Anfang des Jahres haben wir uns entschlossen, zu lernen, wie VK-Debugging-Protokolle effizienter als zuvor gespeichert und gelesen werden können. Debugging-Protokolle sind beispielsweise Videokonvertierungsprotokolle (im Grunde die Ausgabe des Befehls ffmpeg und eine Liste von Schritten zur Vorverarbeitung von Dateien), die manchmal nur 2-3 Monate nach der Verarbeitung der Problemdatei benötigt werden.
Zu diesem Zeitpunkt hatten wir zwei Möglichkeiten, Protokolle zu speichern und zu verarbeiten - unsere eigene Protokoll-Engine und rsyslog, die wir parallel verwendeten. Wir begannen andere Optionen in Betracht zu ziehen und stellten fest, dass ClickHouse von Yandex für uns gut geeignet ist - wir entschieden uns, es zu implementieren.
In diesem Artikel werde ich darüber sprechen, wie wir ClickHouse auf VKontakte verwendet haben, auf welche Art von Rechen sie getreten sind und was KittenHouse und LightHouse sind. Beide Produkte sind in Open-Source-Links am Ende des Artikels dargestellt.
Protokollsammlungsaufgabe
Systemanforderungen:
- Speicherung von Hunderten von Terabyte an Protokollen.
- Lagerung für Monate oder (selten) Jahre.
- Hohe Schreibgeschwindigkeit.
- Hohe Lesegeschwindigkeit (Lesen ist selten).
- Indexunterstützung
- Unterstützung für lange Saiten (> 4 Kb).
- Einfache Bedienung.
- Kompakte Lagerung.
- Die Möglichkeit, von Zehntausenden von Servern einzufügen (UDP ist ein Plus).
Mögliche Lösungen
Lassen Sie uns kurz die Optionen auflisten, die wir in Betracht gezogen haben, und ihre Nachteile:
Protokolliert die Engine
Unser selbstgeschriebener Microservice für Protokolle.
- Kann nur die letzten N Zeilen angeben, die in den RAM passen.
- Nicht sehr kompakter Speicher (keine transparente Komprimierung).
Hadoop
- Nicht alle Formate haben Indizes.
- Die Lesegeschwindigkeit kann höher sein (je nach Format).
- Die Komplexität der Einstellungen.
- Es gibt keine Möglichkeit, von Zehntausenden von Servern einzufügen (Kafka oder Analoga werden benötigt).
Rsyslog + -Dateien
- Keine Indizes.
- Niedrige Lesegeschwindigkeit (normales grep / zgrep).
- Architektonisch nicht unterstützte Strings> 4 Kb, UDP noch weniger (1,5 Kb).
± Eine kompakte Lagerung wird durch logrotate über der Krone erreicht
Wir haben rsyslog als Fallback für die Langzeitspeicherung verwendet, aber lange Zeilen wurden abgeschnitten, sodass es kaum als ideal bezeichnet werden kann.
LSD + -Dateien
- Keine Indizes.
- Niedrige Lesegeschwindigkeit (normales grep / zgrep).
- Nicht speziell für das Einfügen von Zehntausenden von Servern konzipiert.
± Eine kompakte Lagerung wird durch logrotate über der Krone erreicht.
Die Unterschiede zu rsyslog bestehen in unserem Fall darin, dass LSD lange Zeichenfolgen unterstützt. Zum Einfügen von Zehntausenden von Servern sind jedoch erhebliche Änderungen am internen Protokoll erforderlich, obwohl dies möglich ist.
Elasticsearch
- Betriebsprobleme.
- Instabile Aufnahme.
- Kein UDP.
- Schlechte Komprimierung.
Der ELK-Stack ist bereits fast der Industriestandard für die Protokollspeicherung. Nach unserer Erfahrung ist alles in Ordnung mit der Lesegeschwindigkeit, aber es gibt Probleme beim Schreiben, zum Beispiel beim Zusammenführen von Indizes.
ElasticSearch wurde hauptsächlich für die Volltextsuche und relativ häufige Leseanforderungen entwickelt. Für uns sind eine stabile Aufzeichnung und die Fähigkeit, unsere Daten mehr oder weniger schnell zu lesen, wichtiger und genau zufällig. Der Index bei ElasticSearch ist für die Volltextsuche geschärft, und der Speicherplatz ist im Vergleich zum gzip des ursprünglichen Inhalts ziemlich groß.
Clickhouse
- Kein UDP.
Im Großen und Ganzen war das einzige, was uns bei ClickHouse nicht gefiel, der Mangel an UDP-Kommunikation. Von den oben genannten Optionen verfügte nur rsyslog darüber, aber rsyslog unterstützte keine langen Warteschlangen.
Nach anderen Kriterien kam ClickHouse auf uns zu und wir entschieden uns, es zu verwenden, und Probleme mit dem Transport wurden dabei gelöst.
Warum KittenHouse benötigt wird
Wie Sie wahrscheinlich wissen, arbeitet VKontakte mit PHP / KPHP, mit "Engines" (Microservices) in C / C ++ und ein wenig mit Go. PHP hat kein Konzept des "Status" zwischen Anforderungen, außer vielleicht für gemeinsam genutzten Speicher und offene Verbindungen.
Da wir Zehntausende von Servern haben, von denen wir Protokolle an ClickHouse senden möchten, wäre es unrentabel, offene Verbindungen von jedem PHP-Worker aufrechtzuerhalten (es können mehr als 100 Worker für jeden Server sein). Daher benötigen wir eine Art Proxy zwischen ClickHouse und PHP. Wir haben diesen Proxy KittenHouse genannt.
KittenHouse, v1
Zuerst haben wir uns entschlossen, ein möglichst einfaches Schema auszuprobieren, um zu verstehen, ob unser Ansatz funktioniert oder nicht. Wenn Ihnen Kafka bei der Lösung dieses Problems in den Sinn kommt, sind Sie nicht allein. Wir wollten jedoch keine zusätzlichen Zwischenserver verwenden. In diesem Fall können wir uns leicht auf die Leistung dieser Server und nicht auf ClickHouse selbst verlassen. Außerdem haben wir Protokolle gesammelt und brauchten eine vorhersehbare und kleine Verzögerung beim Einfügen von Daten. Das Schema ist wie folgt:

Auf jedem der Server ist unser lokaler Proxy (Kittenhouse) installiert, und jede Instanz unterhält ausschließlich eine HTTP-Verbindung mit dem erforderlichen ClickHouse-Server. Das Einfügen erfolgt in Spool-Tabellen, da das Einfügen von MergeTree häufig nicht empfohlen wird.
Eigenschaften KittenHouse, v1
Die erste Version von KittenHouse wusste einiges, aber dies war genug zum Testen:
- Kommunikation über unser RPC (TL Scheme).
- Pflegen Sie 1 TCP / IP-Verbindung pro Server.
- Standardmäßig speicherinterne Pufferung mit begrenzter Puffergröße (der Rest wird verworfen).
- Die Möglichkeit, auf die Festplatte zu schreiben, besteht in diesem Fall eine Zustellgarantie (mindestens einmal).
- Das Einfügeintervall beträgt einmal alle 2 Sekunden.
Erste Probleme
Das erste Problem trat auf, als wir den ClickHouse-Server mehrere Stunden lang „zurückzahlten“ und ihn dann wieder einschalteten. Unten sehen Sie den Lastdurchschnitt auf dem Server, nachdem dieser "gestiegen" ist:
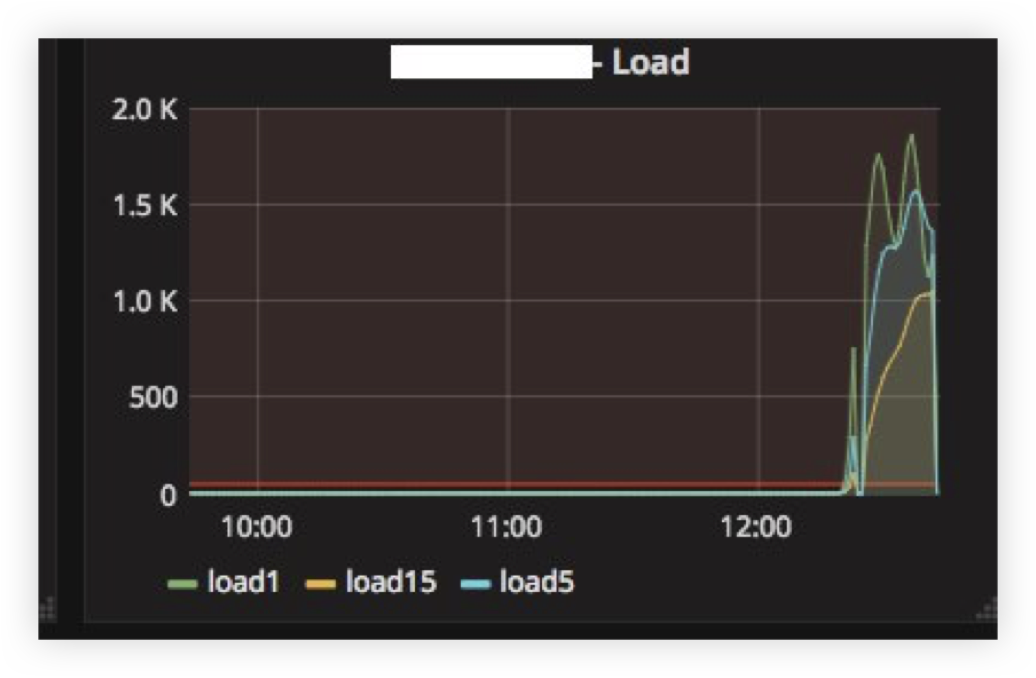
Die Erklärung ist recht einfach: ClickHouse verfügt über ein Netzwerk pro Thread-Modell. Wenn ich also versuche, INSERT aus Tausenden von Knoten gleichzeitig zu erstellen, gab es eine sehr starke Konkurrenz um CPU-Ressourcen und der Server reagierte kaum. Schließlich wurden jedoch alle Daten eingefügt und nichts fiel.
Um dieses Problem zu lösen, haben wir nginx vor ClickHouse gestellt und im Allgemeinen hat es geholfen.
Weiterentwicklung
Während des Betriebs stießen wir auf eine Reihe von Problemen, die hauptsächlich nicht mit ClickHouse, sondern mit unserer Funktionsweise zusammenhängen. Hier ist ein weiterer Rechen, auf den wir getreten sind:
Eine große Anzahl von "Blöcken" von Puffertabellen führt zu häufigen Pufferlöschungen in MergeTree
In unserem Fall gab es alle 2 Sekunden 16 Pufferstücke und ein Rücksetzintervall, und es gab 20 Tabellenstücke, die bis zu 160 Einfügungen pro Sekunde ergaben. Dies wirkte sich in regelmäßigen Abständen sehr stark auf die Einfügeleistung aus - es gab viele Hintergrundzusammenführungen und die Festplattenauslastung erreichte 80% und mehr.
Lösung: Erhöhen Sie das Standardintervall für das Zurücksetzen des Puffers und reduzieren Sie die Anzahl der Teile auf 2.
Nginx gibt 502 zurück, wenn Verbindungen zum Upstream-Ende hergestellt werden
Dies ist an sich kein Problem, aber in Kombination mit dem häufigen Leeren des Puffers ergab dies einen ziemlich hohen Hintergrund von 502 Fehlern beim Versuch, in eine der Tabellen einzufügen, sowie beim Versuch, SELECT auszuführen.
Lösung: Sie haben ihren Reverse-Proxy mithilfe der
fasthttp- Bibliothek geschrieben, die die Einfügung in Tabellen gruppiert und Verbindungen sehr wirtschaftlich verbraucht. Es unterscheidet auch zwischen SELECT und INSERT und verfügt über separate Verbindungspools zum Einfügen und Lesen.
Bei intensiver Einfügung geht der Speicher aus
Die fasthttp-Bibliothek hat ihre Vor- und Nachteile. Einer der Nachteile besteht darin, dass die Anforderung und die Antwort vollständig im Speicher gepuffert sind, bevor der Anforderungshandler gesteuert wird. Für uns führte dies dazu, dass, wenn die Einfügung in ClickHouse "keine Zeit hatte", die Puffer zu wachsen begannen und schließlich der gesamte Speicher auf dem Server leer wurde, was dazu führte, dass OOM den Reverse Proxy tötete. Kollegen haben einen Demotivator gezogen:
 Lösung: Das
Lösung: Das Patchen von fasthttp zur Unterstützung des Streamings der POST-Anforderung stellte sich als entmutigende Aufgabe heraus. Daher haben wir uns entschieden, Hijack () -Verbindungen zu verwenden und die Verbindung zu unserem Protokoll zu aktualisieren, wenn die Anforderung mit der KITTEN-HTTP-Methode geliefert wurde. Da der Server MEOW als Antwort antworten muss, wird das gesamte Schema als KITTEN / MEOW-Protokoll bezeichnet, wenn er dieses Protokoll versteht.
Wir lesen jeweils nur von 50 zufälligen Verbindungen. Dank TCP / IP „warten“ die restlichen Clients und geben keinen Speicher für Puffer aus, bis die Warteschlange die jeweiligen Clients erreicht. Dies reduzierte den Speicherverbrauch um mindestens das 20-fache, und wir hatten keine derartigen Probleme mehr.
ALTER-Tabellen können bei langen Abfragen sehr lang werden
ClickHouse verfügt über einen nicht blockierenden ALTER in dem Sinne, dass er sowohl SELECT- als auch INSERT-Abfragen nicht beeinträchtigt. ALTER kann jedoch erst gestartet werden, wenn die vor ALTER gesendeten Abfragen an diese Tabelle abgeschlossen sind.
Wenn Sie Hintergrundinformationen zu „langen“ Abfragen an Tabellen auf Ihrem Server haben, kann es vorkommen, dass ALTER in dieser Tabelle in einem Standardzeitlimit von 60 Sekunden keine Zeit für die Ausführung hat. Dies bedeutet jedoch nicht, dass ALTER fehlschlägt: Es wird ausgeführt, sobald diese SELECT-Abfragen abgeschlossen sind.
Dies bedeutet, dass Sie nicht wissen, zu welchem Zeitpunkt ALTER tatsächlich aufgetreten ist, und dass Sie nicht in der Lage sind, Puffertabellen automatisch neu zu erstellen, sodass ihr Layout immer gleich ist. Dies kann zu Einfügeproblemen führen.

 Lösung: Aus diesem
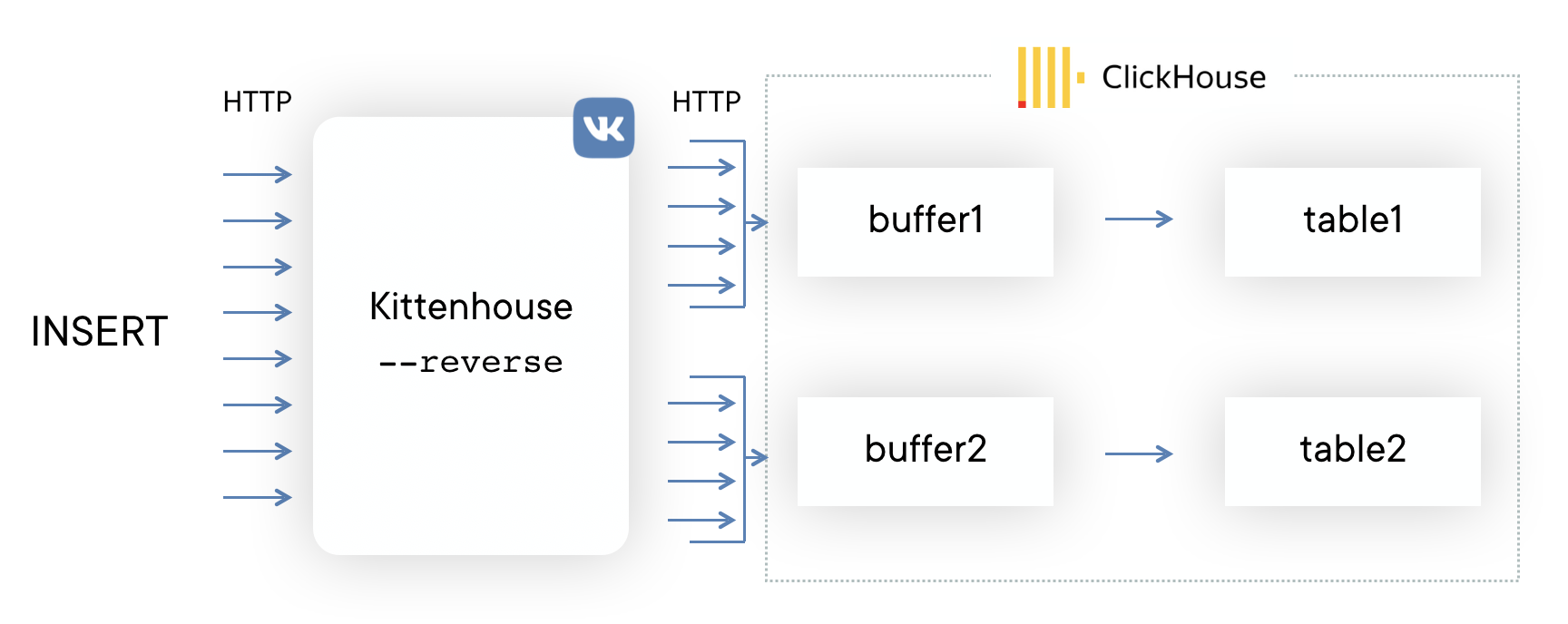
Lösung: Aus diesem Grund planen wir, die Verwendung von Puffertabellen vollständig aufzugeben. Im Allgemeinen haben Puffertabellen einen Gültigkeitsbereich. Bisher verwenden wir sie und haben keine großen Probleme. Jetzt haben wir endlich den Punkt erreicht, an dem es einfacher ist, die Funktionalität von Puffertabellen auf der Reverse-Proxy-Seite zu implementieren, als ihre Mängel weiterhin in Kauf zu nehmen. Eine Beispielschaltung sieht folgendermaßen aus (die gestrichelte Linie zeigt die ACK-Asynchronität bei INSERT).

Daten lesen
Nehmen wir an, wir haben die Beilage herausgefunden. Wie lese ich diese Protokolle von ClickHouse? Leider haben wir keine praktischen und benutzerfreundlichen Tools zum Lesen von Rohdaten (ohne Grafiken und andere) von ClickHouse gefunden. Deshalb haben wir unsere eigene Lösung geschrieben - LightHouse. Seine Fähigkeiten sind eher bescheiden:
- Schnelle Ansicht des Tabelleninhalts.
- Filtern, Sortieren.
- Bearbeiten einer SQL-Abfrage.
- Tabellenstruktur anzeigen.
- Zeigt die ungefähre Anzahl der Zeilen und den verwendeten Speicherplatz an.
LightHouse ist jedoch schnell und in der Lage, das zu tun, was wir brauchen. Hier ein paar Screenshots:
Tabellenstruktur anzeigen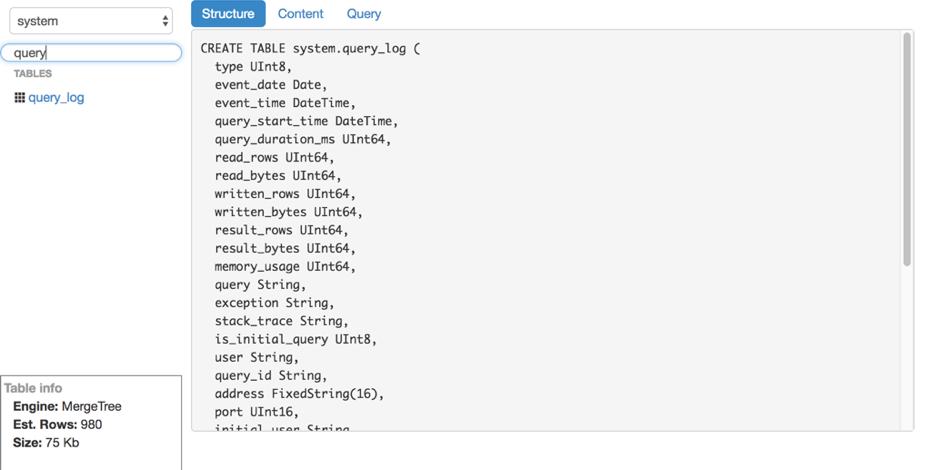 Inhaltsfilterung
Inhaltsfilterung
Ergebnisse
ClickHouse ist praktisch die einzige Open-Source-Datenbank, die in VKontakte Fuß gefasst hat. Wir sind mit der Geschwindigkeit seiner Arbeit zufrieden und bereit, die unten diskutierten Mängel in Kauf zu nehmen.
Schwierigkeiten bei der Arbeit
Alles in allem ist ClickHouse eine sehr stabile Datenbank und sehr schnell. Wie bei jedem Produkt, insbesondere bei so jungen, gibt es jedoch Merkmale in der Arbeit, die berücksichtigt werden müssen:
- Nicht alle Versionen sind gleich stabil: Aktualisieren Sie in der Produktion nicht direkt auf die neue Version. Warten Sie besser auf mehrere Bugfix-Versionen.
- Für eine optimale Leistung ist es sehr ratsam, RAID und einige andere Dinge gemäß den Anweisungen zu konfigurieren. Dies wurde kürzlich bei Hochlast gemeldet .
- Die Replikation hat keine integrierten Geschwindigkeitsbegrenzungen und kann die Serverleistung erheblich beeinträchtigen, wenn Sie sie nicht selbst einschränken (sie versprechen jedoch, sie zu beheben).
- Linux hat eine unangenehme Funktion des virtuellen Speichermechanismus: Wenn Sie aktiv auf die Festplatte schreiben und die Daten keine Zeit zum Löschen haben, geht der Server irgendwann vollständig in sich selbst über, beginnt aktiv, den Seitencache auf die Festplatte zu leeren und blockiert den ClickHouse-Prozess fast vollständig. Dies geschieht manchmal bei großen Zusammenführungen, und Sie müssen dies überwachen, z. B. die Puffer regelmäßig selbst leeren oder synchronisieren.
Open Source
KittenHouse und LightHouse sind jetzt als Open Source in unserem Github-Repository verfügbar:
Vielen Dank!
Yuri Nasretdinov, Entwickler in der Backend-Infrastrukturabteilung von VKontakte