Hallo allerseits!
Nachdem ich den
ersten Teil geschrieben hatte, der nicht sehr ernst und praktisch nicht besonders nützlich war, verschluckte mich mein Gewissen leicht. Und ich beschloss zu beenden, was ich begonnen hatte. Das heißt, die gleiche Implementierung eines neuronalen Netzwerks für die Ausführung auf Rasperry Pi Zero W in Echtzeit zu wählen (natürlich so viel wie möglich auf einer solchen Hardware). Um sie auf die Daten aus dem wirklichen Leben aufmerksam zu machen und die Ergebnisse auf Habré zu beleuchten.
Achtung Es gibt einen funktionsfähigen Code und ein paar mehr Katzen unter dem Schnitt als im ersten Teil. Auf dem Bild Kinderbett bzw. Kabeljau.
Welches Netzwerk soll ich wählen?
Ich erinnere mich, dass aufgrund der Schwäche des Himbeereisens die Auswahl an Realisierungen des neuronalen Netzwerks gering ist. Nämlich:
1. SqueezeNet.
2. YOLOv3 Tiny.
3. MobileNet.
4. ShuffleNet.
Wie richtig war die Wahl zugunsten von SqueezeNet im
ersten Teil ? .. Jedes der oben genannten neuronalen Netze auf Ihrer Hardware auszuführen, ist ein ziemlich langes Ereignis. Aus vagen Zweifeln gequält, entschied ich mich daher zu googeln, wenn jemand vor mir eine solche Frage gestellt hatte. Es stellte sich heraus, dass er sich wunderte und es im Detail untersuchte. Wer möchte, kann sich auf die
Quelle beziehen. Ich werde mich auf ein einziges Bild beschränken:
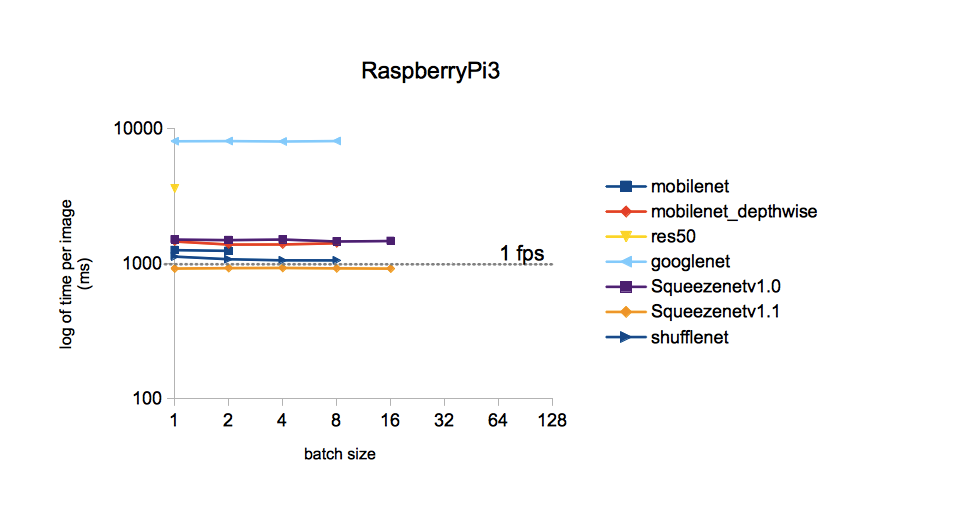
Aus dem Bild folgt, dass die Verarbeitungszeit für ein Bild für verschiedene Modelle, die im ImageNet-Dataset trainiert wurden, mit SqueezeNet v.1.1 am geringsten ist. Wir werden dies als Leitfaden zum Handeln nehmen. YOLOv3 wurde nicht in den Vergleich einbezogen, aber soweit ich mich erinnere, ist YOLO teurer als MobileNet. Das heißt, Die Geschwindigkeit sollte auch der von SqueezeNet unterlegen sein.
Implementierung des ausgewählten Netzwerks
Die Gewichte und Topologie von SqueezeNet, die im ImageNet-Dataset (Caffe-Framework) trainiert wurden, finden Sie auf
GitHub . Nur für den Fall, ich habe beide Versionen heruntergeladen, damit sie später verglichen werden können. Warum ImageNet? Dieser Satz aller verfügbaren hat die maximale Anzahl von Klassen (1000 Stk.), Daher versprechen die Ergebnisse des neuronalen Netzwerks ziemlich interessant zu sein.
Dieses Mal werden wir sehen, wie die Raspberry Zero mit der Bilderkennung von der Kamera umgeht. Hier ist er, unser bescheidener harter Arbeiter des heutigen Postens:

Ich habe den Quellcode aus dem im
ersten Teil erwähnten Adrian Rosebrock-Blog als Grundlage für den Code genommen, nämlich
von hier aus . Aber ich musste es deutlich pflügen:
1. Ersetzen Sie Ihr Modell durch MobileNetSSD in SqueezeNet.
2. Die Implementierung von Klausel 1 hat dazu geführt, dass die Anzahl der Klassen auf 1000 erhöht wurde. Gleichzeitig wurde die Funktion zum Hervorheben von Objekten mit mehrfarbigen Rahmen (SSD-Funktion) leider entfernt.
3. Den Empfang von Argumenten über die Befehlszeile zu entfernen (aus irgendeinem Grund stört mich eine solche Eingabe von Parametern).
4. Entfernen Sie die VideoStream-Methode und damit die von Adrian geliebte Imutils-Bibliothek. Anfänglich wurde das Verfahren verwendet, um den Videostream von der Kamera zu erhalten. Aber mit meiner Kamera, die an die Raspberry Zero angeschlossen ist, hat es dumm nicht funktioniert und so etwas wie "Illegale Anweisung" ausgegeben.
5. Fügen Sie dem erkannten Bild die Bildrate (FPS) hinzu und schreiben Sie die FPS-Berechnung neu.
6. Speichern Sie Frames, um diesen Beitrag zu schreiben.
Auf der Himbeere mit dem Rapbian Stretch OS, Python 3.5.3 und der über pip3 installierten OpenCV 3.4.1-Installation stellte sich Folgendes heraus und startete:
Code hierimport picamera from picamera.array import PiRGBArray import numpy as np import time from time import sleep import datetime as dt import cv2
Ergebnisse
Der Code wird auf dem Bildschirm des mit der Himbeere verbundenen Monitors angezeigt, dem nächsten erkannten Bild in dieser Form. Am oberen Rand des Rahmens wird nur die wahrscheinlichste Klasse angezeigt.

Eine Computermaus wurde also mit sehr hoher Wahrscheinlichkeit als Maus identifiziert. Gleichzeitig werden Bilder mit einer Frequenz von 0,34 FPS (d. H. Ungefähr alle drei Sekunden) aktualisiert. Es ist etwas ärgerlich, die Kamera zu halten und auf die Verarbeitung des nächsten Bilds zu warten, aber Sie können leben. Wenn Sie den Speicherrahmen auf der SD-Karte entfernen, erhöht sich die Verarbeitungsgeschwindigkeit übrigens auf 0,37 ... 0,38 FPS. Sicher gibt es andere Möglichkeiten, sich zu zerstreuen. Wir werden abwarten und sehen, auf jeden Fall werden wir diese Frage für die nächsten Beiträge belassen.
Separat entschuldige ich mich für den Weißabgleich. Tatsache ist, dass die IR-Kamera mit eingeschalteter Hintergrundbeleuchtung mit Rapberry verbunden war, sodass die meisten Bilder ziemlich seltsam aussehen. Aber je wertvoller jeder Treffer des neuronalen Netzes. Offensichtlich war der Weißabgleich auf dem Trainingssatz korrekter. Außerdem habe ich beschlossen, nur die Rohrahmen einzufügen, damit der Leser sie ungefähr so sieht, wie sie das neuronale Netzwerk sehen.
Vergleichen wir zunächst die Arbeit der SqueezeNet-Versionen 1.0 (links) und 1.1 (rechts):

Es ist ersichtlich, dass Version 1.1 zweieinhalb Mal schneller als 1.0 arbeitet (0,34 FPS gegenüber 0,15). Der Geschwindigkeitsgewinn ist spürbar. Es lohnt sich nicht, Rückschlüsse auf die Erkennungsgenauigkeit in diesem Beispiel zu ziehen, da die Genauigkeit stark von der Position der Kamera in Bezug auf das Objekt, Beleuchtung, Blendung, Schatten usw. abhängt.
Angesichts eines solch signifikanten Geschwindigkeitsvorteils v1.1 gegenüber v.1.0 in der Zukunft wurde nur SqueezeNet v.1.1 verwendet. Um die Leistung des Modells zu beurteilen, richtete ich die Kamera auf verschiedene Objekte,
die zur Hand waren, und erhielt am Ausgang die folgenden Bilder:

Eine Tastatur ist schlimmer als eine Maus. Vielleicht waren im Trainingsset die meisten Tastaturen weiß.

Ein Handy ist ziemlich gut definiert, wenn Sie den Bildschirm einschalten. Eine Zelle mit ausgeschaltetem Bildschirm zählt ein neuronales Netzwerk nicht als Zelle.

Eine leere Tasse wird durchaus als Kaffeetasse definiert. Bisher läuft alles ziemlich gut.

Scheren sind schlechter dran, sie werden vom Netz hartnäckig als Haarspange definiert. In den Apfelbaum gelangen, wenn nicht ins Bullauge)
Lassen Sie uns die Aufgabe komplizieren
Versuchen wir, dem neuronalen Netz des
Schweins etwas Kniffliges
aufzuzwingen . Ich bin gerade auf ein hausgemachtes Kinderspielzeug gestoßen. Ich glaube, dass die meisten Leser es als Spielzeugkatze erkennen. Ich frage mich, was unsere rudimentäre künstliche Intelligenz davon halten wird.
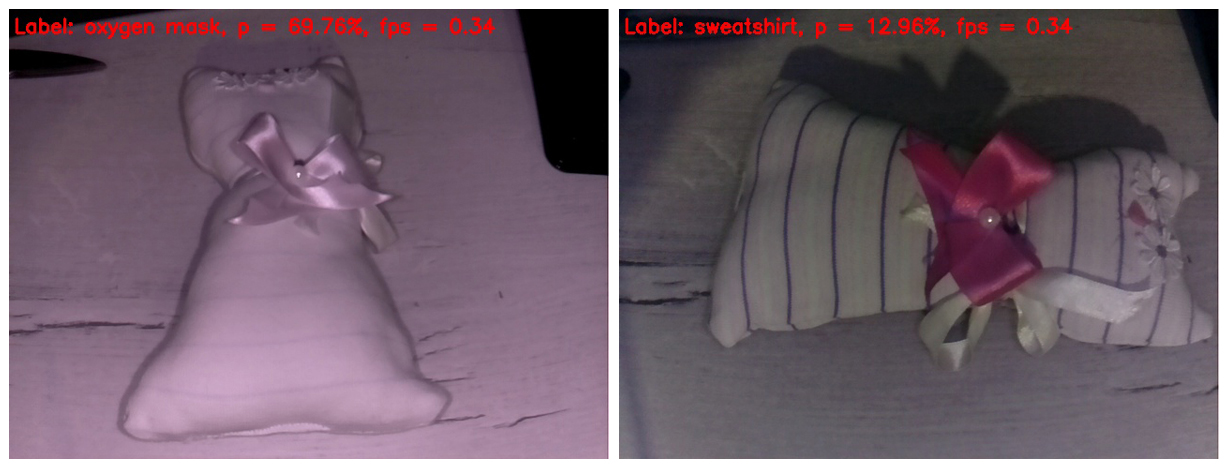
Im Rahmen links löschte das IR-Licht alle Streifen vom Stoff. Infolgedessen wurde das Spielzeug als Sauerstoffmaske mit einer ziemlich guten Wahrscheinlichkeit definiert. Warum nicht? Die Form des Spielzeugs ähnelt wirklich einer Sauerstoffmaske.
Im Rahmen rechts bedeckte ich meine Finger mit einem IR-Highlight, sodass die Streifen auf dem Spielzeug erschienen und der Weißabgleich glaubwürdiger wurde. Tatsächlich ist dies der einzige Frame, der in diesem Beitrag mehr oder weniger normal aussieht. Aber das neuronale Netzwerk hat eine solche Fülle von Details im Bild verwirrt. Sie identifizierte das Spielzeug als Sweatshirt. Ich muss sagen, dass dies auch nicht wie ein "Finger am Himmel" aussieht. Hit wenn nicht im "Apfelbaum", dann zumindest im Apfelgarten).
Nun, wir näherten uns reibungslos dem Höhepunkt unserer Aktion. Der herausragende Sieger der Schlacht, der im
ersten Beitrag ausführlich geweiht wurde
, betritt den Ring. Und es nimmt das Gehirn unseres neuronalen Netzwerks von Anfang an leicht heraus.

Es ist merkwürdig, dass eine Katze ihre Position praktisch nicht ändert, sondern jedes Mal anders bestimmt wird. Und aus dieser Perspektive ist es einem Stinktier am ähnlichsten. An zweiter Stelle steht die Ähnlichkeit mit einem Hamster. Versuchen wir, den Winkel zu ändern.

Ja, wenn Sie die Katze von oben fotografieren, wird sie korrekt bestimmt, aber wenn Sie nur die Position des Katzenkörpers im Rahmen ein wenig ändern, wird sie für das neuronale Netzwerk zu einem Hund - vom Siberian Husky bzw. Malamute (Eskimo-Schlittenhund).

Und diese Auswahl ist insofern schön, als ein Hund verschiedener Rassen auf jedem einzelnen Rahmen einer Katze definiert ist. Und die Rassen wiederholen sich nicht)

Übrigens gibt es Posen, in denen neuronale Netze deutlich werden, dass es sich immer noch um eine Katze handelt, nicht um einen Hund. Das heißt, SqueezeNet v.1.1 hat es immer noch geschafft, sich selbst bei einem solchen Objekt zu beweisen, das schwer zu analysieren ist. Angesichts des Erfolgs des neuronalen Netzwerks bei der Erkennung von Objekten zu Beginn des Tests und der Erkennung einer Katze als Katze am Ende erklären wir diesmal eine solide Auslosung.
Nun, das ist alles. Ich lade alle ein, den vorgeschlagenen Code für ihre Himbeeren und alle Objekte auszuprobieren, die in die Ansicht von lebhaften und leblosen Objekten geraten sind. Besonders dankbar bin ich denen, die die FPS am Rapberry Pi B + messen. Ich verspreche, die Ergebnisse in diesem Beitrag unter Bezugnahme auf die Person aufzunehmen, die die Daten gesendet hat. Ich glaube, dass es deutlich mehr als 1 FPS werden sollte!
Ich hoffe, dass einige der Informationen aus diesem Beitrag für Unterhaltungs- oder Bildungszwecke nützlich sind und jemand vielleicht sogar neue Ideen einbringt.
Ich wünsche Ihnen eine gute Arbeitswoche! Und bis bald)

UPD1: Auf dem Raspberry Pi 3B + arbeitet das obige Skript mit einer Frequenz von 2 mit einer kleinen FPS.
UPD2: Auf RPi 3B + mit Movidius NCS wird das Skript mit 6 FPS ausgeführt.