
Wie Sie wissen, ist HTTP 1.1 ein textbasiertes Datenübertragungsprotokoll. HTTP-Nachrichten werden mit ISO-8859-1 codiert (dies kann bedingt als erweiterte Version von ASCII angesehen werden, die Umlaute, diakritische Zeichen und andere in westeuropäischen Sprachen verwendete Zeichen enthält). Gleichzeitig kann im Nachrichtentext eine andere Codierung verwendet werden, die im Header „Content-Type“ angegeben werden sollte. Was aber, wenn wir Nicht-ASCII-Zeichen nicht im Nachrichtentext, sondern in den Headern selbst angeben müssen? Der wahrscheinlich häufigste Fall ist das Einfügen eines Dateinamens in den Header "Content-Disposition". Dies scheint eine ziemlich häufige Aufgabe zu sein, aber ihre Umsetzung ist nicht so offensichtlich.
TL; DR: Verwenden Sie die in
RFC 6266 für „Content-Disposition“ beschriebene Codierung und konvertieren Sie den Text in anderen Fällen in Latein (Transliteration).
Eine kleine Einführung in Codierungen
Der Artikel erwähnt und verwendet US-ASCII-Codierungen (oft einfach als ASCII bezeichnet), ISO-8859-1 und UTF-8. Dies ist eine kleine Einführung in diese Codierungen. Der Abschnitt richtet sich an Entwickler, die selten oder vollständig nicht mit Codierungen arbeiten und diese vergessen haben. Wenn Sie nicht zu ihnen gehören, können Sie den Abschnitt überspringen.
ASCII ist eine einfache Codierung mit 128 Zeichen, die das gesamte englische Alphabet, Zahlen, Satzzeichen und Dienstzeichen enthält.
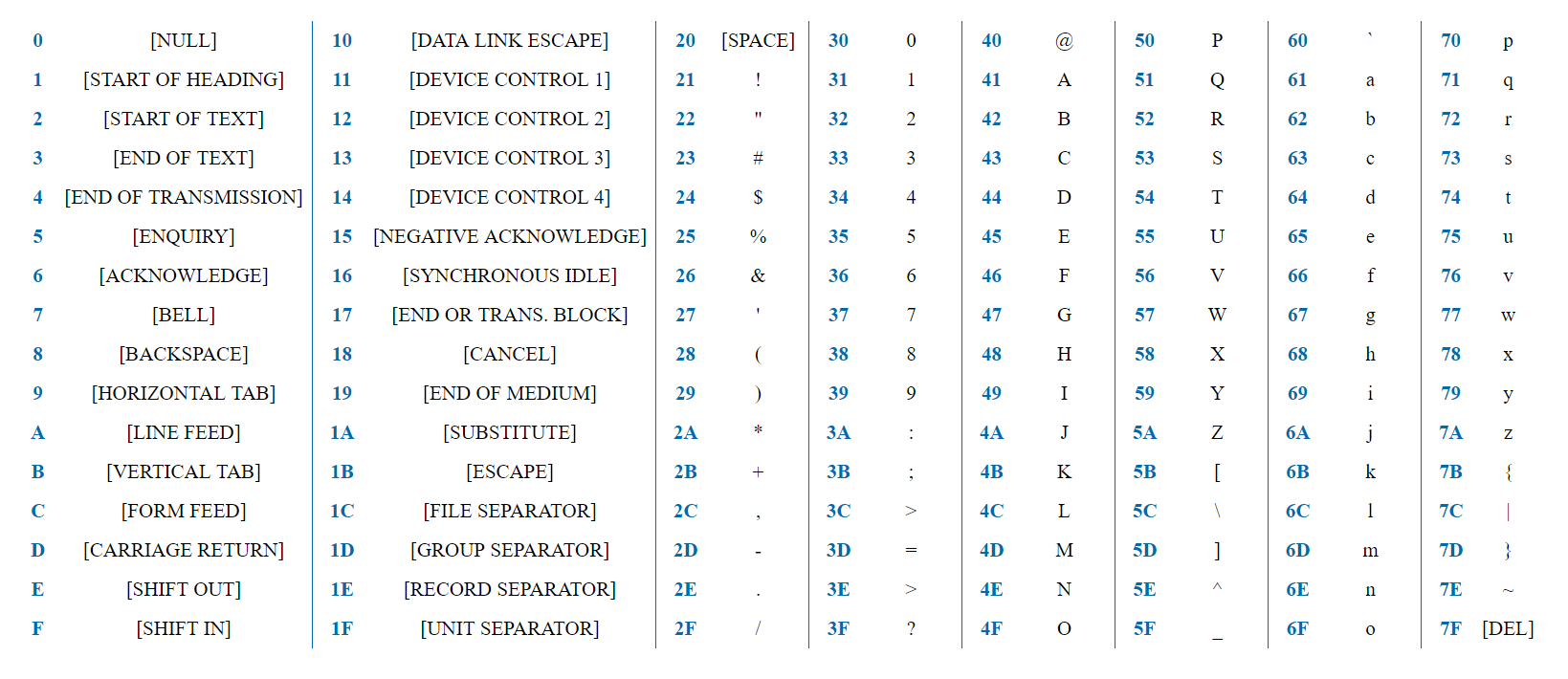
7 Bits reichen aus, um ein beliebiges ASCII-Zeichen darzustellen. Das Wort "Test" wird in der HEX-Darstellung als 0x74 0x65 0x73 0x74 dargestellt. Das erste Bit für alle Zeichen ist immer 0, da die Zeichen in 128 codiert sind und das Byte 2 ^ 8 = 256 Optionen bietet.
ISO-8859-1 ist eine Codierung für westeuropäische Sprachen. Enthält französische Diakritika, deutsche Umlaute usw.
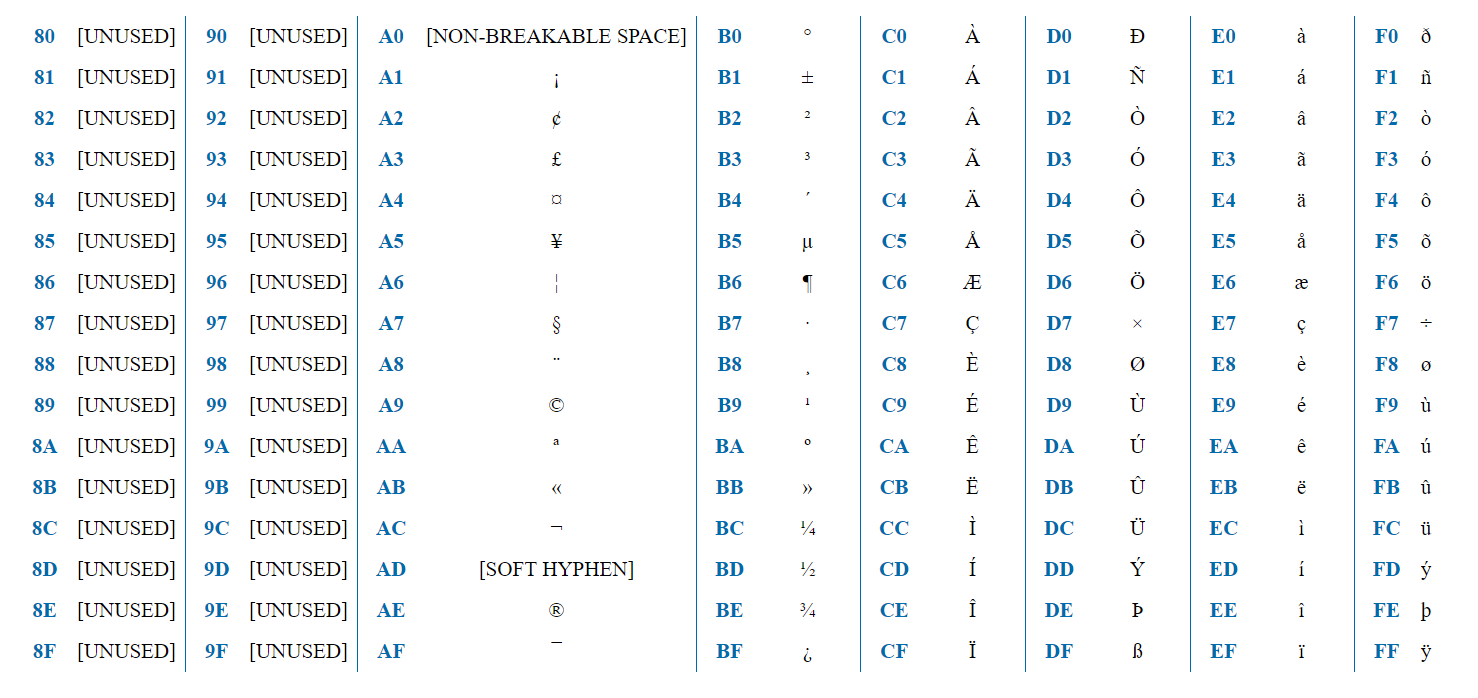
Die Codierung enthält 256 Zeichen und kann somit durch ein Byte dargestellt werden. Die erste Hälfte (128 Zeichen) entspricht genau ASCII. Wenn also das erste Bit = 0 ist, ist dies ein reguläres ASCII-Zeichen. Wenn 1, dann ist dies ein Zeichen, das für ISO-8859-1 spezifisch ist.
UTF-8 ist neben ASCII eine der bekanntesten Codierungen. Kann 1.112.064 Zeichen codieren.
Die Größe jedes Zeichens variiert zwischen 1 und 4 Bytes (
zuvor waren bis zu 6 Bytes zulässig).

Das Programm, das mit dieser Codierung arbeitet, bestimmt anhand der ersten Bits, wie viele Bytes im Zeichen enthalten sind. Wenn das Oktett bei 0 beginnt, wird das Zeichen durch ein Byte dargestellt. 110 - zwei Bytes, 1110 - drei Bytes, 11110 - 4 Bytes.
Wie bei ISO-8859-1 sind die ersten 128 Zeichen vollständig ASCII-kompatibel. Daher sind Texte, die nur ASCII-Zeichen verwenden, in der Binärdarstellung absolut identisch, unabhängig davon, ob US-ASCII, ISO-8859-1 oder UTF-8 für die Codierung verwendet wurden.
Verwenden von UTF-8 im Nachrichtentext
Bevor wir zu den Headern übergehen, werfen wir einen kurzen Blick auf die Verwendung von UTF-8 im Nachrichtentext. Verwenden Sie dazu den Header
"Content-Type" .

Wenn der "Inhaltstyp" nicht angegeben ist, sollte der Browser die Nachrichten so verarbeiten, als wären sie in ISO-8859-1 geschrieben.
Der Browser sollte nicht versuchen, die Codierung zu erraten und außerdem den "Inhaltstyp" ignorieren. Was jedoch in einer Situation, in der der "Inhaltstyp" nicht übertragen wird, wirklich auftritt, hängt von der Implementierung des Browsers ab. Beispielsweise arbeitet Firefox gemäß der Spezifikation und liest die Nachricht so, als ob sie in ISO-8859-1 codiert wäre. Im Gegensatz dazu wird Google Chrome die Codierung des Betriebssystems verwenden, die für viele russische Benutzer Windows-1251 entspricht. Wenn sich die Nachricht in UTF-8 befand, wird sie in jedem Fall nicht korrekt angezeigt.

Wir setzen die UTF-8-Nachricht in den Header-Wert
Mit dem Nachrichtentext ist alles ganz einfach. Der Nachrichtentext folgt immer den Überschriften, sodass keine technischen Probleme auftreten. Aber was ist mit den Schlagzeilen? In der Spezifikation wird
ausdrücklich angegeben, dass die Reihenfolge der Header in der Nachricht keine Rolle spielt. Das heißt, Es ist nicht möglich, die Codierung in einem Header durch einen anderen Header anzugeben.
Was passiert, wenn Sie nur den UTF-8-Wert in den Header-Wert schreiben? Wir haben gesehen, dass ein solcher Trick mit dem Nachrichtentext dazu führt, dass der Wert einfach in ISO-8859-1 gelesen wird. Es wäre logisch anzunehmen, dass das Gleiche mit der Überschrift passieren wird. Aber das ist nicht so. Tatsächlich funktioniert diese Lösung in vielen, wenn nicht den meisten Fällen. Dies schließt alte iPhones, IE11, Firefox und Google Chrome ein. Der einzige Browser, der mir zur Verfügung stand, als ich diesen Artikel schrieb, der nicht mit diesem Titel arbeiten wollte, war Edge.

Dieses Verhalten ist in den Spezifikationen nicht erfasst. Vielleicht haben die Browser-Entwickler beschlossen, den Entwicklern das Leben zu erleichtern und automatisch zu erkennen, dass die Nachrichtenkopfzeilen in UTF-8 codiert wurden. Im Allgemeinen ist dies keine so schwierige Aufgabe. Wir betrachten das erste Bit: wenn 0, dann ASCII, wenn 1 - dann möglicherweise UTF-8.
Gibt es in diesem Fall einen Schnittpunkt mit ISO-8859-1? In der Tat fast keine. Nehmen Sie zum Beispiel UTF-8 ein 2-Oktett-Zeichen (russische Buchstaben werden durch zwei Oktette dargestellt). Das Symbol in der dargestellten Binärdatei sieht folgendermaßen aus:
110xxxxx 10xxxxxx . In der HEX-Darstellung:
[0xC0-0x6F] [0x80-0xBF] . In ISO-8859-1 können diese Zeichen kaum etwas codieren, das eine semantische Last trägt. Daher ist das Risiko, dass der Browser die Nachricht falsch entschlüsselt, sehr gering.
Wenn Sie jedoch versuchen, diese Methode zu verwenden, können technische Probleme auftreten: Ihr Webserver oder Framework erlaubt möglicherweise einfach nicht, UTF-8-Zeichen in den Header-Wert zu schreiben. Zum Beispiel setzt Apache Tomcat 0x3F (Fragezeichen) anstelle aller UTF-8-Zeichen. Natürlich kann diese Einschränkung umgangen werden, aber wenn die Anwendung selbst Hände schüttelt und es Ihnen nicht erlaubt, etwas zu tun, müssen Sie dies möglicherweise nicht tun.
Unabhängig davon, ob Sie mit Ihrem Framework oder Server UTF-8-Nachrichten in den Header schreiben können oder nicht, empfehle ich dies nicht. Dies ist keine dokumentierte Lösung, die zu einem bestimmten Zeitpunkt möglicherweise nicht mehr in Browsern funktioniert.
Übersetzen
Ich denke, dass Translit verwendet wird - eto bolee horoshee reshenie. Viele große populäre russische Ressourcen verachten die Verwendung von Transliteration in Dateinamen nicht. Dies ist eine garantierte Lösung, die mit der Veröffentlichung neuer Browser nicht kaputt geht und nicht auf jeder Plattform separat getestet werden muss. Natürlich müssen Sie darüber nachdenken, wie Sie das gesamte Spektrum möglicher Zeichen konvertieren können, was möglicherweise nicht ganz trivial ist. Wenn die Anwendung beispielsweise für ein russisches Publikum konzipiert ist, können die tatarischen Buchstaben ә und ң im Dateinamen erscheinen, der irgendwie verarbeitet und nicht nur durch "?" Ersetzt werden muss.
RFC 2047
Wie bereits erwähnt, erlaubte mir der Tomkat nicht, UTF-8 in den Nachrichtenkopf aufzunehmen. Spiegelt sich diese Verhaltensfunktion in Java-Dokumenten für Servlets wider? Ja, reflektiert:
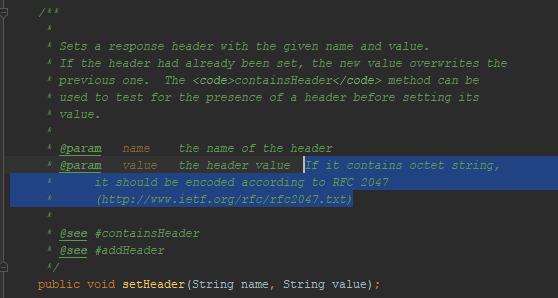
Erwähnt
RFC 2047 . Ich habe versucht, Nachrichten in diesem Format zu verschlüsseln - der Browser hat mich nicht verstanden. Diese Codierungsmethode funktioniert nicht in HTTP. Obwohl er vorher gearbeitet hat. Beispiel: Ein
Ticket zum Entfernen der Unterstützung für diese Codierung aus Firefox.
RFC 6266
In dem Ticket, auf das im vorherigen Abschnitt
verwiesen wird ,
gibt es Hinweise, dass es auch nach Beendigung der Unterstützung für RFC 2047 noch eine Möglichkeit gibt, UTF-8-Werte im Namen der heruntergeladenen Dateien zu übertragen:
RFC 6266 . Meiner Meinung nach ist dies die bisher richtigste Entscheidung. Viele beliebte Online-Ressourcen verwenden es. Wir von
CUBA Platform verwenden diesen speziellen RFC auch, um die „Content-Disposition“ zu generieren.
RFC 6266 ist eine Spezifikation, die die Verwendung des Headers "Content-Disposition" beschreibt. Das Codierungsverfahren selbst ist in einer anderen Spezifikation,
RFC 8187 ,
ausführlich beschrieben .

Der Parameter "Dateiname" enthält den Dateinamen in ASCII, "Dateiname *" - in jeder erforderlichen Codierung. Bei beiden Attributen wird "Dateiname" in allen modernen Browsern (einschließlich IE11 und älteren Versionen von Safari) ignoriert. Im Gegensatz dazu ignorieren die meisten alten Browser "Dateiname *".
Bei Verwendung dieser Codierungsmethode gibt der Parameter zuerst die Codierung an, gefolgt vom codierten Wert. Sichtbare Zeichen aus der ASCII-Codierung sind nicht erforderlich. Die restlichen Zeichen werden einfach in hexadezimaler Darstellung mit einem "%" vor jedem Oktett geschrieben.
Was tun mit anderen Headern?
Die in RFC 8187 beschriebene Codierung ist nicht universell. Ja, Sie können einen Parameter mit dem Präfix * in den Header einfügen. Dies funktioniert möglicherweise sogar für einige Browser, die
Spezifikation schreibt jedoch vor, dies nicht zu tun.
In jedem Fall, in dem UTF-8 in den Headern unterstützt wird, wird dies derzeit im entsprechenden RFC ausdrücklich erwähnt. Zusätzlich zur Inhaltsdisposition wird diese Codierung beispielsweise bei der
Webverknüpfung und der
Digest-Zugriffsauthentifizierung verwendet .
Es ist zu beachten, dass sich die Standards in diesem Bereich ständig ändern. Die Verwendung der oben in HTTP beschriebenen Codierung wurde
erst 2010 vorgeschlagen . Die Verwendung dieser Kodierung in „Content-Disposition“ wurde
2011 im Standard festgelegt . Trotz der Tatsache, dass sich diese Standards nur
in der Phase „Vorgeschlagener Standard“ befinden , werden sie überall unterstützt. Die Option, dass wir in Zukunft neue Standards erwarten, die eine einheitlichere Arbeit mit unterschiedlichen Codierungen in den Headern ermöglichen, ist nicht ausgeschlossen. Daher bleibt es nur, die Nachrichten in der Welt der HTTP-Standards und deren Unterstützungsgrad auf der Seite der Browser zu verfolgen.