. Glücklicherweise unterstützt der Produktservice diese Funktion bereits über einen Parameter idsin der Erfassungsressource: GET /products?ids=:id1,:id2,...,:idn
Lassen Sie uns sehen, wie Sie den Beispielmethodencode für das Produktfeld ändern können . Vorherige Version: @GraphQLQuery(name = "product") public Product product(@GraphQLContext CartItem cartItem) { return http.getForObject( "http://localhost:9090/products/{id}", Product.class, cartItem.getProductId() ); }
Ersetzen Sie durch eine effektivere: @GraphQLQuery(name = "product") @Batched public List<Product> products(@GraphQLContext List<Item> items) { String productIds = items.stream() .map(Item::getProductId) .collect(Collectors.joining(",")); return http.getForObject( "http://localhost:9090/products?ids={ids}", Products.class, productIds ).getProducts(); }
Wir haben genau drei Dinge getan:- markierte die Bootloader-Methode mit der Annotation @Batched , um GraphQL SPQR klar zu machen, dass das Laden mit einem Stapel erfolgen sollte;
- Der Rückgabetyp und der Kontextparameter wurden in eine Liste geändert, da bei der Arbeit mit dem Stapel davon ausgegangen wird, dass mehrere Objekte akzeptiert und zurückgegeben werden.
- änderte den Hauptteil der Methode und implementierte eine Auswahl aller erforderlichen Produkte gleichzeitig.
Diese Änderungen reichen aus, um unser N + 1-Problem zu lösen. Das Charles Proxy-Anwendungsfenster zeigt jetzt eine Anforderung an den Produktservice an, der drei Produkte gleichzeitig zurückgibt:
Effektive Feldproben
Wir haben das Hauptproblem gelöst, aber Sie können die Auswahl noch schneller treffen! Jetzt gibt der Produktservice alle Daten zurück, unabhängig davon, was der Endkunde benötigt. Wir könnten die Abfrage verbessern und nur die angeforderten Felder zurückgeben. Wenn der Endkunde beispielsweise nicht nach dem Bild gefragt hat, warum müssen wir sie dann an den Warenkorbservice übertragen?Es ist großartig, dass die HTTP-API des Produktservices diese Funktion bereits über den Parameter include für dieselbe Erfassungsressource unterstützt: GET /products?ids=...?include=:field1,:field2,...,:fieldN
Fügen Sie für die Bootloader-Methode einen Parameter vom Typ Set with annotation hinzu @GraphQLEnvironment. GraphQL SPQR versteht, dass der Code in diesem Fall eine Liste von Feldnamen "anfordert", die für das Produkt angefordert werden, und diese automatisch ausfüllt: @GraphQLQuery(name = "product") @Batched public List<Product> products(@GraphQLContext List<Item> items, @GraphQLEnvironment Set<String> fields) { String productIds = items.stream() .map(Item::getProductId) .collect(Collectors.joining(",")); return http.getForObject( "http://localhost:9090/products?ids={ids}&include={fields}", Products.class, productIds, String.join(",", fields) ).getProducts(); }
Jetzt ist unsere Stichprobe wirklich effektiv, ohne das N + 1-Problem und verwendet nur die erforderlichen Daten:
"Schwere" Anfragen
Stellen Sie sich vor, Sie arbeiten mit einem Benutzerdiagramm in einem klassischen sozialen Netzwerk wie Facebook. Wenn ein solches System die GraphQL-API bereitstellt, hindert nichts den Client daran, eine Anforderung der folgenden Art zu senden: { user(name: "Vova Unicorn") { friends { name friends { name friends { name friends { name ... } } } } } }
Auf der Verschachtelungsebene 5-6 führt die vollständige Implementierung einer solchen Anforderung zu einer Auswahl aller Benutzer auf der Welt. Der Server wird eine solche Aufgabe sicherlich nicht in einer Sitzung bewältigen können und höchstwahrscheinlich einfach „fallen“.Es gibt eine Reihe von Maßnahmen, die ergriffen werden müssen, um sich vor solchen Situationen zu schützen:- Anfragetiefe begrenzen. Mit anderen Worten, Kunden sollten nicht die Möglichkeit haben, Daten einer beliebigen Verschachtelung anzufordern.
- Begrenzen Sie die Komplexität der Anforderung. Indem Sie jedem Feld eine Gewichtung zuweisen und die Summe der Gewichte aller Felder in der Anforderung berechnen, können Sie solche Anforderungen auf dem Server akzeptieren oder ablehnen.
Betrachten Sie beispielsweise die folgende Abfrage: { cart(id: 1) { items { product { title } quantity } subTotal } }
Offensichtlich beträgt die Tiefe einer solchen Anforderung 4, da sich der längste Pfad darin befindet cart -> items -> product -> title.Wenn wir davon ausgehen, dass die Gewichtung jedes Felds 1 beträgt, beträgt die Komplexität unter Berücksichtigung von 7 Feldern in der Abfrage ebenfalls 7.In GraphQL Java wird die Überlagerung von Prüfungen durch Angabe zusätzlicher Instrumente beim Erstellen des Objekts erreicht GraphQL: GraphQL.newGraphQL(schema) .instrumentation(new ChainedInstrumentation(Arrays.asList( new MaxQueryComplexityInstrumentation(20), new MaxQueryDepthInstrumentation(3) ))) .build();
Die Instrumentierung MaxQueryDepthInstrumentationüberprüft die Tiefe der Anforderung und lässt nicht zu, dass zu "tiefe" Anforderungen gestartet werden (in diesem Fall mit einer Tiefe von mehr als 3).Die Instrumentierung MaxQueryComplexityInstrumentationvor der Ausführung einer Abfrage zählt und überprüft ihre Komplexität. Wenn diese Zahl den angegebenen Wert (20) überschreitet, wird eine solche Anforderung abgelehnt. Sie können das Gewicht für jedes Feld neu definieren, da einige von ihnen offensichtlich "härter" werden als andere. Beispielsweise kann dem Produktfeld durch die @GraphQLComplexity,in GraphQL SPQR unterstützte Anmerkung die Komplexität 10 zugewiesen werden : @GraphQLQuery(name = "product") @GraphQLComplexity("10") public List<Product> products(...)
Hier ist ein Beispiel für eine Tiefenprüfung, wenn sie den angegebenen Wert deutlich überschreitet: Übrigens ist der Instrumentierungsmechanismus nicht darauf beschränkt, Einschränkungen aufzuerlegen. Es kann auch für andere Zwecke verwendet werden, z. B. zum Protokollieren oder Verfolgen.Wir haben die für GraphQL spezifischen Schutzmaßnahmen untersucht. Es gibt jedoch eine Reihe von Tricks, die unabhängig von der Art der API beachtet werden sollten:
Übrigens ist der Instrumentierungsmechanismus nicht darauf beschränkt, Einschränkungen aufzuerlegen. Es kann auch für andere Zwecke verwendet werden, z. B. zum Protokollieren oder Verfolgen.Wir haben die für GraphQL spezifischen Schutzmaßnahmen untersucht. Es gibt jedoch eine Reihe von Tricks, die unabhängig von der Art der API beachtet werden sollten:- Drosselung / Ratenbegrenzung - Begrenzen Sie die Anzahl der Anforderungen pro Zeiteinheit
- Zeitüberschreitungen - Zeitlimit für Operationen mit anderen Diensten, Datenbanken usw.;
- Paginierung - Paginierungsunterstützung.
Mutation von Daten
Bisher haben wir eine reine Datenerfassung in Betracht gezogen. Mit GraphQL können Sie jedoch nicht nur den Empfang von Daten, sondern auch deren Änderung organisch organisieren. Dafür gibt es einen Mechanismus mutation: schema { query: EntryPoints, mutation: Mutations }
Das Hinzufügen eines Produkts zu einem Warenkorb kann beispielsweise durch die folgende Mutation organisiert werden: type Mutations { addProductToCart(cartId: Long!, productId: String!, count: Int = 1): Cart }
Dies ähnelt dem Definieren eines Felds, da eine Mutation auch Parameter und einen Rückgabewert enthält.Die Implementierung einer Mutation im Servercode mit GraphQL SPQR ist wie folgt: @GraphQLMutation(name = "addProductToCart") public Cart addProductToCart( @GraphQLArgument(name = "cartId") Long cartId, @GraphQLArgument(name = "productId") String productId, @GraphQLArgument(name = "quantity", defaultValue = "1") int quantity) { return cartService.addProductToCart(cartId, productId, quantity); }
Natürlich wird der größte Teil der nützlichen Arbeit intern erledigt cartService. Die Aufgabe dieser Interlayer-Methode besteht darin, sie der API zuzuordnen. Wie bei der Datenerfassung ist dank Anmerkungen @GraphQL*sehr leicht zu verstehen, welches GraphQL-Schema aus dieser Methodendefinition generiert wird.In der GraphQL-Konsole können Sie jetzt eine Mutationsanforderung ausführen, um ein bestimmtes Produkt in einer Menge von 2 in unseren Warenkorb zu legen: mutation { addProductToCart( cartId: 1, productId: "59eb83c0040fa80b29938e3f", quantity: 2) { items { product { title } quantity total } subTotal } }
Da die Mutation einen Rückgabewert hat, ist es möglich, Felder nach denselben Regeln wie bei normalen Stichproben anzufordern.Mehrere WIX-Entwicklungsteams verwenden GraphQL aktiv mit Scala und der Sangria-Bibliothek, der Hauptimplementierung von GraphQL in dieser Sprache.Eine der nützlichen Techniken in WIX ist die Unterstützung von GraphQL-Abfragen beim Rendern von HTML. Wir tun dies, um JSON direkt im Seitencode zu generieren. Hier ist ein Beispiel zum Füllen einer HTML-Vorlage: // Pre-rendered <html> <script data-embedded-graphiql> { product(productId: $productId) title description price ... } } </script> </html>
Und hier ist die Ausgabe: // Rendered <html> <script> window.DATA = { product: { title: 'GraphQL Sticker', description: 'High quality sticker', price: '$2' ... } } </script> </html>
Eine solche Kombination aus HTML-Renderer und GraphQL-Server ermöglicht es uns, unsere API maximal wiederzuverwenden und keine zusätzliche Ebene von Controllern zu erstellen. Darüber hinaus erweist sich diese Technik häufig als vorteilhaft für die Leistung, da die JavaScript-Anwendung nach dem Laden der Seite nicht für die ersten erforderlichen Daten zum Backend gehen muss - sie befindet sich bereits auf der Seite.Nachteile von GraphQL
Heute nutzt GraphQL eine große Anzahl von Unternehmen, darunter Giganten wie GitHub, Yelp, Facebook und viele andere. Und wenn Sie sich entscheiden, sich ihrer Nummer anzuschließen, sollten Sie nicht nur die Vorteile von GraphQL kennen, sondern auch die Nachteile, und es gibt viele davon:- -, GraphQL . GraphQL , HTTP API. Cache-Control Last-Modified HTTP GraphQL API. , proxy gateways (Varnish, Fastly ). , GraphQL , , .
- GraphQL — . , API, , .
- GraphQL . .
- . GraphQL — . JSON XML, , , GraphQL, .
- GraphQL . , HTTP PUT POST -. , . GraphQL . .
- . , -: «delete» «kill», «annihilate» «terminate», . GraphQL API . HTTP DELETE .
- Joker 2016 . GraphQL . API- , , , HATEOAS, , « REST». , , GraphQL .
Denken Sie auch daran, dass Sie die GraphQL-API höchstwahrscheinlich nicht entwickeln können, wenn es Ihnen nicht gelungen ist, die HTTP-API gut zu entwickeln. Was ist schließlich bei der Entwicklung einer API am wichtigsten? Trennen Sie das interne Domänenmodell vom externen API-Modell. Erstellen Sie eine API basierend auf Verwendungsszenarien, nicht auf dem internen Gerät der Anwendung. Öffnen Sie nur die erforderlichen Mindestinformationen und nicht alle hintereinander. Wählen Sie die richtigen Namen. Beschreiben Sie das Diagramm richtig. In der HTTP-API gibt es ein Ressourcendiagramm und in der GraphQL-API ein Felddiagramm. In beiden Fällen muss dieses Diagramm qualitativ erstellt werden.In der HTTP-API-Welt gibt es Alternativen, und Sie müssen GraphQL nicht immer verwenden, wenn Sie komplexe Auswahlen benötigen. Zum Beispiel gibt es den OData-Standard, der teilweise und expandierende Auswahlen wie GraphQL unterstützt und auf HTTP aufbaut. Es gibt eine Standard-JSON-API, die mit JSON zusammenarbeitet und Hypermedia- und komplexe Abruffunktionen unterstützt. Es gibt auch LinkRest, über das Sie mehr aus dem https://youtu.be/EsldBtrb1Qc "> Bericht von Andrus Adamchik über Joker 2017 erfahren können .Für diejenigen, die GraphQL ausprobieren möchten, empfehle ich dringend, Vergleichsartikel von Ingenieuren zu lesen, die sich gut auskennen REST und GraphQL aus praktischer und philosophischer Sicht:Zum Schluss über Abonnements und Aufschub
GraphQL hat einen interessanten Vorteil gegenüber Standard-APIs. In GraphQL können sowohl synchrone als auch asynchrone Anwendungsfälle unter einem Dach sitzen.Wir haben überlegt, Daten über Sie zu empfangen queryund den Status des Servers durch zu ändern mutation, aber es gibt noch eine weitere Güte. Zum Beispiel die Möglichkeit, Abonnements zu organisieren subscriptions.Stellen Sie sich vor, ein Kunde möchte Benachrichtigungen über das asynchrone Hinzufügen eines Produkts zum Warenkorb erhalten. Über die GraphQL-API kann dies basierend auf einem solchen Schema erfolgen: schema { query: Queries, mutation: Mutations, subscription: Subscriptions } type Subscriptions { productAdded(cartId: String!): Cart }
Der Kunde kann sich über folgende Anfrage anmelden: subscription { productAdded(cart: 1) { items { product ... } subTotal } }
Jedes Mal, wenn ein Produkt zum Warenkorb 1 hinzugefügt wird, sendet der Server jedem abonnierten Client eine Nachricht in WebSocket mit den angeforderten Daten im Warenkorb. Wenn Sie die GraphQL-Richtlinie fortsetzen, werden nur die Daten angezeigt, die der Client beim Abonnieren angefordert hat: { "data": { "productAdded": { "items": [ { "product": …, "subTotal": … }, { "product": …, "subTotal": … }, { "product": …, "subTotal": … }, { "product": …, "subTotal": … } ], "subTotal": 289.33 } } }
Der Kunde kann jetzt den Warenkorb neu zeichnen, nicht unbedingt die gesamte Seite.Dies ist praktisch, da sowohl die synchrone API (HTTP) als auch die asynchrone API (WebSocket) über GraphQL beschrieben werden können.Ein weiteres Beispiel für die Verwendung der asynchronen Kommunikation ist der Verzögerungsmechanismus . Die Hauptidee ist, dass der Client auswählt, welche Daten er sofort (synchron) empfangen möchte und welche er später (asynchron) empfangen möchte. Zum Beispiel für eine solche Anfrage: query { feedStories { author { name } message comments @defer { author { name } message } } }
Der Server gibt zuerst den Autor und eine Nachricht für jede Geschichte zurück: { "data": { "feedStories": [ { "author": …, "message": … }, { "author": …, "message": … } ] } }
Danach sendet der Server, nachdem er Daten zu Kommentaren erhalten hat, diese asynchron über WebSocket an den Client und gibt im Pfad an, für den Verlaufskommentare jetzt bereit sind: { "path": [ "feedStories", 0, "comments" ], "data": [ { "author": …, "message": … } ] }
Beispielquelle
Der zur Erstellung dieses Berichts verwendete Code befindet sich auf GitHub .Zuletzt haben wir JPoint 2019 angekündigt , das vom 5. bis 6. April 2019 stattfinden wird. In unserem Hub erfahren Sie mehr darüber, was Sie von der Konferenz erwarten können . Bis zum 1. Dezember sind Early Bird-Tickets noch zum niedrigsten Preis erhältlich.