Velocity ist eine Konferenz für verteilte Systeme. Es wird vom O'Reilly-Verlag organisiert und findet dreimal im Jahr statt: einmal in Kalifornien, einmal in New York und einmal in Europa (und die Stadt wechselt jedes Jahr).
2018 fand die Konferenz vom 30. Oktober bis 2. November in London statt. Das Hauptbüro von Badoo befindet sich dort, daher hatten meine Kollegen und ich zwei Gründe, zu Velocity zu gehen.
Ihr Gerät erwies sich als etwas komplizierter als das, auf das ich auf russischen Konferenzen gestoßen bin. Zusätzlich zu den üblichen zwei Präsentationstagen gab es zwei weitere Trainingstage, die vollständig, teilweise oder gar nicht absolviert werden können. Zusammen wird dies zu einer ernsthaften Suche nach der Art des Tickets, das Sie benötigen.
In dieser Rezension werde ich über die Berichte und Meisterklassen sprechen, an die ich mich erinnere. Ich füge einigen Berichten Links zu zusätzlichen Materialien hinzu. Teilweise handelt es sich um Materialien, auf die sich die Autoren bezogen, und teilweise um Materialien für weitere Studien, die ich selbst gefunden habe.
Der allgemeine Eindruck der Konferenz: Die Autoren schneiden sehr gut ab (und Keynote-Sessions sind eine ganze Show mit Rednern, die die Musik präsentieren und auf die Bühne gehen), aber gleichzeitig stieß ich auf einige Berichte, die aus technischer Sicht tiefgreifend waren.
Das heißeste Thema dieser Konferenz ist Kubernetes , das in fast jedem zweiten Bericht erwähnt wird.
Die Arbeit mit sozialen Netzwerken ist sehr gut aufgebaut: Im offiziellen Twitter-Account während der Konferenz gab es viele operative Retweets mit Berichten. Dies ermöglichte einen kurzen Blick auf das, was in anderen Räumen geschah.
Meisterkurse
Der 31. Oktober war der Tag, an dem es keine Berichte gab, aber es gab sechs oder acht Meisterklassen mit jeweils drei Stunden reiner Zeit, von denen zwei ausgewählt werden mussten.
PS Im Original werden sie als Tutorial bezeichnet, aber es scheint mir richtig, sie als "Meisterklasse" zu übersetzen.
Chaos Engineering Bootcamp
Moderatorin: Ana Medina , Ingenieurin bei Gremlin | Beschreibung
Der Workshop war der Einführung von Chaos Engineering gewidmet. Ana erzählte fließend, was es ist, welche Vorteile es bringt, zeigte, wie es verwendet werden kann, welche Software helfen kann und wie man es in einem Unternehmen einsetzt.
Im Allgemeinen war dies eine gute Einführung für Anfänger, aber ich mochte den praktischen Teil nicht wirklich, nämlich die Bereitstellung einer Demo-Webanwendung in einem Cluster von mehreren Computern unter Verwendung von Kubernetes und die Überwachung von DataDog . Das Hauptproblem war, dass wir fast die Hälfte der Zeit der Meisterklasse damit verbracht haben und es nur notwendig war, 5-10 Minuten lang mit Skripten zu spielen, die verschiedene Probleme im Cluster emulieren, und die Änderungen in den Grafiken zu betrachten.
Es scheint mir, dass es für den gleichen Effekt ausreichte, Zugriff auf einen vorkonfigurierten DataDog zu gewähren und / oder alles von der Szene aus zu demonstrieren, und diese Zeit sollte zum Beispiel für eine detailliertere Überprüfung und Beispiele für die Verwendung desselben Chaos-Affen verwendet werden, über die gerade wörtlich gesprochen wurde ein paar Sätze.


Interessant: Auf dieser Konferenz erwähnten die Redner oft den Begriff "Explosionsradius", den ich vorher nicht gesehen hatte. Sie haben den Teil des Systems festgelegt, der betroffen ist, wenn ein bestimmtes Problem auftritt.
Zusätzliche Materialien:
Aufbau einer evolutionären Infrastruktur
Moderator: Kief Morris , Infrastrukturberater und Autor von Infrastruktur als Code | Beschreibung
Die Hauptpunkte der Meisterklasse können auf zwei Dinge reduziert werden:
- Die Systeme ändern sich ständig, daher muss sich auch die Infrastruktur ändern.
- Sobald sich die Infrastruktur ändert, müssen Sie sicherstellen, dass sie einfach und sicher ist. Dies kann nur durch Automatisierung erreicht werden.
Der Hauptteil seiner Geschichte war speziell der Automatisierung von Infrastrukturänderungen, möglichen Lösungen für dieses Problem und dem Testen von Änderungen gewidmet. Ich bin kein Experte in diesem Thema, aber es schien mir, dass er sehr sicher und ausführlich (und sehr schnell) sprach.
Der Hauptpunkt, an den ich mich aus dieser Meisterklasse erinnere, ist die Empfehlung, die Unterscheidung zwischen Umgebungen (Produktion, Staging usw.) vom Code in Umgebungsvariablen zu maximieren. Dies verringert die Wahrscheinlichkeit von Fehlern in der Infrastruktur beim Ändern der Umgebung und macht sie testbarer.



Berichte
Der 1. und 2. November waren Tage der Berichte. Sie waren in zwei Hauptblöcke unterteilt: eine Reihe von drei oder vier kurzen Keynote-Berichten, die morgens in einem Strom abliefen (und für sie eine große Halle, die aus zwei kleineren bestand), und längere thematische Berichte in fünf Abläufen, die den Rest des Tages dauerten . Tagsüber gab es mehrere große Pausen zwischen den Berichten, in denen es möglich war, mit den Ständen der Konferenzpartner auf der Messe herumzulaufen.
Entwicklung des Runtastic Backend
Simon Lasselsberger (Runtastic GmbH) | Beschreibung und Folien
Einer der wenigen Berichte, in denen der Autor nicht nur erklärte, wie man etwas macht, sondern Details eines bestimmten Projekts und was mit ihm passiert ist.
Am Anfang hatte Runtastic eine gemeinsame Percona Server-Datenbank und einen Monolithen mit Code für mobile Anwendungen und eine Site. Dann fingen sie an, in Cassandra (ich weiß nicht mehr, warum es darin war) den Teil der Daten zu schreiben, für den der Schlüsselwert des Speichers ausreichte. Allmählich wurde die Datenbank aufgedunsen und sie fügten MongoDB hinzu, in das sie Daten von den meisten Diensten zu schreiben begannen. Im Laufe der Zeit haben sie eine allgemeine Ebene erstellt, die Anfragen sowohl aus dem Web als auch aus mobilen Anwendungen bedient (so etwas wie unsere App , wie ich es verstehe).
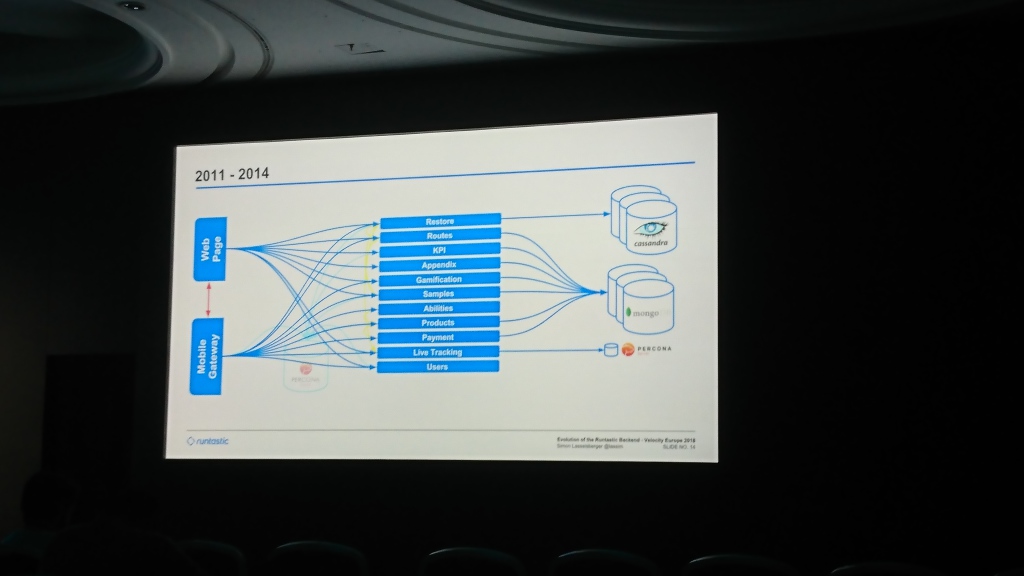
Der größte Teil des Berichts war dem Wechsel zwischen Rechenzentren gewidmet. Zunächst wurde der Server in Hetzner gehalten, der nach einiger Zeit als unzureichend stabil galt und die Daten auf T-Systems migrierten. Einige Jahre später hatten sie bereits Platzmangel und wechselten erneut zur Linz AG. Der interessanteste Teil hier ist die Datenmigration. Sie fingen an, Daten zu kopieren, die mehrere Monate dauerten. Sie konnten nicht so lange warten, weil Ihnen ging der Speicherplatz aus und sie konnten ihn nicht hinzufügen. Daher haben sie den Code zurückgesetzt, der versuchte, Daten aus dem alten Rechenzentrum zu lesen, wenn sie nicht im neuen waren.
In Zukunft planen sie, die Daten in mehrere separate Rechenzentren aufzuteilen (Simon sagte mehrmals, dass dies für Russland und China erforderlich ist) und die Datenbanken starr nach separaten Diensten aufzuteilen (jetzt wird für alle Dienste ein gemeinsamer Pool verwendet).
Ein interessanter Ansatz für den Entwurf von Modulen in einem System, über den Simon beiläufig sprach: hexagonale Architektur .
Ermöglichen Sie, dass eine Anwendung gleichermaßen von Benutzern, Programmen, automatisierten Test- oder Batch-Skripten gesteuert und isoliert von ihren eventuellen Laufzeitgeräten und Datenbanken entwickelt und getestet wird.
Alistair Cockburn
Zusätzliche Materialien:
Überwachen von benutzerdefinierten Metriken; oder, wie ich gelernt habe, zuerst zu instrumentieren und später Fragen zu stellen
Maxime Petazzoni (SignalFx) | Beschreibung und Darstellung
Die Geschichte widmete sich dem Sammeln der Metriken, die zum Verständnis der Anwendung erforderlich sind. Die Hauptbotschaft war, dass die üblichen ROTEN Metriken (Rate, Fehler und Dauer) nicht ausreichen. Außerdem müssen Sie sofort andere sammeln, um zu verstehen, was in der Anwendung geschieht.
Zusammenfassend schlug der Autor vor, Zähler und Zeitgeber für einige wichtige Aktionen im System (und notwendigerweise für Fehlerzähler) zu sammeln, daraus Diagramme und Histogramme der Verteilung zu erstellen und ein Metamodell für Benutzermetriken zu bestimmen (sodass verschiedene Metriken den gleichen Satz erforderlicher Parameter haben und die gleichen Bedeutungen wurden überall gleich genannt).

Es ist ziemlich schwierig, Details in Worten nacherzählen zu können. Es ist einfacher, Details und Beispiele in der Präsentation zu sehen. Ein Link dazu befindet sich auf der Berichtsseite auf der Konferenzwebsite.
Zusätzliche Materialien:
Wie serverlos die IT-Abteilung verändert
Paul Johnston (Kreisverkehr Labs) | Beschreibung und Darstellung
Der Autor stellte sich als CTO und Umweltschützer vor und sagte, dass Serverless keine technologische, sondern eine Geschäftslösung sei ("Sie zahlen nichts, wenn es nicht verwendet wird"). Anschließend beschrieb er die Best Practices für die Arbeit mit Serverless, welche Kompetenzen für die Arbeit mit ihm erforderlich sind und wie sich dies auf die Auswahl neuer Mitarbeiter und die Arbeit mit bestehenden Mitarbeitern auswirkt.

Der entscheidende Moment des „Einflusses auf die IT-Abteilung“, an den ich mich erinnerte, war die Verlagerung der erforderlichen Kompetenzen vom Schreiben von Code zum Arbeiten mit der Infrastruktur und ihrer Automatisierung („Mehr“ Engineering “als„ Entwickeln “). Alles andere war ziemlich banal (Sie müssen es ständig ausführen Codeüberprüfung, um die Datenströme und Ereignisse zu dokumentieren, die für die Verwendung im System verfügbar sind, um mehr zu kommunizieren und schnell zu lernen), aber aus irgendeinem Grund führte der Autor sie auf die serverlosen Funktionen zurück.

Insgesamt wirkte der Bericht etwas gemischt. Viele der Dinge, über die der Sprecher sprach, können auf jedes komplexe System zurückgeführt werden, das nicht vollständig in den Kopf passt.
Zusätzliche Materialien:
Keine Panik! Wie Sie jetzt damit umgehen, dass Sie für die Produktion verantwortlich sind
Euan Finlay (Financial Times) | Beschreibung und Darstellung
Ein Bericht über den Umgang mit Produktionsvorfällen, wenn gerade etwas schief geht. Die Hauptpunkte wurden nach Zeit in Teile unterteilt.
Vor dem Vorfall:
- Unterscheiden Sie Warnungen nach Kritikalität - vielleicht können einige warten, und Sie müssen sich nicht dringend mit ihnen befassen.
- Erstellen Sie im Voraus einen Plan zur Analyse von Vorfällen und halten Sie die Dokumentation auf dem neuesten Stand.
- Übungen durchführen - etwas kaputt machen und sehen, was passiert (auch bekannt als Chaos Engineering);
- Richten Sie einen einzigen Ort ein, an dem alle Informationen zu Änderungen und Problemen zusammenkommen.
Während des Vorfalls:
- Es ist normal, dass Sie nicht alles wissen - ziehen Sie bei Bedarf andere Personen an.
- Einrichtung eines einzigen Ortes für die Kommunikation zwischen Personen, die an der Lösung des Vorfalls arbeiten;
- Suchen Sie nach der einfachsten Lösung, die die Produktion wieder in einen funktionsfähigen Zustand versetzt, und versuchen Sie nicht, das Problem vollständig zu lösen.
Nach dem Vorfall:
- Finden Sie heraus, warum das Problem aufgetreten ist und was es Ihnen beigebracht hat.
- Es ist wichtig, einen Bericht darüber zu schreiben ("Vorfallbericht").
- Identifizieren Sie, was verbessert werden kann, und planen Sie spezifische Maßnahmen.
Am Ende erzählte Ewan eine lustige Geschichte über den Vorfall in der Financial Times, die entstand, weil die Produktionsbasis ( Prod genannt ) fälschlicherweise anstelle der Vorproduktion ( pprod ) geändert wurde , und empfahl, solche ähnlichen Namen zu vermeiden.
Aus dem Netz des Lebens lernen (Keynote)
Claire Janisch (BiomimicrySA) | Beschreibung
Ich war zu spät für diesen Bericht, aber auf Twitter haben sie sehr gut darüber gesprochen. Sie müssen sehen, ob es rüberkommt.
Ein Video mit einem Fragment der Rede kann auf der Konferenzwebsite angesehen werden .
Jane Adams (Zwei Sigma-Investitionen) | Beschreibung
Philosophischer Bericht zum Thema "Können wir Entscheidungsalgorithmen vertrauen?" Die allgemeine Schlussfolgerung war, dass dies nicht der Fall war: Der Algorithmus kann bestimmte Metriken optimieren, wirkt sich jedoch gleichzeitig ernsthaft auf das aus, was schwer zu messen ist oder außerhalb dieser Metriken liegt (beispielsweise wurde der Algorithmus für die Einstellung von Mitarbeitern bei Amazon diskriminiert, was sich negativ auf die Unternehmenskultur auswirkte und gezwungen, diesen Algorithmus aufzugeben).
Die Freiheit der Kubernetes (Keynote)
Kris Nova | Beschreibung
Von dort erinnerte ich mich an zwei Gedanken:
- Flexibilität ist nicht Freiheit, sondern Chaos;
- Komplexität an sich ist kein Problem, wenn sie einen Wert trägt (im Original wurde sie als "notwendige Komplexität" bezeichnet), der die Kosten dieser Komplexität übersteigt.
Der Bericht war ziemlich philosophisch, daher konnte ich einerseits nicht viel daraus machen, andererseits galt das, was ich herausbrachte, nicht nur für Kubernetes.

Was ändert sich, wenn wir zuerst offline gehen? (Keynote)
Martin Kleppmann (Universität Cambridge), Autor von Designing Data-Intensive Applications | Beschreibung
Der Bericht bestand aus zwei logischen Teilen: Im ersten Teil sprach Martin über das Problem der Synchronisierung von Daten untereinander, die in mehreren Quellen unabhängig voneinander geändert werden können, und im zweiten Teil sprach er über mögliche Lösungen und Algorithmen, die hierfür verwendet werden können ( Operational Transformation , OT) und konfliktfreier replizierter Datentyp (CRDT)) und schlug seine Lösung vor - die Automerge-Bibliothek zur Lösung solcher Probleme.
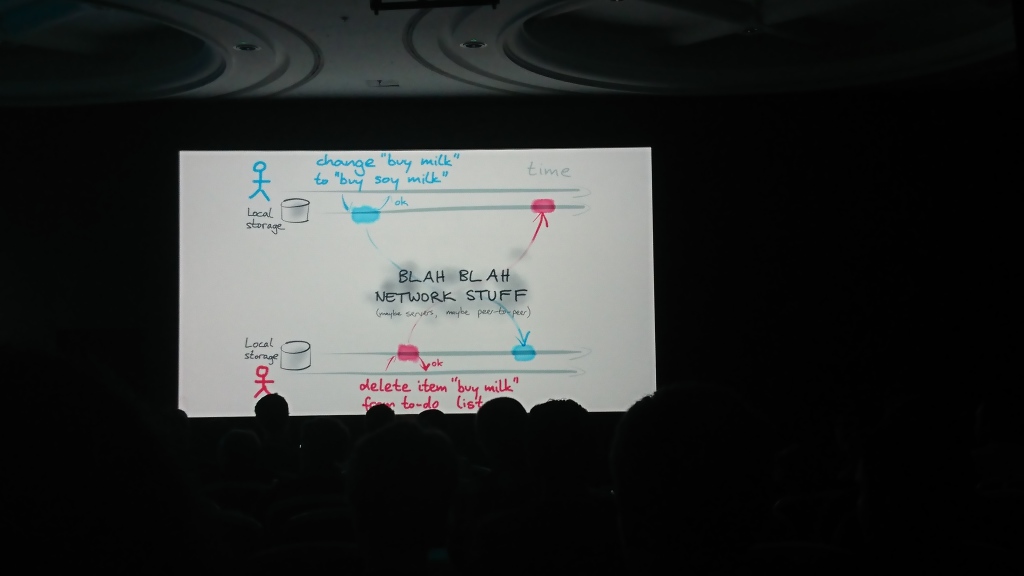


Zusätzliche Materialien:
Ein Programmierhandbuch zum Sichern von Verbindungen
Sprecherin: Liz Rice | Beschreibung und Folien
Der Bericht wurde in Form einer Live-Codierungssitzung gehalten, und darin zeigte Liz, wie HTTPS funktioniert, welche Fehler beim Arbeiten mit sicheren Verbindungen auftreten können und wie diese behoben werden können. Es gab keine großen Tiefen, aber die Demonstration selbst war sehr gut.
Am nützlichsten: eine Folie mit den Hauptfehlern (auch bekannt als Liz 'Bericht auf einer anderen Konferenz ):

Zusätzliche Materialien:
Alles, was Sie über Monorepos wissen wollten, aber Angst hatten zu fragen
Simon Stewart (Selenium-Projekt) | Beschreibung
Die Hauptthese des Berichts ist, dass es in Monorepo viel einfacher ist, Abhängigkeiten im Code zu verwalten, und dies deckt alle Vorteile einzelner Repositorys ab. Er appellierte an die Tatsache, dass Google und Microsoft Daten in einem Repository (86 Tb bzw. 300 Gb) speichern und das Facebook-Repository (54 Gb-Dateien) "off the shell mercurial" verwendet.
Der Raum "explodierte" nach der Frage "Wer hat mehr Repositories im Unternehmen als Mitarbeiter?"
Das Argument "mit einem großen Repository, um langsam zu arbeiten" wurde wie folgt gebrochen:
- Sie müssen nicht den gesamten Änderungsverlauf auf den lokalen Computer übertragen: Verwenden Sie Shadow Clone und Sparse Checkout .
- Sie müssen nicht alle Dateien aus dem Repository verwenden: Organisieren Sie die Hierarchie der Dateien, arbeiten Sie nur mit dem erforderlichen Verzeichnis und schließen Sie alles andere aus.
Zusätzliche Materialien:
Aufbau eines verteilten Echtzeit-Stream-Verarbeitungssystems
Amy Boyle (Neues Relikt) | Beschreibung und Darstellung
Eine gute Geschichte über das Arbeiten mit Streaming-Daten von einem Ingenieur von NewRelic (wo er eindeutig viel Erfahrung im Umgang mit solchen Daten hat). Amy sagte, dass es mit Streaming-Daten funktioniert, wie sie aggregiert werden können, was mit verzögerten Daten gemacht werden kann, wie Ereignisströme gespalten werden können und wie sie bei Prozessorausfällen neu ausgeglichen werden können, was überwacht werden muss usw.
Der Bericht war viel Material, ich werde nicht versuchen, ihn noch einmal zu erzählen, sondern nur empfehlen, die Präsentation selbst zu sehen (sie befindet sich bereits auf der Konferenz-Website).


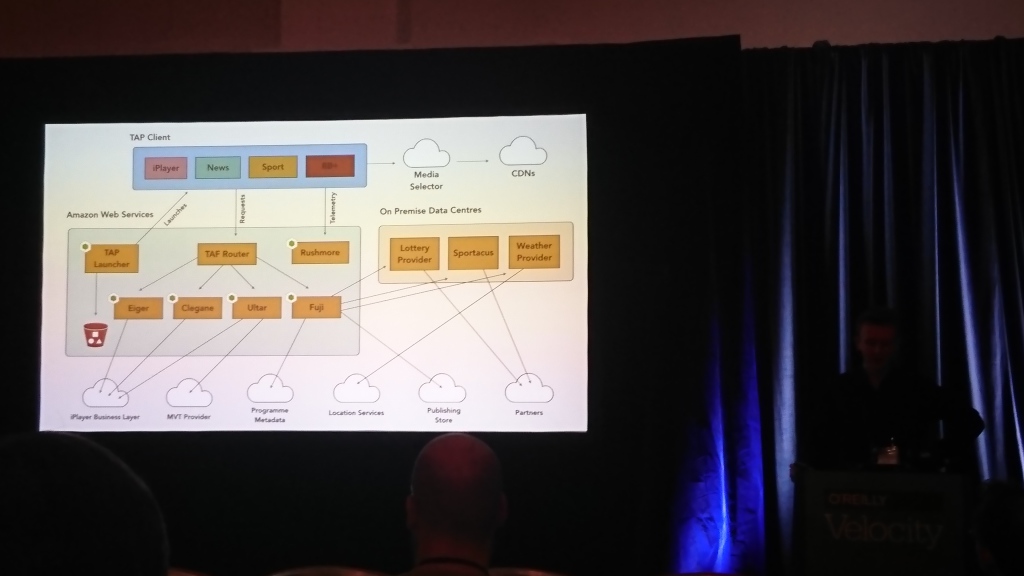
Architektur für das Fernsehen
David Buckhurst (BBC), Ross Wilson (BBC) | Beschreibung
Der größte Teil des Gesprächs drehte sich um das BBC-Frontend. Die Jungs haben interaktives Fernsehen und viele Fernseher und andere Geräte (Computer, Telefone, Tablets), auf denen dies funktionieren sollte. Sie müssen auf völlig unterschiedliche Weise mit verschiedenen Geräten arbeiten. Daher haben sie eine eigene JSON-basierte Sprache entwickelt, um Schnittstellen zu beschreiben und in das zu übersetzen, was ein bestimmtes Gerät verstehen kann.
Die wichtigste Schlussfolgerung für mich ist, dass mobile Anwendungen im Vergleich zu TV-Leuten keine Probleme mit alten Kunden haben.