In großen Diensten bedeutet das Lösen eines Problems mithilfe von maschinellem Lernen, nur einen Teil der Arbeit zu erledigen. Das Einbetten von ML-Modellen ist nicht so einfach, und das Erstellen von CI / CD-Prozessen um sie herum ist noch schwieriger. Auf der Yandex-Konferenz
„Data & Science: Das Anwendungsprogramm“ sprach Adam Eldarov
, Leiter Data Science bei YouDo, darüber, wie man den Lebenszyklus von Modellen verwaltet, Umschulungs- und Umschulungsprozesse einrichtet, skalierbare Mikrodienste entwickelt und vieles mehr.
- Beginnen wir mit der Einführung. Es gibt einen Datenwissenschaftler, der Code in das Jupyter-Notizbuch schreibt, Feature-Engineering, Kreuzvalidierung und Modellmodelle trainiert. Die Geschwindigkeit wächst.

Aber irgendwann versteht er: Um dem Unternehmen einen geschäftlichen Wert zu verleihen, muss er die Lösung irgendwo in der Produktion an eine mythische Produktion anhängen, die uns viele Probleme bereitet. Der Laptop, den wir in den meisten Fällen in der Produktion gesehen haben, kann nicht gesendet werden. Und es stellt sich die Frage, wie dieser Code im Laptop an einen bestimmten Dienst gesendet werden kann. In den meisten Fällen müssen Sie einen Dienst mit einer API schreiben. Oder sie kommunizieren über PubSub, über Warteschlangen.

Wenn wir Empfehlungen aussprechen, müssen wir häufig Modelle trainieren und neu trainieren. Dieser Prozess muss überwacht werden. In diesem Fall muss immer sowohl der Code selbst als auch die Modelle mit Tests überprüft werden, damit unser Modell nicht in einem Moment verrückt wird und nicht immer anfängt, Null vorherzusagen. Es muss auch bei echten Benutzern durch AB-Tests überprüft werden - was wir besser oder zumindest nicht schlechter gemacht haben.
Wie nähern wir uns dem Code? Wir haben GitLab. Unser gesamter Code ist in viele kleine Bibliotheken aufgeteilt, die ein bestimmtes Domänenproblem lösen. Gleichzeitig handelt es sich um ein separates GitLab-Projekt, eine Git-Versionskontrolle und das GitFlow-Verzweigungsmodell. Wir verwenden Dinge wie Pre-Commit-Hooks, damit Sie keinen Code festschreiben können, der unsere statistischen Testprüfungen nicht erfüllt. Und die Tests selbst, Unit-Tests. Wir verwenden für sie den eigenschaftsbasierten Testansatz.

Wenn Sie Tests schreiben, meinen Sie normalerweise, dass Sie eine Testfunktion und die Argumente haben, die Sie mit Ihren Händen erstellen, einige Beispiele und welche Werte Ihre Testfunktion zurückgibt. Dies ist unpraktisch. Der Code ist aufgeblasen, viele sind im Prinzip zu faul, um ihn zu schreiben. Infolgedessen haben wir eine Menge Code, der durch Tests aufgedeckt wurde. Eigenschaftsbasiertes Testen impliziert, dass alle Ihre Argumente eine bestimmte Verteilung haben. Lassen Sie uns phasenweise vorgehen und alle unsere Argumente aus diesen Verteilungen häufig testen, die zu testende Funktion mit diesen Argumenten aufrufen und das Ergebnis dieser Funktion auf bestimmte Eigenschaften überprüfen. Infolgedessen haben wir viel weniger Code und gleichzeitig gibt es viel mehr Tests.
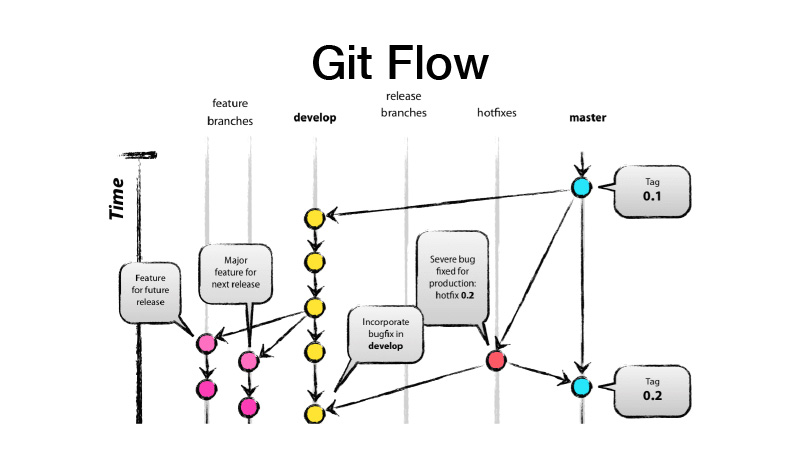
Was ist GitFlow? Dies ist ein Verzweigungsmodell, das impliziert, dass Sie zwei Hauptzweige haben - Entwickeln und Mastern, in denen sich der produktionsbereite Code befindet, und die gesamte Entwicklung in dem Entwicklungszweig ausgeführt wird, in dem alle neuen Funktionen von Feature-Brunchs stammen. Das heißt, jedes Feature ist ein neuer Feature-Brunch, während der Feature-Brunch kurzlebig und endgültig sein sollte - auch durch Feature-Toggle abgedeckt. Wir machen dann eine Veröffentlichung von dev, werfen die Änderungen auf master und setzen das Versions-Tag unserer Bibliothek oder unseres Dienstes darauf.
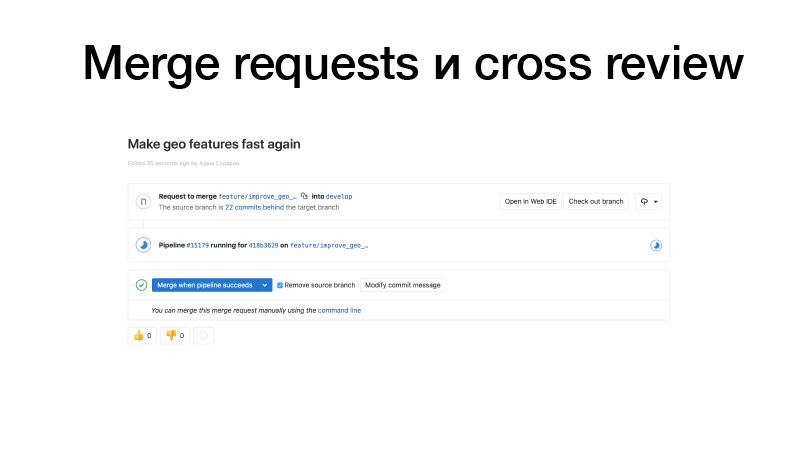
Wir entwickeln, sägen einige Funktionen, übertragen sie an GitLab und erstellen eine Zusammenführungsanforderung vom Feature-Brunch an Jungfrauen. Trigger funktionieren, Tests ausführen, wenn alles in Ordnung ist, können wir es einfrieren. Aber nicht wir halten es, sondern jemand aus dem Team. Es überarbeitet den Code und erhöht dadurch den Busfaktor. Dieser Codeabschnitt ist bereits zwei Personen bekannt. Wenn jemand von einem Bus angefahren wird, weiß jemand bereits, was er tut.

Die kontinuierliche Integration von Bibliotheken sieht normalerweise wie ein Test auf Änderungen aus. Und wenn wir es veröffentlichen, wird es auch auf dem privaten PyPI-Server unseres Pakets veröffentlicht.
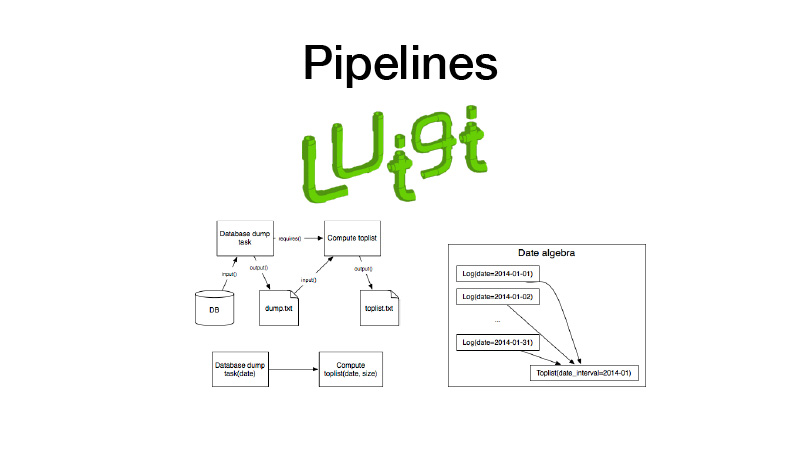
Weiter können wir es in Pipelines sammeln. Dafür nutzen wir die Luigi-Bibliothek. Es funktioniert mit einer Entität wie einer Aufgabe, die eine Ausgabe hat, in der das während der Ausführung der Aufgabe erzeugte Artefakt gespeichert wird. Es gibt einen Task-Parameter, der die von ihm ausgeführte Geschäftslogik parametrisiert, die Task und ihre Ausgabe identifiziert. Gleichzeitig haben Aufgaben immer Anforderungen, die andere Aufgaben stellen. Wenn wir eine Aufgabe ausführen, werden alle Abhängigkeiten durch Überprüfen der Ausgaben überprüft. Wenn die Ausgabe vorhanden ist, startet unsere Abhängigkeit nicht. Wenn das Artefakt in einem Speicher fehlt, wird es gestartet. Dies bildet eine Pipeline, einen gerichteten zyklischen Graphen.
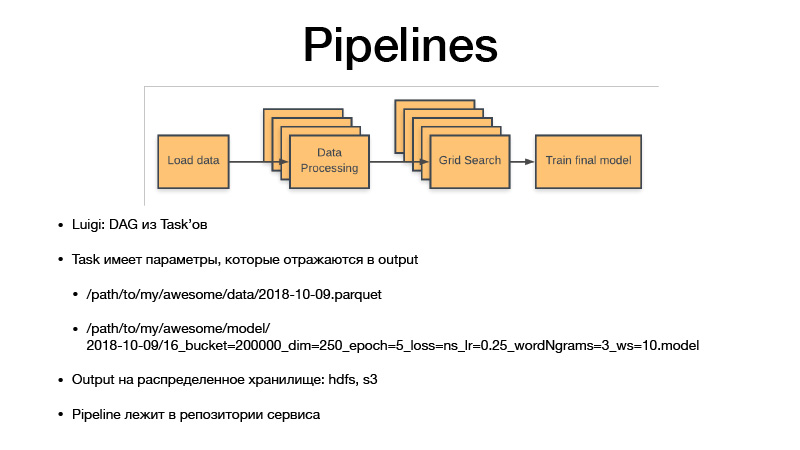
Alle Parameter identifizieren die Geschäftslogik. Dabei identifizieren sie das Artefakt. Es ist immer ein Datum mit einer gewissen Granularität, Empfindlichkeit oder einer Woche, einem Tag, einer Stunde oder drei Stunden. Wenn wir ein Modell trainieren, hat Luigi taska immer Hyperparameter dieser Aufgabe, sie lecken in das von uns produzierte Artefakt, Hyperparameter spiegeln sich im Namen des Artefakts wider. Daher versionieren wir im Wesentlichen alle Zwischendatensätze und endgültigen Artefakte, und sie werden niemals überschrieben, sondern nur für den Speicher verwendet. Der Speicher ist HDFS und S3 privat, wobei die endgültigen Artefakte einiger Gurken, Modelle oder etwas anderem angezeigt werden . Der gesamte Pipeline-Code befindet sich im Serviceprojekt in dem Repository, auf das er sich bezieht.

Es muss irgendwie behoben werden. Der HashiCorp-Stack kommt zur Rettung, wir verwenden Terraform, um die Infrastruktur in Form von Code zu deklarieren, Vault, um Geheimnisse zu verwalten, es gibt alle Passwörter, Erscheinungen in der Datenbank. Consul ist ein Erkennungsdienst, der über den Schlüsselwertspeicher verteilt wird und den Sie zum Konfigurieren verwenden können. Außerdem führt Consul Integritätsprüfungen Ihrer Knoten und Ihrer Dienste durch und überprüft deren Verfügbarkeit.
Und - Nomade. Es ist ein Orchestrierungssystem, das Ihre Dienste und eine Art Batch-Job vergießt.
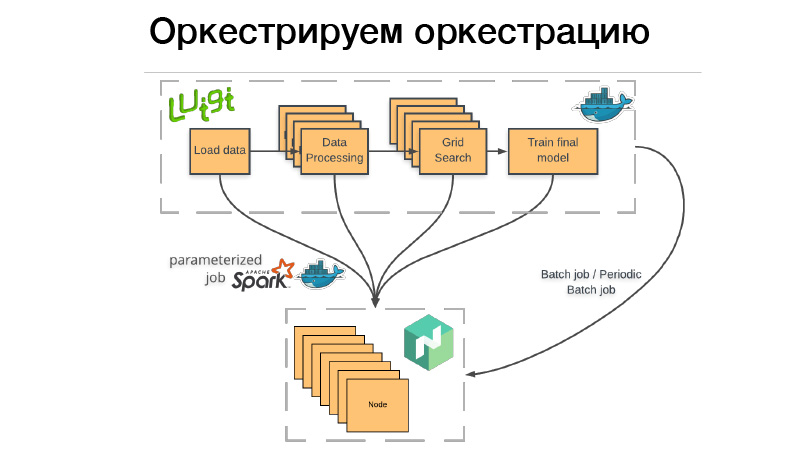
Wie nutzen wir das? Es gibt eine Luigi-Pipeline, die wir in den Docker-Container packen, den Schläger oder den periodischen Batch-Job in Nomad ablegen. Stapeljob - dies ist etwas erledigt, vorbei, und wenn alles erfolgreich ist - alles ist in Ordnung, können wir es manuell erneut starten. Aber wenn etwas schief gelaufen ist, versucht Nomad es erneut, bis der Versuch erschöpft ist oder es nicht erfolgreich endet.
Periodischer Stapeljob - das ist genau das gleiche, funktioniert nur nach einem Zeitplan.
Es gibt ein Problem. Wenn wir einen Container für ein Orchestrierungssystem bereitstellen, müssen wir angeben, wie viel Speicher dieser Container, diese CPU oder dieser Speicher benötigt. Wenn wir eine Pipeline haben, die drei Stunden lang läuft, verbrauchen zwei Stunden 10 GB RAM, 1 Stunde - 70 GB. Wenn wir das Limit überschreiten, das wir ihm gegeben haben, kommt der Docker-Daemon und tötet Docker und (nrzb.) [02:26:13] Wir möchten nicht ständig aus dem Speicher herausholen, daher müssen wir alle 70 GB angeben, die maximale Speicherlast. Aber hier ist das Problem: Alle 70 GB für drei Stunden werden zugewiesen und sind für keinen anderen Job zugänglich.
Deshalb sind wir den anderen Weg gegangen. Unsere gesamte Luigi-Pipeline startet keine Geschäftslogik, sondern startet lediglich eine Reihe von Würfeln in Nomad, dem sogenannten parametrisierten Job. Tatsächlich ist dies ein Analogon der Serverfunktionen (NRZB.) [02:26:39], AVS Lambda, wer weiß. Wenn wir eine Bibliothek erstellen, stellen wir unseren gesamten Code über CI in Form von parametrisierten Jobs bereit, dh einem Container mit einigen Parametern. Angenommen, Lite JBM Classifier enthält einen Parameter zum Pfad zu den Eingabedaten für das Training, Hyperparameter der Modelle und den Pfad zu den Ausgabeartefakten. All dies ist in Nomad registriert, und dann können wir aus der Luigi-Pipeline alle diese Nomad-Jobs über die API abrufen, während Luigi sicherstellt, dass nicht dieselbe Aufgabe viele Male ausgeführt wird.
Angenommen, wir haben dieselbe Textverarbeitung. Es gibt 10 bedingte Modelle, und wir möchten die Textverarbeitung nicht jedes Mal neu starten. Es wird nur einmal gestartet und gleichzeitig wird jedes Mal, wenn es wiederverwendet wird, ein fertiges Ergebnis angezeigt. Gleichzeitig funktioniert dies alles auf verteilte Weise. Wir können eine riesige Rastersuche in einem großen Cluster durchführen und haben nur Zeit, Gusseisen zu verwenden.
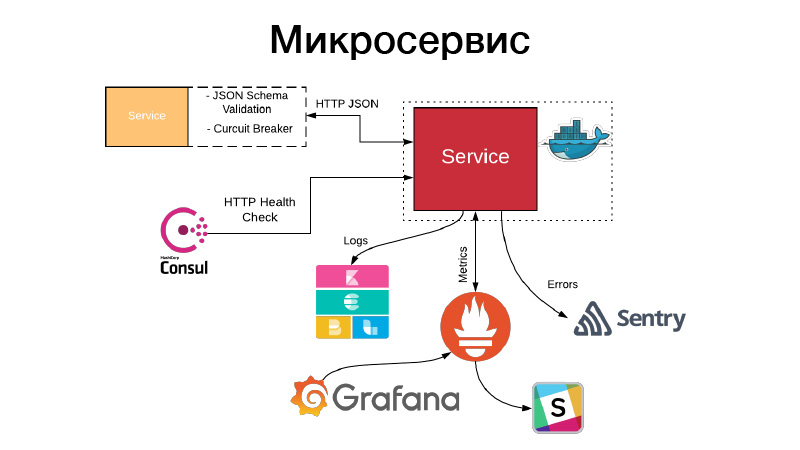
Wir haben ein Artefakt, wir müssen dies irgendwie in Form eines Dienstes arrangieren. Dienste stellen entweder eine HTTP-API bereit oder kommunizieren über Warteschlangen. In diesem Beispiel ist dies die HTTP-API, das einfachste Beispiel. Gleichzeitig validiert die Kommunikation mit dem Dienst oder unser Dienst mit anderen Diensten über die HTTP-JSON-API das JSON-Schema. Der Dienst selbst beschreibt immer ein JSON-Objekt in der Dokumentation für seine API und das Schema dieses Objekts. Es werden jedoch nicht immer alle Felder des JSON-Objekts benötigt. Daher werden verbrauchergesteuerte Verträge validiert. Dieses Schema wird validiert. Die Kommunikation erfolgt über den Leistungsschalter, um zu verhindern, dass unser verteiltes System aufgrund von Kaskadenfehlern ausfällt.
Gleichzeitig muss der Dienst eine HTTP-Integritätsprüfung festlegen, damit Consul die Verfügbarkeit dieses Dienstes überprüfen kann. Gleichzeitig kann Nomad es so gestalten, dass es einen Dienst für drei Hallo-Checks hintereinander gibt. Es kann den Dienst neu starten, um ihm zu helfen. Der Dienst schreibt alle seine Protokolle im JSON-Format. Wir verwenden den JSON-Protokollierungstreiber und den Elastics-Stack. An jedem Punkt nimmt FileBit einfach alle JSON-Protokolle und wirft sie in den Protokollcache. Von dort gelangen sie zu Elastic. Wir können KBan analysieren. Gleichzeitig verwenden wir keine Protokolle zum Sammeln von Metriken und zum Erstellen von Dashboards. Dies ist ineffizient. Wir verwenden hierfür das Prometheus-Entoring-System. Wir haben einen Prozess zum Erstellen von Vorlagen für jeden Dashboard-Service und können technische Metriken analysieren, die vom Service erstellt werden.
Wenn etwas schief gelaufen ist, werden Warnungen angezeigt, die jedoch in den meisten Fällen nicht ausreichen. Sentry hilft uns, dies ist eine Sache für die Vorfallanalyse. Tatsächlich erfassen wir alle Fehlerstufenprotokolle vom Sentry-Handler und übertragen sie in Sentry. Und dann gibt es einen detaillierten Traceback, es gibt alle Informationen darüber, in welcher Umgebung sich der Dienst befand, in welcher Version, welche Funktionen von welchen Argumenten aufgerufen wurden und welche Variablen in diesem Bereich mit welchen Werten versehen waren. Alle Konfigurationen, all dies ist sichtbar und es hilft sehr, schnell zu verstehen, was passiert ist, und den Fehler zu beheben.
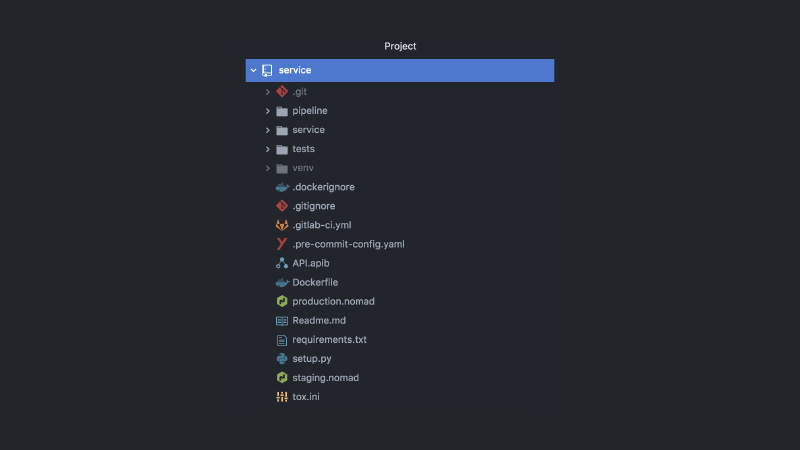
Infolgedessen sieht der Service ungefähr so aus. Separates GitLab-Projekt, Pipeline-Code, Testcode, Service-Code selbst, eine Reihe verschiedener Konfigurationen, Nomad, CI-Konfigurationen, API-Dokumentation, Commit-Hooks und mehr.
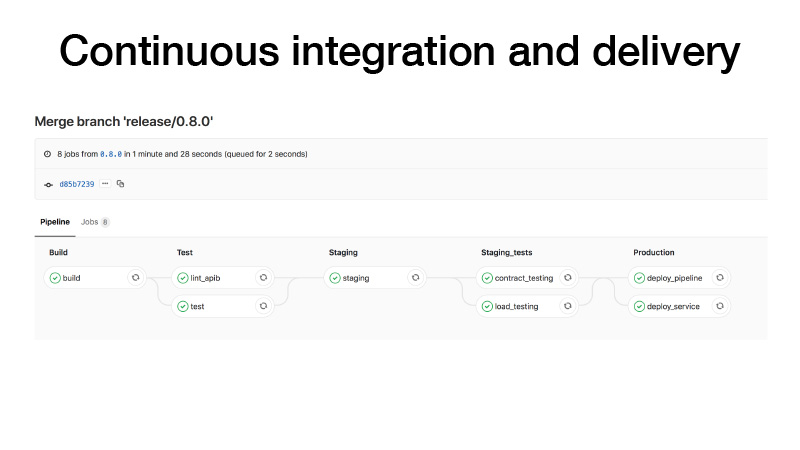
CI: Wenn wir ein Release erstellen, gehen wir folgendermaßen vor: Erstellen Sie einen Container, führen Sie Tests durch, werfen Sie einen Cluster auf eine Bühne, führen Sie dort einen Testvertrag für unseren Service aus, führen Sie Stresstests durch, um sicherzustellen, dass unsere Vorhersage nicht zu langsam ist, und halten Sie die Last, die wir denken . Wenn alles in Ordnung ist, werden wir diesen Service für die Produktion bereitstellen. Und es gibt zwei Möglichkeiten: Wir können die Pipeline bereitstellen, wenn der periodische Stapeljob irgendwo im Hintergrund funktioniert und Artefakte erzeugt, oder wenn wir mit den Stiften eine Pipeline auslösen, ein Modell trainieren, danach verstehen wir, dass alles in Ordnung ist und stellen Sie den Dienst bereit.

Was passiert sonst noch in diesem Fall? Ich sagte, dass es bei der Entwicklung von Feature-Brunchs ein solches Paradigma gibt, wie Feature-Toggles. Auf eine gute Weise müssen Sie Features mit einigen Umschaltern abdecken, um ein Feature im Kampf zu reduzieren, wenn etwas schief gelaufen ist. Wir können dann alle Funktionen in Release-Zügen sammeln und selbst wenn die Funktionen noch nicht fertig sind, können wir sie bereitstellen. Nur Feature-Toggle wird deaktiviert. Da wir alle Data Scientists sind, möchten wir auch AV-Tests durchführen. Angenommen, wir haben LightGBM durch CatBoost ersetzt. Wir möchten dies überprüfen, aber gleichzeitig wird der AV-Test unter Bezugnahme auf eine Benutzer-ID verwaltet. Das Umschalten von Funktionen ist an die Benutzer-ID gebunden und besteht somit den AV-Test. Wir müssen diese Metriken hier überprüfen.
Alle Dienste werden für Nomad bereitgestellt. Wir haben zwei Nomad-Produktionscluster - einen für Batch-Jobs und einen für Services.
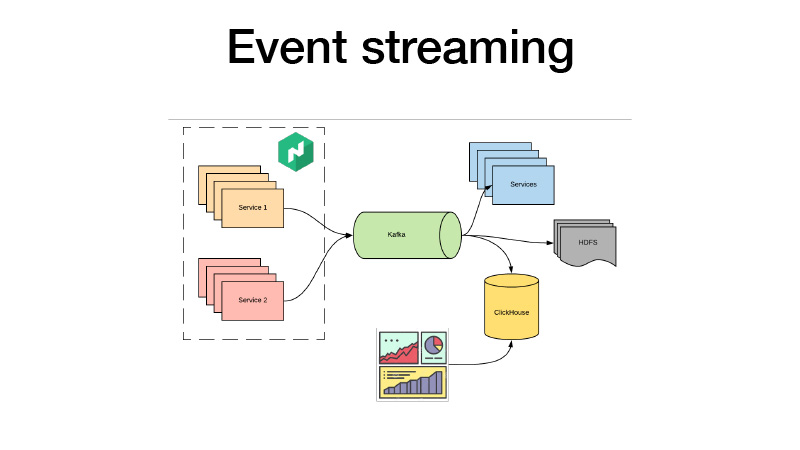
Sie schieben alle ihre Geschäftsveranstaltungen nach Kafka. Von dort können wir sie abholen. Im Wesentlichen handelt es sich um eine Lammarchitektur. Wir können HDFS mit einigen Diensten abonnieren, Echtzeitanalysen durchführen und gleichzeitig ClickHouse einbinden und Dashboards erstellen, um alle Geschäftsereignisse für unsere Dienste zu analysieren. Wir können AV-Tests analysieren, was auch immer.
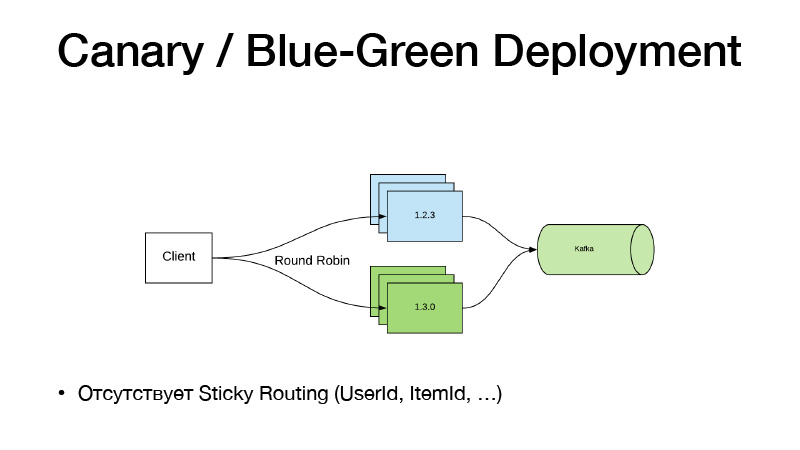
Und wenn wir den Code nicht geändert haben, verwenden Sie keine Feature-Toggles. Wir haben gerade angefangen, mit einigen Stiften an einer Pipeline zu arbeiten. Er hat uns ein neues Modell beigebracht. Wir haben einen neuen Weg dorthin. Wir ändern einfach den Nomad-Pfad zum Modell in der Konfiguration, geben den neuen Dienst frei, und hier hilft uns das Canary Deployment-Paradigma. Es ist sofort in Nomad verfügbar.
Wir haben die aktuelle Version des Dienstes in drei Fällen. Wir sagen, wir wollen drei Kanarienvögel - drei weitere Repliken neuer Versionen werden bereitgestellt, ohne die alten zu reduzieren. Infolgedessen beginnt sich der Verkehr in zwei Teile aufzuteilen. Ein Teil des Datenverkehrs entfällt auf neue Versionen von Diensten. Alle Dienste senden alle ihre Geschäftsereignisse an Kafka. Als Ergebnis können wir Metriken in Echtzeit analysieren.
Wenn alles in Ordnung ist, können wir sagen, dass alles in Ordnung ist. Bei der Bereitstellung wird Nomad alle alten Versionen vorsichtig ausschalten und neue skalieren.
Dieses Modell ist insofern schlecht, als wir das Versionsrouting durch eine Entität, User Item, binden müssen. Ein solches Schema funktioniert nicht, da der Verkehr durch Round-Robin ausgeglichen wird. Deshalb sind wir den folgenden Weg gegangen und haben den Service in zwei Teile zersägt.
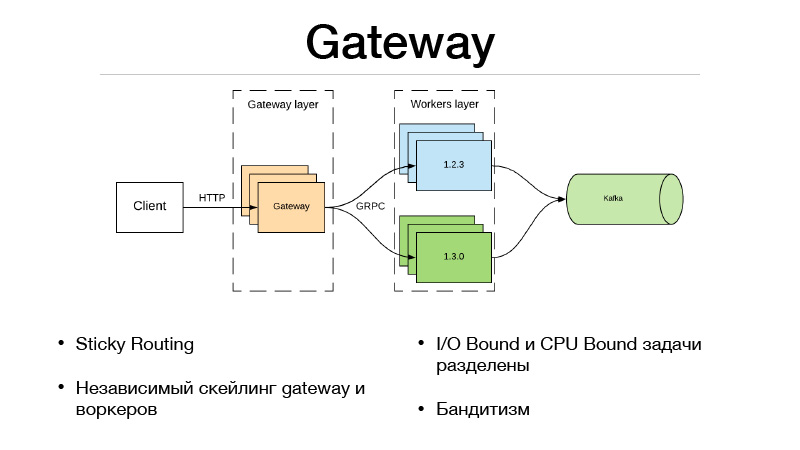
Dies ist die Gateway-Schicht und die Worker-Schicht. Der Client kommuniziert über HTTP mit der Gateway-Schicht. Die gesamte Logik der Versionsauswahl und des Datenverkehrsausgleichs befindet sich im Gateway. Gleichzeitig befinden sich alle E / A-gebundenen Aufgaben, die zum Abschließen des Prädikats erforderlich sind, auch im Gateway. Angenommen, wir erhalten eine Benutzer-ID im Prädikat in der Anforderung, die wir mit einigen Informationen anreichern müssen. Wir müssen andere Microservices abrufen und alle Informationen, Funktionen oder Grundlagen abrufen. Infolgedessen geschieht dies alles im Gateway. Er kommuniziert mit Arbeitern, die nur im Modell sind, und tut eines - eine Vorhersage. Ein- und Ausgabe.
Da wir unseren Service jedoch in zwei Teile aufteilten, trat aufgrund eines Remote-Netzwerkanrufs Overhead auf. Wie kann man es nivellieren? Das JRPC-Framework von Google, das RPC von Google, das auf HTTP2 ausgeführt wird, hilft dabei. Sie können Multiplexing und Komprimierung verwenden. JPRC verwendet Protobuff. Dies ist ein stark typisiertes Binärprotokoll mit schneller Serialisierung und Deserialisierung.
Dadurch haben wir auch die Möglichkeit, Gateway und Worker unabhängig voneinander zu skalieren. Angenommen, wir können eine bestimmte Anzahl offener HTTP-Verbindungen nicht beibehalten. Okay, das Gateway skalieren. Unsere Vorhersage ist zu langsam, wir haben keine Zeit, die Last zu halten - ok, wir skalieren die Arbeiter. Dieser Ansatz passt sehr gut zu mehrarmigen Banditen. Da in Gateway die gesamte Logik des Verkehrsausgleichs implementiert ist, kann es zu externen Microservices gehen und dort alle Statistiken für jede Version entnehmen sowie Entscheidungen zum Ausgleich des Verkehrs treffen. Angenommen, Sie verwenden Thompson Sampling.
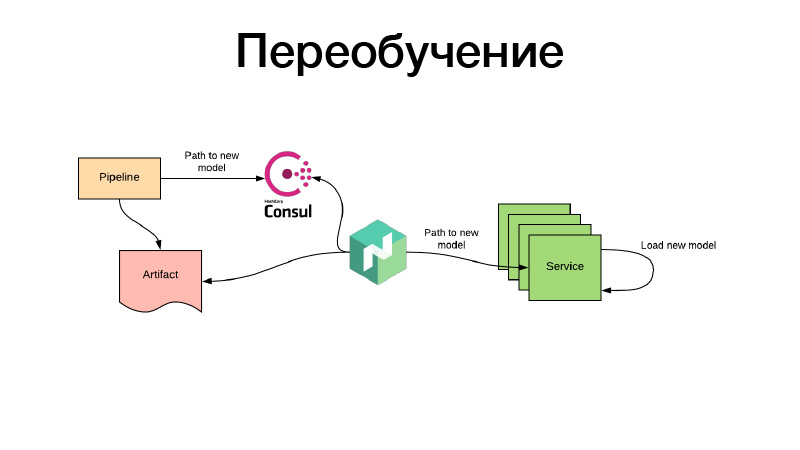
Alles in Ordnung, die Modelle waren irgendwie trainiert, wir haben sie in der Nomad-Konfiguration registriert. Aber was ist, wenn es ein Modell von Empfehlungen gibt, das bereits Zeit hat, während des Trainings überholt zu werden, und wir sie ständig neu schulen müssen? Alles wird auf die gleiche Weise erledigt: Durch regelmäßige Batch-Jobs wird ein Artefakt erzeugt - beispielsweise alle drei Stunden. Gleichzeitig legt die Pipeline am Ende ihrer Arbeit den Weg für das neue Modell in Consul fest. Dies ist der Schlüsselwertspeicher, der für die Konfiguration verwendet wird. Nomad kann Konfigurationen konfigurieren. Es soll eine Umgebungsvariable geben, die auf den Werten des Schlüsselwertspeichers Consul basiert. Er überwacht Änderungen und entscheidet, sobald ein neuer Pfad angezeigt wird, dass zwei Pfade eingeschlagen werden können. Er lädt das Artefakt selbst über einen neuen Link herunter, legt den Service-Container mithilfe von Volume in Docker ab und lädt ihn neu - und tut dies alles, damit keine Ausfallzeiten auftreten, dh langsam und individuell. Oder er rendert eine neue Konfiguration und meldet ihm den Dienst. Oder der Dienst selbst erkennt es - und kann sein Modell in sich selbst live aktualisieren. Das ist alles, danke.