Bisher konnten Sie unter Avito mithilfe von Keyword-Filterung oder Kategoriebaumnavigation das richtige Produkt finden. Diese Methode war zwar bekannt, aber nicht immer praktisch. Um ein Produkt oder eine Dienstleistung zu finden, musste eine große Anzahl von Klicks ausgeführt werden. Vor mehr als einem Jahr haben wir an Relevanz gewonnen, wodurch die Suche besser geworden ist. Jetzt ist es einfacher und bequemer, ein Produkt oder eine Dienstleistung auch auf der Hauptseite zu finden. Mit dieser Innovation fielen ungeeignete, offen gesagt „Müll“ -Waren nicht mehr in das Thema. Und dies ist nur einer der Schritte, um Ihre Suche zu verbessern. Wir ändern schrittweise die Infrastruktur, wodurch wir intensiver an der Suchqualität arbeiten, diese schneller verbessern und neue Funktionen einführen können, die Verkäufern und Käufern von Avito zugute kommen.
In dem Artikel werde ich Ihnen erzählen, wie sich die Suche nach Avito verändert hat: wie wir angefangen haben und wie wir uns jetzt darauf konzentrieren, das Leben unserer Benutzer zu verbessern, und unsere Innovationen sowohl im Produkt als auch in seiner Füllung - dem technischen Teil - teilen. Es wird hier kein Hardcore-Fleisch geben, aber ich hoffe es gefällt euch.

Einige einleitende Anmerkungen: Avito ist der beliebteste Werbedienst in Russland. Wir haben jeden Tag mehr als 450.000 Anzeigen und die monatliche Anzahl der eindeutigen Besucher erreicht 35 Millionen, was täglich mehr als 140 Millionen Suchanfragen entspricht.
Typisches Suchszenario zuvor
Schauen wir uns ein einfaches Beispiel an, wie eine Suche vor über einem Jahr funktioniert hat. Angenommen, Sie brauchen ein Klavier (warum nicht?). Wir gehen zur Hauptseite und geben "Klavier" ein.
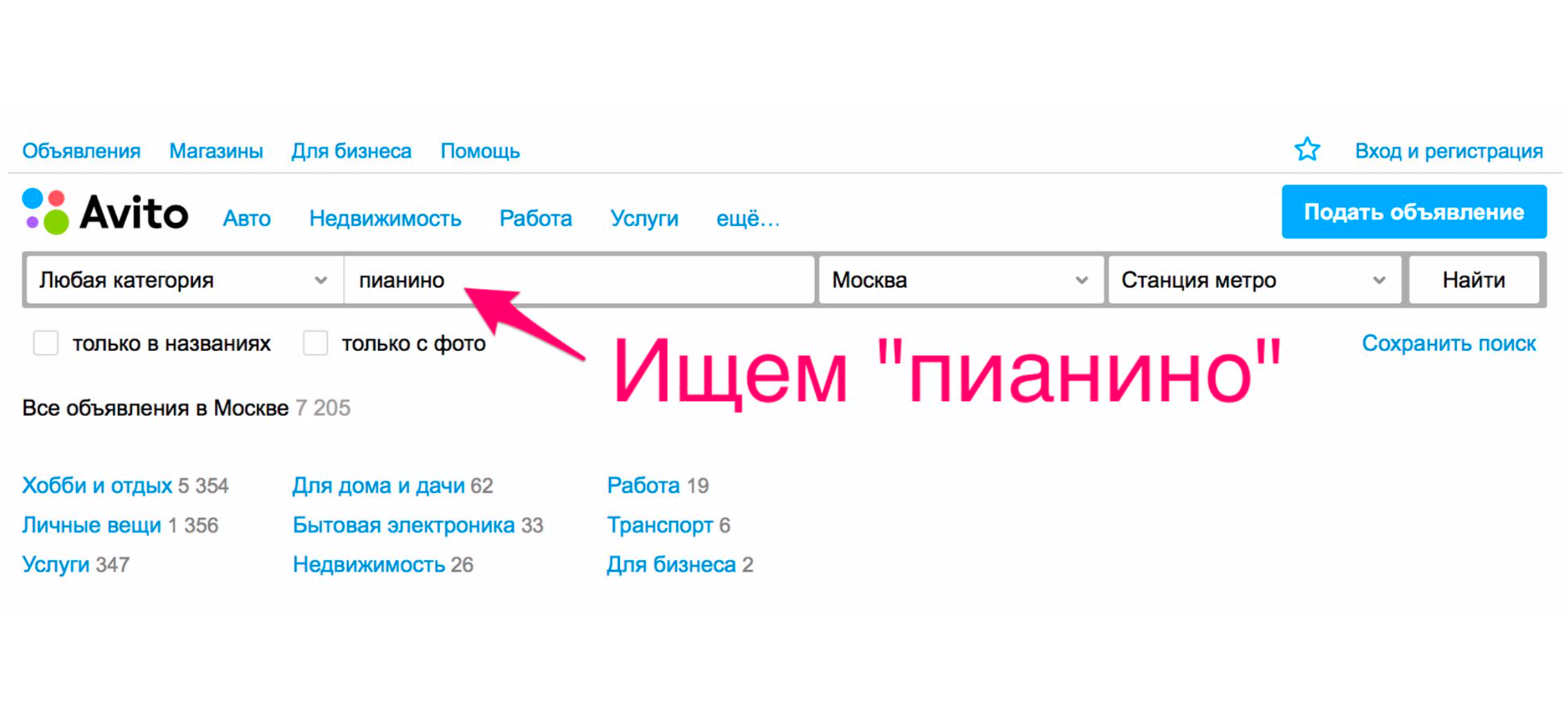
Bei der Auslieferung erhalten Sie höchstwahrscheinlich Umzugsunternehmen, Klaviertransportdienste oder ähnliches, jedoch kein Musikinstrument.

Dies geschieht, weil wir nach dem Datum der Platzierung sortieren müssen - und diese Dienste werden am häufigsten platziert.
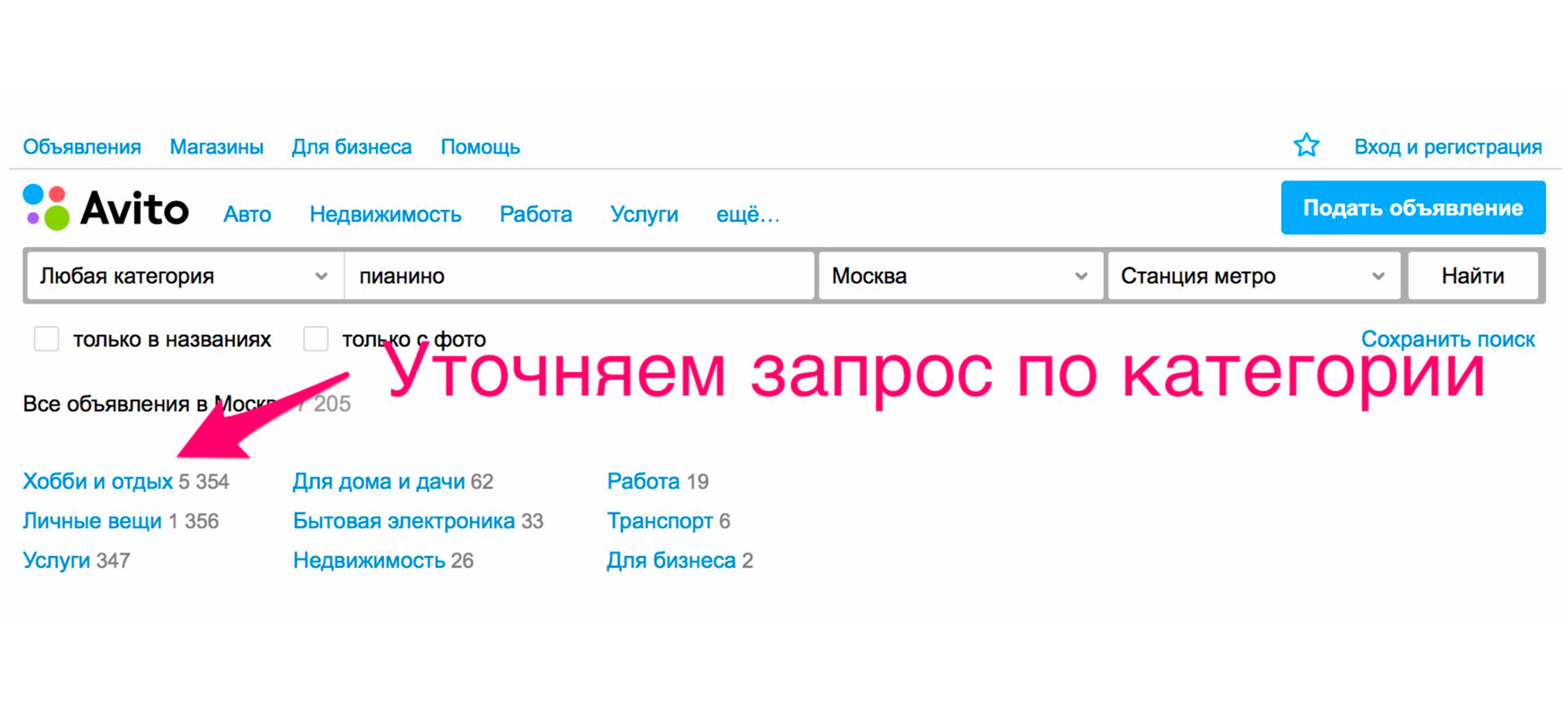
Um das Klavier zu sehen, müssen Sie die Kategorie angeben. Wir klicken auf die Überschrift „Hobbys und Freizeit“, gehen den Kategorienbaum hinunter zu „Musikinstrumente“ und dann zu „Tastaturinstrumenten“.
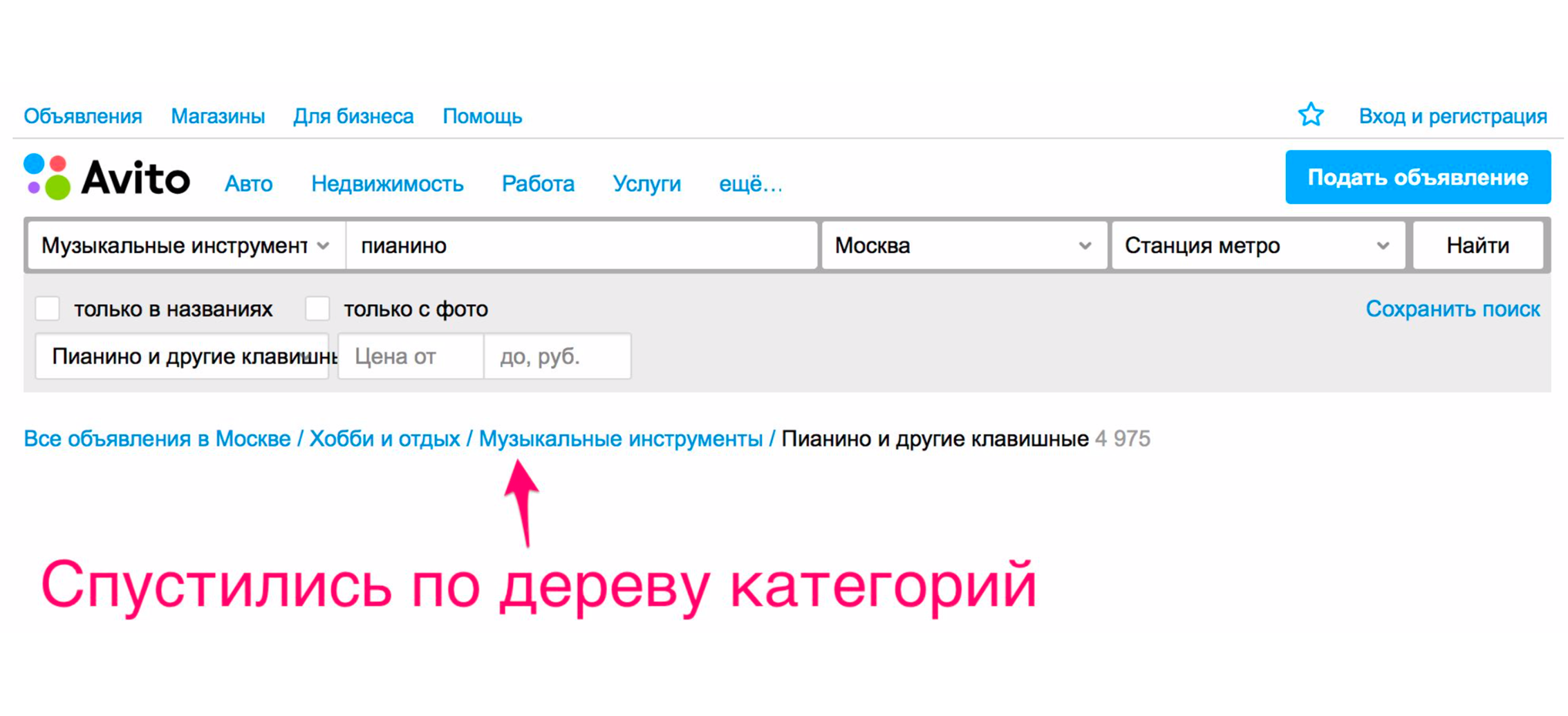
Und erst danach sehen wir das Klavier, das wir gesucht haben.
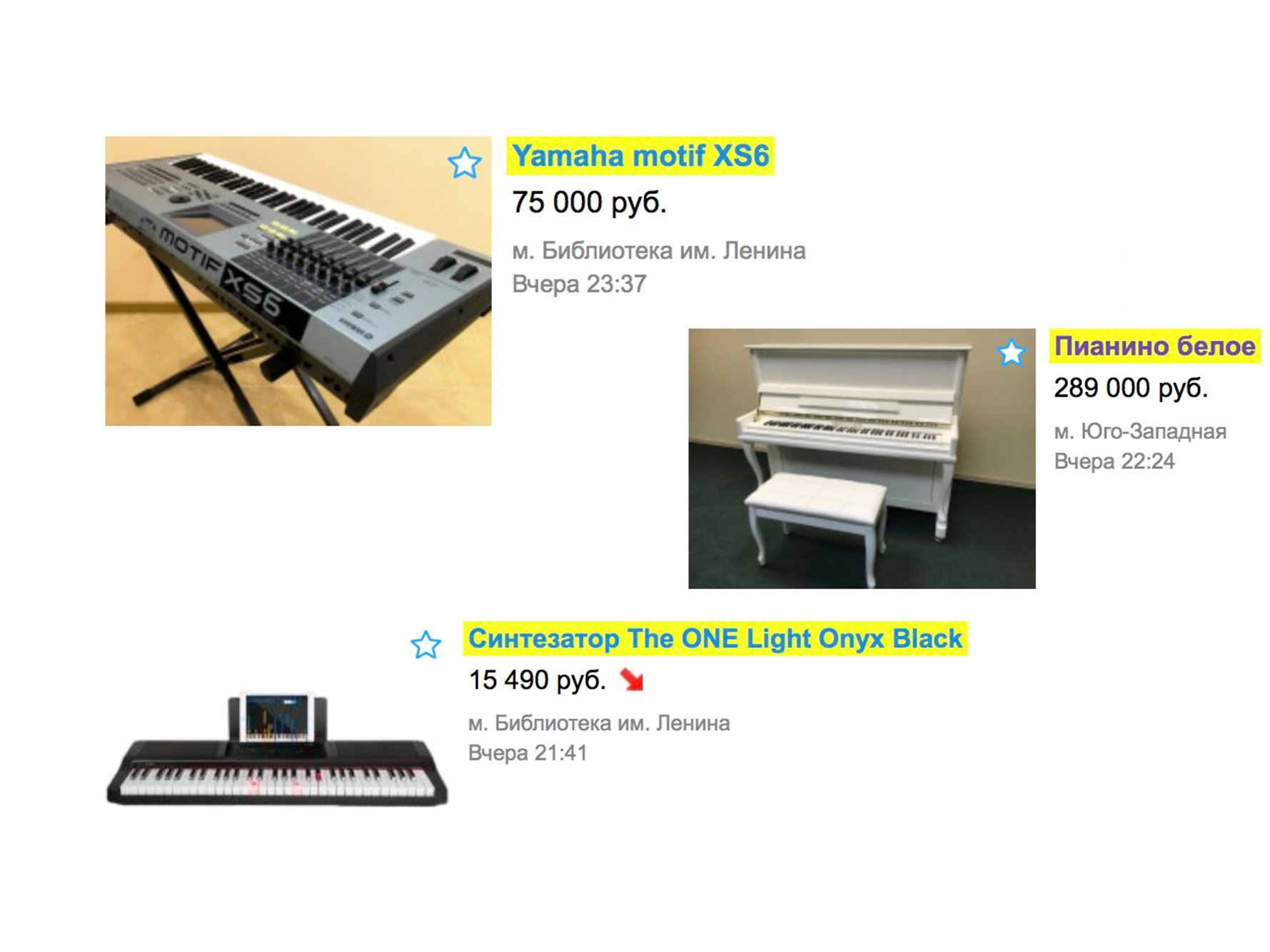
Es stellte sich heraus, dass es die folgenden Optionen gab, um die gewünschte Anzeige zu finden:
- Verfeinerung der Kategorie bei der Suche nach Stichwörtern,
- Sortierung nach Frische und Preis,
- Filter
- Suche nur nach Namen.
Was hat sich aufgrund der Relevanz geändert
Anzeigen, die überhaupt nicht passen, werden aufgrund ihrer Relevanz nicht mehr in die Ausgabe aufgenommen. Wenn Sie auf der Hauptseite nach einem Klavier suchen, werden Sie höchstwahrscheinlich nicht die Dienste von Ladern sehen, die Ihnen beim Transport helfen, aber Sie werden sofort das gewünschte Musikinstrument sehen. Gleichzeitig wurde eine neue Sortierung hinzugefügt - "Standardmäßig". Es besteht aus zwei Indikatoren: Anzeigenrelevanz für die Textabfrage und Aktualität.

Oben sehen Sie die frischesten der relevanten.
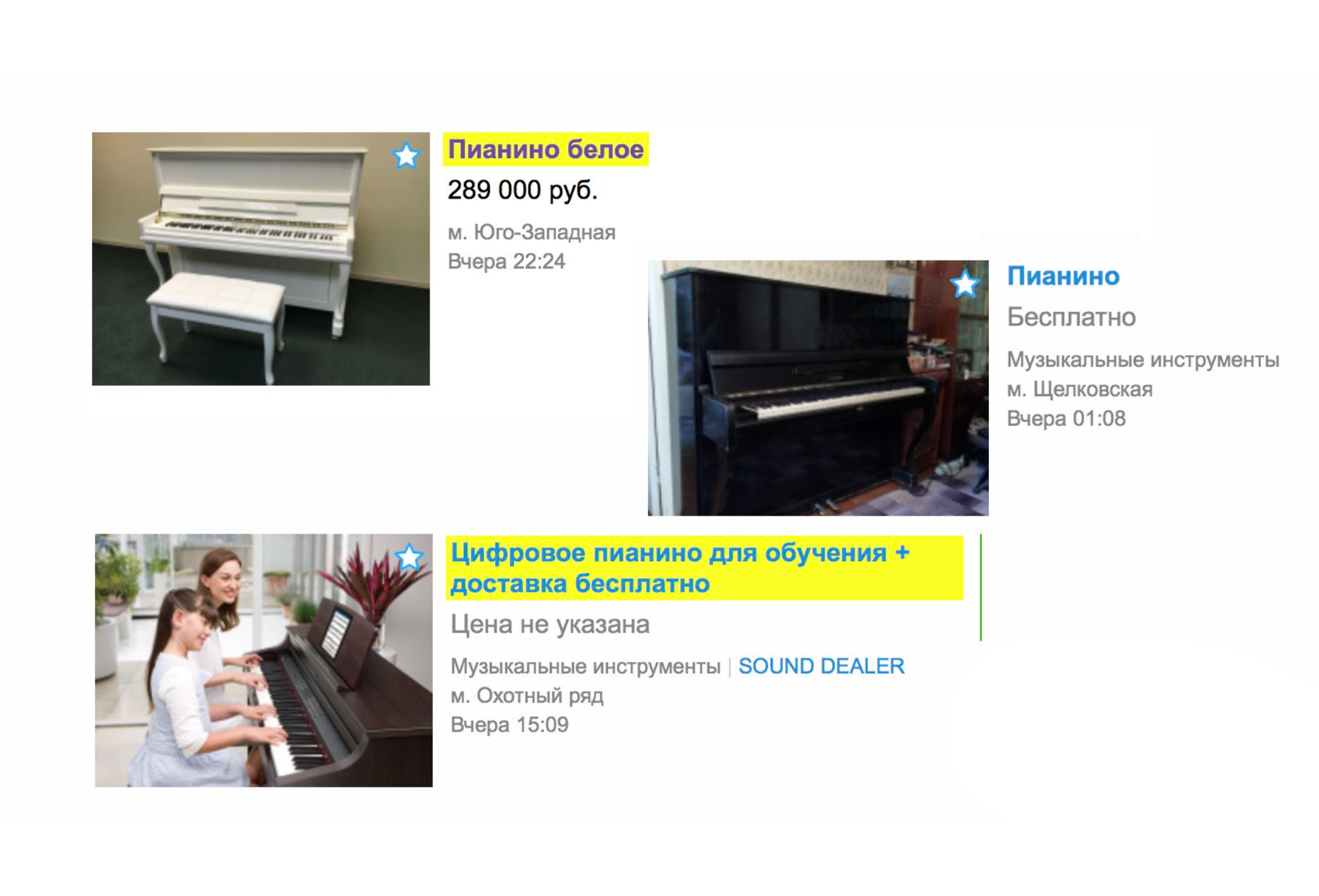
Auf Avito können Sie gegen eine zusätzliche Gebühr Ihre Anzeige schalten. Und mit der Einführung von Relevanz arbeiten bezahlte Erhöhungen effizienter. Sie funktionieren zunächst, wenn Ihre Anzeige für die Textabfrage relevant ist.
Die Einführung von Relevanz bedeutet nicht, dass wir die Übergänge zum Kategoriebaum vollständig aufgegeben haben. In den meisten Fällen haben wir die Anzahl der Klicks auf die gewünschte Anzeige reduziert, wenn wir von der Hauptseite aus gesucht haben. Wenn Sie weiterhin Transportdienste benötigen, obwohl Sie bei der Suche gerade "Klavier" eingegeben haben, durchsuchen Sie den Kategoriebaum und Sie finden diese Anzeigen. Die Suche begann auch effizienter und innerhalb der Kategorie zu arbeiten, zum Beispiel „Persönliche Gegenstände“ und „Haushaltsgeräte“.
So finden Sie mit drei Klicks das richtige Produkt
Die Suche wird für Benutzer nicht nur aufgrund der Qualität der Suchergebnisse bequemer. Es gibt andere Möglichkeiten, dies zu verbessern. Einer von ihnen leitet an die Kategorie weiter. Zum Beispiel suchen wir Lamborghini Gayardo (ja, Sie spielen gerne Klavier und möchten Lamborghini reiten). Um in die Kategorie eines Autos eines bestimmten Modells zu gelangen, müssen Sie zwei zusätzliche Klicks ausführen. Mit Relevanz erhalten Sie höchstwahrscheinlich das, was Sie wollen.
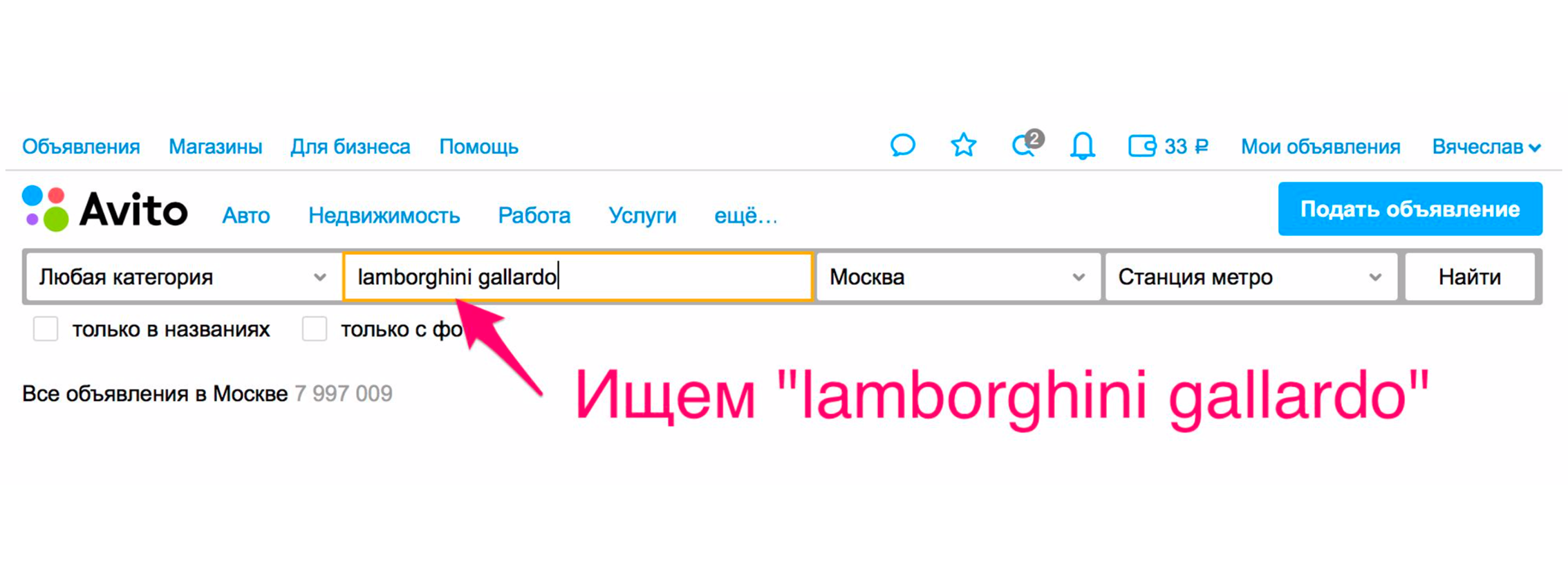
Es gibt jedoch eine zusätzliche Methode, mit der Sie sofort in Autos geworfen werden. Die Ausgabe wird eingegrenzt, das richtige Auto wird in den Filtern ausgewählt und Sie erhalten wirklich Autos in der Ausgabe.
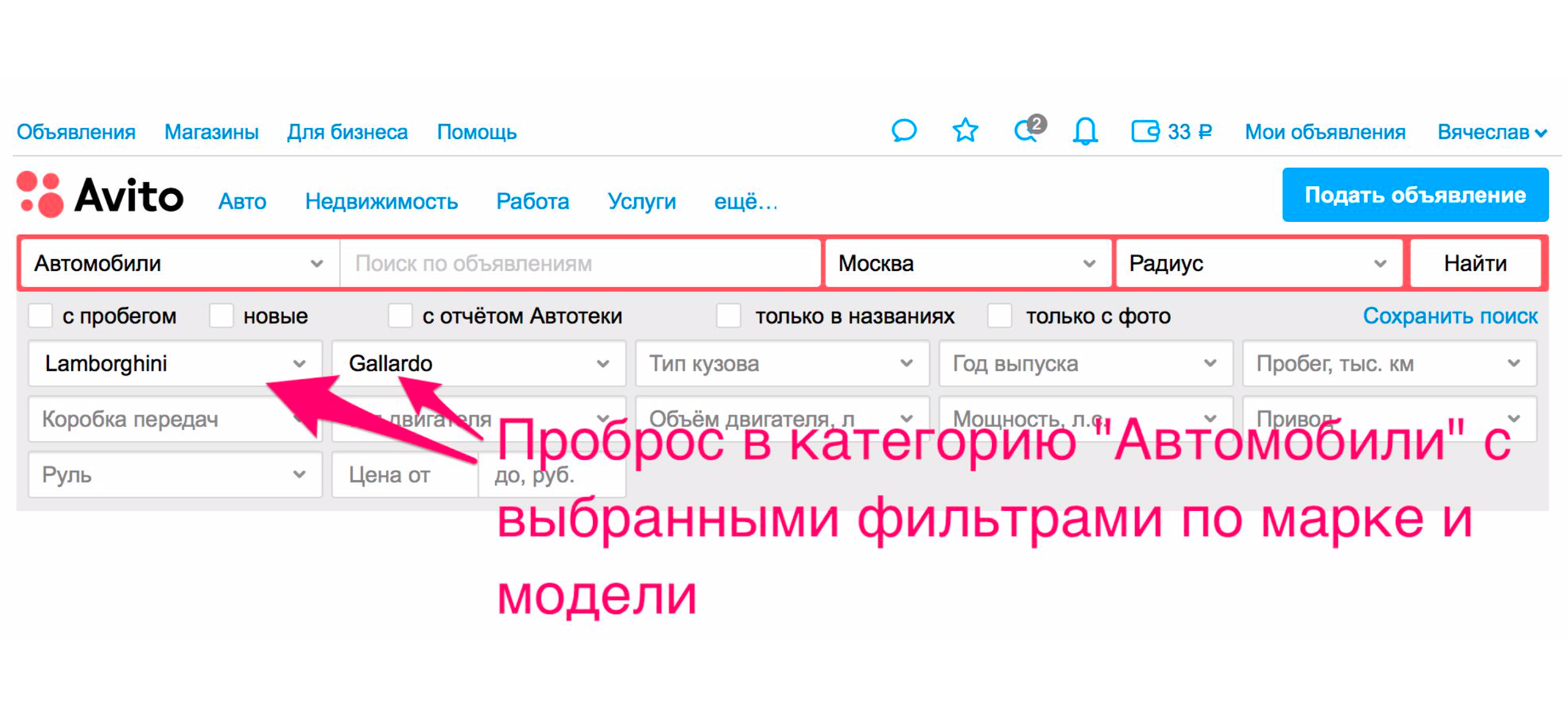

Eine andere Möglichkeit besteht darin, Tags zu erweitern. Wenn Sie beispielsweise das Wort "Jacke" eingeben, erhalten Sie Hinweise.
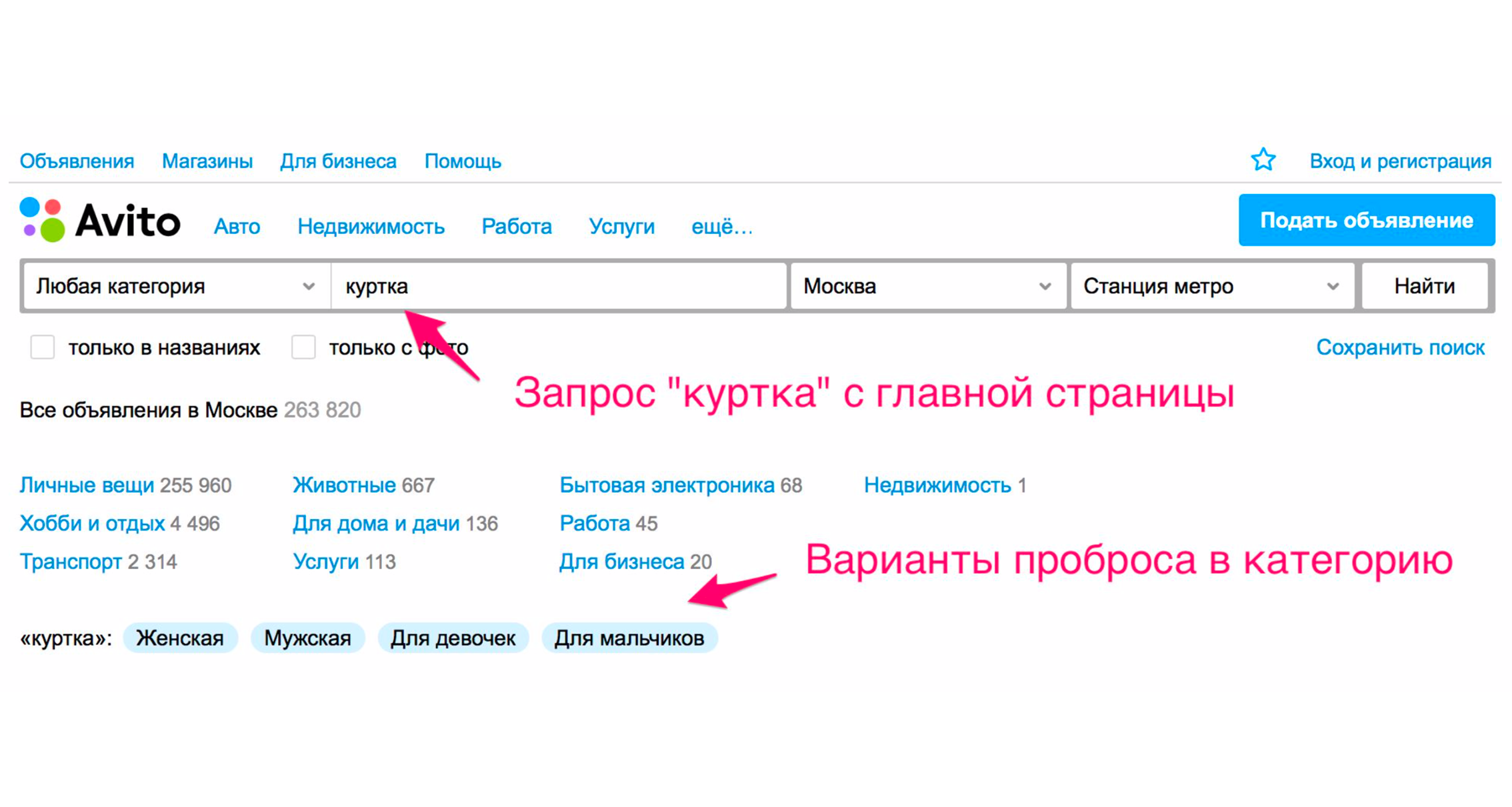
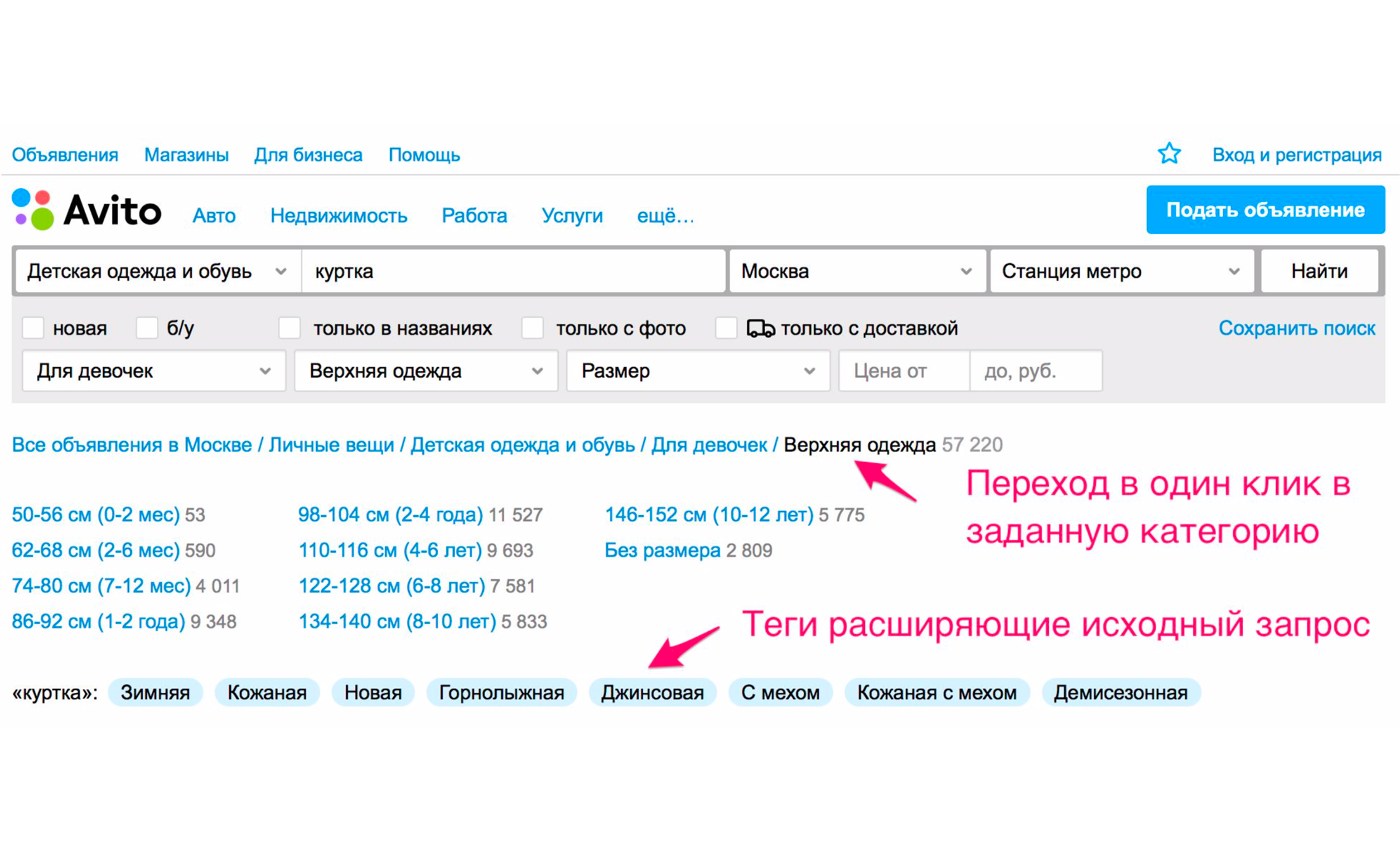
Der Screenshot oben zeigt die Tipps: die Art der Jacken - weiblich, männlich, für Mädchen, für Jungen. Wenn Sie auf "Für Mädchen" klicken, fallen Sie sofort in die Kategorie, in der die entsprechenden Filter ausgewählt werden. Hier wird auch eine Reihe zusätzlicher expandierender Tags angezeigt: Winterjacke, Leder, Neu und so weiter. Wenn Sie den Kategoriebaum manuell zum gewünschten Produkt durchgehen, müssen Sie weitere Aktionen ausführen.
Was ist der Unterschied zwischen Suche und Filtern?
Als ich bei RIT ++ sprach, hatte das Publikum eine Frage: Was ist der Unterschied zwischen Textsuche und Filtern? Alles ist ganz einfach. Sie können die gewünschte Anzeige auch ohne Textanforderung finden, indem Sie den Kategoriebaum durchgehen. In diesem Fall werden bei der Suche weiterhin Waren und Dienstleistungen gefunden, nicht anhand des angegebenen Textes, sondern anhand der Parameter, die von den entsprechenden Filtern der ausgewählten Kategorie übergeben wurden.
Jede Kategorie hat ihre eigenen Filter. Zum Beispiel in der Kategorie „Autos“ - einige Filter, in der Kategorie „Persönliche Dinge“ - andere Filter. Das heißt, Filter sind fest an eine Kategorie gebunden.
Schalten einer Anzeige in zwei Minuten
Für Verkäufer ist eine wichtige Neuerung aufgetaucht, die sie beim Einreichen ihrer Anzeige spüren. Wenn Ihre Anzeige kein "Verbotenes" enthält oder kein Duplikat ist - die übliche gute Anzeige -, wird sie fast sofort in der Ausgabe angezeigt. Eigentlich dauert diese Verzögerung ungefähr zwei Minuten, kann aber in seltenen Fällen auf bis zu 30 Minuten verlängert werden. Bisher wurde eine Anzeige immer erst nach einer halben Stunde auf der Website geschaltet.
Avito-Assistent
Avito Helper ist eine Erweiterung für Chrome, die den Preis eines ähnlichen Produkts auf Avito auf Websites von Drittanbietern anzeigt. In der Erweiterung können Sie die Preise in vielen Online-Shops mit den Preisen für Avito vergleichen oder einfach nach den erforderlichen Waren und Dienstleistungen in unserem Service suchen, ohne direkt auf die Website oder die Anwendung zuzugreifen. Wir konnten den „Assistenten“ auch dank neuer Infrastrukturänderungen implementieren.

Architektur
Einen Monolithen sägen
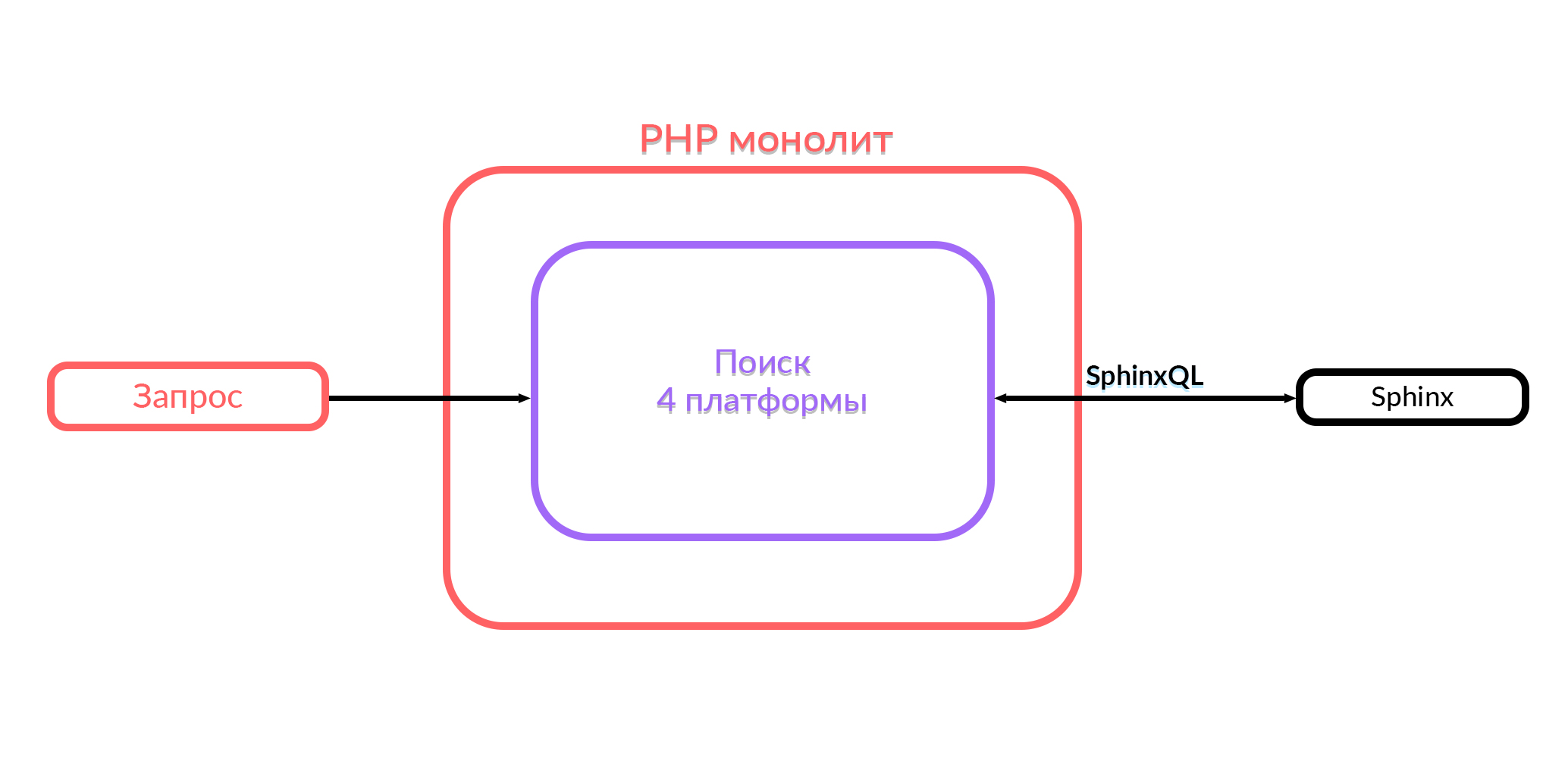
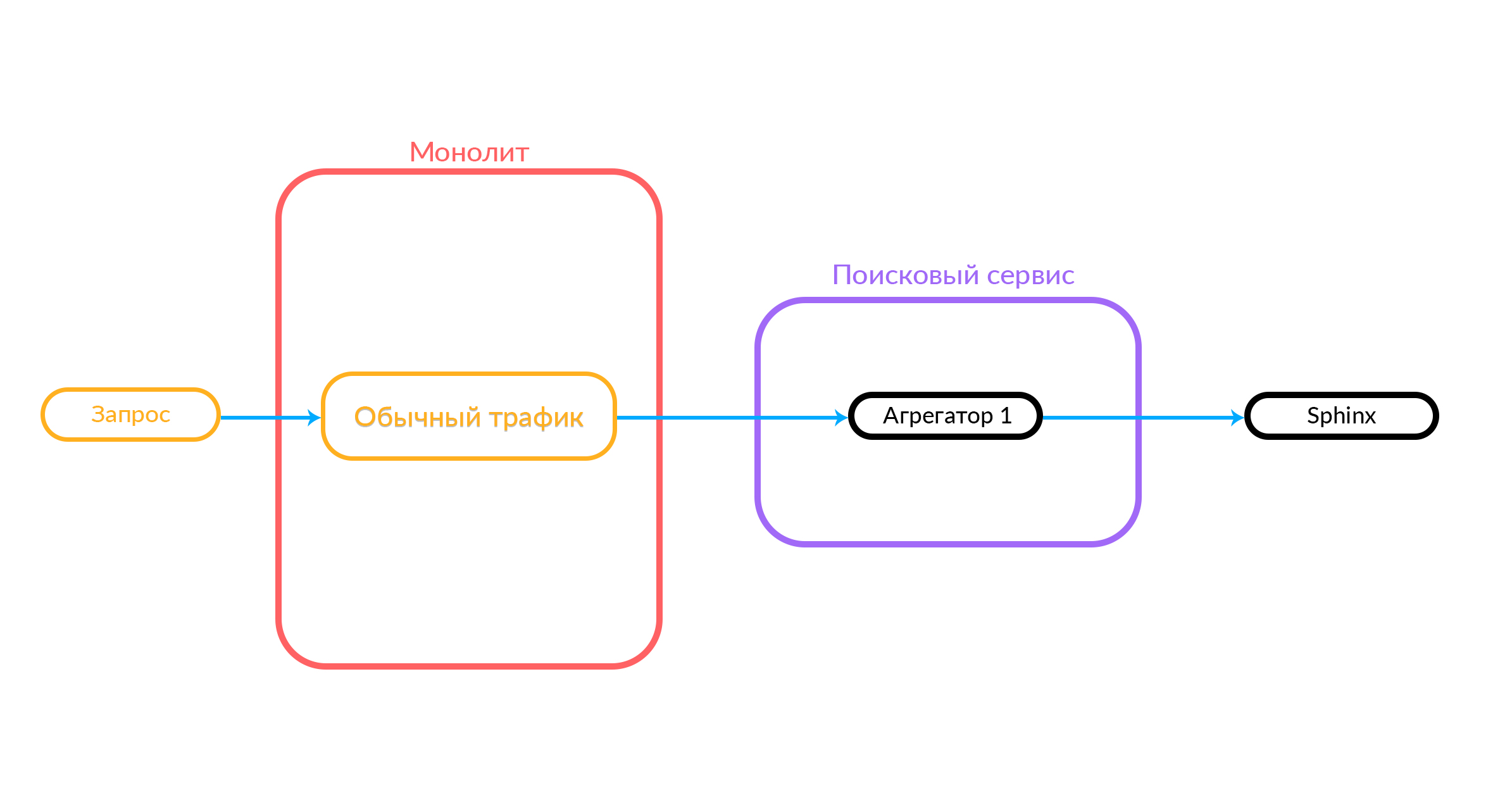
Avito hat einen Monolithen in PHP. Vor einem Jahr befand sich die gesamte Suchfunktion, die in Avito funktioniert, in diesem Monolithen. Die Suche im Monolithen funktionierte mit vier Plattformen: Android, iOS, die mobile Version im Browser und Desktop. Um die Ausgabe zu erhalten, wurden die entsprechenden SQL-Abfragen in Sphinx in diesem Code generiert, die Verarbeitung wurde fortgesetzt und die Ausgabe wurde im JSON- oder HTML-Format gesendet. Dann sahen die Benutzer, wonach sie suchten.
Was wir jetzt haben
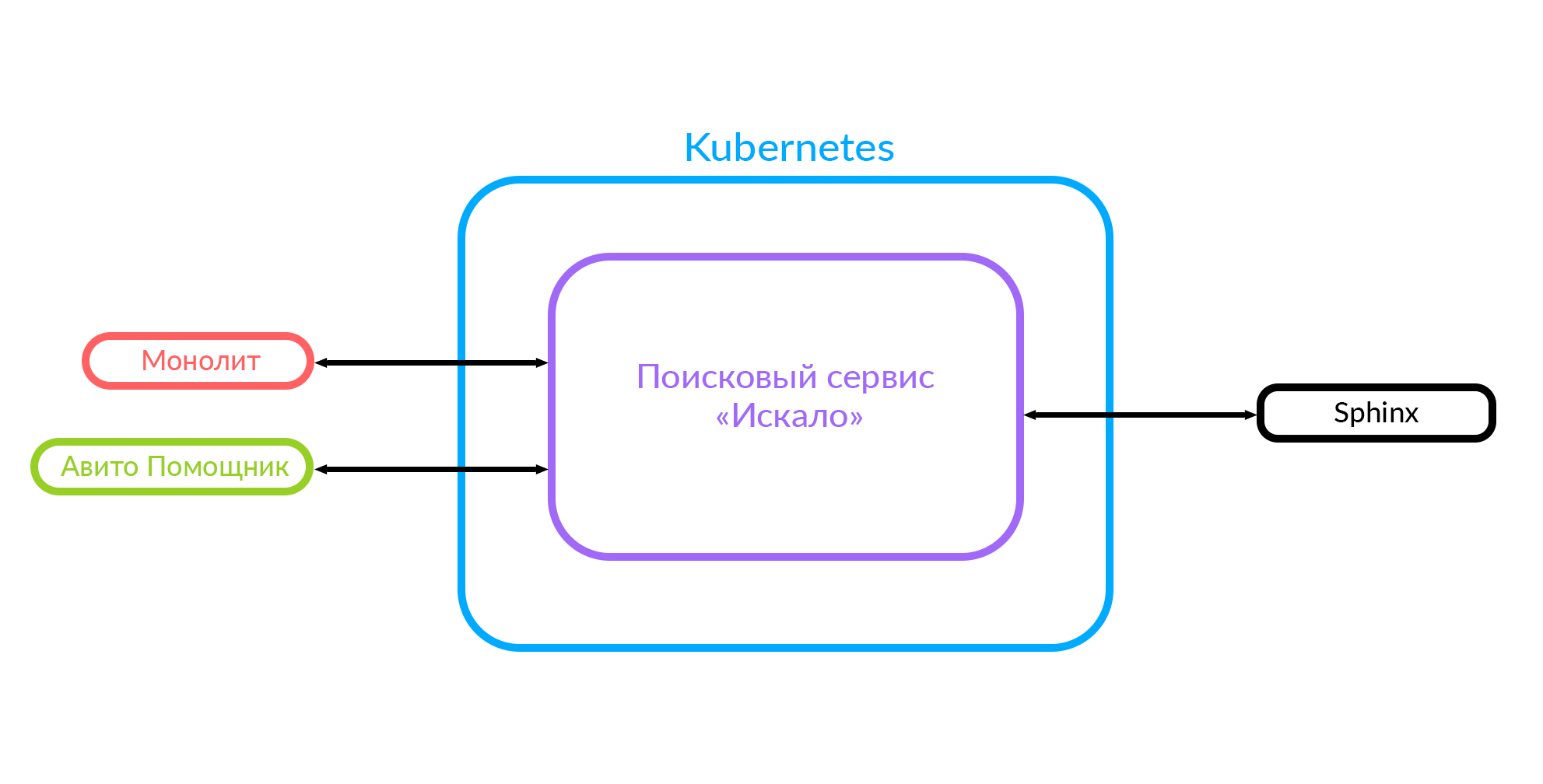
Wenn Sie neue Funktionen implementieren, ist die Integration in diesen Monolithen sehr schwierig. Aus diesem Grund haben wir uns entschlossen, einen Suchdienst zu entwickeln, den wir "Gesucht" nannten. Jetzt geht der Monolith zu diesem Suchdienst und der Dienst geht zu Sphinx.

Gründe für die Erstellung eines Suchdienstes
Bei der Entwicklung von Diensten müssen Sie immer verstehen, warum Sie dies tun. Das erste offensichtliche Plus ist das Entfernen der Logik auf niedriger Ebene. In unserem Fall verbirgt dies die Küche für die Verarbeitung von SphinxQL-Abfragen. Darüber hinaus können wir Suchsystemen für Systeme von Drittanbietern einfacher bereitstellen.
Asynchrone Abfrageausführung. Dieser Vorteil liegt auf der Hand und je nach Implementierung kann der eine oder andere Erfolg erzielt werden. Unser Service wurde auf Golang implementiert und es gab Funktionen, die parallelisiert werden konnten - drei Anfragen in Sphinx, die zu guten Ergebnissen führten.
Schnelle Bereitstellung. Wir haben eine separate Funktion mit weniger Code und zusätzlichen Tests identifiziert (der Monolith verfügt über viele Tests, nicht nur Suchfunktionen), und die Einführung ist einfacher. Vor allem konnten wir aufgrund eines erfolgreichen Ansatzes für die Implementierung dieses Dienstes interessante Dinge reduzieren und fortschrittliche Ranking-Algorithmen implementieren - um eine ziemlich komplizierte Verarbeitung durchzuführen, die wir in einem Monolithen nicht durchführen konnten. Dies bietet uns eine sehr gute Grundlage für das Experimentieren mit der Suchqualität.
Als Bonus haben wir die Möglichkeit, von Sphinx zu Elastic zu wechseln, da die Logik auf niedriger Ebene jetzt verborgen ist.
Dieses Diagramm zeigt bereits den Fall eines Monolithen, des Dienstes "Gesucht" und des Drittanbieter-Dienstes "Avito-Assistent".
Wie funktioniert ein Suchdienst?
Es hat eine Reihe von Aggregatoren. Jeder Aggregator führt eine bestimmte Geschäftslogik aus, die sich auf die Verarbeitung der Ausgabe bezieht. Er kann dieses Thema auf eine bestimmte Weise gestalten.
Die Anfrage kommt beim Scheduler an. Der Scheduler wählt den Aggregator gemäß den Abfragekriterien hinsichtlich seiner Parameter aus (oder wenn der gewünschte Aggregator in der Anforderung selbst angegeben ist). Aggregator geht zur Sphinx. Nachdem eine Antwort von Sphinx erhalten wurde, wird eine Ausgabe generiert und die Antwort an den Client weitergegeben.

In diesem Fall war die Anfrage außerhalb und nicht aus der Cloud, in der unser Suchdienst arbeitet. Es ist aber auch eine andere Option möglich: Einige andere unserer Dienste in der Cloud, z. B. Avito Assistant, wenden sich an einen Suchdienst. Diese Anfrage geht bereits an einen anderen Aggregator - es gibt eine andere Geschäftslogik. So funktioniert es:
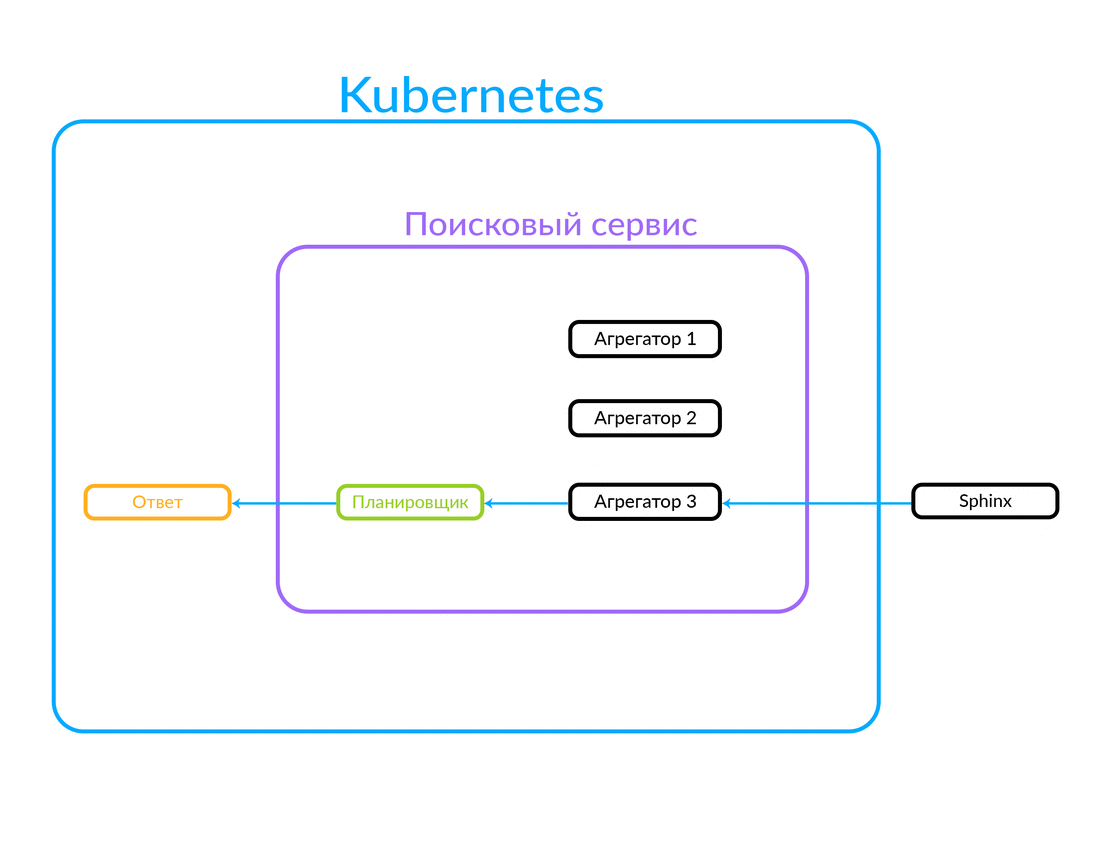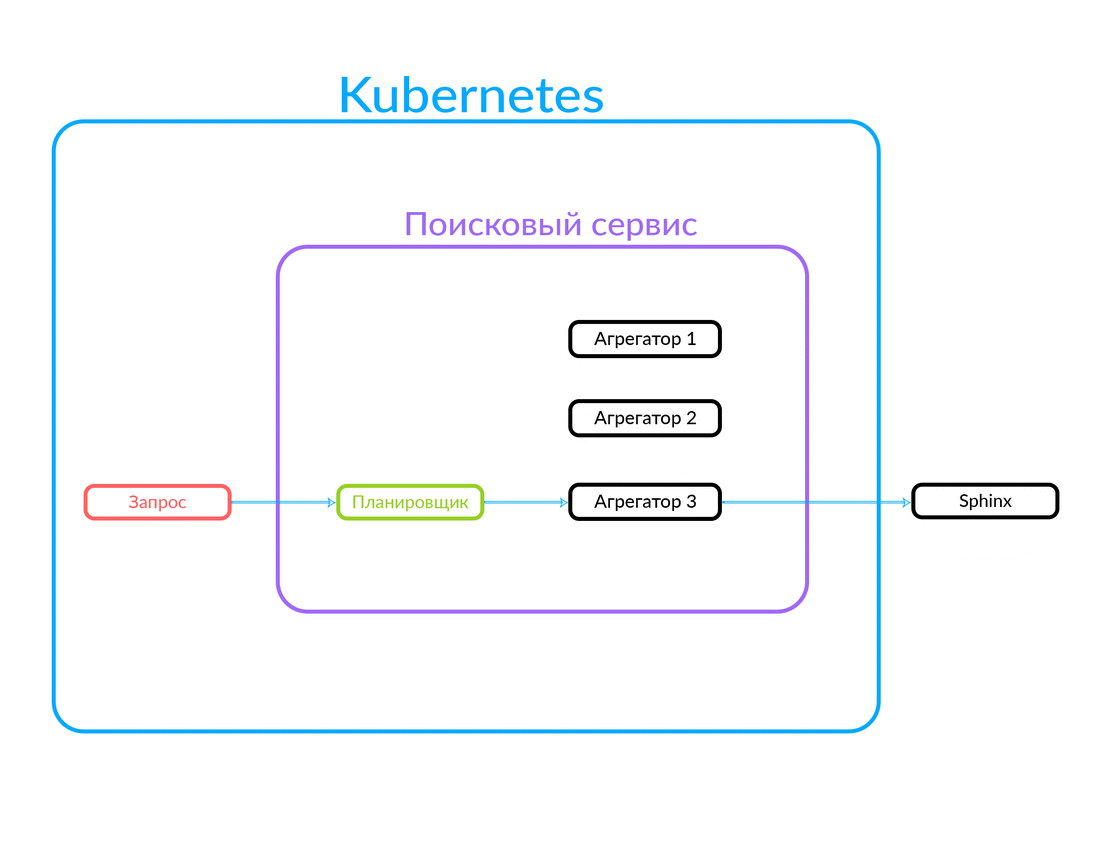
Funktionsweise der asynchronen Abfrageausführung auf dem Aggregator
Der Aggregator besteht aus mehreren Profilen. Ein Profil ist grob gesagt eine Entität, in der Sie eine Ankündigung eines bestimmten Typs oder auf eine bestimmte Art und Weise erhalten können. Dies kann zum Beispiel durch eine Analogie erklärt werden: Es gibt "Premium" -, "VIP" - und reguläre Anzeigen auf Avito. Der Aggregator empfängt eine Anforderung vom Scheduler, während parallele Anforderungen für den im Aggregator bekannten Profilsatz ausgeführt werden. Das Profil enthält einen Treiber, der physisch auf die zugrunde liegende Ebene zugreift, in diesem Fall in Sphinx. Es kann sich jedoch auch um eine andere Datenquelle handeln
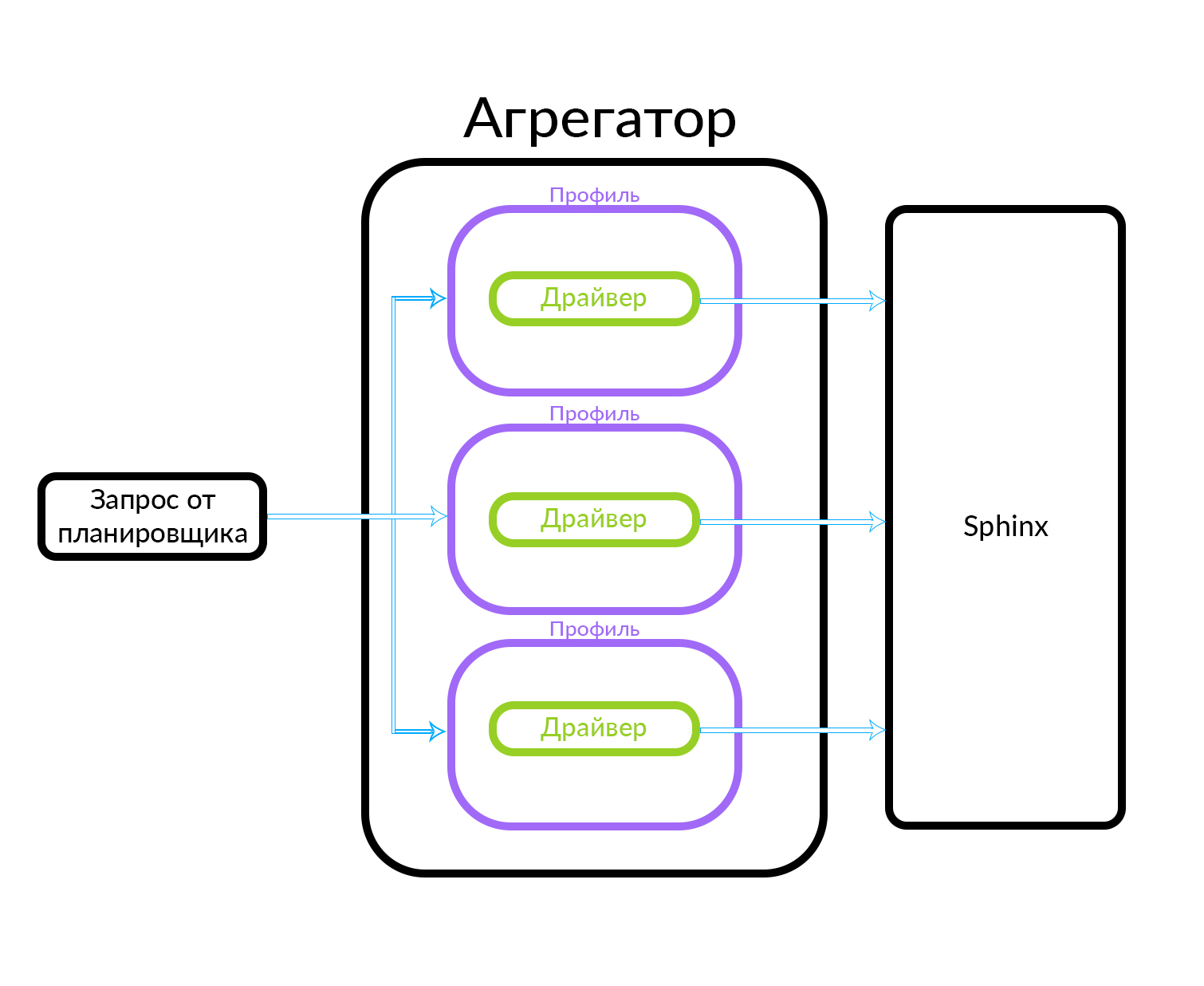
Der Aggregator kann dem Scheduler einfach die Ergebnisse von Abfragen an die Profile geben und auch komplexere Aktionen ausführen, z. B. diese Ergebnisse mit dem einen oder anderen Algorithmus mischen.
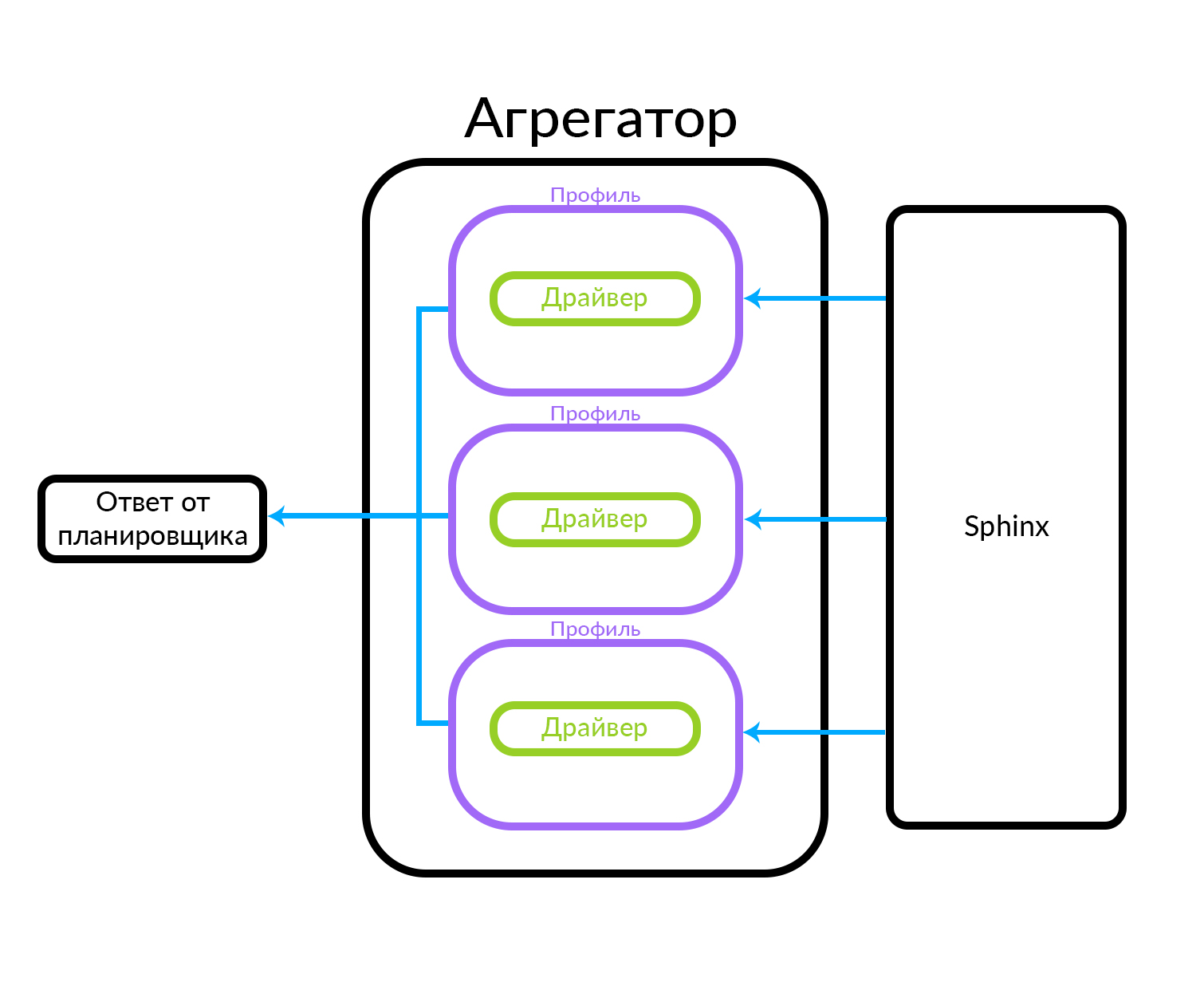
Indexspeicher durchsuchen
Aufgrund der Tatsache, dass wir Kubernetes in der Architektur verwenden, wurde mir bei RIT ++ eine Frage zum Speichern des Suchindex gestellt - wird dieser in Kubernetes gespeichert? Nein, wir haben Sphinx, die auf physischen Maschinen lebt. Bei Kubernetes stellen wir einen Suchdienst bereit, der die Suchlogik verarbeitet. Die Cloud enthält auch einen Beispielsuchindex für die Entwicklungsumgebung, in der Tests ausgeführt werden. Es ist jedoch unerwünscht, dort einen Kampfindex zu platzieren, da es sich bei den in Kubernetes funktionierenden Diensten in erster Linie um zustandslose Dienste handelt.
Suchdienst laden
Jetzt ist dieser Dienst im Kampf, er dient mit wenigen Ausnahmen 100% der Last. Die Last, die er hält, beträgt ungefähr 200 krpm. Verzögerung: Median - bis zu 17 ms, 95 Perzentil - bis zu 120 ms, 99 Perzentil - bis zu 320 ms.
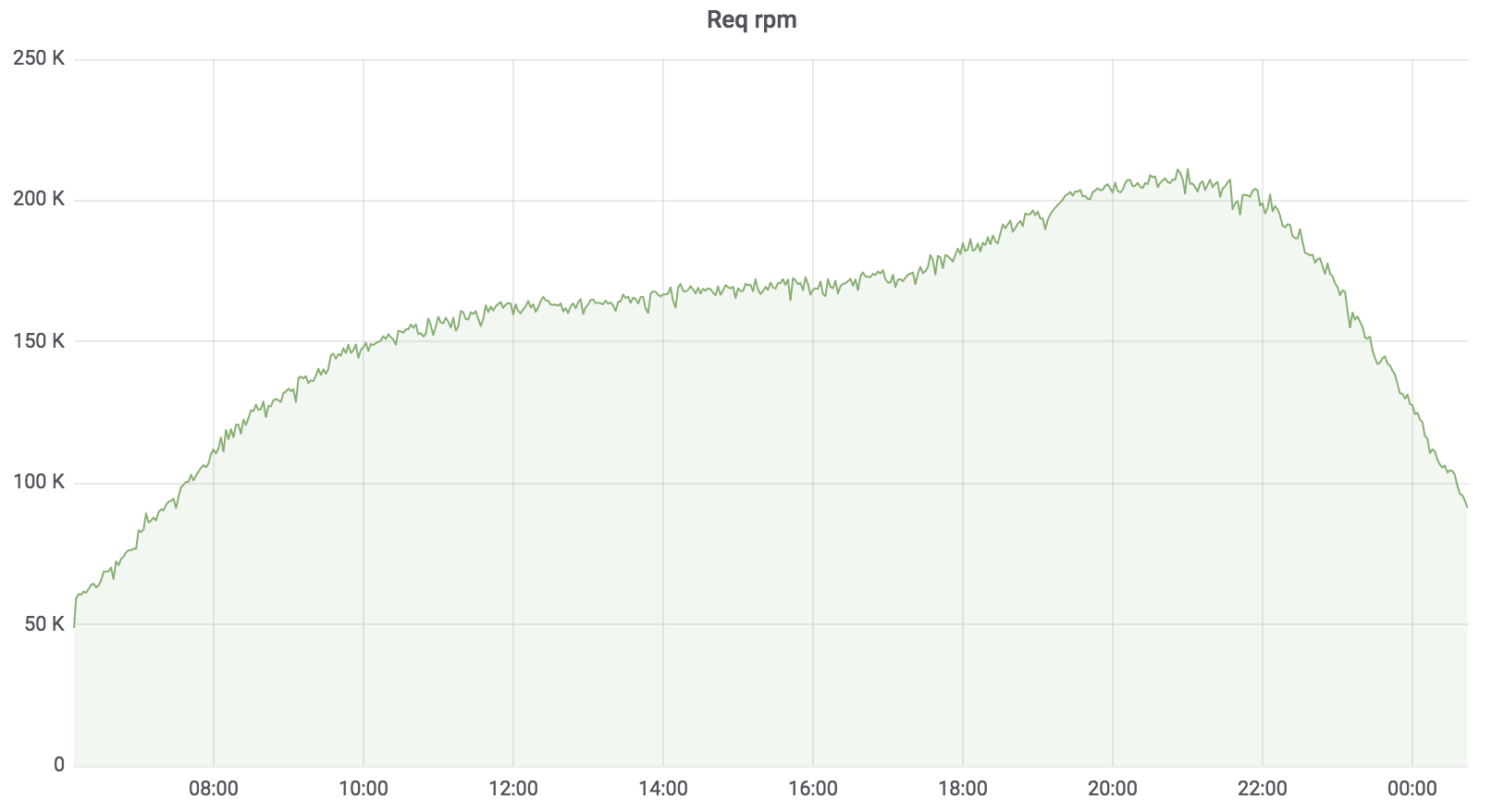
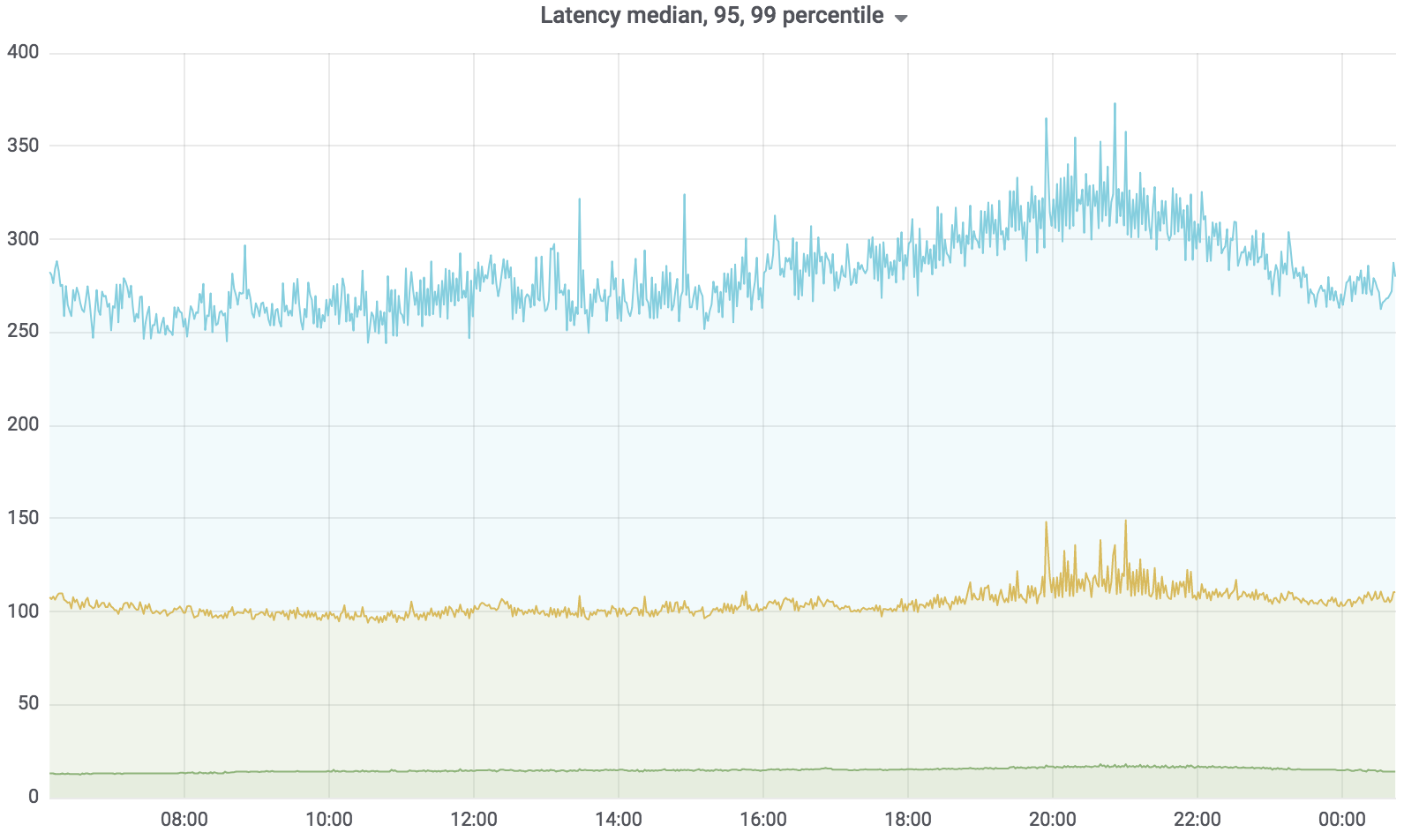
Gesamtsuchdienst
Der Suchdienst ist in Golang geschrieben und für Kubernetes bereitgestellt. Der Aggregator arbeitet asynchron mit mehreren Profilen. Das Profil funktioniert mit dem angegebenen Treiber, der Treiber greift auf die angegebene Datenquelle zu, z. B. Sphinx. Die Anzahl der Anfragen, die unser Service bearbeitet, beträgt derzeit bis zu 200 krpm. Verzögerung: Median - bis zu 17 ms, 95 Perzentil - bis zu 120 ms, 99 Perzentil - bis zu 320 ms.
Implementierung des Dienstes in einem funktionierenden System
Das Problem der doppelten Funktionalität liegt auf der Hand. Wir müssen zwei Codebasen unterstützen, die dieselbe Aufgabe ausführen müssen. Wir brauchen einen Fallback. Wir nannten es "Strohhalme" - wir erinnerten uns an "Strohhalme". Darüber hinaus benötigen wir eine Verkehrskontrolle. Es ist wünschenswert, dass diese über ein Dashboard schnell ist.
Wie funktioniert der "Strohhalm"
Die Suchabfrage kommt zum „Strohhalm“, der innerhalb des Monolithen funktioniert und entweder eine neue oder eine alte Suche aufrufen kann. Sie ruft eine neue Suche an, er erfüllt sie, und wenn sie erfolgreich ist, erhalten wir nur das Ergebnis einer neuen Suche.
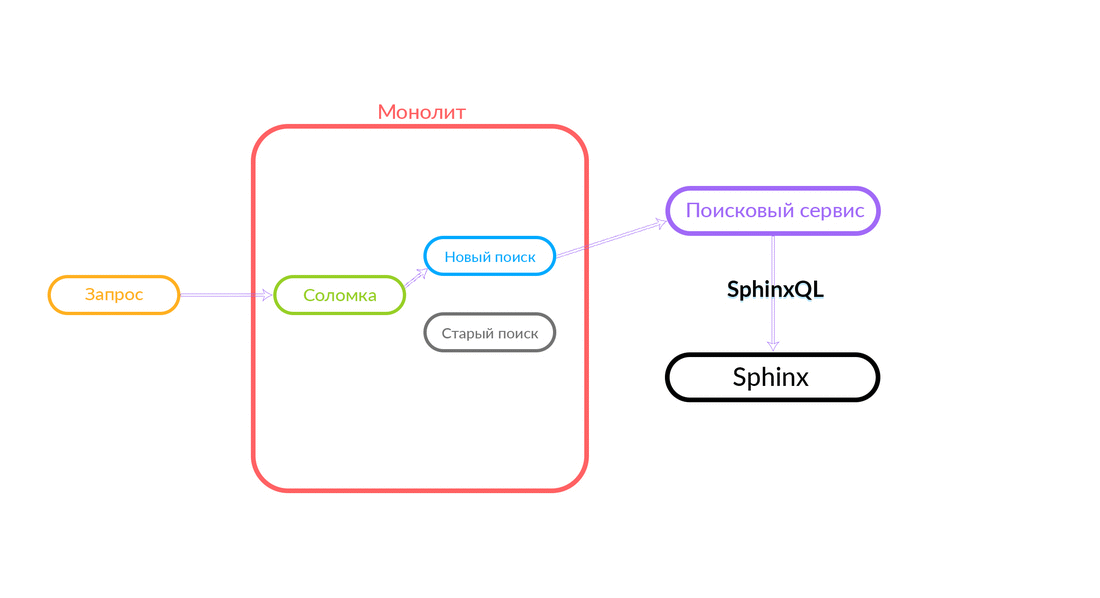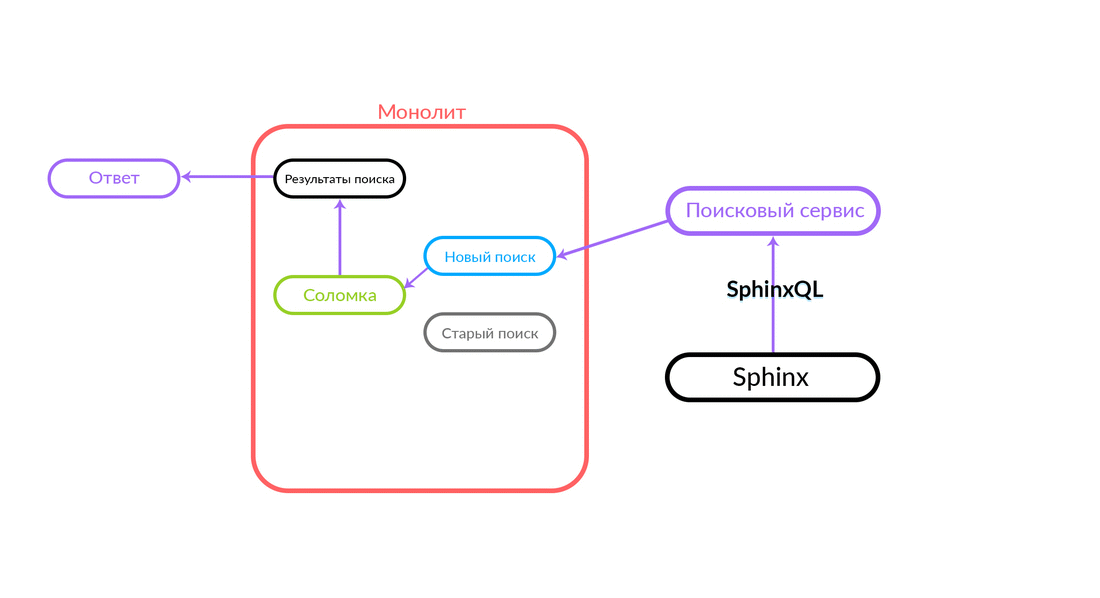
Es gibt Situationen, in denen eine Abfrage an den Suchdienst fehlschlägt: Zum Beispiel und bis eine bestimmte Funktionalität im Suchdienst implementiert ist. Dann versprechen wir unbedingt eine solche Anfrage - "The Straw" wird sie in der alten Suche ausführen. Die alte Suche des Monolithen wird an Sphinx weitergeleitet, und die Antwort geht an den Kunden. Der Kunde wird nichts fühlen.
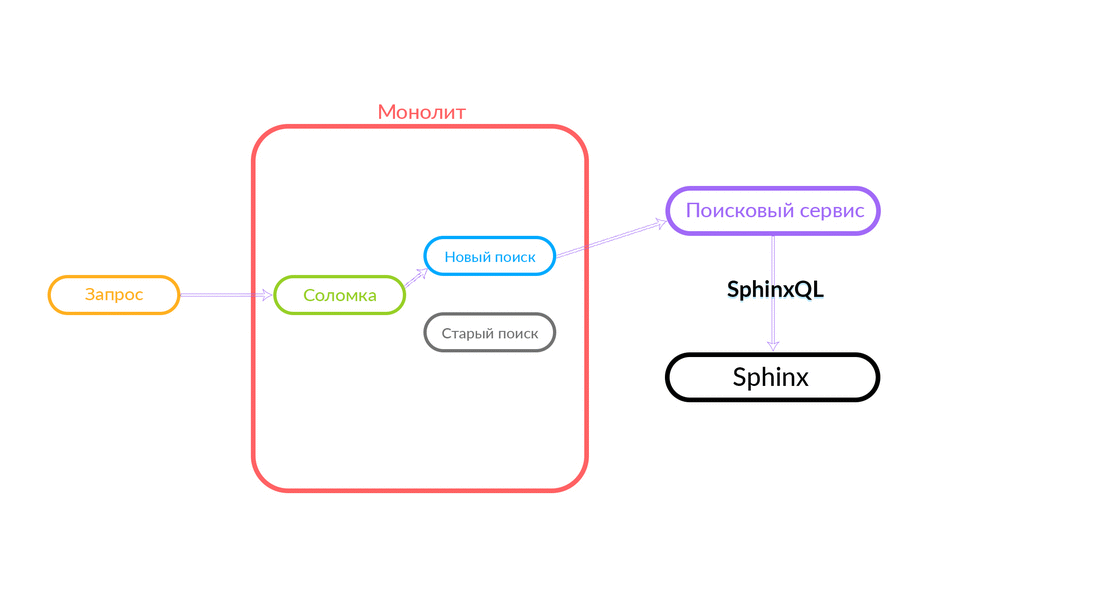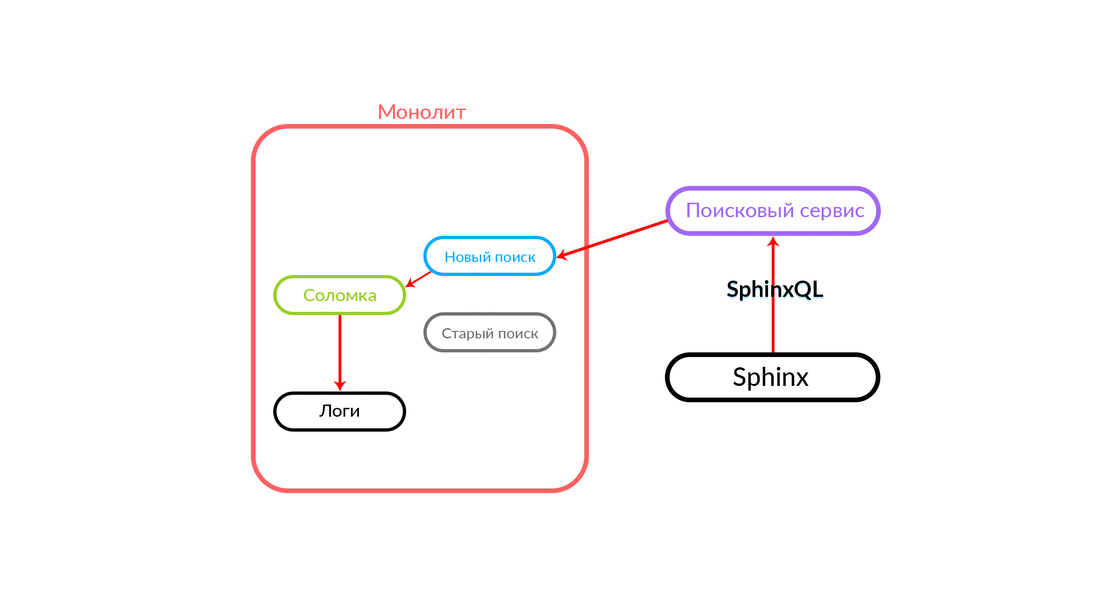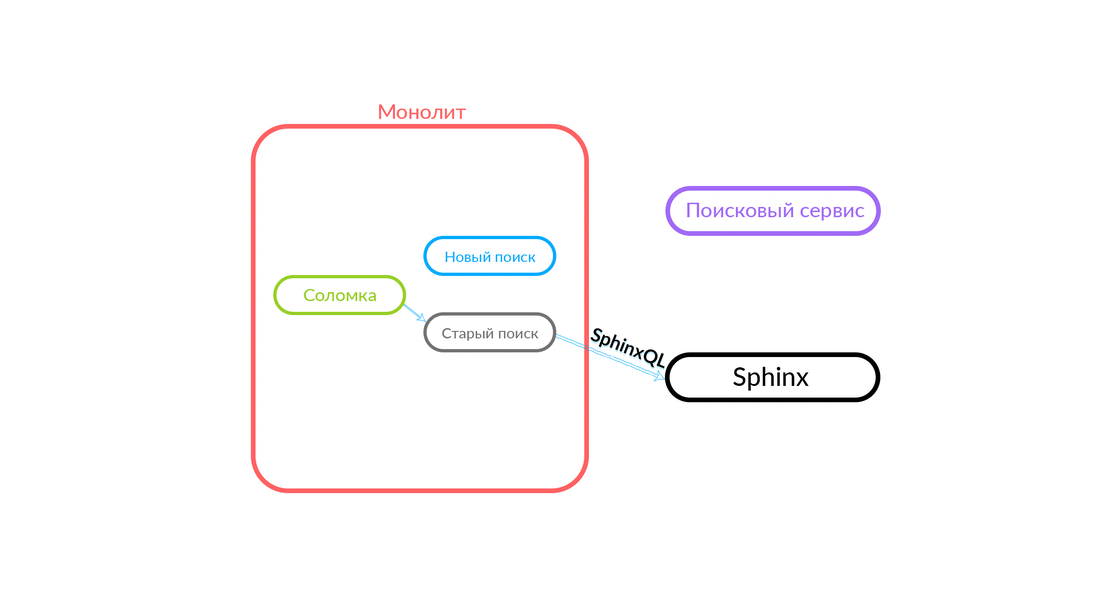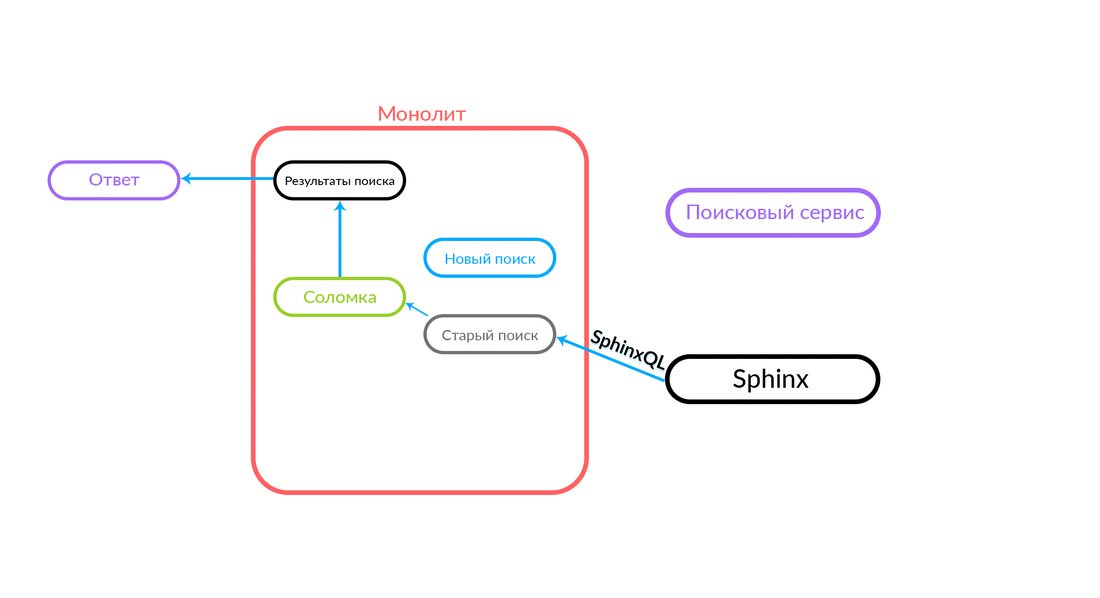
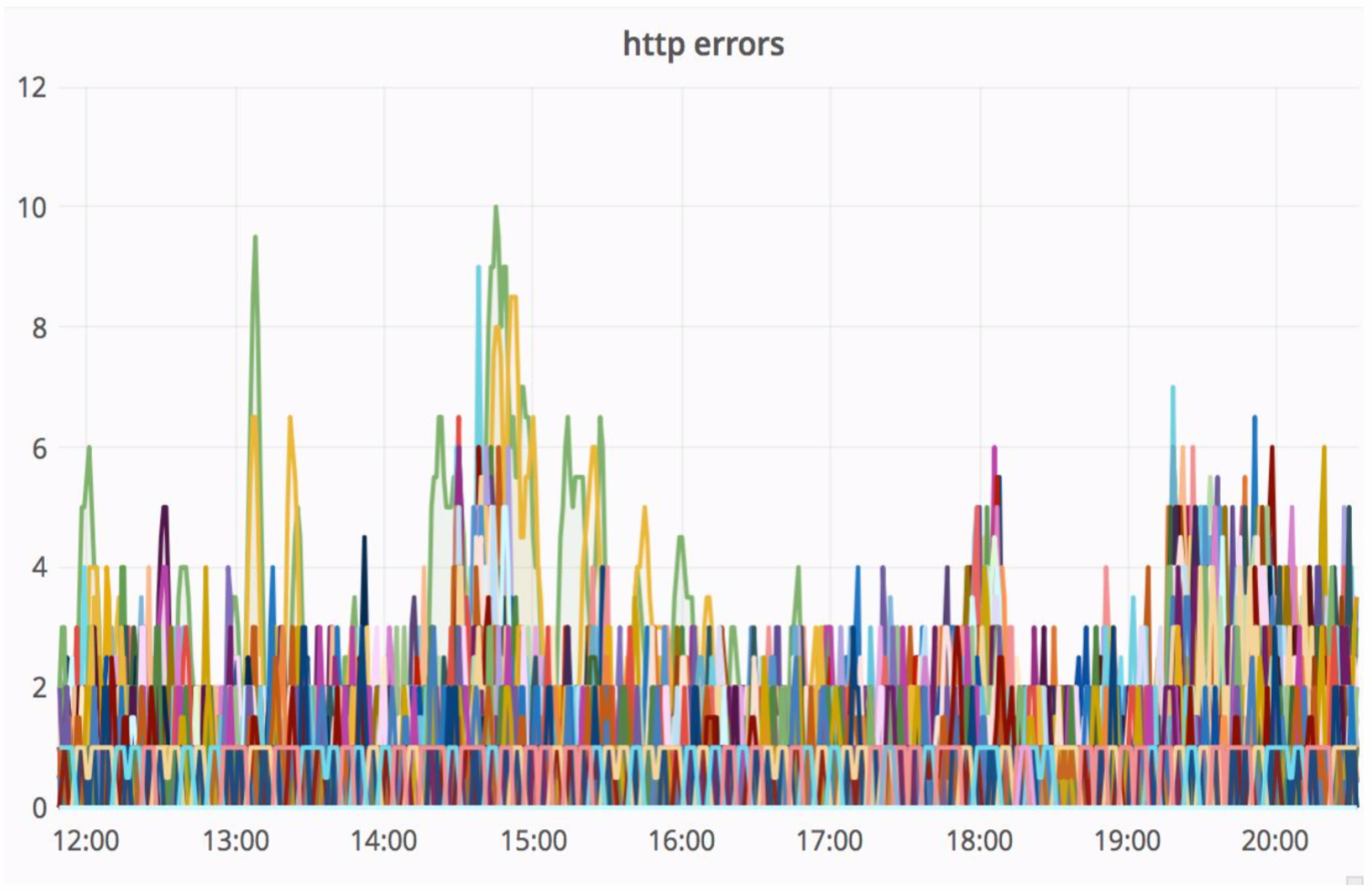
Ein ziemlich zuverlässiges Schema, und es ist immer interessant zu sehen, was in der Praxis passiert. Die Architekturabteilung von Avito verbessert unsere Cloud ständig, optimiert sie und macht sie zuverlässiger und produktiver. Irgendwann gab es Probleme, dass bei der Wartung eines der Knoten mit einer ausreichend hohen Intensität Fehler vom Monolithen kamen (100 Fehler pro Sekunde).

Gleichzeitig hat sich die Serviceverzögerung stark erhöht - im Bild unten sehen Sie Spitzen.
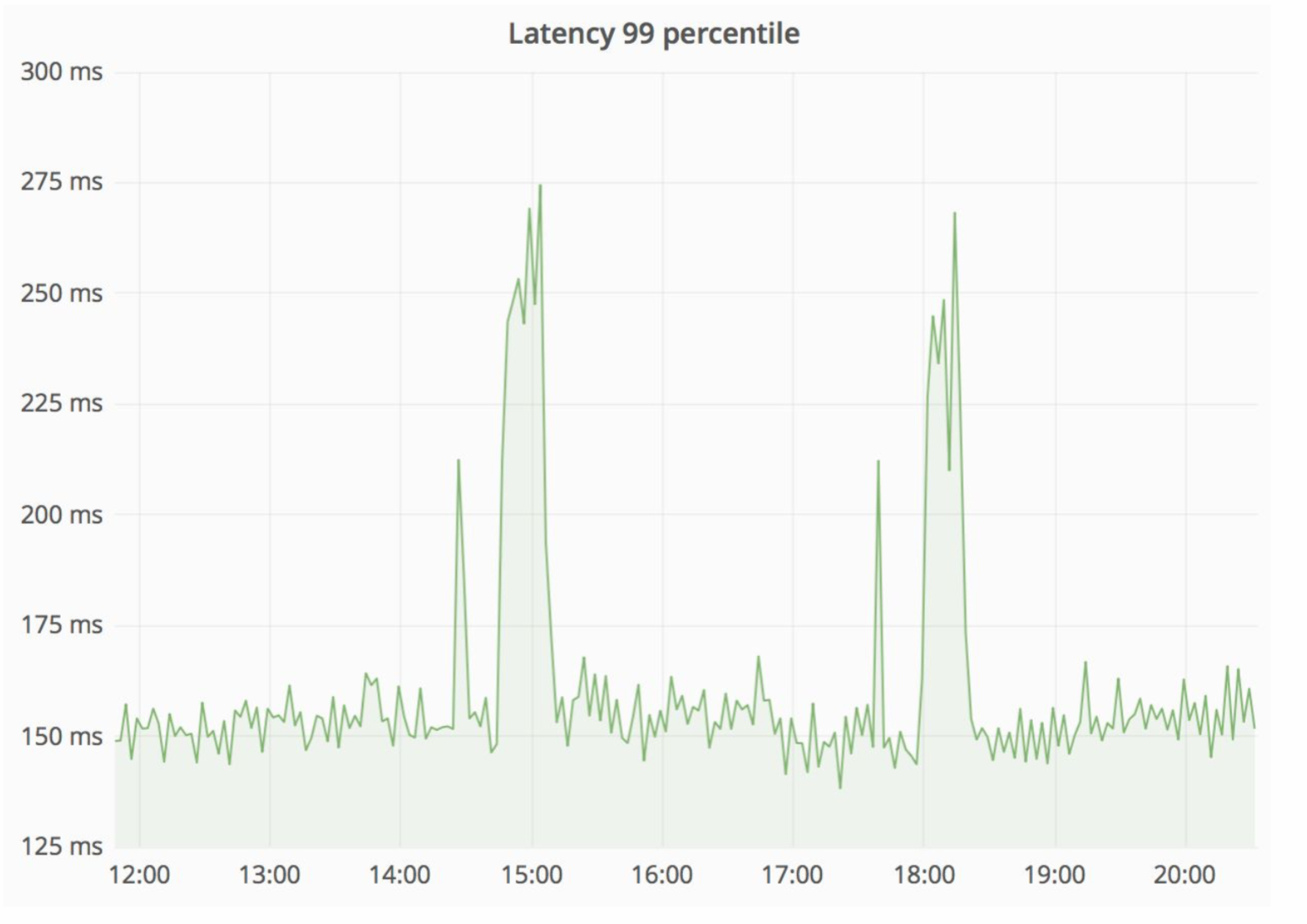
Der „Strohhalm“ hat diese Situation bemerkenswert gelöst, und die daraus resultierenden HTTP-Fehler waren auf dem gleichen Niveau - eine Fehlereinheit für den gesamten Avito. Unsere Besucher haben nichts bemerkt.
Experimentautomatisierung
Wir möchten, dass sich die Suche schnell entwickelt und die Einführung neuer Funktionen einfacher wurde. Hierzu wird eine entsprechende Infrastruktur benötigt. Wir haben die Automatisierung von A / B-Tests konfiguriert. Über das Dashboard können wir neue Experimente starten, sie basierend auf den hinzugefügten Innovationen konfigurieren und dementsprechend Experimente ausführen, ohne den Monolithen zu rollen.
Im Ausgangszustand, wenn kein einziges Experiment gestartet wurde, sehen alle Besucher die üblichen Suchfunktionen.
In einem typischen Experiment werden Benutzer in Gruppen eingeteilt. Die Kontrollgruppe - mit der für unsere Besucher üblichen Funktionalität. Es gibt mehrere Testgruppen - mit Innovationen. Wenn wir ein neues Experiment erstellen müssen, implementieren wir im Suchdienst eine neue Suchfunktion (neue Aggregatoren hinzufügen) und richten das Experiment über das Dashboard mit den erforderlichen Gruppen ein und verknüpfen sie mit neuen Aggregatoren.
Bei der Analyse von Experimenten vergleichen wir das Verhalten der Besucher in der Kontrollgruppe mit denen der Testgruppe und ziehen daraus Schlussfolgerungen über den Erfolg des Experiments.

Angenommen, wir haben eine neue Ranking-Formel entwickelt. Was müssen wir tun, um mit ihr zu experimentieren?
- Rollen Sie im Suchdienst den entsprechenden Aggregator ein (sei es "Aggregator 2").
- Erstellen Sie ein Experiment über ein Dashboard und verbinden Sie eine der Gruppen in diesem Experiment mit diesem Aggregator.
- Wenn nun eine Abfrage in der Suche eintrifft, die in die Testgruppe fällt, wird sie an den Suchdienst unter "Aggregator 2" weitergeleitet.
Wir können weiterhin neue Experimente erstellen und ihre Testgruppen neuen Aggregatoren zuordnen.
Gesamte Suchinfrastruktur
Es gibt einen Cluster von Sphinx 3-Servern mit 13 krps SphinxQL-Abfragen und mehr als 45 Millionen aktiven Anzeigen.
Sphinx 3.0 ist stabil und gefällt mit seiner Leistung. Binärdateien sind übrigens gemeinfrei . Dank Avito werden in Sphinx 3 außerdem neue Funktionen gefilmt, z. B. die Funktionsweise des Skalarprodukts von Vektoren, und gefundene Fehler werden behoben.
Wir verwenden Service-Architektur. Wir haben den Suchdienst "Iskalo" und den Dienst "Avito Assistant". Ein Teil der Funktionalität ist im Monolithen geblieben, aber wir arbeiten weiter an seinem Schneiden.
Schlussfolgerungen
Im vergangenen Jahr wurde ein erweitertes Entwicklungssystem für Suchfunktionen erhalten. Wir hatten die Möglichkeit, schnelle und flexible Experimente durchzuführen. Und jetzt ist die Suche nach Benutzern bequemer, schneller und hilft besser, ihre Probleme zu lösen.
Was weiter
Außerdem werden wir weiterhin das, was übrig bleibt, aus dem Monolithen entfernen: Rendering, Filter. Wir werden daran arbeiten, die Qualität der Suche zu verbessern und unsere Besucher weiterhin zu begeistern. Hoffe du auch.
Wenn Sie Fragen zur Arbeit unserer Suche haben, möchten wir weitere technische Details erfahren, schreiben Sie in die Kommentare. Ich werde gerne antworten. Übrigens sprach Andrey Drozdov kürzlich auf der Highload ++ 2018 mit einem Bericht über die Optimierung der Suchergebnisse nach mehreren Kriterien. Hier ist seine Präsentation .