Frühere Beiträge im Unternehmensblog enthielten kein einziges Konsolenteam, und wir beschlossen, aufzuholen.
Unser Unternehmen verfügt über eine Metrik, mit der große Fehler beim Shared Hosting vermieden werden sollen. Auf jedem gemeinsam genutzten Hosting-Server befindet sich eine Test-Site in WordPress, auf die regelmäßig zugegriffen wird.
So sieht die Testsite auf jedem gemeinsam genutzten Hosting-Server aus
Die Geschwindigkeit und der Erfolg der Standortantwort werden gemessen. Jeder Mitarbeiter des Unternehmens kann sich die allgemeinen Statistiken ansehen und sehen, wie gut es dem Unternehmen geht. Kann den Prozentsatz der erfolgreichen Antworten einer Testwebsite für das gesamte Hosting oder für einen bestimmten Server anzeigen. Es ist nicht erforderlich, Mitarbeiter des Unternehmens zu sein. In der Systemsteuerung sehen Kunden auch Statistiken auf dem Server, auf dem sich ihr Konto befindet.
Wir haben diese Verfügbarkeitsmetrik genannt (der Prozentsatz der erfolgreichen Antworten von der Test-Site auf alle Anfragen an die Test-Site). Kein sehr guter Name, es ist leicht, ihn mit der Verfügbarkeit zu verwechseln, die die Gesamtzeit nach dem letzten Neustart des Servers beträgt.
Der Sommer verging und der Zeitplan für die Betriebszeit ging langsam zurück.
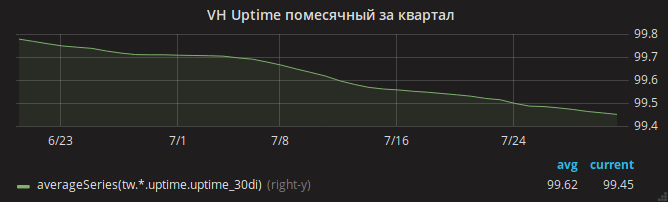
Administratoren identifizierten sofort den Grund - Mangel an RAM. Es war leicht, OOM-Fälle in den Protokollen zu sehen, wenn der Server keinen Speicher mehr hatte und der Kernel Nginx tötete.
Der Abteilungsleiter Andrey teilt eine Aufgabe mithilfe eines Assistenten in mehrere auf und parallelisiert sie zu verschiedenen Administratoren. Man wird die Apache-Einstellungen analysieren - vielleicht sind die Einstellungen nicht optimal und bei viel Verkehr nutzt Apache den gesamten Speicher? Ein anderer analysiert den Speicherverbrauch von mysqld - plötzlich gibt es veraltete Einstellungen aus der Zeit, als Shared Hosting das Gentoo-Betriebssystem verwendete? Der dritte Teil befasst sich mit den letzten Änderungen an den Nginx-Einstellungen.
Nacheinander kehren Administratoren mit Ergebnissen zurück. Jeder konnte den Speicherverbrauch in dem ihm zugewiesenen Bereich reduzieren. Im Fall von nginx wurde beispielsweise eine eingeschlossene, aber nicht verwendete mod_security erkannt. OOM ist mittlerweile auch häufig.
Schließlich ist zu bemerken, dass der Kernspeicherverbrauch (insbesondere SUnreclaim) auf einigen Servern furchtbar hoch ist. Weder in der ps-Ausgabe noch in htop ist dieser Parameter sichtbar, daher haben wir ihn nicht sofort bemerkt! Beispielserver mit infernalischem SUnreclaim:
root@vh28.timeweb.ru:~
Dem Kernel werden 24 Gigabyte RAM zur Verfügung gestellt, und der Kernel gibt sie aus, denn niemand weiß was!
Der Administrator (nennen wir ihn Gabriel) eilt in die Schlacht. Setzt den Kernel mit KMEMLEAK-Optionen zur Lecksuche wieder zusammen.
Optionen für den WiederaufbauUm KMEMLEAK zu aktivieren, geben Sie einfach die unten aufgeführten Optionen an und laden Sie den Kernel mit dem Parameter kmemleak = on.
CONFIG_HAVE_DEBUG_KMEMLEAK=y CONFIG_DEBUG_KMEMLEAK=y CONFIG_DEBUG_KMEMLEAK_DEFAULT_OFF=y CONFIG_DEBUG_KMEMLEAK_EARLY_LOG_SIZE=10000
KMEMLEAK schreibt (in /sys/kernel/debug/kmemleak ) diese Zeilen:
unreferenced object 0xffff88013a028228 (size 8): comm "apache2", pid 23254, jiffies 4346187846 (age 1436.284s) hex dump (first 8 bytes): 00 00 00 00 00 00 00 00 ........ backtrace: [<ffffffff818570c8>] kmemleak_alloc+0x28/0x50 [<ffffffff811d450a>] kmem_cache_alloc_trace+0xca/0x1d0 [<ffffffff8136dcc3>] apparmor_file_alloc_security+0x23/0x40 [<ffffffff81332d63>] security_file_alloc+0x33/0x50 [<ffffffff811f8013>] get_empty_filp+0x93/0x1c0 [<ffffffff811f815b>] alloc_file+0x1b/0xa0 [<ffffffff81728361>] sock_alloc_file+0x91/0x120 [<ffffffff8172b52e>] SyS_socket+0x7e/0xc0 [<ffffffff81003854>] do_syscall_64+0x54/0xc0 [<ffffffff818618ab>] return_from_SYSCALL_64+0x0/0x6a [<ffffffffffffffff>] 0xffffffffffffffff unreferenced object 0xffff880d67030280 (size 624): comm "hrrb", pid 23713, jiffies 4346190262 (age 1426.620s) hex dump (first 32 bytes): 01 00 00 00 03 00 ff ff 00 00 00 00 00 00 00 00 ................ 00 e7 1a 06 10 88 ff ff 00 81 76 6e 00 88 ff ff ..........vn.... backtrace: [<ffffffff818570c8>] kmemleak_alloc+0x28/0x50 [<ffffffff811d4337>] kmem_cache_alloc+0xc7/0x1d0 [<ffffffff8172a25d>] sock_alloc_inode+0x1d/0xc0 [<ffffffff8121082d>] alloc_inode+0x1d/0x90 [<ffffffff81212b01>] new_inode_pseudo+0x11/0x60 [<ffffffff8172952a>] sock_alloc+0x1a/0x80 [<ffffffff81729aef>] __sock_create+0x7f/0x220 [<ffffffff8172b502>] SyS_socket+0x52/0xc0 [<ffffffff81003854>] do_syscall_64+0x54/0xc0 [<ffffffff818618ab>] return_from_SYSCALL_64+0x0/0x6a [<ffffffffffffffff>] 0xffffffffffffffff
Gabriel hat uns nicht alle seine Geheimnisse preisgegeben und nicht erzählt, wie er aus den obigen Zeilen die genaue Ursache des Speicherverlusts herausgefunden hat. Höchstwahrscheinlich verwendete er den addr2line /usr/lib/debug/lib/modules/`uname -r`/vmlinux ffffffff81722361 , um die genaue Zeile zu finden. Oder öffnen Sie net/socket.c und sehen Sie sie sich an, bis die Datei unangenehm wird.
Das Problem stellte sich als Patch in der net/socket.c , der vor vielen Jahren zu unserem Repository hinzugefügt wurde. Der Zweck besteht darin, Clients die Verwendung des Systemaufrufs bind () zu untersagen. Dies ist ein einfacher Schutz gegen Proxyserver, die von Clients gestartet werden. Der Patch hat seinen Zweck erfüllt, aber den Speicher nach sich selbst nicht gelöscht.
Möglicherweise gab es in PHP neue modische Malware, die versuchte, einen Proxyserver in einer Schleife auszuführen - was zu Hunderttausenden blockierter bind () -Aufrufe und einem Verlust von Gigabyte RAM führte.
Dann war es einfach - Gabriel reparierte den Patch und baute den Kernel neu auf. Überwachung des Werts von SUnreclaim auf allen Servern unter Linux hinzugefügt. Ingenieure warnten Kunden und starteten das Hosting im neuen Kern neu.
OOM verschwand.
Das Problem mit der Verfügbarkeit von Websites blieb jedoch bestehen
Auf allen Servern reagierte die Testwebsite mehrmals täglich nicht mehr.
Hier fing der Autor an, Haare an verschiedenen Körperteilen zu reißen. Aber Gabriel blieb ruhig und schaltete die Aufzeichnung des Datenverkehrs zu Teilen der Hosting-Server ein.
Im Verkehrsdump wurde festgestellt, dass die Anforderung an die Teststelle am häufigsten nach dem plötzlichen Empfang eines TCP RST Pakets fällt. Mit anderen Worten, die Anforderung erreichte den Server, aber die Verbindung wurde von nginx unterbrochen.
Noch interessanter! Das von Gabriel gestartete Dienstprogramm strace zeigt, dass der Nginx-Daemon dieses Paket nicht sendet. Wie kann das sein, weil nur Nginx Port 80 abhört?
Der Grund war eine Kombination mehrerer Faktoren:
- In den
reuseport Einstellungen wird die Option " reuseport " reuseport (einschließlich der Socket- SO_REUSEPORT ), mit der verschiedene Prozesse Verbindungen an derselben Adresse und demselben Port akzeptieren können - In der (zu diesem Zeitpunkt neuesten) Version von Nginx 1.13.0 gibt es einen Fehler, aufgrund dessen dieser Nginx-Testprozess beim Starten des Nginx-Konfigurationstests über
nginx -t und unter Verwendung der SO_REUSEPORT wirklich begann, Port 80 abzuhören und Anforderungen von echten Clients abzufangen . Am Ende des Konfigurationstestprozesses erhielten die Clients die Connection reset by peer - Schließlich wurde bei der Überwachung des zabbix die Überwachung der Korrektheit der Nginx-Konfiguration auf allen Servern mit installiertem Nginx konfiguriert: Der Befehl
nginx -t wurde einmal pro Minute auf ihnen aufgerufen.
Erst nach der Aktualisierung von Nginx können Sie ruhig ausatmen. Das Betriebszeitdiagramm der Websites ist gestiegen.
Was ist die Moral dieser ganzen Geschichte? Seien Sie optimistisch und vermeiden Sie die Verwendung selbstorganisierter Kernel.