Bei der optischen Zeichenerkennung (OCR) werden gedruckte Texte in digitalisiertem Format abgerufen. Wenn Sie einen klassischen Roman auf einem digitalen Gerät gelesen oder einen Arzt gebeten haben, alte Krankenakten über das Computersystem des Krankenhauses abzurufen, haben Sie wahrscheinlich OCR verwendet.
OCR macht zuvor statische Inhalte bearbeitbar, durchsuchbar und gemeinsam nutzbar. Viele Dokumente, die digitalisiert werden müssen, enthalten Kaffeeflecken, Seiten mit gekräuselten Ecken und viele Falten, die einige gedruckte Dokumente nicht digitalisieren.
Jeder weiß seit langem, dass Millionen alter Bücher eingelagert sind. Die Verwendung dieser Bücher ist aufgrund ihres Verfalls und ihrer Altersschwäche verboten, weshalb die Digitalisierung dieser Bücher so wichtig ist.
Das Papier befasst sich mit der Aufgabe, Text von Rauschen zu befreien, Text in einem Bild zu erkennen und in ein Textformat zu konvertieren.

Für das Training wurden 144 Bilder verwendet. Die Größe kann unterschiedlich sein, sollte aber vorzugsweise im Rahmen des Zumutbaren liegen. Bilder müssen im PNG-Format vorliegen. Nach dem Lesen des Bildes wird die Binärisierung verwendet - der Prozess des Konvertierens eines Farbbilds in Schwarzweiß, dh jedes Pixel wird auf einen Bereich von 0 bis 255 normalisiert, wobei 0 schwarz und 255 weiß ist.
Um ein Faltungsnetzwerk zu trainieren, benötigen Sie mehr Bilder als vorhanden. Es wurde beschlossen, die Bilder in Teile zu teilen. Da das Trainingsbeispiel aus Bildern unterschiedlicher Größe besteht, wurde jedes Bild auf 448 x 448 Pixel komprimiert. Das Ergebnis waren 144 Bilder mit einer Auflösung von 448 x 448 Pixel. Dann wurden alle in nicht überlappende Fenster mit einer Größe von 112 x 112 Pixel geschnitten.

Somit wurden von 144 Anfangsbildern ungefähr 2304 Bilder im Trainingssatz erhalten. Das war aber nicht genug. Für ein gutes Faltungsnetzwerktraining ist mehr Training erforderlich. Infolgedessen war es am besten, die Bilder um 90 Grad, dann um 180 und 270 Grad zu drehen. Infolgedessen wird dem Netzwerkeingang ein Array mit der Größe [16,112,112,1] zugeführt. Dabei ist 16 die Anzahl der Bilder, 112 die Breite und Höhe jedes Bildes, 1 die Farbkanäle. Es stellte sich heraus, 9216 Beispiele für das Training. Dies reicht aus, um ein Faltungsnetzwerk zu trainieren.
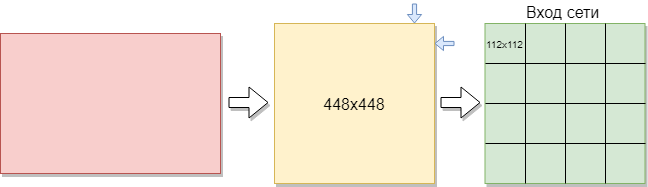
Jedes Bild hat eine Größe von 112 x 112 Pixel. Wenn die Größe zu groß ist, erhöht sich der Rechenaufwand bzw. die Einschränkungen der Antwortgeschwindigkeit werden verletzt, die Bestimmung der Größe in diesem Problem wird durch das Auswahlverfahren gelöst. Wenn Sie eine zu kleine Größe auswählen, kann das Netzwerk keine Schlüsselzeichen identifizieren. Jedes Bild hat ein Schwarzweißformat, daher ist es in einen Kanal unterteilt. Farbbilder sind in 3 Kanäle unterteilt: Rot, Blau, Grün. Da wir Schwarzweißbilder haben, beträgt die Größe jedes Bildes 112 x 122 x 1 Pixel.
Zunächst ist es notwendig, ein Faltungsnetzwerk auf vorbereiteten, verarbeiteten Bildern zu trainieren. Für diese Aufgabe wurde die U-Net-Architektur ausgewählt.
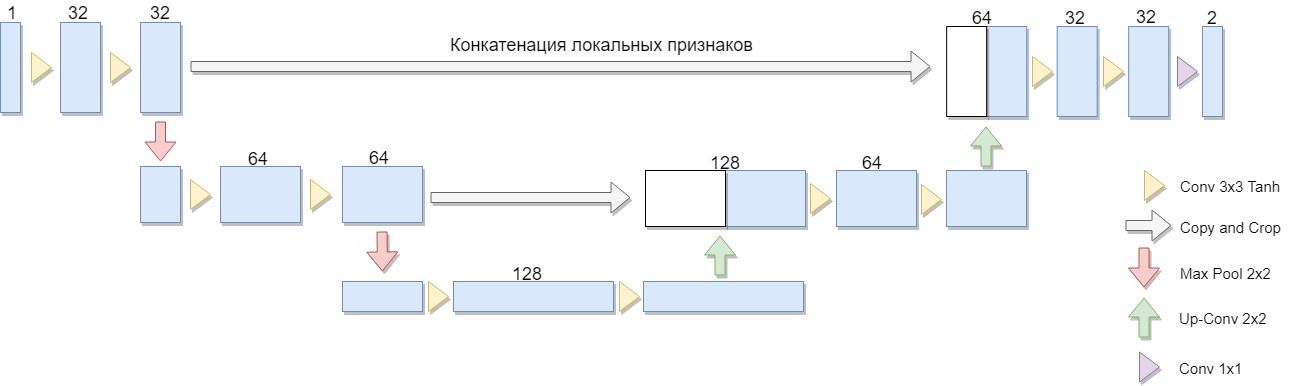
Es wurde eine reduzierte Version der Architektur ausgewählt, die nur aus zwei Blöcken besteht (die ursprüngliche Version von vier). Eine wichtige Überlegung war die Tatsache, dass eine große Klasse bekannter Binärisierungsalgorithmen in einer solchen Architektur oder einer ähnlichen Architektur explizit ausgedrückt wird (als Beispiel können wir den Niblack-Algorithmus modifizieren, indem wir die Standardabweichung durch die mittlere Abweichung ersetzen. In diesem Fall wird das Netzwerk besonders einfach aufgebaut).
Der Vorteil dieser Architektur besteht darin, dass Sie zum Trainieren des Netzwerks eine ausreichende Menge an Trainingsdaten aus einer kleinen Anzahl von Quellbildern erstellen können. Darüber hinaus weist das Netzwerk aufgrund seiner Faltungsarchitektur eine relativ geringe Anzahl von Gewichten auf. Aber es gibt einige Nuancen. Insbesondere das verwendete künstliche neuronale Netzwerk löst streng genommen das Binärisierungsproblem nicht: Für jedes Pixel des Originalbilds wird eine Zahl von 0 bis 1 zugeordnet, die den Grad kennzeichnet, in dem dieses Pixel zu einer der Klassen gehört (sinnvolle Füllung oder Hintergrund) und der erforderlich ist konvertiere immer noch zur endgültigen binären Antwort. [1]
U-Net besteht aus einem Komprimierungs- und Dekomprimierungspfad und "Weiterleiten" zwischen ihnen. Der Komprimierungspfad in dieser Architektur besteht aus zwei Blöcken (in der ursprünglichen Version von vier). Jeder Block hat zwei Faltungen mit einem 3x3-Filter (unter Verwendung der Tanh-Aktivierungsfunktion nach der Faltung) und ein Pooling mit einer 2x2-Filtergröße in Schritten von 2. Die Anzahl der Kanäle bei jedem Schritt verdoppelt sich.
Der Quetschweg besteht ebenfalls aus zwei Blöcken. Jeder von ihnen besteht aus einem "Sweep" mit einer Filtergröße von 2x2, der Halbierung der Anzahl der Kanäle, der Verkettung mit der entsprechenden abgeschnittenen Feature-Map aus dem Komprimierungspfad ("Weiterleitung") und zwei Faltungen mit einem 3x3-Filter (unter Verwendung der Tanh-Aktivierungsfunktion nach der Faltung). Als nächstes wird auf der letzten Schicht eine 1x1-Faltung (unter Verwendung der Sigmoid-Aktivierungsfunktion) durchgeführt, um ein flaches Ausgabebild zu erhalten. Beachten Sie, dass das Trimmen der Feature-Map während der Verkettung aufgrund des Verlusts von Grenzpixeln für jede Faltung wesentlich ist. Adam wurde als Methode zur stochastischen Optimierung gewählt.
Im Allgemeinen ist Architektur eine Folge von Faltungs- + Pooling-Schichten, die die räumliche Auflösung des Bildes verringern und dann erhöhen, indem sie im Voraus mit den Bilddaten kombiniert werden und die anderen Faltungsschichten durchlaufen. Somit wirkt das Netzwerk als eine Art Filter. [2]
Die Testprobe bestand aus ähnlichen Bildern, die Unterschiede bestanden nur in der Rauschstruktur und im Text. Auf diesem Bild wurden Netzwerktests durchgeführt.

Am Ausgang des Faltungsnetzwerks wird ein Array von Zahlen mit einer Größe von [16,112,112,1] erhalten. Jede Nummer ist ein separates Pixel, das vom Netzwerk verarbeitet wird. Bilder haben ein Format von 112x112 Pixel, wie zuvor wurde es in Stücke geschnitten. Sie muss das ursprüngliche Aussehen verraten. Wir kombinieren die erhaltenen Bilder in einem Teil, so dass das Bild ein Format von 448x448 hat. Als nächstes multiplizieren wir jede Zahl im Array mit 255, um einen Bereich von 0 bis 255 zu erhalten, wobei 0 schwarz und 255 weiß ist. Wir bringen das Bild auf seine ursprüngliche Größe zurück, da es zuvor komprimiert wurde. Das Ergebnis ist das Bild unten in der Abbildung.

In diesem Beispiel ist zu sehen, dass das Faltungsnetzwerk den größten Teil des Rauschens bewältigte und sich als effizient erwies. Es ist jedoch deutlich zu erkennen, dass das Bild wolkiger wurde und die fehlenden Geräusche sichtbar sind. Dies kann in Zukunft die Genauigkeit der Texterkennung beeinträchtigen.
Aufgrund dieser Tatsache wurde beschlossen, ein anderes neuronales Netzwerk zu verwenden - ein mehrschichtiges Perzeptron. Im erwarteten Ergebnis sollte das Netzwerk den Text im Bild klarer machen und das Rauschen entfernen, das im Faltungs-Neuronalen Netzwerk fehlt.
Ein Bild, das bereits vom Faltungsnetzwerk verarbeitet wurde, wird an den Eingang des mehrschichtigen Perzeptrons gesendet. In diesem Fall unterscheidet sich das Trainingsmuster für dieses Netzwerk von dem Beispiel für das Faltungsnetzwerk, da die Netzwerke das Bild unterschiedlich verarbeiten. Das Faltungsnetzwerk wird als Hauptnetzwerk betrachtet und entfernt den größten Teil des Bildrauschens, während das mehrschichtige Perzeptron verarbeitet, was das Faltungsnetzwerk nicht getan hat.
Hier sind einige Beispiele aus dem Trainingsset für ein mehrschichtiges Perzeptron.

Bilddaten wurden erhalten, indem die Trainingsprobe für das Faltungsnetzwerk mit einem mehrschichtigen Perzeptron verarbeitet wurde. Zur gleichen Zeit wurde das Perzeptron an derselben Probe trainiert, jedoch an einer kleinen Anzahl von Beispielen und einer kleinen Anzahl von Epochen.
Für das Perzeptron-Training wurden 36 Bilder verarbeitet. Das Netzwerk wird Pixel für Pixel trainiert, dh ein Pixel aus dem Bild wird an den Netzwerkeingang gesendet. Am Ausgang des Netzwerks erhalten wir auch ein Ausgangsneuron - ein Pixel, dh die Netzwerkantwort. Um die Genauigkeit der Verarbeitung zu erhöhen, wurden 29 Eingangsneuronen hergestellt. Und dem Bild, das nach der Verarbeitung durch das Faltungsnetzwerk erhalten wurde, werden 28 Filter überlagert. Das Ergebnis sind 29 Bilder mit verschiedenen Filtern. Wir senden ein Pixel von jedem 29 Bild an den Netzwerkeingang und nur ein Pixel wird am Netzwerkausgang empfangen, dh an der Netzwerkantwort.
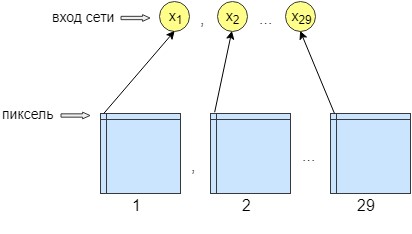
Dies wurde für ein besseres Training und Networking durchgeführt. Danach begann das Netzwerk, die Genauigkeit und den Kontrast des Bildes zu erhöhen. Außerdem werden kleinere Fehler behoben, durch die das Faltungsnetzwerk nicht gelöscht werden konnte.
Infolgedessen hat das neuronale Netzwerk 29 Eingangsneuronen, ein Pixel von jedem Bild. Nach den Experimenten wurde festgestellt, dass nur eine verborgene Schicht benötigt wurde, in der 500 Neuronen. Es gibt nur einen Ausweg aus dem Netzwerk. Da das Training Pixel für Pixel stattfand, wurde n * m mal auf das Netzwerk zugegriffen, wobei n die Bildbreite bzw. m die Höhe ist.

Nach der sequentiellen Verarbeitung des Bildes durch zwei neuronale Netze bleibt nur noch die Erkennung des Textes. Hierzu wurde eine vorgefertigte Lösung gewählt, nämlich die Python-Bibliothek Pytesseract. Pytesseract bietet keine echten Python-Bindungen. Es ist vielmehr ein einfacher Wrapper für die Tesseract-Binärdatei. In diesem Fall wird tesseract separat auf dem Computer installiert. Pytesseract speichert das Bild in einer temporären Datei auf der Festplatte, ruft dann die Tesseract-Binärdatei auf und schreibt das Ergebnis in eine Datei.
Dieser Wrapper wurde von Google entwickelt und ist kostenlos und kostenlos zu verwenden. Es kann sowohl für eigene als auch für kommerzielle Zwecke verwendet werden. Die Bibliothek funktioniert ohne Internetverbindung, unterstützt viele Sprachen zur Erkennung und beeindruckt durch ihre Geschwindigkeit. Seine Anwendung kann in verschiedenen populären Anwendungen gefunden werden.
Der letzte verbleibende Punkt besteht darin, den erkannten Text in einem für die Verarbeitung geeigneten Format in eine Datei zu schreiben. Wir verwenden dafür ein normales Notizbuch, das nach Beendigung des Programms geöffnet wird. Außerdem wird der Text auf der Testoberfläche angezeigt. Ein gutes Beispiel für eine Schnittstelle.
Referenzliste:
- Die Siegesgeschichte beim internationalen Dokumentenerkennungswettbewerb des SmartEngines-Teams [Elektronische Ressource]. Zugriffsmodus: https://habr.com/company/smartengines/blog/344550/
- Bildsegmentierung über ein neuronales Netzwerk: U-Net [Elektronische Ressource]. Zugriffsmodus: http://robocraft.ru/blog/machinelearning/3671.html
> Github-Repository