Vladimir Ivanov vivanov879 , Sr. Der Deep Learning Engineer von NVIDIA spricht weiterhin über das verstärkte Lernen. In diesem Artikel wird die Schulung eines Agenten zum Abschließen von Quests und die Verwendung von Filtern zur Erkennung von Bildern durch neuronale Netze erläutert.
In einem
früheren Artikel wurde das Agententraining für einfache Schützen erörtert.
Vladimir wird auf der
KI-Konferenz am 22. November über die Anwendung von verstärktem Lernen in der Praxis sprechen.
Das letzte Mal haben wir uns Beispiele für Videospiele angesehen, bei denen das Verstärkungstraining zur Lösung des Problems beiträgt. Seltsamerweise wurden für das erfolgreiche Spielen des neuronalen Netzwerks nur visuelle Informationen benötigt. Jedes neuronale Netzwerk des vierten Frames analysiert den Screenshot und trifft eine Entscheidung.
Auf den ersten Blick sieht es nach Magie aus. Eine bestimmte komplexe Struktur, bei der es sich um ein neuronales Netzwerk handelt, erhält am Eingang ein Bild und gibt die richtige Lösung aus. Lassen Sie uns herausfinden, was im Inneren passiert: Was macht eine Reihe von Pixeln in Aktion?
Bevor wir zum Computer übergehen, wollen wir herausfinden, was eine Person sieht.Wenn eine Person ein Bild betrachtet, klammert sich ihr Blick an kleine Details (Gesichter, Figuren von Menschen, Bäume) und an das Bild als Ganzes. Ob es sich um ein Kinderspiel in der Gasse oder ein Fußballspiel handelt, eine Person kann den Inhalt, die Stimmung und den Kontext des Bildes anhand ihrer Lebenserfahrung verstehen.

Wenn wir die Arbeit eines Meisters in einer Kunstgalerie bewundern, sagt uns unsere Lebenserfahrung immer noch, dass Charaktere hinter Farbschichten versteckt sind. Sie können ihre Absichten und Bewegungen im Bild erraten.

Bei der abstrakten Malerei findet das Auge einfache Figuren im Bild: Kreise, Dreiecke, Quadrate. Sie sind viel leichter zu finden. Manchmal ist das alles, was man sehen kann.

Elemente können so angeordnet werden, dass das Bild einen unerwarteten Farbton annimmt.

Das heißt, wir können das Bild als Ganzes wahrnehmen und von seinen spezifischen Komponenten abstrahieren. Im Gegensatz zu uns verfügt ein Computer zunächst nicht über diese Funktion. Wir haben eine Fülle von Lebenserfahrungen, die uns sagen, welche Gegenstände wichtig sind und welche physikalischen Eigenschaften sie haben. Lassen Sie uns darüber nachdenken, wie Sie die Maschine mit einem Werkzeug ausstatten können, damit sie Bilder studieren kann.
Viele glückliche Besitzer von Telefonen mit hochwertigen Kameras, bevor sie ein Foto von einem Telefon in einem sozialen Netzwerk veröffentlichen, legen verschiedene Filter fest. Mit dem Filter können Sie die Stimmung des Fotos ändern. Sie können einige Objekte deutlicher hervorheben.
Darüber hinaus kann der Filter die Kanten von Objekten im Foto hervorheben.
Da Filter diese Fähigkeit haben, verschiedene Objekte in einem Bild hervorzuheben, geben wir dem Computer die Möglichkeit, sie aufzunehmen. Was ist ein digitales Bild? Dies ist eine quadratische Zahlenmatrix, an deren jedem Punkt Intensitätswerte für drei Farbkanäle vorhanden sind: Rot, Grün und Blau. Jetzt geben wir dem neuronalen Netzwerk zum Beispiel 32 Filter. Jeder Filter überlagert seinerseits das Bild. Der Filterkern wird auf benachbarte Pixel angewendet.
Anfänglich sind die Kernwerte jedes Filters zufällig. Wir geben neuronalen Netzen jedoch die Möglichkeit, sie je nach Aufgabe zu konfigurieren. Nach der ersten Schicht mit Filtern können wir noch ein paar setzen. Da wir viele Filter erhalten, benötigen wir viele Daten, um sie einzurichten. Hierfür eignet sich eine große Anzahl von markierten Bildern. Zum Beispiel MSCoco-Dataset.

Das neuronale Netzwerk passt die Gewichte an, um dieses Problem zu lösen. In unserem Fall für die Bildsegmentierung, dh die Definition der Klasse jedes Bildpixels. Nun wollen wir sehen, wie die Bilder nach jeder Filterebene aussehen.
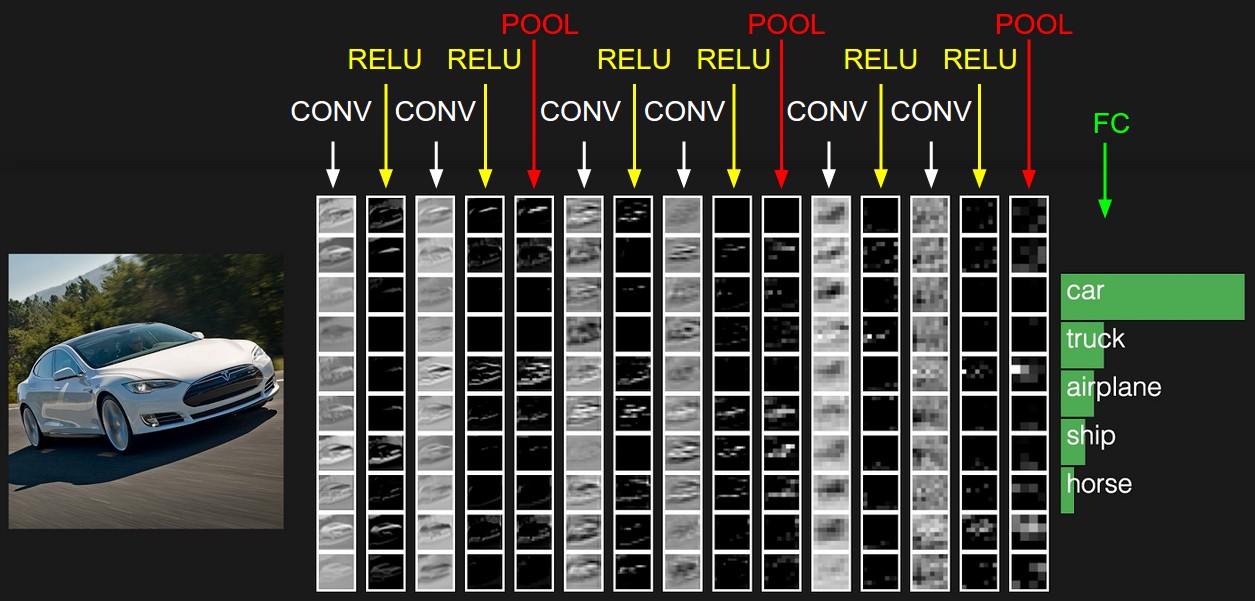
Wenn Sie genau hinschauen, werden Sie feststellen, dass die Filter bis zu dem einen oder anderen Grad das Auto verlassen und die Umgebung reinigen - die Straße, die Bäume und den Himmel.
Zurück zu dem Agenten, der lernt, Spiele zu spielen. Nehmen Sie zum Beispiel das Mario Kart-Rennspiel.
Wir haben ihm ein leistungsstarkes Bildanalysewerkzeug gegeben - ein neuronales Netzwerk. Mal sehen, welche Filter er wählt, um das Fahren zu lernen. Nehmen wir für den Anfang einen offenen Bereich.
Mal sehen, wie das Bild nach den ersten 24 Filmen aussieht. Hier befinden sie sich in Form einer 8x3-Tabelle.
Es ist völlig optional, dass jeder der 24 Ausgänge eine offensichtliche Bedeutung hatte, da die Bilder mit den folgenden Filtern weiter zum Eingang gehen. Abhängigkeiten können völlig unterschiedlich sein. In diesem Fall finden Sie jedoch eine Logik in den Ausgängen. Beispielsweise hebt der zweite Filter in der ersten Zeile die Straße schwarz hervor. Der erste Filter der siebten Zeile dupliziert seine Funktion. Bei den meisten anderen Filtern sind die von uns gesteuerten Karten deutlich sichtbar.
In diesem Spiel ändert sich die Umgebung und ein Tunnel trifft sich. Worauf achtet ein neuronales Rennnetz, wenn es auf einen Eingang zu einem Tunnel stößt?
Die Ausgaben der ersten Filterschicht:
In der sechsten Zeile hebt der erste Filter den Eingang zum Tunnel hervor. Während der Fahrt lernte das Netzwerk, sie zu identifizieren.
Und was passiert, wenn die Maschine den Tunnel betritt?
Das Ergebnis der ersten 24 Filter:
Trotz der Tatsache, dass sich die Beleuchtung der Szene sowie die Umgebung geändert haben, erfasst das neuronale Netzwerk das Wichtigste - die Straße und die Karten. Auch hier behält der zweite Filter in der ersten Zeile, der für das Auffinden des Pfades im Freien verantwortlich war, im Tunnel seine Funktionen bei. Und auf die gleiche Weise findet der erste Filter der siebten Zeile wie zuvor den Weg.
Nachdem wir herausgefunden haben, was das neuronale Netzwerk sieht, versuchen wir, damit komplexere Probleme zu lösen. Zuvor haben wir Aufgaben in Betracht gezogen, bei denen Sie praktisch nicht vorausdenken müssen, sondern das Problem lösen müssen, mit dem wir gerade konfrontiert sind. Bei Schießspielen und Rennen müssen Sie „reflexiv“ handeln und schnell auf plötzliche Änderungen im Spiel reagieren. Was ist mit dem Abschluss des Questspiels? Zum Beispiel das Spiel Montezuma Revenge, in dem Sie die Schlüssel finden und die verschlossenen Türen öffnen müssen, um aus der Pyramide herauszukommen.

Beim letzten Mal haben wir besprochen, dass der Agent nicht lernen wird, nach neuen Schlüsseln und Türen zu suchen, da diese Aktionen viel Spielzeit in Anspruch nehmen und daher das Signal in Form von erhaltenen Punkten sehr selten sein wird. Wenn Sie Punkte für geschlagene Feinde als Belohnung für den Agenten verwenden, schlägt er ständig rollende Schädel aus und sucht nicht nach neuen Zügen.
Belohnen wir den Agenten für die Eröffnung neuer Räume. Wir werden die a priori bekannte Tatsache verwenden, dass dies eine Suche ist und alle Räume darin unterschiedlich sind.

Wenn sich das Bild auf dem Bildschirm grundlegend von dem unterscheidet, was wir zuvor gesehen haben, erhält der Agent eine Belohnung.
Zuvor haben wir Spielagenten in Betracht gezogen, die sich während des Trainings ausschließlich auf visuelle Daten stützen. Wenn wir jedoch Zugriff auf andere Daten aus dem Spiel haben, werden wir diese auch verwenden. Betrachten Sie zum Beispiel Dots Spiel. Hier erhält das Netzwerk am Eingang zwanzigtausend Nummern, die den Stand des Spiels vollständig beschreiben. Zum Beispiel die Position der Verbündeten, die Gesundheit der Türme.

Die Spieler sind in zwei Teams mit jeweils fünf Personen aufgeteilt. Ein Spiel dauert durchschnittlich 40 Minuten. Jeder Spieler wählt einen Helden mit einzigartigen Fähigkeiten aus. Und jeder Spieler kann Gegenstände kaufen, die die Parameter Schaden, Geschwindigkeit und Sichtfeld ändern.
Trotz der Tatsache, dass sich das Spiel auf den ersten Blick erheblich von Doom unterscheidet, bleibt der Lernprozess derselbe. Bis auf ein paar Punkte. Da der Planungshorizont in diesem Spiel höher ist als in Doom, werden wir die letzten 16 Frames verarbeiten, um Entscheidungen zu treffen. Und das Signal der Belohnungen, das der Agent erhält, wird etwas komplizierter sein. Es enthält die Anzahl der besiegten Gegner, den zugefügten Schaden sowie das im Spiel verdiente Geld. Damit die neuronalen Netze zusammenspielen können, werden wir das Wohl der Mitglieder des Agententeams als Belohnung einbeziehen.
Infolgedessen
besiegt das Team der Bots ziemlich starke Teams, verliert jedoch gegen die Champions. Der Grund für die Niederlage ist, dass Bots selten eine Stunde lang Matches spielten. Und Spiele mit echten Menschen dauerten länger als solche, die auf Simulatoren gespielt wurden. Das heißt, wenn sich ein Agent in einer Situation befindet, für die er nicht ausgebildet wurde, treten in ihm Schwierigkeiten auf.