
Hallo an alle!
Als Fortsetzung des Studiums zum Thema
Deep Learning wollten wir einmal mit Ihnen darüber sprechen,
warum Schafe in neuronalen Netzen überall zu sein scheinen . Dieses Thema wird im 9. Kapitel des Buches von François Scholl behandelt.
So gingen wir zu den wunderbaren Studien über positive Technologien,
die bei Habré vorgestellt wurden , sowie zu der hervorragenden Arbeit von zwei MIT-Mitarbeitern, die der Ansicht sind, dass „böswilliges maschinelles Lernen“ nicht nur ein Hindernis und ein Problem ist, sondern auch ein wunderbares Diagnosewerkzeug.
Weiter - unter dem Schnitt.
In den letzten Jahren haben Fälle von böswilligen Eingriffen in der Deep-Learning-Community ernsthafte Aufmerksamkeit erregt. In diesem Artikel möchten wir dieses Phänomen allgemein skizzieren und diskutieren, wie es in den breiteren Kontext der Zuverlässigkeit des maschinellen Lernens passt.
Böswillige Interventionen: Ein faszinierendes PhänomenUm den Umfang unserer Diskussion zu skizzieren, geben wir einige Beispiele für solche böswilligen Eingriffe. Wir glauben, dass die meisten Forscher in der Region Moskau auf ähnliche Bilder gestoßen sind:
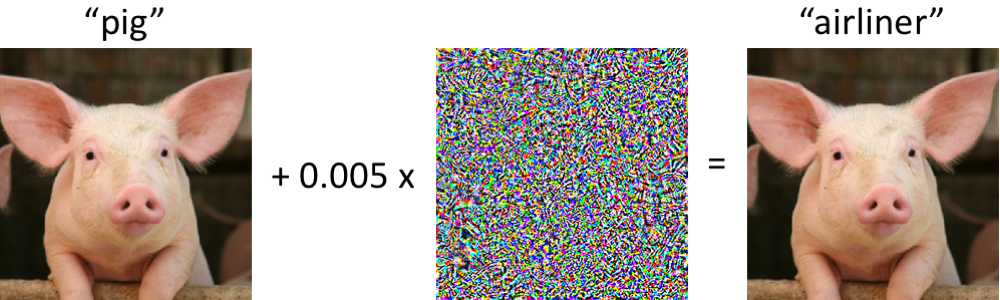
Auf der linken Seite befindet sich ein Schweinchen, das vom modernen Faltungsnetzwerk korrekt als Ferkel klassifiziert wurde. Sobald wir minimale Änderungen am Bild vornehmen (alle Pixel liegen im Bereich [0, 1] und jeder ändert sich um nicht mehr als 0,005) - und jetzt gibt das Netzwerk die Klasse „Verkehrsflugzeug“ mit hoher Zuverlässigkeit zurück. Solche Angriffe auf trainierte Klassifikatoren sind seit mindestens 2004 bekannt (
Link ), und die ersten Arbeiten zu böswilligen Interferenzen mit Bildklassifikatoren stammen aus dem Jahr 2006 (
Link ). Dann erregte dieses Phänomen seit etwa 2013 deutlich mehr Aufmerksamkeit, als sich herausstellte, dass neuronale Netze für Angriffe dieser Art anfällig sind (siehe
hier und
hier ). Seitdem haben viele Forscher Optionen für die Konstruktion böswilliger Beispiele sowie Möglichkeiten vorgeschlagen, die Resistenz von Klassifikatoren gegen solche pathologischen Störungen zu erhöhen.
Es ist jedoch wichtig zu bedenken, dass es nicht notwendig ist, sich mit neuronalen Netzen zu befassen, um solche böswilligen Beispiele zu beobachten.
Wie robust sind Malware-Beispiele?Vielleicht ist die Situation, in der der Computer das Ferkel mit dem Verkehrsflugzeug verwechselt, zunächst alarmierend. Es ist jedoch zu beachten, dass der in diesem Fall verwendete Klassifikator (
Inception-v3-Netzwerk ) nicht so fragil ist, wie es auf den ersten Blick erscheinen mag. Obwohl sich das Netzwerk wahrscheinlich irrt, wenn versucht wird, ein verzerrtes Ferkel zu klassifizieren, geschieht dies nur bei speziell ausgewählten Verstößen.
Das Netzwerk ist viel widerstandsfähiger gegen zufällige Störungen vergleichbarer Größe. Die Hauptfrage ist daher, ob es böswillige Störungen sind, die die Fragilität von Netzwerken verursachen. Wenn die Bösartigkeit als solche entscheidend von der Kontrolle über jedes Eingabepixel abhängt, scheinen solche böswilligen Beispiele bei der Klassifizierung von Bildern unter realistischen Bedingungen kein ernstes Problem zu sein.
Neuere Studien weisen auf etwas anderes hin: Es ist möglich, die Stabilität von Störungen gegenüber verschiedenen Kanaleffekten in bestimmten physikalischen Szenarien sicherzustellen. Beispielsweise können böswillige Muster auf einem normalen Bürodrucker gedruckt werden, sodass Bilder, die mit der Kamera eines Smartphones aufgenommen wurden,
immer noch nicht korrekt klassifiziert sind . Sie können auch Aufkleber
erstellen , aufgrund derer neuronale Netze verschiedene reale Szenen falsch klassifizieren (siehe z. B.
Link1 ,
Link2 und
Link3 ). Schließlich haben Forscher kürzlich eine 3D-Schildkröte auf einem 3D-Drucker gedruckt, den das Standard-Inception-Netzwerk fälschlicherweise
als Gewehr in nahezu jedem Betrachtungswinkel betrachtet.
Fehlerhafte Vorbereitung des KlassifizierungsangriffsWie kann man solche böswilligen Störungen verursachen? Es gibt viele Ansätze, aber die Optimierung ermöglicht es uns, all diese verschiedenen Methoden auf eine verallgemeinerte Darstellung zu reduzieren. Wie Sie wissen, wird das Klassifizierertraining häufig so formuliert, dass Modellparameter gefunden werden
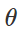
Minimierung der empirischen Verlustfunktion für einen gegebenen Satz von Beispielen

::
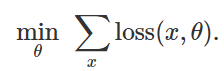
Daher, um eine fehlerhafte Klassifizierung für ein festes Modell zu provozieren
und "harmlose" Eingabe
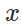
versuchen Sie natürlich, eine begrenzte Störung zu finden

so dass Verluste auf

stellte sich als maximal heraus:
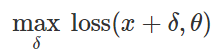
Basierend auf dieser Formulierung können viele Methoden zum Erstellen böswilliger Eingaben als verschiedene Optimierungsalgorithmen (einzelne Gradientenschritte, projizierter Gradientenabstieg usw.) für verschiedene Sätze von Einschränkungen (klein) betrachtet werden
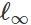
-normale Störung, kleine Pixeländerungen usw.). In den folgenden Artikeln werden einige Beispiele aufgeführt:
Link1 ,
Link2 ,
Link3 ,
Link4 und
Link5 .
Wie oben erläutert, arbeiten viele erfolgreiche Methoden zum Generieren bösartiger Beispiele mit einem festen Zielklassifizierer. Die wichtige Frage ist daher: Beeinflussen diese Störungen nicht nur ein bestimmtes Zielmodell? Interessanterweise nein. Bei Verwendung vieler Störungsmethoden werden die resultierenden schädlichen Stichproben vom Klassifizierer an den Klassifizierer übertragen, der mit einem anderen Satz von anfänglichen Zufallswerten oder unterschiedlichen Modellarchitekturen trainiert wurde. Darüber hinaus können Sie böswillige Beispiele erstellen, die nur eingeschränkten Zugriff auf das Zielmodell haben (in diesem Fall handelt es sich manchmal um „Black-Box-Angriffe“). Siehe zum Beispiel die folgenden fünf Artikel:
Link1 ,
Link2 ,
Link3 ,
Link4 und
Link5 .
Nicht nur BilderSchädliche Proben finden sich nicht nur in der Klassifizierung von Bildern. Ähnliche Phänomene sind bei
der Spracherkennung , in
Frage-Antwort-Systemen , beim
verstärkten Lernen und bei der Lösung anderer Probleme bekannt. Wie Sie bereits wissen, wird die Untersuchung bösartiger Proben seit über zehn Jahren durchgeführt:
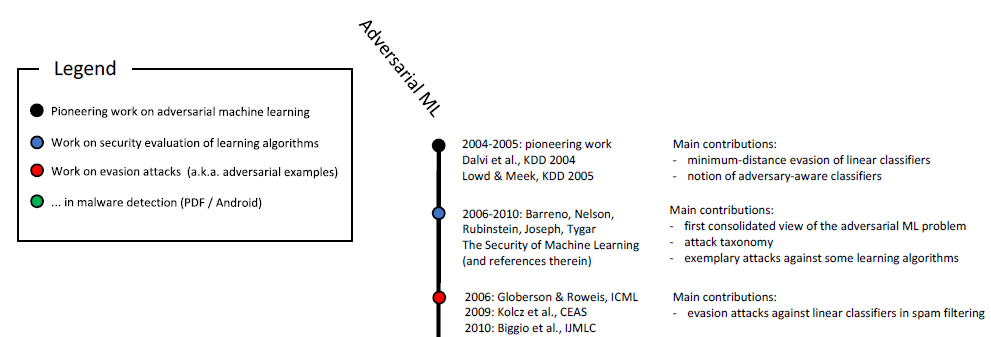
Chronologische Skala des böswilligen maschinellen Lernens (Anfang). Der vollständige Maßstab ist in Abb. 1 dargestellt. 6 in
dieser Studie .
Darüber hinaus sind sicherheitsrelevante Anwendungen ein natürliches Medium, um die böswilligen Aspekte des maschinellen Lernens zu untersuchen. Wenn ein Angreifer den Klassifikator austricksen und böswillige Eingaben (z. B. Spam oder Viren) als harmlos weitergeben kann, ist ein Spam-Detektor oder ein auf maschinellem Lernen basierender Antivirenscanner
unwirksam . Es sollte betont werden, dass diese Überlegungen nicht rein akademisch sind. Beispielsweise veröffentlichte das Google Safebrowsing-Team 2011 eine
mehrjährige Studie darüber, wie Angreifer versuchten, ihre Malware-Erkennungssysteme zu umgehen. Lesen Sie auch diesen
Artikel über böswillige Beispiele im Zusammenhang mit der Spam-Filterung in GMail-E-Mails.
Nicht nur SicherheitDie neuesten Arbeiten zur Untersuchung bösartiger Proben sind im Hinblick auf die Gewährleistung der Sicherheit sehr eindeutig. Dies ist ein vernünftiger Standpunkt, aber wir glauben, dass solche Stichproben in einem breiteren Kontext betrachtet werden sollten.
ZuverlässigkeitZuallererst werfen böswillige Beispiele die Frage nach der Zuverlässigkeit des gesamten Systems auf. Bevor wir die Eigenschaften des Klassifikators unter Sicherheitsgesichtspunkten angemessen diskutieren können, müssen wir sicherstellen, dass der Mechanismus eine hohe Klassifizierungsgenauigkeit bietet. Wenn wir unsere trainierten Modelle in realen Szenarien einsetzen wollen, müssen sie letztendlich ein hohes Maß an Zuverlässigkeit aufweisen, wenn Sie die Verteilung der Basisdaten ändern - unabhängig davon, ob diese Änderungen durch böswillige Interferenzen oder nur durch natürliche Schwankungen verursacht werden.
In diesem Zusammenhang sind Malware-Beispiele ein nützliches Diagnosewerkzeug zur Bewertung der Zuverlässigkeit maschineller Lernsysteme. Insbesondere können Sie mit dem Malware-sensitiven Ansatz über das Standard-Evaluierungsprotokoll hinausgehen, bei dem der trainierte Klassifikator auf einem sorgfältig ausgewählten (und normalerweise statischen) Testsatz ausgeführt wird.
So können Sie zu erstaunlichen Schlussfolgerungen kommen. Es stellt sich beispielsweise heraus, dass man leicht bösartige Beispiele erstellen kann, ohne auf ausgefeilte Optimierungsmethoden zurückgreifen zu müssen. In einem
kürzlich erschienenen Artikel zeigen wir, dass hochmoderne Bildklassifizierer überraschend anfällig für kleine pathologische Übergänge oder Windungen sind. (Weitere Arbeiten zu diesem Thema finden Sie
hier und
hier .)

Selbst wenn wir beispielsweise Störungen durch die discharge∞ℓ∞-Entladung keine Bedeutung beimessen, treten daher häufig Probleme mit der Zuverlässigkeit aufgrund von Rotationen und Übergängen auf. Im weiteren Sinne ist es notwendig, die Zuverlässigkeitsindikatoren unserer Klassifikatoren zu verstehen, bevor sie als wirklich zuverlässige Komponenten in größere Systeme integriert werden können.
Das Konzept der KlassifikatorenUm zu verstehen, wie ein ausgebildeter Klassifikator funktioniert, müssen Sie Beispiele für seine eindeutig erfolgreichen oder erfolglosen Operationen finden. In diesem Fall zeigen böswillige Beispiele, dass trainierte neuronale Netze oft nicht unserem intuitiven Verständnis dessen entsprechen, was es bedeutet, ein bestimmtes Konzept zu „lernen“. Dies ist besonders wichtig beim Deep Learning, wo häufig biologisch plausible Algorithmen und Netzwerke beansprucht werden, deren Erfolg dem menschlichen Erfolg nicht unterlegen ist (siehe zum Beispiel
hier ,
hier oder
hier ). Bösartige Proben lassen dies in vielen Zusammenhängen deutlich bezweifeln:
- Wenn beim Klassifizieren von Bildern der Pixelsatz minimal geändert oder das Bild leicht gedreht wird, wird dies kaum verhindern, dass eine Person es der richtigen Kategorie zuordnet. Trotzdem werden solche Änderungen von den modernsten Klassifikatoren vollständig abgeschnitten. Wenn Sie Objekte an einem ungewöhnlichen Ort platzieren (z. B. Schafe auf einem Baum ), können Sie auch leicht sicherstellen, dass das neuronale Netzwerk die Szene ganz anders interpretiert als ein Mensch.
- Wenn Sie die erforderlichen Wörter in einer Textpassage ersetzen, können Sie das Frage-Antwort-System ernsthaft verwirren, obwohl sich aus Sicht einer Person die Bedeutung des Textes aufgrund solcher Einfügungen nicht ändert.
- In diesem Artikel zeigen sorgfältig ausgewählte Textbeispiele die Grenzen von Google Translate.
In allen drei Fällen helfen böswillige Beispiele dabei, unsere aktuellen Modelle auf Stärke zu testen und hervorzuheben, in welchen Situationen sich diese Modelle völlig anders verhalten als eine Person.
SicherheitSchließlich stellen böswillige Proben eine Gefahr in Bereichen dar, in denen maschinelles Lernen bereits eine gewisse Genauigkeit bei „harmlosem“ Material erreicht. Noch vor wenigen Jahren wurden Aufgaben wie die Bildklassifizierung noch sehr schlecht ausgeführt, sodass das Sicherheitsproblem in diesem Fall zweitrangig schien. Am Ende wird der Sicherheitsgrad eines maschinellen Lernsystems erst dann signifikant, wenn dieses System beginnt, die „harmlosen“ Eingaben mit ausreichender Qualität zu verarbeiten. Ansonsten können wir ihren Prognosen immer noch nicht vertrauen.
In verschiedenen Themenbereichen hat sich die Genauigkeit solcher Klassifizierer erheblich verbessert, und ihr Einsatz in Situationen, in denen Sicherheitsaspekte kritisch sind, ist nur eine Frage der Zeit. Wenn wir dies verantwortungsbewusst angehen wollen, ist es wichtig, ihre Eigenschaften genau im Kontext der Sicherheit zu untersuchen. Das Thema Sicherheit erfordert jedoch einen ganzheitlichen Ansatz. Das Schmieden einiger Features (z. B. einer Reihe von Pixeln) ist viel einfacher als beispielsweise andere sensorische Modalitäten, kategoriale Features oder Metadaten. Letztendlich ist es bei der Gewährleistung der Sicherheit am besten, sich auf genau die Zeichen zu verlassen, die sich nur schwer oder gar nicht ändern lassen.
Ergebnisse (ist es zu früh, um zu scheitern?)Trotz der beeindruckenden Fortschritte beim maschinellen Lernen, die wir in den letzten Jahren gesehen haben, müssen die Grenzen der Fähigkeiten der Werkzeuge, die uns zur Verfügung stehen, berücksichtigt werden. Es gibt eine Vielzahl von Problemen (z. B. im Zusammenhang mit Ehrlichkeits-, Datenschutz- oder Rückkopplungseffekten), und die Zuverlässigkeit ist von größter Bedeutung. Die Wahrnehmung und das Erkennen des Menschen sind gegen eine Vielzahl von Umweltstörungen im Hintergrund resistent. Böswillige Beispiele zeigen jedoch, dass neuronale Netze noch weit von einer vergleichbaren Ausfallsicherheit entfernt sind.
Wir sind uns also sicher, wie wichtig es ist, böswillige Beispiele zu untersuchen. Ihre Anwendbarkeit beim maschinellen Lernen ist keineswegs auf Sicherheitsprobleme beschränkt, sondern kann als
Diagnosestandard für die Bewertung trainierter Modelle dienen. Der Ansatz, bei dem böswillige Stichproben verwendet werden, ist im Vergleich zu Standardbewertungsverfahren und statischen Tests insofern günstig, als er potenziell nicht offensichtliche Fehler identifiziert. Wenn wir die Zuverlässigkeit des modernen maschinellen Lernens verstehen wollen, sind die neuesten Errungenschaften wichtig, um sie aus der Sicht eines Angreifers zu untersuchen (korrekte Auswahl bösartiger Beispiele).
Solange unsere Klassifikatoren auch bei minimalen Änderungen zwischen Training und Testverteilung versagen, können wir keine zufriedenstellende garantierte Zuverlässigkeit erreichen. Letztendlich bemühen wir uns, Modelle zu erstellen, die nicht nur zuverlässig sind, sondern auch unseren intuitiven Vorstellungen darüber entsprechen, was es bedeutet, ein Problem zu „untersuchen“. Dann sind sie sicher, zuverlässig und einfach in einer Vielzahl von Umgebungen einzusetzen.