Die Aufrechterhaltung einer riesigen Codebasis bei gleichzeitiger Gewährleistung einer hohen Produktivität für eine große Anzahl von Entwicklern ist eine ernsthafte Herausforderung. In den letzten 5 Jahren hat Yandex ein spezielles System für die kontinuierliche Integration entwickelt. In diesem Artikel werden wir über die Größe der Yandex-Codebasis sprechen, über die Übertragung der Entwicklung in ein einzelnes Repository mit einem stammbasierten Entwicklungsansatz und darüber, welche Aufgaben ein kontinuierliches Integrationssystem lösen muss, um unter solchen Bedingungen effektiv zu arbeiten.

Vor vielen Jahren hatte Yandex keine besonderen Regeln für die Entwicklung von Diensten: Jede Abteilung konnte beliebige Sprachen, Technologien und Bereitstellungssysteme verwenden. Und wie die Praxis gezeigt hat, hat diese Freiheit nicht immer dazu beigetragen, schneller voranzukommen. Zu dieser Zeit gab es zur Lösung der gleichen Probleme häufig mehrere proprietäre oder Open-Source-Entwicklungen. Als das Unternehmen wuchs, funktionierte ein solches Ökosystem schlechter. Gleichzeitig wollten wir ein einziges großes Yandex bleiben und uns nicht in viele unabhängige Unternehmen aufteilen, da dies viele Vorteile bietet: Viele Menschen erledigen die gleichen Aufgaben, die Ergebnisse ihrer Arbeit können wiederverwendet werden. Ausgehend von einer Vielzahl von Datenstrukturen wie verteilten Hash-Tabellen und Warteschlangen ohne Sperren und endend mit vielen verschiedenen speziellen Codes, die wir über 20 Jahre geschrieben haben.
Viele der Aufgaben, die wir lösen, lösen sich in der Open-Source-Welt nicht. Es gibt kein MapReduce, das auf unseren Volumes (über 5000 Server) und unseren Aufgaben gut funktioniert. Es gibt keinen Task-Tracker, der all unsere zig Millionen Tickets verarbeiten kann. Das ist attraktiv in Yandex - Sie können wirklich großartige Dinge tun.
Wir verlieren jedoch ernsthaft an Effizienz, wenn wir dieselben Probleme erneut lösen, vorgefertigte Lösungen wiederholen und die Integration zwischen Komponenten erschweren. Es ist gut und bequem, alles nur für sich selbst in Ihrer eigenen Ecke zu tun. Sie können vorerst nicht an andere denken. Sobald der Dienst jedoch ausreichend auffällt, weist er Abhängigkeiten auf. Es scheint nur, dass verschiedene Dienste nur schwach voneinander abhängig sind - es gibt viele Verbindungen zwischen verschiedenen Teilen des Unternehmens. Viele Dienste sind über die Yandex-Anwendung / den Browser / usw. verfügbar oder ineinander eingebettet. Zum Beispiel erscheint Alice im Browser. Mit Alice können Sie ein Taxi bestellen. Wir alle verwenden gemeinsame Komponenten: YT , YQL , Nirvana .
Das alte Entwicklungsmodell hatte erhebliche Probleme. Aufgrund des Vorhandenseins vieler Repositories ist es für einen normalen Entwickler, insbesondere für Anfänger, schwierig, Folgendes herauszufinden:
- Wo ist die Komponente?
- wie es funktioniert: Es gibt keine Möglichkeit zum "Nehmen und Lesen"
- Wer entwickelt und unterstützt es jetzt?
- Wie fange ich an, es zu benutzen?
Infolgedessen trat das Problem der gegenseitigen Verwendung von Komponenten auf. Komponenten konnten fast keine anderen Komponenten verwenden, da sie "Black Boxes" für einander darstellten. Dies wirkte sich negativ auf das Unternehmen aus, da die Komponenten nicht nur nicht wiederverwendet, sondern häufig nicht verbessert wurden. Viele Komponenten wurden dupliziert, die Menge an Code, die unterstützt werden musste, nahm erheblich zu. Wir bewegten uns im Allgemeinen langsamer als wir konnten.
Single Repository und Infrastruktur
Vor 5 Jahren haben wir ein Projekt gestartet, um die Entwicklung auf ein einziges Repository zu übertragen, mit gemeinsamen Systemen für Montage, Test, Bereitstellung und Überwachung.
Das Hauptziel, das wir erreichen wollten, war es, die Hindernisse zu beseitigen, die die Integration des Codes eines anderen verhindern. Das System sollte einen einfachen Zugriff auf den fertigen Arbeitscode, ein klares Schema für die Verbindung und Verwendung sowie die Sammelbarkeit bieten: Projekte werden immer gesammelt (und bestehen Tests).
Als Ergebnis des Projekts entstand ein einziger Stapel von Infrastrukturtechnologien für das Unternehmen: Quellcode-Speicher, Code-Überprüfungssystem, Build-System, kontinuierliches Integrationssystem, Bereitstellung, Überwachung.
Jetzt wird der größte Teil des Quellcodes für Yandex-Projekte in einem einzelnen Repository gespeichert oder wird gerade verschoben:
- Über 2000 Entwickler arbeiten an Projekten.
- mehr als 50.000 Projekte und Bibliotheken.
- Die Repository-Größe überschreitet 25 GB.
- Mehr als 3.000.000 Commits wurden bereits für das Repository festgeschrieben.
Pluspunkte für das Unternehmen:
- Jedes Projekt aus dem Repository erhält eine vorgefertigte Infrastruktur:
- ein System zum Anzeigen und Navigieren des Quellcodes und ein Codeüberprüfungssystem.
- Montagesystem und verteilte Montage. Dies ist ein separates großes Thema, das wir in den folgenden Artikeln auf jeden Fall behandeln werden.
- kontinuierliches Integrationssystem.
- Bereitstellung, Integration in das Überwachungssystem.
- Code-Sharing, aktive Teaminteraktion.
- Der gesamte Code ist üblich. Sie können zu einem anderen Projekt kommen und dort die erforderlichen Änderungen vornehmen. Dies ist besonders wichtig in einem großen Unternehmen, da ein anderes Team, von dem Sie etwas benötigen, möglicherweise nicht über die Ressourcen verfügt. Mit dem allgemeinen Code haben Sie die Möglichkeit, einen Teil der Arbeit selbst zu erledigen und die Änderungen zu „unterstützen“, die Sie benötigen.
- Es besteht die Möglichkeit, ein globales Refactoring durchzuführen. Sie müssen keine alten Versionen Ihrer API oder Bibliothek unterstützen. Sie können sie ändern und die Stellen ändern, an denen sie in anderen Projekten verwendet werden.
- Der Code wird weniger "vielfältig". Sie haben eine Reihe von Möglichkeiten, um Probleme zu lösen, und es ist nicht erforderlich, eine andere Möglichkeit hinzuzufügen, die ungefähr dasselbe bewirkt, jedoch mit geringfügigen Unterschieden.
- In dem Projekt neben Ihnen wird es höchstwahrscheinlich keine absolut exotischen Sprachen und Bibliotheken geben.
Es versteht sich auch, dass ein solches Entwicklungsmodell Nachteile aufweist, die berücksichtigt werden müssen:
- Ein gemeinsam genutztes Repository erfordert eine separate, spezifische Infrastruktur.
- Die Bibliothek, die Sie benötigen, befindet sich möglicherweise nicht im Repository, ist jedoch Open Source. Das Hinzufügen und Aktualisieren ist kostenpflichtig. Stark abhängig von Sprache und Bibliothek, irgendwo fast kostenlos, irgendwo sehr teuer.
- Sie müssen ständig an der "Gesundheit" des Codes arbeiten. Dies beinhaltet zumindest den Kampf gegen unnötige Abhängigkeiten und toten Code.
Unser Ansatz für ein gemeinsames Repository legt allgemeine Regeln fest, die jeder befolgen muss. Bei Verwendung eines einzelnen Repositorys gelten Einschränkungen für die verwendeten Sprachen, Bibliotheken und Bereitstellungsmethoden. Aber im benachbarten Projekt wird alles gleich oder sehr ähnlich zu Ihrem sein, und Sie können dort sogar etwas reparieren.
Das Modell eines gemeinsamen Endlagers gilt für alle großen Unternehmen. Das monolithische Repository ist ein großes, gut untersuchtes und diskutiertes Thema, daher werden wir jetzt nicht mehr viel darauf eingehen. Wenn Sie mehr wissen möchten, finden Sie am Ende des Artikels mehrere nützliche Links, die dieses Thema ausführlicher behandeln.
Bedingungen, unter denen das kontinuierliche Integrationssystem arbeitet
Die Entwicklung erfolgt nach dem Trunk-basierten Entwicklungsmodell. Die meisten Benutzer arbeiten mit HEAD oder der neuesten Kopie des Repositorys, die aus dem Hauptzweig Trunk stammt, in dem die Entwicklung läuft. Das Festschreiben von Änderungen am Repository erfolgt nacheinander. Unmittelbar nach dem Festschreiben ist der neue Code sichtbar und kann von allen Entwicklern verwendet werden. Die Entwicklung in separaten Filialen wird nicht gefördert, obwohl Filialen für Releases verwendet werden können.
Projekte hängen vom Quellcode ab. Projekte und Bibliotheken bilden ein komplexes Abhängigkeitsdiagramm. Dies bedeutet, dass Änderungen, die in einem Projekt vorgenommen wurden, möglicherweise Auswirkungen auf den Rest des Repositorys haben.
Ein großer Strom von Commits geht an das Repository:
- mehr als 2000 Commits pro Tag.
- Bis zu 10 Änderungen pro Minute während der Hauptverkehrszeiten.
Die Codebasis enthält über 500.000 Build-Ziele und Tests.
Ohne ein spezielles System der kontinuierlichen Integration unter solchen Bedingungen wäre es sehr schwierig, schnell voranzukommen.
Kontinuierliches Integrationssystem
Das kontinuierliche Integrationssystem startet Baugruppen und Tests für jede Änderung:
- Vorabprüfungen. Sie ermöglichen das Überprüfen des Codes vor dem Festschreiben und das Vermeiden von Unterbrechungstests im Kofferraum. Baugruppen und Tests werden dann auf HEAD ausgeführt. Derzeit werden freiwillige Überprüfungen vor dem Audit gestartet. Für kritische Projekte sind Vorprüfungen erforderlich.
- Überprüfungen nach dem Festschreiben nach dem Festschreiben im Repository.
Builds und Tests werden parallel auf großen Clustern von Hunderten von Servern ausgeführt. Builds und Tests werden auf verschiedenen Plattformen ausgeführt. Unter der Hauptplattform (Linux) werden alle Projekte zusammengestellt und alle Tests unter den anderen Plattformen ausgeführt - eine Teilmenge der vom Benutzer konfigurierbaren.
Nach dem Empfang und der Analyse der Ergebnisse von Baugruppen und dem Ausführen der Tests erhält der Benutzer eine Rückmeldung, z. B. wenn Änderungen Tests unterbrechen.

Bei neuen Montagefehlern oder Tests senden wir eine Benachrichtigung an die Testbesitzer und den Autor der Änderungen. Das System speichert und zeigt die Ergebnisse von Prüfungen auch in einer speziellen Schnittstelle an. Die Weboberfläche des Integrationssystems zeigt den Fortschritt und das Ergebnis des Tests an, aufgeschlüsselt nach Testtyp. Der Bildschirm mit den Scanergebnissen sieht nun folgendermaßen aus:
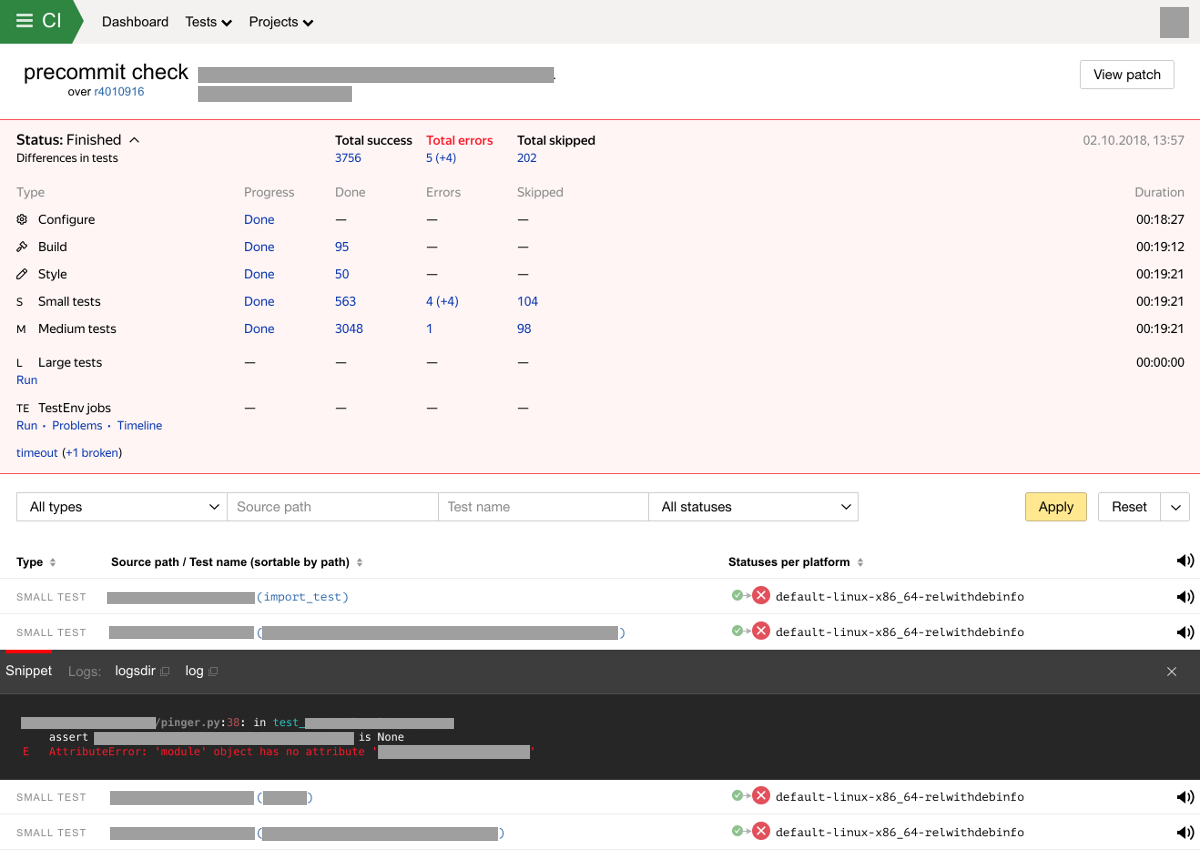
Merkmale und Fähigkeiten des kontinuierlichen Integrationssystems
Um verschiedene Probleme von Entwicklern und Testern zu lösen, haben wir unser System der kontinuierlichen Integration entwickelt. Das System löst bereits viele Probleme, aber es bleibt noch viel zu verbessern.
Arten und Größen von Tests
Es gibt verschiedene Arten von Zielen, die ein kontinuierliches Integrationssystem auslösen kann:
- konfigurieren. Die vom Build-System durchgeführte Konfigurationsphase. Die Konfiguration umfasst eine Analyse der Konfigurationsdateien des Baugruppensystems, die Ermittlung der Abhängigkeiten zwischen Projekten und den Parametern der Baugruppe und die Ausführung der Tests.
- bauen. Zusammenstellung von Bibliotheken und Projekten.
- Stil. Zu diesem Zeitpunkt entspricht der Codestil den angegebenen Anforderungen.
- Test. Die Tests sind entsprechend ihrer Arbeitszeit und den Anforderungen an die Rechenressourcen in Phasen unterteilt.
- klein. <1 min
- mittel. <10 min
- groß. > 10 min Darüber hinaus können spezielle Anforderungen an die Rechenressourcen gestellt werden.
- extra groß. Dies ist eine spezielle Art von Test. Solche Tests zeichnen sich durch eine Reihe der folgenden Merkmale aus: eine lange Betriebszeit, ein hoher Ressourcenverbrauch, eine große Menge an Eingabedaten, sie erfordern möglicherweise spezielle Zugriffe und vor allem Unterstützung für die nachstehend beschriebenen komplexen Testszenarien. Es gibt weniger solche Tests als andere Arten von Tests, aber sie sind sehr wichtig.
Teststartfrequenz und binäre Fehlererkennung
In Yandex werden riesige Ressourcen für Tests bereitgestellt - Hunderte leistungsstarker Server. Aber selbst mit einer großen Anzahl von Ressourcen können wir nicht alle Tests für jede Änderung ausführen, die sie betrifft. Gleichzeitig ist es für uns sehr wichtig, dem Entwickler immer dabei zu helfen, den Ort zu lokalisieren, an dem der Test unterbrochen wird, insbesondere in einem so großen Repository.
Was machen wir Für jede Änderung für alle betroffenen Projekte werden Baugruppen, Stilprüfungen und Tests mit kleinen und mittleren Größen ausgeführt. Der Rest der Tests wird nicht für jedes beeinflussende Commit ausgeführt, sondern mit einer gewissen Periodizität, wenn Commits die Tests beeinflussen. In einigen Fällen können Benutzer die Starthäufigkeit steuern, in anderen Fällen wird die Starthäufigkeit vom System festgelegt. Wenn ein Testfehler erkannt wird, beginnt der Prozess der Suche nach einem Testunterbrechungs-Commit. Je seltener der Test ausgeführt wird, desto länger suchen wir nach einem fehlerhaften Commit, nachdem ein Fehler erkannt wurde.

Beim Starten von Pre-Audit-Prüfungen führen wir auch nur Baugruppen und Lichttests durch. Anschließend kann der Benutzer den Start umfangreicher Tests manuell einleiten, indem er aus der Liste der Tests auswählt, die von den vom System bereitgestellten Änderungen betroffen sind.
Blinkende Testerkennung
Blinktests sind Tests, deren Laufergebnisse (bestanden / fehlgeschlagen) mit demselben Code von verschiedenen Faktoren abhängen können. Die Ursachen für das Flashen von Tests können unterschiedlich sein: Ruhezustand im Testcode, Fehler bei der Arbeit mit Multithreading, Infrastrukturprobleme (Nichtverfügbarkeit von Systemen) usw. Blinktests stellen ein ernstes Problem dar:
- Sie führen dazu, dass das System der kontinuierlichen Integration falsche Warnungen über Testfehler versendet.
- Testergebnisse kontaminieren. Es wird immer schwieriger, über den Erfolg der Verifizierungsergebnisse zu entscheiden.
- Produktfreigaben verzögern.
- Schwer zu erkennen. Tests können sehr selten blinken.
Entwickler können blinkende Tests bei der Analyse der Testergebnisse ignorieren. Manchmal falsch.
Es ist unmöglich, Blinktests vollständig zu eliminieren, dies sollte in einem kontinuierlichen Integrationssystem berücksichtigt werden.
Derzeit führen wir für jeden Test alle Tests zweimal durch, um blinkende Tests zu erkennen. Wir berücksichtigen auch Beschwerden von Nutzern (Empfänger von Benachrichtigungen). Wenn wir ein Blinken feststellen, markieren wir den Test mit einem speziellen Flag (stummgeschaltet) und informieren den Besitzer des Tests. Danach erhalten nur Testbesitzer Benachrichtigungen über Testfehler. Als Nächstes führen wir den Test im normalen Modus weiter aus, während wir den Verlauf seiner Starts analysieren. Wenn der Test in einem bestimmten Zeitfenster nicht blinkt, entscheidet die Automatisierung möglicherweise, dass der Test nicht mehr blinkt, und Sie können das Flag löschen.
Unser aktueller Algorithmus ist recht einfach und an dieser Stelle sind viele Verbesserungen geplant. Zunächst möchten wir viel nützlichere Signale verwenden.
Automatische Aktualisierung der Testeingabe
Beim Testen der komplexesten Yandex-Systeme werden neben anderen Testmethoden häufig Black-Box-Strategietests + datengesteuerte Tests verwendet. Um eine gute Abdeckung zu gewährleisten, erfordern solche Tests einen großen Satz von Eingabedaten. Daten können aus Produktionsclustern ausgewählt werden. Es gibt jedoch ein Problem mit der Tatsache, dass die Daten schnell veraltet sind. Die Welt steht nicht still, unsere Systeme entwickeln sich ständig weiter. Veraltete Testdaten im Laufe der Zeit bieten keine gute Testabdeckung und führen dann vollständig zu einem Testausfall, da Programme beginnen, neue Daten zu verwenden, die in veralteten Testdaten nicht verfügbar sind.
Damit die Daten nicht veraltet sind, kann das kontinuierliche Integrationssystem sie automatisch aktualisieren. Wie funktioniert es
- Testdaten werden in einem speziellen Speicher von Ressourcen gespeichert.
- Der Test enthält Metadaten, die die erforderliche Eingabe beschreiben.
- Die Entsprechung zwischen der erforderlichen Testeingabe und den Ressourcen wird in einem kontinuierlichen Integrationssystem gespeichert.
- Der Entwickler liefert regelmäßig frische Daten an den Ressourcenspeicher.
- Das kontinuierliche Integrationssystem sucht im Ressourcen-Repository nach neuen Versionen von Testdaten und wechselt die Eingabedaten.
Es ist wichtig, die Daten zu aktualisieren, damit der falsche Test nicht auftritt. Sie können nicht einfach ab einem bestimmten Commit neue Daten verwenden, weil Im Falle eines Testausfalls ist nicht klar, wer schuld ist - Commit oder neue Daten. Außerdem werden Diff-Tests (unten beschrieben) außer Betrieb gesetzt.

Daher machen wir es so, dass es ein kleines Intervall von Commits gibt, in denen der Test sowohl mit der alten als auch mit der neuen Version der Eingabedaten gestartet wird.

Diff Tests
Diff-Tests nennen wir eine spezielle Art von datengesteuerten Tests , die sich vom allgemein akzeptierten Ansatz dadurch unterscheiden, dass der Test kein Referenzergebnis hat, aber gleichzeitig müssen wir herausfinden, in welchen Commits der Test sein Verhalten geändert hat.
Der Standardansatz beim datengesteuerten Testen lautet wie folgt. Der Test hat ein Referenzergebnis, das erhalten wurde, als der Test zum ersten Mal durchgeführt wurde. Das Referenzergebnis kann im Repository neben dem Test gespeichert werden. Nachfolgende Testläufe sollten das gleiche Ergebnis liefern.

Wenn das Ergebnis von der Referenz abweicht, muss der Entwickler entscheiden, ob diese erwartete Änderung oder ein Fehler vorliegt. Wenn die Änderung erwartet wird, sollte der Entwickler das Referenzergebnis gleichzeitig mit dem Festschreiben der Änderungen an das Repository aktualisieren.
Es gibt Schwierigkeiten bei der Verwendung dieses Ansatzes in einem großen Repository mit großen Commit-Flows:
- Es kann viele Tests geben und Tests können sehr schwierig sein. Der Entwickler kann nicht alle betroffenen Tests in einer Arbeitsumgebung ausführen.
- Nach dem Vornehmen von Änderungen kann der Test unterbrochen werden, wenn das Referenzergebnis nicht gleichzeitig mit den Änderungen am Code aktualisiert wurde. Dann kann ein anderer Entwickler Änderungen an derselben Komponente vornehmen, und das Testergebnis ändert sich erneut. Wir bekommen die Auferlegung eines Fehlers auf einen anderen. Es ist sehr schwierig, mit solchen Problemen umzugehen, es braucht Zeit von Entwicklern.
Was machen wir Diff-Tests bestehen aus 2 Teilen:
- Komponente prüfen.
- Wir starten den Test und speichern das Ergebnis bei der Speicherung von Ressourcen.
- Vergleichen Sie das Ergebnis nicht mit der Referenz.
- Wir können einige der Fehler abfangen, zum Beispiel, das Programm startet nicht / endet nicht, stürzt ab, das Programm reagiert nicht. Die Validierung des Ergebnisses kann auch durchgeführt werden: Vorhandensein von Feldern in der Antwort usw.
- Diff-Komponente.
- Vergleichen Sie die Ergebnisse verschiedener Starts und bauen Sie diff. Im einfachsten Fall ist dies eine Funktion, die 2 Parameter akzeptiert und diff zurückgibt.
- Das Aussehen von diff hängt vom Test ab, aber es sollte für jemanden verständlich sein, der sich mit diff befasst. Normalerweise ist diff eine HTML-Datei.
Der Start von Check- und Diff-Komponenten wird durch ein kontinuierliches Integrationssystem gesteuert.

Wenn das kontinuierliche Integrationssystem diff erkennt, wird zuerst eine binäre Suche nach dem Commit durchgeführt, das die Änderung verursacht hat. Nachdem Sie eine Benachrichtigung vom Entwickler erhalten haben, können Sie diff untersuchen und entscheiden, was als nächstes zu tun ist: erkennen Sie diff wie erwartet (hierfür müssen Sie eine spezielle Aktion ausführen) oder reparieren / "rollen" Sie Ihre Änderungen zurück.
Fortsetzung folgt
Im nächsten Artikel werden wir darüber sprechen, wie das System der kontinuierlichen Integration funktioniert.
Referenzen
Monolithisches Repository, Trunk-basierte Entwicklung
Datengesteuertes Testen