Wir haben Ihnen bereits interessante
Statistiken von Texten erzählt,
Artikel über die Verwendung von Autocodern bei der Analyse von Texten überprüft und uns mit unseren neuen Suchalgorithmen
für übertragbare Anleihen und
Paraphrasen überrascht. Ich beschloss, unsere Unternehmenstradition fortzusetzen und erstens den Artikel mit „T“ zu beginnen und zweitens zu erzählen:
- wie man schnell einen Textabschnitt unter Hunderten von Millionen von Artikeln findet;
- Was wird aus dem Dokument nach dem Laden in das Anti-Plagiat-System und was ist als Nächstes zu tun?
- wie ein Bericht entsteht, den fast niemand betrachtet, der sich aber lohnt;
- wie man nicht alle indiziert, aber genug.

Wie alles begann
2005 kam der Rektor einer der größten Moskauer Universitäten zu
Forecsys , um ein sehr ernstes Problem zu lösen. In Bildungseinrichtungen haben die Studenten vollständig abgeschriebene Diplome und Hausarbeiten bestanden. Wir haben mehrere hundert Werke exzellenter Studenten genommen und sie mit einfachen Fragen im Netzwerk gesucht. Mehr als die Hälfte der
„hervorragenden Studenten“ waren Betrüger, die ein Diplom aus dem Internet heruntergeladen und nur die Titelseite ersetzt hatten. Mehr als die Hälfte der hervorragenden Schüler, Karl! Was mit gewöhnlichen Schülern passiert ist, ist schwer vorstellbar. Der einfachste Weg, nach einem Job zu suchen, ist eine Abfrage, die Wörter mit "Schwarzen Löchern" enthält. Wir sind uns des Ausmaßes der Katastrophe bewusst geworden. Es war dringend notwendig, etwas zu lösen. Zu diesem Zeitpunkt verwendeten ausländische englischsprachige Universitäten bereits Ausleihsuchlösungen, aber aus irgendeinem Grund überprüfte niemand die Arbeit auf Russisch.
Ausländische Spieler wollten ihre Lösungen damals nicht an die russische Sprache anpassen. Infolgedessen begann am 17. März 2005 die Entwicklung des ersten inländischen Systems zur Suche nach Krediten. Das Wort „Anti-Plagiat“ wurde etwas später geprägt und die Domain antiplagiat.ru wurde am 28. April 2005 registriert. Wir hatten vor, die Site bis zum 1. September 2005 zu veröffentlichen, hatten aber, wie es bei Programmierern häufig der Fall ist, keine Zeit. Der offizielle Geburtstag unseres Unternehmens ist der Tag, an dem antiplagiat.ru die ersten Benutzer erhielt, nämlich der 4. September. Weißt du, ich bin sogar froh darüber, denn während der Firmenfeier anlässlich des Geburtstages des Unternehmens kann jeder ruhig feiern und sich keine Sorgen um den ersten Schultag seiner Kinder machen.
Aber etwas, das mich abgelenkt hat. Im Jahr 2005 haben wir eine Art Suchmaschine erstellt, bei der die Abfrage im Gegensatz zu Yandex und Google nicht aus zwei oder drei Wörtern besteht, sondern aus einem ganzen Text, der aus mehreren Sätzen besteht. Daher ist es sinnvoll, "Anti-Plagiat" zu verwenden, wenn Sie Text mit 1000 Zeichen haben (dies ist ungefähr eine halbe Seite).
Während der Entwicklung des Dienstes wurde ein Prototyp auf PHP (Webpart) und Microsoft SQL Server (Suchmaschine) erstellt. Es wurde sofort klar, dass dies nicht abheben und langsam an mehreren Millionen Dokumenten arbeiten würde. Deshalb musste ich meine Suchmaschine abschneiden. Jetzt ist das System in C # und Python geschrieben, verwendet PostgreSQL und MongoDB (tatsächlich viel mehr, aber mehr dazu im nächsten Artikel). Die Suchmaschine ist noch vollständig von uns entwickelt.
Setzen Sie Likes Schreiben Sie in die Kommentare, wenn Sie mehr über die Geschichte der Entwicklung des Systems, die Änderung der Prozesse des Unternehmens und die Hardware erfahren möchten, an der Anti-Plagiat zu verschiedenen Zeiten in seinem Leben gearbeitet hat und jetzt arbeitet.
Das Wort, das den Namen des Unternehmens gab, ist mittlerweile ein Begriff. Oft findet man in einer Suchmaschine Ausdrücke wie "Auf Anti-Plagiat prüfen", "Anti-Plagiat erhöhen". Jeder, der irgendwie mit dem Bereich der Kreditaufnahme in Russland und den Nachbarländern verbunden ist, versucht, das Wort „Anti-Plagiat“ zu verwenden, um es in den Suchergebnissen hervorzuheben. Wir werden oft nach anderen „Anti-Plagiaten“ gefragt. "Anti-Plagiat" ist also eines, es ist eine Marke und der Name unseres Unternehmens.
Gleich zu Beginn der Implementierung des Kreditsuchdienstes haben wir beschlossen, den Text als Zeichenfolge zu verwenden. Verschiedene semantische Konstruktionen aus Texten, die Suche nach Bedeutungen, die Analyse von Sätzen usw. wurden sofort abgelehnt. Die von uns gewählte Lösung bietet zwei große Vorteile: hohe Suchgeschwindigkeit und relativ geringes Volumen an Suchindizes.
Derzeit befinden sich drei Produkte in unserem Sortiment. Sie zeichnen sich durch Funktionalität aus, enthalten jedoch grundsätzlich das gleiche Prinzip der Leihsuche. In diesem Artikel werde ich darüber sprechen, wie unsere klassische Suche nach Ausleihen funktioniert - die Funktionalität, die von Anfang an zur Grundlage des Dienstes geworden ist und sich konzeptionell noch nicht geändert hat. Das Ausleihsuchschema ist, wie Sie auf dem Bild sehen, einfach und unkompliziert, wie das Zeichnen einer Eule. Zuerst erhalten wir das Dokument vom Benutzer, dann extrahieren wir den Text daraus. Dann suchen wir in diesem Text nach Ausleihen, erhalten „Überarbeitungen“ (wie wir den Bericht für ein Suchmodul nennen) und sammeln schließlich Überarbeitungen in einem großen Bericht, den wir dem Benutzer als Ergebnis anzeigen.
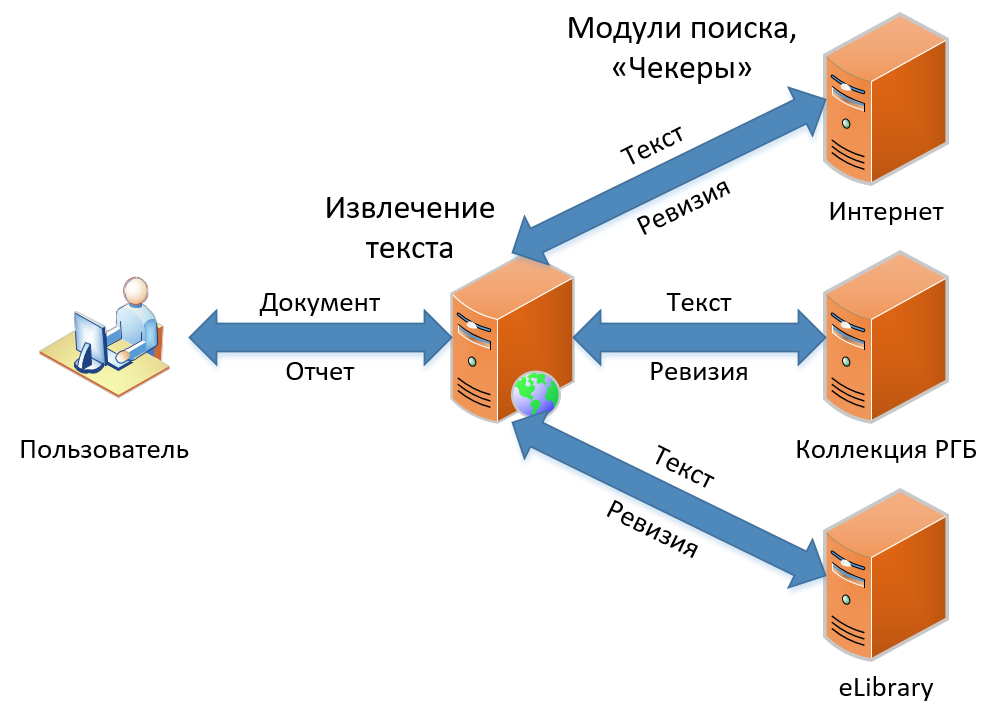
Mal sehen, wie das alles im Detail passiert.
Textextraktion
Zuallererst ist „Anti-Plagiat“ ein Dienst, bei dem nur
Textausleihen durchsucht
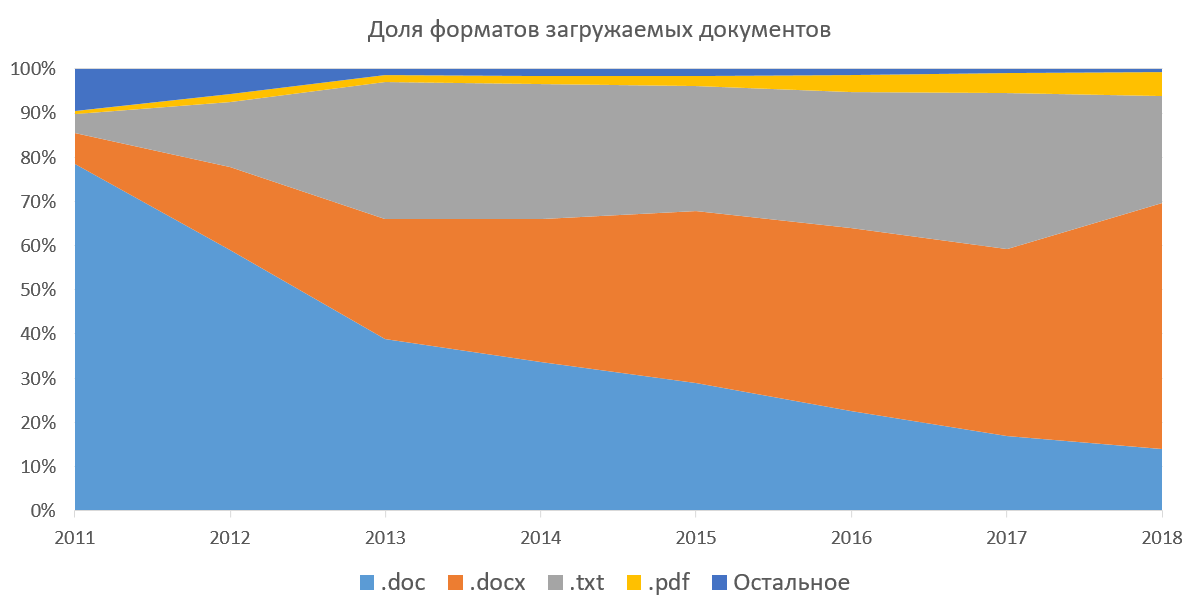
werden. Dies bedeutet, dass wir Text aus allen Dokumenten extrahieren müssen, um weiter damit arbeiten zu können. Das System unterstützt das Herunterladen von Dokumenten in den Formaten docx, doc, txt, pdf, rtf, odt, html, pptx und verschiedenen anderen (nie verwendeten) Formaten. Sie können alle diese Dokumente auch in Archiven herunterladen (7z, zip, rar). Diese Methode war beliebt, als wir nicht mehrere Dokumente gleichzeitig über die Weboberfläche hochladen konnten. Nachfolgend finden Sie eine grafische Darstellung der Beliebtheit von herunterladbaren Dokumentformaten im Unternehmensteil unseres Systems. Es zeigt, wie docx über mehrere Jahre durch doc ersetzt wurde und der Anteil von PDFs allmählich zunimmt. Wenn Sie txt nicht in Betracht ziehen (das Extrahieren von Text ist trivial), ist PDF für uns am angenehmsten. Ausland pdf ist der De-facto-Standard, es veröffentlicht Artikel, bereitet studentische Arbeiten vor. Laut unserer Statistik gewinnt PDF in Russland und den GUS-Ländern allmählich an Popularität. Wir selbst fördern dieses Format bei den Massen und empfehlen, Dokumente darin herunterzuladen.
Wir haben die Download-Formate für Privatkunden auf PDF und TXT beschränkt. Deshalb haben wir den Ressourcenverbrauch und die Kosten für die Unterstützung eines kostenlosen Dienstes gesenkt. Schließlich müssen Sie den Text überprüfen und das System nicht testen? Was ist der Unterschied in welchem Format, um es hochzuladen?
Der nächst einfachere Weg, Text zu extrahieren, ist docx, da es sich in der Tat um ein Zip-Archiv mit XML handelt, das recht einfach zu verarbeiten ist und auf niedriger Ebene viel getan werden kann.
Das Schwierigste für uns ist der Doc. Dieses Format ist seit langem geschlossen, und jetzt gibt es eine Reihe von Implementierungen. Das letzte Microsoft Word, das .docx nicht unterstützte (allerdings über das Microsoft Office Compatibility Pack), wurde vor 20 Jahren veröffentlicht und in Microsoft Office 97 aufgenommen. Das Format verwendet OLE, das später zu COM und ActiveX wurde. Alles ist binär, manchmal inkompatibel zwischen den Versionen. Im Allgemeinen der schreckliche Traum eines modernen Programmierers. Es ist gut, dass das DOC-Format die Szene allmählich verlässt. Ich denke, es ist an der Zeit, dass wir ihm helfen, in den Ruhestand zu gehen. In Kürze werden wir Benutzer absichtlich warnen, dass dieses Format veraltet ist.
Also zurück zum Bericht. Wir haben die Datei bekommen und angefangen, den Text zu extrahieren. Zusammen mit dem Text extrahiert das System auch die Positionen der Wörter auf den Seiten, so dass es unseren Benutzern in Zukunft möglich sein wird, das Markup des Ausleihberichts auf dem Dokument selbst anzuzeigen. Gleichzeitig suchen wir nach technischen Problemumgehungen für das Antiplagiat.
Sobald das „Anti-Plagiat“ auftauchte, das den Prozentsatz der Originalität anzeigt, gab es Leute, die mit minimalem Aufwand einen Scheck zum Ausleihen ausstellen wollten, sowie Leute, die einen solchen Service für Geld anboten. Das Problem ist, dass der numerische Parameter nach einer Schätzung fragt. Immerhin ist es so einfach - anstatt ein Werk mit dem System als Werkzeug zu lesen, lesen Sie es nicht, sondern bewerten Sie es anhand des Prozentsatzes der Originalität! Es war dieses Unglück, das zu einer Richtung wie der Abstimmung von Werken führte (eine Änderung des Textes, um den Prozentsatz der Originalität des Werks zu erhöhen). Lesen Sie mehr über Probleme in Universitätsprozessen im Artikel
"Über die Praxis der Erkennung von Kreditaufnahmen an russischen Universitäten".In ausländischen Suchsystemen lohnen sich die Probleme, technische Problemumgehungen zu erkennen und ihnen entgegenzuwirken, praktisch nicht. Tatsache ist, dass auf die entdeckte „Finte mit Ohren“ eine sehr harte Bestrafung folgen wird - Vertreibung und unauslöschlicher Fleck auf dem wissenschaftlichen Ruf, unvereinbar mit der weiteren Karriere. In unserem Fall ist die Situation lächerlich einfach: "Oh, dieses System hat etwas durcheinander gebracht!", "Oh, ich bin es nicht, es ist selbst!" Der Schüler wird wahrscheinlich zum Wiederherstellen geschickt. Tatsache ist, dass das Abschreiben leider keine Schande ist.
Aber wieder abgelenkt. Eine andere Möglichkeit, Text zu extrahieren, ist OCR. Wir drucken das Dokument auf einem virtuellen Drucker und erkennen es dann. Lesen Sie mehr dazu im Artikel
„Bilderkennung im Dienste des Antiplagiats“ .
Nun ein kleiner Teil unserer Geschichte über das Extrahieren von Texten. Zuerst haben wir Texte mit IFilters extrahiert. Sie sind nur unter Windows langsam und geben keine Formatierungsinformationen zurück (es ist nicht klar, wo sich der weiße Text auf dem weißen Hintergrund befindet, dann können Sie die Ausleihblöcke nicht direkt im Benutzerdokument markieren). Wir dachten, dass diese Probleme gelöst werden würden, wenn wir kostenpflichtige Bibliotheken verwenden würden, aber hier fanden wir Einschränkungen: Noch unter Windows sehen sie keine Formeln, manchmal fallen sie auf speziell vorbereitete Dokumente (verschiedene Bibliotheken auf verschiedenen!). Die nächste Idee war, alle eingehenden Dokumente zu OCR zu machen. Dieser Ansatz ist jedoch sehr ressourcenintensiv (Verarbeitung von nur 10 Seiten pro Minute auf einem Kern), und an einigen Stellen wird der Text nicht genau extrahiert.
Wir haben keine Silberkugel gefunden, obwohl wir ein paar Mal dachten, es sei Glück. Nachdem sie jedoch ein wenig damit gelebt hatten, erkannten sie, dass es wieder eine Erfahrung war. Die Textextraktion ist ein ausgewogenes Verhältnis zwischen Leistung (Sie müssen Text aus Hunderten von Dokumenten pro Minute extrahieren), Zuverlässigkeit (Sie müssen Text aus allem extrahieren) und Funktionalität (Formatierung, Problemumgehungen, das ist alles). Jetzt arbeiten alle oben genannten und ein wenig mehr für uns. Wir experimentieren ständig mit diesem Bereich und suchen weiterhin nach unserem Glück.
Der Text wird extrahiert, Runden gefunden und teilweise beseitigt, wir machen uns auf die Suche nach Ausleihen!
Ausleihensuche
Die im Suchverfahren implementierte Idee wurde von Ilya Segalovich und Yuri Zelenkov vorgeschlagen (Sie können beispielsweise im Artikel lesen:
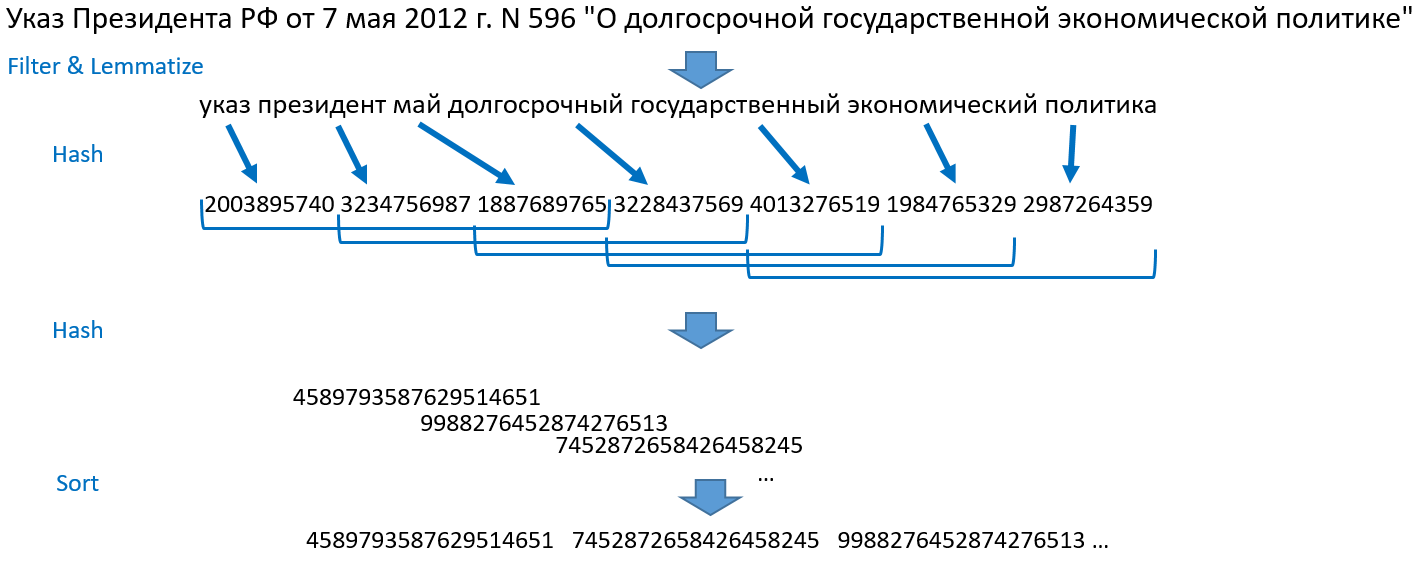
Vergleichende Analyse von Methoden zur Bestimmung von Fuzzy-Duplikaten für Webdokumente ). Ich werde Ihnen sagen, wie es bei uns funktioniert. Nehmen wir zum Beispiel den Satz: "Dekret des Präsidenten der Russischen Föderation vom 7. Mai 2012 N 596" Über die langfristige staatliche Wirtschaftspolitik "."
- Wir zerlegen Sätze in Wörter, wir werfen Zahlen, Satzzeichen weg, stoppen Wörter. Lemmatisieren (auf normale Form bringen) alle Wörter.
- Wir wandeln die Wörter durch Hashing in ganze Zahlen um und erhalten eine Reihe von Zahlen.
- Wir nehmen die ersten drei Hashes, dann den 2., 3., 4. Hash, dann den 3., 4., 5. und so weiter bis zum Ende des Hash-Arrays. Das ist Schindelfliesen. Diese Methode erhielt ihren Namen aufgrund solcher gekachelten überlappenden Mengen. Wir führen jede Kachel zu einem Objekt zusammen und hashen erneut.
- Wir sortieren die resultierenden Zahlen und erhalten ein geordnetes Array von ganzen Zahlen. Dies ist die Basis für die Suche.
Für die Suche benötigen wir nun eine magische Funktion, die gemäß einer solchen Liste von Hashes Dokumente, die in absteigender Reihenfolge der Anzahl der übereinstimmenden Hashes angeordnet sind, in ein Quelldokument umwandelt. Diese Funktion sollte da schnell funktionieren Wir wollen in Milliarden von Dokumenten suchen. Um eine solche Menge schnell zu finden, benötigen wir einen umgekehrten Index, der per Hash eine Liste von Dokumenten zurückgibt, in denen sich dieser Hash befindet. Wir haben eine solche riesige Hash-Tabelle implementiert. Im Gegensatz zu unseren älteren Suchbrüdern speichern wir diese Tabelle auf SSD, nicht im Speicher. Wir sind ziemlich kurz vor einer solchen Leistung. Die Indexsuche nimmt einen kleinen Teil des gesamten Dokumentverarbeitungszyklus ein. Sehen Sie, wie die Suche verläuft:
Stufe 1. Indexsuche
Für jeden Hash des Anforderungstextes erhalten wir eine Liste der Kennungen der Quelldokumente, in denen er vorkommt. Als Nächstes ordnen wir die Liste der Kennungen von Quelldokumenten nach der Anzahl der Hashes, die im Anforderungstext gefunden wurden. Wir erhalten eine Rangliste der Kandidatendokumente für die Quelle der Ausleihe.
Phase 2. Aufbau des Audits
Für eine große Textanfrage von Kandidaten können es ungefähr 10 Tausend sein. Dies ist immer noch eine Menge, um jedes Dokument mit dem Text der Anfrage zu vergleichen. Wir handeln gierig, aber entschlossen. Wir nehmen das erste Quelldokument, vergleichen es mit dem Anfragetext und schließen von allen anderen Kandidaten die Hashes aus, die bereits in diesem ersten Dokument enthalten waren. Wir entfernen diejenigen aus der Liste der Kandidaten, die keine Hashes haben, und sortieren die Kandidaten entsprechend der neuen Anzahl von Hashes neu. Wir nehmen das erste Dokument aus der neuen Liste, vergleichen es mit dem Quelltext, löschen die Hashes, löschen die Nullkandidaten und sortieren die Kandidaten neu. Wir machen das 10-20 Mal. Normalerweise reicht dies aus, um die Liste zu löschen, oder es verbleiben nur Dokumente, die mit mehreren Hashes übereinstimmen.
Die Verwendung von Hashes von Wörtern ermöglicht es uns, Vergleichsvorgänge schneller durchzuführen, Speicherplatz zu sparen und nicht die Texte von Quelldokumenten zu speichern, sondern deren digitale Besetzungen (TextSpirit, wie wir sie liebevoll nennen), die während der Indizierung erhalten wurden, wodurch das Urheberrecht verletzt wird. Die Auswahl spezifischer Ausleihfragmente erfolgt über den Suffixbaum.
Als Ergebnis der Überprüfung mit einem Suchmodul erhalten wir eine Überarbeitung, die eine Liste der Quellen, ihrer Metadaten und der Koordinaten der Ausleiheeinheiten relativ zum Anforderungstext enthält.
Montage melden
Was ist übrigens, wenn eines der 10-15 Module nicht rechtzeitig reagiert hat? Wir durchsuchen die Sammlungen von RSL, eLibrary und Guarantee. Diese Suchmodule befinden sich im Gebiet von Drittorganisationen und können aus urheberrechtlichen Gründen nicht auf unsere Website übertragen werden. Der Fehlerpunkt kann hier immer ein Kommunikationskanal und verschiedene höhere Gewalt in Rechenzentren sein, die nicht von uns kontrolliert werden. Einerseits kann die Ausleihe in jedem Suchmodul gefunden werden. Wenn andererseits eine der Komponenten des Systems nicht verfügbar ist, können Sie die Qualität der Suche beeinträchtigen, aber den größten Teil des Ergebnisses angeben, während Sie den Benutzer warnen, dass das Ergebnis für einige Suchmodule noch nicht fertig ist. Welche Option würden Sie anwenden? Wir wenden beide Optionen entsprechend an.

Nachdem alle Überarbeitungen eingegangen sind, beginnen wir mit der Erstellung des Berichts. Es wird ein ähnlicher Ansatz wie bei der Vorbereitung einer Revision verwendet. Es scheint nichts kompliziertes zu sein, aber es gibt auch interessante Aufgaben. Wir haben zwei Arten von Anleihen. "Zitate" werden in grün angezeigt - korrekt zitierte Zitate (gemäß GOST) aus dem Modul "Zitat", Ausdrücke des Typs "Was musste nachgewiesen werden" aus dem Modul "Gemeinsame Ausdrücke", Zulassungsdokumente aus den Datenbanken "Garantiegeber" und "Lexpro". Alle anderen Anleihen sind orange markiert. Grüns haben Vorrang vor Orangen, es sei denn, sie betreten den gesamten orangefarbenen Block.
Infolgedessen kann der Bericht mit dem Text verglichen werden, der auf auf dem Tisch liegendem Papier gedruckt ist, über das mehrfarbige Streifen (Blöcke von Anleihen und Zitaten) gekritzelt sind, die sich phantasievoll überlappen. Was wir oben sehen, ist ein Bericht. Wir haben zwei Indikatoren für jede Quelle:
Der Anteil am Bericht ist das Verhältnis des aus dieser Quelle berücksichtigten Kreditvolumens zum Gesamtvolumen des Dokuments. Wenn derselbe Text in mehreren Quellen gefunden wurde, wird er nur in einer von ihnen berücksichtigt. Wenn Sie die Konfiguration des Berichts ändern (Quellen aktivieren oder deaktivieren), kann sich dieser Indikator für die Quelle ändern. Insgesamt gibt es den Prozentsatz der Anleihen und Zitate an (abhängig von der Farbe der Quelle).
Anteil am Text - das Verhältnis des von der angegebenen Textquelle geliehenen Volumens zum Gesamtvolumen des Dokuments. Es macht keinen Sinn, die Anteile des Textes nach Quellen zusammenzufassen, es wird leicht 146% oder sogar mehr ergeben. Dieser Indikator ändert sich nicht, wenn sich der Bericht ändert.
Natürlich kann der Bericht bearbeitet werden. Dies ist eine spezielle Funktion für den Experten, der die Arbeit überprüft, um das Ausleihen der eigenen Werke des Autors zu deaktivieren (es kann den Anschein haben, dass dieses Fragment nicht nur in der eigenen Arbeit des Autors, sondern auch an einer anderen Stelle enthalten ist), und den Auslese-Typ von separaten Leihblöcken zu ändern Ausleihe zum Zitieren. Durch die Bearbeitung des Berichts erhält der Experte den tatsächlichen Wert der Kreditaufnahme. Alle Arbeiten zur Überprüfung müssen gelesen werden. Es ist zweckmäßig, dies zu tun, indem Sie sich die Originalform des Dokuments ansehen, in der die Ausleihblöcke markiert sind, und den Bericht beim Lesen sofort bearbeiten. Leider ist dies nicht jedermanns logische Handlung, viele sind mit dem Prozentsatz der Originalität zufrieden, ohne sich den Bericht anzusehen.
Gehen wir jedoch einen Schritt zurück und finden heraus, was in den Index des von Anti-Plagiat erstellten Internet-Suchmoduls aufgenommen wird.
Internet-Indizierung
Anti-Plagiat konzentriert sich hauptsächlich auf studentische Arbeiten, wissenschaftliche Veröffentlichungen, Abschlussarbeiten, Dissertationen usw. Wir indizieren das Internet direktional - wir suchen nach großen Clustern wissenschaftlicher Texte, Abstracts, Artikel, Dissertationen, wissenschaftlicher Zeitschriften usw. Die Indizierung erfolgt folgendermaßen:
- Unser Roboter kommt, stellt sich vor und lädt unter Anleitung von robots.txt (wir haben einen guten Roboter) Dokumente mit einer angemessenen Belastung auf jedem Host herunter (Hunderte von Websites werden gleichzeitig ausgeführt, sodass wir zwischen dem Laden der Seite eine Weile warten können).
- Der Roboter übergibt das Dokument und seine Metadaten an die Verarbeitungswarteschlange. Der Text wird aus dem Dokument extrahiert.
- Der Text wird auf „Qualität“ analysiert. Wie Sie sich aus dem Artikel über die Deponie erinnern, können wir das Genre des Dokuments bestimmen, dem Band hier einfache Heuristiken hinzufügen und verstehen, ob ein geeigneter Text zu uns gekommen ist oder Müll.
- Qualitativer Text geht weiter und verwandelt sich in Hashes. Hashes und Metadaten werden an den Haupt-Internetindex gesendet.
- Wir vergleichen den empfangenen Text mit den zuvor von uns indizierten Texten. Ein Neuling wird nur hinzugefügt, wenn er wirklich neu ist , d. H. 90% - . , url .
Daher indizieren wir qualitativ hochwertige Texte, und alle indizierten Texte unterscheiden sich für uns erheblich. Das im Internet indizierte Volumenwachstum ist in der folgenden Abbildung dargestellt. Jetzt fügen wir dem Index durchschnittlich 15 bis 20 Millionen Dokumente pro Monat hinzu.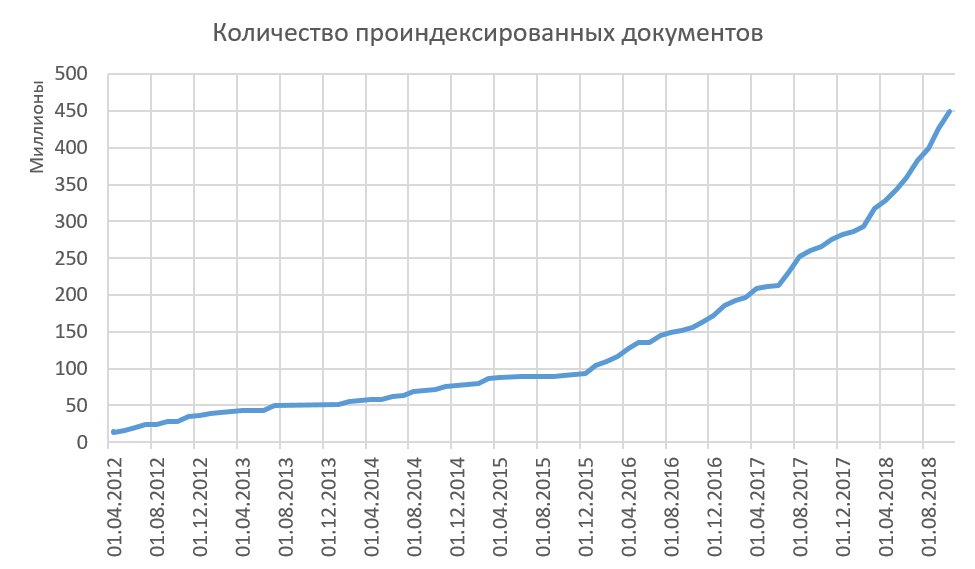 Haben Sie bemerkt, dass das Verfahren zum Entfernen aus dem Index nirgendwo beschrieben wird? Und sie ist nicht! Grundsätzlich löschen wir keine Dokumente aus dem Index. Wir glauben, wenn wir etwas im Internet sehen könnten, könnten andere Menschen diesen Text sehen und ihn auf die eine oder andere Weise verwenden. In dieser Hinsicht gibt es eine interessante Statistik darüber, was früher im Internet war und jetzt nicht mehr da ist. Ja, stellen Sie sich vor, der Ausdruck "Einmal im Internet wird für immer dort bleiben" ist nicht wahr! Etwas verschwindet für immer aus dem Internet. Möchten Sie mehr über unsere Statistiken dazu erfahren?
Haben Sie bemerkt, dass das Verfahren zum Entfernen aus dem Index nirgendwo beschrieben wird? Und sie ist nicht! Grundsätzlich löschen wir keine Dokumente aus dem Index. Wir glauben, wenn wir etwas im Internet sehen könnten, könnten andere Menschen diesen Text sehen und ihn auf die eine oder andere Weise verwenden. In dieser Hinsicht gibt es eine interessante Statistik darüber, was früher im Internet war und jetzt nicht mehr da ist. Ja, stellen Sie sich vor, der Ausdruck "Einmal im Internet wird für immer dort bleiben" ist nicht wahr! Etwas verschwindet für immer aus dem Internet. Möchten Sie mehr über unsere Statistiken dazu erfahren?Fazit
Es ist erstaunlich, wie relevant technische Lösungen sind, die vor mehr als 10 Jahren eingeführt wurden. Wir bereiten uns jetzt auf die Veröffentlichung von Version 4 des Index vor. Er ist schneller, technologisch fortschrittlicher und besser, basiert jedoch auf denselben Lösungen. Es sind neue Suchrichtungen aufgetaucht - übertragbare Anleihen, Paraphrasierung, aber unser Index wird auch dort verwendet und führt sogar einen kleinen, aber wichtigen Teil der Arbeit aus.Liebe Leserinnen und Leser, was würde Sie noch über unseren Service wissen?