Im ersten Teil haben wir uns mit den Methoden der Domänenanpassung durch tiefes Lernen vertraut gemacht. Wir sprachen über die Hauptdatensätze sowie über diskrepanzbasierte und kontradiktorische nicht generative Ansätze. Diese Methoden eignen sich gut für einige Aufgaben. Und dieses Mal werden wir die komplexesten und vielversprechendsten kontradiktorischen Methoden analysieren: generative Modelle sowie Algorithmen, die die besten Ergebnisse im VisDA-Datensatz zeigen (Anpassungen von synthetischen Daten an reale Fotos).

Generative Modelle
Grundlage dieses Ansatzes ist die Fähigkeit des GAN, Daten aus der erforderlichen Verteilung zu generieren. Dank dieser Eigenschaft können Sie die richtige Menge synthetischer Daten abrufen und für Schulungen verwenden. Die Hauptidee von Methoden aus der Familie der generativen Modelle besteht darin, Daten unter Verwendung der Quelldomäne zu generieren, die den Vertretern der Zieldomäne so ähnlich wie möglich ist. Somit haben die neuen synthetischen Daten die gleichen Bezeichnungen wie die Vertreter der ursprünglichen Domäne, auf deren Grundlage sie erhalten wurden. Dann wird das Modell für die Zieldomäne einfach auf diesen generierten Daten trainiert.
Die auf der ICML-2018 eingeführte CyCADA: Cycle-Consistent Adversarial Domain Adaptation- Methode ( Code ) ist ein repräsentatives Mitglied der Familie der generativen Modelle. Es kombiniert mehrere erfolgreiche Ansätze aus GANs und Domänenanpassung. Ein wichtiger Teil davon ist die Verwendung des Verlusts der Zykluskonsistenz , der erstmals in einem Artikel über CycleGAN vorgestellt wurde . Die Idee des Verlusts der Zykluskonsistenz besteht darin, dass das Bild, das durch Erzeugen von der Quell- zur Zieldomäne, gefolgt von der inversen Transformation, erhalten wird, nahe am Anfangsbild liegen sollte. Darüber hinaus umfasst CyCADA eine Anpassung auf Pixelebene und auf der Ebene der Vektordarstellungen sowie einen semantischen Verlust, um die Struktur im generierten Bild zu speichern.
Lass fT und fS - Netzwerke für die Ziel- bzw. Quelldomäne XT und XS - Ziel- und Quelldomänen, YS - Markup auf der Quelldomäne, GS−>T und GT−>S - Generatoren von der Quelle zur Zieldomäne und umgekehrt, DT und DS - Diskriminatoren der Zugehörigkeit zur Ziel- bzw. Quelldomäne. Dann ist die Verlustfunktion, die in CyCADA minimiert wird, die Summe von sechs Verlustfunktionen (das Trainingsschema mit Verlustnummern ist unten dargestellt):
- LAufgabe(fT,GS−>T(XS),YS) - Modellklassifizierung fT auf generierte Daten und Pseudo-Labels aus der Quelldomäne.
- LGAN(GS−>T,DT,XT,XS) - Widersprüchlicher Verlust für das Generatortraining GS−>T .
- LGAN(GT−>S,DS,XS,XT) - Widersprüchlicher Verlust für das Generatortraining GT−>S .
- Lcyc(GS−>T,GT−>S,XS,XT) (Zykluskonsistenzverlust) - L1 -verlust, um sicherzustellen, dass Bilder von erhalten GS−>T und GT−>S wird in der Nähe sein.
- LGAN(fT,Dfeat,fS(GS−>T(XS)),XT) - Widersprüchlicher Verlust für Vektordarstellungen fT und fS auf die generierten Daten (ähnlich wie in ADDA verwendet).
- Lsem(GS−>T,GT−>S,XS,XT,fS) (semantischer Konsistenzverlust) - L1 Verlust, verantwortlich für die Tatsache, dass fS funktioniert ähnlich wie bei Bildern von GS−>T beide von GT−>S .
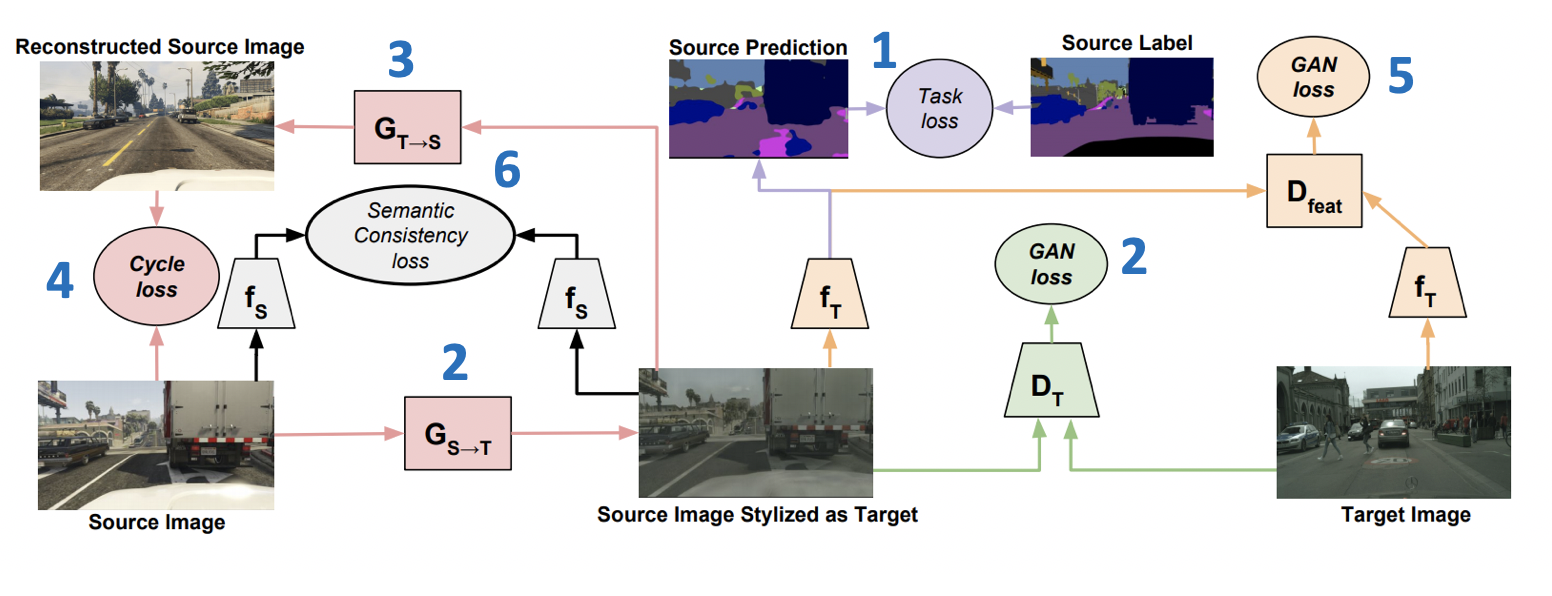
CyCADA-Ergebnisse:
- Auf einem Paar digitaler USPS-Domains -> MNIST: 95,7%.
- Zur Aufgabe der Segmentierung GTA 5 -> Stadtlandschaften: Mittlere IoU = 39,5%.
Als Teil des Ansatzes trainieren Generate To Adapt: Ausrichten von Domänen mithilfe von Generative Adversarial Networks ( Code ) einen solchen Generator G so dass am Ausgang Bilder in der Nähe der ursprünglichen Domäne erzeugt werden. So. G Mit dieser Option können Sie Daten aus der Zieldomäne konvertieren und den Klassifizierer, der auf die markierten Daten der Quelldomäne trainiert wurde, auf diese anwenden.
Um einen solchen Generator zu trainieren, verwenden die Autoren einen modifizierten Diskriminator D aus dem Artikel AC-GAN . Merkmal davon D liegt in der Tatsache, dass er nicht nur 1 antwortet, wenn die Eingabe aus der Quelldomäne stammt, und 0 sonst, sondern auch im Falle einer positiven Antwort die Eingabedaten nach den Klassen der Quelldomäne klassifiziert.
Wir bezeichnen F wie ein Faltungsnetzwerk, das eine Vektordarstellung eines Bildes erzeugt, C - Ein Klassifikator, der mit einem von abgeleiteten Vektor arbeitet F . Lern- und Inferenzalgorithmen:
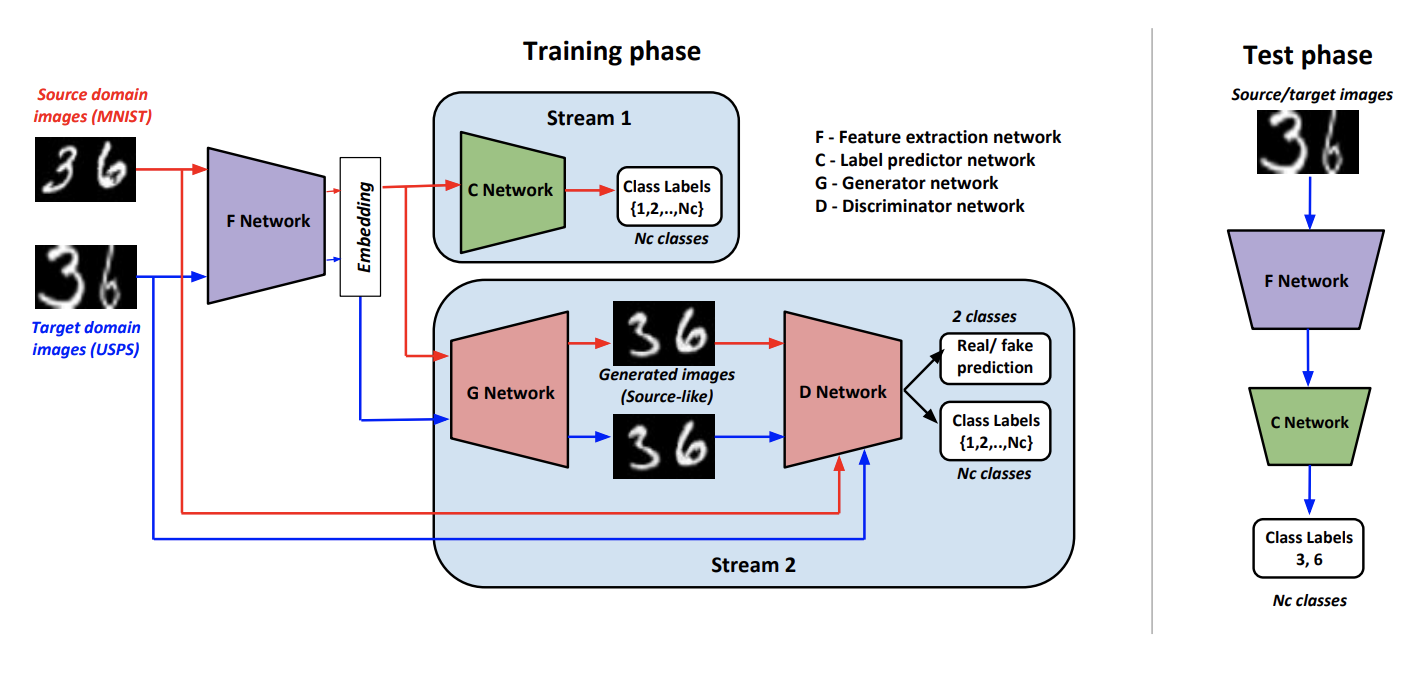
Das Trainingsverfahren besteht aus mehreren Komponenten:
- Diskriminator D lernt, die Domain für alle empfangenen von zu bestimmen G Daten und für die Quelldomäne wird weiterhin ein Klassifizierungsverlust hinzugefügt, wie oben beschrieben.
- Auf Daten aus der Quelldomäne G Unter Verwendung einer Kombination aus gegnerischem Verlust und Klassifizierungsverlust wird trainiert, um ein Ergebnis zu generieren, das der Quelldomäne ähnlich ist, und korrekt klassifiziert D .
- F und C Erfahren Sie, wie Sie Daten aus der Quelldomäne klassifizieren. Auch F Mit Hilfe eines weiteren Klassifizierungsverlusts wird dieser geändert, um die Qualität der Klassifizierung zu verbessern D .
- Verwendung von gegnerischem Verlust F lernt "betrügen" D auf Daten aus der Zieldomäne.
- Die Autoren kamen empirisch zu dem Schluss, dass vor der Einreichung bei G Es ist sinnvoll, einen Vektor aus zu verketten F mit normalem Rauschen und One-Hot-Class-Vektor ( K+1 für Zieldaten).
Die Ergebnisse der Methode auf Benchmarks:
- Auf digitalen USPS-Domains -> MNIST: 90,8%.
- Im Office-Dataset beträgt die durchschnittliche Anpassungsqualität für Paare von Amazon- und Webcam-Domänen 86,5%.
- Im VisDA-Datensatz beträgt der durchschnittliche Qualitätswert für 12 Kategorien ohne unbekannte Klasse 76,7%.
In dem Artikel Von der Quelle zum Ziel und zurück: Symmetrisches bidirektionales adaptives GAN ( Code ) wurde das SBADA-GAN-Modell vorgestellt, das CyCADA sehr ähnlich ist und dessen Zielfunktion wie CyCADA aus 6 Komponenten besteht. In der Notation der Autoren Gst und Gts - Generatoren von der Quelldomäne zum Ziel und umgekehrt, Ds und Dt - Diskriminatoren, die reale Daten von den in der Quell- bzw. Zieldomäne generierten unterscheiden; Cs und Ct - Klassifizierer, die auf Daten aus der Quelldomäne und auf ihre in die Zieldomäne transformierten Versionen trainiert werden.
SBADA-GAN verwendet wie CyCADA die Idee von CycleGAN, Konsistenzverlust und Pseudo-Labels für die in der Zieldomäne generierten Daten und setzt die Zielfunktion aus den entsprechenden Begriffen zusammen. Die Funktionen von SBADA-GAN umfassen:
- Das Bild + Rauschen wird dem Eingang der Generatoren zugeführt.
- Der Test verwendet eine lineare Kombination von Vorhersagen des Zielmodells und des Quellmodells basierend auf der Transformation Gst .
SBADA-GAN-Schulungsprogramm:
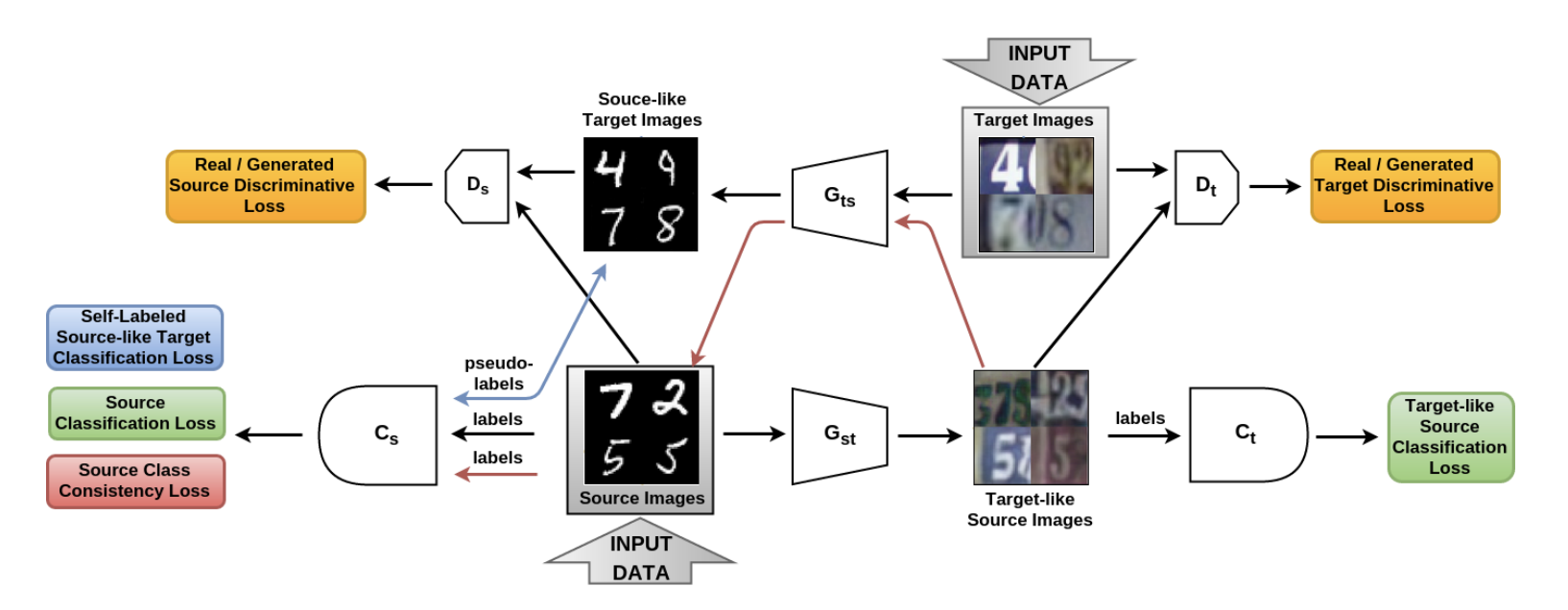
Die Autoren von SBADA-GAN führten mehr Experimente durch als die Autoren von CyCADA und erzielten die folgenden Ergebnisse:
- Auf USPS -> MNIST-Domains: 95,0%.
- Auf den MNIST -> SVHN-Domänen: 61,1%.
- Auf Verkehrszeichen Synth Signs -> GTSRB: 97,7%.
Aus der Familie der generativen Modelle ist es sinnvoll, die folgenden wichtigen Artikel zu betrachten:
Herausforderung zur Anpassung der visuellen Domäne
Im Rahmen des Workshops veranstalten ECCV- und ICCV-Konferenzen einen Domain-Anpassungswettbewerb zur Visual Domain Adaptation Challenge . Darin werden die Teilnehmer aufgefordert, den Klassifikator auf synthetische Daten zu schulen und ihn an nicht zugewiesene Daten aus ImageNet anzupassen.
Der in Self-Ensembling für die visuelle Domänenanpassung ( Code ) vorgestellte Algorithmus wurde in VisDA-2017 gewonnen. Diese Methode basiert auf der Idee der Selbstorganisation: Es gibt ein Lehrernetzwerk (Lehrermodell) und ein Schülernetzwerk. Bei jeder Iteration wird das Eingabebild durch diese beiden Netzwerke ausgeführt. Der Schüler wird anhand der Summe aus Klassifizierungsverlust und Konsistenzverlust trainiert, wobei Klassifizierungsverlust die übliche Kreuzentropie mit einem bekannten Klassenlabel ist und Konsistenzverlust die durchschnittliche quadratische Differenz zwischen den Vorhersagen des Lehrers und des Schülers ist (quadratische Differenz). Die Gewichte des Lehrernetzwerks werden als exponentieller gleitender Durchschnitt der Gewichte des Schülernetzwerks berechnet. Dieses Trainingsverfahren ist unten dargestellt.
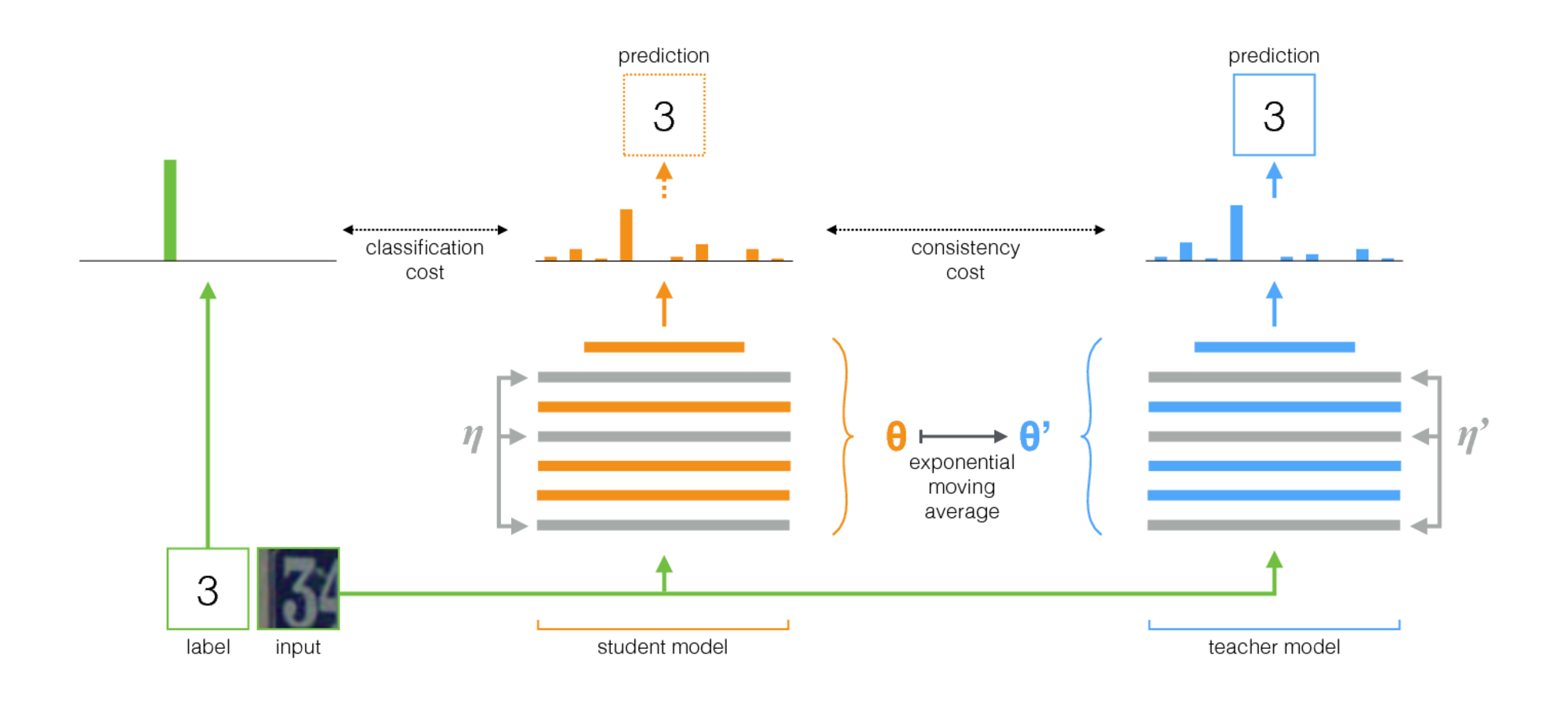
Wichtige Merkmale der Anwendung dieser Methode zur Domänenanpassung sind:
- Im Trainingsstapel werden Daten aus der Quelldomäne gemischt xSi mit Klassenbezeichnungen ySi und Daten aus der Zieldomäne xTi ohne Tags.
- Vor der Eingabe von Bildern in die neuronalen Netze werden verschiedene starke Erweiterungen angewendet: Gaußsche Rauschen, affine Transformationen usw.
- Beide Netzwerke verwendeten starke Regularisierungsmethoden (z. B. Dropout).
- zTi - Studentennetzwerkausgabe, widetildezTi - Netzwerklehrer. Wenn die Eingabe von der Zieldomäne stammte, dann nur der Konsistenzverlust zwischen zTi und widetildezTi Kreuzentropieverlust = 0.
- Für die Nachhaltigkeit des Lernens wird die Vertrauensschwelle verwendet: Wenn die Vorhersage des Lehrers unter der Schwelle (0,9) liegt, ist der Verlust des Konsistenzverlusts = 0.
Schema des beschriebenen Verfahrens:

Bei den Hauptdatensätzen erzielte der Algorithmus eine hohe Leistung. Zwar haben die Autoren für jede Aufgabe separat eine Reihe von Erweiterungen ausgewählt.
- USPS -> MNIST: 99,54%.
- MNIST -> SVHN: 97,0%.
- Synth Numbers -> SVHN: 97,11%.
- Auf Verkehrszeichen Synth Signs -> GTSRB: 99,37%.
- Im VisDA-Datensatz beträgt der durchschnittliche Qualitätswert für 12 Kategorien ohne die unbekannte Klasse 92,8%. Es ist wichtig zu beachten, dass dieses Ergebnis unter Verwendung eines Ensembles von 5 Modellen und unter Verwendung der Testzeitvergrößerung erhalten wurde.
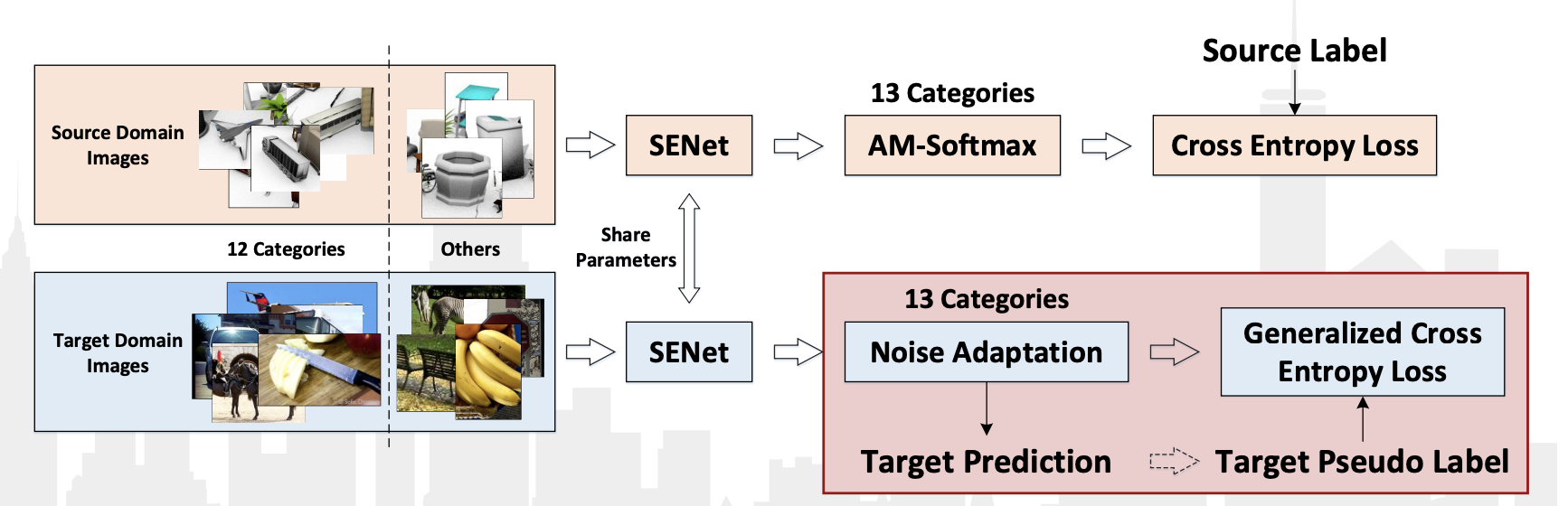
Der VisDA-2018- Wettbewerb fand dieses Jahr im Rahmen der ECCV-2018-Konferenz statt. Diesmal fügten sie die 13. Klasse hinzu: Unbekannt, die alles bekam, was nicht in 12 Klassen fiel. Darüber hinaus wurde ein separater Wettbewerb durchgeführt, um Objekte dieser 12 Klassen zu ermitteln. In beiden Kategorien gewann das chinesische Team JD AI Research . Beim Klassifizierungswettbewerb erreichten sie ein Ergebnis von 92,3% (der durchschnittliche Qualitätswert in 13 Kategorien). Es gibt keine Veröffentlichungen mit einer detaillierten Beschreibung ihrer Methode, es gibt nur eine Präsentation aus dem Workshop .
Von den Merkmalen ihres Algorithmus können festgestellt werden:
- Verwenden von Pseudo-Labels für Daten aus der Zieldomäne und Umschulung des Klassifikators auf diesen zusammen mit Daten aus der Quelldomäne.
- Unter Verwendung des Faltungsnetzwerks SE-ResNeXt-101, AM-Softmax und Noise Adaption Layer, Generalisierter Kreuzentropieverlust für Daten aus der Zieldomäne.
Algorithmusdiagramm aus der Präsentation:
Fazit
Zum größten Teil haben wir Anpassungsmethoden diskutiert, die auf dem kontradiktorischen Ansatz basieren. In den letzten beiden VisDA-Wettbewerben haben jedoch Algorithmen gewonnen, die nicht damit zusammenhängen und die das Training auf Pseudo-Labels und Modifikationen klassischerer Deep-Learning-Methoden verwenden. Meiner Meinung nach liegt dies daran, dass auf GANs basierende Methoden erst am Anfang ihrer Entwicklung stehen und äußerst instabil sind. Aber jedes Jahr erhalten wir mehr und mehr neue Ergebnisse, die die Arbeit von GANs verbessern. Darüber hinaus liegt der Schwerpunkt des Interesses der wissenschaftlichen Gemeinschaft auf dem Gebiet der Domänenanpassung hauptsächlich auf kontradiktorischen Methoden, und neue Artikel untersuchen hauptsächlich diesen Ansatz. Daher ist es wahrscheinlich, dass die mit GANs verbundenen Algorithmen bei Anpassungsproblemen allmählich in den Vordergrund treten.
Es wird aber auch an nicht kontradiktorischen Ansätzen geforscht. Hier einige interessante Artikel aus diesem Bereich:
Diskrepanzbasierte Methoden können als „historisch“ klassifiziert werden, aber viele der Ideen, die in den neuesten Methoden verwendet werden: MMD, Pseudo-Labels, metrisches Lernen usw. Darüber hinaus ist es manchmal bei einfachen Anpassungsproblemen sinnvoll, diese Methoden anzuwenden, da sie relativ einfach zu trainieren sind und die Ergebnisse besser interpretierbar sind.
Abschließend möchte ich festhalten, dass die Methoden der Domänenanpassung immer noch nach ihrer Anwendung in angewandten Bereichen suchen, aber es gibt allmählich immer vielversprechendere Aufgaben, die den Einsatz von Anpassung erfordern. Beispielsweise wird die Domänenanpassung beim Training autonomer Automodule aktiv eingesetzt: Da das Sammeln realer Daten auf Stadtstraßen für das Training von Autopiloten teuer und zeitaufwändig ist, verwenden autonome Autos synthetische Daten (insbesondere SYNTHIA- und GTA 5-Datenbanken). um das Problem der Segmentierung dessen zu lösen, was die Kamera vom Auto „sieht“.
Das Erhalten hochwertiger Modelle, die auf einer eingehenden Schulung in Computer Vision basieren, hängt weitgehend von der Verfügbarkeit großer beschrifteter Datensätze für die Schulung ab. Markup erfordert fast immer viel Zeit und Geld, was den Entwicklungszyklus von Modellen und damit von darauf basierenden Produkten erheblich verlängert.
Die Methoden der Domänenanpassung zielen auf die Lösung dieses Problems ab und können möglicherweise zu einem Durchbruch bei vielen angewandten Problemen und bei der künstlichen Intelligenz im Allgemeinen beitragen. Der Wissenstransfer von einer Domäne in eine andere ist eine wirklich schwierige und interessante Aufgabe, die derzeit aktiv untersucht wird. Wenn Sie bei Ihren Aufgaben unter Datenmangel leiden und Daten emulieren oder ähnliche Domänen finden können, empfehle ich, Methoden zur Domänenanpassung auszuprobieren!