Analyse von Lenta.ru-Veröffentlichungen über 18 Jahre (von September 1999 bis Dezember 2017) mit Python, Sklearn, Scipy, XGBoost, Pymorphy2, Nltk, Gensim, MongoDB, Keras und TensorFlow.

Die Studie verwendete Daten aus dem Beitrag " Analyze this - Lenta.ru " von ildarchegg . Der Autor stellte freundlicherweise 3 Gigabyte Artikel in einem praktischen Format zur Verfügung, und ich entschied, dass dies eine großartige Gelegenheit war, einige Textverarbeitungsmethoden zu testen. Wenn Sie Glück haben, lernen Sie gleichzeitig etwas Neues über den russischen Journalismus, die Gesellschaft und allgemein.
Inhalt:
MongoDB zum Importieren von JSON in Python
Leider stellte sich heraus, dass JSON mit Texten etwas kaputt war, was für mich nicht kritisch ist, aber Python weigerte sich, mit der Datei zu arbeiten. Daher habe ich es zuerst in MongoDB importiert und erst dann über MongoClient aus der Pymongo-Bibliothek das Array geladen und es in Teilen in csv neu gespeichert.
Aus den Kommentaren: 1. Ich musste die Datenbank mit dem Befehl sudo service mongod start starten - es gibt andere Optionen, aber sie haben nicht funktioniert; 2. mongoimport - eine separate Anwendung, die nicht von der mongo-Konsole aus startet, sondern nur vom Terminal.
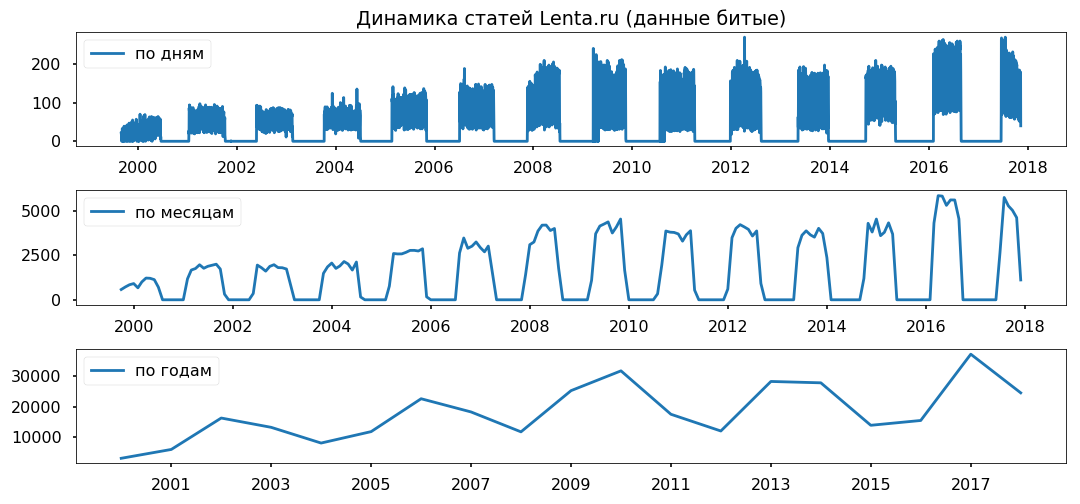
Datenlücken sind gleichmäßig über Jahre verteilt. Ich habe nicht vor, den Zeitraum von weniger als einem Jahr zu nutzen, ich hoffe, dass dies die Richtigkeit der Schlussfolgerungen nicht beeinträchtigt.
Text bereinigen und normalisieren
Bevor Sie das Array direkt analysieren, müssen Sie es in die Standardform bringen: Entfernen Sie Sonderzeichen, konvertieren Sie den Text in Kleinbuchstaben (Pandas-String-Methoden haben hervorragende Arbeit geleistet), entfernen Sie Stoppwörter (stopwords.words ('russisch') aus nltk.corpus) und bringen Sie die Wörter in ihre normale Form zurück mit Lemmatisierung (pymorphy2.MorphAnalyzer).
Es gab einige Mängel, zum Beispiel verwandelte sich Dmitry Peskov in "Dmitry" und "Sand", aber insgesamt war ich mit dem Ergebnis zufrieden.
Tag Cloud
Lassen Sie uns als Keim sehen, welche Veröffentlichungen in der allgemeinsten Form vorliegen. Wir werden die 50 häufigsten Wörter, die von Lenta-Journalisten von 1999 bis 2017 verwendet wurden, in Form einer Tag-Cloud anzeigen.

Ria Novosti (die beliebteste Quelle), Milliarden Dollar und Millionen Dollar (Finanzthemen), anwesend (Sprachauflage allen Nachrichtenseiten gemeinsam), Strafverfolgungsbehörde und Strafverfahren (kriminelle Nachrichten) ), "Premierminister" und "Wladimir Putin" (Politik) - der erwartete Stil und die Themen für das Nachrichtenportal.
LDA-thematische Modellierung
Wir berechnen die beliebtesten Themen für jedes Jahr mit der LDA von gensim. LDA (thematische Modellierung unter Verwendung der Dirichlet-Latent-Placement-Methode) identifiziert versteckte Themen (eine Reihe von Wörtern, die zusammen und am häufigsten vorkommen) automatisch anhand der beobachteten Worthäufigkeiten in den Artikeln.
Der Eckpfeiler des inländischen Journalismus war Russland, Putin, die Vereinigten Staaten.
In einigen Jahren wurde dieses Thema mit dem Tschetschenienkrieg (von 1999 bis 2000) am 11. September verwässert - 2001 im Irak (von 2002 bis 2004). Von 2008 bis 2009 stand die Wirtschaft an erster Stelle: Zinsen, Unternehmen, Dollar, Rubel, Milliarden, Millionen. 2011 schrieben sie oft über Gaddafi.
Von 2014 bis 2017 Die Jahre der Ukraine begannen und dauern in Russland an. Der Höhepunkt ereignete sich im Jahr 2015, dann begann der Trend abzunehmen, bleibt aber weiterhin auf einem hohen Niveau.
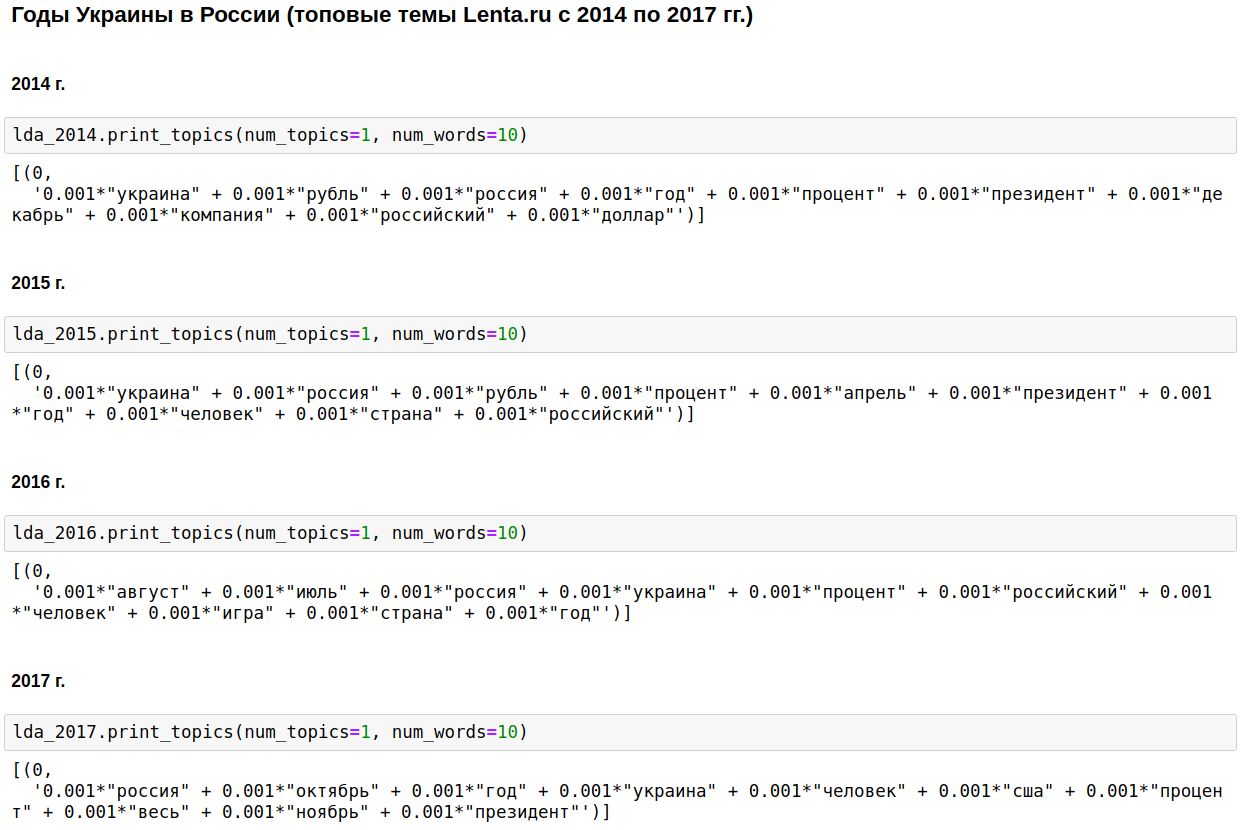
Es ist natürlich interessant, aber es gibt nichts, was ich nicht wissen oder erraten würde.
Lassen Sie uns den Ansatz ein wenig ändern - wählen Sie die Top-Themen für die gesamte Zeit aus und sehen Sie, wie sich ihr Verhältnis von Jahr zu Jahr geändert hat. Das heißt, wir werden die Entwicklung der Themen untersuchen.
Die am meisten interpretierte Option war Top 5:
- Verbrechen (männlich, Polizei, auftreten, inhaftieren, Polizist);
- Politik (Russland, Ukraine, Präsident, USA, Leiter);
- Kultur (Spinner, Eitriger, Instagram, Wandern - ja, dies ist unsere Kultur, obwohl sich speziell dieses Thema als ziemlich gemischt herausstellte);
- Sport (Spiel, Mannschaft, Spiel, Verein, Athlet, Meisterschaft);
- Wissenschaft (Wissenschaftler, Weltraum, Satellit, Planet, Zelle).
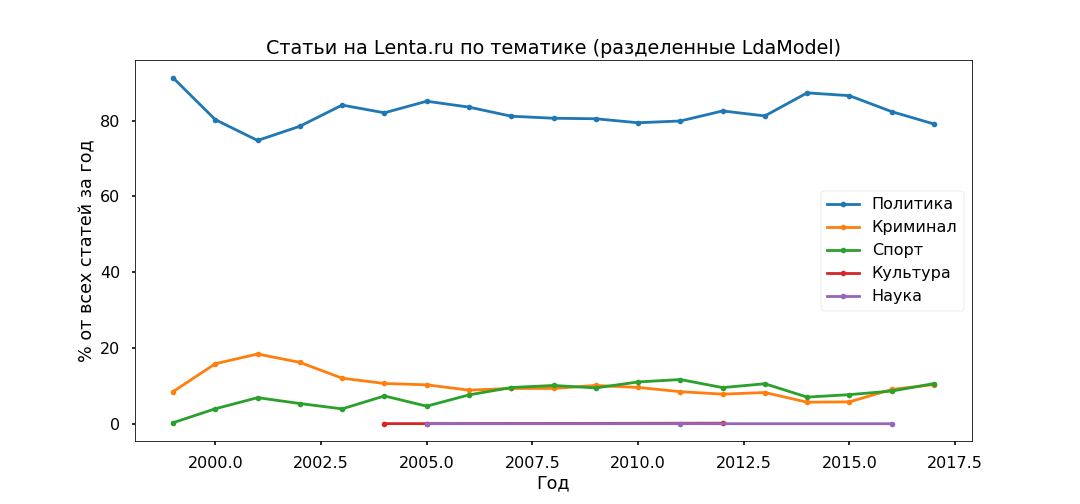
Als nächstes nehmen wir jeden Artikel und sehen, wie er sich auf ein bestimmtes Thema bezieht. Daher werden alle Materialien in fünf Gruppen unterteilt.
Die Politik erwies sich als die beliebteste - unter 80% aller Veröffentlichungen. Der Höhepunkt der Popularität von politischem Material wurde jedoch 2014 erreicht, jetzt nimmt ihr Anteil ab und der Beitrag zur Informationsagenda von Kriminalität und Sport wächst.
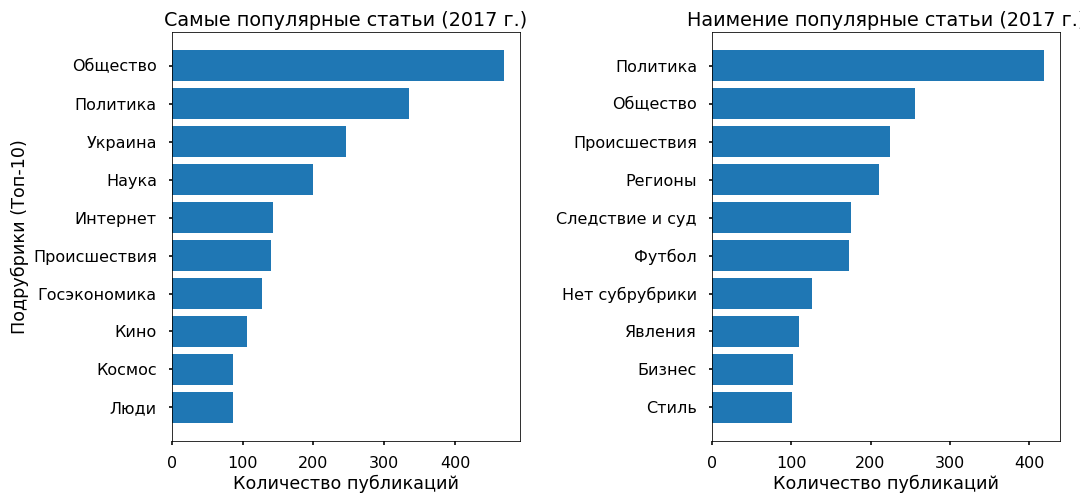
Wir werden die Angemessenheit thematischer Modelle anhand der von den Herausgebern angegebenen Unterüberschriften prüfen. Top-Unterkategorien wurden seit 2013 mehr oder weniger korrekt identifiziert.

Es wurden keine besonderen Widersprüche festgestellt: Die Politik stagniert 2017, Fußball und Zwischenfälle nehmen zu, die Ukraine ist immer noch im Trend, mit einem Höhepunkt im Jahr 2015.
Vorhersage der Popularität: XGBClassifier, LogisticRegression, Embedding & LSTM
Versuchen wir zu verstehen, ob es möglich ist, die Popularität eines Artikels auf dem Band anhand des Textes vorherzusagen und wovon diese Popularität im Allgemeinen abhängt. Als Zielvariable habe ich die Anzahl der Facebook-Reposts für 2017 verwendet.
Dreitausend Artikel für 2017 hatten keine Reposts auf Fb - sie wurden der Klasse „unbeliebt“ zugeordnet, 3.000 Materialien mit der größten Anzahl von Reposts erhielten das Label „am beliebtesten“.
Der Text (6.000 Veröffentlichungen für 2017) wurde in Unogramme und Bigramme (Token-Wörter, sowohl Einzel- als auch Zwei-Wort-Phrasen) unterteilt, und es wurde eine Matrix erstellt, in der die Spalten Token, Zeilen Artikel und am Schnittpunkt relativ sind Häufigkeit des Auftretens von Wörtern in Artikeln. Verwendete Funktionen von sklearn - CountVectorizer und TfidfTransformer.
Die vorbereiteten Daten wurden in XGBClassifier (einen Klassifikator basierend auf Gradientenverstärkung aus der xgboost-Bibliothek) eingegeben, der nach 13 Minuten Aufzählung von Hyperparametern (GridSearchCV mit cv = 3) eine Genauigkeit von 76% für den Test ergab.

Dann habe ich die übliche logistische Regression (sklearn.linear_model.LogisticRegression) verwendet und nach 17 Sekunden eine Genauigkeit von 81% erhalten.
Ich bin erneut davon überzeugt, dass lineare Methoden für die Klassifizierung von Texten am besten geeignet sind, sofern die Daten sorgfältig aufbereitet werden.
Als Hommage an die Mode habe ich ein wenig neuronale Netze getestet. Ich übersetzte die Wörter mit one_hot von keras in Zahlen, brachte alle Artikel auf die gleiche Länge (pad_sequences-Funktion von keras) und wandte LSTM (Faltungs-Neuronales Netzwerk mit TensorFlow-Backend) über die Einbettungsschicht an (um die Dimension zu reduzieren und die Verarbeitungszeit zu verkürzen).
Das Netzwerk arbeitete in 2 Minuten und zeigte eine Genauigkeit von 70% beim Test. Es ist überhaupt nicht die Grenze, aber in diesem Fall macht es keinen Sinn, viel zu stören.
Im Allgemeinen erzeugten alle Verfahren eine relativ geringe Genauigkeit. Wie die Erfahrung zeigt, funktionieren Klassifizierungsalgorithmen gut mit einer Vielzahl von Stilen - mit anderen Worten auf urheberrechtlich geschütztem Material. Es gibt solche Materialien auf Lenta.ru, aber es gibt nur sehr wenige - weniger als 2%.

Das Hauptarray wird mit neutralem Nachrichtenvokabular geschrieben. Und die Popularität von Nachrichten wird nicht durch den Text selbst und nicht einmal durch das Thema als solches bestimmt, sondern durch ihre Zugehörigkeit zu einem Aufwärtstrend der Informationen.
Zum Beispiel behandeln einige populäre Artikel Ereignisse in der Ukraine, die am wenigsten populären betreffen dieses Thema fast nicht.
Objekte mit Word2Vec erkunden
Abschließend wollte ich eine sentimentale Analyse durchführen - um zu verstehen, wie Journalisten sich auf die beliebtesten Objekte beziehen, die sie in ihren Artikeln erwähnen, ob sich ihre Einstellung im Laufe der Zeit ändert.
Aber ich habe nicht die markierten Daten und eine Suche nach semantischen Thesauri funktioniert wahrscheinlich nicht richtig, da das Nachrichtenvokabular ziemlich neutral und geizig ist. Daher habe ich mich entschlossen, mich auf den Kontext zu konzentrieren, in dem die Objekte erwähnt werden.
Ich habe die Ukraine (2015 gegen 2017) und Putin (2000 gegen 2017) als Test genommen. Ich habe die Artikel ausgewählt, in denen sie erwähnt werden, den Text in einen mehrdimensionalen Vektorraum übersetzt (Word2Vec von gensim.models) und mit der Methode der Hauptkomponenten auf zweidimensional projiziert.
Nach dem Rendern der Bilder erwiesen sie sich als episch, nicht weniger als die Größe eines Wandteppichs aus Bayeux. Ich schneide die notwendigen Cluster aus, um die Wahrnehmung zu vereinfachen, so gut ich konnte, entschuldige die "Schakale".


Was mir aufgefallen ist.
Putin des Modells von 2000 ist immer im Kontext Russlands aufgetreten und hat sich persönlich angesprochen. 2017 wurde der Präsident der Russischen Föderation zum Führer (was auch immer das bedeutet) und distanzierte sich vom Land. Nach dem Kontext ist er nun ein Vertreter des Kremls, der über seinen Pressesprecher mit der Welt kommuniziert.
Ukraine-2015 in den russischen Medien - Krieg, Schlachten, Explosionen; es wird depersonalisiert erwähnt (Kiew erklärte, Kiew begann). Die Ukraine-2017 erscheint hauptsächlich im Rahmen von Verhandlungen zwischen Beamten, und diese Personen haben spezifische Namen.
...
Sie können die seit einiger Zeit erhaltenen Informationen interpretieren, aber wie ich denke, ist dies eine offtopische Ressource für diese Ressource. Wer möchte, kann sich selbst davon überzeugen. Ich lege den Code und die Daten bei.
Skript-Link
Datenverbindung