Es gibt eine so beliebte Klasse von Aufgaben, bei denen es notwendig ist, eine ziemlich gründliche Analyse des gesamten Volumens der von einem Informationssystem (IS) aufgezeichneten Arbeitsketten durchzuführen. Als IP kann es einen Dokumentenfluss, einen Service Desk, einen Bugtracker, ein elektronisches Journal, eine Lagerabrechnung usw. geben. Die Nuancen manifestieren sich in Datenmodellen, APIs, Datenmengen und anderen Aspekten, aber die Prinzipien zur Lösung solcher Probleme sind ungefähr dieselben. Und der Rechen, auf den Sie treten können, ist auch sehr ähnlich.
Um diese Klasse von Problemen zu lösen, passt R perfekt. Aber um nicht enttäuschend mit den Schultern zu zucken, dass R gut sein kann, aber oh, sehr langsam, ist es wichtig, auf die Leistung der ausgewählten Datenverarbeitungsverfahren zu achten.
Es ist eine Fortsetzung früherer Veröffentlichungen .
Normalerweise ist ein oberflächlicher „Stirn“ -Ansatz nicht der effektivste. 99% der mit der Analyse und Verarbeitung von Daten verbundenen Aufgaben beginnen mit ihrem Import. In diesem kurzen Aufsatz werden wir die Probleme betrachten, die in der Grundphase des Imports von Daten mit Daten im json Format auftreten, am Beispiel einer typischen Aufgabe der "tiefen" Analyse von Jira-Installationsdaten. json unterstützt im Gegensatz zu csv ein komplexes Objektmodell, sodass das Parsen bei komplexen Strukturen sehr schwierig und langwierig werden kann.
Erklärung des Problems
Gegeben:
- jira wird im Softwareentwicklungsprozess als Task-Management-System und Bug-Tracker implementiert und verwendet.
- Es gibt keinen direkten Zugriff auf die Jira-Datenbank, die Interaktion erfolgt über die REST-API (Galvanic Isolation).
- Die zu verwendenden JSON-Dateien haben eine sehr komplexe Baumstruktur mit verschachtelten Tupeln, die zum Hochladen des gesamten Aktionsverlaufs erforderlich sind. Die Berechnung von Metriken erfordert eine relativ kleine Anzahl von Parametern, die über verschiedene Hierarchieebenen verteilt sind.
Ein Beispiel für einen regulären Jira Json in der Abbildung.
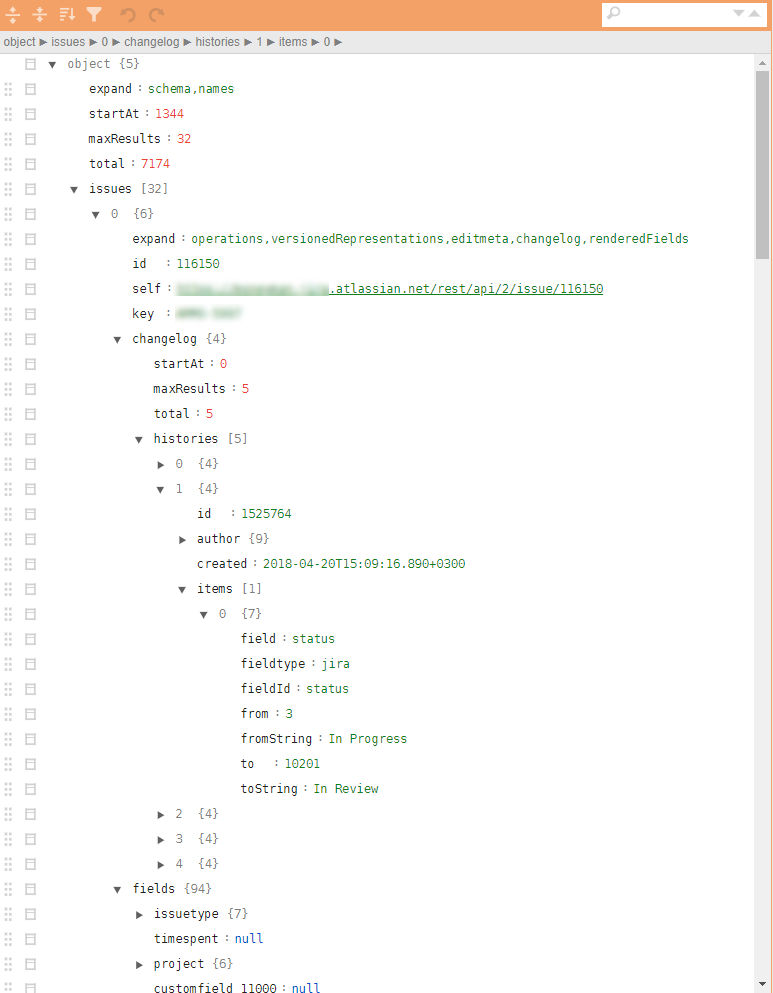
Es ist erforderlich:
- Basierend auf Jira-Daten ist es notwendig, Engpässe und Punkte einer möglichen Steigerung der Effizienz von Entwicklungsprozessen zu finden und die Qualität des resultierenden Produkts basierend auf einer Analyse aller registrierten Aktionen zu verbessern.
Lösung
Theoretisch gibt es in R verschiedene Pakete, um json zu laden und in data.frame zu data.frame . Das bequemste Paket ist jsonlite . Die direkte Konvertierung der data.frame Hierarchie in data.frame jedoch aufgrund der mehrstufigen Verschachtelung und der starken Parametrisierung der Datensatzstruktur schwierig. Das Festhalten an bestimmten Parametern, die sich beispielsweise auf die Geschichte der Aktionen beziehen, kann verschiedene ext. Checks and Loops. Das heißt, Die Aufgabe kann gelöst werden, aber für eine JSON-Datei mit 32 Aufgaben (einschließlich aller Artefakte und des gesamten Verlaufs der Aufgaben) dauert eine solche nichtlineare Analyse mit Jsonlite und Tidyverse auf einem Laptop mit durchschnittlicher Leistung ~ 10 Sekunden.
10 Sekunden allein sind nicht viel. Aber genau bis zu dem Moment, in dem es nicht zu viele dieser Dateien gibt. Die Auswertung einer Probe beim Parsen und Laden unter Verwendung einer ähnlichen "direkten" Methode ~ 4000 Dateien (~ 4 GB) ergab 8-9 Stunden Arbeit.
Eine so große Anzahl von Dateien erschien aus einem bestimmten Grund. Erstens hat Jira Zeitlimits für eine REST-Sitzung, es ist unmöglich, alles mit einem Strahl herauszuziehen. Zweitens wird erwartet, dass der tägliche Upload von Daten zu aktualisierten Aufgaben in den Produktivkreislauf integriert wird. Drittens, und dies wird weiter unten erwähnt, eignet sich die Aufgabe sehr gut für die lineare Skalierung, und Sie müssen vom ersten Schritt an über Parallelisierung nachdenken.
Selbst 10-15 Iterationen in der Phase der Datenanalyse, die Ermittlung des erforderlichen Mindestparametersatzes, die Erkennung außergewöhnlicher oder fehlerhafter Situationen und die Entwicklung von Nachbearbeitungsalgorithmen verursachen Kosten in Höhe von 2-3 Wochen (nur Zählzeit).
Natürlich ist eine solche „Leistung“ nicht für Betriebsanalysen geeignet, die in den Produktivkreislauf integriert sind, und ist in der Phase der anfänglichen Datenanalyse und Prototypenentwicklung sehr ineffektiv.
Ich überspringe alle dazwischenliegenden Details und wende mich sofort der Antwort zu. Wir erinnern uns an Donald Knuth, krempeln die Ärmel hoch und beginnen mit dem Mikrobenchen aller wichtigen Operationen, wobei wir rücksichtslos alles abschneiden, was möglich ist.
Die resultierende Lösung wird auf die folgenden 10 Linien reduziert (dies ist ein gefälschtes Skelett ohne nachfolgendes nicht funktionierendes Bodykit):
library(tidyverse) library(jsonlite) library(readtext) fnames <- fs::dir_ls(here::here("input_data"), glob = "*.txt") ff <- function(fname){ json_vec <- readtext(fname, text_field = "texts", encoding = "UTF-8") %>% .$text %>% jqr::jq('[. | {issues: .issues}[] | .[]', '{id: .id, key: .key, created: .fields.created, type: .fields.issuetype.name, summary: .fields.summary, descr: .fields.description}]') jsonlite::fromJSON(json_vec, flatten = TRUE) } tictoc::tic("Loading with jqr-jsonlite single-threaded technique") issues_df <- fnames %>% purrr::map(ff) %>% data.table::rbindlist(use.names = FALSE) tictoc::toc() system.time({fst::write_fst(issues_df, here::here("data", "issues.fst"))})
Was ist hier interessant?
- Um den Ladevorgang zu beschleunigen,
readtext es sich, spezielle, profilierte Pakete wie readtext . - Mit dem
jq Streaming-Parser können jq alle erforderlichen Attribute in eine funktionale Sprache übersetzen, auf die CPP-Ebene senken und die manuelle Bearbeitung verschachtelter Listen oder Listen in data.frame . - Ein vielversprechendes
bench für Mikrobenchmarks ist erschienen. Sie können damit nicht nur die Ausführungszeit von Operationen, sondern auch die Manipulation des Speichers untersuchen. Es ist kein Geheimnis, dass Sie beim Kopieren von Daten im Speicher viel verlieren können. - Für große Datenmengen und eine einfache Verarbeitung ist es bei der endgültigen Entscheidung häufig erforderlich, auf
tidyverse und die zeitaufwändigen Teile in data.table zu data.table . Insbesondere werden hier Tabellen mit data.table . Ebenso wie alle Transformationen in der Nachbearbeitungsphase (die im Zyklus durch die ff Funktion enthalten sind, die auch mittels data.table mit dem Ansatz der Datenänderung durch Referenz vorgenommen wurden, oder Pakete, die mit Rcpp , beispielsweise anytime Pakete zum Arbeiten mit Datums- und Rcpp . - Das
fst Paket eignet sich sehr gut zum fst und anschließenden Lesen von Daten in eine Datei. Insbesondere dauert es nur einen Bruchteil einer Sekunde, um alle Jira-Verlaufsanalysen 4 Jahre lang zu speichern, und die Daten werden genau wie die R-Datentypen gespeichert, was für ihre spätere Wiederverwendung gut ist.
Während der Lösung wurde ein Ansatz unter Verwendung des rjson Pakets in rjson . Die jsonlite::fromJSON ungefähr zweimal langsamer als rjson = rjson::fromJSON(json_vec) , musste jedoch rjson = rjson::fromJSON(json_vec) , da die Daten NULL-Werte enthalten und in der von rjson NULL in NA konvertiert werden Vorteil, und der Code wird schwerer.
Fazit
- Ein solches Refactoring führte zu einer Änderung der Verarbeitungszeit aller JSON-Dateien im Single-Thread-Modus auf demselben Laptop von 8 bis 9 Stunden auf 10 Minuten.
- Das Hinzufügen einer Parallelisierung der Aufgabe mit
foreach belastete den Code praktisch nicht (+ 5 Zeilen), reduzierte jedoch die Ausführungszeit auf 5 Minuten. - Durch das Übertragen der Lösung auf einen schwachen Linux-Server (nur 4 Kerne), das Ausführen auf einer SSD im Multithread-Modus wurde die Ausführungszeit auf 40 Sekunden reduziert.
- Durch die Veröffentlichung auf einer produktiven Schaltung (20 Kerne, 3 GHz, SSD) wurde die Ausführungszeit auf 6 bis 8 Sekunden reduziert, was für operative Analyseaufgaben mehr als akzeptabel ist.
Insgesamt gelang es im Rahmen der R-Plattform durch ein einfaches Code-Refactoring, die Ausführungszeit von ~ 9 Stunden auf ~ 9 Sekunden zu reduzieren.
Entscheidungen über R können sehr schnell sein. Wenn etwas für Sie nicht funktioniert, versuchen Sie es aus einem anderen Blickwinkel und mit neuen Techniken.
Vorherige Veröffentlichung - "Analytical Parachute for Manager" .