
Das Herzstück der Suchmaschinen von Meltwater und
Fairhair.ai ist Elasticsearch, ein Cluster von Clustern mit Milliarden von Medien- und Social-Media-Artikeln.
Index-Shards in Clustern unterscheiden sich stark in Zugriffsstruktur, Arbeitslast und Größe, was einige sehr interessante Probleme aufwirft.
In diesem Artikel beschreiben wir, wie wir mithilfe der linearen Programmierung (lineare Optimierung) die Such- und Indizierungsarbeitslast so gleichmäßig wie möglich auf alle Knoten in den Clustern verteilt haben. Diese Lösung verringert die Wahrscheinlichkeit, dass ein Knoten zu einem Engpass im System wird. Infolgedessen haben wir die Suchgeschwindigkeit erhöht und Infrastruktur gespart.
Hintergrund
Die Suchmaschinen von Fairhair.ai enthalten etwa 40 Milliarden Beiträge aus sozialen Medien und Leitartikeln, die täglich Millionen von Anfragen bearbeiten. Die Plattform bietet Kunden Suchergebnisse, Grafiken, Analysen und Datenexporte für erweiterte Analysen.
Diese massiven Datensätze befinden sich in mehreren Elasticsearch-Clustern mit 750 Knoten und Tausenden von Indizes in über 50.000 Shards.
Weitere Informationen zu unserem Cluster finden Sie in früheren Artikeln zur
Architektur und zum
Load Balancer für maschinelles Lernen .
Ungleichmäßige Arbeitslastverteilung
Sowohl unsere Daten als auch Benutzeranfragen sind normalerweise datumsgebunden. Die meisten Anfragen fallen in einen bestimmten Zeitraum, z. B. letzte Woche, letzten Monat, letztes Quartal oder einen beliebigen Bereich. Um die Indizierung und Abfragen zu vereinfachen, verwenden wir die
Zeitindizierung ähnlich
dem ELK-Stapel .
Diese Indexarchitektur bietet mehrere Vorteile. Sie können beispielsweise eine effiziente Massenindizierung durchführen und ganze Indizes löschen, wenn Daten veraltet sind. Dies bedeutet auch, dass die Arbeitslast für einen bestimmten Index im Laufe der Zeit stark variiert.
Im Vergleich zu den alten werden exponentiell mehr Abfragen an die neuesten Indizes gesendet.
 Abb. 1. Zugriffsschema für Zeitindizes. Die vertikale Achse repräsentiert die Anzahl der abgeschlossenen Abfragen, die horizontale Achse repräsentiert das Alter des Index. Wöchentliche, monatliche und jährliche Hochebenen sind deutlich sichtbar, gefolgt von einem langen Schwanz geringerer Arbeitsbelastung bei älteren Indizes
Abb. 1. Zugriffsschema für Zeitindizes. Die vertikale Achse repräsentiert die Anzahl der abgeschlossenen Abfragen, die horizontale Achse repräsentiert das Alter des Index. Wöchentliche, monatliche und jährliche Hochebenen sind deutlich sichtbar, gefolgt von einem langen Schwanz geringerer Arbeitsbelastung bei älteren IndizesDie Muster in Abb. Ich war ziemlich vorhersehbar, da unsere Kunden mehr an frischen Informationen interessiert sind und regelmäßig den aktuellen Monat mit der Vergangenheit und / oder dieses Jahr mit dem vergangenen Jahr vergleichen. Das Problem ist, dass Elasticsearch dieses Muster nicht kennt und nicht automatisch für die beobachtete Arbeitslast optimiert!
Der integrierte Elasticsearch-Shard-Zuweisungsalgorithmus berücksichtigt nur zwei Faktoren:
- Die Anzahl der Shards auf jedem Knoten. Der Algorithmus versucht, die Anzahl der Shards pro Knoten im gesamten Cluster gleichmäßig auszugleichen.
- Beschriftet den freien Speicherplatz. Elasticsearch berücksichtigt den verfügbaren Speicherplatz auf einem Knoten, bevor entschieden wird, ob diesem Knoten neue Shards zugewiesen oder Segmente von diesem Knoten auf andere verschoben werden sollen. Bei 80% der verwendeten Festplatte ist es verboten, neue Shards auf einem Knoten zu platzieren. 90% des Systems beginnen, Shards aktiv von diesem Knoten zu übertragen.
Die Grundannahme des Algorithmus ist, dass jedes Segment im Cluster ungefähr die gleiche Arbeitslast erhält und dass jeder die gleiche Größe hat. In unserem Fall ist dies sehr weit von der Wahrheit entfernt.
Standard-Lastausgleich führt schnell zu Hot Spots im Cluster. Sie erscheinen und verschwinden zufällig, wenn sich die Arbeitslast im Laufe der Zeit ändert.
Ein Hot Spot ist im Wesentlichen ein Host, der nahe der Grenze einer oder mehrerer Systemressourcen arbeitet, z. B. einer CPU, einer Festplatten-E / A oder einer Netzwerkbandbreite. In diesem Fall stellt der Knoten die Anforderungen zunächst für eine Weile in die Warteschlange, wodurch sich die Antwortzeit auf die Anforderung erhöht. Wenn die Überlastung jedoch lange anhält, werden die Anforderungen letztendlich abgelehnt und Benutzer erhalten Fehler.
Eine weitere häufige Folge der Überlastung ist der instabile Druck des JVM-Mülls aufgrund von Abfragen und Indexierungsvorgängen, der zum Phänomen der „gruseligen Hölle“ des JVM-Müllsammlers führt. In einer solchen Situation kann die JVM den Speicher entweder nicht schnell genug abrufen und stürzt nicht mehr ab oder sie bleibt in einem endlosen Speicherbereinigungszyklus stecken, friert ein und reagiert nicht mehr auf Clusteranforderungen und Pings.
Das Problem verschlimmerte sich, als wir
unsere Architektur unter AWS überarbeiteten . Zuvor wurden wir durch die Tatsache „gerettet“, dass wir bis zu vier Elasticsearch-Knoten auf unseren eigenen leistungsstarken Servern (24 Kerne) in unserem Rechenzentrum ausgeführt haben. Dies maskierte den Einfluss der asymmetrischen Verteilung der Scherben: Die Last wurde durch eine relativ große Anzahl von Kernen auf der Maschine weitgehend geglättet.
Nach dem Refactoring haben wir jeweils nur einen Knoten auf weniger leistungsstarken Maschinen (8 Kerne) platziert - und die ersten Tests haben sofort große Probleme mit den „Hot Spots“ ergeben.
Elasticsearch weist Shards in zufälliger Reihenfolge zu, und bei mehr als 500 Knoten in einem Cluster hat die Wahrscheinlichkeit zu vieler „heißer“ Shards auf einem einzelnen Knoten stark zugenommen - und solche Knoten sind schnell übergelaufen.
Für Benutzer würde dies eine ernsthafte Verschlechterung der Arbeit bedeuten, da überlastete Knoten langsam reagieren und Anforderungen oder Abstürze manchmal vollständig ablehnen. Wenn Sie ein solches System in die Produktion bringen, werden Benutzer anscheinend häufig zufällige Verlangsamungen der Benutzeroberfläche und zufällige Zeitüberschreitungen feststellen.
Gleichzeitig bleibt eine große Anzahl von Knoten mit Shards ohne viel Last übrig, die tatsächlich inaktiv sind. Dies führt zu einer ineffizienten Nutzung unserer Clusterressourcen.
Beide Probleme könnten vermieden werden, wenn Elasticsearch Shards intelligenter verteilt, da der durchschnittliche Verbrauch von Systemressourcen an allen Knoten bei einem gesunden Niveau von 40% liegt.
Cluster Continuous Change
Bei der Arbeit mit mehr als 500 Knoten haben wir noch eines beobachtet: eine ständige Änderung des Knotenzustands. Scherben bewegen sich in Knoten unter dem Einfluss der folgenden Faktoren ständig hin und her:
- Neue Indizes werden erstellt und alte verworfen.
- Datenträgerbezeichnungen werden aufgrund von Indizierung und anderen Shard-Änderungen ausgelöst.
- Elasticsearch entscheidet zufällig, dass der Knoten im Vergleich zum Durchschnittswert des Clusters zu wenige oder zu viele Shards enthält.
- Hardware-Abstürze und Abstürze auf Betriebssystemebene führen dazu, dass neue AWS-Instanzen gestartet und dem Cluster hinzugefügt werden. Bei 500 Knoten geschieht dies durchschnittlich mehrmals pro Woche.
- Aufgrund des normalen Datenwachstums werden fast jede Woche neue Websites hinzugefügt.
Unter Berücksichtigung all dessen kamen wir zu dem Schluss, dass eine komplexe und kontinuierliche Lösung aller Probleme einen kontinuierlichen und dynamischen Algorithmus zur Neuoptimierung erfordert.
Lösung: Shardonnay
Nach einer langen Untersuchung der verfügbaren Optionen kamen wir zu dem Schluss, dass wir:
- Erstellen Sie Ihre eigene Lösung. Wir haben keine guten Artikel, Codes oder andere vorhandene Ideen gefunden, die in unserem Maßstab und für unsere Aufgaben gut funktionieren würden.
- Starten Sie den Neuausgleichsprozess außerhalb von Elasticsearch und verwenden Sie die Clustered Redirect-APIs, anstatt zu versuchen , ein Plugin zu erstellen . Wir wollten eine schnelle Rückkopplungsschleife, und die Bereitstellung eines Plugins in einem Cluster dieser Größenordnung kann mehrere Wochen dauern.
- Verwenden Sie die lineare Programmierung , um zu jedem Zeitpunkt optimale Shard-Bewegungen zu berechnen.
- Führen Sie die Optimierung kontinuierlich durch, damit der Clusterstatus allmählich optimal wird.
- Bewegen Sie nicht zu viele Scherben gleichzeitig.
Wir haben eine interessante Sache bemerkt: Wenn Sie zu viele Scherben gleichzeitig bewegen, ist es sehr einfach, einen
kaskadierenden Sturm von Scherbenbewegungen auszulösen. Nach dem Einsetzen eines solchen Sturms kann es stundenlang andauern, wenn sich die Scherben unkontrolliert hin und her bewegen und an verschiedenen Stellen Markierungen über den kritischen Speicherplatz auftreten. Dies führt wiederum zu neuen Splitterbewegungen und so weiter.
Um zu verstehen, was passiert, ist es wichtig zu wissen, dass beim Verschieben eines aktiv indizierten Segments tatsächlich viel mehr Speicherplatz auf der Festplatte belegt wird, von der es verschoben wird. Dies liegt daran, wie Elasticsearch
Transaktionsprotokolle speichert. Wir haben Fälle gesehen, in denen sich der Index beim Verschieben eines Knotens verdoppelt hat. Dies bedeutet, dass der Knoten, der die Shard-Bewegung aufgrund der hohen Speicherplatznutzung initiiert hat,
für eine Weile
noch mehr Speicherplatz benötigt, bis genügend Shards auf andere Knoten verschoben werden.
Um dieses Problem zu lösen, haben wir den
Shardonnay- Service zu Ehren der berühmten Chardonnay-Rebsorte entwickelt.
Lineare Optimierung
Die lineare Optimierung (oder
lineare Programmierung , LP) ist eine Methode, um das beste Ergebnis wie maximalen Gewinn oder niedrigste Kosten in einem mathematischen Modell zu erzielen, dessen Anforderungen durch lineare Beziehungen dargestellt werden.
Die Optimierungsmethode basiert auf einem System linearer Variablen, einigen Einschränkungen, die erfüllt sein müssen, und einer Zielfunktion, die bestimmt, wie eine erfolgreiche Lösung aussieht. Das Ziel der linearen Optimierung besteht darin, die Werte von Variablen zu finden, die die Zielfunktion unter Einschränkungen minimieren.
Scherbenverteilung als lineares Optimierungsproblem
Shardonnay sollte kontinuierlich arbeiten und bei jeder Iteration den folgenden Algorithmus ausführen:
- Mithilfe der API ruft Elasticsearch Informationen zu vorhandenen Shards, Indizes und Knoten im Cluster sowie deren aktuellen Speicherort ab.
- Modelliert den Status eines Clusters als Satz binärer LP-Variablen. Jede Kombination (Knoten, Index, Shard, Replikat) erhält eine eigene Variable. Im LP-Modell gibt es eine Reihe sorgfältig entworfener Heuristiken, Einschränkungen und eine objektive Funktion, mehr dazu weiter unten.
- Sendet das LP-Modell an einen linearen Löser, der unter Berücksichtigung der Einschränkungen und der Zielfunktion eine optimale Lösung bietet. Die Lösung besteht darin, Shards Knoten neu zuzuweisen.
- Interpretiert die Lösung der LP und wandelt sie in eine Folge von Splitterbewegungen um.
- Weist Elasticsearch an, Shards durch die Clusterumleitungs-API zu verschieben.
- Wartet darauf, dass der Cluster die Shards verschiebt.
- Kehrt zu Schritt 1 zurück.
Die Hauptsache ist, die richtigen Einschränkungen und die richtige Zielfunktion zu entwickeln. Der Rest wird von Solver LP und Elasticsearch erledigt.
Es überrascht nicht, dass die Aufgabe für einen Cluster dieser Größe und Komplexität sehr schwierig war!
Einschränkungen
Wir stützen das Modell auf einige Einschränkungen, die auf den von Elasticsearch selbst vorgegebenen Regeln basieren. Halten Sie sich beispielsweise immer an Festplattenetiketten oder verbieten Sie das Platzieren eines Replikats auf demselben Knoten wie ein anderes Replikat desselben Shards.
Andere werden aufgrund der jahrelangen Erfahrung mit großen Clustern hinzugefügt. Hier sind einige Beispiele für unsere eigenen Einschränkungen:
- Verschieben Sie die heutigen Indizes nicht, da sie am heißesten sind und das Lesen und Schreiben nahezu konstant belasten.
- Bevorzugen Sie kleinere Shards, da Elasticsearch sie schneller verarbeitet.
- Es ist ratsam, zukünftige Shards einige Tage vor ihrer Aktivierung zu erstellen und zu platzieren, mit der Indizierung zu beginnen und einer hohen Belastung zu unterliegen.
Kostenfunktion
Unsere Kostenfunktion wiegt verschiedene Faktoren zusammen. Zum Beispiel wollen wir:
- Minimieren Sie die Varianz von Indizierungs- und Suchanfragen, um die Anzahl der "Hot Spots" zu verringern.
- Halten Sie die minimale Varianz der Festplattennutzung für einen stabilen Systembetrieb ein.
- Minimieren Sie die Anzahl der Splitterbewegungen, damit "Stürme" mit einer Kettenreaktion nicht wie oben beschrieben beginnen.
Reduktion von LP-Variablen
In unserer Größenordnung wird die Größe dieser LP-Modelle zum Problem. Wir haben schnell erkannt, dass Probleme mit mehr als 60 Millionen Variablen nicht in angemessener Zeit gelöst werden können. Daher haben wir viele Optimierungs- und Modellierungstricks angewendet, um die Anzahl der Variablen drastisch zu reduzieren. Dazu gehören voreingenommene Stichproben, Heuristiken, die Divide-and-Conquer-Methode, iterative Relaxation und Optimierung.
 Abb. 2. Die Heatmap zeigt die unausgeglichene Last des Elasticsearch-Clusters. Dies äußert sich in einer großen Streuung des Ressourcenverbrauchs auf der linken Seite des Diagramms. Durch kontinuierliche Optimierung stabilisiert sich die Situation allmählich
Abb. 2. Die Heatmap zeigt die unausgeglichene Last des Elasticsearch-Clusters. Dies äußert sich in einer großen Streuung des Ressourcenverbrauchs auf der linken Seite des Diagramms. Durch kontinuierliche Optimierung stabilisiert sich die Situation allmählich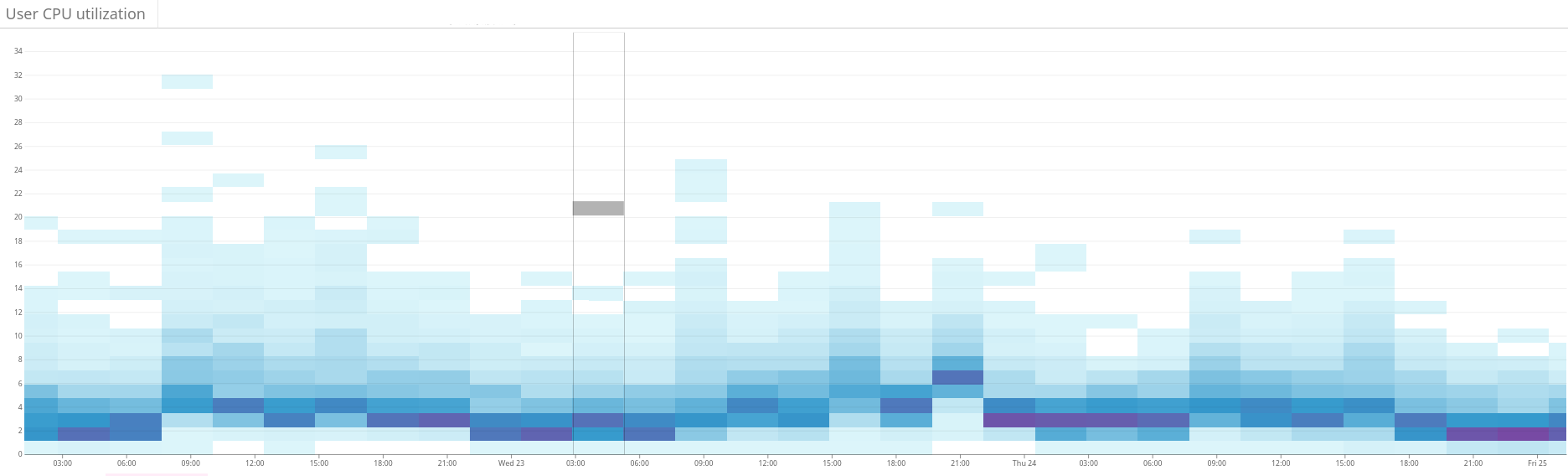 Abb. 3. Die Heatmap zeigt die CPU-Auslastung auf allen Knoten des Clusters vor und nach dem Einrichten der Hotness-Funktion in Shardonnay. Eine signifikante Änderung der CPU-Auslastung ist bei konstanter Arbeitslast zu beobachten.
Abb. 3. Die Heatmap zeigt die CPU-Auslastung auf allen Knoten des Clusters vor und nach dem Einrichten der Hotness-Funktion in Shardonnay. Eine signifikante Änderung der CPU-Auslastung ist bei konstanter Arbeitslast zu beobachten. Abb. 4. Die Heatmap zeigt den Lesedurchsatz der Festplatten im gleichen Zeitraum wie in Abb. 4. 3. Lesevorgänge sind auch gleichmäßiger über den Cluster verteilt.
Abb. 4. Die Heatmap zeigt den Lesedurchsatz der Festplatten im gleichen Zeitraum wie in Abb. 4. 3. Lesevorgänge sind auch gleichmäßiger über den Cluster verteilt.Ergebnisse
Dadurch findet unser LP-Solver in wenigen Minuten gute Lösungen, selbst für unseren riesigen Cluster. Somit verbessert das System iterativ den Zustand des Clusters in Richtung der Optimalität.
Und das Beste daran ist, dass die Streuung der Arbeitslast und der Festplattennutzung wie erwartet konvergiert - und dieser nahezu optimale Zustand bleibt nach vielen absichtlichen und unerwarteten Änderungen des Clusterzustands seitdem erhalten!
Wir unterstützen jetzt eine gesunde Arbeitslastverteilung in unseren Elasticsearch-Clustern. Alles dank linearer Optimierung und unserem Service, den wir gerne
Chardonnay nennen.