vorherige Kapitel
Lernkurven
28 Diagnose von Verzerrung und Streuung: Lernkurven
Wir haben verschiedene Ansätze zur Trennung von Fehlern in vermeidbare Verzerrungen und Streuungen untersucht. Dazu haben wir den optimalen Fehleranteil bewertet und Fehler an der Trainingsstichprobe des Algorithmus und an der Validierungsstichprobe berechnet. Lassen Sie uns einen informativeren Ansatz diskutieren: Lernkurvendiagramme.
Die Diagramme der Lernkurven sind die Abhängigkeiten des Fehleranteils von der Anzahl der Beispiele der Trainingsstichprobe.
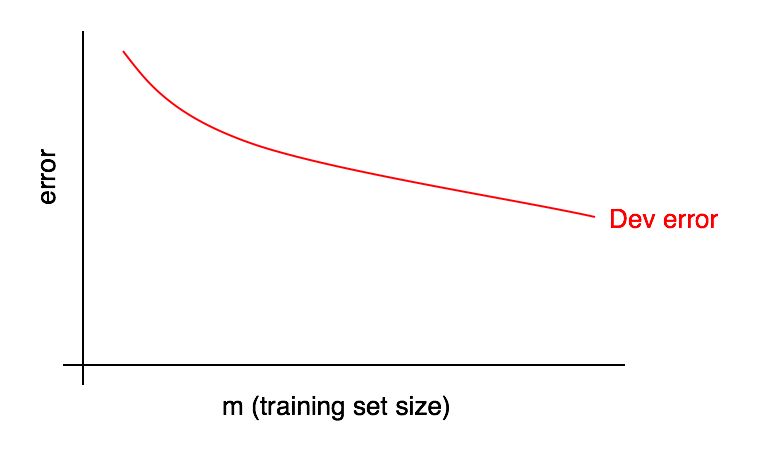
Mit zunehmender Größe der Trainingsstichprobe sollte der Fehler in der Validierungsstichprobe abnehmen.
Wir werden uns oft auf einen „gewünschten Anteil von Fehlern“ konzentrieren, von dem wir hoffen, dass er irgendwann unseren Algorithmus erreicht. Zum Beispiel:
- Wenn wir hoffen, ein für den Menschen zugängliches Qualitätsniveau zu erreichen, sollte der Anteil menschlicher Fehler zum „gewünschten Anteil von Fehlern“ werden.
- Wenn der Lernalgorithmus in einem Produkt (z. B. einem Katzenbildanbieter) verwendet wird, wissen wir möglicherweise, welches Qualitätsniveau Sie erreichen müssen, damit die Benutzer den größten Nutzen daraus ziehen können
- Wenn Sie lange an einer wichtigen Anwendung gearbeitet haben, haben Sie möglicherweise ein vernünftiges Verständnis dafür, welche Fortschritte Sie im nächsten Quartal / Jahr erzielen können.
Fügen Sie unserer Lernkurve das gewünschte Qualitätsniveau hinzu:

Sie können die rote Fehlerkurve im Validierungsbeispiel visuell extrapolieren und davon ausgehen, wie nahe Sie dem gewünschten Qualitätsniveau kommen können, indem Sie weitere Daten hinzufügen. In dem im Bild gezeigten Beispiel ist es wahrscheinlich, dass durch Verdoppeln der Größe des Trainingsmusters das gewünschte Qualitätsniveau erreicht wird.
Wenn jedoch die Kurve des Bruchteils des Fehlers der Validierungsprobe ein Plateau erreicht hat (d. H. Sich in eine gerade Linie parallel zur Abszissenachse verwandelt hat), zeigt dies sofort an, dass das Hinzufügen zusätzlicher Daten nicht zur Erreichung des Ziels beiträgt:
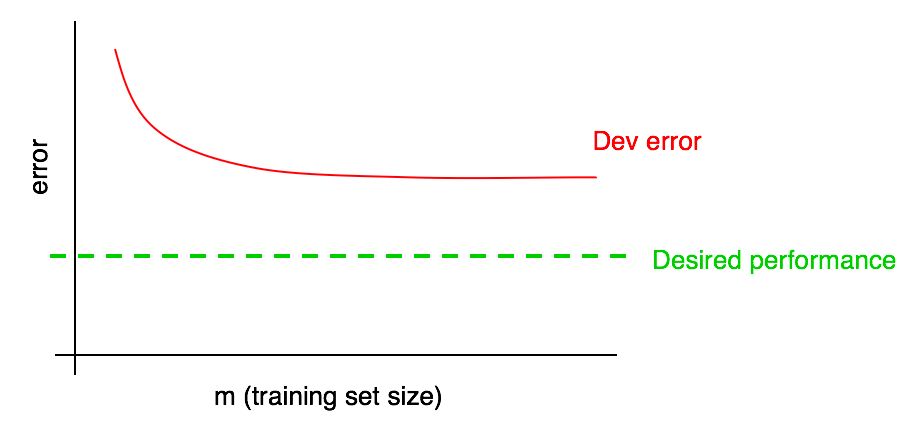
Ein Blick auf die Lernkurve kann Ihnen somit helfen, Monate damit zu verschwenden, doppelt so viele Trainingsdaten zu sammeln, nur um zu erkennen, dass das Hinzufügen nicht hilft.
Einer der Nachteile dieses Ansatzes besteht darin, dass es schwierig sein kann, das Verhalten der roten Kurve zu extrapolieren und genau vorherzusagen, wenn Sie weitere Daten hinzufügen, wenn Sie nur die Fehlerkurve in der Validierungsstichprobe betrachten. Daher gibt es ein weiteres zusätzliches Diagramm, mit dessen Hilfe die Auswirkungen zusätzlicher Trainingsdaten auf den Fehleranteil bewertet werden können: einen Lernfehler.
29 Trainingsfehlerdiagramm
Fehler in Validierungs- (und Test-) Proben sollten mit zunehmender Trainingsprobe abnehmen. Im Trainingsbeispiel wächst jedoch normalerweise der Fehler beim Hinzufügen von Daten.
Lassen Sie uns diesen Effekt anhand eines Beispiels veranschaulichen. Angenommen, Ihr Trainingsmuster besteht nur aus zwei Beispielen: Ein Bild mit Katzen und eines ohne Katzen. In diesem Fall kann sich der Lernalgorithmus leicht an beide Beispiele der Trainingsprobe erinnern und 0% Fehler in der Trainingsprobe anzeigen. Selbst wenn beide Trainingsbeispiele falsch beschriftet sind, kann sich der Algorithmus leicht an ihre Klassen erinnern.
Stellen Sie sich nun vor, Ihr Trainingsset besteht aus 100 Beispielen. Angenommen, eine bestimmte Anzahl von Beispielen ist falsch klassifiziert, oder es ist unmöglich, in einigen Beispielen eine Klasse festzulegen, beispielsweise in verschwommenen Bildern, wenn selbst eine Person nicht feststellen kann, ob eine Katze auf dem Bild vorhanden ist oder nicht. Angenommen, der Lernalgorithmus „merkt“ sich immer noch die meisten Beispiele für Trainingsbeispiele, aber jetzt ist es schwieriger, eine Genauigkeit von 100% zu erhalten. Wenn Sie die Trainingsstichprobe von 2 auf 100 Beispiele erhöhen, werden Sie feststellen, dass die Genauigkeit des Algorithmus in der Trainingsstichprobe allmählich abnimmt.
Angenommen, Ihr Trainingsset besteht am Ende aus 10.000 Beispielen. In diesem Fall wird es für den Algorithmus zunehmend schwieriger, alle Beispiele ideal zu klassifizieren, insbesondere wenn der Trainingssatz verschwommene Bilder und Klassifizierungsfehler enthält. Daher funktioniert Ihr Algorithmus bei einem solchen Trainingsmuster schlechter.
Fügen wir unseren vorherigen ein Lernfehlerdiagramm hinzu.
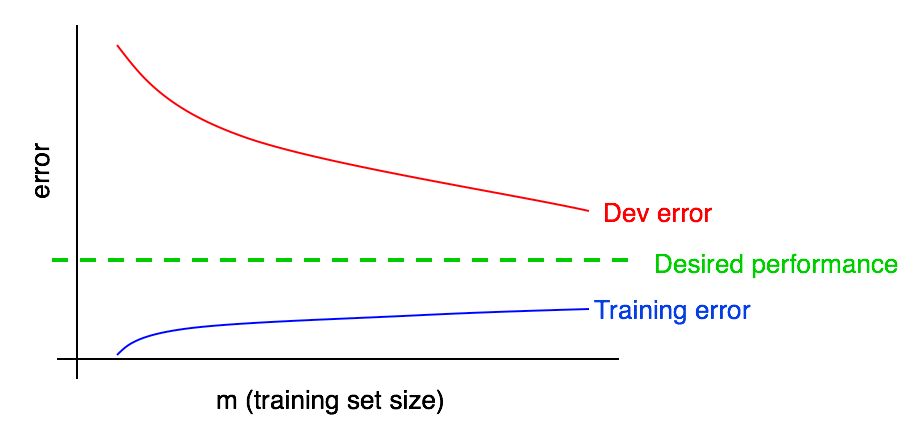
Sie können sehen, dass die blaue Kurve „Lernfehler“ mit zunehmender Trainingsstichprobe wächst. Darüber hinaus zeigt ein Lernalgorithmus in einer Trainingsprobe normalerweise eine bessere Qualität als in einer Validierungsprobe. Somit liegt die rote Fehlerkurve in der Validierungsprobe streng über der blauen Fehlerkurve in der Trainingsprobe.
Lassen Sie uns als Nächstes diskutieren, wie diese Diagramme interpretiert werden.
Fortsetzung