
Ich bin auf interessantes Material über künstliche Intelligenz in Spielen gestoßen. Mit einer Erklärung der grundlegenden Dinge über KI anhand einfacher Beispiele und im Inneren finden Sie viele nützliche Werkzeuge und Methoden für die bequeme Entwicklung und Gestaltung. Wie, wo und wann man sie benutzt - ist auch da.
Die meisten Beispiele sind in Pseudocode geschrieben, sodass keine detaillierten Programmierkenntnisse erforderlich sind. Unter dem Schnitt 35 Blatt Text mit Bildern und Gifs, also machen Sie sich bereit.
UPD Es
tut mir leid , aber
PatientZero hat diesen Artikel über Habré bereits übersetzt. Sie können die Version
hier lesen, aber aus irgendeinem Grund hat mich der Artikel überholt (ich habe die Suche verwendet, aber etwas ist schief gelaufen). Und da ich einen Blog für Spieleentwickler schreibe, habe ich beschlossen, meine Übersetzungsoption den Abonnenten zu überlassen (einige Momente sind für mich anders, andere werden auf Anraten der Entwickler absichtlich verpasst).
Was ist KI?
Die Spiel-KI konzentriert sich darauf, welche Aktionen ein Objekt basierend auf den Bedingungen ausführen soll, unter denen es sich befindet. Dies wird normalerweise als Management von „intelligenten Agenten“ bezeichnet, bei denen der Agent ein Spielcharakter, ein Fahrzeug, ein Bot und manchmal etwas Abstrakteres ist: eine ganze Gruppe von Entitäten oder sogar eine Zivilisation. In jedem Fall ist es eine Sache, die ihre Umgebung sehen, Entscheidungen auf ihrer Grundlage treffen und in Übereinstimmung mit ihnen handeln muss. Dies wird als Sense / Think / Act-Zyklus bezeichnet:
- Sinn: Der Agent findet oder empfängt Informationen über Dinge in seiner Umgebung, die sein Verhalten beeinflussen können (Bedrohungen in der Nähe, Gegenstände zum Sammeln, interessante Orte zum Forschen).
- Denken Sie: Der Agent entscheidet, wie er reagieren soll (überlegt, ob das Sammeln von Gegenständen sicher ist oder ob er zuerst kämpfen / sich verstecken muss).
- Handlung: Der Agent führt Aktionen aus, um die vorherige Entscheidung umzusetzen (bewegt sich auf den Gegner oder das Objekt zu).
- ... jetzt hat sich die Situation aufgrund der Aktionen der Charaktere geändert, sodass sich der Zyklus mit neuen Daten wiederholt.
KI tendiert dazu, sich auf den Sinnesteil der Schleife zu konzentrieren. Zum Beispiel machen autonome Autos Fotos von der Straße, kombinieren sie mit Radar- und Lidar-Daten und interpretieren sie. Normalerweise erfolgt dies durch maschinelles Lernen, das die eingehenden Daten verarbeitet und ihnen Bedeutung verleiht und semantische Informationen wie "20 Meter vor Ihnen steht ein weiteres Auto" extrahiert. Dies sind die sogenannten Klassifizierungsprobleme.
Spiele benötigen kein komplexes System zum Extrahieren von Informationen, da die meisten Daten bereits ein wesentlicher Bestandteil davon sind. Es ist nicht erforderlich, Bilderkennungsalgorithmen auszuführen, um festzustellen, ob ein Feind vor Ihnen liegt. Das Spiel kennt und überträgt Informationen bereits direkt im Entscheidungsprozess. Daher ist ein Teil des Sinneszyklus oft viel einfacher als Denken und Handeln.
Einschränkungen der Spiel-KI
AI hat eine Reihe von Einschränkungen, die beachtet werden müssen:
- KI muss nicht im Voraus trainiert werden, als wäre es ein Algorithmus für maschinelles Lernen. Es ist sinnlos, während der Entwicklung ein neuronales Netzwerk zu schreiben, um Zehntausende von Spielern zu beobachten und zu lernen, wie man am besten gegen sie spielt. Warum? Weil das Spiel nicht veröffentlicht wird, aber es keine Spieler gibt.
- Das Spiel sollte unterhalten und herausfordern, daher sollten Agenten nicht den besten Ansatz gegen Menschen finden.
- Agenten müssen realistisch aussehen, damit die Spieler das Gefühl haben, gegen echte Menschen zu spielen. AlphaGo übertraf die Menschen, aber die unternommenen Schritte waren weit vom traditionellen Verständnis des Spiels entfernt. Wenn das Spiel einen menschlichen Gegner imitiert, sollte es kein solches Gefühl geben. Der Algorithmus muss geändert werden, damit er plausible und keine idealen Entscheidungen trifft.
- KI sollte in Echtzeit funktionieren. Dies bedeutet, dass der Algorithmus die Verwendung des Prozessors für eine lange Zeit zur Entscheidungsfindung nicht monopolisieren kann. Selbst 10 Millisekunden sind zu lang, da die meisten Spiele nur 16 bis 33 Millisekunden haben, um die gesamte Verarbeitung abzuschließen und mit dem nächsten Frame der Grafik fortzufahren.
- Im Idealfall ist zumindest ein Teil des Systems datengesteuert, sodass Nicht-Codierer Änderungen vornehmen und Anpassungen schneller durchführen können.
Betrachten Sie KI-Ansätze, die den gesamten Sense / Think / Act-Zyklus umfassen.
Grundlegende Entscheidungsfindung
Beginnen wir mit dem einfachsten Spiel - Pong. Ziel: Bewegen Sie die Plattform (Paddel) so, dass der Ball davon abprallt, anstatt vorbei zu fliegen. Es ist wie beim Tennis, bei dem man verliert, wenn man den Ball nicht schlägt. Hier hat die KI eine relativ einfache Aufgabe - zu entscheiden, in welche Richtung die Plattform bewegt werden soll.

Bedingte Anweisungen
Für AI hat Pong die naheliegendste Lösung - versuchen Sie immer, die Plattform unter dem Ball zu positionieren.
Ein einfacher Algorithmus hierfür, geschrieben in Pseudocode:
jedes Frame / Update während das Spiel läuft:
Wenn sich der Ball links vom Paddel befindet:
Paddel nach links bewegen
sonst, wenn sich der Ball rechts vom Paddel befindet:
Paddel nach rechts bewegenWenn sich die Plattform mit der Geschwindigkeit des Balls bewegt, ist dies der perfekte Algorithmus für AI in Pong. Es besteht keine Notwendigkeit, etwas zu komplizieren, wenn nicht so viele Daten und mögliche Aktionen für den Agenten vorhanden sind.
Dieser Ansatz ist so einfach, dass der gesamte Sense / Think / Act-Zyklus kaum spürbar ist. Aber er ist:
- Der Sense-Teil besteht aus zwei if-Anweisungen. Das Spiel weiß, wo sich der Ball befindet und wo sich die Plattform befindet, daher wendet sich die KI an ihn, um diese Informationen zu erhalten.
- Der Think-Teil besteht auch aus zwei if-Anweisungen. Sie verkörpern zwei Lösungen, die sich in diesem Fall gegenseitig ausschließen. Infolgedessen wird eine von drei Aktionen ausgewählt: Verschieben Sie die Plattform nach links, bewegen Sie sich nach rechts oder tun Sie nichts, wenn sie bereits richtig positioniert ist.
- Der Act-Teil befindet sich in den Anweisungen Move Paddle Left und Move Paddle Right. Je nach Design des Spiels können sie die Plattform sofort oder mit einer bestimmten Geschwindigkeit bewegen.
Solche Ansätze werden als reaktiv bezeichnet - es gibt ein einfaches Regelwerk (in diesem Fall if-Anweisungen im Code), die auf den aktuellen Zustand der Welt reagieren und handeln.
Entscheidungsbaum
Das Pong-Beispiel entspricht tatsächlich dem formalen KI-Konzept, das als Entscheidungsbaum bezeichnet wird. Der Algorithmus übergibt es, um ein „Blatt“ zu erreichen - eine Entscheidung darüber, welche Maßnahmen ergriffen werden sollen.
Lassen Sie uns ein Blockdiagramm des Entscheidungsbaums für den Algorithmus unserer Plattform erstellen:
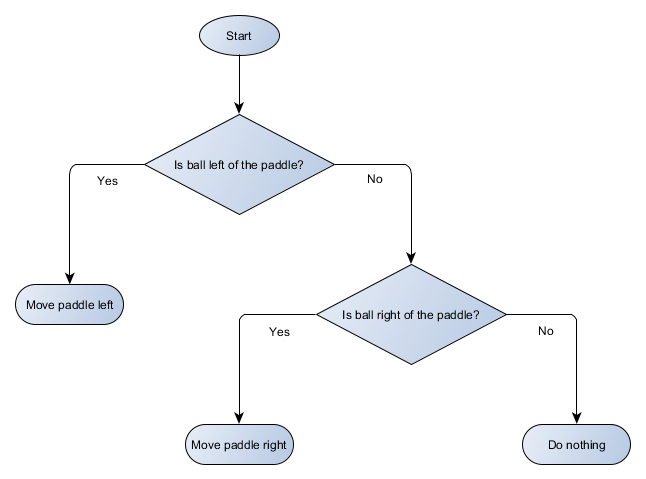
Jeder Teil des Baums wird als Knoten bezeichnet - die KI verwendet die Graphentheorie, um solche Strukturen zu beschreiben. Es gibt zwei Arten von Knoten:
- Entscheidungsknoten: Auswahl zwischen zwei Alternativen basierend auf der Überprüfung einer bestimmten Bedingung, bei der jede Alternative als separater Knoten dargestellt wird.
- Endknoten: Eine auszuführende Aktion, die die endgültige Entscheidung darstellt.
Der Algorithmus beginnt mit dem ersten Knoten (der "Wurzel" des Baums). Es entscheidet entweder, zu welchem untergeordneten Knoten es gehen soll, oder es führt eine im Knoten gespeicherte Aktion aus und schließt sie ab.
Was ist der Vorteil, wenn der Entscheidungsbaum dieselbe Aufgabe erfüllt wie die if-Anweisungen im vorherigen Abschnitt? Hier gibt es ein gemeinsames System, bei dem jede Lösung nur eine Bedingung und zwei mögliche Ergebnisse aufweist. Auf diese Weise kann der Entwickler aus den Daten, die die Entscheidungen im Baum darstellen, eine KI erstellen und deren Hardcodierung vermeiden. Stellen Sie sich in Form einer Tabelle vor:
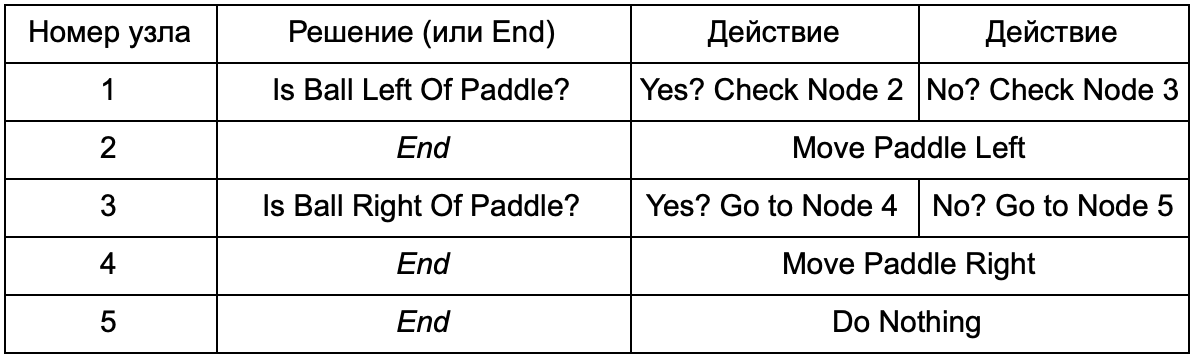
Auf der Codeseite erhalten Sie ein System zum Lesen von Zeichenfolgen. Erstellen Sie für jeden einen Knoten, verbinden Sie die Entscheidungslogik basierend auf der zweiten Spalte und die untergeordneten Knoten basierend auf der dritten und vierten Spalte. Sie müssen noch die Bedingungen und Aktionen programmieren, aber jetzt wird die Struktur des Spiels komplizierter. Darin fügen Sie zusätzliche Entscheidungen und Aktionen hinzu und konfigurieren dann die gesamte KI, indem Sie einfach eine Textdatei mit einer Baumdefinition bearbeiten. Übertragen Sie als Nächstes die Datei an den Spieledesigner, der das Verhalten ändern kann, ohne das Spiel neu zu kompilieren und den Code zu ändern.
Entscheidungsbäume sind sehr nützlich, wenn sie automatisch anhand einer Vielzahl von Beispielen erstellt werden (z. B. mithilfe des ID3-Algorithmus). Dies macht sie zu einem effektiven und leistungsstarken Tool zur Klassifizierung von Situationen anhand der empfangenen Daten. Wir gehen jedoch über ein einfaches System hinaus, mit dem Agenten Aktionen auswählen können.
Szenarien
Wir haben ein Entscheidungsbaumsystem zerlegt, das vorab erstellte Bedingungen und Aktionen verwendet. Der KI-Designer kann den Baum so anordnen, wie er möchte, aber er muss sich immer noch auf den Encoder verlassen, der alles programmiert hat. Was wäre, wenn wir den Designern Werkzeuge geben könnten, um unsere eigenen Bedingungen oder Aktionen zu erstellen?
Um zu verhindern, dass der Programmierer Code für die Bedingungen Is Ball Left Of Paddle und Is Ball Right Of Paddle schreibt, kann er ein System erstellen, in dem der Designer die Bedingungen für die Überprüfung dieser Werte aufzeichnet. Dann sehen die Daten des Entscheidungsbaums folgendermaßen aus:
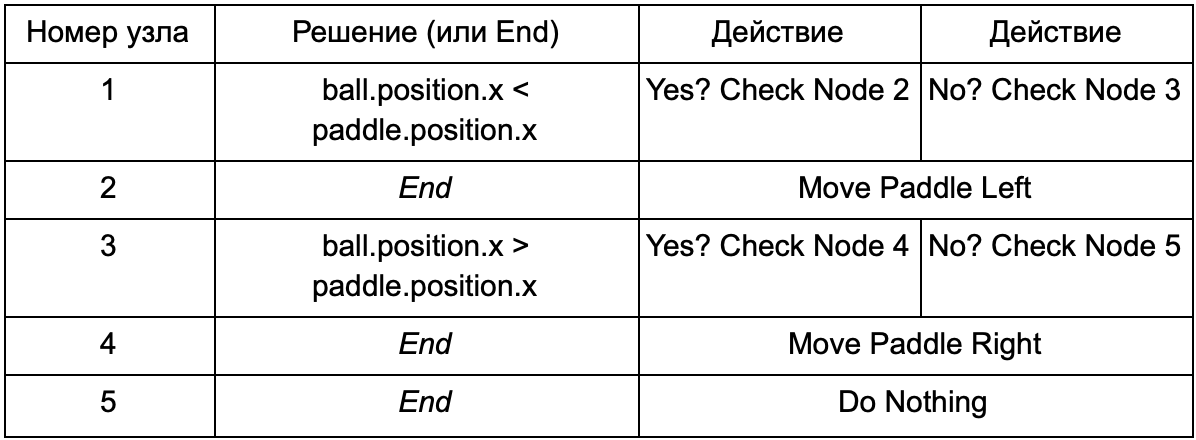
Im Wesentlichen ist dies dasselbe wie in der ersten Tabelle, aber die Lösungen in sich haben ihren eigenen Code, ähnlich dem bedingten Teil der if-Anweisung. Auf der Codeseite würde dies in der zweiten Spalte für Entscheidungsknoten gelesen, aber anstatt nach einer bestimmten zu erfüllenden Bedingung zu suchen (Is Ball Left Of Paddle), wertet es den bedingten Ausdruck aus und gibt true bzw. false zurück. Dies geschieht mit der Skriptsprache Lua oder Angelscript. Mit ihnen kann der Entwickler Objekte in seinem Spiel (Ball und Paddel) nehmen und Variablen erstellen, die im Skript verfügbar sind (ball.position). Darüber hinaus ist die Skriptsprache einfacher als C ++. Es erfordert keine vollständige Kompilierungsphase, ist daher ideal für die schnelle Anpassung der Spielelogik geeignet und ermöglicht es „Nicht-Codierern“, die erforderlichen Funktionen selbst zu erstellen.
Im obigen Beispiel wird die Skriptsprache nur zum Auswerten eines bedingten Ausdrucks verwendet, sie kann jedoch auch für Aktionen verwendet werden. Beispielsweise können Daten zum Verschieben des Paddels nach rechts zu einer Skriptanweisung werden (ball.position.x + = 10). Damit wird die Aktion auch im Skript definiert, ohne dass Move Paddle Right programmiert werden muss.
Sie können noch weiter gehen und einen vollständigen Entscheidungsbaum in einer Skriptsprache schreiben. Dies ist ein Code in Form von fest codierten bedingten Anweisungen, die sich jedoch in externen Skriptdateien befinden. Das heißt, sie können geändert werden, ohne das gesamte Programm neu zu kompilieren. Oft können Sie die Skriptdatei direkt während des Spiels ändern, um schnell verschiedene KI-Reaktionen zu testen.
Ereignisantwort
Die obigen Beispiele sind perfekt für Pong. Sie führen kontinuierlich den Sense / Think / Act-Zyklus durch und handeln auf der Grundlage des neuesten Zustands der Welt. Bei komplexeren Spielen müssen Sie jedoch auf einzelne Ereignisse reagieren und nicht alles auf einmal bewerten. Pong ist bereits ein erfolgloses Beispiel. Wähle einen anderen.
Stellen Sie sich einen Schützen vor, bei dem die Feinde bewegungslos sind, bis sie den Spieler finden. Danach handeln sie abhängig von ihrer "Spezialisierung": Jemand rennt, um "zu vernichten", jemand greift aus der Ferne an. Dies ist immer noch das grundlegende Reaktionssystem - „Wenn der Spieler bemerkt wird, dann tun Sie etwas“ -, aber es kann logisch in das Ereignis Spieler gesehen (der Spieler wird bemerkt) und die Reaktion (Antwort auswählen und ausführen) unterteilt werden.
Dies bringt uns zurück zum Sense / Think / Act-Zyklus. Wir können den Sense-Teil codieren, der in jedem Frame überprüft, ob die KI des Spielers sichtbar ist. Wenn nicht, passiert nichts, aber wenn es sieht, wird das Ereignis Spieler gesehen ausgelöst. Der Code enthält einen separaten Abschnitt mit der Aufschrift: "Wenn das Ereignis" Spieler gesehen "auftritt, tun Sie es". Hier finden Sie die Antwort, die Sie benötigen, um auf die Teile "Denken und Handeln" zu verweisen. Auf diese Weise richten Sie Reaktionen auf das Ereignis "Spieler gesehen" ein: "ChargeAndAttack" für den "wachsenden" Charakter und "HideAndSnipe" für den Scharfschützen. Diese Beziehungen können in der Datendatei zur schnellen Bearbeitung erstellt werden, ohne dass eine Neukompilierung erforderlich ist. Und hier können Sie auch die Skriptsprache verwenden.
Schwierige Entscheidungen treffen
Obwohl einfache Reaktionssysteme sehr effektiv sind, gibt es viele Situationen, in denen sie nicht ausreichen. Manchmal ist es notwendig, verschiedene Entscheidungen zu treffen, basierend auf dem, was der Agent gerade tut, aber es ist schwierig, sich dies als Bedingung vorzustellen. Manchmal gibt es zu viele Bedingungen, um sie effektiv in einem Entscheidungsbaum oder Skript darzustellen. Manchmal müssen Sie vorab entscheiden, wie sich die Situation ändern wird, bevor Sie sich für den nächsten Schritt entscheiden. Die Lösung dieser Probleme erfordert komplexere Ansätze.
Endliche Zustandsmaschine
Finite State Machine oder FSM (State Machine) ist eine Möglichkeit zu sagen, dass sich unser Agent derzeit in einem von mehreren möglichen Zuständen befindet und von einem Zustand in einen anderen wechseln kann. Es gibt eine bestimmte Anzahl solcher Zustände - daher der Name. Das beste Beispiel des Lebens ist eine Ampel. An verschiedenen Orten unterschiedliche Lichtfolgen, aber das Prinzip ist das gleiche - jeder Zustand repräsentiert etwas (stehen, gehen usw.). Eine Ampel befindet sich zu einem bestimmten Zeitpunkt nur in einem Zustand und wechselt nach einfachen Regeln von einem in einen anderen.
Mit NPCs in Spielen eine ähnliche Geschichte. Nehmen Sie zum Beispiel eine Wache mit den folgenden Bedingungen:
- Patrouillieren
- Angreifen
- Flucht
Und solche Bedingungen für die Änderung seines Zustands:
- Wenn der Wachmann den Feind sieht, greift er an.
- Wenn der Wachmann angreift, den Feind aber nicht mehr sieht, patrouilliert er wieder.
- Wenn der Wachmann angreift, aber schwer verwundet ist, rennt er weg.
Sie können auch if-Anweisungen mit einer Schutzzustandsvariablen und verschiedenen Überprüfungen schreiben: Befindet sich ein Feind in der Nähe, wie hoch ist der Gesundheitszustand des NPC usw. Fügen wir noch einige weitere Zustände hinzu:
- Untätigkeit (Leerlauf) - zwischen Patrouillen.
- Suchen (Suchen) - wenn der bemerkte Feind verschwunden ist.
- Bitten Sie um Hilfe (Hilfe finden) - wenn der Feind gesehen wird, aber zu stark, um mit ihm allein zu kämpfen.
Die Auswahl für jeden von ihnen ist begrenzt - zum Beispiel wird ein Wachmann nicht nach einem versteckten Feind suchen, wenn er sich in einem schlechten Gesundheitszustand befindet.
Am Ende kann die riesige Liste von "wenn <x und y, aber nicht z>, dann <p>" zu umständlich werden, daher sollten wir eine Methode formalisieren, die es uns ermöglicht, die Zustände und Übergänge zwischen Zuständen im Auge zu behalten. Dazu berücksichtigen wir alle Zustände und listen unter jedem Zustand alle Übergänge zu anderen Zuständen zusammen mit den dafür erforderlichen Bedingungen auf.
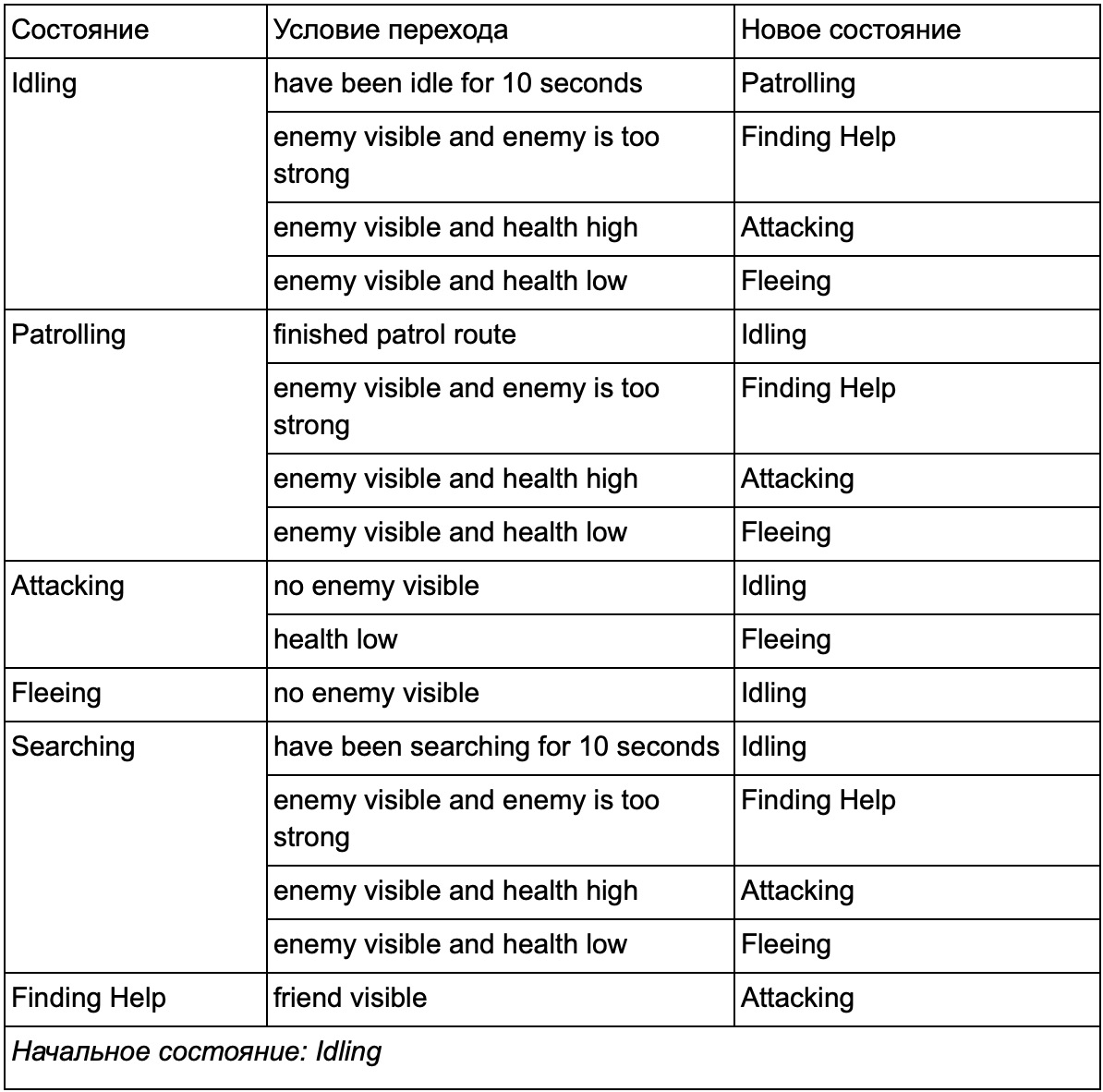
Diese Zustandsübergangstabelle ist eine umfassende Möglichkeit, FSM darzustellen. Zeichnen wir ein Diagramm und erhalten einen vollständigen Überblick darüber, wie sich das Verhalten von NPCs ändert.
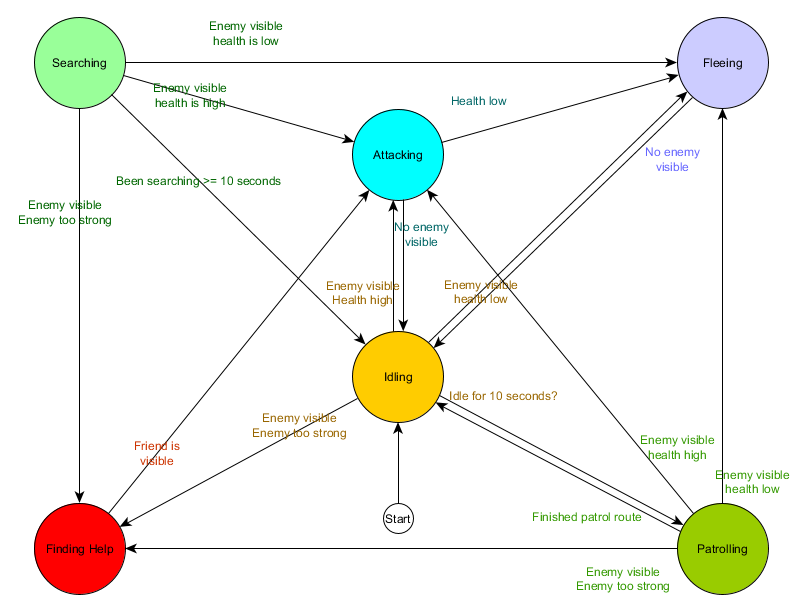
Das Diagramm spiegelt das Wesentliche der Entscheidungsfindung für diesen Agenten auf der Grundlage der aktuellen Situation wider. Darüber hinaus zeigt jeder Pfeil einen Übergang zwischen Zuständen, wenn die Bedingung daneben erfüllt ist.
Bei jedem Update überprüfen wir den aktuellen Status des Agenten, sehen uns die Liste der Übergänge an und wenn die Bedingungen für den Übergang erfüllt sind, nimmt er einen neuen Status an. Beispielsweise prüft jeder Frame, ob der 10-Sekunden-Timer abgelaufen ist, und wenn ja, wechselt der Schutz von Leerlauf zu Patrouillieren. Auf die gleiche Weise überprüft der Angriffsstatus den Zustand des Agenten. Wenn er niedrig ist, wechselt er in den Fluchtzustand.
Dies behandelt Zustandsübergänge, aber was ist mit dem Verhalten, das mit den Zuständen selbst verbunden ist? In Bezug auf die Implementierung des tatsächlichen Verhaltens für einen bestimmten Status gibt es normalerweise zwei Arten von „Hooks“, bei denen wir dem FSM Aktionen zuweisen:
- Aktionen, die wir regelmäßig für den aktuellen Status ausführen.
- Die Maßnahmen, die wir ergreifen, wenn wir von einem Staat in einen anderen wechseln.
Beispiele für den ersten Typ. Patrouillenstatus Jeder Frame bewegt den Agenten entlang der Patrouillenroute. Angriffsstatus Jeder Frame versucht, einen Angriff zu starten oder wenn möglich in einen Status zu wechseln.
Betrachten Sie für den zweiten Typ den Übergang: „Wenn der Feind sichtbar und der Feind zu stark ist, wechseln Sie in den Status Hilfe suchen. Der Agent muss auswählen, wo er Hilfe anfordern möchte, und diese Informationen speichern, damit der Status "Hilfe suchen" weiß, wohin er gehen soll. Sobald Hilfe gefunden wird, kehrt der Agent in den Angriffszustand zurück. An diesem Punkt möchte er den Verbündeten über die Bedrohung informieren, sodass die Aktion NotifyFriendOfThreat auftreten kann.
Und wieder können wir dieses System durch das Prisma des Sense / Think / Act-Zyklus betrachten. Sinn übersetzt sich in Daten, die von der Übergangslogik verwendet werden. Think - Übergänge in jedem Zustand verfügbar. Und Act wird durch Aktionen ausgeführt, die regelmäßig innerhalb des Staates oder bei Übergängen zwischen Staaten durchgeführt werden.
Manchmal kann eine kontinuierliche Abfrage der Übergangsbedingungen kostspielig sein. Wenn beispielsweise jeder Agent komplexe Berechnungen für jeden Frame durchführt, um festzustellen, ob er Feinde sieht, und um zu verstehen, ob es möglich ist, vom patrouillierenden Status zum Angriff zu wechseln, nimmt dies viel Prozessorzeit in Anspruch.
Wichtige Änderungen im Zustand der Welt können als Ereignisse betrachtet werden, die verarbeitet werden, sobald sie auftreten. Anstatt dass FSM die Übergangsbedingung "Kann mein Agent den Player sehen?" Überprüft, können Sie in jedem Frame ein separates System konfigurieren, um Überprüfungen weniger häufig durchzuführen (z. B. 5 Mal pro Sekunde). Und das Ergebnis ist, Spieler gesehen zu geben, wenn der Scheck bestanden wird.
Dies wird an die FSM übergeben, die nun in die empfangene Bedingung "Spieler gesehen" wechseln und entsprechend reagieren muss. Das resultierende Verhalten ist bis auf eine fast unmerkliche Verzögerung vor der Beantwortung dasselbe. Die Leistung wurde jedoch durch die Trennung eines Teils von Sense in einem separaten Teil des Programms verbessert.
Hierarchische endliche Zustandsmaschine
Das Arbeiten mit großen FSMs ist jedoch nicht immer bequem. Wenn wir den Status des Angriffs erweitern und durch separate Nahkampfangriffe (Nahkampf) und Fernkampfangriffe (Fernkampf) ersetzen möchten, müssen wir die Übergänge von allen anderen Zuständen ändern, die zum Angriffsstatus führen (aktuell und zukünftig).
Sicherlich haben Sie bemerkt, dass es in unserem Beispiel viele doppelte Übergänge gibt. Die meisten Übergänge im Leerlauf sind identisch mit Übergängen im Überwachungszustand. Es wäre schön, nicht zu wiederholen, besonders wenn wir weitere ähnliche Zustände hinzufügen. Es ist sinnvoll, Leerlauf und Patrouillieren unter dem gemeinsamen Label „Nichtkampf“ zusammenzufassen, bei dem es nur einen gemeinsamen Satz von Übergängen zu Kampfstaaten gibt. Wenn wir dieses Label als Status präsentieren, werden Idling und Patrolling zu Unterzuständen. Ein Beispiel für die Verwendung einer separaten Umrechnungstabelle für einen neuen Nichtkampf-Unterzustand:
Die Hauptbedingungen: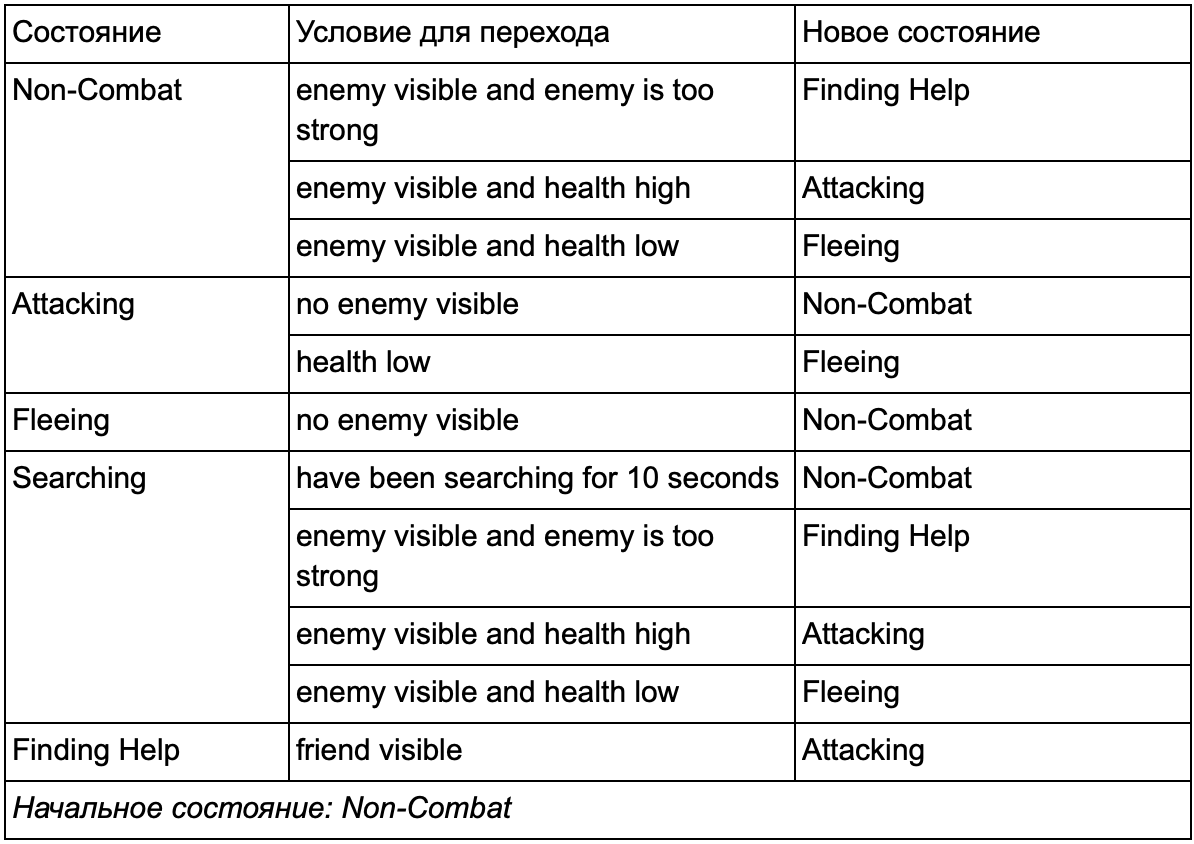 Status außerhalb des Kampfes:
Status außerhalb des Kampfes:
Und in Diagrammform:
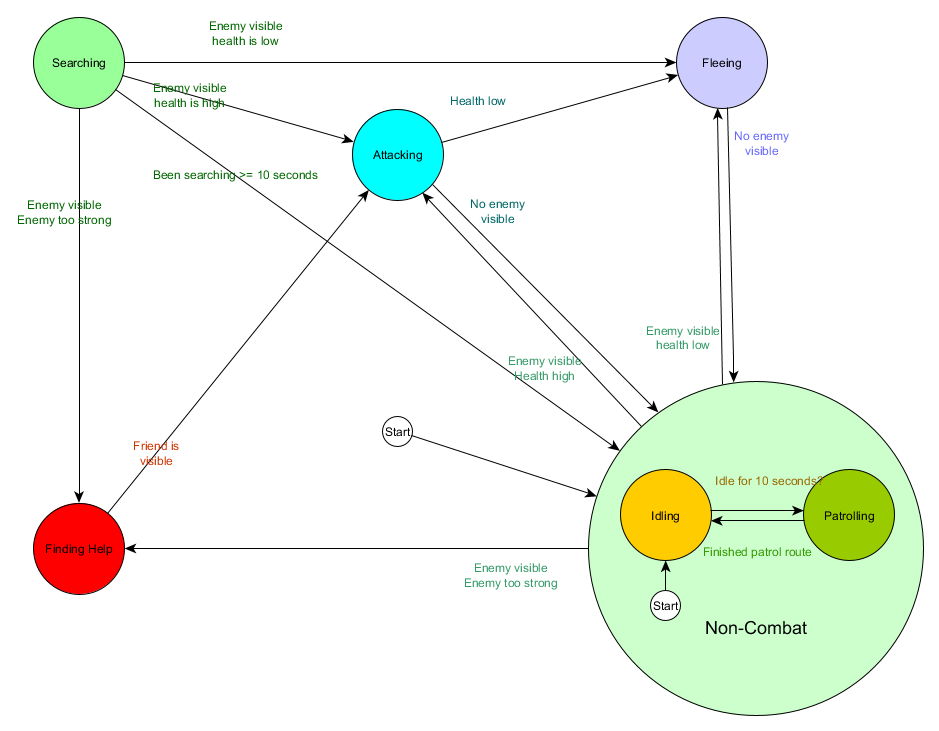
Dies ist das gleiche System, jedoch mit einem neuen Nichtkampfzustand, der Leerlauf und Patrouillieren umfasst. Mit jedem Zustand, der FSMs mit Unterzuständen enthält (und diese Unterzustände enthalten wiederum ihre eigenen FSMs - und so weiter, so viel Sie benötigen), erhalten wir eine hierarchische endliche Zustandsmaschine oder HFSM (hierarchische Zustandsmaschine). Nachdem wir einen Nichtkampfstaat gruppiert haben, haben wir eine Reihe redundanter Übergänge herausgeschnitten. Wir können dasselbe für alle neuen Staaten mit gemeinsamen Übergängen tun. Wenn wir beispielsweise in Zukunft den Angriffszustand auf die Zustände Nahkampfangriff und Raketenangriff ausweiten, handelt es sich um Unterzustände, die sich je nach Entfernung zum Feind und Vorhandensein von Munition kreuzen. Infolgedessen können komplexe Verhaltensmodelle und Untermodelle des Verhaltens mit einem Minimum an doppelten Übergängen dargestellt werden.
HFSM . , , . , . . , , . , 25%, , , , — . 25% 10%, .
, « », , . .
, : «» , , , . :
- : Succeeded ( ), Failed ( ) Running ( ).
- . Decorator, . Succeed, .
- , , Running .
. HFSM :
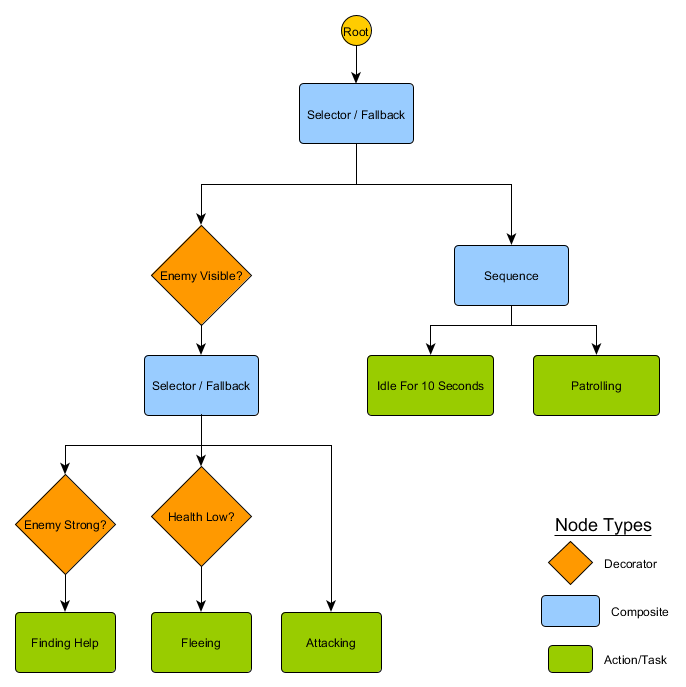
Idling/Patrolling Attacking . , , Fleeing, , — Patrolling, Idling, Attacking .
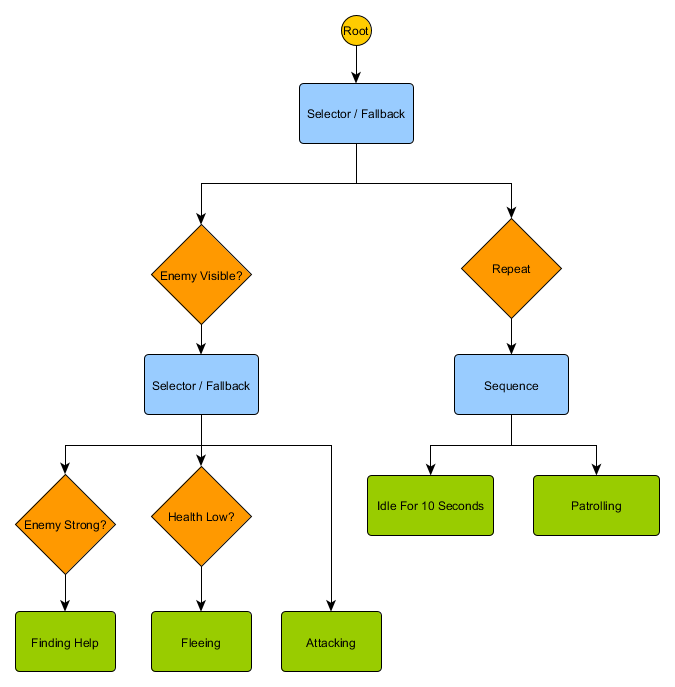
— , . , — , ? , — , Idling 10 , , ?
. , . , .
Utility-based system
. , , . , , .
Utility-based system (, ) . , , , . — , .
, . FSM, , , . , ( , ). , .
— , 0 ( ) 100 ( ). , . :

— . . , , , Fleeing, FindingHelp . FindingHelp . , 50, . .
, . . , Fleeing , , Attacking , . - Fleeing Attacking , , . , , FSM.
. . The Sims, , — «», . , , EatFood , , , EatFood .
, Utility-based system , . . , Utility , , .
, , , . ? , , , , ? .
Management
, , , . , , . . Sense/Think/Act, , Think , Act . , , . — , . , , . :
desired_travel = destination_position – agent_position2D-. (-2,-2), - - (30, 20), , — (32, 22). , — 5 , (4.12, 2.83). 8 .
. , , 5 / ( ), . , .
— , , , . . steering behaviours, : Seek (), Flee (), Arrival () . . , , , .
. Seek Arrival — . Obstacle Avoidance ( ) Separation () , . Alignment () Cohesion () . steering behaviours . , Arrival, Separation Obstacle Avoidance, . .
, — , - Arrival Obstacle Avoidance. , , . : , .
, , - .
Steering behaviours ( ), — . pathfinding ( ), .
— . - , , . . , ( , ). , Breadth-First Search BFS ( ). ( breadth, «»). , , — , , .
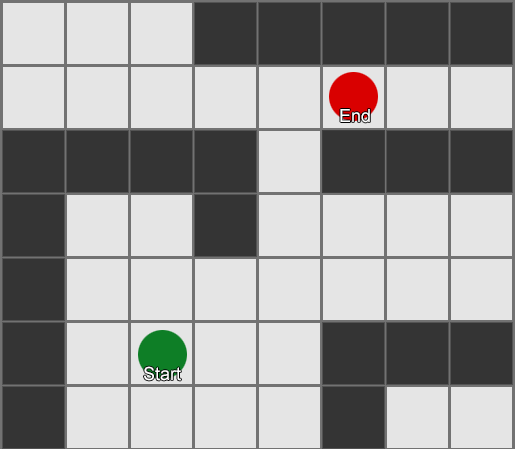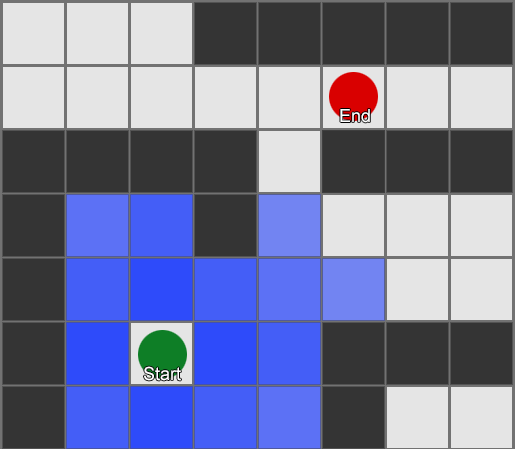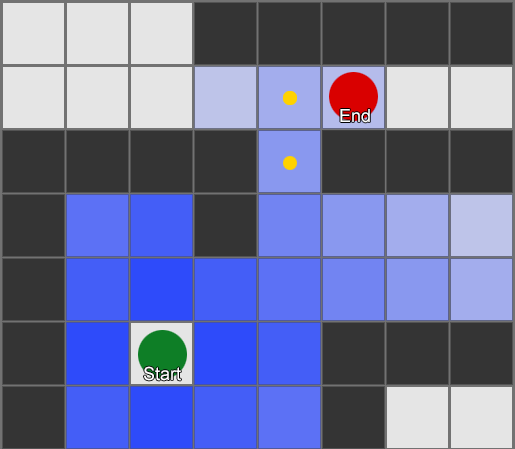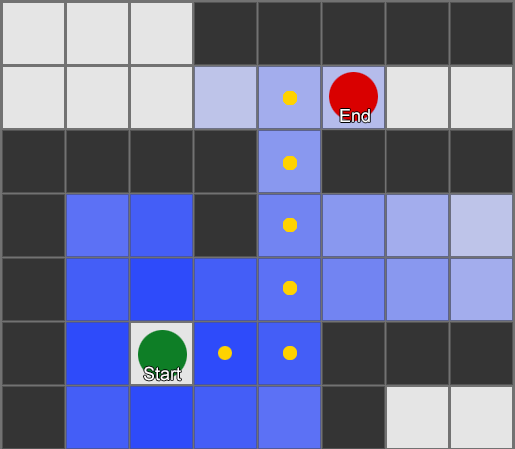
, . (, pathfinding) — , , .
, , steering behaviours, — 1 2, 2 3 . — , — . - .
BFS — «» , «». A* (A star). , - ( , ), , , . , — «» ( ) , ( ).
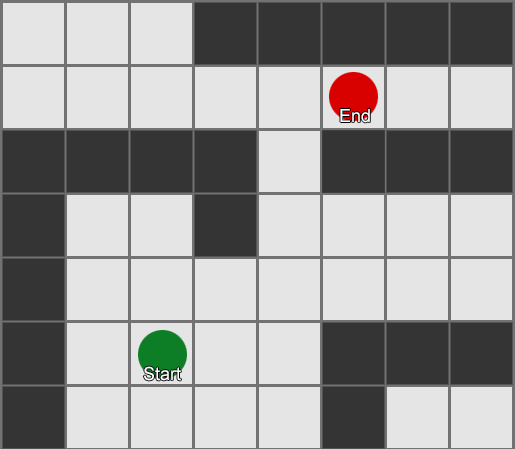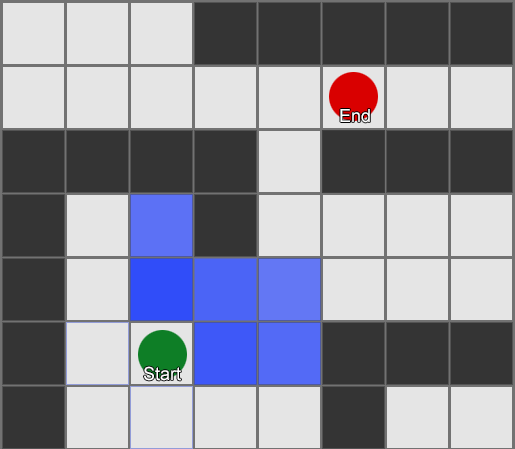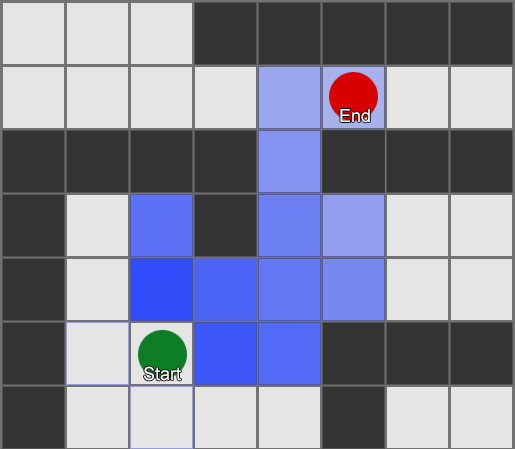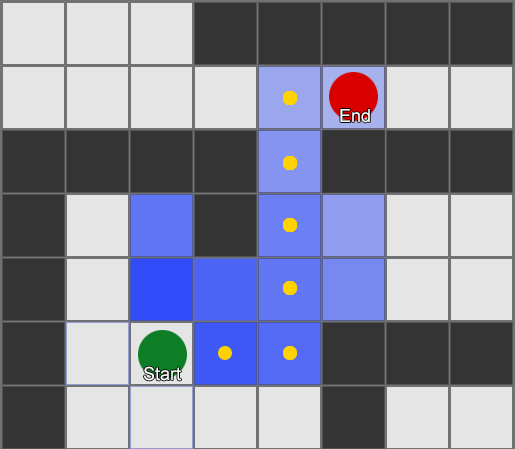
, , , . , BFS, — .
Aber die meisten Spiele sind nicht in der Startaufstellung angeordnet, und oft ist dies nicht möglich, ohne den Realismus zu beeinträchtigen. Kompromisse sind erforderlich. Wie groß sollten die Quadrate sein? Zu groß - und sie können sich kleine Korridore oder Kurven nicht richtig vorstellen, zu klein - es werden zu viele Quadrate gesucht, was am Ende viel Zeit in Anspruch nehmen wird.
Das erste, was zu verstehen ist, ist, dass das Gitter uns ein Diagramm der verbundenen Knoten gibt. Die A * - und BFS-Algorithmen arbeiten tatsächlich mit Diagrammen und kümmern sich überhaupt nicht um unser Raster. Wir könnten die Knoten überall in der Spielwelt platzieren: Wenn eine Verbindung zwischen zwei verbundenen Knoten sowie zwischen dem Start- und Endpunkt und mindestens einem der Knoten besteht, funktioniert der Algorithmus genauso gut wie zuvor. Dies wird oft als Wegpunktsystem bezeichnet, da jeder Knoten eine signifikante Position in der Welt darstellt, die Teil einer beliebigen Anzahl hypothetischer Pfade sein kann.
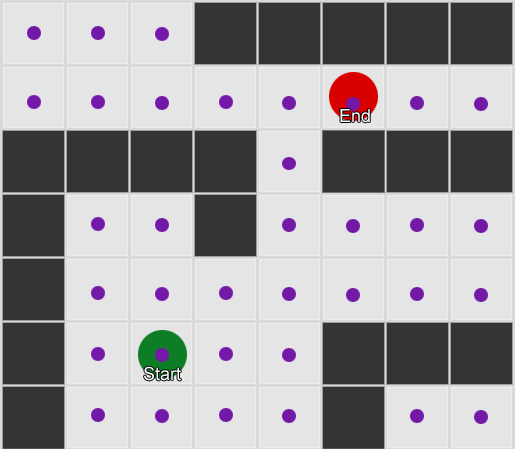 Beispiel 1: Ein Knoten in jedem Quadrat. Die Suche beginnt an dem Knoten, an dem sich der Agent befindet, und endet am Knoten des gewünschten Quadrats.
Beispiel 1: Ein Knoten in jedem Quadrat. Die Suche beginnt an dem Knoten, an dem sich der Agent befindet, und endet am Knoten des gewünschten Quadrats.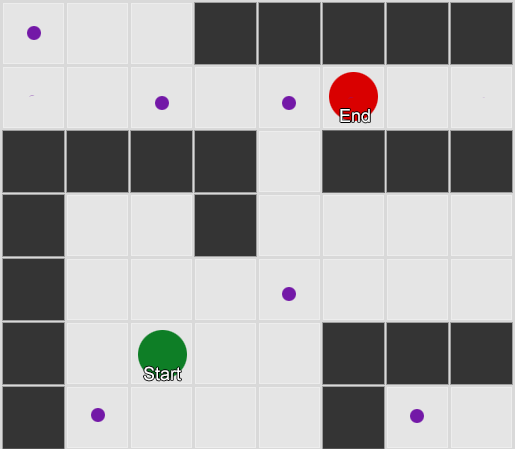 Beispiel 2: Ein kleinerer Satz von Knoten (Wegpunkten). Die Suche beginnt im Quadrat mit dem Agenten, durchläuft die erforderliche Anzahl von Knoten und wird dann zum Ziel fortgesetzt.
Beispiel 2: Ein kleinerer Satz von Knoten (Wegpunkten). Die Suche beginnt im Quadrat mit dem Agenten, durchläuft die erforderliche Anzahl von Knoten und wird dann zum Ziel fortgesetzt.Dies ist ein völlig flexibles und leistungsstarkes System. Bei der Entscheidung, wo und wie der Wegpunkt platziert werden soll, ist jedoch Vorsicht geboten. Andernfalls sehen die Agenten möglicherweise nicht den nächstgelegenen Punkt und können den Pfad nicht starten. Es wäre einfacher, wenn wir automatisch Wegpunkte basierend auf der Geometrie der Welt festlegen könnten.
Dann erscheint ein Navigationsnetz oder ein Navigationsnetz. Dies ist normalerweise ein 2D-Netz aus Dreiecken, das die Geometrie der Welt überlagert - überall dort, wo der Agent gehen darf. Jedes der Dreiecke im Raster wird zu einem Knoten im Diagramm und hat bis zu drei benachbarte Dreiecke, die zu benachbarten Knoten im Diagramm werden.
Dieses Bild ist ein Beispiel aus der Unity-Engine - er analysierte die Geometrie in der Welt und erstellte ein Navmesh (hellblau im Screenshot). Jedes Polygon in Navmesh ist ein Bereich, in dem ein Agent stehen oder sich von einem Polygon zu einem anderen Polygon bewegen kann. In diesem Beispiel sind die Polygone kleiner als die Böden, auf denen sie sich befinden - hergestellt, um die Abmessungen des Agenten zu berücksichtigen, die über seine nominelle Position hinausgehen.

Wir können die Route durch dieses Gitter erneut mit dem A * -Algorithmus suchen. Dies gibt uns eine nahezu perfekte Route in der Welt, die die gesamte Geometrie berücksichtigt und keine zusätzlichen Knoten und Wegpunkte erfordert.
Die Pfadfindung ist ein zu umfangreiches Thema, zu dem ein Abschnitt des Artikels nicht ausreicht. Wenn Sie es genauer studieren möchten, hilft Ihnen die
Website von Amit Patel dabei.
Planung
Wir haben mit der Pfadfindung sichergestellt, dass es manchmal nicht ausreicht, nur eine Richtung zu wählen und sich zu bewegen. Wir müssen eine Route auswählen und mehrere Kurven fahren, um zum gewünschten Ziel zu gelangen. Wir können diese Idee zusammenfassen: Das Erreichen des Ziels ist nicht nur der nächste Schritt, sondern eine ganze Sequenz, in der Sie manchmal ein paar Schritte nach vorne schauen müssen, um herauszufinden, was der erste sein sollte. Dies nennt man Planung. Die Pfadfindung kann als eine von mehreren Planungsergänzungen betrachtet werden. Aus der Perspektive unseres Sense / Think / Act-Zyklus plant der Think-Teil hier mehrere Act-Teile für die Zukunft.
Schauen wir uns das Beispiel des Brettspiels Magic: The Gathering an. Wir gehen zuerst mit einem solchen Kartensatz zur Hand:
- Sumpf - gibt 1 schwarzes Mana (Erdkarte).
- Wald - gibt 1 grünes Mana (Erdkarte).
- Flüchtiger Zauberer - Benötigt 1 blaues Mana, um beschworen zu werden.
- Elfenmystiker - Benötigt 1 grünes Mana, um beschworen zu werden.
Wir ignorieren die restlichen drei Karten, um es einfacher zu machen. Gemäß den Regeln darf ein Spieler pro Spielzug 1 Landkarte spielen. Er kann auf diese Karte „tippen“, um Mana daraus zu extrahieren, und dann Zaubersprüche (einschließlich Beschwörungskreaturen) entsprechend der Manamenge verwenden. In dieser Situation weiß der menschliche Spieler, dass Sie Wald spielen, 1 grünes Mana „tippen“ und dann Elfenmystiker anrufen müssen. Aber wie erraten Sie die Spiel-KI?
Einfache Planung
Der triviale Ansatz besteht darin, jede Aktion der Reihe nach zu versuchen, bis es geeignete gibt. Wenn die KI auf die Karten schaut, sieht sie, was Swamp spielen kann. Und spielt es. Gibt es in dieser Runde noch andere Aktionen? Er kann weder Elfenmystiker noch flüchtige Zauberer beschwören, da ihre Beschwörung jeweils grünes und blaues Mana erfordert und Swamp nur schwarzes Mana gibt. Und er wird nicht in der Lage sein, Forest zu spielen, weil er bereits Swamp gespielt hat. Somit hielt sich die Spiel-KI an die Regeln, tat es aber schlecht. Es kann verbessert werden.
Die Planung kann eine Liste von Aktionen finden, die das Spiel in den gewünschten Zustand bringen. So wie jedes Feld auf dem Pfad Nachbarn hatte (bei der Pfadfindung), hat jede Aktion im Plan auch Nachbarn oder Nachfolger. Wir können nach diesen Aktionen und nachfolgenden Aktionen suchen, bis wir den gewünschten Zustand erreicht haben.
In unserem Beispiel ist das gewünschte Ergebnis "Beschwöre eine Kreatur, wenn möglich". Zu Beginn des Zuges sehen wir nur zwei mögliche Aktionen, die nach den Spielregeln zulässig sind:
1. Spielen Sie Swamp (Ergebnis: Swamp im Spiel)
2. Spielen Sie Wald (Ergebnis: Wald im Spiel)Jede Aktion kann je nach Spielregeln zu weiteren Aktionen führen und andere wieder schließen. Stellen Sie sich vor, wir haben Swamp gespielt - dies entfernt Swamp als nächsten Schritt (wir haben es bereits gespielt) und löscht auch Forest (da Sie nach den Regeln eine Karte des Landes pro Spielzug spielen können). Danach fügt die KI als nächsten Schritt 1 schwarzes Mana hinzu, da es keine anderen Optionen gibt. Wenn er weiter geht und Tap the Swamp wählt, erhält er 1 Einheit schwarzes Mana und kann nichts damit anfangen.
1. Spielen Sie Swamp (Ergebnis: Swamp im Spiel)
1.1 Sumpf „tippen“ (Ergebnis: Sumpf „tippen“, +1 Einheit schwarzes Mana)
Keine Aktionen verfügbar - ENDE
2. Spielen Sie Wald (Ergebnis: Wald im Spiel)Die Liste der Aktionen war kurz, wir sind in einer Sackgasse. Wiederholen Sie den Vorgang für den nächsten Schritt. Wir spielen Wald, eröffnen die Aktion "Erhalte 1 grünes Mana", die wiederum die dritte Aktion eröffnet - den Ruf des Elfenmystikers.
1. Spielen Sie Swamp (Ergebnis: Swamp im Spiel)
1.1 Sumpf „tippen“ (Ergebnis: Sumpf „tippen“, +1 Einheit schwarzes Mana)
Keine Aktionen verfügbar - ENDE
2. Spielen Sie Wald (Ergebnis: Wald im Spiel)
2.1 Wald „tippen“ (Ergebnis: Wald „tippen“, +1 grüne Manaeinheit)
2.1.1 Elfenmystiker beschwören (Ergebnis: Elfenmystiker im Spiel, -1 Einheit grünes Mana)
Keine Aktionen verfügbar - ENDESchließlich untersuchten wir alle möglichen Aktionen und fanden einen Plan, der die Kreatur anrief.
Dies ist ein sehr vereinfachtes Beispiel. Es ist ratsam, den bestmöglichen Plan zu wählen, und keinen, der bestimmte Kriterien erfüllt. In der Regel können Sie potenzielle Pläne anhand des Endergebnisses oder des Gesamtnutzens ihrer Implementierung bewerten. Sie können sich 1 Punkt hinzufügen, um eine Karte der Erde zu spielen, und 3 Punkte, um eine Kreatur herauszufordern. Swamp zu spielen wäre ein Plan, der 1 Punkt gibt. Und um Wald zu spielen → Tippe auf den Wald → rufe Elfenmystiker an - er gibt sofort 4 Punkte.
So funktioniert Planung in Magic: The Gathering, aber nach der gleichen Logik gilt sie auch in anderen Situationen. Bewegen Sie zum Beispiel einen Bauern, um Platz für den Bischof zu schaffen, damit er sich im Schach bewegen kann. Oder gehen Sie hinter einer Wand in Deckung, um sicher auf XCOM zu schießen. Im Allgemeinen verstehen Sie den Punkt.
Verbesserte Planung
Manchmal gibt es zu viele mögliche Maßnahmen, um jede mögliche Option in Betracht zu ziehen. Zurück zum Beispiel mit Magic: The Gathering: Nehmen wir an, im Spiel und auf Ihren Händen befinden sich mehrere Karten mit Land und Kreaturen - die Anzahl der möglichen Kombinationen von Zügen kann im Zehnerbereich liegen. Es gibt verschiedene Lösungen für das Problem.
Der erste Weg ist die Rückwärtsverkettung. Anstatt alle Kombinationen zu sortieren, ist es besser, mit dem Endergebnis zu beginnen und einen direkten Weg zu finden. Anstelle des Weges von der Wurzel des Baumes zu einem bestimmten Blatt bewegen wir uns in die entgegengesetzte Richtung - vom Blatt zur Wurzel. Diese Methode ist einfacher und schneller.
Wenn der Gegner 1 Gesundheitseinheit hat, können Sie einen Plan finden, um "1 oder mehr Schadenseinheiten zuzufügen". Um dies zu erreichen, müssen eine Reihe von Bedingungen erfüllt sein:
1. Schaden kann durch einen Zauber verursacht werden - er sollte in der Hand liegen.
2. Um einen Zauber wirken zu können, brauchst du Mana.
3. Um Mana zu erhalten, musst du eine Landkarte spielen.
4. Um eine Karte der Erde zu spielen, müssen Sie sie in der Hand haben.
Ein anderer Weg ist die Best-First-Suche. Anstatt alle Wege zu gehen, wählen wir den am besten geeigneten. Meistens liefert diese Methode einen optimalen Plan ohne unnötige Suchkosten. A * ist die Form der besten ersten Suche - er erkundet von Anfang an die vielversprechendsten Routen und kann bereits den besten Weg finden, ohne andere Optionen prüfen zu müssen.
Eine interessante und immer beliebter werdende Option für die Best-First-Suche ist die Monte-Carlo-Baumsuche. Anstatt zu erraten, welche Pläne bei der Auswahl jeder nachfolgenden Aktion besser sind als andere, wählt der Algorithmus bei jedem Schritt zufällige Nachfolger aus, bis das Ende erreicht ist (als der Plan zum Sieg oder zur Niederlage führte). Das Endergebnis wird dann verwendet, um die Gewichtsbewertung der vorherigen Optionen zu erhöhen oder zu verringern. Der Algorithmus wiederholt diesen Vorgang mehrmals hintereinander und gibt eine gute Schätzung, welcher nächste Schritt besser ist, selbst wenn sich die Situation ändert (wenn der Gegner Maßnahmen ergreift, um den Spieler zu verhindern).
Die Geschichte über die Planung in Spielen wird nicht ohne zielorientierte Aktionsplanung oder GOAP (zielorientierte Aktionsplanung) auskommen. Dies ist eine weit verbreitete und diskutierte Methode, aber abgesehen von einigen charakteristischen Details handelt es sich im Wesentlichen um die Rückwärtsverkettungsmethode, über die wir zuvor gesprochen haben. Wenn die Aufgabe darin bestand, „den Spieler zu zerstören“ und der Spieler sich in Deckung befindet, könnte der Plan folgender sein: Zerstöre mit einer Granate → hol sie dir → lass sie fallen.
Normalerweise gibt es mehrere Ziele, von denen jedes seine eigene Priorität hat. Wenn das Ziel mit der höchsten Priorität nicht erreicht werden kann (keine Kombination von Aktionen erstellt einen Plan zur „Zerstörung des Spielers“, da der Spieler nicht sichtbar ist), kehrt die KI zu Zielen mit einer niedrigeren Priorität zurück.
Training und Anpassung
Wir haben bereits gesagt, dass die Gaming-KI normalerweise kein maschinelles Lernen verwendet, da sie nicht für die Verwaltung von Agenten in Echtzeit geeignet ist. Dies bedeutet jedoch nicht, dass Sie nichts aus diesem Bereich ausleihen können. Wir wollen einen solchen Gegner in einem Schützen, von dem wir etwas lernen können. Informieren Sie sich beispielsweise über die besten Positionen auf der Karte. Oder ein Gegner in einem Kampfspiel, der häufig verwendete Combo-Tricks des Spielers blockiert und andere zum Einsatz motiviert. Daher kann maschinelles Lernen in solchen Situationen sehr nützlich sein.
Statistiken und Wahrscheinlichkeiten
Bevor wir zu komplexen Beispielen übergehen, werden wir abschätzen, wie weit wir gehen können, indem wir einige einfache Messungen vornehmen und sie verwenden, um Entscheidungen zu treffen. Zum Beispiel eine Echtzeitstrategie - wie können wir bestimmen, ob ein Spieler in den ersten Minuten eines Spiels einen Angriff starten kann und welche Verteidigung dagegen vorbereitet werden muss? Wir können die Erfahrungen des Spielers in der Vergangenheit studieren, um zu verstehen, wie die zukünftige Reaktion aussehen könnte. Zunächst haben wir keine solchen Anfangsdaten, aber wir können sie sammeln. Jedes Mal, wenn die KI gegen eine Person spielt, kann sie den Zeitpunkt des ersten Angriffs aufzeichnen. Nach mehreren Sitzungen erhalten wir die durchschnittliche Zeit, in der der Spieler in Zukunft angreifen wird.
Die Durchschnittswerte haben ein Problem: Wenn ein Spieler 20 Mal „entscheidet“ und 20 Mal langsam spielt, liegen die erforderlichen Werte irgendwo in der Mitte, und dies gibt uns nichts Nützliches. Eine Lösung besteht darin, die Eingabe zu begrenzen - Sie können die letzten 20 Teile berücksichtigen.
Ein ähnlicher Ansatz wird verwendet, um die Wahrscheinlichkeit bestimmter Aktionen zu bewerten, vorausgesetzt, dass die früheren Präferenzen des Spielers in Zukunft dieselben sein werden. Wenn ein Spieler uns fünfmal mit einem Feuerball angreift, zweimal mit einem Blitz und einmal mit einem Nahkampf, ist es offensichtlich, dass er einen Feuerball bevorzugt. Wir extrapolieren und sehen die Wahrscheinlichkeit des Einsatzes verschiedener Waffen: Feuerball = 62,5%, Blitz = 25% und Nahkampf = 12,5%. Unsere Spiel-KI muss sich auf den Brandschutz vorbereiten.
Eine weitere interessante Methode ist die Verwendung des Naive Bayes-Klassifikators (naiver Bayes-Klassifikator), um große Mengen von Eingabedaten zu untersuchen und die Situation so zu klassifizieren, dass die KI richtig reagiert. Bayesianische Klassifikatoren sind am besten für die Verwendung von E-Mail-Spam-Filtern bekannt. Dort recherchieren sie Wörter, vergleichen sie mit der Stelle, an der diese Wörter früher erschienen (in Spam oder nicht), und ziehen Schlussfolgerungen über eingehende Briefe. Wir können dasselbe auch mit weniger Input tun. Auf der Grundlage aller nützlichen Informationen, die die KI sieht (zum Beispiel, welche feindlichen Einheiten erstellt werden, welche Zauber sie verwenden oder welche Technologien sie erforscht haben) und dem Endergebnis (Krieg oder Frieden, „Quetschen“ oder Verteidigen usw.) - Wir werden das gewünschte KI-Verhalten auswählen.
Alle diese Trainingsmethoden sind ausreichend, es ist jedoch ratsam, sie auf der Grundlage von Testdaten zu verwenden. AI lernt, sich an die verschiedenen Strategien anzupassen, die Ihre Spieletester angewendet haben. Eine KI, die sich nach einer Veröffentlichung an einen Spieler anpasst, kann zu vorhersehbar oder umgekehrt zu komplex werden, um zu gewinnen.
Wertbasierte Anpassung
Angesichts des Inhalts unserer Spielwelt und der Regeln können wir die Werte ändern, die sich auf die Entscheidungsfindung auswirken, und nicht nur die Eingabedaten verwenden. Wir machen das:
- Lassen Sie die KI Daten über den Zustand der Welt und wichtige Ereignisse während des Spiels sammeln (wie oben angegeben).
- Lassen Sie uns einige wichtige Werte basierend auf diesen Daten ändern.
- Wir realisieren unsere Entscheidungen auf der Grundlage der Verarbeitung oder Bewertung dieser Werte.
Ein Agent verfügt beispielsweise über mehrere Räume, in denen er einen Ego-Shooter auf der Karte auswählen kann. Jedes Zimmer hat seinen eigenen Wert, der bestimmt, wie wünschenswert ein Besuch ist. Die KI wählt zufällig anhand des Wertes den Raum aus. Dann merkt sich der Agent, in welchem Raum er getötet wurde, und verringert seinen Wert (die Wahrscheinlichkeit, dass er dorthin zurückkehrt). Ähnliches gilt für die umgekehrte Situation: Wenn der Agent viele Gegner zerstört, erhöht sich der Wert des Raums.
Markov-Modell
Was ist, wenn wir die gesammelten Daten für Prognosen verwenden? Wenn wir uns für einen bestimmten Zeitraum an jeden Raum erinnern, in dem wir den Spieler sehen, werden wir vorhersagen, in welchen Raum der Spieler gehen kann. Indem wir die Bewegung des Spielers in den Räumen (Werte) verfolgen und aufzeichnen, können wir sie vorhersagen.
Nehmen wir drei Räume: rot, grün und blau. Sowie die Beobachtungen, die wir beim Anschauen einer Spielsitzung aufgezeichnet haben:
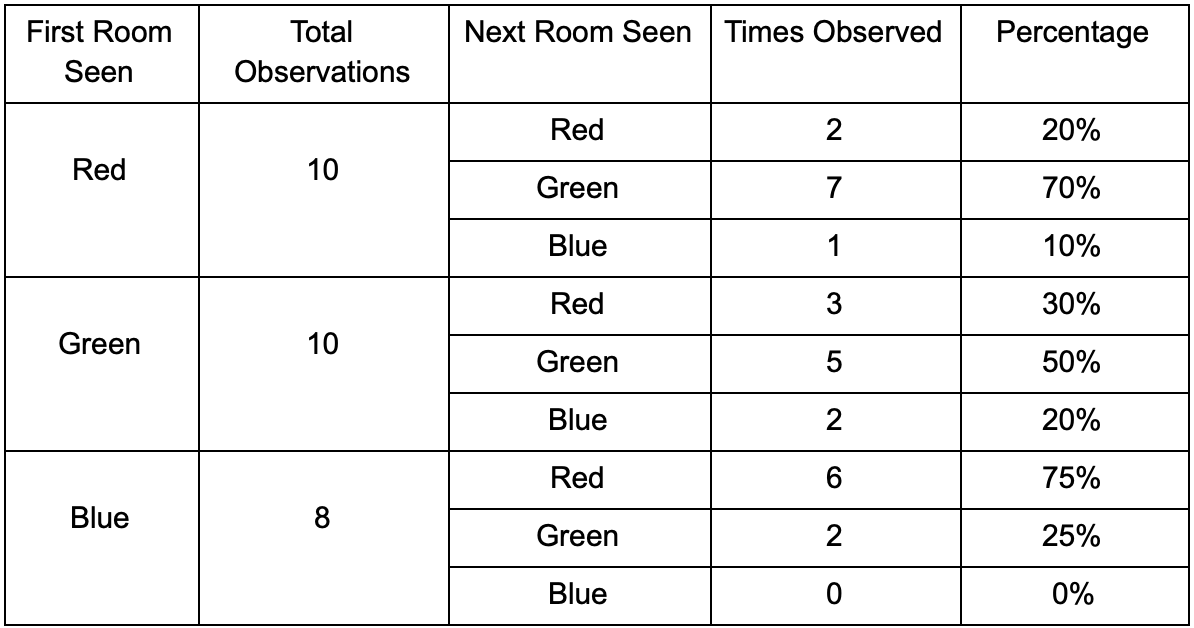
Die Anzahl der Beobachtungen für jeden Raum ist fast gleich - wir wissen immer noch nicht, wo wir einen guten Platz für einen Hinterhalt finden sollen. Das Sammeln von Statistiken wird auch durch das Respawn von Spielern erschwert, die gleichmäßig auf der Karte erscheinen. Die Daten im nächsten Raum, die sie nach dem Erscheinen auf der Karte eingeben, sind jedoch bereits nützlich.
Es ist zu sehen, dass der grüne Raum zu den Spielern passt - die meisten Leute von Rot gehen dorthin, 50% davon bleiben dort und weiter. Das blaue Zimmer ist im Gegenteil nicht beliebt, es wird fast nie besucht, und wenn ja, verweilt es nicht.
Aber die Daten sagen uns etwas Wichtigeres - wenn sich der Spieler im blauen Raum befindet, ist der nächste Raum, in dem wir ihn höchstwahrscheinlich sehen werden, rot und nicht grün. Trotz der Tatsache, dass der grüne Raum beliebter ist als der rote, ändert sich die Situation, wenn der Spieler blau ist. Der nächste Zustand (d. H. Der Raum, in den der Spieler gehen wird) hängt vom vorherigen Zustand ab (d. H. Dem Raum, in dem sich der Spieler gerade befindet). Aufgrund der Untersuchung von Abhängigkeiten werden wir Prognosen genauer erstellen, als wenn wir die Beobachtungen einfach unabhängig voneinander berechnen würden.
Die Vorhersage eines zukünftigen Zustands auf der Grundlage vergangener Zustandsdaten wird als Markov-Modell bezeichnet, und solche Beispiele (mit Räumen) werden als Markov-Ketten bezeichnet. Da die Modelle die Wahrscheinlichkeit von Änderungen zwischen aufeinanderfolgenden Zuständen darstellen, werden sie visuell als FSMs mit einer Wahrscheinlichkeit in der Nähe jedes Übergangs angezeigt. Früher haben wir FSM verwendet, um den Verhaltensstatus darzustellen, in dem sich der Agent befand. Dieses Konzept gilt jedoch für jeden Status, unabhängig davon, ob er mit dem Agenten zusammenhängt oder nicht. In diesem Fall stellen die Zustände den vom Agenten belegten Raum dar:
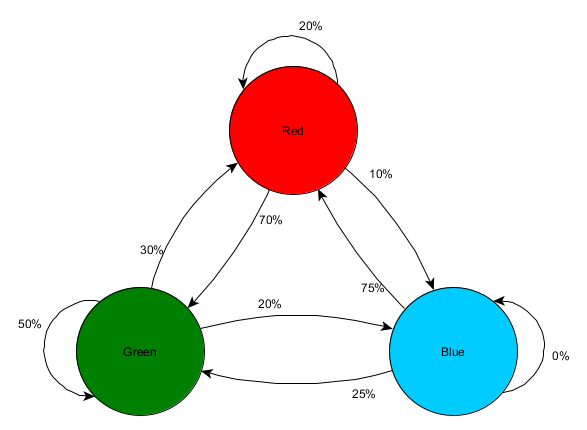
Dies ist eine einfache Version der Darstellung der relativen Wahrscheinlichkeit von Zustandsänderungen, die der KI die Möglichkeit gibt, den nächsten Zustand vorherzusagen. Sie können einige Schritte vorwärts vorhersagen.
Befindet sich der Spieler im grünen Raum, besteht eine 50% ige Chance, dass er bei der nächsten Beobachtung dort bleibt. Aber wie hoch ist die Wahrscheinlichkeit, dass er auch danach noch da sein wird? Es besteht nicht nur die Möglichkeit, dass der Spieler nach zwei Beobachtungen im grünen Raum blieb, sondern auch die Möglichkeit, dass er gegangen ist und zurückgekehrt ist. Hier ist die neue Tabelle mit den neuen Daten:
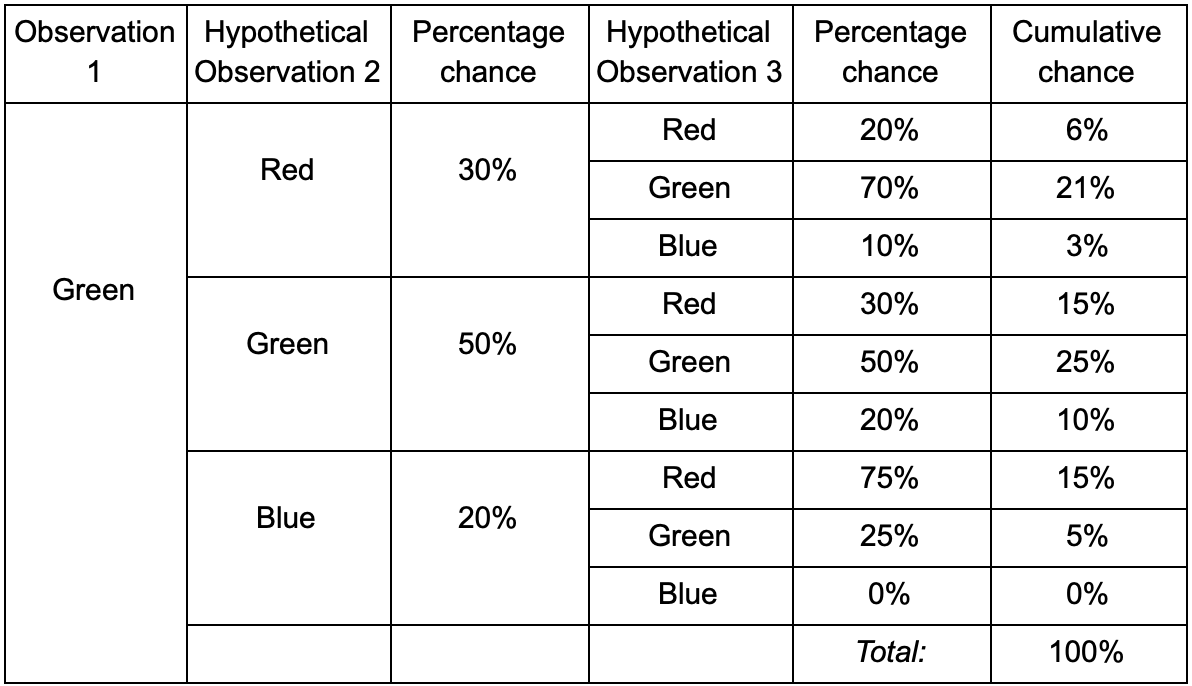
Es zeigt, dass die Chance, einen Spieler nach zwei Beobachtungen im grünen Raum zu sehen, 51% - 21% beträgt, dass er aus dem roten Raum kommt, 5% von ihnen, dass der Spieler den blauen Raum zwischen ihnen besucht und 25%, dass der Spieler dies nicht tut wird das grüne Zimmer verlassen.
Eine Tabelle ist nur ein visuelles Werkzeug - eine Prozedur erfordert nur eine Multiplikation der Wahrscheinlichkeiten bei jedem Schritt. Dies bedeutet, dass Sie mit einer Änderung weit in die Zukunft blicken können: Wir gehen davon aus, dass die Möglichkeit, einen Raum zu betreten, vollständig vom aktuellen Raum abhängt. Dies wird als Markov-Eigenschaft bezeichnet - der zukünftige Zustand hängt nur von der Gegenwart ab. Dies ist jedoch nicht ganz richtig. Spieler können Entscheidungen in Abhängigkeit von anderen Faktoren treffen: Gesundheitszustand oder Munitionsmenge. Da wir diese Werte nicht festlegen, sind unsere Prognosen weniger genau.
N-Gramm
- ? Das selbe! , , -.
— (, Kick, Punch Block) . , Kick, Kick, Punch, SuperDeathFist, , .
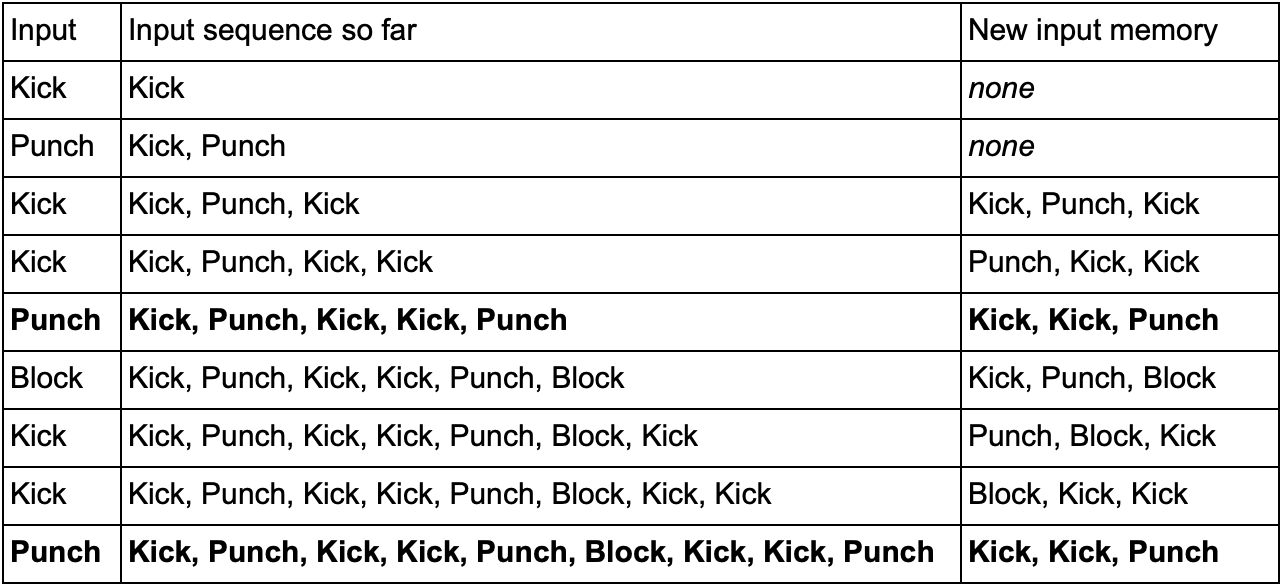
( , SuperDeathFist.)
, Kick, Kick, , Punch. - SuperDeathFist , .
N- (N-grams), N — . 3- (), : . 5- .
N-. N , . , 2- () Kick, Kick Kick, Punch, Kick, Kick, Punch, SuperDeathFist.
, , . Kick, Punch Block, 10-, 60 .
— « / » , . 3- N- , ( N-) , — . Kick Kick Kick Punch. , , , . , , - .
Fazit
. , .
. , , . , :
- , ,
- / (minimax alpha-beta pruning)
- (, )
- ( , )
- ( )
- ( , anytime, timeslicing)
- :
1. GameDev.net
,
.
2.
AiGameDev.com .
3.
The GDC Vault GDC AI, .
4.
AI Game Programmers Guild .
5. , , YouTube-
AI and Games .
:
1. Game AI Pro , , .
Game AI Pro: Collected Wisdom of Game AI ProfessionalsGame AI Pro 2: Collected Wisdom of Game AI ProfessionalsGame AI Pro 3: Collected Wisdom of Game AI Professionals2. AI Game Programming Wisdom — Game AI Pro. , .
AI Game Programming Wisdom 1AI Game Programming Wisdom 2AI Game Programming Wisdom 3AI Game Programming Wisdom 43.
Artificial Intelligence: A Modern Approach — . — .