Hallo% Benutzername%!
Zuletzt endete die Highload ++ - Konferenz (nochmals vielen Dank an das gesamte Team von Organisatoren und
Olegbunin persönlich. Es war sehr cool!).
Am Vorabend der Konferenz schlug Alexey
Fisher vor, auf der Konferenz eine Initiativgruppe von „Stalkern“ einzurichten. Während der Berichte haben wir kleine Notizen geschrieben, die wir ausgetauscht haben. Einige Notizen erwiesen sich als sehr detailliert und detailliert.
Die Community in sozialen Netzwerken hat dieses Format positiv bewertet, daher habe ich (mit Genehmigung) beschlossen, eine Zusammenfassung des ersten Berichts zu veröffentlichen. Wenn dieses Format interessant ist, kann ich mehrere weitere Artikel vorbereiten.

Fuhr
Avito hat viele Dienste und viele Verbindungen zwischen ihnen. Dies verursacht Probleme:
- Viele Repositories. Es ist schwierig, den Code überall gleichzeitig zu ändern
- Teams sind durch ihren Kontext begrenzt. Maximale Überlappung leicht und nicht alle
- Die Fragmentierung von Daten wird hinzugefügt.
Eine Vielzahl von Infrastrukturelementen:
- Protokollierung
- Trace anfordern (Jaeger)
- Fehleraggregation (Sentry)
- Status / Nachrichten / Ereignisse von Kubernetes
- Rennlimit / Leistungsschalter (Hystrix)
- Service-Konnektivität (Istio)
- Überwachung (Grafana)
- Versammlung (Teamcity)
- Kommunikation
- Task-Tracker
- Die Dokumentation
- ...
Es gibt eine Reihe von Ebenen, der Bericht beschreibt nur eine (PaaS).
Die Plattform besteht aus 3 Hauptteilen:
- Generatoren gesteuert von cli
- Aggregator (Kollektor), der über ein Dashboard gesteuert wird
- Speicher mit Triggern für bestimmte Aktionen.
Standard-Microservice-Entwicklungspipeline
CLI-Push -> CI -> Backen -> Bereitstellen -> Testen -> Kanarienvogel -> ProduktionCLI-Push
Lange Zeit gelehrt, die richtigen Entwickler zu machen. Trotzdem blieb es eine Schwachstelle.
Automatisiert durch das Dienstprogramm cli, mit dessen Hilfe eine Basis für den Mikroservice geschaffen werden kann:
- Erstellt einen Vorlagendienst (Vorlagen für eine Reihe von PLs werden unterstützt).
- Stellt automatisch die Infrastruktur für die lokale Entwicklung bereit
- Verbindet eine Datenbank (erfordert keine Konfiguration, der Entwickler denkt nicht über den Zugriff auf eine Datenbank nach).
- Live bauen
- Autotest-Disc-Generierung.
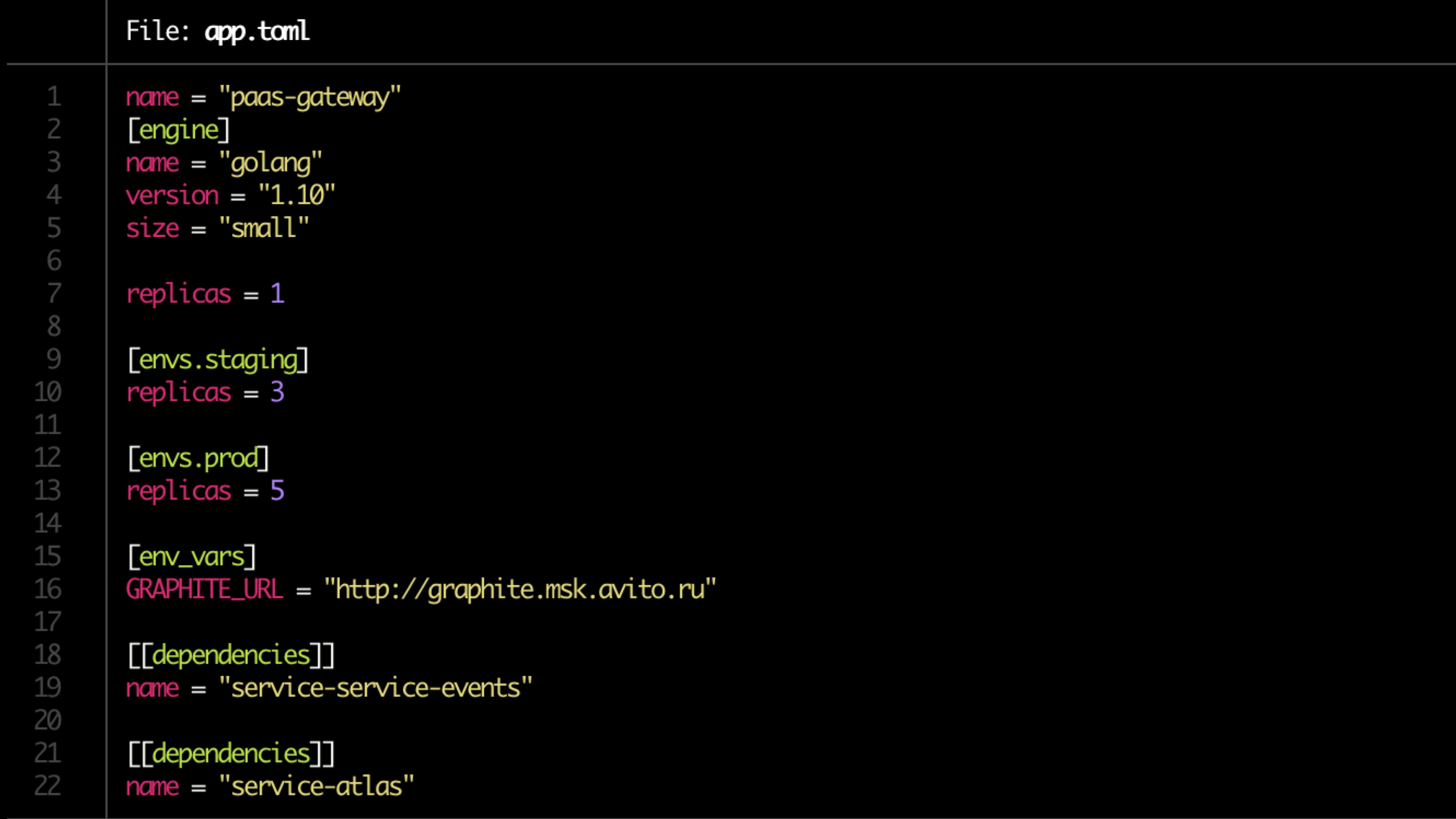
Die Konfiguration ist in der Toml-Datei beschrieben.
Beispieldatei:
Validierung
Grundlegende Validierungsprüfungen:
- Dockerfile-Verfügbarkeit
- app.toml
- Verfügbarkeit der Dokumentation
- Abhängigkeiten
- Warnregeln für die Überwachung (vom Servicebesitzer festgelegt)
Die Dokumentation
Jeder sollte Dokumentation haben, aber fast niemand hat sie
Die Dokumentation sollte Folgendes enthalten:
- Leistungsbeschreibung (kurz)
- Link zum Architekturdiagramm
- Runbook
- FAQ
- Beschreibung der Endpunkt-API
- Etiketten (Bindung an Produkt, Funktionalität, strukturelle Aufteilung)
- Die Eigentümer des Dienstes (es können mehrere vorhanden sein, in den meisten Fällen kann dies automatisch ermittelt werden).
Die Dokumentation muss überprüft werden.
Pipeline-Vorbereitung
- Repositories kochen
- Erstellen einer Pipeline in TeamCity
- Wir setzen die Rechte
- Wir suchen den Besitzer (zwei, einer unzuverlässig)
- Service in Atlas registrieren (internes Produkt)
- Überprüfen Sie die Migration.
Backen
- Erstellen der Anwendung im Docker-Image.
- Generierung von Helmdiagrammen für den Dienst selbst und zugehörige Ressourcen (DB, Cache)
- Es werden Tickets für Administratoren zum Öffnen von Ports erstellt, Speicher- und CPU-Einschränkungen werden berücksichtigt.
- Führen Sie Unit-Tests durch. Die Codeabdeckung wird beibehalten. Wenn unter einem bestimmten Wert, wird die Bereitstellung abgeschlossen. Wenn die Abdeckung nicht fortschreitet, werden Benachrichtigungen gesendet.
Die Besitzersuche wird durch den Push bestimmt (die Anzahl der Pushs und die Menge des darin enthaltenen Codes).
Bei potenziell gefährlichen Migrationen (alter) wird der Trigger im Atlas registriert und der Dienst unter Quarantäne gestellt.
Die Quarantäne wird durch Push an die Eigentümer gelöst (im manuellen Modus?)
Convention Check
Wir prüfen:
- Service-Endpunkt
- Übereinstimmende Antworten
- Protokollformat
- Festlegen von Headern (einschließlich X-Source-ID beim Senden von Nachrichten an den Bus, um die Konnektivität über den Bus zu verfolgen)
Tests
Das Testen wird in einem geschlossenen Regelkreis (z. B. hoverfly.io) durchgeführt - eine typische Last wird aufgezeichnet. Dann wird es in einer geschlossenen Schleife emuliert.
Die Entsprechung des Ressourcenverbrauchs wird überprüft (wir betrachten Extremfälle separat - zu wenige / viele Ressourcen) und durch RPS abgeschnitten.
Lasttests zeigen auch ein Leistungsdelta zwischen den Versionen.
Kanarische Tests
Wir starten den Start bei einer sehr kleinen Anzahl von Benutzern (<0,1%).
Mindestlast 5 Minuten. Die Haupt 2 Stunden. Dann erhöht sich die Anzahl der Benutzer, wenn alles in Ordnung ist.
Wir schauen:
- Produktmetriken (zuallererst) - es gibt viele davon (100500)
- Wachfehler
- Antwortstatus,
- Zeit der Befragten - genaue und durchschnittliche Antwortzeit
- Latenz
- Ausnahmen (verarbeitet und unverarbeitet)
- Spezifischer für die metrische Sprache (z. B. PHP-Fpm-Mitarbeiter)
Quetschtest
Extrusionstests.
Wir laden echte Benutzer 1 Instanz bis zum Fehler. Wir schauen an die Decke. Fügen Sie als Nächstes eine weitere Instanz hinzu und laden Sie sie. Wir schauen auf die nächste Decke. Wir betrachten die Regression. Wir bereichern oder ersetzen Daten aus Lasttests in Atlas.
Skalieren
Nur die CPU ist schlecht, Sie müssen Produktmetriken hinzufügen.
Das endgültige Schema:
- CPU + RAM
- Anzahl der Anfragen
- Reaktionszeit
- Historische Prognose
Vergessen Sie beim Skalieren nicht, die Dienstabhängigkeiten zu berücksichtigen. Denken Sie an die Skalierungskaskade (+1 Stufe). Wir betrachten die historischen Daten des Initialisierungsdienstes.
Optional
- Trigger-Behandlung - Migrationen, wenn keine Version unter X mehr vorhanden ist
- Der Service wurde schon lange nicht mehr aktualisiert
- Quarantäne
- Sichere Updates
Dashboard
Wir betrachten alles von oben in aggregierter Form und ziehen Schlussfolgerungen.
- Service- und Etikettenfilterung
- Integration mit Trace, Protokollierung, Überwachung
- Single Point Service-Dokumentation
- Ein einziger Anzeigepunkt aller Serviceereignisse
Ein Beispiel:
