Erstellen von Client-Routing / semantischer Suche und Clustering beliebiger externer Korpusse bei Profi.ru.
TLDR
Dies ist eine sehr kurze Zusammenfassung (oder ein Teaser) darüber, was wir in ungefähr 2 Monaten in der Profi.ru DS-Abteilung geschafft haben (ich war etwas länger dort, aber mich und mein Team einzubinden war eine separate Sache zuerst gemacht).
Projizierte Ziele
- Verstehen Sie die Eingabe / Absicht des Clients und leiten Sie die Clients entsprechend weiter (wir haben uns am Ende für einen agnostischen Klassifikator für die Eingabequalität entschieden, obwohl wir auch Modelle mit Char-Level und Sprachmodellen in Betracht gezogen haben. Einfachheitsregeln);
- Finden Sie völlig neue Dienste und Synonyme für die vorhandenen Dienste.
- Als Teilziel von (2) - lernen, richtige Cluster auf beliebigen externen Korpussen aufzubauen;
Ziele erreicht
Offensichtlich wurden einige dieser Ergebnisse nicht nur von unserem Team erzielt, sondern auch von mehreren Teams (d. H. Wir haben den Scraping-Teil für Domain-Korpusse und die manuelle Annotation offensichtlich nicht durchgeführt, obwohl ich glaube, dass das Scraping auch von unserem Team gelöst werden kann - Sie brauchen es nur genug Proxies + wahrscheinlich etwas Erfahrung mit Selen).
Geschäftsziele:
- ~
88+% (gegenüber ~ 60% bei elastischer Suche) Genauigkeit bei Client-Routing / Intent-Klassifizierung (~ 5k Klassen); - Die Suche ist unabhängig von der Eingabequalität (Druckfehler / Teileingabe).
- Der Klassifikator verallgemeinert, die morphologische Struktur der Sprache wird ausgenutzt;
- Der Klassifikator schlägt die elastische Suche bei verschiedenen Benchmarks deutlich (siehe unten).
- Um auf der sicheren Seite zu sein - es wurden mindestens
1,000 neue Dienste gefunden + mindestens 15,000 Synonyme (gegenüber dem aktuellen Stand von 5,000 + ~ 30,000 ). Ich erwarte, dass sich diese Zahl verdoppelt oder sogar verdreifacht;
Die letzte Kugel ist eine Schätzung des Baseballstadions, aber eine konservative.
Auch AB-Tests werden folgen. Aber ich bin von diesen Ergebnissen überzeugt.
"Wissenschaftliche" Ziele:
- Wir haben viele moderne Satzeinbettungstechniken unter Verwendung einer nachgeschalteten Klassifizierungsaufgabe + KNN gründlich mit einer Datenbank von Dienstsynonymen verglichen.
- Wir haben es geschafft, die schwach überwachte elastische Suche in diesem Benchmark (siehe Details unten) mit UNSUPERVISED- Methoden zu schlagen (im Wesentlichen ist ihr Klassifikator ein Beutel mit Gramm).
- Wir haben eine neuartige Methode entwickelt, um angewandte NLP-Modelle zu erstellen (eine einfache Vanille-Bi-LSTM + -Tüte mit Einbettungen, im Wesentlichen schneller Text entspricht RNN) - dies berücksichtigt die Morphologie der russischen Sprache und verallgemeinert sich gut;
- Wir haben gezeigt, dass unsere endgültige Einbettungstechnik (eine Flaschenhalsschicht des besten Klassifikators) in Kombination mit modernsten unbeaufsichtigten Algorithmen (UMAP + HDBSCAN) Sternhaufen erzeugen kann.
- Wir haben in der Praxis die Möglichkeit, Durchführbarkeit und Verwendbarkeit von:
- Wissensdestillation;
- Erweiterungen für Textdaten (sic!);
- Das Training textbasierter Klassifikatoren mit dynamischen Erweiterungen reduzierte die Konvergenzzeit drastisch (10x) im Vergleich zur Erzeugung größerer statischer Datensätze (d. H. Das CNN lernt, den Fehler zu verallgemeinern, der angezeigt wird, wenn drastisch weniger erweiterte Sätze angezeigt werden).
Gesamtprojektstruktur
Dies schließt den endgültigen Klassifikator nicht ein.
Auch am Ende haben wir gefälschte RNN- und Triplett-Verlust-Modelle zugunsten des Klassifikator-Engpasses aufgegeben.

Was funktioniert jetzt in NLP?
Eine Vogelperspektive:

Vielleicht wissen Sie auch, dass NLP jetzt den Imagenet-Moment erlebt.
UMAP-Hack in großem Maßstab
Beim Erstellen von Clustern stießen wir auf einen Weg / Hack, um UMAP im Wesentlichen auf Datensätze mit einer Größe von über 100 m (oder vielleicht sogar 1 Mrd.) anzuwenden. Erstellen Sie im Wesentlichen ein KNN-Diagramm mit FAISS und schreiben Sie dann einfach die UMAP-Hauptschleife mithilfe Ihrer GPU in PyTorch neu. Wir haben das nicht gebraucht und das Konzept aufgegeben (wir hatten immerhin nur 10-15 Millionen Punkte), aber bitte folgen Sie diesem Thread für Details.
Was funktioniert am besten
- Für die überwachte Klassifizierung erfüllt Fast-Text die RNN (Bi-LSTM) + sorgfältig ausgewählte Menge von n-Gramm;
- Implementierung - einfaches Python für n-Gramm + PyTorch Embedding Bag Layer;
- Für das Clustering - die Engpassschicht dieses Modells + UMAP + HDBSCAN;
Beste Klassifikator-Benchmarks
Manuell kommentierter Entwickler-Set
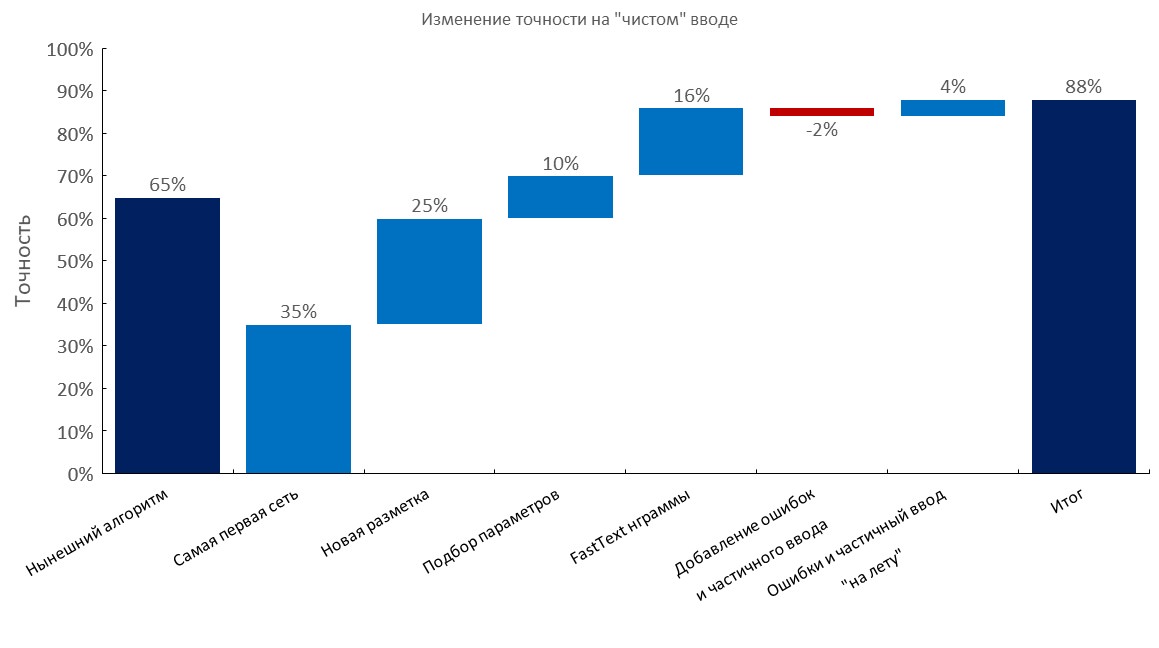
Von links nach rechts:
(Top1 Genauigkeit)
- Aktueller Algorithmus (elastische Suche);
- Erste RNN;
- Neue Anmerkung;
- Tuning
- Fast-Text-Einbettungsbeutelschicht;
- Hinzufügen von Tippfehlern und Teileingaben;
- Dynamische Erzeugung von Fehlern und Teileingabe ( Trainingszeit um das 10-fache reduziert );
- Endergebnis;
Manuell kommentierte Entwicklermenge + 1-3 Fehler pro Abfrage

Von links nach rechts:
(Top1 Genauigkeit)
- Aktueller Algorithmus (elastische Suche);
- Fast-Text-Einbettungsbeutelschicht;
- Hinzufügen von Tippfehlern und Teileingaben;
- Dynamische Erzeugung von Fehlern und Teileingabe;
- Endergebnis;
Manuell kommentierter Dev Set + Teileingabe
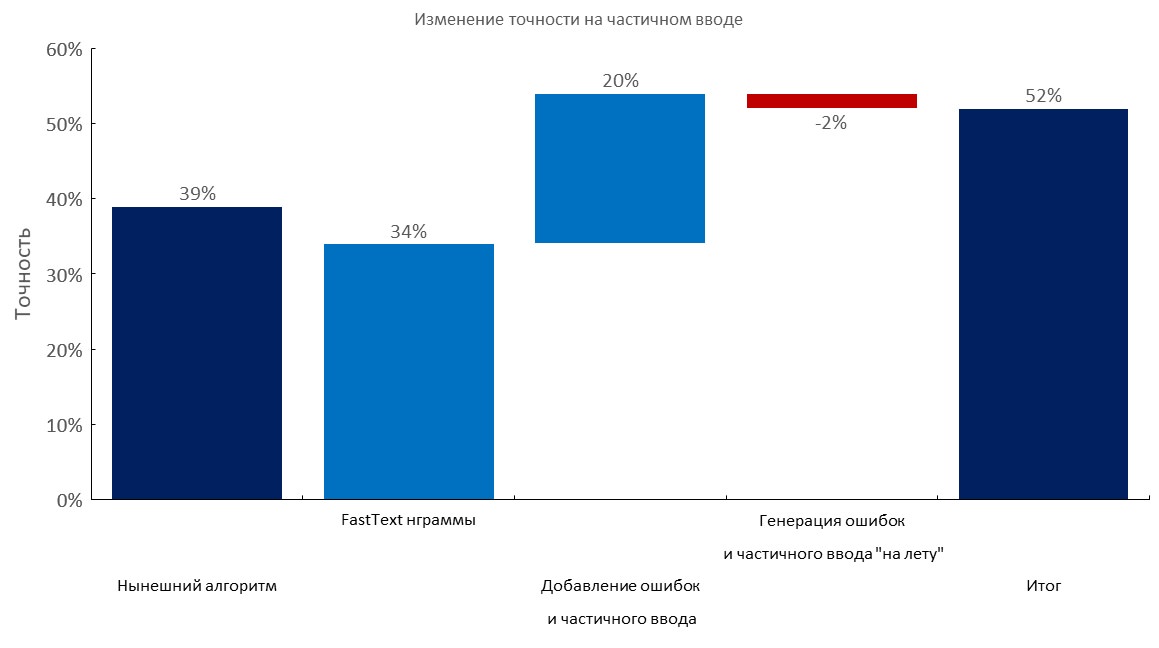
Von links nach rechts:
(Top1 Genauigkeit)
- Aktueller Algorithmus (elastische Suche);
- Fast-Text-Einbettungsbeutelschicht;
- Hinzufügen von Tippfehlern und Teileingaben;
- Dynamische Erzeugung von Fehlern und Teileingabe;
- Endergebnis;
Große Korpusse / n-Gramm-Auswahl
- Wir haben die größten Korpusse für die russische Sprache gesammelt:
- Areneum - eine verarbeitete Version ist hier verfügbar - die Autoren des Datensatzes haben nicht geantwortet.
- Taiga
- Allgemeines Crawlen und Wiki - bitte folgen Sie diesen Artikeln;
- Wir haben ein
100m Wörterbuch mit 1 TB Crawl gesammelt. - Verwenden Sie diesen Hack auch , um solche Dateien schneller (über Nacht) herunterzuladen.
- Wir haben einen optimalen Satz von
1m n-Gramm für unseren Klassifikator ausgewählt, um ihn am besten zu verallgemeinern ( 500k beliebteste n-Gramm aus schnellem Text, der auf russischer Wikipedia trainiert wurde, + 500k beliebteste n-Gramm in unseren Domain-Daten).
Stresstest unserer 1M n-Gramm auf 100M Vokabeln:

Texterweiterungen
Kurz gesagt:
- Nehmen Sie ein großes Wörterbuch mit Fehlern (z. B. 10-100 m eindeutige Wörter);
- Generieren Sie einen Fehler (lassen Sie einen Buchstaben fallen, tauschen Sie einen Buchstaben mit berechneten Wahrscheinlichkeiten aus, fügen Sie einen zufälligen Buchstaben ein, verwenden Sie möglicherweise das Tastaturlayout usw.);
- Überprüfen Sie, ob das neue Wort im Wörterbuch enthalten ist.
Wir haben viele Anfragen an Dienste wie diesen brutal gestellt (um ihren Datensatz im Wesentlichen rückzuentwickeln), und sie enthalten ein sehr kleines Wörterbuch (auch dieser Dienst wird von einem Baumklassifizierer mit n-Gramm-Funktionen unterstützt). Es war irgendwie lustig zu sehen, dass sie nur 30-50% der Wörter abdeckten, die wir auf einigen Korpussen hatten .
Unser Ansatz ist weit überlegen, wenn Sie Zugriff auf ein großes Domain-Vokabular haben .
Beste unbeaufsichtigte / halbüberwachte Ergebnisse
KNN diente als Benchmark zum Vergleich verschiedener Einbettungsmethoden.
(Vektorgröße) Liste der getesteten Modelle:
- (512) Falscher Satzdetektor in großem Maßstab, der auf 200 GB allgemeiner Durchforstungsdaten trainiert ist;
- (300) Fälschungssatzdetektor, der darauf trainiert ist, einen zufälligen Satz aus Wikipedia von einem Dienst zu unterscheiden;
- (300) Von hier erhaltener Fast-Text, der auf Araneum Corpus vorab trainiert wurde;
- (200) Fast-Text, der auf unseren Domain-Daten trainiert wurde;
- (300) Fast-Text, der auf 200 GB Common Crawl-Daten trainiert wurde;
- (300) Ein siamesisches Netzwerk mit Triplettverlust, das mit Diensten / Synonymen / zufälligen Sätzen aus Wikipedia trainiert wurde;
- (200) Erste Iteration der Einbettungsschicht des Einbettungsbeutels RNN, ein Satz wird als ein ganzer Beutel mit Einbettungen codiert;
- (200) Gleich, aber zuerst wird der Satz in Wörter aufgeteilt, dann wird jedes Wort eingebettet, dann wird der Durchschnitt genommen;
- (300) Wie oben, jedoch für das endgültige Modell;
- (300) Wie oben, jedoch für das endgültige Modell;
- (250) Engpassschicht des endgültigen Modells (250 Neuronen);
- Schwach überwachte elastische Suchgrundlinie;
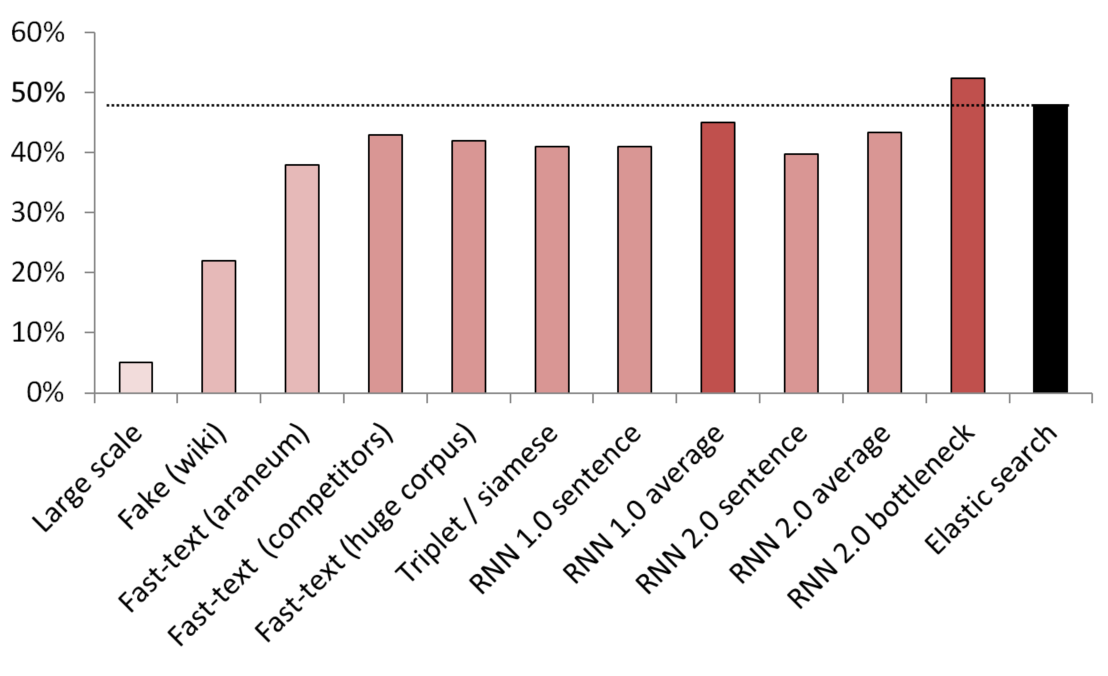
Um Undichtigkeiten zu vermeiden, wurden alle zufälligen Sätze zufällig ausgewählt. Ihre Länge in Worten entsprach der Länge der Dienste / Synonyme, mit denen sie verglichen wurden. Es wurden auch Maßnahmen ergriffen, um sicherzustellen, dass Modelle nicht nur durch Trennen von Vokabeln lernten (Einbettungen wurden eingefroren, Wikipedia wurde unterabgetastet, um sicherzustellen, dass in jedem Wikipedia-Satz mindestens ein Domain-Wort enthalten war).
Cluster-Visualisierung
3D

2D

Cluster-Exploration "Schnittstelle"
Grün - neues Wort / Synonym.
Grauer Hintergrund - wahrscheinlich neues Wort.
Grauer Text - vorhandenes Synonym.

Ablationstests und was funktioniert, was wir versucht haben und was nicht
- Siehe die obigen Tabellen;
- Einfacher Durchschnitt / tf-idf Durchschnitt der Einbettungen in schnellen Text - eine SEHR beeindruckende Basislinie ;
- Fast-Text> Word2Vec für Russisch;
- Satzeinbettung durch falsche Satzerkennung funktioniert, verblasst aber im Vergleich zu anderen Methoden;
- BPE (Satzstück) zeigte keine Verbesserung unserer Domain;
- Char-Level-Modelle hatten trotz des widerrufenen Papiers von Google Schwierigkeiten, sich zu verallgemeinern.
- Wir haben versucht, einen Mehrkopf-Transformator (mit Klassifikator- und Sprachmodellierungsköpfen) zu verwenden, aber die zur Verfügung stehende Anmerkung ergab ungefähr die gleiche Leistung wie einfache Vanille-LSTM-basierte Modelle. Als wir zur Einbettung schlechter Ansätze übergingen, gaben wir diese Forschungsrichtung auf, da der Transformator weniger praktisch und unpraktisch war, einen LM-Kopf zusammen mit einer Einbettungsbeutelschicht zu haben.
- BERT - scheint übertrieben zu sein, auch einige Leute behaupten, dass Transformatoren buchstäblich wochenlang trainieren;
- ELMO - Die Verwendung einer Bibliothek wie AllenNLP erscheint meiner Meinung nach sowohl in Forschungs- / Produktions- als auch in Bildungsumgebungen aus Gründen, die ich hier nicht angeben werde, kontraproduktiv.
Bereitstellen
Fertig mit:
- Docker-Container mit einem einfachen Web-Service;
- Nur CPU für Inferenz ist ausreichend;
- ~
2.5 ms pro Abfrage auf der CPU, Batching nicht wirklich notwendig; - ~
1GB RAM-Speicherplatz; - Fast keine Abhängigkeiten, außer
PyTorch , numpy und pandas (und Webserver ofc). - Imitieren Sie eine solche Fast-Text-N-Gramm-Generation.
- Einbetten von Bag Layer + Indizes, wie sie gerade in einem Wörterbuch gespeichert wurden;