Hallo allerseits!
Wir haben einen neuen Stream für den Kurs für
maschinelles Lernen eröffnet. Warten Sie also in naher Zukunft auf Artikel, die sich sozusagen auf diese Disziplin beziehen. Natürlich offene Seminare. Schauen wir uns nun an, was Verstärkungslernen ist.
Verstärktes Lernen ist eine wichtige Form des maschinellen Lernens, bei der ein Agent lernt, sich in einer Umgebung zu verhalten, indem er Aktionen ausführt und Ergebnisse sieht.
In den letzten Jahren haben wir auf diesem faszinierenden Forschungsgebiet viele Erfolge erzielt. Zum Beispiel
DeepMind und Deep Q Learning Architecture im Jahr 2014, der
Sieg über den Go-Champion mit AlphaGo im Jahr 2016,
OpenAI und PPO im Jahr 2017, unter anderem.
 DeepMind DQN
DeepMind DQNIn dieser Artikelserie konzentrieren wir uns auf die verschiedenen Architekturen, die heute zur Lösung des Problems des verstärkten Lernens verwendet werden. Dazu gehören Q-Learning, Deep Q-Learning, Policy Gradients, Actor Critic und PPO.
In diesem Artikel erfahren Sie:
- Was ist verstärkendes Lernen und warum Belohnungen eine zentrale Idee sind
- Drei Ansätze zum verstärkten Lernen
- Was „tief“ bedeutet, um tief zu lernen
Es ist sehr wichtig, diese Aspekte zu beherrschen, bevor Sie in die Implementierung von Verstärkungslernmitteln eintauchen.
Die Idee des Verstärkungstrainings ist, dass der Agent aus der Umgebung lernt, indem er mit ihr interagiert und Belohnungen für die Durchführung von Aktionen erhält.

Lernen durch Interaktion mit der Umwelt kommt aus unserer natürlichen Erfahrung. Stellen Sie sich vor, Sie sind ein Kind im Wohnzimmer. Sie sehen den Kamin und gehen dorthin.
In der Nähe warm fühlen Sie sich gut (positive Belohnung +1). Sie verstehen, dass Feuer eine positive Sache ist.
Aber dann versuchst du das Feuer zu berühren. Autsch! Er verbrannte sich die Hand (negative Belohnung -1). Sie haben gerade festgestellt, dass Feuer positiv ist, wenn Sie sich in ausreichender Entfernung befinden, weil es Wärme erzeugt. Aber wenn Sie sich ihm nähern, werden Sie sich verbrennen.
So lernen Menschen durch Interaktion. Verstärktes Lernen ist einfach ein rechnerischer Ansatz zum Lernen durch Handeln.
Lernprozess zur Verstärkung

Stellen Sie sich als Beispiel einen Agenten vor, der lernt, Super Mario Bros. zu spielen. Der Reinforcement Learning (RL) -Prozess kann als ein Zyklus modelliert werden, der wie folgt funktioniert:
- Der Agent erhält den Status S0 von der Umgebung (in unserem Fall erhalten wir den ersten Frame des Spiels (Status) von Super Mario Bros (Umgebung)).
- Basierend auf diesem Zustand S0 ergreift der Agent die Aktion A0 (der Agent bewegt sich nach rechts).
- Die Umgebung wechselt in einen neuen Zustand S1 (neuer Frame)
- Die Umgebung gibt dem R1-Agenten eine Belohnung (nicht tot: +1)
Dieser RL-Zyklus erzeugt eine Folge von
Zuständen, Aktionen und Belohnungen.Das Ziel des Agenten ist es, die erwarteten akkumulierten Belohnungen zu maximieren.
Zentrale IdeenprämienhypothesenWarum ist es das Ziel eines Agenten, die erwarteten kumulierten Belohnungen zu maximieren? Nun, das Lernen der Verstärkung basiert auf der Idee einer Belohnungshypothese. Alle Ziele können durch Maximierung der erwarteten kumulierten Belohnungen beschrieben werden.
Um das beste Verhalten zu erzielen, müssen wir daher im Verstärkungstraining die erwarteten akkumulierten Belohnungen maximieren.Die akkumulierte Belohnung zu jedem Zeitpunkt Schritt t kann wie folgt geschrieben werden:

Dies entspricht:
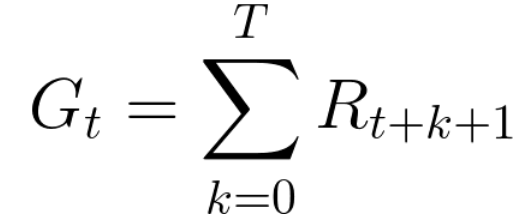
In Wirklichkeit können wir solche Belohnungen jedoch nicht einfach hinzufügen. Belohnungen, die früher (zu Beginn des Spiels) eintreffen, sind wahrscheinlicher, weil sie in Zukunft vorhersehbarer sind als Belohnungen.

Angenommen, Ihr Agent ist eine kleine Maus und Ihr Gegner ist eine Katze. Ihr Ziel ist es, die maximale Menge Käse zu essen, bevor die Katze Sie frisst. Wie wir in der Abbildung sehen, frisst eine Maus eher Käse neben sich als Käse in der Nähe einer Katze (je näher wir ihm sind, desto gefährlicher ist er).
Infolgedessen wird die Belohnung einer Katze, selbst wenn sie größer ist (mehr Käse), verringert. Wir sind uns nicht sicher, ob wir es essen können. Um die Vergütung zu reduzieren, gehen wir wie folgt vor:
- Wir bestimmen den Abzinsungssatz namens Gamma. Es sollte zwischen 0 und 1 liegen.
- Je größer das Gamma, desto geringer der Rabatt. Dies bedeutet, dass sich der Lernagent mehr um langfristige Belohnungen kümmert.
- Andererseits ist der Rabatt umso größer, je kleiner das Gamma ist. Dies bedeutet, dass kurzfristigen Belohnungen (nächster Käse) Vorrang eingeräumt wird.
Die kumulierte erwartete Gegenleistung unter Berücksichtigung der Diskontierung lautet wie folgt:
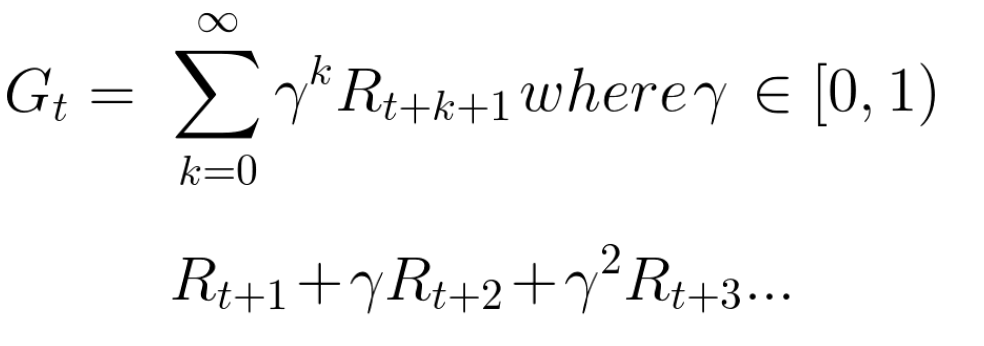
Grob gesagt wird jede Belohnung mit dem Gamma auf die Zeitanzeige reduziert. Mit zunehmendem Zeitschritt kommt die Katze uns näher, sodass die zukünftige Belohnung immer unwahrscheinlicher wird.
Gelegentliche oder kontinuierliche AufgabenEine Aufgabe ist ein Beispiel für das Lernproblem mit Verstärkung. Wir können zwei Arten von Aufgaben haben: episodische und kontinuierliche.
Episodische AufgabeIn diesem Fall haben wir einen Startpunkt und einen Endpunkt
(Endzustand). Dadurch wird eine Episode erstellt : eine Liste von Zuständen, Aktionen, Belohnungen und neuen Zuständen.
Nehmen wir zum Beispiel Super Mario Bros: Die Episode beginnt mit dem Start des neuen Mario und endet, wenn Sie getötet werden oder das Ende des Levels erreichen.
 Der Beginn einer neuen EpisodeKontinuierliche AufgabenDies sind Aufgaben, die für immer andauern (ohne Terminalstatus)
Der Beginn einer neuen EpisodeKontinuierliche AufgabenDies sind Aufgaben, die für immer andauern (ohne Terminalstatus) . In diesem Fall muss der Agent lernen, die besten Aktionen auszuwählen und gleichzeitig mit der Umgebung zu interagieren.
Zum Beispiel ein Agent, der den automatisierten Aktienhandel durchführt. Für diese Aufgabe gibt es keinen Startpunkt und keinen Endstatus.
Der Agent arbeitet weiter, bis wir uns entschließen, ihn aufzuhalten. Monte-Carlo-Zeitdifferenzmethode
Monte-Carlo-ZeitdifferenzmethodeEs gibt zwei Möglichkeiten zu lernen:
- Sammeln Sie am Ende der Episode Belohnungen und berechnen Sie dann die maximal erwarteten zukünftigen Belohnungen - Monte-Carlo-Ansatz
- Bewertung der Belohnungen bei jedem Schritt - ein vorübergehender Unterschied
Monte CarloWenn die Episode endet (der Agent erreicht einen „Endzustand“), überprüft der Agent die insgesamt angesammelte Belohnung, um festzustellen, wie gut er es gemacht hat. Beim Monte-Carlo-Ansatz werden Belohnungen erst am Ende des Spiels erhalten.
Dann starten wir ein neues Spiel mit erweitertem Wissen.
Der Agent trifft bei jeder Iteration die besten Entscheidungen.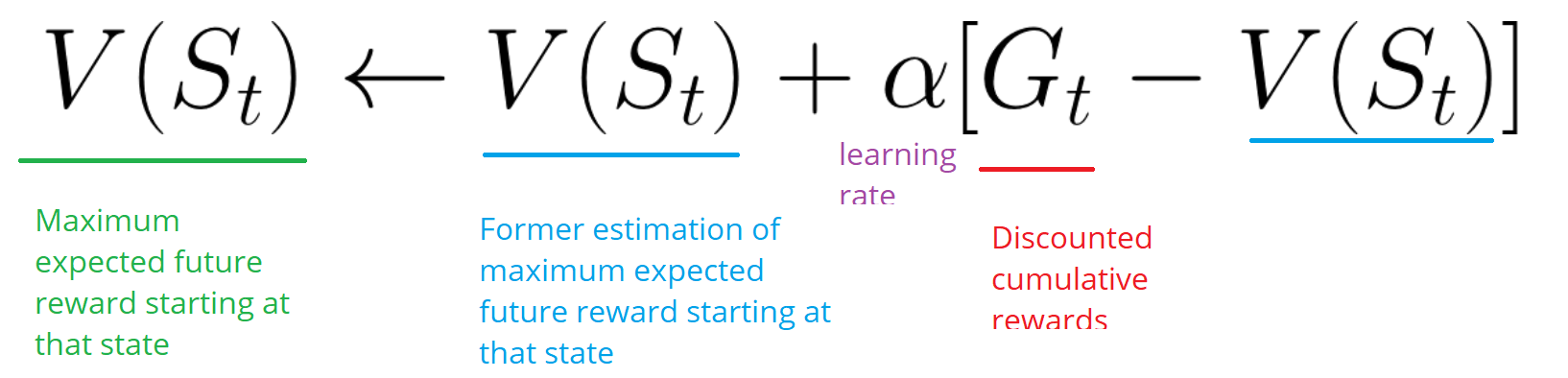
Hier ist ein Beispiel:
Wenn wir das Labyrinth als Umgebung betrachten:
- Wir beginnen immer am selben Ausgangspunkt.
- Wir stoppen die Episode, wenn die Katze uns frisst oder wir> 20 Schritte gehen.
- Am Ende der Episode haben wir eine Liste von Zuständen, Aktionen, Belohnungen und neuen Zuständen.
- Der Agent fasst die Gesamtbelohnung von Gt zusammen (um zu sehen, wie gut er es gemacht hat).
- Dann aktualisiert es V (st) gemäß der obigen Formel.
- Dann beginnt ein neues Spiel mit neuem Wissen.
In immer mehr Folgen
lernt der
Agent, immer besser zu spielen.Zeitunterschiede: Lernen zu jedem ZeitschrittDie TD-Methode (Temporal Difference Learning) wartet nicht auf das Ende der Episode, um die höchstmögliche Belohnung zu aktualisieren. Er wird V abhängig von der gesammelten Erfahrung aktualisieren.
Diese Methode wird als TD (0) oder
schrittweise TD bezeichnet (aktualisiert die Dienstprogrammfunktion nach jedem einzelnen Schritt).
TD-Methoden erwarten nur, dass der nächste
Zeitschritt die Werte aktualisiert. Zum Zeitpunkt t + 1
wird ein TD-Ziel unter Verwendung der Belohnung Rt + 1 und der aktuellen Bewertung V (St + 1) gebildet.Das TD-Ziel ist eine Schätzung des erwarteten Wertes: Tatsächlich aktualisieren Sie die vorherige V (St) -Bewertung innerhalb eines Schritts auf das Ziel.
Kompromiss Exploration / BetriebBevor wir verschiedene Strategien zur Lösung von Problemen mit dem Verstärkungstraining in Betracht ziehen, müssen wir ein weiteres sehr wichtiges Thema betrachten: den Kompromiss zwischen Exploration und Exploitation.
- Intelligenz findet mehr Informationen über die Umgebung.
- Die Nutzung nutzt bekannte Informationen, um die Belohnungen zu maximieren.
Denken Sie daran, dass das Ziel unseres RL-Agenten darin besteht, die erwarteten akkumulierten Belohnungen zu maximieren. Wir können jedoch in eine gemeinsame Falle tappen.
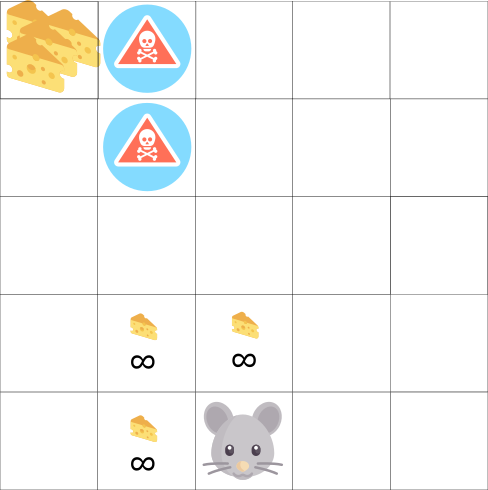
In diesem Spiel kann unsere Maus unendlich viele kleine Käsestücke haben (jeweils +1). Aber oben im Labyrinth befindet sich ein riesiges Stück Käse (+1000). Wenn wir uns jedoch nur auf Belohnungen konzentrieren, wird unser Agent niemals einen riesigen Teil erreichen. Stattdessen verwendet er nur die nächstgelegene Belohnungsquelle, auch wenn diese Quelle klein ist (Ausbeutung). Aber wenn unser Agent ein wenig nachforscht, kann er eine große Belohnung finden.
Dies ist ein Kompromiss zwischen Exploration und Exploitation. Wir müssen eine Regel definieren, die bei der Bewältigung dieses Kompromisses hilft. In zukünftigen Artikeln erfahren Sie verschiedene Möglichkeiten, dies zu tun.
Drei Ansätze zum verstärkten LernenNachdem wir die Hauptelemente des verstärkten Lernens identifiziert haben, gehen wir zu drei Ansätzen zur Lösung des verstärkten Lernens über: kostenbasiert, politikbasiert und modellbasiert.
Basierend auf den KostenIn der kostenbasierten RL besteht das Ziel darin, die Nutzfunktion V (s) zu optimieren.
Eine Utility-Funktion ist eine Funktion, die uns über die maximal erwartete Belohnung informiert, die ein Agent in jedem Status erhält.
Der Wert jedes Status ist der Gesamtbetrag der Belohnung, die der Agent ab diesem Status in Zukunft erwarten kann.
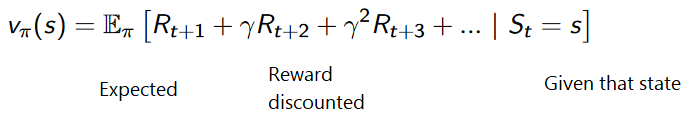
Der Agent verwendet diese Dienstprogrammfunktion, um zu entscheiden, welcher Status bei jedem Schritt ausgewählt werden soll. Der Agent wählt den Status mit dem höchsten Wert aus.
Im Labyrinthbeispiel nehmen wir bei jedem Schritt den höchsten Wert: -7, dann -6, dann -5 (usw.), um das Ziel zu erreichen.
RichtlinienbasiertIn richtlinienbasiertem RL möchten wir die Richtlinienfunktion π (s) direkt optimieren, ohne die Dienstprogrammfunktion zu verwenden. Eine Richtlinie bestimmt das Verhalten eines Agenten zu einem bestimmten Zeitpunkt.
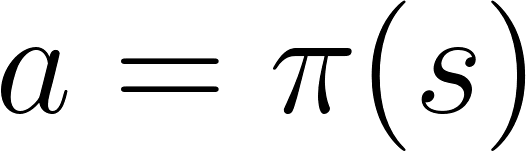 Aktion = Politik (Staat)
Aktion = Politik (Staat)Wir untersuchen die Funktion der Politik. Dies ermöglicht es uns, jeden Zustand mit der am besten geeigneten Aktion zu korrelieren.
Es gibt zwei Arten von Richtlinien:
- Deterministisch: Politik in einem bestimmten Staat wird immer die gleiche Aktion zurückgeben.
- Stochastisch: Zeigt die Wahrscheinlichkeit der Verteilung durch Aktion an.

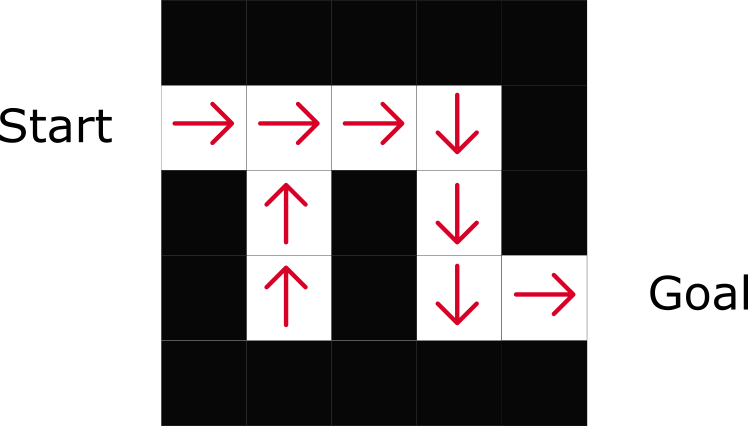
Wie Sie sehen können, gibt die Richtlinie direkt die beste Aktion für jeden Schritt an.
Basierend auf dem ModellIn modellbasiertem RL modellieren wir die Umgebung. Dies bedeutet, dass wir ein Modell des Umweltverhaltens erstellen. Das Problem ist, dass jede Umgebung eine andere Ansicht des Modells benötigt. Aus diesem Grund werden wir uns in den folgenden Artikeln nicht besonders auf diese Art der Schulung konzentrieren.
Einführung in tiefgreifendes LernenDeep Reinforcement Learning führt tiefe neuronale Netze ein, um die Probleme des verstärkten Lernens zu lösen - daher der Name „tief“.
Zum Beispiel werden wir im nächsten Artikel über Q-Learning (klassisches Verstärkungslernen) und Deep Q-Learning arbeiten.
Sie werden den Unterschied in der Tatsache sehen, dass wir beim ersten Ansatz den traditionellen Algorithmus verwenden, um die Q-Tabelle zu erstellen, mit deren Hilfe wir herausfinden können, welche Maßnahmen für jeden Zustand zu ergreifen sind.
Im zweiten Ansatz verwenden wir ein neuronales Netzwerk (um zustandsbasierte Belohnungen zu approximieren: q-Wert).
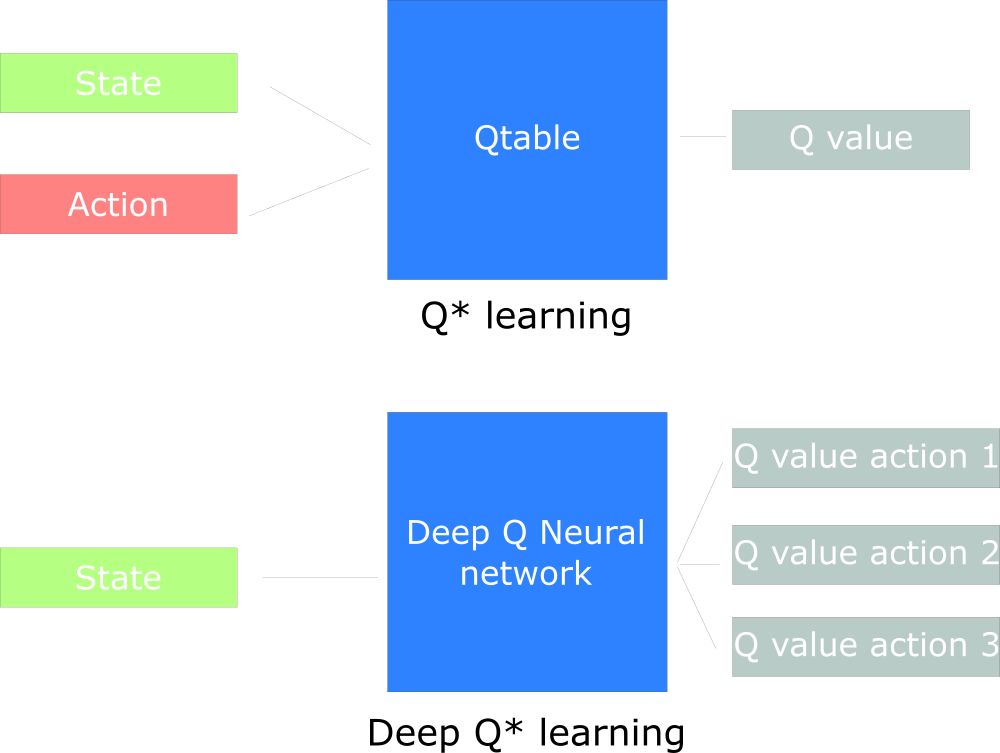 Udacity Inspired Q Design Chart
Udacity Inspired Q Design Chart
Das ist alles. Wie immer warten wir hier auf Ihre Kommentare oder Fragen, oder Sie können sie dem
Kurslehrer Arthur Kadurin in seiner
offenen Lektion zum Thema Networking stellen.