Ich möchte über unsere Erfahrungen bei der Entwicklung von Anwendungen sprechen, die auf der Apache Solr-Volltextsuchplattform basieren.
Unsere Aufgabe war es, ein Sprachanalysesystem für Contact Center zu entwickeln. Das System basiert auf zwei grundlegenden Technologien: Spracherkennung und indizierte Suche. Zur Erkennung haben wir unsere Engines verwendet und für die Indizierung und Suche haben wir Solr gewählt.
Warum Solr? Wir haben keine eigenen vergleichenden Untersuchungen zu indizierten Suchmaschinen durchgeführt, sondern die
Meinungen unserer Kollegen sorgfältig geprüft. Natürlich könnte die Wahl zugunsten von Elasticsearch oder Sphinx getroffen werden, aber anscheinend haben sich die Sterne in unserem Projekt zugunsten von Solr gebildet, wir haben es „gesägt“. Bereits im Verlauf des Projekts haben wir festgestellt, dass die in Solr verfügbaren Einstellungen ausreichen, um für unsere Aufgaben konfiguriert zu werden.
Merkmale unseres Projekts
Das System wurde für die Analyse von Kundenanrufen entwickelt, die im Contact Center aufgezeichnet werden, um die Servicequalität zu überwachen. Es wird nicht der Ton analysiert, sondern der Text, der durch die automatische Erkennung des Dialogs erhalten wird. Die Texte der anerkannten Sprache unterscheiden sich grundlegend von den Texten, die wir regelmäßig auf Websites oder per E-Mail finden. Selbst bei einer Erkennungsgenauigkeit von 100% scheinen die Texte der erkannten spontanen Sprache keine Bedeutung zu haben.
Dies ist auf zwei Hauptfaktoren zurückzuführen. Erstens werden in der mündlichen Rede sehr häufig nonverbale und Mimik verwendet, die im Text nicht erkannt werden, aber wichtig sind, um das Gesagte zu verstehen. Zweitens werden in der Sprache ständig Abkürzungen und Auslassungen von Sprachstrukturen verwendet, die aus dem Kontext einer Kommunikationssituation wiederhergestellt werden können. Dieses Phänomen in der Linguistik wird als Ellipse bezeichnet.
Um den Text der erkannten Sprache mit all ihren Funktionen mit eigenen Augen zu sehen, schauen Sie sich die automatischen Untertitel für das Video auf Youtube mit ausgeschaltetem Ton an. Das ist ungefähr dieser Inhalt, das Material geht an die Eingabe des Sprachanalysesystems.
Komplizierte Abfragen
Obwohl Solr standardmäßige
bedingte Anweisungen und
Gruppierungen unterstützt , reichen diese Funktionen häufig nicht aus, um alle Szenarien für Analysten zu implementieren.
Häufig muss der Analyst eine Abfrage mit Parametern erstellen, die nicht im Solr-Index enthalten sind. Suchen Sie beispielsweise alle Wörter „Danke“, die in den letzten 30 Sekunden des Gesprächs gesprochen wurden. Wörter werden von Solr indiziert, aber keine temporären Wortpositionen. Wir nennen solche Abfragen „komplex“ - Abfragen, die die Parameter des Solr-Index und alle anderen Datenauswahlparameter enthalten, die nicht im Solr-Index enthalten sind.
Wie formuliert ein Analyst Abfragen?
Der Analyst hat keine Ahnung von der Zusammensetzung des Solr-Index. Es ist wichtig, dass er alle Attribute von Phonogrammen von Anrufen und deren Textabschriften sucht und durchschneidet. Daher ist das Konzept der „komplexen Abfrage“ für den Analysten rein pragmatisch: Abfragen, in denen viele Auswahlparameter vorhanden sind, oder Abfragen sind in einer Hierarchie angeordnet.
Wenn wir die Handlungen des Analytikers in der Sprache der Mengenlehre beschreiben, können wir sagen, dass der Analytiker mit Hilfe von Abfragen die Beziehungen zwischen verschiedenen Teilmengen untersucht: Schnittpunkte, Unterschiede, Additionen. Mithilfe hierarchischer Abfragen analysiert der Analyst das Datenarray auf den erforderlichen Detaillierungsgrad seiner Struktur.
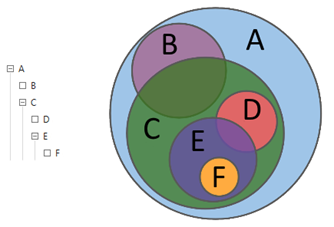 Abbildung 1. Hierarchische Abfragen
Abbildung 1. Hierarchische AbfragenAbbildung 2 zeigt ein klassisches Beispiel einer komplexen Abfrage, die sowohl textuelle als auch numerische Auswahlkriterien enthält.
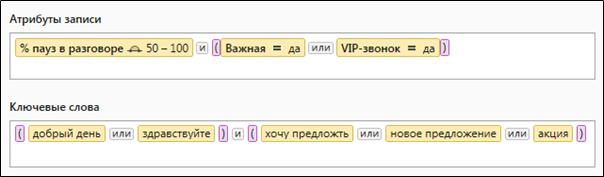 Abbildung 2. Eine komplexe Abfrage mit quantitativen und lexikalischen Datenauswahlparametern
Abbildung 2. Eine komplexe Abfrage mit quantitativen und lexikalischen DatenauswahlparameternWie sehen Abfragen für Solr aus?
Betrachten Sie den allgemeinen Mechanismus zum Ausführen einer Abfrage in Solr am Beispiel von Abfrage
B in Abbildung 1. Wie wir sehen können, hat Abfrage
B eine übergeordnete Abfrage
A , mit anderen Worten
B⊆A . In der Sprachanalyse kann eine Anfrage nicht erfüllt werden, solange mindestens einer ihrer „Eltern“ nicht erfüllt ist. Somit wird die Abfrage
A zuerst und erst dann
B ausgeführt. Offensichtlich muss
B die Bedingungen der Abfrage
A enthalten.Das erste, was mir in den Sinn kommt, ist, die Bedingungen beider Abfragen durch
AND zu kombinieren und in die
query :
q=key:A AND key:BWenn wir jedoch einfach alle aufeinander folgenden Abfragen zu einer
query kombinieren, ist sie groß, für jede Abfrage unterschiedlich und wird vollständig berechnet. Die Bedingungen
A beeinflussen auch die Relevanz der Ergebnisse der Abfrage
B , was nicht wünschenswert wäre.
Versuchen wir, übergeordnete Abfragen als
FilterQuery . In diesem Fall ist Abfrage
A nicht von Nichtrelevanz betroffen, und wir können davon ausgehen, dass sie bereits abgeschlossen wurde und sich die Ergebnisse im Cache befinden. Daher muss Solr nur die Abfrage
B berechnen, während Solr die resultierende Auswahl wie folgt sortiert:
q=keyword:B &fq=keyword:AWenn wir das Format der Anfrage an Solr schematisch betrachten, können wir zwei Hauptentitäten unterscheiden:
MainQuery - Die Hauptabfrage mit einer Reihe von Parametern, die das Dokument erfüllen muss. Eine Suchanfrage für höfliche Operatoren würde beispielsweise folgendermaßen aussehen: text_operator: ” ” .
Dies bedeutet, dass das Feld text_operator des Suchdokuments den Ausdruck “ ” enthalten muss.
FilterQuery - Eine Reihe zusätzlicher Filter, die die resultierende Auswahl einschränken. FilterQuery Format entspricht MainQuery
Durch Aufteilen der Anforderung in
Main und
Filter können Sie:
- Geben Sie explizit an, welche Abfrageparameter den Rang des Dokuments in der Auswahl beeinflussen sollen und welche nur zur Auswahl in der resultierenden Auswahl dienen. Die Relevanz für die Erstellung des Dokumentrangs wird berechnet, wenn der Teil der MainQuery-Abfrage ausgeführt wird und wenn der Teil der
FilterQuery Abfrage FilterQuery Dokumente, die die FilterQuery nicht erfüllen - Reduzieren Sie die Belastung der Suchmaschine erheblich, da das nach
FilterQuery Berechnungen erhaltene Ergebnis vollständig zwischengespeichert wird, während die Ergebnisse der MainQuery Berechnung nur für die ersten im Rang von 50 Werten im Cache gespeichert werden
MainQuery und
FiletrQuery haben unterschiedliche Auswirkungen auf die Solr-Funktionen. Zum
Hervorheben der Funktion, die für das Hervorheben relevanter Dokumentfragmente verantwortlich ist, ist beispielsweise nur
MainQuery , und
FilterQuery Parameter wirken
FilterQuery nicht auf das
highlighting . Dies ist logisch, da die Relevanz genau im Teil der
MainQuery Abfrage
MainQuery . So sehen
highlighting bei einer echten Suche nach Texten mit den Wörtern „Hallo“ und „Dienste“ aus.
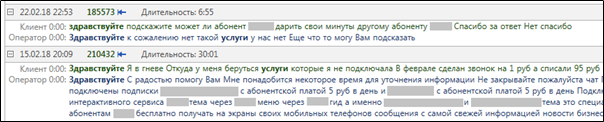 Abbildung 3. Hervorheben relevanter Wörter nach Abschluss einer
Abbildung 3. Hervorheben relevanter Wörter nach Abschluss einer MainQuery Abfrage.
Komplizierte Abfragen in Solr
Kehren wir zum Beispiel eines höflichen Operators zurück. In diesem Beispiel haben wir die entsprechenden Anrufe anhand des Ausdrucks "Guten Tag" in der Rede des Bedieners ermittelt, jedoch nicht das Zeitintervall angegeben, in dem nach Schlüsselwörtern für den Beginn oder das Ende des Gesprächs gesucht werden soll.
Hierfür scheint alles Notwendige vorhanden zu sein - das Textprotokoll des Telefongesprächs enthält den Zeitstempel für jedes Wort sowie Informationen darüber, zu welchen Teilnehmern des Dialogs es gehört. Diese Daten können auch bei der Suche verwendet werden.
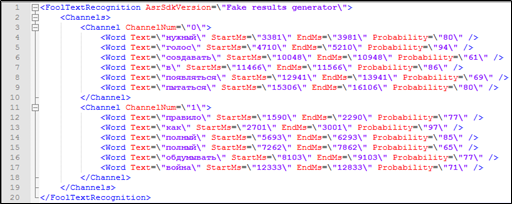 Abbildung 4. Ein Fragment der Textentschlüsselung mit Markup, das nicht im Solr-Index enthalten ist: Zugehörigkeit des Sprechers, Zeitstempel.
Abbildung 4. Ein Fragment der Textentschlüsselung mit Markup, das nicht im Solr-Index enthalten ist: Zugehörigkeit des Sprechers, Zeitstempel.Aber wie verarbeitet man eine Suchabfrage an Solr, wenn nicht indizierbare Parameter an der Abfrage beteiligt sind - die Zeit, zu der das Wort ausgesprochen wird?
Es gibt zwei offensichtliche Möglichkeiten, dieses Problem zu lösen:
- Fügen Sie dem Solr-Index nicht indizierte Parameter hinzu. Gleichzeitig wird der Speicherverbrauch leicht ansteigen, der Index wird jedoch erheblich höher sein
- Die Auswahl der Daten nach nicht indizierbaren Parametern sollte über ihren Dienst erfolgen. Bei der Sammlung von Dokumenten, die nach einer solchen Auswahl erhalten wurden, sollte nach dem Solr-Index gesucht werden. Gleichzeitig ist der Speicherverbrauch erheblich höher als im ersten Fall, die Leistung ist jedoch vorhersehbar
Wir haben die zweite Option gewählt. Zu diesem Zweck haben wir einen Dienst entwickelt, der Sammlungen anhand von Anforderungen berechnet, die logische und numerische Parameter enthalten, die nicht im Solr-Index enthalten sind. Aufgrund der Arbeit dieses Dienstes wurde der Teil der Sammlung, der die Anforderung nicht erfüllte, mit einem speziellen Tag markiert ("Escape") und nahm dann nicht an der Berechnung der Abfrageergebnisse teil.
Stellen Sie sich vor, wir möchten der Suche
B , die wir bereits kennen, nur in den ersten 30 Sekunden des Dialogfelds eine Einschränkung für die Suche auferlegen. In der ersten Phase führen wir
B als einfache Abfrage aus und „screenen“ dann die Wörter, die über den ausgewählten Bereich hinausgehen, damit sie nicht in den Solr-Index fallen, aber gleichzeitig können wir das Originaldokument aus ihnen wiederherstellen. Die resultierenden Dokumente werden in einer separaten Solr-Sammlung abgelegt und die Suche nach Abfrage
B wird darauf neu gestartet.
Hier muss ich sagen, dass die Einschränkungen zu Beginn oder am Ende des Gesprächs Blumen sind, Beeren Einschränkungen für die Ergebnisse der Elternanfrage. Betrachten Sie die Ausführung einer solchen Anfrage.
Stellen Sie sich vor, unsere Dokumente bestehen aus Bällen mit Zahlen. Versuchen wir, alle Bälle „6“ in nicht mehr als zwei Bällen rechts von „5“ zu finden.
Sie haben bereits festgestellt, dass die Ballnummern im Solr-Index enthalten sind und zwischen den Bällen kein Abstand besteht.
|  |
Finden Sie alle Dokumente mit den Bällen "6" und "5". Als MainQuery eine Abfrage für die Bälle "5" und eine Abfrage für "6", die wir an FilterQuery senden. Infolgedessen wird Solr die „5“ Bälle in den Suchergebnissen hervorheben, was unser Leben im nächsten Schritt erheblich vereinfachen wird. | 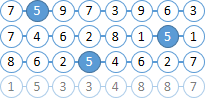 |
| Wir überprüfen alle Bälle mit Ausnahme derjenigen, die sich im gewünschten Abstand von „5“ befinden. Die erhaltenen Dokumente (Dokumente mit den gewünschten Bällen) werden in einer separaten Sammlung abgelegt. |  |
Lassen Sie uns FilterQuery für die Bälle „6“ in der resultierenden Sammlung ausführen. FilterQuery Ergebnis sind die Dokumente, nach denen wir FilterQuery . |  |
In der Praxis verbergen die Bälle 5 und 6 normalerweise Abfragen, die in ihrer Textdarstellung mehrere Bildschirme belegen. Ich bin froh, dass wir diese Suche nicht umsonst implementiert haben - Analysten verwenden sehr oft Abfragen mit Einschränkungen des übergeordneten Elements.
Fazit
Was haben wir gelernt, was haben wir gelernt und was haben wir als Ergebnis des Projekts erreicht?
Wir wissen, wie man Solr effektiv verwendet, um mit Daten verschiedener Typen zu arbeiten. Wir können Solr „beibringen“, Abfragen mit Parametern zu verarbeiten, die nicht in seinem Suchindex enthalten sind.
Wir haben ein industrielles Sprachanalysesystem entwickelt, das unter hoher Last arbeitet: Komplexe Suchanfragen von Analysten werden für Stichproben von bis zu fünf Millionen Textdokumenten berechnet. Es ist möglich und mehr, aber es gab keinen praktischen Bedarf. Die übliche Stichprobe des Analysten besteht aus bis zu 500.000 Texten erkannter Telefonanrufe, und die Gesamtzahl der Anrufe kann 15 Millionen erreichen.
Für unsere Kunden in Contact Centern bietet das System beispiellose Möglichkeiten für Analysen ganz anderer Art: Analyse von Themen und Gründen für Anfragen, Analyse der Kundenzufriedenheit und viele andere.
Jetzt verbinden wir neue Quellen mit unseren Analysen - Text-Chats von Kunden mit Betreibern. Wir implementieren eine einzige Anwendung zur Analyse von Kundenanrufen über alle Kanäle des Contact Centers: Telefon, Chat, Formulare auf Websites usw.
Gerne beantworten wir Ihre Fragen.
Vielen Dank.
PS Solr ist eine sehr schwierige Sache und erfordert eine gute Abstimmung, um gute Ergebnisse zu erzielen. Wir werden in den folgenden Artikeln über unsere Erfahrungen auf diesem Gebiet berichten.