Im letzten Beitrag habe ich über Kubernetes gesprochen, wie ThoughtSpot es für seine eigenen Entwicklungsunterstützungsbedürfnisse verwendet. Heute möchte ich das Gespräch über eine kurze, aber nicht weniger interessante Debugging-Geschichte fortsetzen, die kürzlich stattgefunden hat. Der Artikel basiert auf der Tatsache, dass Containerisierung! = Virtualisierung. Darüber hinaus wird gezeigt, wie containerisierte Prozesse auch bei optimalen Einschränkungen der cgroup und hoher Maschinenleistung um Ressourcen konkurrieren.
Zuvor haben wir eine Reihe von Vorgängen im Zusammenhang mit der Entwicklung von b CI / CD im internen Kubernetes-Cluster gestartet. Alles wäre in Ordnung, aber wenn Sie eine "Docker" -Anwendung starten, sinkt die Leistung plötzlich dramatisch. Wir waren nicht geizig: In jedem der Container gab es Einschränkungen hinsichtlich der Rechenleistung und des Arbeitsspeichers (5 CPU / 30 GB RAM), die durch die Pod-Konfiguration festgelegt wurden. Auf einer virtuellen Maschine mit solchen Parametern würden alle unsere Anforderungen aus einem winzigen Datensatz (10 KB) für Tests fliegen. In Docker & Kubernetes mit 72 CPU / 512 GB RAM konnten wir jedoch 3-4 Kopien des Produkts starten, und dann wurden die Bremsen gestartet. Anforderungen, die früher in ein paar Millisekunden abgeschlossen wurden, hingen jetzt 1-2 Sekunden lang, und dies verursachte alle Arten von Fehlern in der CI-Task-Pipeline. Ich musste mich eng mit dem Debuggen befassen.
In der Regel werden alle Arten von Konfigurationsfehlern beim Packen einer Anwendung in Docker vermutet. Wir haben jedoch nichts gefunden, was zumindest zu einer Verlangsamung führen könnte (im Vergleich zu Installationen auf nackter Hardware oder virtuellen Maschinen). Alles scheint richtig zu sein. Als nächstes haben wir alle Arten von Tests aus dem Sysbench- Paket ausprobiert . Wir haben die Leistung von CPU, Festplatte und Speicher überprüft - alles war das gleiche wie bei Bare Metal. Einige Services unseres Produktspeichers enthalten detaillierte Informationen zu allen Aktionen: Sie können dann zur Profilerstellung verwendet werden. Wenn eine Ressource (CPU, RAM, Festplatte, Netzwerk) knapp ist, tritt bei einigen Aufrufen in der Regel ein erheblicher Zeitfehler auf. Wir finden also heraus, was genau und wo langsamer wird. In diesem Fall ist jedoch nichts passiert. Die zeitlichen Proportionen unterschieden sich nicht von der Arbeitskonfiguration - mit dem einzigen Unterschied, dass jeder Anruf viel langsamer war als bei Bare Metal. Nichts deutete auf die wahre Ursache des Problems hin. Wir waren bereit aufzugeben, als wir dies plötzlich fanden .
In diesem Artikel analysiert der Autor einen ähnlichen mysteriösen Fall, in dem sich zwei prinzipielle Lichtprozesse gegenseitig töteten, wenn sie in Docker auf demselben Computer ausgeführt wurden, und die Ressourcenlimits auf sehr bescheidene Werte festgelegt wurden. Wir haben zwei wichtige Schlussfolgerungen gezogen:
- Der Hauptgrund lag im Linux-Kernel selbst. Aufgrund der Struktur von Dentry-Cache-Objekten im Kernel hat das Verhalten eines Prozesses den Aufruf des Kernels
__d_lookup_loop stark __d_lookup_loop , was sich direkt auf die Leistung eines anderen Kernels __d_lookup_loop . - Der Autor hat
perf , um Fehler im Kernel zu erkennen. Ein großartiges Debugging-Tool, das wir noch nie benutzt haben (was schade ist!).
perf (manchmal auch als perf_events oder perf tools bezeichnet; früher bekannt als Performance Counters for Linux, PCL) ist ein Linux-Tool zur Leistungsanalyse, das ab Kernel Version 2.6.31 verfügbar ist. Das Dienstprogramm zur Verwaltung des Benutzerbereichs perf steht über die Befehlszeile zur Verfügung und ist eine Sammlung von Unterbefehlen.
Es führt eine statistische Profilerstellung des gesamten Systems (Kernel und Benutzerbereich) durch. Dieses Tool unterstützt Hardware- und Software-Leistungsindikatoren (z. B. HRTimer) -Plattformen, Ablaufverfolgungspunkte und dynamische Beispiele (z. B. kprobes oder uprobes). Im Jahr 2012 erkannten zwei IBM-Ingenieure perf (zusammen mit OProfile) als eines der beiden am häufigsten verwendeten Tools zur Erstellung von Leistungsindikatoren unter Linux an.
Also dachten wir: Vielleicht haben wir das Gleiche? Wir haben Hunderte verschiedener Prozesse in Containern gestartet und alle hatten den gleichen Kern. Wir spürten, dass wir die Spur angegriffen hatten! Mit perf bewaffnet wiederholten wir das Debuggen und warteten am Ende auf eine höchst interessante Entdeckung.
Unten finden Sie die perf Einträge der ersten 10 Sekunden von ThoughtSpot, die auf einer gesunden (schnellen) Maschine (links) und im Container (rechts) ausgeführt werden.
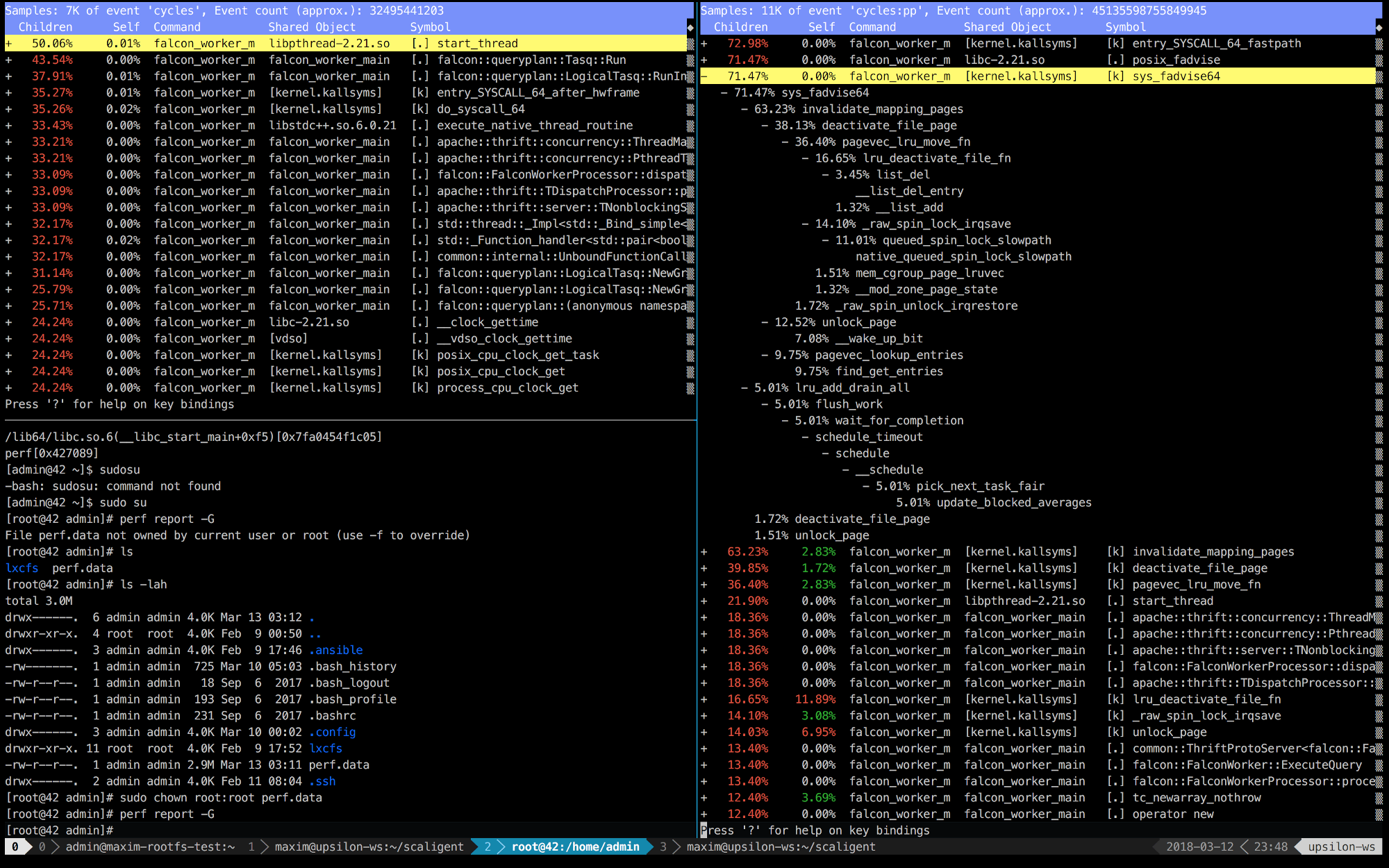
Es ist sofort klar, dass rechts die ersten 5 Aufrufe mit dem Kernel verbunden sind. Die Zeit wird hauptsächlich für den Kernel-Speicherplatz aufgewendet, während sie sich links befindet. Die meiste Zeit wird für unsere eigenen Prozesse aufgewendet, die im Benutzerbereich ausgeführt werden. Das Interessanteste ist jedoch, dass der Aufruf von posix_fadvise die ganze Zeit dauert.
Programme verwenden posix_fadvise () und erklären ihre Absicht, in Zukunft nach einem bestimmten Muster auf Dateidaten zuzugreifen. Dies gibt dem Kernel die Möglichkeit, die notwendige Optimierung durchzuführen.
Der Aufruf wird für alle Situationen verwendet und gibt daher die Ursache des Problems nicht explizit an. Beim Durchsuchen des Codes fand ich jedoch nur einen Ort, der theoretisch jeden Prozess im System betraf:
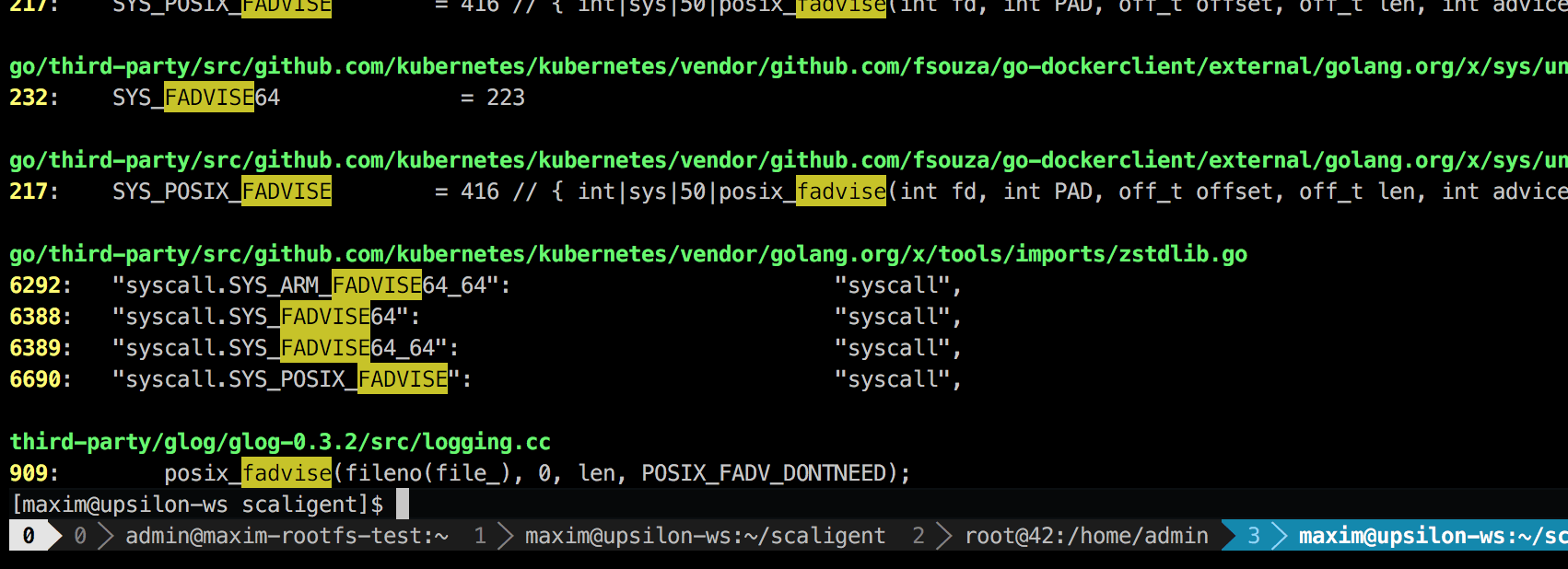
Dies ist eine Protokollierungsbibliothek eines Drittanbieters namens glog . Wir haben es für das Projekt verwendet. Insbesondere ist diese Zeile (in LogFileObject::Write ) wahrscheinlich der kritischste Pfad der gesamten Bibliothek. Es wird für alle Ereignisse "Protokoll zu Datei" (Protokoll zu Datei) und viele Instanzen unseres Produktprotokolls ziemlich oft aufgerufen. Ein kurzer Blick auf den Quellcode legt nahe, dass der Fadvise-Teil durch Setzen des Parameters --drop_log_memory=false deaktiviert werden kann:
if (file_length_ >= logging::kPageSize) {
was wir natürlich getan haben und ... im Bullauge!
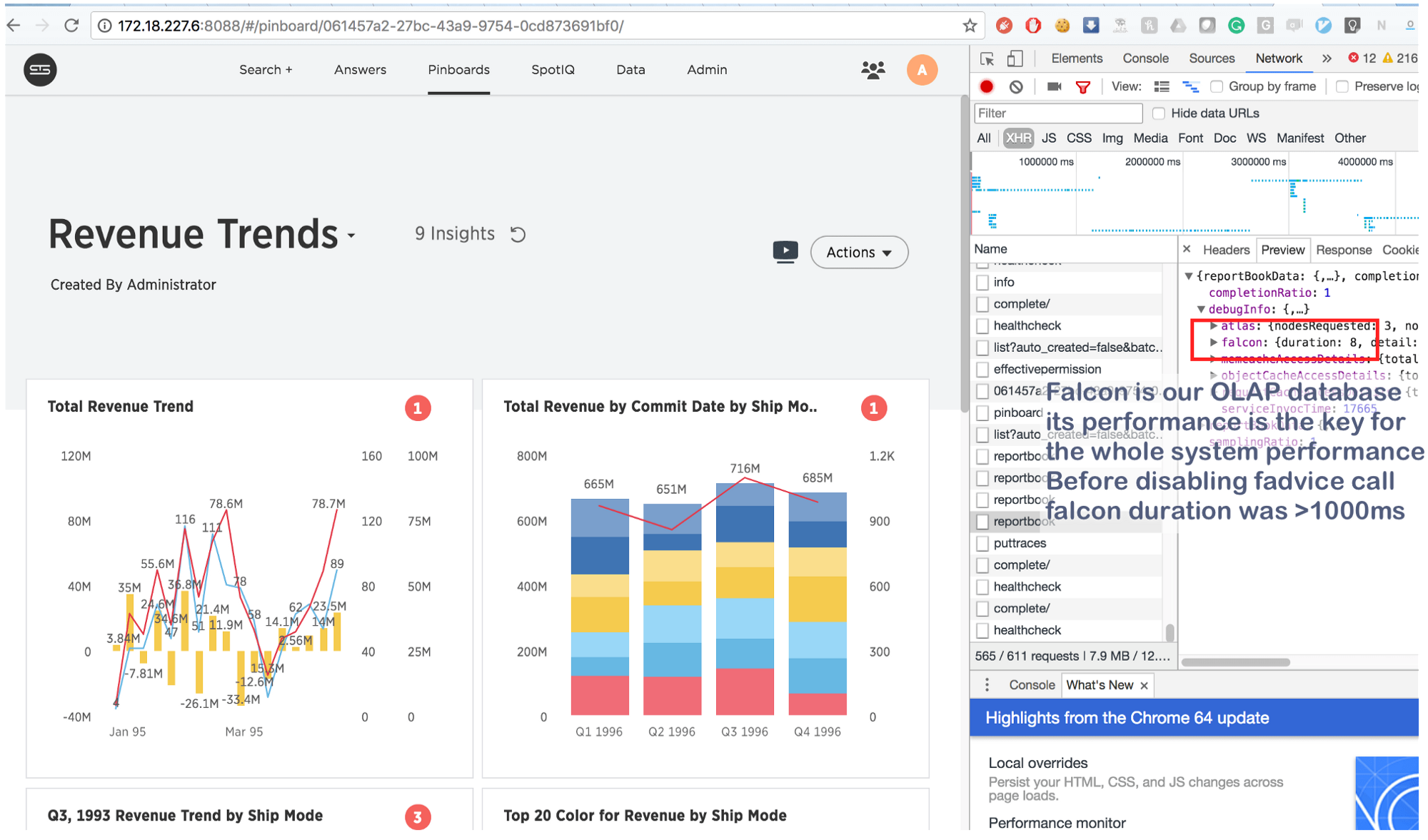
Was früher ein paar Sekunden dauerte, ist jetzt in 8 (acht!) Millisekunden erledigt. Ein wenig googeln, fanden wir dies: https://issues.apache.org/jira/browse/MESOS-920 und auch dies: https://github.com/google/glog/pull/145 , was erneut bestätigt wurde unsere Vermutung über die wahre Ursache der Hemmung. Höchstwahrscheinlich passierte dasselbe auf der virtuellen Maschine / dem Bare-Metal-System, aber da wir 1 Kopie des Prozesses pro Maschine / Kernel hatten, war die Intensität der Fadvise-Anrufe viel geringer, was den Mangel an zusätzlichem Ressourcenverbrauch erklärte. Als wir die Protokollierungsprozesse um das 3-4-fache erhöhten und einen gemeinsamen Kern für sie hervorhoben, stellten wir fest, dass Fadvise wirklich ins Stocken geriet.
Und zum Schluss:
Diese Informationen sind nicht neu, aber aus irgendeinem Grund vergessen viele Menschen die Hauptsache: In Fällen mit Containern konkurrieren „isolierte“ Prozesse um alle Kernressourcen und nicht nur um CPU , RAM , Speicherplatz und Netzwerk . Und da der Kernel eine äußerst komplexe Struktur ist, können Abstürze überall auftreten (wie zum Beispiel in __d_lookup_loop aus dem Sysdig-Artikel ). Dies bedeutet jedoch nicht, dass Container schlechter oder besser sind als herkömmliche Virtualisierung. Sie sind ein hervorragendes Werkzeug, um ihre Aufgaben zu lösen. Denken Sie daran: Der Kernel ist eine gemeinsam genutzte Ressource und bereiten Sie sich darauf vor, unerwartete Konflikte im Kernelbereich zu debuggen. Darüber hinaus bieten solche Konflikte Angreifern eine hervorragende Gelegenheit, die „verdünnte“ Isolation zu durchbrechen und verborgene Kanäle zwischen den Containern zu schaffen. Und schließlich gibt es perf - ein hervorragendes Tool, das zeigt, was im System passiert, und hilft, Leistungsprobleme zu beheben. Wenn Sie hochgeladene Anwendungen in Docker ausführen möchten, nehmen Sie sich Zeit, um perf zu lernen.