Zuvor mussten sie, um ein Taxi zu rufen, eine unterschiedliche Anzahl von Versanddiensten anrufen und mindestens eine halbe Stunde warten, bis das Auto geliefert wurde. Jetzt sind die Taxiservices gut automatisiert und die durchschnittliche Lieferzeit für Yandex.Taxi in Moskau beträgt ca. 3-4 Minuten. Aber es lohnt sich, ein Massenereignis zu regnen oder zu beenden, und wieder kann es zu einem Mangel an kostenlosen Autos kommen.
Mein Name ist Anton Skogorev, ich leite die Performance Development Group der Yandex.Taxi-Plattform. Heute werde ich den Lesern von Habr erzählen, wie wir gelernt haben, eine hohe Nachfrage vorherzusagen und zusätzlich Fahrer anzulocken, damit Benutzer jederzeit ein kostenloses Auto finden können. Sie erfahren, wie ein Koeffizient gebildet wird, der sich auf den Wert der Bestellung auswirkt. Alles dort ist alles andere als so einfach, wie es auf den ersten Blick erscheinen mag.
Dynamische Preisherausforderung
Die wichtigste Aufgabe der dynamischen Preisgestaltung ist es, immer die Möglichkeit zu bieten, ein Taxi zu bestellen. Dies wird mit dem Anstiegspreiskoeffizienten erreicht, mit dem der berechnete Preis multipliziert wird. Wir nennen es einfach Schwall. Es ist wichtig zu sagen, dass der Anstieg nicht nur die Nachfrage nach Taxis reguliert, sondern auch dazu beiträgt, neue Fahrer für die Steigerung des Angebots zu gewinnen.
Wenn der Anstieg zu groß eingestellt ist, werden wir die Nachfrage zu stark reduzieren, es wird einen Überschuss an kostenlosen Autos geben. Wenn zu niedrig eingestellt, sehen Benutzer "keine freien Autos". Sie müssen in der Lage sein, einen Koeffizienten zu wählen, bei dem wir zwischen dem Mangel an freien Autos und der geringen Nachfrage auf dünnem Eis laufen.
Wovon sollte dieser Koeffizient abhängen? Es fällt sofort die Abhängigkeit von der Anzahl der Autos und Bestellungen rund um den Benutzer ein. Jetzt können Sie einfach die Anzahl der Bestellungen durch die Anzahl der Fahrer teilen, den Koeffizienten ermitteln und ihn mit einer Formel (möglicherweise linear) in unseren Anstieg umwandeln.
Bei dieser Aufgabe gibt es jedoch ein kleines Problem: Es kann zu spät sein, Bestellungen um den Benutzer herum zu zählen. Schließlich ist eine Bestellung fast immer eine bereits besetzte Maschine, was bedeutet, dass eine Erhöhung unseres Koeffizienten immer zu spät kommt. Daher betrachten wir keine erstellten Bestellungen, sondern die
Absicht, einen
Autostift zu bestellen. Eine Stecknadel ist eine Bezeichnung „A“ auf einer Karte, die ein Benutzer beim Starten unserer Anwendung anbringt.

Lassen Sie uns das Problem formulieren: Wir müssen die
Momentanwerte von Maschinen und Stiften irgendwann im Benutzer lesen.
Wir zählen die Anzahl der Stifte und Autos
Wenn sich die Pin-Position ändert (der Benutzer wählt Punkt „A“), sendet die Benutzeranwendung neue Koordinaten und ein kleines Blatt mit zusätzlichen Informationen an das Backend, um den Pin genauer zu bewerten (z. B. den ausgewählten Tarif).
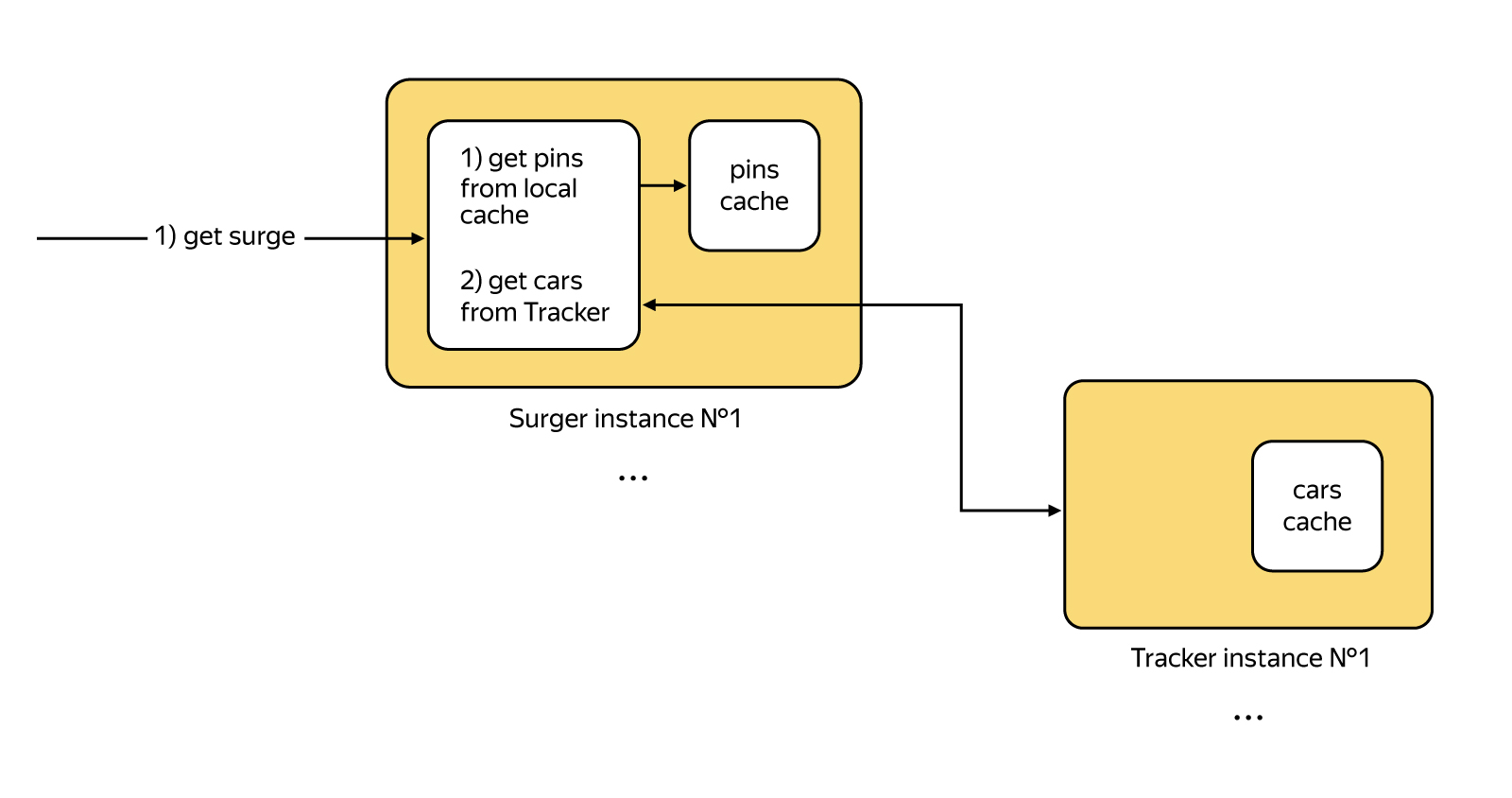
Wir versuchen, uns an die Microservice-Architektur zu halten, bei der jeder Microservice separate Aufgaben ausführt. Der Surger Microservice befasst sich mit der Berechnung des Surges. Es registriert die Pins, speichert sie in der Datenbank und aktualisiert auch das Nugget der Pins im RAM, in das sie ziemlich gut passen. Die Cache-Verzögerung während einer solchen Arbeit beträgt nur wenige Sekunden, was in unserem Fall akzeptabel ist.
Ein paar Worte zur DatenbankBei der Registrierung wird jeder Pin asynchron zu MongoDb mit dem
TTL-Index hinzugefügt, wobei TTL die „Lebensdauer“ des Pins ist, bei der wir ihn für die Berechnung des Erhöhungskoeffizienten als aktiv betrachten. Der Benutzer wartet nicht, während wir diese Aktionen ausführen. Selbst wenn etwas schief geht, ist der Verlust einer Stecknadel keine so große Tragödie.

Ein Hot-Cache wird mit einem
Geo-Hash- Index erstellt. Wir gruppieren alle Stifte nach Geohash und sammeln dann die Stifte für den gewünschten Radius um den Bestellpunkt.
Wir machen dasselbe mit Autos, aber in einem anderen Dienst namens Tracker, zu dem der Surger einfach mit der Frage geht, "wie viele Fahrer sich in diesem Radius befinden".
Wir betrachten also die Momentanwerte des Koeffizienten.
Caching
Fall : Sie stehen im Gartenring in Moskau und möchten ein Auto buchen. Gleichzeitig springt der Preis ziemlich oft und das ist ärgerlich.
Wenn man die Mechanik bereits kennt, kann man verstehen, dass dies daran liegen kann, dass sich die Fahrer zum Zeitpunkt der Anforderung des Überspannungsschutzes an einer bedingten Ampel ansammeln und auch schnell abreisen. Aus diesem Grund können Anstieg und Preis spürbar „springen“.
Um dies zu vermeiden, speichern wir den Wert des Anstiegs nach Benutzer zwischen. Wenn ein Benutzer zu einer Überspannung kommt, prüfen wir, ob für diesen Benutzer ein gespeicherter Überspannungswert in einem akzeptablen Radius vorliegt (eine lineare Tour aller gespeicherten Überspannungen des Benutzers). Wenn ja, geben wir es zurück, sonst rechnen wir mit einem neuen und sparen auch.
Das hat gut funktioniert, aber es gibt andere Situationen.
Fall : 2 Benutzer fordern einen Anstieg an. Einer bestellt 30 Sekunden später als der andere, wenn Autos von einer Ampel aus einem früheren Fall bereits abgefahren sind. Wir erhalten ein Bild, in dem 2 Benutzer, die fast gleichzeitig bestellen, merklich unterschiedliche Spannungsspitzen haben können.
Und hier gehen wir vom Cache nach Benutzer zum Cache nach Position. Anstatt den Anstiegswert nur vom Benutzer zwischenzuspeichern, beginnen wir nun, ihn mit dem bereits bekannten Geo-Hash zwischenzuspeichern. Also haben wir das Problem fast behoben. Warum fast? Weil es an den Grenzen von Geoheshes Unterschiede geben kann. Aber das Problem ist nicht so bedeutend, weil wir eine Glättung haben.
Glätten
Vielleicht ist Ihnen beim Lesen eines Falles über eine Ampel aufgefallen, dass es irgendwie unfair war, einen sofortigen Anstieg in Abhängigkeit von der Ampel in Betracht zu ziehen. Wir denken auch, also haben wir herausgefunden, wie wir die Situation beheben können.
Wir haben uns entschlossen, die
Methode der
nächsten Nachbarn aus dem maschinellen Lernen für das Regressionsproblem auszuleihen, um festzustellen, inwieweit sich der Wert des sofortigen Anstiegs von dem unterscheidet, was um uns herum geschieht.
Die Trainingsphase besteht, wie in der formalen Beschreibung der Methode, darin, alle Objekte zu speichern. In unserem Fall, den berechneten Werten des Anstiegs im Pin, tun wir dies bereits zum Zeitpunkt des Ladens aller Pins in den Cache. Die kleine Sache ist, den Momentanwert zu berechnen, ihn mit dem Wert in der Zone zu vergleichen und zuzustimmen, dass wir nicht zu stark vom Wert in der Zone abweichen können.
So erhalten wir ein System mit einer schnellen Reaktion auf Ereignisse, mit dem Sie den Wert des ansteigenden Koeffizienten schnell ablesen können.
Surge Driving Card
Um mit dem Fahrer zu kommunizieren, müssen wir in der Lage sein, die Überspannungskarte in der Fahreranwendung anzuzeigen - einem Taxameter. Dies gibt dem Fahrer eine Rückmeldung darüber, ob in dem Bereich, in dem er sich gerade befindet, Nachfrage besteht und wohin er umziehen sollte, um die teuersten Bestellungen zu erhalten. Für uns bedeutet dies, dass mehr Fahrer mit hoher Nachfrage in die Zone kommen und diese abwickeln werden.
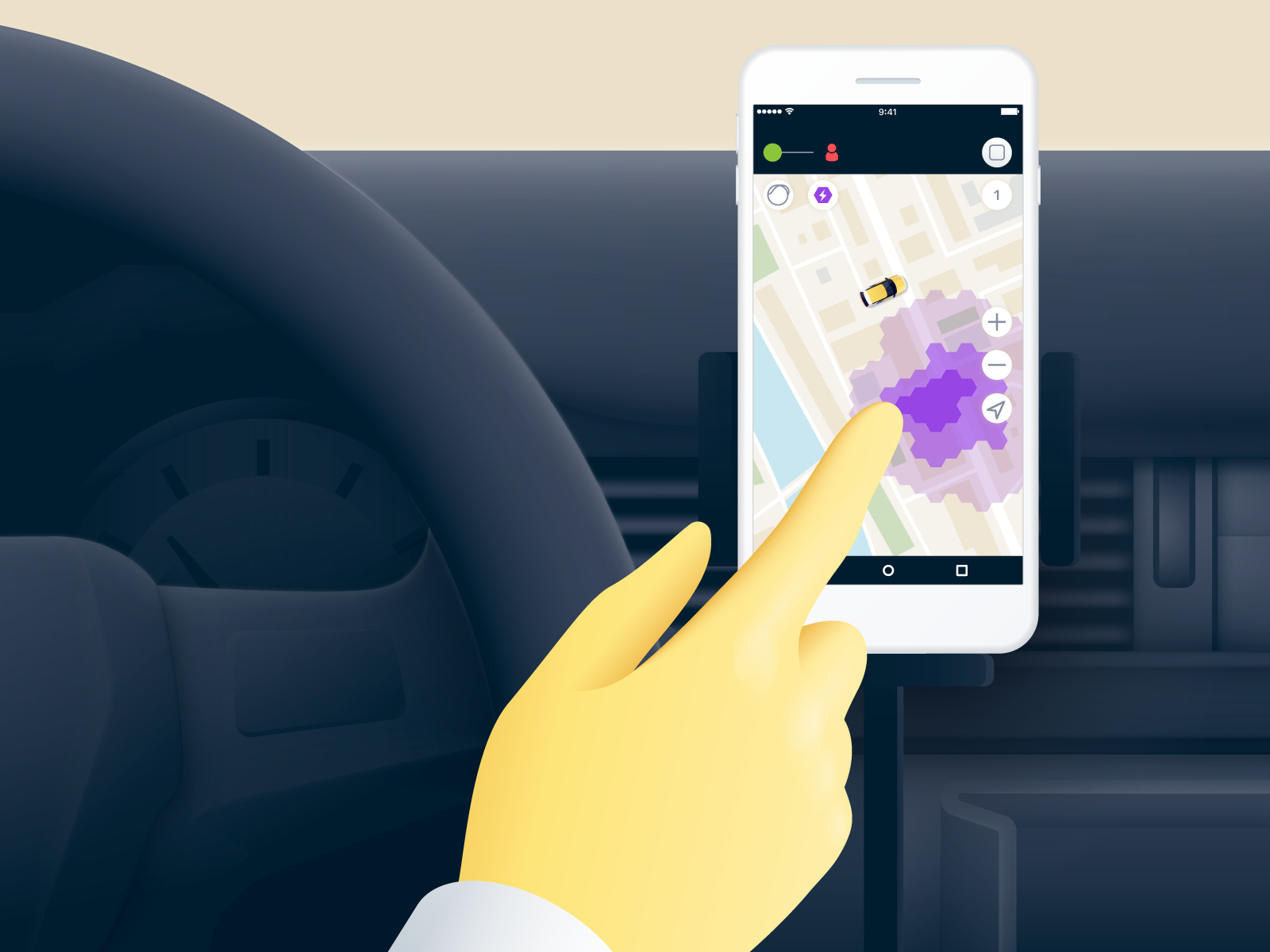
Wir leben mit dem Paradigma, dass das Gerät des Fahrers ein eher schwaches Gerät ist. Daher liegt das Rendern des hexagonalen Stoßgitters auf der Backend-Seite. Der Client kommt zum Backend für Kacheln. Dies sind geschnittene Rasterbilder zur direkten Anzeige auf der Karte.
Wir haben einen separaten Dienst, der regelmäßig Abgüsse von Stiften aus dem Surger-Mikroservice aufnimmt und alle Metainformationen berechnet, die zum Rendern des hexagonalen Gitters erforderlich sind: Wo ist welches Hex und welcher Schwall befindet sich in jedem.
Fazit
Dynamische Preisgestaltung ist eine ständige Suche nach einem Gleichgewicht zwischen Angebot und Nachfrage, sodass den Nutzern immer kostenlose Autos zur Verfügung stehen, auch durch den Mechanismus, zusätzliche Fahrer für Gebiete mit hoher Nachfrage zu gewinnen. Zum Beispiel arbeiten wir derzeit an einer tieferen Nutzung des maschinellen Lernens zur Berechnung des Anstiegs. Im Rahmen einer der Aufgaben in diesem Bereich lernen wir, die Wahrscheinlichkeit zu bestimmen, mit der ein Pin in eine Bestellung umgewandelt wird, und diese Informationen zu berücksichtigen. Da hier genug Arbeit vorhanden ist, freuen wir uns immer über
neue Spezialisten im Team.
Wenn Sie mehr über einen Teil dieses großen Themas erfahren möchten, schreiben Sie in die Kommentare. Feedback und Ideen sind ebenfalls willkommen!
PS In der nächsten
Veröffentlichung wird mein Kollege über den Einsatz von maschinellem Lernen sprechen, um die erwartete Ankunftszeit eines Taxis vorherzusagen.